kafka安装说明以及在项目中使用
一、window 安装
1.1、下载安装包
- 下载kafka 地址,其中官方版内置zk, kafka_2.12-3.4.0.tgz
- 其中这个名称的意思是 kafka3.4.0 版本 ,所用语言 scala 版本为 2.12
1.2、安装配置
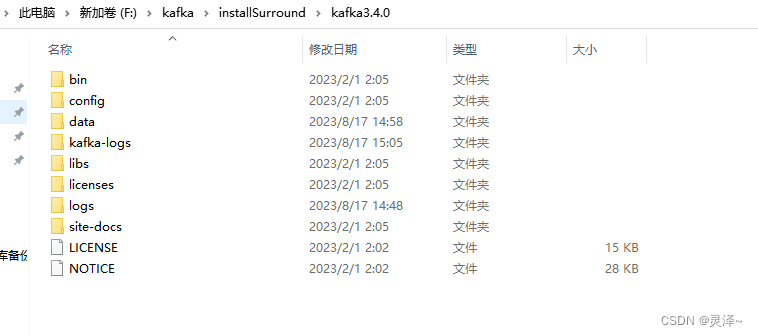
1、解压刚刚下载的配置文件,解压后如下,其中 data和kafka-logs 这两个文件是没有的
2、修改配置:进入到config目录,
- 修改service.properties里面log.dirs路径未 log.dirs=F:\kafka\installSurround\kafka3.4.0\kafka-logs,该目录是kafka的数据存储目录

