【深度学习-图像识别】使用fastai对Caltech101数据集进行图像多分类(50行以内的代码就可达到很高准确率)
文章目录
- 前言
- fastai介绍
- 数据集介绍
- 一、环境准备
- 二、数据集处理
- 1.数据目录结构
- 2.导入依赖项
- 2.读入数据
- 3.模型构建
- 3.1 寻找合适的学习率
- 3.2 模型调优
- 4.模型保存与应用
- 总结
- 人工智能-图像识别 系列文章目录
前言
fastai介绍
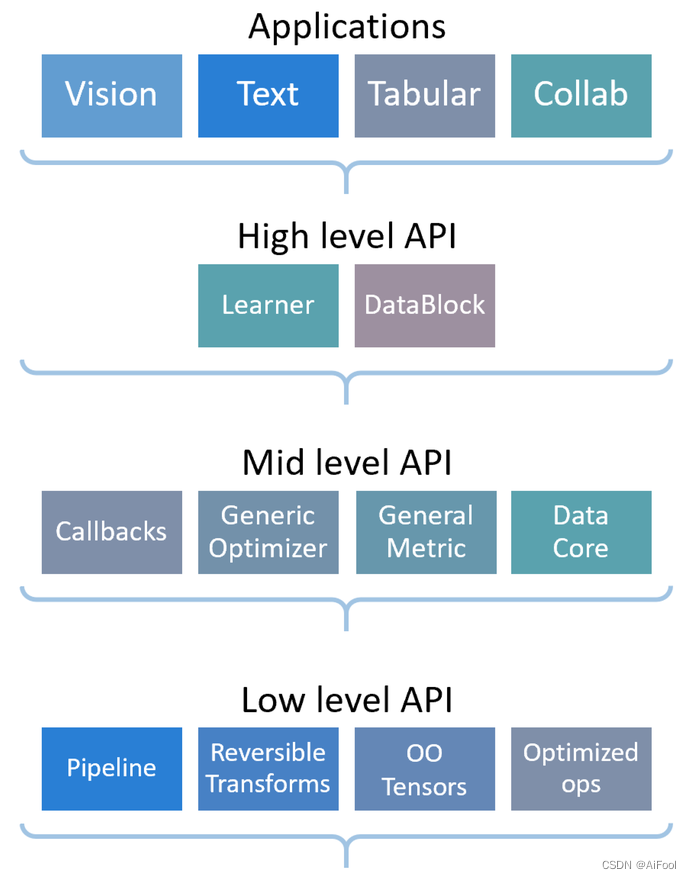
fastai 是一个深度学习库,它为从业人员提供了高级组件,可以快速、轻松地在标准深度学习领域提供最先进的结果,并为研究人员提供了低级组件,可以混合和匹配以构建新的方法。以解耦抽象的方式表达了许多深度学习和数据处理技术的通用底层模式。
fastai 有两个主要的设计目标:易于使用、快速高效,同时具有很强的可破解性和可配置性。它建立在提供可组合构件的低级应用程序接口的层次结构之上。这样,如果用户想重写部分高级应用程序接口或添加特定行为以满足自己的需求,就不必学习如何使用最底层的应用程序接口。
数据集介绍
下载链接
Caltech101国内下载地址
Caltech101
Caltech101数据集内部有 101 个类别的物体图片。每个类别约有 40 至 800 张图片。大多数类别约有 50 张图片。每张图片的大小大约为 300 x 200 像素。并且作者还标注了这些图片中每个物体的轮廓,这些都包含在 "Annotations.tar "中。还有一个 MATLAB 脚本 "show_annotations.m "可以查看注释。
Collected in September 2003 by Fei-Fei Li, Marco Andreetto, and
Marc’Aurelio Ranzato。
一、环境准备
这里展示使用GPU进行训练的环境搭建,只用CPU也可以进行训练,只是训练时间比较慢。
首先安装Anaconda,通过conda安装我们需要的包
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiaconda install -c nvidia fastai anaconda
详情可见第一篇文章。
二、数据集处理
1.数据目录结构
├───data_iamge
│ ├───101_ObjectCategories
│ │ ├───accordion
│ │ ├───airplanes
│ │ ├───anchor
│ │ ├───ant
│ │ ├───BACKGROUND_Google
│ │ ├───barrel
│ │ ├───bass
│ │ ├───beaver
│ │ ├───binocular
│ │ ├───bonsai
│ │ ├───brain
│ │ ├───brontosaurus
...
2.导入依赖项
from fastai import *
from fastai.vision.all import *
from fastai.metrics import error_rateimport os
#from keras.utils import plot_model
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
查看环境以及版本信息,cuda.is_available()判断是否可以用GPU。
print(torch.cuda.is_available())
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
True
2.0.1
11.8
8700
'''SEED Everything'''
def seed_everything(SEED=42):random.seed(SEED)np.random.seed(SEED)torch.manual_seed(SEED)torch.cuda.manual_seed(SEED)torch.cuda.manual_seed_all(SEED)torch.backends.cudnn.benchmark = True # keep True if all the input have same size.
SEED=42
seed_everything(SEED=SEED)
'''SEED Everything'''
2.读入数据
代码如下(示例):
path='./data_image/101_ObjectCategories/'
image_rsize=224
item_tfms = [Resize((image_rsize,image_rsize))]
data = ImageDataLoaders.from_folder(path, train = '.', valid_pct=0.2,size=image_rsize,item_tfms=item_tfms)
data.show_batch(figsize=(7,6))

