Python自动化小技巧18——自动化资产月报(word设置字体表格样式,查找替换文字)
案例背景
每月都要写各种月报,经营管理月报,资产月报.....这些报告文字目标都是高度相似的,只是需要替换为每个月的实际数据就行,如下:

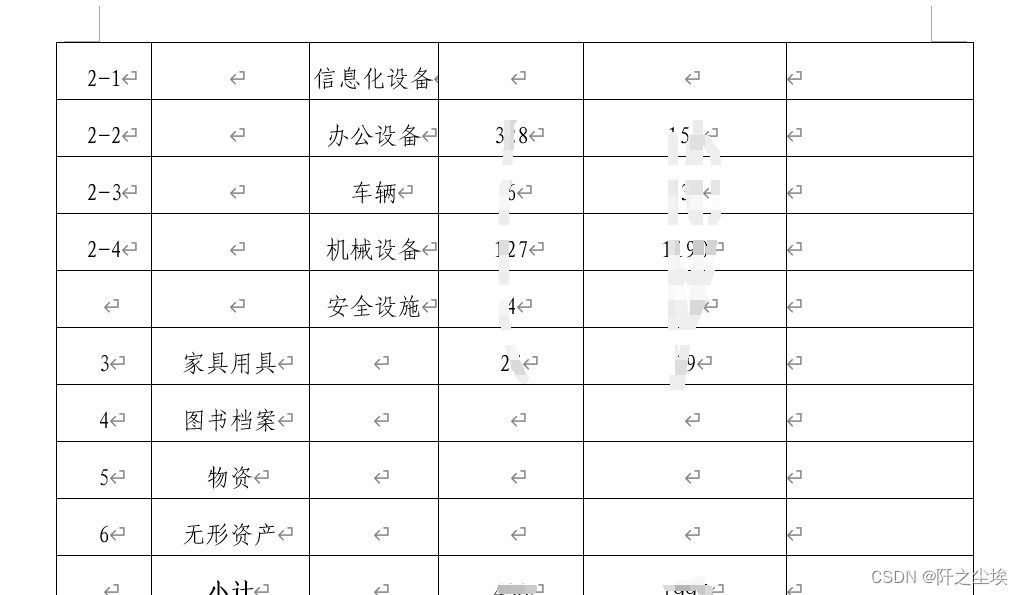
(打码是怕信息泄露.....)
可以看到,这个报告的都是高度模板化,我们只需要对里面的某些文字进行替换,例如2023年7月换成2023年8月,资产数量490替换为最新的值,表格里面的数值也是一样的情况。
这篇文章的目的:我们并不是从头到尾,去从0开始生产月报,而是在往期的月报上进行修改。
这些东西都是复制粘贴,数据准备好了,按照定点的位置填就行了。所以代码来自动化这个流程就很变得很便捷。
代码实现
导入包:
import xlrd
import pandas as pdimport docx
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
from docx import Document
from docx.oxml.ns import qn
import calendar
from docx.shared import Cm, Pt #设置像素、缩进等
from docx.enum.table import WD_TABLE_ALIGNMENT, WD_ALIGN_VERTICAL
from docx.enum.text import WD_PARAGRAPH_ALIGNMENTyear = 2023
month = 7
num_days = calendar.monthrange(year, month)[1]
print(f"{year}年{month}月有{num_days}天")
这里我们要先填入年份和信息,因为月报是月底写,最后的日期可能是31号可能是30号,所以需要用代码自动化计算一下日期.....
锚点查找
进行我们的第一步,我们需要数据来写报告,数据肯定都在excel里面算好了,没算好也肯定需要一定的流程加工算好了再说.....(参考我自动化小技巧16的文章)
例如上面我展示的目标,我需要填资产和负债的信息,这些数据都在财务那边给我的资产负债表里面,我肯定不会自己去打开excel表查找我要的值然后再写入代码里面.....这太低效了,而且这就不是自动化了。我们要用代码来找。
但是怎么找自己特定需要的数据呢?例如我要找流动资产合计这一项,我可以用固定的位置来找,比如财务那边总把流动资产合计的值写在C26这个格子里面。