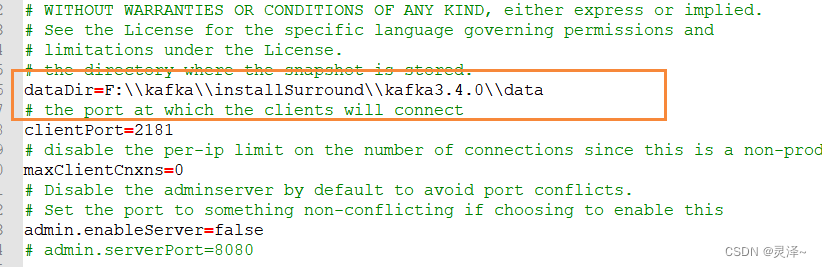
- 修改zookeeper.properties里面dataDir路径为 dataDir=F:\kafka\installSurround\kafka3.4.0\data,该目录是 zookeeper存储的kafka的数据目录
3、server.properties说明
| 属性 | 说明 |
|---|---|
| log.dirs | 指定Broker需要使用的若干个文件目录路径,没有默认值,必须指定。在生产环境中一定要为log.dirs配置多个路径,如果条件允许,需要保证目录被挂载到不同的物理磁盘上。优势在于,提升读写性能,多块物理磁盘同时读写数据具有更高的吞吐量;能够实现故障转移(Failover),Kafka 1.1版本引入Failover功能,坏掉磁盘上的数据会自动地转移到其它正常的磁盘上,而且Broker还能正常工作,基于Failover机制,Kafka可以舍弃RAID方案。 |
| zookeeper.connect | CS格式参数,可以指定值为zk1:2181,zk2:2181,zk3:2181,不同Kafka集群可以指定:zk1:2181,zk2:2181,zk3:2181/kafka1,chroot只需要写一次。 |
| listeners | 设置内网访问Kafka服务的监听器。 |
| advertised.listeners | 设置外网访问Kafka服务的监听器。 |
| auto.create.topics.enable | 是否允许自动创建Topic。 |
| unclean.leader.election.enable | 是否允许Unclean Leader 选举。 |
| auto.leader.rebalance.enable | 是否允许定期进行Leader选举,生产环境中建议设置成false。 |
| log.retention.{hours | minutes |
| log.retention.bytes | 指定Broker为消息保存的总磁盘容量大小。message.max.bytes:控制Broker能够接收的最大消息大小。 |
1.3、启动
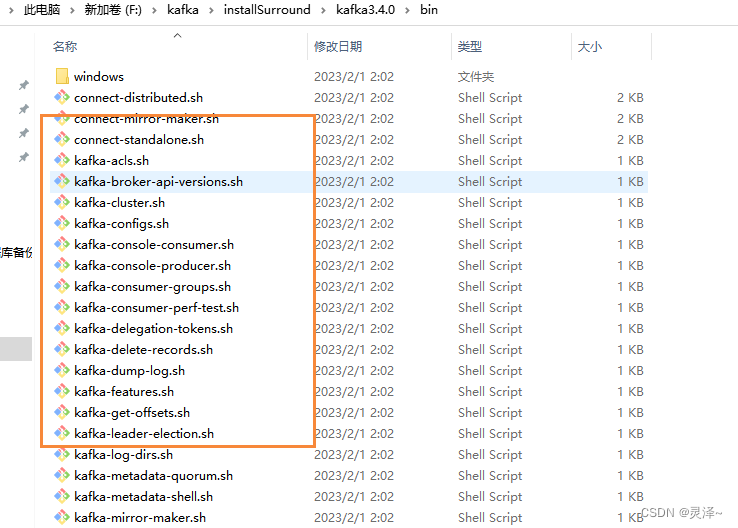
