【Redis】Redis中的布隆过滤器
【Redis】Redis中的布隆过滤器
前言
在实际开发中,会遇到很多要判断一个元素是否在某个集合中的业务场景,类似于垃圾邮件的识别,恶意IP地址的访问,缓存穿透等情况。类似于缓存穿透这种情况,有许多的解决方法,如:Redis存储Null值等,而对于垃圾邮件的识别,恶意IP地址的访问,我们也可以直接用 HashMap 去存储恶意IP地址以及垃圾邮件,然后每次访问时去检索一下对应集合中是否有相同数据。这种思路对于数据量小的项目来说是没有问题的,但是对于大数据量的项目,如:垃圾邮件出现有几十万,恶意IP地址出现有上百万,那么这些大量的数据就会占据大量的空间,这个时候就可以考虑一下布隆过滤器了。
布隆过滤器是什么?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。

可以把布隆过滤器理解为一个不怎么精确的 set 结构,当你使用它的 contains方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置得合理,它的精确度也可以控制得相对足够精确,只会有小小的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说某个值不存在时那就肯定不存在。打个比方,当它说不认识你时,肯定就是真的不认识;而当它说认识你时,却有可能根本没见过你,只是因为你的脸跟它认识的某人的脸比较相似(某些熟脸的系数组合),所以误判以前认识你。
一句话总结:由一个初始值为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。
使用bit数组的目的就是减少内存的占用,数组不保存数据信息,只是在内存中存储一个是否存在的表示0或1
布隆过滤器的优缺点:
优点:
高效插入和查询,内存占用空间少
缺点:
- 存在误判,不能精确过滤
- 不能删除元素
布隆过滤器的使用场景
黑白名单校验、识别垃圾邮件
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于Redis前面挡着一个布隆过滤器。当有新的请求时,先到布隆过滤器中查询是否存在:如果布隆过滤器中不存在该条数据则直接返回;如果布隆过滤器中已存在,才去查询缓存Redis,如果Redis里没查询到则再查询MySQL数据库
布隆过滤器的原理
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不-样的无偏 hash函数,如下图中的F、G、H就是这样的hash函数。所谓无偏就是能够把元素的 hash 值算得比较均匀,让元素被 hash映射到位数组中的位置比较随机。

