基于Flink CDC实时同步PostgreSQL与Tidb【Flink SQL Client模式下亲测可行,详细教程】
文章目录
- 一、PostgreSQL作为数据来源(source),由flink读取
- 1.postgre安装与配置
- 2.flink安装与配置
- 3.flink cdc postgre配置
- 3.1 postgre配置(for flink cdc)
- 3.2 flink cdc postgres的jar包下载
- 4.flink cdc postgre测试
- 二、Tidb作为数据去向(sink),由flink写入
- 1.tidb安装与配置
- 2.flink cdc tidb的jar包下载
- 3.flink cdc tidb测试
- 三、用Flink SQL Client同步PostgreSQL到Tidb
操作系统:ubuntu-22.04,运行于wsl 2
软件版本:PostgreSQL 14.9,TiDB v7.3.0,flink 1.7.1,flink cdc 2.4.0
一、PostgreSQL作为数据来源(source),由flink读取
1.postgre安装与配置
已有postgre的跳过此步
(1)pg安装
https://zhuanlan.zhihu.com/p/143156636
sudo apt install postgresql
sudo -u postgres psql -c "SELECT version();"
sudo -u postgres psql # 连接进入postgre shell(以管理员用户)
(2)pg配置
# 创建新用户和数据库
sudo su - postgres -c "createuser domeya"
sudo su - postgres -c "createdb domeya_db"sudo -u postgres psql # 进入psql(管理员用户postgres)
grant all privileges on database domeya_db to domeya; # 授权用户操作数据库
\password 123 # 设置用户密码
\q # 退出psql# psql postgres://username:password@host:port/dbname
psql postgres://domeya:123@localhost:5432/domeya_db # 新用户测试连接
可能出现的问题
sudo -u postgres psql报错:
psql: error: connection to server on socket “/var/run/postgresql/.s.PGSQL.5432” failed: No such file or directory
Is the server running locally and accepting connections on that socket?
解决:重装pg,重启pg服务
https://stackoverflow.com/questions/69639250/pgconnectionbad-connection-to-server-on-socket-var-run-postgresql-s-pgsql
https://blog.csdn.net/psiitoy/article/details/7310003
# 卸载
dpkg --list | grep postgresql
dpkg --purge postgresql postgresql-14 postgresql-client-14 postgresql-client-common postgresql-common # 根据dpkg --list | grep postgresql中展示的结果进行填写
# rm -rf /var/lib/postgresql/
# 重装
sudo apt install postgresql
# 重启
sudo service postgresql restart # 重要!
ps -ef | grep postgres
2.flink安装与配置
已有flink的跳过此步
flink安装,配置环境变量
# https://flink.apache.org/downloads/
curl -O -L https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
tar zxvf flink-1.17.1-bin-scala_2.12.tgz -C /optsudo vim /etc/profile.d/flink.sh
# flink.sh
export FLINK_HOME=/opt/flink-1.17.1
export PATH=$PATH:$FLINK_HOME/binsource /etc/profile
启动flink
cd $FLINK_HOME
./bin/start-cluster.sh # 启动flink
jps # 查看是否启动StandaloneSessionClusterEntrypoint, TaskManagerRunner# ./bin/stop-cluster.sh # 关闭flink
3.flink cdc postgre配置
3.1 postgre配置(for flink cdc)
https://www.cnblogs.com/xiongmozhou/p/14817641.html
(1)修改配置文件
cd /etc/postgresql/14/main
cp postgresql.conf postgresql.conf.backup
vim postgresql.conf
postgresql.conf修改几个关键配置如下:
# 更改wal日志方式为logical
wal_level = logical # minimal, replica, or logical# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20 # max number of replication slots# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20 # max number of walsender processes# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s)
wal_sender_timeout = 180s # in milliseconds; 0 disable
修改完之后重启postgresql,service postgresql restart
(2)赋予权限
以管理员进入psql,sudo -u postgres psql
(可选)如果没有测试表,可以新建一个
-- 如果没有测试表,可创建一个
CREATE TABLE test_table1(id varchar(8),p_dt varchar(8)
);
-- 查看表
\dinsert into test_table1 values('1', '20230820');
select * from test_table1;