但这种固定位置的查找可能有时候会有问题,比如财务那边突然需要加个标题,把资产负债表整体向下挪动了一行....那么C26这个位置就不对了。
所以绝对位置不准确,那我们就应该用相对位置,例如我发现我需要的这个值总是在‘流动资产合计’这个格子的右边两列的位置。那我先查找‘流动资产合计’这一项,然后右移动两格就是我需要的值了。
我称这种查找为锚定查找,找一个锚点,然后偏移找到自己需要的附近的值。这种相对查找的方法比绝对查找的方法出问题的可能性会小一点。
读取资产负债表,定义一个函数来进行锚点查找:
#资产负债表
wb = xlrd.open_workbook('*************业有限公司2023年7月报表20230731.xls')
sheet = wb.sheet_by_index(0) #wb.sheet_by_name('资产负债表')
def find_and_offset_xlrd(sheet, target_value, offset_row, offset_column):for row in range(sheet.nrows):for col in range(sheet.ncols):if str(sheet.cell(row, col).value).replace(' ','') == target_value:target_cell_value = sheet.cell(row + offset_row, col + offset_column).valuereturn target_cell_value然后进行查找各种我们需要的值:(注意这个函数是针对xls文件的,xlsx文件读取不了。。后面还会有针对xlsx的锚点查找函数,放在文章最后)
资产总计 = find_and_offset_xlrd(sheet, '资产总计', 0, 2)/10000
流动资产合计=find_and_offset_xlrd(sheet, '流动资产合计', 0, 2)/10000
非流动资产合计=find_and_offset_xlrd(sheet, '非流动资产合计', 0, 2)/10000
负债合计=find_and_offset_xlrd(sheet, '负债合计', 0, 2)/10000
固定资产净值=find_and_offset_xlrd(sheet, '固定资产净值', 0, 2)/10000
[资产总计,流动资产合计,非流动资产合计,负债合计,固定资产净值]![]()
这就是我们需要的值,然后进行一些必要的运算
流动资产占比=100*流动资产合计/资产总计
非流动资产占比=100*非流动资产合计/资产总计
净资产=资产总计-负债合计
固定资产占比=100*固定资产净值/资产总计
其他非流动资产=非流动资产合计-固定资产净值
其他非流动资产占比=100*其他非流动资产/资产总计段落替换
由于我们是资产月报,还得往表格里面填入各种资产的信息,我们需要读取我之前文章做好的资产分类汇总表:
df=pd.read_excel('../../资产管理/资产类别变动后汇总/分类汇总金额.xlsx',sheet_name='汇总').set_index('资产类别名称')
df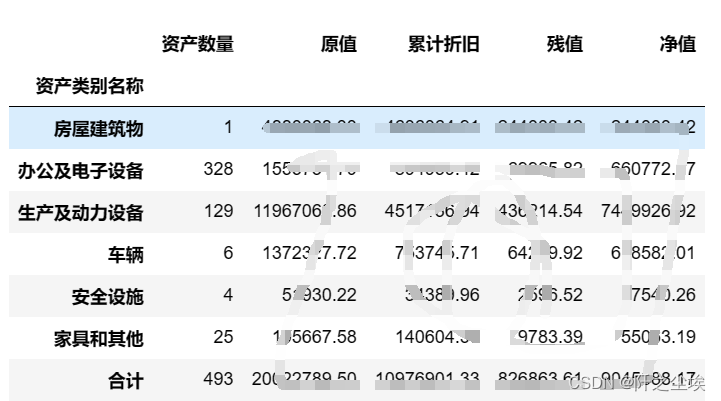
进行一些必要的计算...:
实物资产数量=df.loc['合计','资产数量']
资产原值=df.loc['合计','原值']/10000
生产及动力设备=df.loc['生产及动力设备','原值']/10000写好我们 需要的文字目标:
txt=f'''截至{year}年{month}月,**公司资产总计约{资产总计:.0f}万元。其中,流动资产{流动资产合计:.0f}万元,占比{流动资产占比:.1f}%;非流动资产{非流动资产合计:.0f}万元,占比{非流动资产占比:.1f}%。负债合计{负债合计:.0f}万元,净资产{净资产:.0f}万元。
公司非流动资产中,固定资产{固定资产净值:.0f}万元(固定资产净值),占资产总额{固定资产占比:.0f}%;其他类非流动资产{其他非流动资产:.0f}万元,占资产总额{其他非流动资产占比:.2f}%(长期待摊费用、递延所得税资产、无形资产)。
截至{year}年{month}月,**公司管理实物资产数量{实物资产数量:.0f}项,金额{资产原值:.0f}万元(资产原值)。其中,自有实物资产数量{实物资产数量:.0f}项,主要为机械设备,账面价值{生产及动力设备:.0f}万元;受托管理实物资产数量0项,账面价值(或资产原值)0万元。公司管理实物资产情况如下表:
'''
txt=txt.split('\n')这几句话我们就需要进行替换了,替换掉原来的段落。这种很多需要修改的我们就进行段落替换,如果只是像2023年7月换成8月的这种小修改就简单替换(后面会有这种函数)
核心函数!!修改样式:
def set_style(paragraphs,style=u'仿宋_GB2312',size=16):for run in paragraphs.runs:run.font.name = stylerun.font.size = Pt(size)r = run._element.rPr.rFontsr.set(qn("w:eastAsia"),style)这个函数的功能是修改这个段落的字体和大小。因为我发现每次代码修改了word里面的东西后,它就会默认使用微软体文字.....使用我们需要把内容变成我们要的模板格式。我们需要这个函数,无论替换了什么内容,都需要它来变一下格式 擦屁股。
读取文档,替换文字:
doc = docx.Document(f'./资产附件/附件1:资产管理月度情况简报{month-1}月.docx')
