解析从Linux零拷贝深入了解Linux-I/O(下)
接上文解析从Linux零拷贝深入了解Linux-I/O(上)
大文件传输场景
零拷贝还是最优选吗
在大文件传输的场景下,零拷贝技术并不是最优选择;因为在零拷贝的任何一种实现中,都会有「DMA 将数据从磁盘拷贝到内核缓存区——Page Cache」这一步,但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能。
这是因为在大文件传输场景下,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,PageCache 空间很快被这些大文件占满;且由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,这样就会带来 2 个问题:
-
PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache,于是这样磁盘读写的性能就会下降了;
-
PageCache 中的大文件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷贝到 PageCache 一次。
异步 I/O +direct I/O
那么大文件传输场景下我们该选择什么方案呢?让我们先来回顾一下我们在文章开头介绍 DMA 时最早提到过的同步 I/O:

这里的同步 体现在当进程调用 read 方法读取文件时,进程实际上会阻塞在 read 方法调用,因为要等待磁盘数据的返回,并且我们当然不希望进程在读取大文件时被阻塞,对于阻塞的问题,可以用异步 I/O 来解决,即:
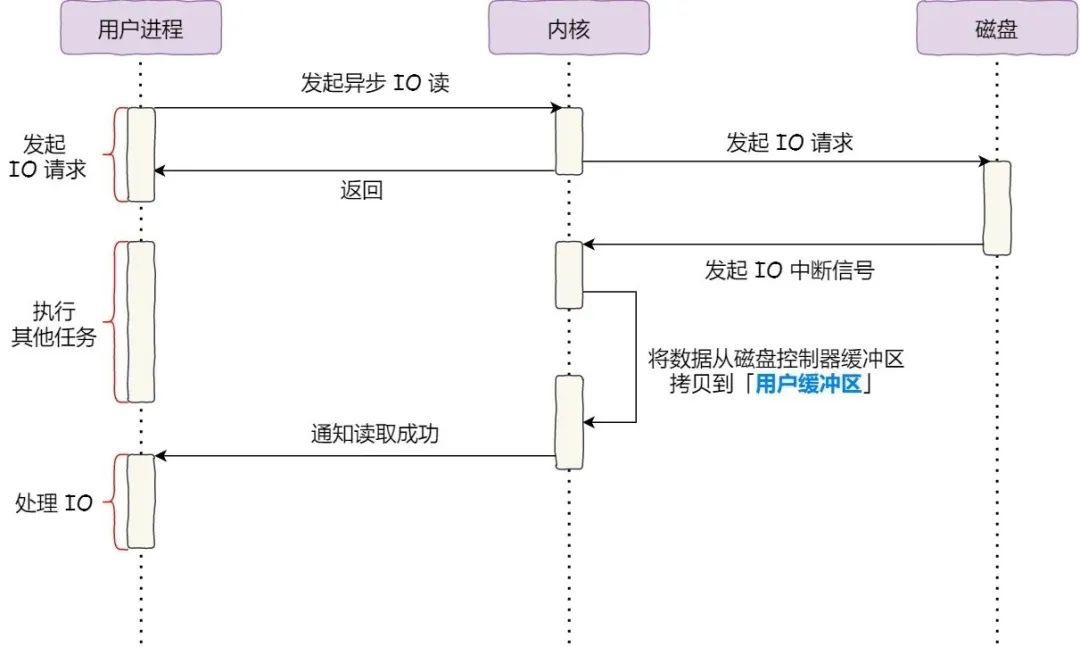
它把读操作分为两部分:
-
前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就返回 ,于是进程此时可以处理其他任务;
-
后半部分,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知 ,再去处理数据;
而且,我们可以发现,异步 I/O 并没有涉及到 PageCache;使用异步 I/O 就意味着要绕开 PageCache,因为填充 PageCache 的过程在内核中必须阻塞。
所以异步 I/O 中使用的是direct I/O(对比使用 PageCache 的buffer I/O),这样才能不阻塞进程,立即返回。
direct I/O 应用场景常见的两种:
-
应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启direct I/O,默认是不开启;
-
传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用`direct I/O;;
当然,由于direct I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
-
内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并 」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
-
内核也会「预读 」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作;
实际应用中也有类似的配置,在 nginx 中,我们可以用如下配置,来根据文件的大小来使用不同的方式传输:
location /video/ { sendfile on; aio on; directio 1024m; }当文件大小大于 directio 值后,使用「异步 I/O + 直接 I/O」,否则使用「零拷贝技术」。
使用 direct I/O 需要注意的点
首先,贴一下我们的Linus(Linus Torvalds)对 O_DIRECT的评价:
"The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances." —Linus
一般来说能引得Linus开骂的东西,那是一定有很多坑的。
在 Linux 的man page中我们可以看到O_DIRECT 下有一个 Note,还挺长的,这里我就不贴出来了。
总结一下其中需要注意的点如下:
地址对齐限制
O_DIRECT 会带来强制的地址对齐限制,这个对齐的大小也跟文件系统/存储介质 相关,并且当前没有不依赖文件系统自身的接口提供指定文件/文件系统是否有这些限制的信息