1、 启动脚本都在bin目录的window目录下,一定要先启动 zookeeper,再启动kafka
如果是linux,不使用window下的命令即可,使用对应的 xxxx.sh 即可
2、首先启动zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
3、在启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
二、linux 安装
暂略
三、docker 安装
暂略
四、docker 安装
暂略
五、命令行使用
5.1、topic 命令
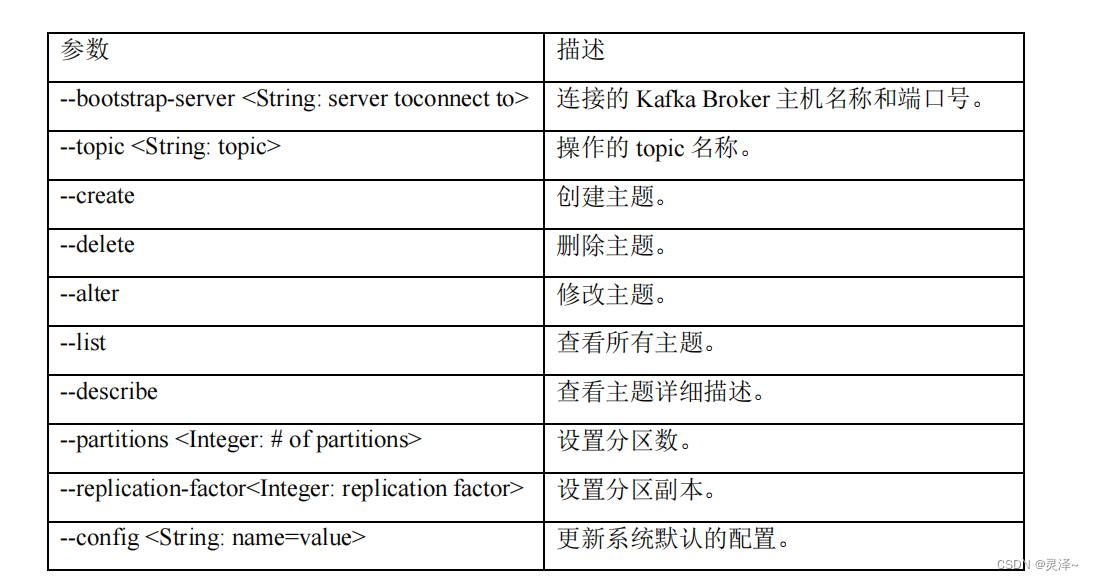
1、关于topic,这里用window 来示例
bin\windows\kafka-topics.bat
2、创建 first topic,五个分区,1个副本
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --create --partitions 5 --replication-factor 1 --topic first

3、查看当前服务器中的所有 topic
bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092

4、查看 first 主题的详情
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --describe --topic first

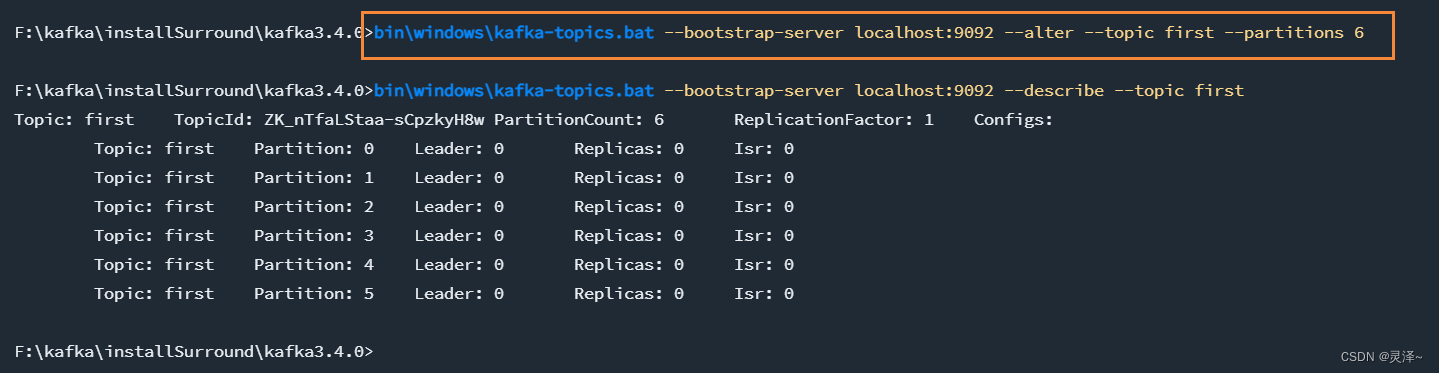
5、修改分区数**(注意:分区数只能增加,不能减少)**
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --alter --topic first --partitions 6
6、删除 topic,该操作在winodw,会出现文件授权问题,日志可以在kafka的启动命令窗口中查看,只需要修改文件权限即可,如果出现这个问题,我们需要清空之前配置的 data和kafka-logs 这两个文件中的内容,再次重新启动即可。
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --delete --topic first