3.模型构建
这里使用预训练模型resnet101,这是一个非常优秀的残差网络模型。
这些残差网络更容易优化,并且可以从显着增加的深度中获得准确性。
这些残差网络的集合在 ImageNet 测试集上实现了 3.57% 的误差。该结果在ILSVRC 1分类任务中获得第一名。
learn = cnn_learner(data, models.resnet101, model_dir='./model', path = Path("."))
3.1 寻找合适的学习率
learn.lr_find()
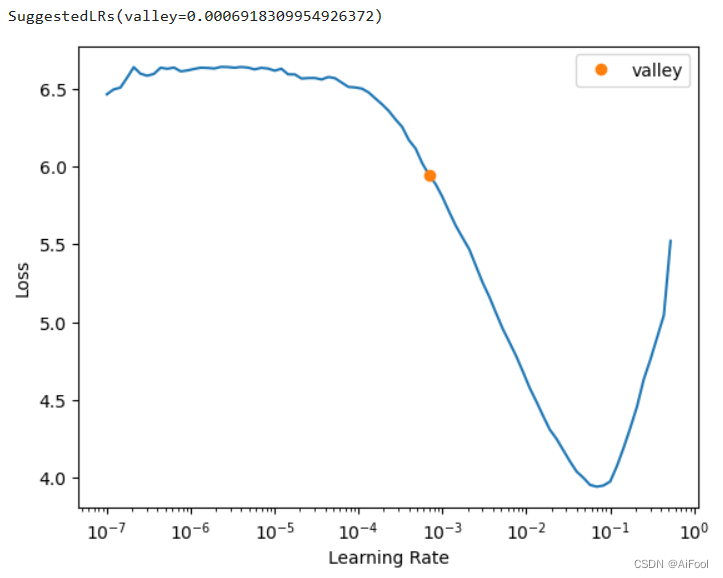
接下来使用fit_one_cycle方法用更小的学习率进一步训练。fit_one_cycle使用的是一种周期性学习率,从较小的学习率开始学习,缓慢提高至较高的学习率,然后再慢慢下降,周而复始,每个周期的长度略微缩短,在训练的最后部分,允许学习率比之前的最小值降得更低。这不仅可以加速训练,还有助于防止模型落入损失平面的陡峭区域,使模型更倾向于寻找更平坦的极小值,从而缓解过拟合现象。
lr1 = 1e-3
lr2 = 1e-1
epoch train_loss valid_loss time
0 1.417713 1.648756 00:45
1 3.097069 9.964518 00:43
2 5.385355 5.347832 00:44
3 4.194504 12.162844 00:44
4 2.985504 3.486863 00:43
5 2.152388 22.297184 00:43
6 1.295905 3.554162 00:43
7 0.630879 9.193820 00:43
8 0.361619 49.334236 00:43
9 0.255115 9.832499 00:43
3.2 模型调优
unfreeze
在fastai课程中使用的是预训练模型,模型卷积层的权重已经提前在ImageNet
上训练好了,在使用的时候一般只需要在预训练模型最后一层卷积层后添加自定义的全连接层即可。卷积层默认是freeze的,即在训练阶段进行反向传播时不会更新卷积层的权重,只会更新全连接层的权重。在训练几个epoch之后,全连接层的权重已经训练的差不多了,但accuracy还没有达到你的要求,这时你可以调用unfreeze然后再进行训练,这样在进行反向传播时便会更新卷积层的权重(一般不会对卷积层权重进行较大的更新,只会进行一点点的微调,越靠前的卷积层调整的幅度越小,所以有了differential
learning rate 这一想法)
precompute
当precompute=True时,会提前计算出每一个训练样本(不包括增强样本)在预训练模型最后一层卷积层的activation,
并将其缓存下来,之后在训练阶段进行前向传播的时候,直接将precompute 的activation 作为后面全连接层(FC
Layer)的输入,这样便省去前面卷积层进行前向传播的计算量,减少训练所需时间(这种优势在epoch比较大的时候能够显著0提高训练速度)。当precompute=False时,则不会提前计算训练样本的activation,每一个epoch都需要重新将训练样本+增强样本(前提是进行了增强操作)进行卷积层的前向传播,然后进行反向传播更新对应的权重。
learn.unfreeze()
learn.show_results()

从展示的部分训练结果可以看出,只有一张图被预测错误了,其他的都是正确的。
4.模型保存与应用
最后我们可以将模型保存下来,并且对验证集的图片的类别进行预测。
learn.export(Path("./model/export.pkl"))
from PIL import Image
img = Image.open(path+'ant/image_0001.jpg')
image_rsize=224
# Resize the image to 224x224
img_resized = img.resize((image_rsize,image_rsize))
pred, pred_idx, probs = learn.predict(img_resized)
im_t = cast(array(img_resized), TensorImage)
# Print the predicted label and probability
print(f"Predicted label: {pred}, probability: {probs[pred_idx]:.4f}")
img