赋予普通用户复制流权限、发布表、更改表的复制标识包含更新和删除的值
-- 给用户复制流权限
ALTER ROLE domeya replication;
-- 查看权限
\du\c domeya_db -- 重要:进入到domeya_db数据库(以管理员账号进入)
-- 设置发布为true
update pg_publication set puballtables=true where pubname is not null;
-- 把所有表进行发布(包括以后新建的表);
-- 注意,此处PUBLICATION名字必须为dbz_publication,否则后续flink sql报错must be superuser to create FOR ALL TABLES publication
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 查询哪些表已经发布
select * from pg_publication_tables;-- 更改复制标识包含更新和删除之前值
ALTER TABLE test_table1 REPLICA IDENTITY FULL; -- 对应前面创建的测试表
-- 查看复制标识(为f标识说明设置成功)
select relreplident from pg_class where relname='test_table1'; -- 对应前面创建的测试表-- 退出
\q
wal_level = logical源表的数据修改时,默认的逻辑复制流只包含历史记录的primary key,如果需要输出更新记录的历史记录的所有字段,需要在表级别修改参数:ALTER TABLE tableName REPLICA IDENTITY FULL; 这样才能捕获到源表所有字段更新后的值
3.2 flink cdc postgres的jar包下载
下载flink cdc postgres相关jar包,放在$FLINK_HOME/lib
cd $FLINK_HOME/lib# 以下用于flink cdc postgres连接
# 注意:用于flink sql的jar包是flink-sql-connector-postgres-cdc,不是flink-connector-postgres-cdc
# https://mvnrepository.com/artifact/com.ververica/flink-sql-connector-postgres-cdc/2.4.0
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-postgres-cdc/2.4.0/flink-sql-connector-postgres-cdc-2.4.0.jar
如果flink在运行状态,需要重启flink,之后再启动flink sql client
cd $FLINK_HOME
./bin/stop-cluster.sh
./bin/start-cluster.sh
4.flink cdc postgre测试
https://ververica.github.io/flink-cdc-connectors/master/content/connectors/postgres-cdc.html【官方文档demo】
启动flink sql client(之前重启了flink cluster)
cd $FLINK_HOME
./bin/sql-client.sh
在flink sql client创建表,与pg中的表结构对应,表名字可以不同
CREATE TABLE source_table (id STRING,p_dt STRING
) WITH ('connector' = 'postgres-cdc','hostname' = 'localhost','port' = '5432','username' = 'domeya','password' = '123','database-name' = 'domeya_db','schema-name' = 'public','table-name' = 'test_table1','slot.name' = 'flink',-- experimental feature: incremental snapshot (default off)-- 'scan.incremental.snapshot.enabled' = 'true''decoding.plugin.name' = 'pgoutput' -- 必须加,否则报错could not access file "decoderbufs"
);select * from source_table;
可能出现的问题
运行select * from source_table;时报错
报错1:
[ERROR] Could not execute SQL statement. Reason:
org.postgresql.util.PSQLException: ERROR: could not access file “decoderbufs”: No such file or directory
https://github.com/ververica/flink-cdc-connectors/issues/37
table sql加:WITH('decoding.plugin.name' = 'pgoutput')
dataStream加:PostgreSQLSource.<String>builder().decodingPluginName("pgoutput").build()
报错2:
[ERROR] Could not execute SQL statement. Reason:
org.postgresql.util.PSQLException: ERROR: must be superuser to create FOR ALL TABLES publication
https://gist.github.com/alexhwoods/4c4c90d83db3c47d9303cb734135130d
检查之前的操作
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
select * from pg_publication_tables;
注意,flink postgres-cdc只能读(作为source),不能写(作为sink)
Flink SQL> insert into source_table values('3', '20230820');
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: Connector 'postgres-cdc' can only be used as a source. It cannot be used as a sink.
二、Tidb作为数据去向(sink),由flink写入
1.tidb安装与配置
已有tidb的跳过此步
https://docs.pingcap.com/zh/tidb/stable/quick-start-with-tidb
su xxx # 切换到你的普通用户