向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash,算得一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1,就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟add 一样,也会把 hash 的几个位置都算出来,**看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果这几个位置都是 1,并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其他的 key 存在所致。**如果这个位数组比较稀疏,判断正确的概率就会很大,如果这个位数组比较拥挤,判断正确的概率就会降低。具体的概率计算公式比较复杂,感兴趣可以阅读相关的更深入研究的资料,不过非常烧脑,不建议读者细看。
参考博客:Redis系列–布隆过滤器(Bloom Filter)_redistemplate 布隆过滤器_幼儿园里的山大王的博客-CSDN博客
基于Redisson的布隆过滤器使用实例
1.引入Redisson依赖
<!--原生-->
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.13.4</version>
</dependency><!--或者另一种Spring集成starter-->
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.13.6</version>
</dependency>
2.配置Redisson
@Configuration
public class RedissionConfig {@Value("${spring.redis.host}")private String redisHost;@Value("${spring.redis.password}")private String password;private int port = 6379;@Beanpublic RedissonClient getRedisson() {Config config = new Config();config.useSingleServer().setAddress("redis://" + redisHost + ":" + port).setPassword(password);config.setCodec(new JsonJacksonCodec());return Redisson.create(config);}
}
3.配置布隆过滤器
@Configuration
public class BloomFilterConfig {@Autowiredprivate RedissonClient redissonClient;/*** 创建订单号布隆过滤器* @return*/@Beanpublic RBloomFilter<Long> orderBloomFilter() {//过滤器名称String filterName = "orderBloomFilter";// 预期插入数量long expectedInsertions = 10000L;// 错误比率double falseProbability = 0.01;RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(filterName);bloomFilter.tryInit(expectedInsertions, falseProbability);return bloomFilter;}
}
4.创建订单表
CREATE TABLE `tb_order` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '订单Id',`order_desc` varchar(50) NOT NULL COMMENT '订单描述',`user_id` bigint NOT NULL COMMENT '用户Id',`product_id` bigint NOT NULL COMMENT '商品Id',`product_num` int NOT NULL COMMENT '商品数量',`total_account` decimal(10,2) NOT NULL COMMENT '订单金额',`create_time` datetime NOT NULL COMMENT '创建时间',PRIMARY KEY (`id`),KEY `ik_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=51 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
5.编写业务处理代码
@Slf4j
@Service
public class OrderServiceImpl implements OrderService {@Resourceprivate RBloomFilter<Long> orderBloomFilter;@Resourceprivate TbOrderMapper tbOrderMapper;@Resourceprivate RedisTemplate<String,Object> redisTemplate;@Overridepublic void createOrder(TbOrder tbOrder) {//1、创建订单tbOrderMapper.insert(tbOrder);//2、订单id保存到布隆过滤器log.info("布隆过滤器中添加订单号:{}",tbOrder.getId());orderBloomFilter.add(tbOrder.getId());}@Overridepublic TbOrder get(Long orderId) {TbOrder tbOrder = null;//1、根据布隆过滤器判断订单号是否存在if(orderBloomFilter.contains(orderId)){log.info("布隆过滤器判断订单号{}存在",orderId);String key = "order:"+orderId;//2、先查询缓存Object object = redisTemplate.opsForValue().get(key);if(object != null){log.info("命中缓存");tbOrder = (TbOrder)object;}else{//3、缓存不存在则查询数据库log.info("未命中缓存,查询数据库");tbOrder = tbOrderMapper.selectById(orderId);redisTemplate.opsForValue().set(key,tbOrder);}}else{log.info("判定订单号{}不存在,不进行查询",orderId);}return tbOrder;}
}
6.单元测试
@Test
public void testCreateOrder() {for (int i = 0; i < 50; i++) {TbOrder tbOrder = new TbOrder();tbOrder.setOrderDesc("测试订单"+(i+1));tbOrder.setUserId(1958L);tbOrder.setProductId(102589L);tbOrder.setProductNum(5);tbOrder.setTotalAccount(new BigDecimal("300"));tbOrder.setCreateTime(new Date());orderService.createOrder(tbOrder);}}
@Test
public void testGetOrder() {TbOrder tbOrder = orderService.get(25L);log.info("查询结果:{}", tbOrder.toString());
}
总结
布隆过滤器的原理其实非常简单,就是bitmap + 多重hash,主要优势就是利用非常小的空间就可以实现在大规模数据下快速判断某一对象是否存在,缺点是存在误判的可能,但不会漏判,也就是存在的对象一定会判断为存在,而不存在的对象会有较低的概率为误判为存在,且不支持对象的删除,因为会增加误判的概率。最典型的使用是解决缓存穿透的问题。
相关文章:
【Redis】Redis中的布隆过滤器
【Redis】Redis中的布隆过滤器 前言 在实际开发中,会遇到很多要判断一个元素是否在某个集合中的业务场景,类似于垃圾邮件的识别,恶意IP地址的访问,缓存穿透等情况。类似于缓存穿透这种情况,有许多的解决方法…...

接口测试 —— Jmeter 参数加密实现
Jmeter有两种方法可以实现算法加密 1、使用__digest自带函数 参数说明: Digest algorithm:算法摘要,可输入值:MD2、MD5、SHA-1、SHA-224、SHA-256、SHA-384、SHA-512 String to be hashed:要加密的数据 Salt to be…...

Linux c语言字节序
文章目录 一、简介二、大小端判断2.1 联合体2.2 指针2.3 网络字节序 一、简介 字节序(Byte Order)指的是在存储和表示多字节数据类型(如整数和浮点数)时,字节的排列顺序。常见的字节序有大端字节序(Big En…...

批量将excel中第5列中内容将人名和电话号码进行分列
使用Python可以使用openpyxl库来实现批量将Excel中第5列的内容分列为人名和电话号码的操作。下面是示例代码: import openpyxl def split_names_and_phone_numbers(file_path, sheet_name): # 加载Excel文件 workbook openpyxl.load_workbook(file_path) …...