总结
epoch train_loss valid_loss time
0 1.030772 979.477417 00:52
1 1.074642 86.289436 00:52
2 0.553576 0.457210 00:52
3 0.302997 0.546438 00:52
4 0.176070 0.596845 00:52
我们借助fastai训练了resnet101模型,对 101 个类别的图像数据集进行了分类。
使用基于pytorch的fastai库,使用resnet模型和有101个类别的Caltech101图像数据集,训练了一个高准确率的多分类的深度学习模型,能够对101个类别的图像大数据集进行准确的图像类别识别。
使用简洁高效的代码,借助GPU提升训练速度(也可以使用CPU训练,本项目会自动识别硬件),首先数据集进行预处理,然后对模型进行训练,并将模型保存为pkl格式,最后对测试集的图像的类别进行预测。
可见,使用fastai进行图像多分类是非常简便的,所使用的代码行数非常少却能达到很高的准确率,而且借助GPU训练速度非常快。
这里将全部的代码和图片数据集打包起来了,方便大家复现。
开箱即用,欢迎下载
使用fastai对Caltech101数据集进行图像多分类
人工智能-图像识别 系列文章目录
- 环境搭建: pytorch以及fastai安装,配置GPU训练环境 待更新。。。
- 使用fastai对Caltech101数据集进行图像多分类(50行以内的代码就可达到很高准确率)
相关文章:
【深度学习-图像识别】使用fastai对Caltech101数据集进行图像多分类(50行以内的代码就可达到很高准确率)
文章目录 前言fastai介绍数据集介绍 一、环境准备二、数据集处理1.数据目录结构2.导入依赖项2.读入数据3.模型构建3.1 寻找合适的学习率3.2 模型调优 4.模型保存与应用 总结人工智能-图像识别 系列文章目录 前言 fastai介绍 fastai 是一个深度学习库,它为从业人员…...
Debian10: 安装nut服务器(UPS)
UPS说明: UPS的作用就不必讲了,我选择是SANTAKTGBOX-850,规格为 850VA/510W,可以满足所需,关键是Debian10自带了驱动可以支持,免去安装驱动,将UPS通过USB线连接服务器即可,如下图所示…...

神经网络基础-神经网络补充概念-47-动量梯度下降法
概念 动量梯度下降法(Momentum Gradient Descent)是一种优化算法,用于加速梯度下降的收敛速度,特别是在存在高曲率、平原或局部最小值的情况下。动量法引入了一个称为“动量”(momentum)的概念,…...
 补充知识、线程池浅谈、数量谈、总结)
C++11并发与多线程笔记(13) 补充知识、线程池浅谈、数量谈、总结
C11并发与多线程笔记(13) 补充知识、线程池浅谈、数量谈、总结 1、补充一些知识点1.1 虚假唤醒:1.2 atomic 2、浅谈线程池:3、线程创建数量谈: 1、补充一些知识点 1.1 虚假唤醒: notify_one或者notify_al…...
python高级基础
文章目录 python高级基础闭包修饰器单例模式跟工厂模式工厂模式单例模式 多线程多进程创建websocket服务端手写客户端 python高级基础 闭包 简单解释一下闭包就是可以在内部访问外部函数的变量,因为如果声明全局变量,那在后面就有可能会修改 在闭包中的…...
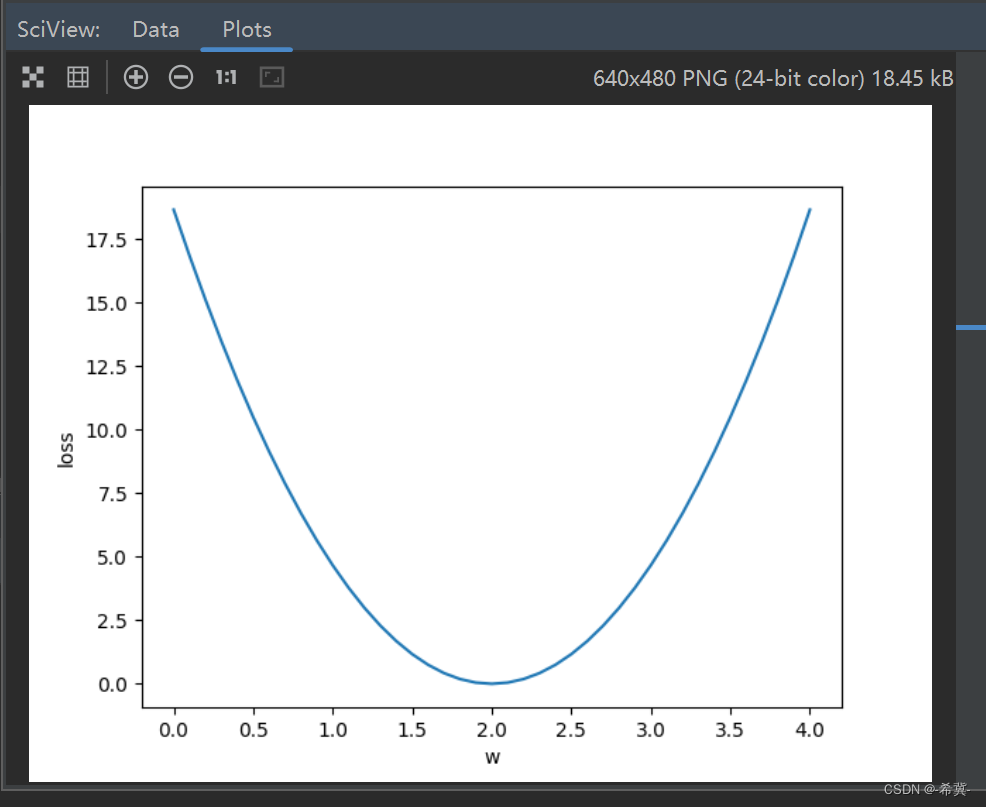
使用线性回归模型优化权重:探索数据拟合的基础
文章目录 前言一、示例代码二、示例代码解读1.线性回归模型2.MSE损失函数3.优化过程4.结果解读 总结 前言 在机器学习和数据科学中,线性回归是一种常见而重要的方法。本文将以一个简单的代码示例为基础,介绍线性回归的基本原理和应用。将使用Python和Nu…...