-
Linux 2.6 以前 总传输大小、用户的对齐缓冲区起始地址、文件偏移量必须都是逻辑文件系统的数据块 大小的倍数,这里说的数据块(block)是一个逻辑概念,是文件系统捆绑一定数量的连续扇区而来,因此通常称为 “文件系统逻辑块”,可通过以下命令获取:blockdev --getss
-
Linux2.6以后对齐的基数变为物理上的存储介质的sector size扇区大小,对应物理存储介质的最小存储粒度,可通过以下命令获取:blockdev --getpbsz
带来这个限制的原因也很简单,内存对齐这件小事通常是内核来处理的,而O_DIRECT 绕过了内核空间,那么内核处理的所有事情都需要用户自己来处理,这里贴一篇详细解释。
O_DIRECT 平台不兼容
这应该是大部分跨平台应用需要注意到的点,O_DIRECT 本身就是Linux中才有的东西,在语言层面 / 应用层面需要考虑这里的兼容性保证,比如在Windows下其实也有类似的机制FILE_FLAG_NO_BUFFERIN 用法类似,参考微软的官方文档;再比如macOS下的F_NOCACHE 虽然类似O_DIRECT ,但实际使用中也有差距(参考这个issue)。
不要并发地运行 fork 和 O_DIRECT I/O
如果O_DIRECT I/O中使用到的内存buffer是一段私有的映射(虚拟内存),如任何使用上文中提到过的mmap并以MAP_PRIVATE flag 声明的虚拟内存,那么相关的O_DIRECT I/O(不管是异步 I/O / 其它子线程中的 I/O)都必须在调用fork系统调用前执行完毕;否则会造成数据污染或产生未定义的行为(实例可参考这个Page)。
以下情况这个限制不存在:
-
相关的内存buffer是使用shmat分配或是使用mmap以MAP_SHARED flag 声明的;
-
相关的内存buffer是使用madvise以MADV_DONTFORK 声明的(注意这种方式下该内存buffer在子进程中不可用)。
避免对同一文件混合使用 O_DIRECT 和普通 I/O
在应用层需要避免对同一文件(尤其是对同一文件的相同偏移区间内 )混合使用O_DIRECT和普通I/O;即使我们的文件系统能够帮我们处理和保证这里的一致性问题 ,总体来说整个I/O吞吐量也会比单独使用某一种I/O方式要小。
同样的,应用层也要避免对同一文件混合使用direct I/O和mmap。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
NFS 协议下的 O_DIRECT
虽然NFS文件系统就是为了让用户像访问本地文件一样去访问网络文件,但O_DIRECT在NFS文件系统中的表现和本地文件系统不同,比较老版本的内核或是魔改过的内核可能并不支持这种组合。
这是因为在NFS协议中并不支持传递flag 参数 到服务器,所以O_DIRECT I/O实际上只绕过了本地客户端的Page Cache,但服务端/同步客户端仍然会对这些I/O进行cache。
当客户端请求服务端进行I/O同步来保证O_DIRECT的同步语义时,一些服务器的性能表现不佳(尤其是当这些I/O很小时);还有一些服务器干脆设置为欺骗客户端 ,直接返回客户端「数据已写入存储介质 」,这样就可以一定程度上避免I/O同步带来的性能损失,但另一方面,当服务端断电时就无法保证未完成I/O同步的数据的数据完整性 了。
Linux的NFS客户端也没有上面说过的地址对齐的限制。
在 Golang 中使用 direct I/O
direct io 必须要满足 3 种对齐规则:io 偏移扇区对齐,长度扇区对齐,内存 buffer 地址扇区对齐;前两个还比较好满足,但是分配的内存地址仅凭原生的手段是无法直接达成的。
先对比一下 c 语言,libc 库是调用 posix_memalign 直接分配出符合要求的内存块,但Golang中要怎么实现呢?
在Golang中,io 的 buffer 其实就是字节数组,自然是用 make 来分配,如下:
buffer := make([]byte, 4096)但buffer中的data字节数组首地址并不一定是对齐的。
方法也很简单,就是先分配一个比预期要大的内存块,然后在这个内存块里找对齐位置 ;这是一个任何语言皆通用的方法,在 Go 里也是可用的。
比如,我现在需要一个 4096 大小的内存块,要求地址按照 512 对齐,可以这样做:
-
先分配 4096 + 512 大小的内存块,假设得到的内存块首地址是 p1;
-