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
source /home/xxx/.bashrc # 按上个命令输出的路径来,上面显示的是Shell profile: /home/xxx/.bashrctiup playground # 下载镜像,并启动某个版本的集群
- 以这种方式执行的 playground,在结束部署测试后 TiUP 会清理掉原集群数据,重新执行该命令后会得到一个全新的集群。
- 若希望持久化数据,可以执行 TiUP 的
--tag参数:tiup --tag <your-tag> playground ...
下载完毕,启动成功之后展示信息:
Connect TiDB: mysql --comments --host 127.0.0.1 --port 4000 -u root
TiDB Dashboard: http://127.0.0.1:2379/dashboard
Grafana: http://127.0.0.1:3000
连接tidb
# 使用mysql client连接tidb
sudo apt install mysql-client
mysql --comments --host 127.0.0.1 --port 4000 -u root# 设置root密码
# https://docs.pingcap.com/zh/tidb/stable/user-account-management#%E8%AE%BE%E7%BD%AE%E5%AF%86%E7%A0%81
# https://blog.csdn.net/qq_45675449/article/details/106866700
SET PASSWORD FOR 'root'@'%' = '123'; # root的localhost是%,可通过 select user,host from mysql.user; 查看exit;# mysql -uroot -p无法连接,必须加上port和host,并且host不能写成localhost
# https://blog.csdn.net/hjf161105/article/details/78850658
mysql -uroot --port 4000 -h 127.0.0.1 -p
2.flink cdc tidb的jar包下载
下载用于jdbc mysql连接的jar包,用于flink cdc tidb连接。
特别注意:Tidb的sink模式得用jdbc+mysql连接,不用官方提供的tidb cdc因为其不能作为sink,只能曲线救国参考这种方法了。
cd $FLINK_HOME/lib
# 以下用于jdbc mysql(用于flink cdc tidb连接)
# https://mvnrepository.com/artifact/org.apache.flink/flink-connector-jdbc/3.1.1-1.17
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc/3.1.1-1.17/flink-connector-jdbc-3.1.1-1.17.jar
# https://mvnrepository.com/artifact/com.mysql/mysql-connector-j/8.1.0
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.1.0/mysql-connector-j-8.1.0.jar
如果flink在运行状态,需要重启flink,之后再启动flink sql client
cd $FLINK_HOME
./bin/stop-cluster.sh
./bin/start-cluster.sh
3.flink cdc tidb测试
基于Flink CDC实时同步数据(MySQL到MySQL)
flink cdc tidb 官方文档demo(无法作为sink,只能作为source)
(可选)tidb创建测试表
# mysql -uroot --port 4000 -h 127.0.0.1 -p# 创建测试表
CREATE TABLE test.test_table1(id varchar(8),p_dt varchar(8)
);
insert into test.test_table1 values('3', '20230819');
启动flink sql client(之前重启了flink cluster)
cd $FLINK_HOME
./bin/sql-client.sh
flink sql连接tidb,仿照mysql的连接
-- checkpoint every 3000 milliseconds
SET 'execution.checkpointing.interval' = '3s';-- register a TiDB table in Flink SQL
CREATE TABLE sink_table (id STRING,p_dt STRING,PRIMARY KEY(id) NOT ENFORCED -- 必须写PRIMARY KEY,否则报错:[ERROR] Could not execute SQL statement. Reason: java.lang.IllegalStateException: please declare primary key for sink table when query contains update/delete record.) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://localhost:4000/test','driver' = 'com.mysql.cj.jdbc.Driver','username' = 'root','password' = '123','table-name' = 'test_table1'
);-- read snapshot and binlogs from table
SELECT * FROM sink_table;
三、用Flink SQL Client同步PostgreSQL到Tidb
# 将会提交一个作业,进行source_table->sink_table的单向同步
insert into sink_table select * from source_table;
[INFO] Submitting SQL update statement to the cluster…
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 8e47bfa3ea78da4c47b395f7517c2812
在flink web ui上可以看到作业运行状态。
只要这个作业是正常runnning,那么对source_table的任何修改都会同步到sink_table。注意这种是单向同步,source_table的变动(增/删/改)会同步到sink_table,但反过来sink_table的变动不会影响到source_table(不会触发source_table->sink_table的同步)。
相关文章:

基于Flink CDC实时同步PostgreSQL与Tidb【Flink SQL Client模式下亲测可行,详细教程】
文章目录 一、PostgreSQL作为数据来源(source),由flink读取1.postgre安装与配置2.flink安装与配置3.flink cdc postgre配置3.1 postgre配置(for flink cdc)3.2 flink cdc postgres的jar包下载 4.flink cdc postgre测试…...
Vue-5.编译器Idea
Vue专栏(帮助你搭建一个优秀的Vue架子) Vue-1.零基础学习Vue Vue-2.Nodejs的介绍和安装 Vue-3.Vue简介 Vue-4.编译器VsCode Vue-5.编译器Idea Vue-6.编译器webstorm Vue-7.命令创建Vue项目 Vue-8.Vue项目配置详解 Vue-9.集成(.editorconfig、…...

qiuzhiji3
本篇想介绍一下慧与,这里的工作氛围和企业文化令人难忘,希望更多人了解它 也想探讨一下不同的文化铸就的不同企业,究竟有哪些差别。 本篇将从我个人角度出发描述慧与。 2022/3/16至2023/7/31 本篇初次写于2023年8月20日 说起来在毕业之前那段…...
JVM——垃圾回收(垃圾回收算法+分代垃圾回收+垃圾回收器)
1.如何判断对象可以回收 1.1引用计数法 只要一个对象被其他对象所引用,就要让该对象的技术加1,某个对象不再引用其,则让它计数减1。当计数变为0时就可以作为垃圾被回收。 有一个弊端叫做循环引用,两个的引用计数都是1ÿ…...