for i,paragraph in enumerate(doc.paragraphs):#if '2023年' in run.text:if '月,远大公司资产总计约'in paragraph.text:paragraph.text =txt[0]print('0') ; set_style(paragraph)if '公司非流动资产中,固定资产' in paragraph.text:paragraph.text = txt[1]print('1') ;set_style(paragraph)if '月,远大公司管理实物资产数量' in paragraph.text:paragraph.text=txt[2]print('2') ;set_style(paragraph) if f'{year}年' in paragraph.text and (i>len(doc.paragraphs)-3):paragraph.text=f'{year}年{month}月{num_days}日' ;set_style(paragraph)paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHTif判断是尽可能找到你需要替换的段落,然后换为上面我们设定的文字,然后设置一下样式。
最后这个条件判断意思是:如果段落行数为最后3行里面的出现了年月日,那么久换为最新的年月日。因为我需要改落款日期,但是对全文全部修改会可能出问题,所以限定了最后3行。
文字替换
这个函数类似于word里面的替换功能,把你要查找的文字,换为其他文字
#查找替换
def docx_replace(old_text, new_text, doc):for paragraph in doc.paragraphs:if old_text in paragraph.text:paragraph.text = paragraph.text.replace(old_text, new_text)set_style(paragraph)
docx_replace(f"截至{year}年{month-1}月", f"截至{year}年{month}月", doc)这是替换了月份,每次都把月报里面的日期肯定要更新为最新的。
docx_replace(f"{year}年1-{month-1}月,经省", f"{year}年1-{month}月,经省", doc)
docx_replace(f"现将**公司{month-1}月资产管理情况报告如下", f"现将**公司{month}月资产管理情况报告如下", doc)表格替换
文字我们都改了之后,我们对word表里面的数据也要进行修改:
我们可以获取word里面的表对象:
table = doc.tables[0]直接替换里面的文字是不行的,还是因为样式会变成默认样式,和领导要求的模板不一样...
所以也需要设置一下。
定义一个表格替换函数,传入你要替换的格子,替换的文本,以及字体样式,大小,居中什么的
def set_cell_text(cell, text, font_name='仿宋_GB2312', font_size=12, alignment=WD_PARAGRAPH_ALIGNMENT.CENTER):cell.text = textfor paragraph in cell.paragraphs:paragraph.alignment = alignmentset_style(paragraph,font_name,font_size)因为目标表格填的位置是固定的,所以我可以使用绝对位置来查找我需要换的数值:
set_cell_text(table.cell(2, 3), str(df.loc['房屋建筑物','资产数量']), '仿宋_GB2312', 12)
set_cell_text(table.cell(2, 4), f'''{df.loc['房屋建筑物','原值']/10000:.0f}''')set_cell_text(table.cell(7, 3), str(df.loc['办公及电子设备','资产数量']))
set_cell_text(table.cell(7, 4), f'''{df.loc['办公及电子设备','原值']/10000:.0f}''')set_cell_text(table.cell(8, 3), str(df.loc['车辆','资产数量']))
set_cell_text(table.cell(8, 4), f'''{df.loc['车辆','原值']/10000:.0f}''')set_cell_text(table.cell(9, 3), str(df.loc['生产及动力设备','资产数量']))
set_cell_text(table.cell(9, 4), f'''{df.loc['生产及动力设备','原值']/10000:.0f}''')set_cell_text(table.cell(10, 3), str(df.loc['安全设施','资产数量']))
set_cell_text(table.cell(10, 4), f'''{df.loc['安全设施','原值']/10000:.0f}''')set_cell_text(table.cell(11, 3), str(df.loc['家具和其他','资产数量']))
set_cell_text(table.cell(11, 4), f'''{df.loc['家具和其他','原值']/10000:.0f}''')set_cell_text(table.cell(15, 3), str(df.loc['合计','资产数量']))
set_cell_text(table.cell(15, 4), f'''{df.loc['合计','原值']/10000:.0f}''')最后保存,一个自动化月报的工程就完成啦。
doc.save(f'附件1:资产管理月度情况简报{month}月.docx')相关文章:
Python自动化小技巧18——自动化资产月报(word设置字体表格样式,查找替换文字)
案例背景 每月都要写各种月报,经营管理月报,资产月报.....这些报告文字目标都是高度相似的,只是需要替换为每个月的实际数据就行,如下: (打码是怕信息泄露.....) 可以看到,这个报告的都是高度模板化&…...
FFmpeg5.0源码阅读——VideoToobox硬件解码
摘要:本文描述了FFmpeg中videotoobox解码器如何进行解码工作,如何将一个编码的码流解码为最终的裸流。 关键字:videotoobox,decoder,ffmpeg VideoToolbox 是一个低级框架,提供对硬件编码器和解码器的直接访问。 它提供视频…...