然后在 [ p1, p1+512 ] 这个地址范围找,一定能找到 512 对齐的地址 p2;
-
返回 p2 ,用户能正常使用 [ p2, p2 + 4096 ] 这个范围的内存块而不越界。
以上就是基本原理了 ,具体实现如下:
// 从 block 首地址往后找到符合 AlignSize 对齐的地址并返回
// 这里很巧妙的使用了位运算,性能upup
func alignment(block []byte, AlignSize int) int {return int(uintptr(unsafe.Pointer(&block[0])) & uintptr(AlignSize-1))
}// 分配 BlockSize 大小的内存块
// 地址按 AlignSize 对齐
func AlignedBlock(BlockSize int) []byte {// 分配一个大小比实际需要的稍大block := make([]byte, BlockSize+AlignSize)// 计算到下一个地址对齐点的偏移量a := alignment(block, AlignSize)offset := 0if a != 0 {offset = AlignSize - a}// 偏移指定位置,生成一个新的 block,这个 block 就满足地址对齐了block = block[offset : offset+BlockSize]if BlockSize != 0 {// 最后做一次地址对齐校验a = alignment(block, AlignSize)if a != 0 {log.Fatal("Failed to align block")}}return block
}
所以,通过以上 AlignedBlock 函数分配出来的内存一定是 512 地址对齐的,唯一的一点点缺点就是在分配较小内存块时对齐的额外开销显得比较大。
开源实现
Github 上就有开源的Golang direct I/O实现:ncw/directio
使用也很简单:
- O_DIRECT 模式打开文件:
// 创建句柄
fp, err := directio.OpenFile(file, os.O_RDONLY, 0666)
- 读数据
// 创建地址按照 4k 对齐的内存块 buffer := directio.AlignedBlock(directio.BlockSize) // 把文件数据读到内存块中 _, err := io.ReadFull(fp, buffer)内核缓冲区和用户缓冲区之间的传输优化
到目前为止,我们讨论的 zero-copy技术都是基于减少甚至是避免用户空间和内核空间之间的 CPU 数据拷贝的,虽然有一些技术非常高效,但是大多都有适用性很窄的问题,比如 sendfile()、splice() 这些,效率很高,但是都只适用于那些用户进程不需要再处理数据 的场景,比如静态文件服务器或者是直接转发数据的代理服务器。
前面提到过的虚拟内存机制和mmap等都表明,通过在不同的虚拟地址上重新映射页面可以实现在用户进程和内核之间虚拟复制和共享内存;因此如果要在实现在用户进程内处理数据(这种场景比直接转发数据更加常见)之后再发送出去的话,用户空间和内核空间的数据传输就是不可避免的 ,既然避无可避,那就只能选择优化了。
两种优化用户空间和内核空间数据传输的技术:
- 动态重映射与写时拷贝 (Copy-on-Write)
- 缓冲区共享 (Buffer Sharing)
写时拷贝 (Copy-on-Write)
前面提到过过利用内存映射(mmap)来减少数据在用户空间和内核空间之间的复制,通常用户进程是对共享的缓冲区进行同步阻塞读写的,这样不会有线程安全 问题,但是很明显这种模式下效率并不高,而提升效率的一种方法就是异步地对共享缓冲区进行读写 ,而这样的话就必须引入保护机制来避免数据冲突 问题,COW (Copy on Write) 就是这样的一种技术。
COW 是一种建立在虚拟内存重映射技术之上的技术,因此它需要 MMU 的硬件支持,MMU 会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候,MMU 就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU 发出执行该进程的写操作。
下图为COW在Linux中的应用之一: fork / clone,fork出的子进程共享父进程的物理空间,当父子进程有内存写入操作时 ,read-only内存页发生中断,将触发的异常的内存页复制一份 (其余的页还是共享父进程的)。