QT TLS initialization failed问题(已解决) QT基础入门【网络编程】openssl
问题: qt.network.ssl: QSslSocket::connectToHostEncrypted: TLS initialization failed 这个问题的出现主要是使用了https请求:HTTPS ≈ HTTP + SSL,即有了加密层的HTTP 所以Qt 组件库需要OpenSSL dll 文件支持HTTPS 解决: 1.加入以下两行代码获取QT是否支持opensll以…...

SpringMVC之获取请求参数
文章目录 前言一、通过ServletAPI获取二、通过控制器方法的形参获取请求参数三、注解1.RequestParam2.RequestHeader3.CookieValue前面的代码总和:4.通过POJO获取请求参数 三、解决获取请求参数的乱码问题总结 前言 下面用到了thymeleaf,不知道的可以看…...
【无标题】QT应用编程: QtCreator配置Git版本控制(码云)
QT应用编程: QtCreator配置Git版本控制(码云) 感谢:DS小龙哥的文章,这篇主要参考小龙哥的内容。 https://cloud.tencent.com/developer/article/1930531?areaSource102001.15&traceIdW2mKALltGu5f8-HOI8fsN Qt Creater 自带了git支持。但是一直没…...

JVM面试题-2
1、有哪几种垃圾回收器,各自的优缺点是什么? 垃圾回收器主要分为以下几种:Serial、ParNew、Parallel Scavenge、Serial Old、Parallel Old、CMS、G1; Serial:单线程的收集器,收集垃圾时,必须stop the worl…...