亿级短视频,如何架构?
说在前面 在尼恩的(50)读者社群中,经常指导大家面试架构,拿高端offer。 前几天,指导一个年薪100W小伙伴,拿到字节面试邀请。 遇到一个 非常、非常高频的一个面试题,但是很不好回答࿰…...
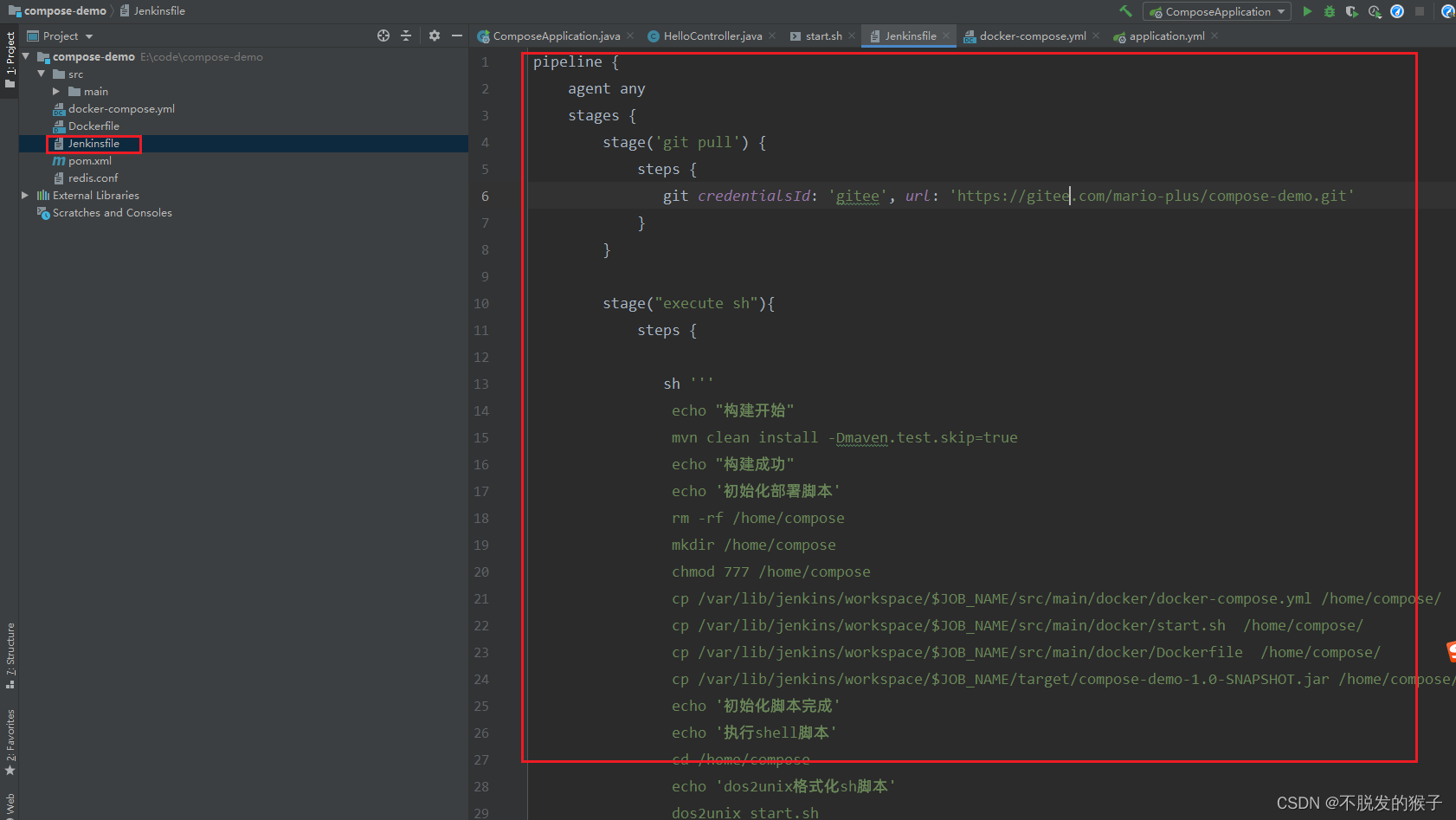
jenkins pipeline方式一键部署github项目
上篇:jenkins一键部署github项目 该篇使用jenkins pipeline-script一键部署,且介绍pipeline-scm jenkins环境配置 前言:按照上篇创建pipeline任务,结果报mvn,jdk环境不存在,就很疑惑,然后配置全…...
Vue 项目搭建
环境配置 1. 安装node.js 官网:nodejs(推荐 v10 以上) 官网:npm 是什么? 由于vue的安装与创建依赖node.js(JavaScript的运行环境)里的npm(包管理和分发工具)ÿ…...
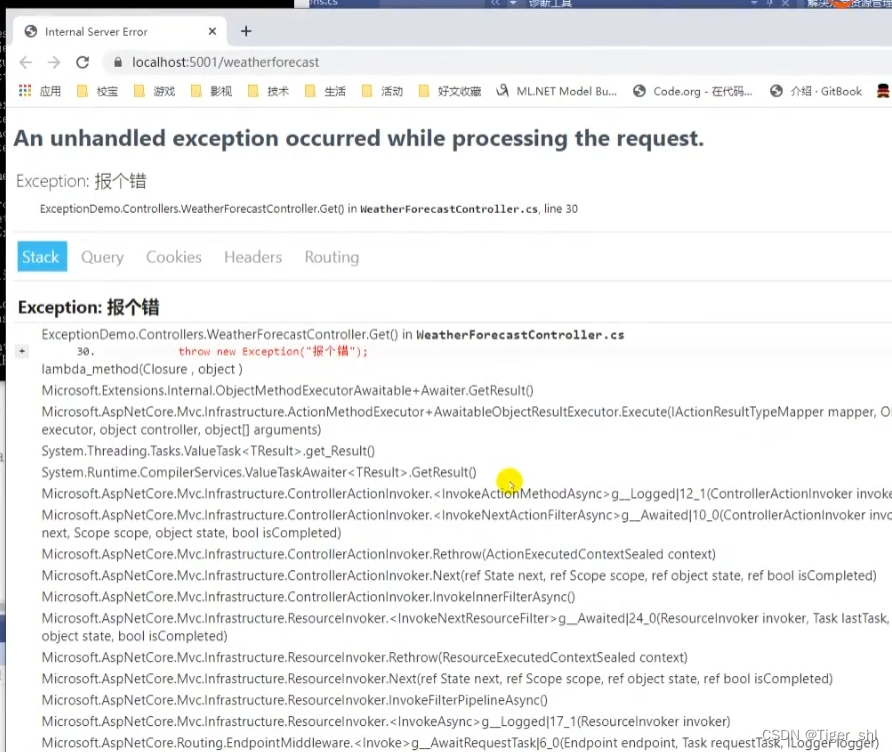
【NetCore】09-中间件
文章目录 中间件:掌控请求处理过程的关键1. 中间件1.1 中间件工作原理1.2 中间件核心对象 2.异常处理中间件:区分真异常和逻辑异常2.1 处理异常的方式2.1.1 日常错误处理--定义错误页的方法2.1.2 使用代理方法处理异常2.1.3 异常过滤器 IExceptionFilter2.1.4 特性过…...