WPF DataGrid columns表头根据数据集动态动态生成Demo
思路是这样的,数组集合装表头的信息,遍历这个集合,遍历过程中处理一下数据,然后就把每表头信息添加到dataGrid2.Columns.Add(templateColumn); 1,页面Xaml代码: <DataGrid x:Name"dataGrid" …...
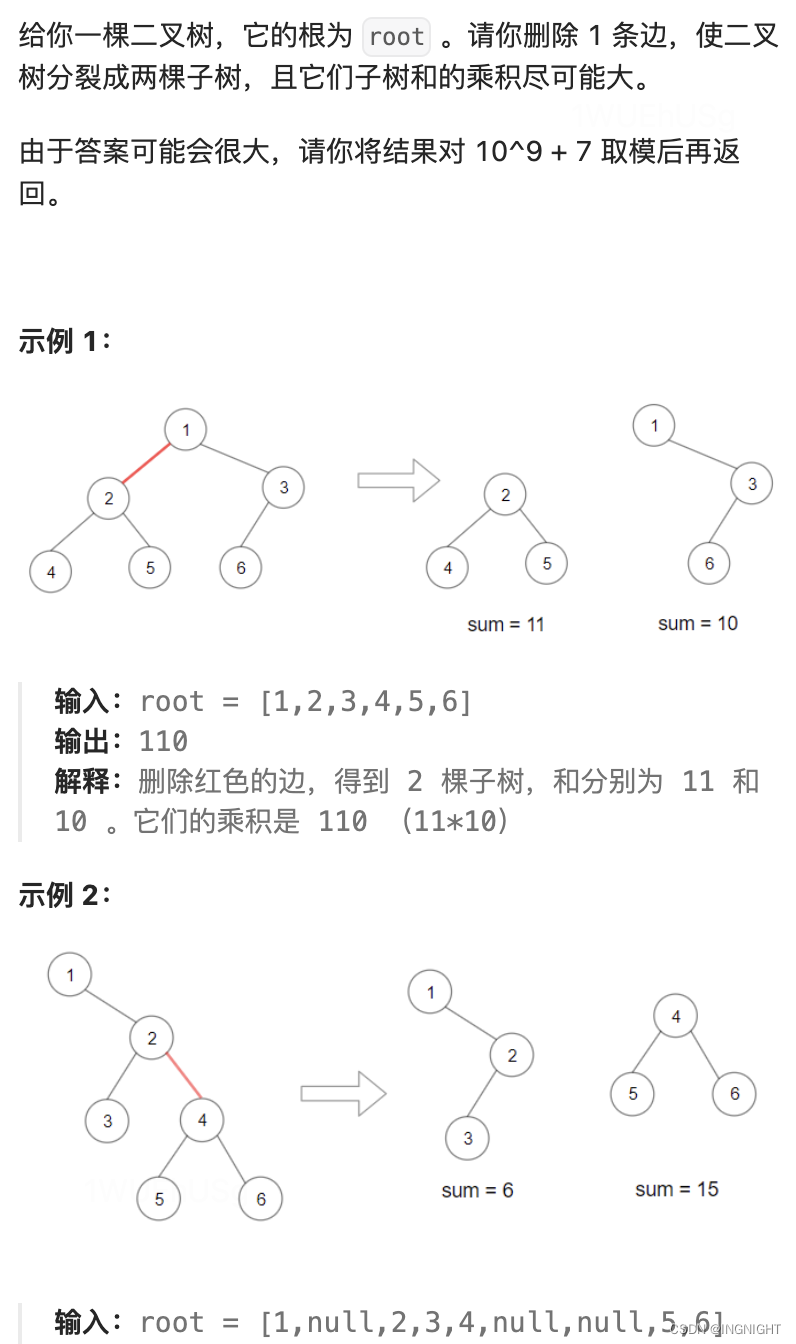
1339. 分裂二叉树的最大乘积
链接: 1339. 分裂二叉树的最大乘积 题解: /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* …...

【C++】Stack和Queue
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析3 目录 👉🏻Stack Constructor👉🏻Stack …...