局限性
COW 这种零拷贝技术比较适用于那种多读少写从而使得 COW 事件发生较少的场景 ,而在其它场景下反而可能造成负优化,因为 COW事件所带来的系统开销要远远高于一次 CPU 拷贝所产生的。
此外,在实际应用的过程中,为了避免频繁的内存映射,可以重复使用同一段内存缓冲区,因此,你不需要在只用过一次共享缓冲区之后就解除掉内存页的映射关系,而是重复循环使用,从而提升性能。
但这种内存页映射的持久化并不会减少由于页表往返移动/换页和 TLB flush所带来的系统开销,因为每次接收到 COW 事件之后对内存页而进行加锁或者解锁的时候,内存页的只读标志 (read-ony) 都要被更改为 (write-only)。
COW 的实际应用
Redis 的持久化机制
Redis 作为典型的内存型应用,一定是有内核缓冲区和用户缓冲区之间的传输优化的。
Redis 的持久化机制中,如果采用 bgsave 或者 bgrewriteaof 命令,那么会 fork 一个子进程来将数据存到磁盘中;总体来说Redis 的读操作是比写操作多的(在正确的使用场景下),因此这种情况下使用 COW 可以减少 fork() 操作的阻塞时间。
语言层面的应用
写时复制的思想在很多语言中也有应用,相比于传统的深层复制,能带来很大性能提升;比如 C++ 98 标准下的 std::string 就采用了写时复制的实现:
std::string x("Hello");
std::string y = x; // x、y 共享相同的 buffer
y += ", World!"; // 写时复制,此时 y 使用一个新的 buffer// x 依然使用旧的 buffer
Golang中的string, slice也使用了类似的思想,在复制 / 切片等操作时都不会改变底层数组的指向,变量共享同一个底层数组,仅当进行append / 修改等操作时才可能进行真正的copy(append时如果超过了当前切片的容量,就需要分配新的内存)。
缓冲区共享 (Buffer Sharing)
从前面的介绍可以看出,传统的 Linux I/O接口,都是基于复制/拷贝的:数据需要在操作系统内核空间和用户空间的缓冲区之间进行拷贝。在进行 I/O 操作之前,用户进程需要预先分配好一个内存缓冲区,使用 read() 系统调用时,内核会将从存储器或者网卡等设备读入的数据拷贝到这个用户缓冲区里;而使用 write() 系统调用时,则是把用户内存缓冲区的数据拷贝至内核缓冲区。
为了实现这种传统的 I/O 模式,Linux 必须要在每一个 I/O 操作时都进行内存虚拟映射和解除。这种内存页重映射的机制的效率严重受限于缓存体系结构、MMU 地址转换速度和 TLB 命中率。如果能够避免处理 I/O 请求的虚拟地址转换和 TLB 刷新所带来的开销,则有可能极大地提升 I/O 性能。而缓冲区共享就是用来解决上述问题的一种技术(说实话我觉得有些套娃的味道了)。
操作系统内核开发者们实现了一种叫 fbufs 的缓冲区共享的框架,也即快速缓冲区( Fast Buffers ),使用一个 fbuf 缓冲区作为数据传输的最小单位,使用这种技术需要调用新的操作系统 API,用户区和内核区、内核区之间的数据都必须严格地在 fbufs 这个体系下进行通信。fbufs 为每一个用户进程分配一个 buffer pool,里面会储存预分配 (也可以使用的时候再分配) 好的 buffers,这些 buffers 会被同时映射到用户内存空间和内核内存空间。fbufs 只需通过一次虚拟内存映射操作即可创建缓冲区,有效地消除那些由存储一致性维护所引发的大多数性能损耗。
共享缓冲区技术的实现需要依赖于用户进程、操作系统内核、以及 I/O 子系统 (设备驱动程序,文件系统等)之间协同工作 。比如,设计得不好的用户进程容易就会修改已经发送出去的 fbuf 从而污染数据,更要命的是这种问题很难 debug。虽然这个技术的设计方案非常精彩,但是它的门槛和限制却不比前面介绍的其他技术少:首先会对操作系统 API 造成变动,需要使用新的一些 API 调用,其次还需要设备驱动程序配合改动,还有由于是内存共享,内核需要很小心谨慎地实现对这部分共享的内存进行数据保护和同步的机制,而这种并发的同步机制是非常容易出 bug 的从而又增加了内核的代码复杂度,等等。因此这一类的技术还远远没有到发展成熟和广泛应用的阶段,目前大多数的实现都还处于实验阶段 。
总结
从早期的I/O到DMA,解决了阻塞CPU的问题;而为了省去I/O过程中不必要的上下文切换和数据拷贝过程,零拷贝技术就出现了。
所谓的零拷贝(Zero-copy)技术,就是完完全全不需要在内存层面拷贝数据,省去CPU搬运数据的过程。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运 。
总体来看,零拷贝技术至少可以把文件传输的性能提高一倍以上 ,以下是各方案详细的成本对比:
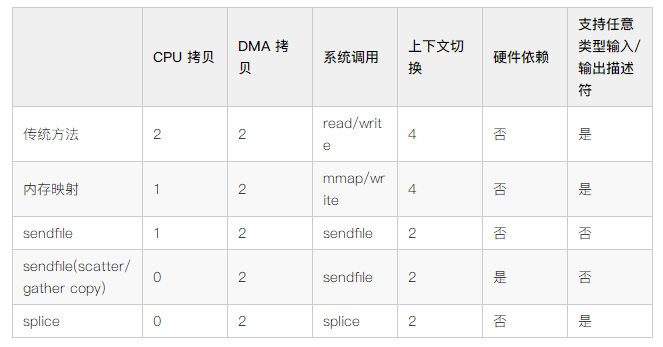
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 I/O 合并与预读,这也是顺序读比随机读性能好的原因之一;这些优势,进一步提升了零拷贝的性能。
但当面对大文件传输时,不能使用零拷贝,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache的问题,并且大文件的缓存命中率不高,这时就需要使用「异步 I/O + direct I/O 」的方式;在使用direct I/O时也需要注意许多的坑点 ,毕竟连Linus也会被 O_DIRECT 'disturbed' 到。
而在更广泛的场景下,我们还需要注意到内核缓冲区和用户缓冲区之间的传输优化 ,这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化,延续了以往那种传统的通信方式,但更灵活。
I/O相关的各类优化自然也已经深入到了日常我们接触到的语言、中间件以及数据库的方方面面,通过了解和学习这些技术和思想,也能对日后自己的程序设计以及性能优化上有所启发。