IDEA 中Tomcat源码环境搭建
一、从仓库中拉取源代码 配置仓库地址、项目目录;点击Clone按钮,从仓库中拉取代码 Tomcat源码对应的github地址: https://github.com/apache/tomcat.git 二、安装Ant插件 打开 File -> Setting -> Plugins 三、添加Build文件 &…...
MATLAB | 七夕节用MATLAB画个玫瑰花束叭
Hey又是一年七夕节要到了,每年一次直男审美MATLAB绘图大赛开始hiahiahia,真的这些代码越写越不知道咋写,又不想每年把之前的代码翻出来再发一遍,于是今年又对我之前写的老代码进行了点优化组合,整了个花球变花束&#…...

嵌入式开发之configure
1 前述 在Linux的应用或者驱动开发过程中,编写makefile是无法避免的问题,但是由于makefile的各种规则,或显式,或隐式,非常多,不经常写的话,很难写出一个可用的makefile文件。为了“偷懒”&…...

深入浅出Pytorch函数——torch.nn.Module
分类目录:《深入浅出Pytorch函数》总目录 Pytorch中所有网络的基类,我们的模型也应该继承这个类。Modules也可以包含其它Modules,允许使用树结构嵌入他们,我们还可以将子模块赋值给模型属性。 语法 torch.nn.Module(*args, **kwargs)方法 …...
【100天精通python】Day38:GUI界面编程_PyQt 从入门到实战(中)_数据库操作与多线程编程
目录 专栏导读 4 数据库操作 4.1 连接数据库 4.2 执行 SQL 查询和更新: 4.3 使用模型和视图显示数据 5 多线程编程 5.1 多线程编程的概念和优势 5.2 在 PyQt 中使用多线程 5.3 处理多线程间的同步和通信问题 5.3.1 信号槽机制 5.3.2 线程安全的数据访问 Q…...
STM32--TIM定时器(3)
文章目录 输入捕获简介频率测量输入捕获通道输入捕获基本结构PWMI的基本结构输入捕获模式测量PWM频率和占空比代码 编码器接口正交编码器工作模式接口基本结构TIM编码接口器测速代码: 输入捕获简介 输入捕获IC(Input Capture),是处理器捕获外部输入信号…...
爬虫框架- feapder + 爬虫管理系统 - feaplat 的学习简记
文章目录 feapder 的使用feaplat 爬虫管理系统部署 feapder 的使用 feapder是一款上手简单,功能强大的Python爬虫框架 feapder 官方文档 文档写的很详细,可以直接上手。 基本命令: 创建爬虫项目 feapder create -p first-project创建爬虫 …...

设计模式详解-享元模式
类型:结构型模式 实现原理:尝试重用现有的同类对象,如果未找到匹配的对象,则创建新对象 目的:减少创建对象的数量以减少内存占用和提高性能。 解决的问题:大量的对象可能造成的内存溢出问题 解决方法&a…...