Maven之tomcat7-maven-plugin 版本低的问题
tomcat7-maven-plugin 版本『低』的问题 相较于当前最新版的 tomcat 10 而言,tomcat7-maven-plugin 确实看起来很显老旧。但是,这个问题并不是问题,至少不是大问题。 原因 1:tomcat7-maven-plugin 仅用于我们(程序员&…...
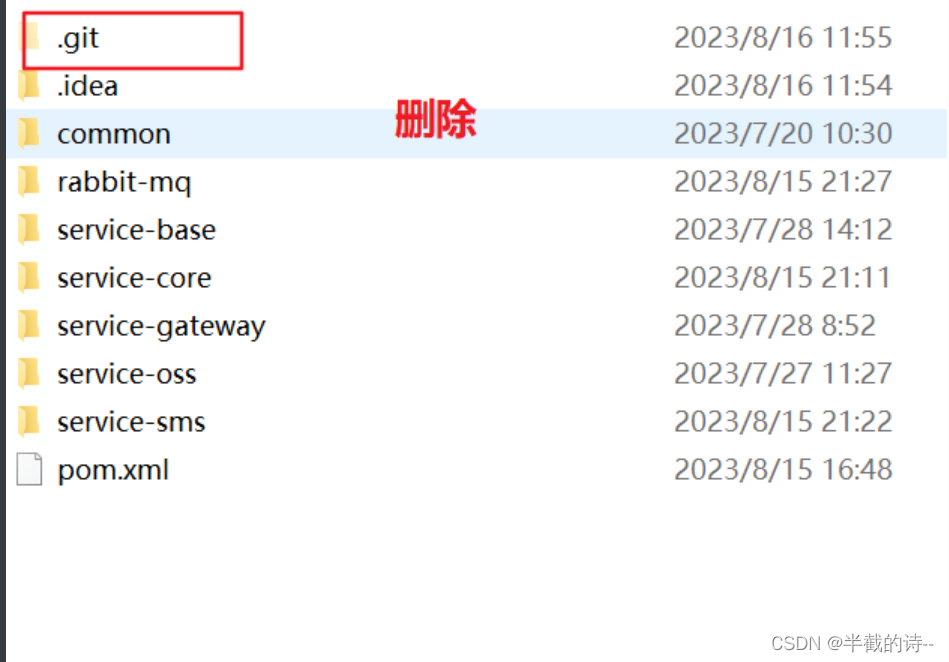
在项目中如何解除idea和Git的绑定
在项目中如何解除idea和Git的绑定 1、点击File--->Settings...(CtrlAltS)--->Version Control--->Directory Mappings--->点击取消Git的注册根路径: 2、回到idea界面就没有Git了: 3、给这个项目初始化 这样就可以重新绑定远程仓库了&#x…...
AGI 在网易云信的技术提效和业务创新
We believe our research will eventually lead to artificial general intelligence, a system that can solve human-level problems. Building safe and beneficial AGI is our mission. ---- OpenAI 通用人工智能 AGI 作为 AI 的终极形态,是 AI 行业内追求的演…...

线性代数的学习和整理9(草稿-----未完成)
3.3 特征值和特征向量是什么? 直接说现在:特征向量这个块往哪个方向进行了拉伸,各个方向拉伸了几倍。这也让人很容易理解为什么,行列式的值就是特征值的乘积。 特征向量也代表了一些良好的性质,即这些线在线性变换后…...

React的useReducer与Reudx对比
useReducer 和 Redux 都是用于处理应用程序的状态管理的工具,但它们在概念和使用场景上存在一些区别。 useReducer: useReducer 是 React 提供的一个 Hook,用于管理局部状态。它接受一个 reducer 函数和初始状态,并返回一个包含当…...
深度学习环境搭建 cuda、模型量化bitsandbytes安装教程 windows、linux
cuda、cudann、conda安装教程 输入以下命令,查看 GPU 支持的最高 CUDA 版本。 nvidia-smi cuda安装(cudatoolkit) 前往 Nvidia 的 CUDA 官网:CUDA Toolkit Archive | NVIDIA Developer CUDA Toolkit 11.8 Downloads | NVIDIA …...

pythond assert 0 <= colx < X12_MAX_COLS AssertionError
python使用xlrd读取excel时,报错: assert 0 < colx < X12_MAX_COLS AssertionError 大意是excel列太多了。主要是xlrd库的问题。最好的方法是不用它,但是我用的其他人提供的工具用到它,没法改。 尝试手动删除excel的列&am…...
js简介以及在html中的2种使用方式(hello world)
简介 javascript :是一个跨平台的脚本语言;是一种轻量级的编程语言。 JavaScript 是 Web 的编程语言。所有现代的 HTML 页面都使用 JavaScript。 HTML: 结构 css: 表现 JS: 行为 HTMLCSS 只能称之为静态网页࿰…...

vsCode使用cuda
一、vsCode使用cuda 前情提要:配置好mingw: 1.安装cuda 参考: **CUDA Toolkit安装教程(Windows):**https://blog.csdn.net/qq_42951560/article/details/116131410 2.在vscode中添加includePath c_cp…...

ubuntu无法使用apt命令时怎么安装库
如题 因为某些原因,不能直接联网使用apt命令安装库。只能手动去ubuntu镜像源里 找对应的包的deb安装文件 镜像源地址(适用于AMD64架构,就是常见的PC的X86-64啦) 镜像源地址(适用于ARM64,armhf,ppc64el,riscv64,s390x架构ÿ…...