相关文章:
解析从Linux零拷贝深入了解Linux-I/O(下)
接上文解析从Linux零拷贝深入了解Linux-I/O(上) 大文件传输场景 零拷贝还是最优选吗 在大文件传输的场景下,零拷贝技术并不是最优选择;因为在零拷贝的任何一种实现中,都会有「DMA 将数据从磁盘拷贝到内核缓存区——P…...

【学习笔记2.19】动态规划、MySQL、Linux、Redis(框架)
动态规划 343整数拆分 class Solution {public int integerBreak(int n) {int dp [] new int [n 1];//dp[i]:正整数i拆分后的最大乘积dp[2] 1;for(int i 2;i < n ;i ){for(int j 1;j < i;j ){dp[i] Math.max(dp[i],Math.max(j * (i - j),j * dp[i - j]));} …...
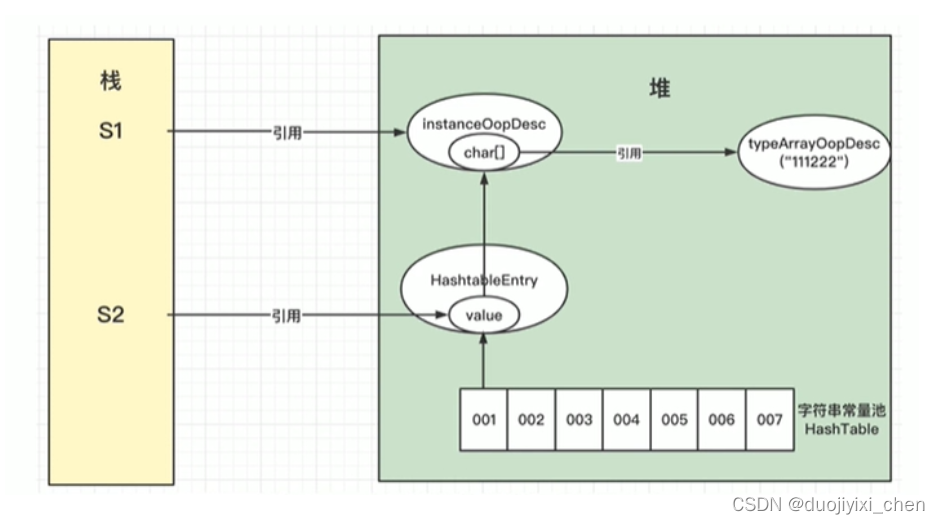
String intern方法理解
1、原理 参考学习视频: https://www.bilibili.com/video/BV1WK4y1M77t/?spm_id_from333.337.search-card.all.click&vd_source4dc3f886f5ce1d43363b603935f02bd1 String s1 “hello”; String s1 "hello"; 代码原理解释如下图String s1 new Str…...