BDA初级分析——用SQL筛选数据
一、用SQL对数据分组 GROUP BY Group by,按...分组 作用:根据给定字段进行字段的分组,通常和聚合函数配合使用,实现分组的分析 写法:select ...from ...group by 字段名 (也可以是多个字段) GROUP BY的逻辑 SELECT gender,COUNT(user_id) …...
(成功踩坑)electron-builder打包过程中报错
目录 注意:文中的解决方法2,一定全部看完,再进行操作,有坑 背景 报错1: 报错2: 1.原因:网络连接失败 2.解决方法1: 3.解决方法2: 3.1查看缺少什么资源文件 3.2去淘…...
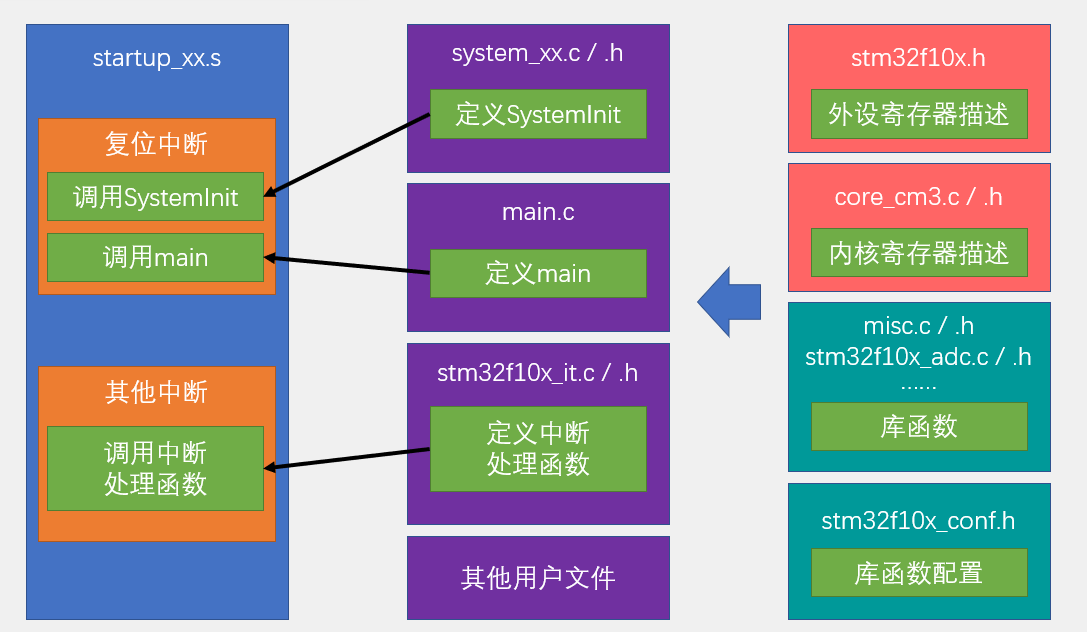
【STM32】 工程
🚩 WRITE IN FRONT 🚩 🔎 介绍:"謓泽"正在路上朝着"攻城狮"方向"前进四" 🔎🏅 荣誉:2021|2022年度博客之星物联网与嵌入式开发TOP5|TOP4、2021|2022博客之星TO…...
Git概述
目录 一、什么是Git 二、什么是版本控制系统 三、Git和SVN对比 SVN集中式 SVN优缺点 Git分布式 Git优缺点 四、Git工作流程 四个工作区域 工作流程 五、Git下载与安装 一、什么是Git 很多人都知道,林纳斯托瓦兹在1991年创建了开源的Linux,从…...