kafka安装说明以及在项目中使用
一、window 安装 1.1、下载安装包 下载kafka 地址,其中官方版内置zk, kafka_2.12-3.4.0.tgz其中这个名称的意思是 kafka3.4.0 版本 ,所用语言 scala 版本为 2.12 1.2、安装配置 1、解压刚刚下载的配置文件,解压后如下&#x…...
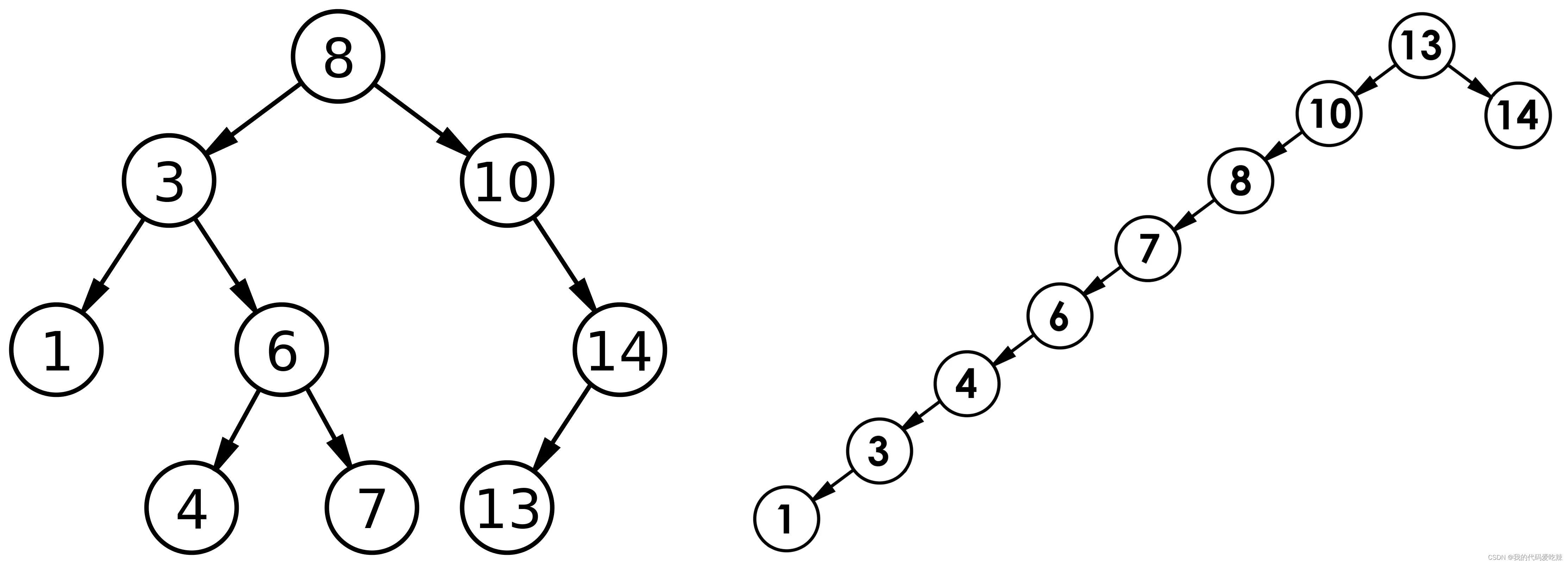
二叉树搜索
✅<1>主页:我的代码爱吃辣📃<2>知识讲解:数据结构——二叉搜索树☂️<3>开发环境 :Visual Studio 2022💬<4>前言:在之前的我们已经学过了普通二叉树,了解了基本的二叉树…...
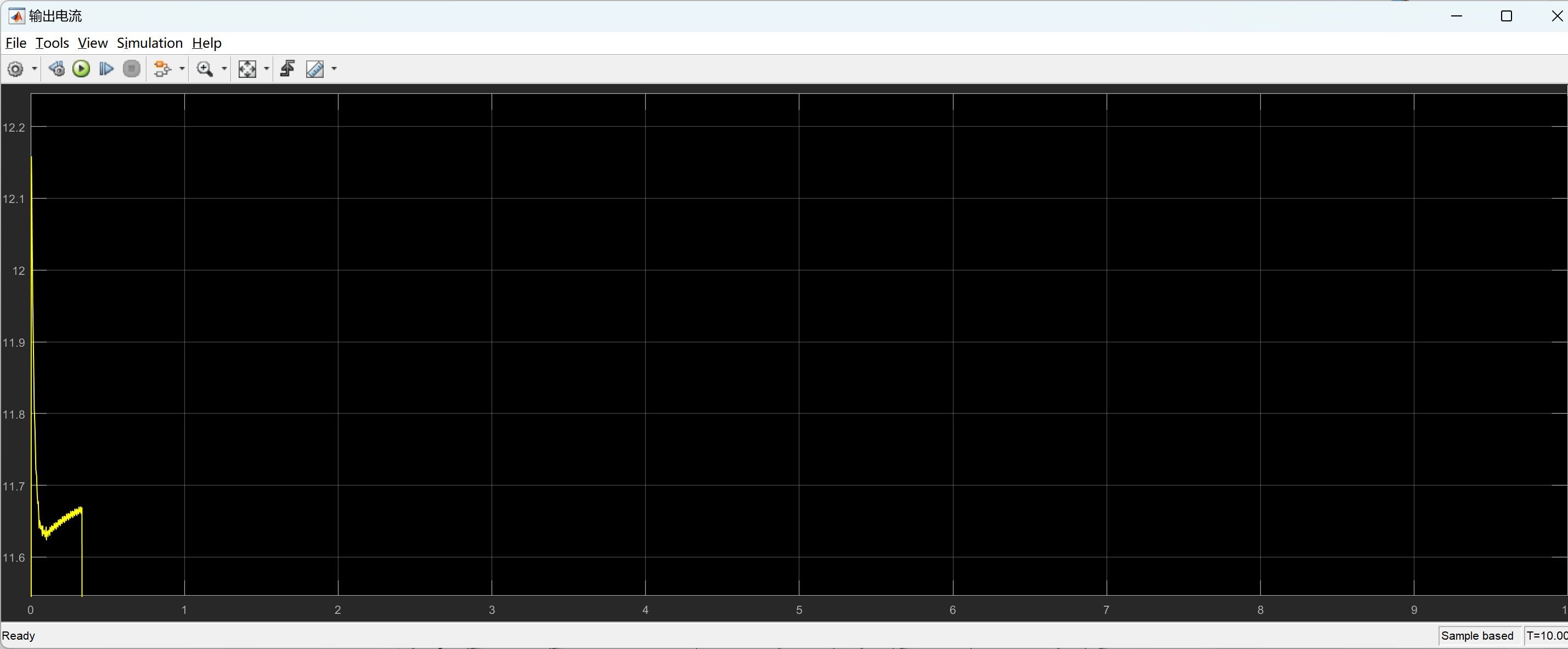
【先进PID控制算法(ADRC,TD,ESO)加入永磁同步电机发电控制仿真模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
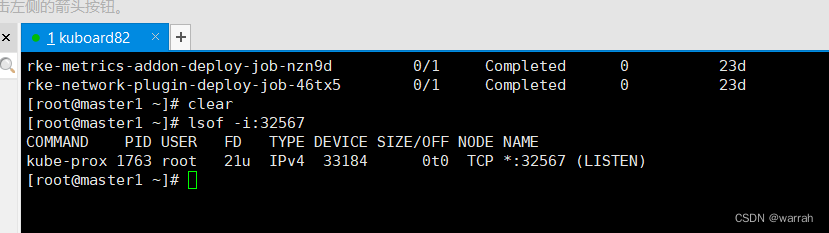
k8s集群生产环境的问题处理
2 k8s上的服务均无法访问 执行命令kubectl get pods -ALL,k8s集群中的服务均是running状态 1 kuboard 网页无法访问 kuboard无法通过浏览器访问,但是查看端口是被占用的...
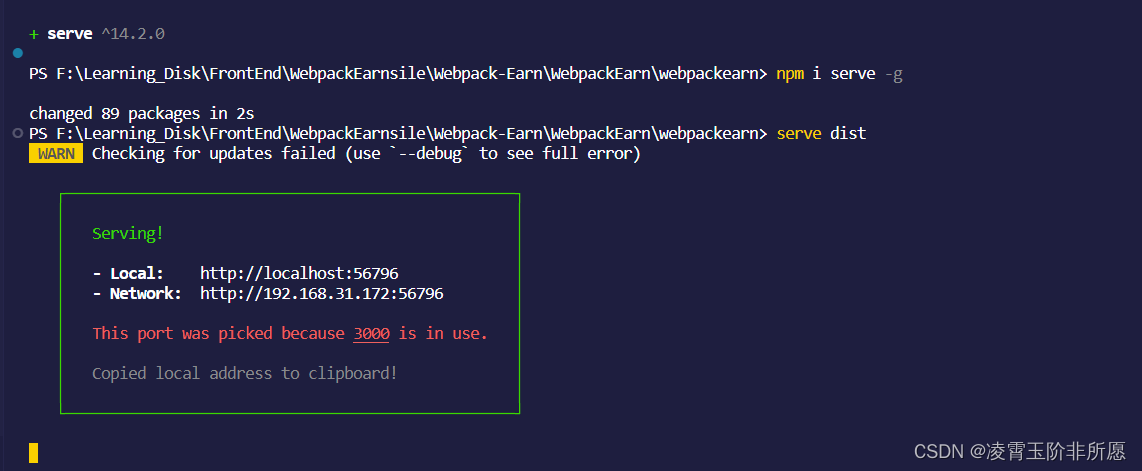
serve : 无法将“serve”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