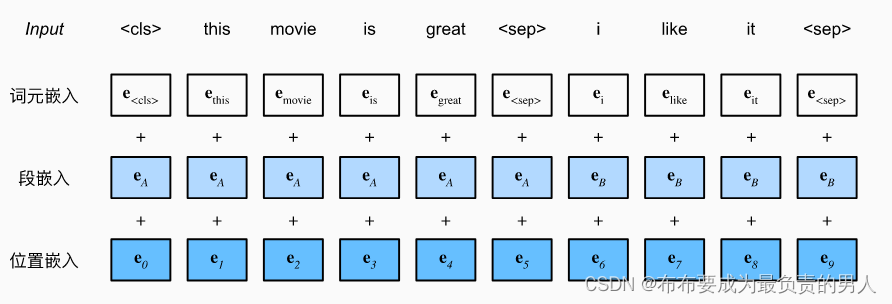
机器学习深度学习——BERT(来自transformer的双向编码器表示)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——transformer(机器翻译的再实现) 📚订阅专栏:机器学习&am…...
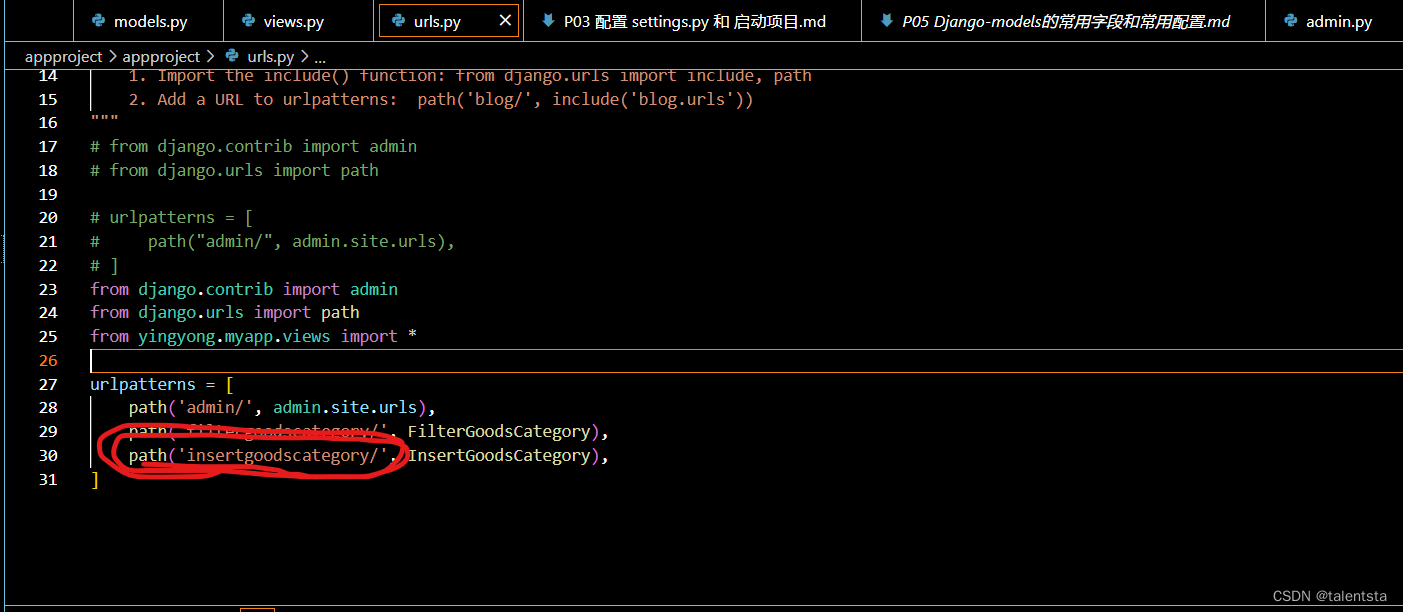
Datawhale Django后端开发入门 Vscode TASK02 Admin管理员、外键的使用
一.Admin管理员的使用 1、启动django服务 使用创建管理员之前,一定要先启动django服务,虽然TASK01和TASK02是分开的,但是进行第二个流程的时候记得先启动django服务,注意此时是在你的项目文件夹下启动的,时刻注意要执…...
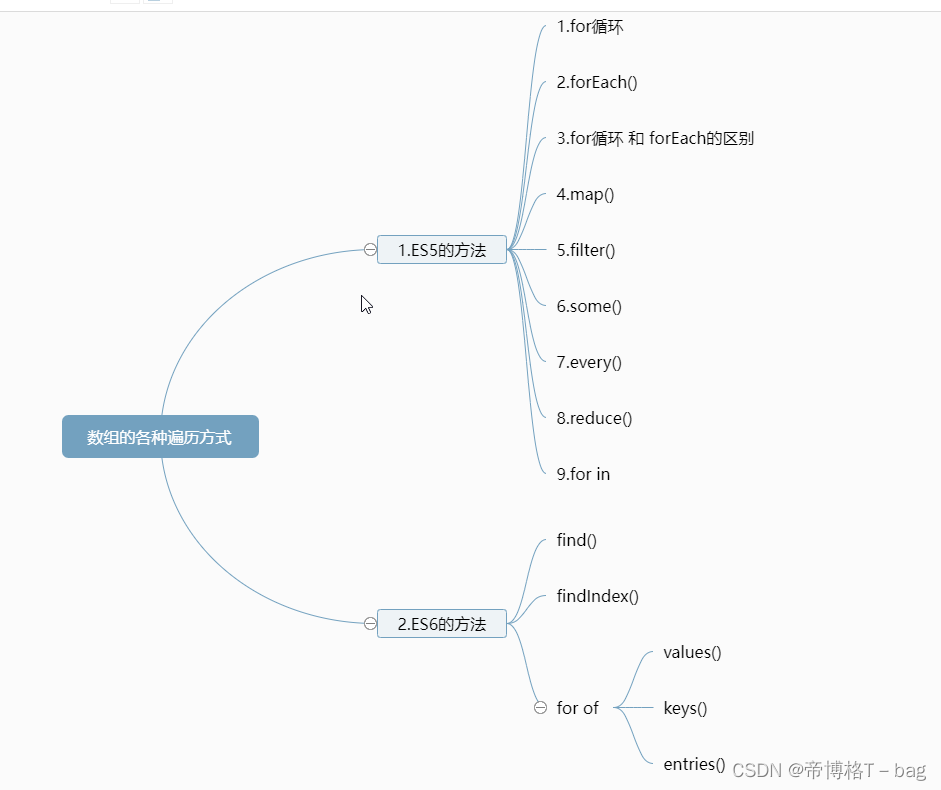
【ES5和ES6】数组遍历的各种方法集合
一、ES5的方法 1.for循环 let arr [1, 2, 3] for (let i 0; i < arr.length; i) {console.log(arr[i]) } // 1 // 2 // 32.forEach() 特点: 没有返回值,只是针对每个元素调用func三个参数:item, index, arr ;当前项&#…...