ubuntu 编译安装nginx及安装nginx_upstream_check_module模块
如果有帮助到你,麻烦点个赞呗~ 一、下载安装包 # 下载nginx_upstream_check_module模块 wget https://codeload.github.com/yaoweibin/nginx_upstream_check_module/zip/master# 解压 unzip master# 下载nginx 1.21.6 wget https://github.com/nginx/…...
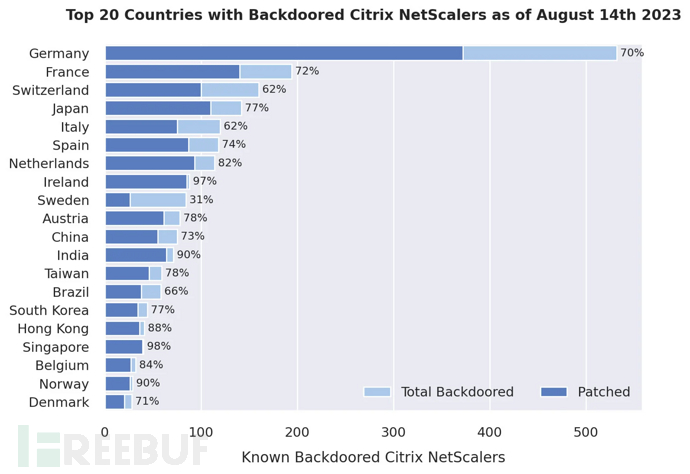
近 2000 台 Citrix NetScaler 服务器遭到破坏
Bleeping Computer 网站披露在某次大规模网络攻击活动中,一名攻击者利用被追踪为 CVE-2023-3519 的高危远程代码执行漏洞,入侵了近 2000 台 Citrix NetScaler 服务器。 研究人员表示在管理员安装漏洞补丁之前已经有 1200 多台服务器被设置了后门&#x…...
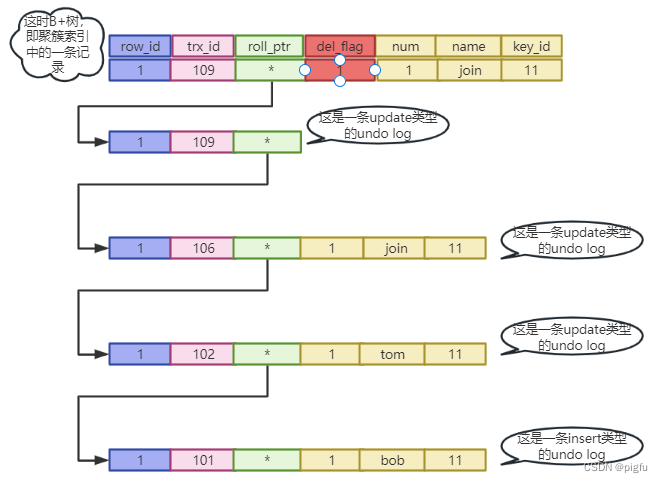
MySQL MVCC的详解之Read View