1、在学习webpack打包的时候,需要 serve用来启动开发服务器来部署代码查看效果的。安装完之后运行出现以下错误: 2、使用命令查看安装目录: npm list -g我们已经安装过了 3、解决: 我们看到上图路径在:C:\Users\qiy…...
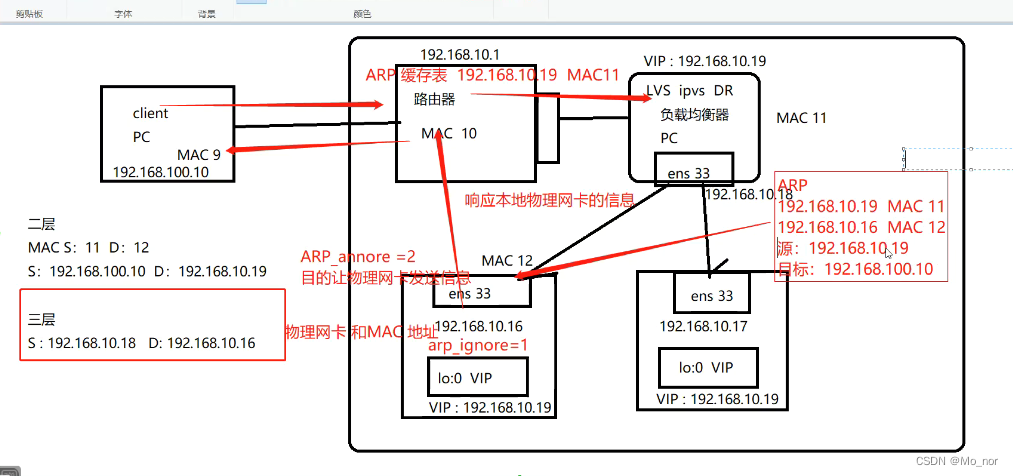
【LVS】2、部署LVS-DR群集
LVS-DR数据包的流向分析 1.客户端发送请求到负载均衡器,请求的数据报文到达内核空间; 2.负载均衡服务器和正式服务器在同一个网络中,数据通过二层数据链路层来传输; 3.内核空间判断数据包的目标IP是本机VIP,此时IP虚…...
)
设计模式 -- 单例模式(传统面向对象与JavaScript 的对比实现)
单例模式 – 传统面向对象与JavaScript 的对比实现 文章目录 单例模式 -- 传统面向对象与JavaScript 的对比实现传统的面向对象的实现定义实现思路初级实现缺点 透明的单例模式实现目的(实现效果)实现缺点 用代理实现单例模式优点 JavaScript 中的单例模…...
YOLOX算法调试记录
YOLOX是在YOLOv3基础上改进而来,具有与YOLOv5相媲美的性能,其模型结构如下: 由于博主只是要用YOLOX做对比试验,因此并不需要对模型的结构太过了解。 先前博主调试过YOLOv5,YOLOv7,YOLOv8,相比而言,YOLOX的环…...
基于小程序的汽车俱乐部系统的设计与实现(论文+源码)_kaic
目录 前 言 1 系统概述 1.1 系统主要功能 1.2 开发及运行环境 2 系统分析和总体设计 2.1 需求分析 2.2 可行性分析 2.3 设计目标 2.4 项目规划 2.5 系统开发语言简介 2.6 系统功能模块图 3 系统数据库设计 3.1 数据库开发工具简介 3.2 数据库需求分析 3.3 数据库…...