学科在线教育元宇宙VR虚拟仿真平台落实更高质量的交互学习
为推动教育数字化,建设全民终身学习的学习型社会、学习型大国,元宇宙企业深圳华锐视点深度融合VR虚拟现实、数字孪生、云计算和三维建模等技术,搭建教育元宇宙平台,为学生提供更加沉浸式的学习体验,提高学习效果和兴趣…...
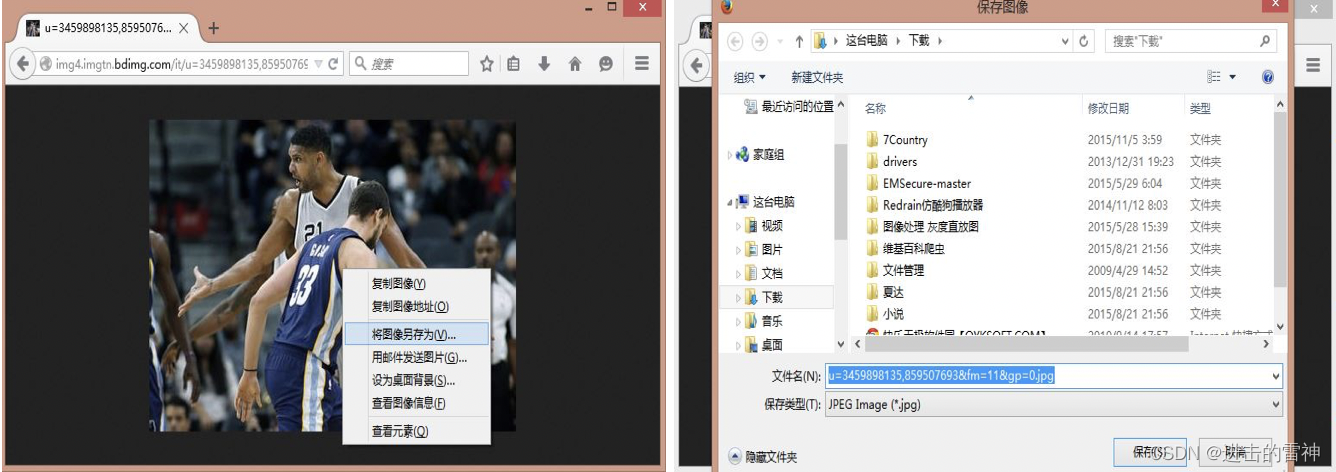
[python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨。同时,作者将进一步帮你巩固selenium自动化操作和urllib…...