文章目录 概要一、基于UNDO LOG的版本链1.1、行记录结构1.2、了解UNDO LOG1.3、版本链 二、Read View2.1、判定机制 三、参考 概要 在上文中,我们提到了MVCC(Multi-Version Concurrency Control)多版本并发控制,是通过undo log来实现的。那具…...
基于springboot+vue的考研资讯平台(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...
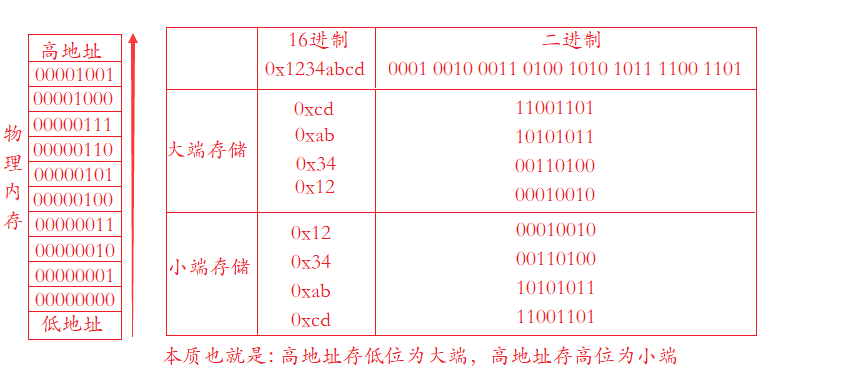
学习网络编程No.3【socket理论实战】
引言: 北京时间:2023/8/12/15:32,自前天晚上更新完文章,看了一下鹅厂新出的《扫毒3》摆烂至现在,不知道是长大了,还是近年港片就那样,给我的感觉不是很好,也可能是国内市场对港片不…...
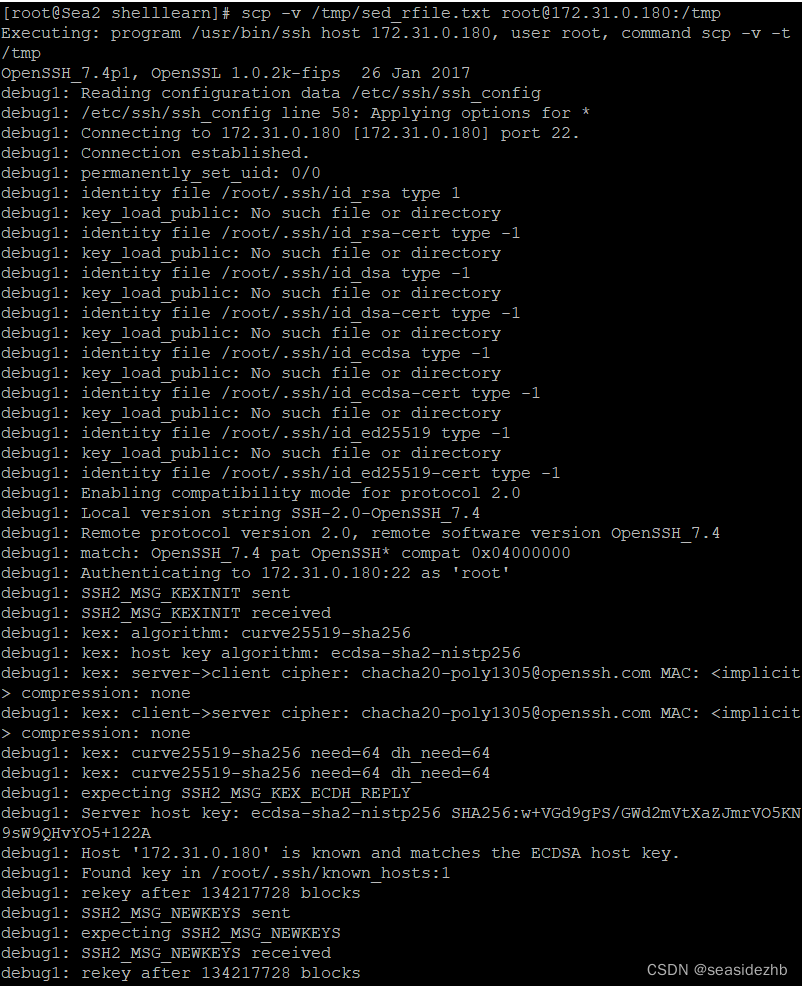
Linux学习之ssh和scp
ls /etc/ssh可以看到这个目录下有一些文件,而/etc/ssh/ssh_config是客户端配置文件,/etc/ssh/sshd_config是服务端配置文件。 cat -n /etc/ssh/sshd_config | grep "Port "可以看一下sshd监听端口的配置信息,发现这个配置端口是22…...