ProgrammingArduino物联网
programming_arduino_ed2 IO 延时闪灯 void setup() {pinMode(13, OUTPUT); }void loop() {digitalWrite(13, HIGH);delay(500);digitalWrite(13, LOW);delay(500); }// sketch 03-02 加入变量 int ledPin 13; int delayPeriod 500;void setup() {pinMode(ledPin, OUTPUT)…...

SSM框架的学习与应用(Spring + Spring MVC + MyBatis)-Java EE企业级应用开发学习记录(第一天)Mybatis的学习
SSM框架的学习与应用(Spring Spring MVC MyBatis)-Java EE企业级应用开发学习记录(第一天)Mybatis的学习 一、当前的主流框架介绍(这就是后期我会发出来的框架学习) Spring框架 Spring是一个开源框架,是为了解决企业应用程序开发复杂…...

Programming abstractions in C阅读笔记: p118-p122
《Programming Abstractions In C》学习第49天,p118-p122,总结如下: 一、技术总结 1.随机数 (1)seed p119,“The initial value–the value that is used to get the entire process start–is call a seed for the random ge…...

从电视伴音收音机消亡看数字技术演进与仪器集成化趋势
1. 从一台“电视伴音收音机”说起:一个时代的消逝与技术演进的注脚我书桌抽屉的角落里,一直躺着一台老旧的收音机。它不是普通的AM/FM收音机,在它的波段选择旋钮上,除了熟悉的“AM”和“FM”,还有一个略显神秘的“TV”…...

开源与闭源软件质量对比:工程实践与激励机制才是关键
1. 开源与闭源软件质量之争:一场被误解的辩论最近和几位同行聊起软件质量的话题,不出所料,讨论很快又滑向了那个经典的对立:开源软件和闭源(或称专有)软件,到底谁的质量更好?场面一度…...

ARM调试状态与Halting Step机制详解
1. ARM调试状态机制深度解析在嵌入式系统开发中,调试功能的重要性不言而喻。ARM架构提供了一套完整的调试机制,其中调试状态(Debug State)是核心组成部分。当处理器进入调试状态时,会暂停正常程序执行,将控…...

Vellium:基于Electron与RAG的本地AI创作工作台架构解析
1. 项目概述:Vellium,一个全能的本地AI创作与对话工作台如果你和我一样,既沉迷于与AI进行深度角色扮演对话,又需要它协助进行严肃的写作、整理知识库,并且对数据隐私和本地化运行有执念,那么你一定会对Vell…...

在Windows上直接安装Android应用的革命性方案:APK安装器完全指南
在Windows上直接安装Android应用的革命性方案:APK安装器完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运行手…...

《蔚蓝档案》主题鼠标指针:从设计到安装的完整指南
1. 项目概述:为你的桌面注入《蔚蓝档案》的活力如果你和我一样,既是《蔚蓝档案》的玩家,又是个喜欢折腾桌面美化的爱好者,那么看到一套高质量的游戏主题鼠标指针,那种“必须拥有”的心情我完全理解。今天要聊的这个项目…...

Encounter/Innovus GIFT TCL 脚本流程索引清单
目录 一、 布局阶段 (Placement) 二、 布线阶段 (Routing) 三、 时序阶段 (Timing) 四、 电源阶段 (Power) 五、 IO 与端口处理 六、 调试与辅助工具 一、 布局阶段 (Placement) 脚本名称 核心用途 调用场景 userAddAllHInsts.tcl 为源模块中的每个扇出添加缓冲器 解决高扇…...

5大架构决策原则:ComfyUI-Manager如何平衡技术演进与系统兼容性
5大架构决策原则:ComfyUI-Manager如何平衡技术演进与系统兼容性 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿
NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否曾经为了收集某个稀有家具而花费数周时间?是否因为地…...

CentOS7网络配置与XShell连接实战:从零搭建远程管理环境
1. 环境准备与工具安装 第一次接触Linux服务器管理的新手,往往会被网络配置和远程连接这两个基础操作难住。我自己刚开始学习时,光是让虚拟机联网就折腾了大半天。其实只要掌握正确的方法,整个过程完全可以像搭积木一样简单明了。 首先需要准…...