vue项目预览pdf功能(解决动态文字无法显示的问题)
最近,因为公司项目需要预览pdf的功能,开始的时候找了市面上的一些pdf插件,都能用,但是,后面因为pdf变成了需要根据内容进行变化的,然后,就出现了需要动态生成的文字不显示了。换了好多好多的插件…...

vue3 样式穿透:deep不生效
初学vue3,今天需要修改el-input组件的属性(去掉border和文字居右) 网上搜了一下,大致都是采用:deep 样式穿透来修改el-input的属性 <div class"input-container"><el-input placeholder"请输入111&qu…...
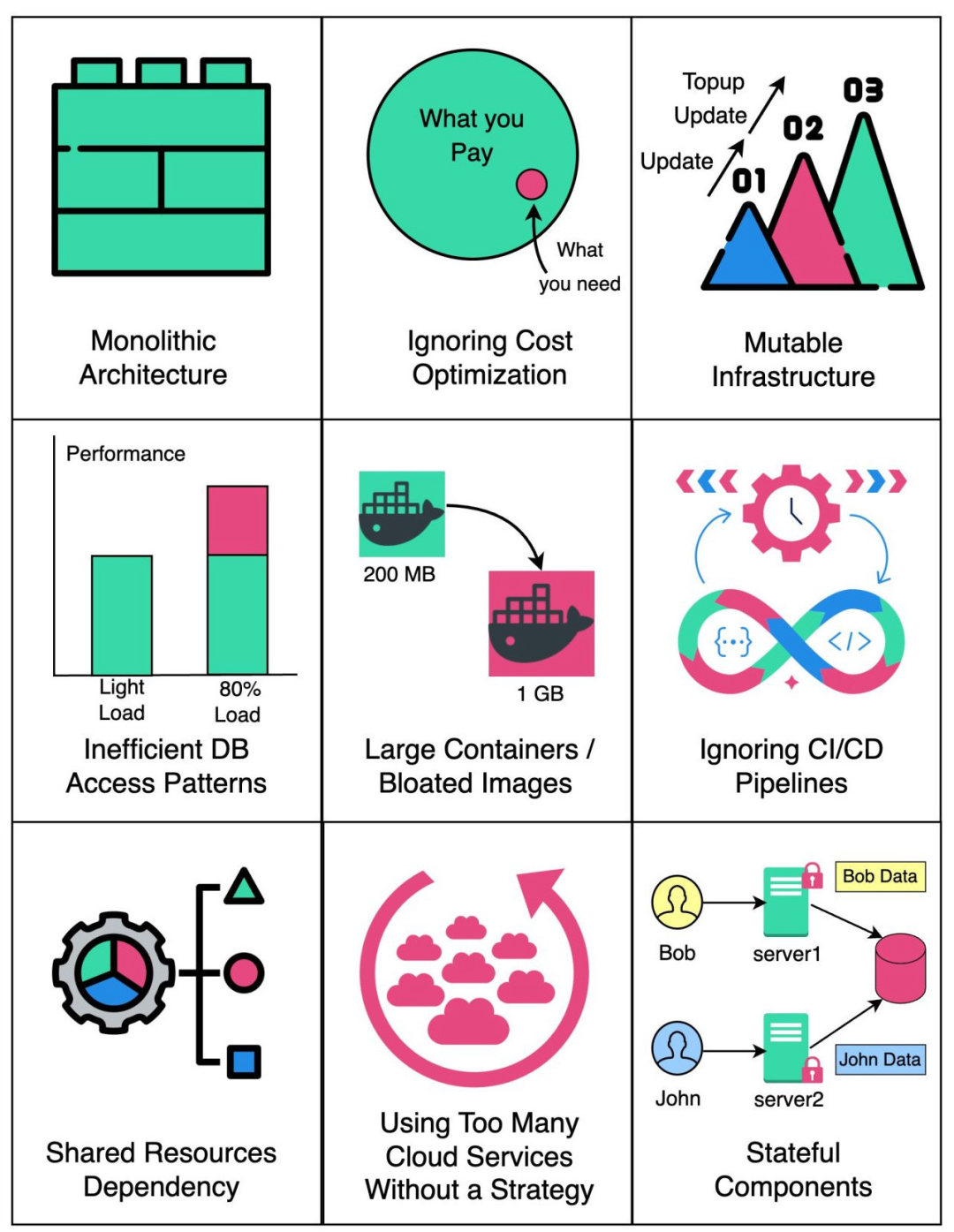
云原生反模式
通过了解这些反模式并遵循云原生最佳实践,您可以设计、构建和运营更加强大、可扩展和成本效益高的云原生应用程序。 1.单体架构:在云上运行一个大而紧密耦合的应用程序,妨碍了可扩展性和敏捷性。2.忽略成本优化:云服务可能昂贵&am…...
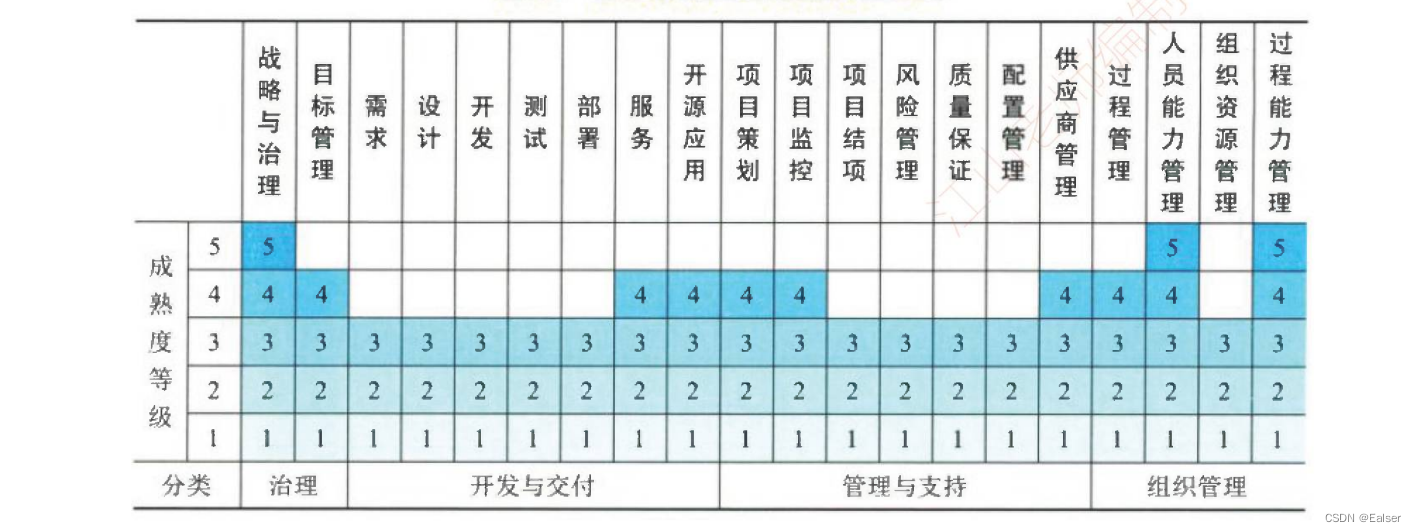
【2023年11月第四版教材】《第5章-信息系统工程(合集篇)》
《第5章-信息系统工程(合集篇)》 章节说明1 软件工程1.1 架构设计1.2 需求分析1.3 软件设计1.4 软件实现[补充第三版教材内容] 1.5 部署交付 2 数据工程2.1 数据建模2.2 数据标准化2.3 数据运维2.4 数据开发利用2.5 数据库安全 3 …...