解决 cocosjs与安卓原生集成 崩溃问题
版本:cocos2dx3.16 背景:公司需要把游戏整合到一个APP里面。于是打算通过activity切换的方式实现。但是游戏退出重进之后总会出现fatal 11线程报错。于是有了以下修改。我是底层小白。折腾了好久总算鼓捣出一个能用的版本。优化的地方应该有很多。不过就没去好好优…...
spring注解方式整合Dubbo
系列文章目录 文章目录系列文章目录一、创建一个父工程项目二、创建子模块(dubbo-api模块)二、创建子模块(dubbo-provider模块)三、创建子模块(dubbo-consumer模块)总结一、创建一个父工程项目 这里我们通过Spring Initializer 来帮我们构建一个spring-dubbo这个父项目,点击nex…...
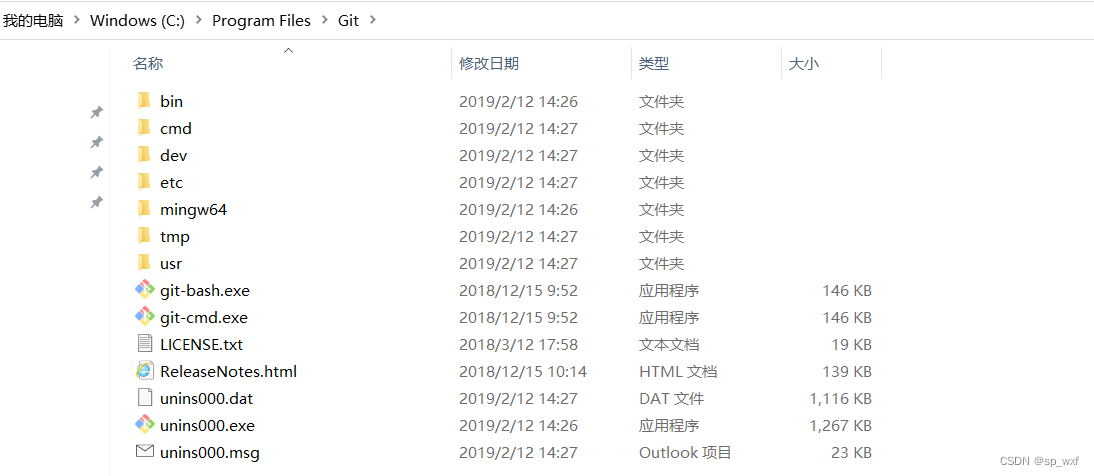
Git详解
Git1.Git简介1.1 Git是什么1.2 Git的作用1.3 Git的简介1.4 Git的下载和安装1.5 Git的安装目录结构如下2.Git代码托管服务2.1 常用的Git代码托管服务1.Git简介 1.1 Git是什么 Git是一个分布式版本控制工具,主要用于管理开发过程中的源代码文件(Java类、x…...

003__JAVA模板方法-设计模式
模板方法 定义:定义了一个算法的骨架,并允许子类为一个或多个步骤提供实现 举个例子,把大象放进冰箱分几步,第一打开冰箱,第二打大象放进冰箱,第三把冰箱关闭。这三个步骤就可以用模板方法的设计模式。 …...

Springboot项目集成Netty组件
系列文章目录 Springboot项目集成Netty组件 Netty新增解析数据包指定长度功能 文章目录系列文章目录前言一、Netty是什么?二、使用步骤1. 项目引入依赖1.1 项目基础版本信息:1.2 Netty依赖2. 项目配置2.1 在 yml 配置文件中配置以下:2.2 创建…...

python 中的import cfg问题
pip install cfg 报错: ERROR: Could not find a version that satisfies the requirement cfg (from versions: none) ERROR: No matching distribution found for cfg 要使用pip install cfg2才行...
[oeasy]python0088_字节_Byte_存储单位_KB_MB_GB_TB
编码进化 回忆上次内容 上次 回顾了 字符大战的结果 ibm 曾经的 EBCDIC 由于字符不连续的隐患 导致后续 出现 无数问题无法补救 7-bit 的 ASA X3.4-1963 字母序号连续 比较字符时 效率高判断字符 是否是字母 也很容易 获得了 IBM以外公司的 支持 为什么 ASA X3.4-1963 是 7…...
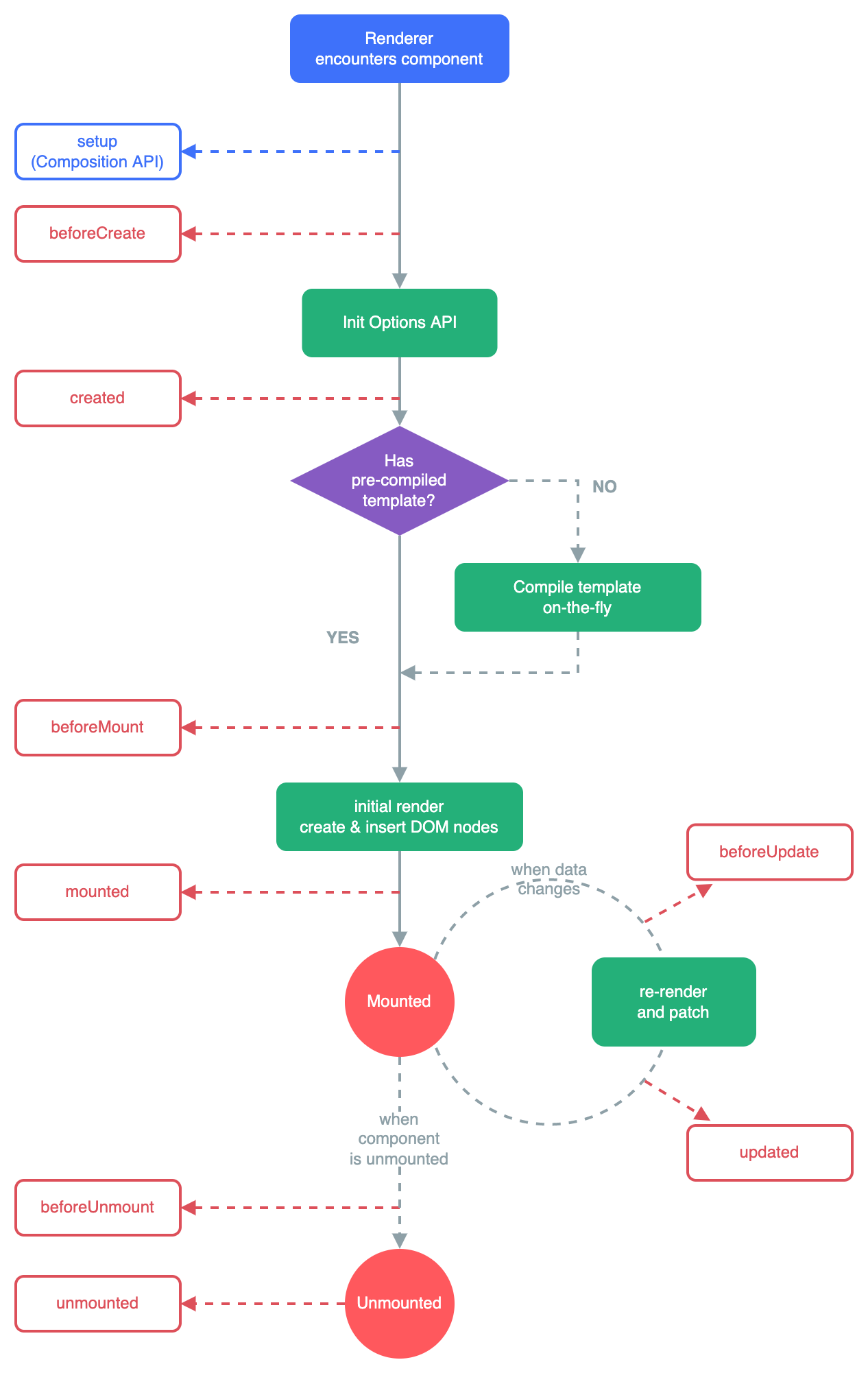
vue3.0 生命周期
目录前言:vue3.0生命周期图例1.beforeCreate2.created3.beforeMount/onBeforeMount4.mounted/onMounted5.beforeUpdate/onBeforeUpdate6.updated/onUpdated7.beforeUnmount/onBeforeUnmount8.unmounted/onUnmounted案例:总结前言: 每个Vue组…...