物联网时代:从技术连接到价值过滤的思辨与实践
1. 从“动能”到“意义”:一场关于技术本质的思辨“你能发出闪电,叫它行去,使它对你说:‘我们在这里’?”——《约伯记》38:35。这句古老的诘问,在今天读来,竟意外地切中了我们与技术关系的核心…...

半导体产业模式之争:IDM与代工在先进制程下的博弈与融合
1. 从代工模式回归IDM?一场半导体产业路线的深度思辨最近在翻看一些老资料,2012年EE Times上的一篇旧文又把我拉回了那个充满争论的十字路口。文章标题直指核心:“代工模式正在向IDM模式逆转吗?” 当时,英特尔的技术大…...

在线教程丨单卡即可爆改,面壁智能等开源MiniCPM-V-4.6,1.3B端侧模型支持图像理解/视频理解/OCR/多轮多模态对话
过去几年,整个 AI 行业几乎都笼罩在 Scaling Law 的叙事之下。参数越大、训练数据越多,模型似乎就越接近「通用智能」。从千亿到万亿参数,大模型不断刷新人们对推理能力与世界知识的想象,也让「堆算力、卷规模」成为行业默认的发展…...

植物大战僵尸95版下载2026最新版及与原本区别介绍
一、游戏版本简介 植物大战僵尸95版是基于官方原版修改优化的经典改版,也是国内玩家知名度最高、流传最广的怀旧改版之一。该版本保留原版全部关卡、场景、背景音乐以及基础玩法,没有大幅度颠覆原作设定,仅对植物属性、僵尸数值、判定机制进…...

面向少儿的 AI 背单词 APP开发
开发一款面向少儿的 AI 背单词 APP,核心在于将“机械记忆”转化为“交互式探索”。结合 2026 年主流的 AI 智能体技术,其主要功能可以归纳为以下几个维度。1. 沉浸式动态语境生成不同于传统的静态例句,AI 会根据孩子的兴趣(如恐龙…...

ZYNQ实战:从零构建uCOSIII最小系统与BSP配置详解
1. 环境准备与硬件设计 第一次在ZYNQ上跑uCOSIII时,我踩了不少坑。记得当时为了找个靠谱的参考文档,翻遍了国内外论坛。现在回头看,其实只要硬件配置对了,软件移植就是水到渠成的事。咱们先从最基础的Vivado工程搭建说起。 我用的…...

Wi-Fi卸载技术解析:从运营商策略到用户体验的深度实践
1. 项目概述:当“大哥”开始管理你的Wi-Fi十年前,一篇发表在EE Times上的文章提出了一个在今天看来依然尖锐的问题:智能手机用户使用Wi-Fi是件好事吗?这甚至上升到了“人权”层面——每个有手机的人是否都应该有权访问Wi-Fi&#…...

基于MCP协议的食品安全供应链智能风险评估服务器设计与应用
1. 项目概述:一个为AI工作流赋能的食品安全供应链智能MCP服务器如果你在食品制造、餐饮连锁或进口贸易领域工作,那么“食品安全”这四个字背后,是无数个不眠之夜和如履薄冰的日常。从原料采购到成品上架,每一个环节都可能潜藏着生…...

6.1B激活,三榜开源第一!蚂蚁·安诊儿医疗大模型发布
刚刚,由浙江省卫生健康信息中心、蚂蚁健康与浙江省安诊儿医学人工智能科技有限公司联合研发,迄今为止规模最大、能力最强的开源医疗语言模型 AntAngelMed 发布并开源。模型基于 Ling-flash-2.0,MoE架构,100B 总参数仅激活 6.1B 即…...

Windows系统美化终极指南:如何快速实现个性化定制与性能优化 [特殊字符]
Windows系统美化终极指南:如何快速实现个性化定制与性能优化 🚀 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and usability. 项目地址: https://gitcode.com/…...