【qiankun】微前端在项目中的具体使用
1、安装qiankun npm install qiankun --save2、主应用中注册和配置qiankun 在主应用的入口文件main.ts中,引入qiankun的注册方法: import { registerMicroApps, start } from qiankun;创建一个数组,用于配置子应用的相关信息。每个子应用都…...

专业解析:Windows APK安装器的架构设计与跨平台应用部署实践
专业解析:Windows APK安装器的架构设计与跨平台应用部署实践 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在移动应用生态日益多元化的今天,W…...

如何在3分钟内掌握PowerPoint专业公式编辑:LaTeX-PPT终极指南
如何在3分钟内掌握PowerPoint专业公式编辑:LaTeX-PPT终极指南 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint中编辑复杂的数学公式而头疼吗?LaTeX-PPT这款开源插件…...

SuperPNG:解决Photoshop PNG导出痛点的高效解决方案
SuperPNG:解决Photoshop PNG导出痛点的高效解决方案 【免费下载链接】SuperPNG SuperPNG plug-in for Photoshop 项目地址: https://gitcode.com/gh_mirrors/su/SuperPNG 你是否曾为Photoshop导出的PNG文件体积过大而烦恼?是否在寻找既能保持图像…...

A*搜索算法原理与工业级优化实践
1. A*搜索算法核心原理与工程实现A搜索算法作为路径规划领域的经典算法,其核心优势在于将Dijkstra算法的完备性与贪心算法的高效性相结合。在实际工程项目中,我经常使用A来解决各类移动机器人的导航问题,它的表现始终稳定可靠。1.1 算法核心三…...

NoSleep:3种工作模式,解决Windows自动休眠的9大场景难题
NoSleep:3种工作模式,解决Windows自动休眠的9大场景难题 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否曾因Windows自动休眠而中断重要的远程演…...

我是怎么用 AI 把自己的知识“榨”出来的:Skill的再实践
在某些 AI 群里潜水久了,我养成了一个坏毛病。 每次看到有人发问题,我都会在心里默默评价:这问题问得太幼稚了、这个思路走歪了、这个工具根本不该这么用、怎么会问出这种问题…… 但如果有人反过来问我:“那你说,正确…...

PySpark 安装全过程总结
而是典型的:Windows 多开发环境下的大数据环境冲突问题。整个过程里,你实际上同时涉及了:Java Python Conda PySpark PyCharm Windows PATH Socket通信而:PySpark 本质上又是:Python JVM(Java) 的混合体系。所以&…...

Lobe Icons:现代AI与工具类应用的SVG图标系统设计与工程实践
1. 项目概述:一套为现代数字界面而生的图标系统如果你和我一样,常年混迹在各类开源项目、独立开发社区,或者自己动手搭建过一些Web应用、设计系统,那你一定对“找图标”这件事深有体会。从Material Design到Font Awesomeÿ…...

用代码管理技能:构建结构化个人技能库的工程实践
1. 项目概述与核心价值最近在整理自己的技能栈时,发现了一个挺有意思的现象:很多开发者,包括我自己在内,对于“技能”的管理往往停留在简历上的一个列表,或者脑子里一个模糊的概念。当需要快速启动一个新项目、评估团队…...

程序员的职业规划:到底是走技术路线还是管理路线
程序员职业规划:技术与管理的岔路口在软件测试行业深耕多年,你或许早已习惯在代码的迷宫中寻找漏洞,在数据的海洋里甄别异常。但当职业生涯的列车行至中途,一个现实的问题总会悄然浮现:是继续在技术的山峰上攀登&#…...