CGAL 数字类型
文章目录 一、简介二、内置数字类型三、CGAL中的数字类型参考资料一、简介 在CGAL汇总,数字类型必须满足特定的语法和语义要求,这样它们才能在CGAL代码中成功使用。一般来说,它们往往是代数结构概念的模型,如果它们对实数的子集模型,那么它们就也是RealEmbeddable模型。 二…...
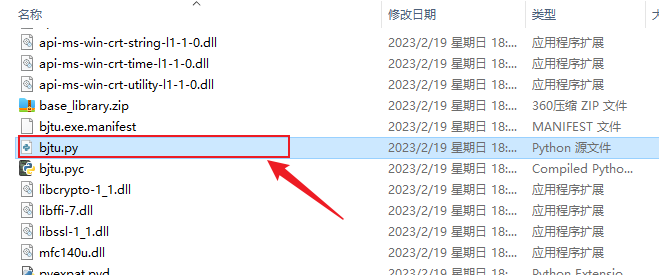
如何将Python打包后的exe还原成.py?
将python打包好的exe解压为py文件,步骤如下:下载pyinstxtractor.py文件下载地址:https://nchc.dl.sourceforge.net/project/pyinstallerextractor/dist/pyinstxtractor.py并将pyinstxtractor.py放到和exe相同的目录文件下打开命令控制台cd 进…...

CJSON简单介绍
json简介 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集,最新的定义可以参考ECMA-404_2nd_ed…...

算法训练营 day49 动态规划 爬楼梯 (进阶)零钱兑换 完全平方数
算法训练营 day49 动态规划 爬楼梯 (进阶)零钱兑换 完全平方数 爬楼梯 (进阶) 70. 爬楼梯 - 力扣(LeetCode) 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同…...

Vue:extends继承组件复用性
提到extends继承,最先想到的可能是ES6中的class、TS中的interface、面向对象编程语言中中的类和接口概念等等,但是我们今天的关注点在于:如何在Vue中使用extends继承特性。 目录 Vue:创建Vue实例的方式 构造函数方式࿱…...