防火墙firewall
一、什么是防火墙 二、iptables 1、iptables介绍 2、实验 138的已经被拒绝,1可以 三、firewalld 1、firewalld简介 关闭iptables,开启firewalld,curl不能使用,远程连接ssh可以使用 添加80端口 这样写也可以:添加http…...

拿来即用,自己封装的 axios
文章目录 一、需求二、分析1. 安装axios2. 新建一个 ts 文件,封装 axios3. store 存放 token 信息4. 使用5. 文件 type.js 一、需求 在日常开发中,我们会经常用到 axios ,那么如何在自己的项目中自己封装 axios 二、分析 1. 安装axios np…...
)
Hadoop小结(下)
HDFS 集群 HDFS 集群是建立在 Hadoop 集群之上的,由于 HDFS 是 Hadoop 最主要的守护进程,所以 HDFS 集群的配置过程是 Hadoop 集群配置过程的代表。 使用 Docker 可以更加方便地、高效地构建出一个集群环境。 每台计算机中的配置 Hadoop 如何配置集群…...

5个关键场景下如何选择DINOv2模型:从ViT-S到ViT-G的完整指南
5个关键场景下如何选择DINOv2模型:从ViT-S到ViT-G的完整指南 【免费下载链接】dinov2 PyTorch code and models for the DINOv2 self-supervised learning method. 项目地址: https://gitcode.com/GitHub_Trending/di/dinov2 DINOv2是Meta AI Research开发的…...

从‘调制方向’到‘闭环稳定’:一个公式搞定单相PWM整流器电流环PI参数整定
从动态模型到实战调参:单相PWM整流器电流环PI整定的工程化方法 在电力电子控制领域,单相PWM整流器的电流环设计一直是工程师面临的实操难点。理论教材中复杂的传递函数推导与实验室里实际系统的振荡现象之间,往往存在一道需要经验跨越的鸿沟…...

TCP专栏-3.三次握手
什么是三次握手三次握手是指,在建立TCP连接时,客户端和服务端总共会发送三个数据包。只有三个数据包都发送成功后,TCP连接才会建立成功。否则,丢失任何一个包,都会导致连接建立失败。发送三个数据包的过程,…...

终极游戏素材资源库:明日方舟开源项目深度解析与实战指南
终极游戏素材资源库:明日方舟开源项目深度解析与实战指南 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 在游戏开发与创作领域,获取高质量、结构化的游戏素材资…...

BilibiliDown:5步快速下载B站视频的免费跨平台神器
BilibiliDown:5步快速下载B站视频的免费跨平台神器 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/B…...

3分钟解锁B站评论区的“读心术“:揭秘用户真实身份的完整指南
3分钟解锁B站评论区的"读心术":揭秘用户真实身份的完整指南 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-c…...

深入AD9361:除了QPSK和FM,这颗射频芯片在Zynq平台上还能玩出什么花样?
深入AD9361:解锁Zynq平台上的射频创新潜能 当工程师们首次接触AD9361这颗射频芯片时,往往会被其标准应用场景如QPSK调制或FM收音所吸引。然而,这颗高度集成的RF收发器IC的真正价值,在于它为Zynq PSPL架构带来的无限可能性。本文将…...

微信网页版访问技术突破:基于请求伪装的多浏览器兼容解决方案
微信网页版访问技术突破:基于请求伪装的多浏览器兼容解决方案 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 微信网页版访问限制一直是开…...

Buildah:从Dockerfile到OCI镜像的构建原理与生产实践
1. 项目概述:从 Dockerfile 到 OCI 镜像的“幕后推手”如果你用过 Docker,那你一定对docker build命令和Dockerfile不陌生。输入一行命令,等待片刻,一个包含了应用及其所有依赖的、可移植的容器镜像就生成了。这感觉就像魔法&…...

终极Anno 1800模组加载器:5分钟轻松定制你的游戏体验
终极Anno 1800模组加载器:5分钟轻松定制你的游戏体验 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an/a…...