ChatGPT 的一些思考
最近 ChatGPT3.5 在全世界范围内掀起了一次 AI 的潮流,ChatGPT1.0/ChatGPT2.0 当时也是比较火爆,但是那个当时感觉还是比较初级的应用,相当于是一个进阶版的微软小冰,给人的感觉是有一点智能,但不多。其实从早期版本开…...
GEE学习笔记 六十九:【GEE之Python版教程三】Python基础编程一
环境配置完成后,那么可以开始正式讲解编程知识。之前我在文章中也讲过,GEE的python版接口它是依赖python语言的。目前很多小伙伴是刚开始学习GEE编程,之前或者没有编程基础,或者是没有学习过python。为了照顾这批小伙伴࿰…...
大数据全系安装
内容版本号CentOS7.6.1810ZooKeeper3.4.6Hadoop2.9.1HBase1.2.0MySQL5.6.51HIVE2.3.7Sqoop1.4.6flume1.9.0kafka2.8.1scala2.12davinci3.0.1spark2.4.8flink1.13.5 1. 下载CentOS 7镜像 CentOS官网 2. 安装CentOS 7系统——采用虚拟机方式 2.1 新建虚拟机 2.2.1 [依次选择]-&…...

stable-diffusion-webui 安装使用
文章目录1.github 下载,按教程运行2.安装python 忘记勾选加入环境变量,自行加入(重启生效)3.环境变量添加后,清理tmp ,venv重新运行4.运行报错,无法升级pip,无法下载包,5…...

终极WebGL 3D图形开发指南:gl-matrix快速集成实战
终极WebGL 3D图形开发指南:gl-matrix快速集成实战 【免费下载链接】gl-matrix Javascript Matrix and Vector library for High Performance WebGL apps 项目地址: https://gitcode.com/gh_mirrors/gl/gl-matrix gl-matrix是一款专为高性能WebGL应用打造的Ja…...
)
SpringBoot+Vue实战:手把手教你搭建苍穹外卖后台管理系统(含Nginx配置避坑指南)
SpringBootVue全栈实战:从零构建外卖管理系统与Nginx部署精要 每次打开招聘网站,看到"要求有完整项目经验"的字样时,你是否也感到一阵心虚?作为全栈开发的学习者,我们往往陷入一个怪圈:学了很多碎…...

如何在2024年继续运行Flash游戏?终极CefFlashBrowser解决方案指南
如何在2024年继续运行Flash游戏?终极CefFlashBrowser解决方案指南 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 随着现代浏览器全面停止对Flash的支持,无数经典F…...

告别纯理论:用OAI 5G开源平台+USRP B210硬件,实测端到端5G SA数据业务
从零构建5G SA实验环境:OAI开源平台与USRP B210实战指南 当5G技术从实验室走向商业化应用时,许多开发者面临一个尴尬的现实:理论知识与实际操作之间存在巨大鸿沟。本文将带你跨越这道鸿沟,使用OAI开源平台和USRP B210软件定义无线…...

TikTok音乐提取全攻略:3分钟学会用DouK-Downloader分离音频
TikTok音乐提取全攻略:3分钟学会用DouK-Downloader分离音频 【免费下载链接】TikTokDownloader JoeanAmier/TikTokDownloader: 这是一个用于从TikTok下载视频和音频的工具。适合用于需要从TikTok下载视频和音频的场景。特点:易于使用,支持多种…...

探索时序并行门控网络TPGN:RNN的崭新继任者
一种RNN的新继任者—时序并行门控网络TPGN,用于时间序列预测。 作为RNN的新继任者。 PGN通过设计的历史信息提取(HIE)层直接从以前的时间步捕获信息,并利用门通机制选择并将其与当前时间步信息融合。 这将信息传播路径减少到0(1)&…...
)
QT实战:用QChartView快速打造动态折线图(附完整代码)
QT实战:用QChartView快速打造动态折线图(附完整代码) 在数据可视化领域,动态折线图因其直观展示数据变化趋势的能力,成为监控系统、金融分析、工业控制等场景的标配。QT框架提供的QChartView组件,让开发者能…...

3步终结C盘爆红:WindowsCleaner革新性磁盘清理工具高效释放空间
3步终结C盘爆红:WindowsCleaner革新性磁盘清理工具高效释放空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 问题剖析:你是否正遭遇这些…...

QAnything混合检索实战:ElasticSearch与向量搜索的协同优化
QAnything混合检索实战:ElasticSearch与向量搜索的协同优化 1. 为什么电商搜索总在“猜”用户心思? 你有没有遇到过这样的情况:在电商平台搜索“轻便透气运动鞋”,结果首页全是厚重的登山靴?或者搜“适合夏天穿的连衣…...

解决RK3588安装OpenCV时libjasper-dev缺失问题:Ubuntu20.04特殊源配置教程
RK3588平台OpenCV安装困境:深度解析libjasper-dev缺失问题与多维度解决方案 在RK3588平台上部署计算机视觉应用时,OpenCV作为核心依赖库的安装过程往往成为开发者的第一个"拦路虎"。特别是在Ubuntu 20.04环境下,当执行标准的sudo a…...