5.2、生产者命令行操作
1、关于查看操作生产者命令参数,这里用window 来示例
.\bin\windows\kafka-console-producer.bat

2、发送消息,这里发送了2次的数据,第一次是hello,第二次是world
.\bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic first

5.3、消费者命令行操作
1、关于查看操作生产者命令参数,这里用window 来示例
.\bin\windows\kafka-console-consumer.bat


2、接受消息,因为前面我们在发送消息的时候,消费者没有启动,所以第一次发的数据这里是收不到的,并没有存储到topic中
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic first


3、把主题中所有的数据都读取出来(包括历史数据),可以看到我们获取到了从消费者没有上线之前到上线之后的所有数据,一共6条。
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --from-beginning --topic first

5.4、脚本说明
| 项目 | Value |
|---|---|
| connect-standalone.sh | 用于启动单节点的Standalone模式的Kafka Connect组件。 |
| connect-distributed.sh | 用于启动多节点的Distributed模式的Kafka Connect组件。 |
| kafka-acls.sh | 脚本用于设置Kafka权限,比如设置哪些用户可以访问Kafka的哪些TOPIC的权限。 |
| kafka-delegation-tokens.sh | 用于管理Delegation Token。基于Delegation Token的认证是一种轻量级的认证机制,是对SASL认证机制的补充。 |
| kafka-topics.sh | 用于管理所有TOPIC。 |
| kafka-console-producer.sh | 用于生产消息。 |
| kafka-console-consumer.sh | 用于消费消息。 |
| kafka-producer-perf-test.sh | 用于生产者性能测试。 |
| kafka-consumer-perf-test.sh | 用于消费者性能测试。 |
| kafka-delete-records.sh | 用于删除Kafka的分区消息,由于Kafka有自己的自动消息删除策略,使用率不高。 |
| kafka-dump-log.sh | 用于查看Kafka消息文件的内容,包括消息的各种元数据信息、消息体数据。 |
| kafka-log-dirs.sh | 用于查询各个Broker上的各个日志路径的磁盘占用情况。 |
| kafka-mirror-maker.sh | 用于在Kafka集群间实现数据镜像。 |
| kafka-preferred-replica-election.sh | 用于执行Preferred Leader选举,可以为指定的主题执行更换Leader的操作。 |
| kafka-reassign-partitions.sh | 用于执行分区副本迁移以及副本文件路径迁移。 |
| kafka-run-class.sh | 用于执行任何带main方法的Kafka类。 |
| kafka-server-start.sh | 用于启动Broker进程。 |
| kafka-server-stop.sh | 用于停止Broker进程。 |
| kafka-streams-application-reset.sh | 用于给Kafka Streams应用程序重设位移,以便重新消费数据。 |
| kafka-verifiable-producer.sh | 用于测试验证生产者的功能。 |
| kafka-verifiable-consumer.sh | 用于测试验证消费者功能。 |
| trogdor.sh | 是Kafka的测试框架,用于执行各种基准测试和负载测试。 |
| kafka-broker-api-versions.sh | 脚本主要用于验证不同Kafka版本之间服务器和客户端的适配性 |
5.5、关闭kafka
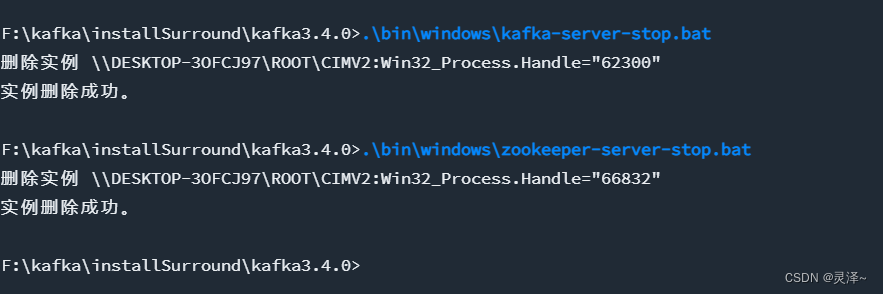
1、一定要先关闭 kafka,再关闭zookeeper,否则容易出现数据错乱
如果出现数据错错乱,最简单的方法就是清空data和kafka-logs 这两个文件下的内容,重新启动即可
2、关闭
.\bin\windows\kafka-server-stop.bat
.\bin\windows\zookeeper-server-stop.bat
5.6、选择分区数及kafka性能测试
1、主要工具是 kafka-producer-perf-test.bat 和 kafka-consumer-perf-test.bat 两个脚本,可以参考 kafka如何选择分区数及kafka性能测试
六、java 使用
6.1、使用原生客户端
1、依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.4.0</version></dependency>
2、发送和消费消息,具体代码如下:
public class KafkaConfig {public static void main(String[] args) {// 声明主题String topic = "first";// 创建消费者Properties consumerConfig = new Properties();consumerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");consumerConfig.put(ConsumerConfig.GROUP_ID_CONFIG,"boot-kafka");consumerConfig.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");consumerConfig.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer kafkaConsumer = new KafkaConsumer(consumerConfig);// 订阅主题并循环拉取消息kafkaConsumer.subscribe(Arrays.asList(topic));new Thread(new Runnable() {@Overridepublic void run() {while (true){ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(10000));for(ConsumerRecord<String, String> record:records){System.out.println(record.value());}}}}).start();// 创建生产者Properties producerConfig = new Properties();producerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");producerConfig.put(ProducerConfig.CLIENT_ID_CONFIG,"boot-kafka-client");producerConfig.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");producerConfig.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer producer = new KafkaProducer<>(producerConfig);// 给主题发送消息producer.send(new ProducerRecord<>(topic, "hello,"+System.currentTimeMillis()));}
}
6.2、使用springBoot
1、依赖
<!-- 不使用kafka的原始客户端,使用spring集成的,这样比较方便 --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><!-- 可以不用指定,springBoot 会帮我们选择,如果有特殊需求,可以更改 --><!-- <version>3.0.2</version>--></dependency>
2、配置文件
server:port: 7280servlet:context-path: /thermal-emqx2kafkashutdown: gracefulspring:application:name: thermal-api-demonstration-tdenginelifecycle:timeout-per-shutdown-phase: 30smvc:pathmatch:matching-strategy: ant_path_matcher # 不然spring boot 2.6以后的版本 和 swagger 会出现 问题,可以参考 https://blog.csdn.net/qq_41027259/article/details/125747298kafka:bootstrap-servers: 127.0.0.1:9092 # 192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094 连接的 Kafka Broker 主机名称和端口号#properties.key-serializer: # 用于配置客户端的附加属性,对于生产者和消费者都是通用的,。 org.apache.kafka.common.serialization.StringSerializerproducer: # 生产者retries: 3 # 重试次数#acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)#batch-size: 16384 # 一次最多发送数据量#buffer-memory: 33554432 # 生产端缓冲区大小key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer: # 消费者group-id: test-consumer-group #默认的消费组ID,在Kafka的/config/consumer.properties中查看和修改#enable-auto-commit: true # 是否自动提交offset#auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)#auto-offset-reset: latest #earliest,latestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3、发送消息
package cn.jt.thermalemqx2kafka.kafka.controller;import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.HashMap;
import java.util.Map;/*** @author GXM* @version 1.0.0* @Description TODO* @createTime 2023年08月17日*/
@Slf4j
@RestController
@RequestMapping("/test")
public class TestController {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@GetMapping("/mock")public String sendKafkaMessage() {Map<String, Object> data = new HashMap<>(2);data.put("id", 1);data.put("name", "gkj");kafkaTemplate.send("first", JSON.toJSONString(data));return "ok";}
}4、接受消息
package cn.jt.thermalemqx2kafka.kafka.config;import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;/*** @author GXM* @version 1.0.0* @Description TODO* @createTime 2023年08月17日*/
@Slf4j
@Component
public class KafkaListener {@org.springframework.kafka.annotation.KafkaListener(topics = "first")private void handler(String content) {log.info("consumer received: {} ", content);}
}相关文章:
kafka安装说明以及在项目中使用
一、window 安装 1.1、下载安装包 下载kafka 地址,其中官方版内置zk, kafka_2.12-3.4.0.tgz其中这个名称的意思是 kafka3.4.0 版本 ,所用语言 scala 版本为 2.12 1.2、安装配置 1、解压刚刚下载的配置文件,解压后如下&#x…...
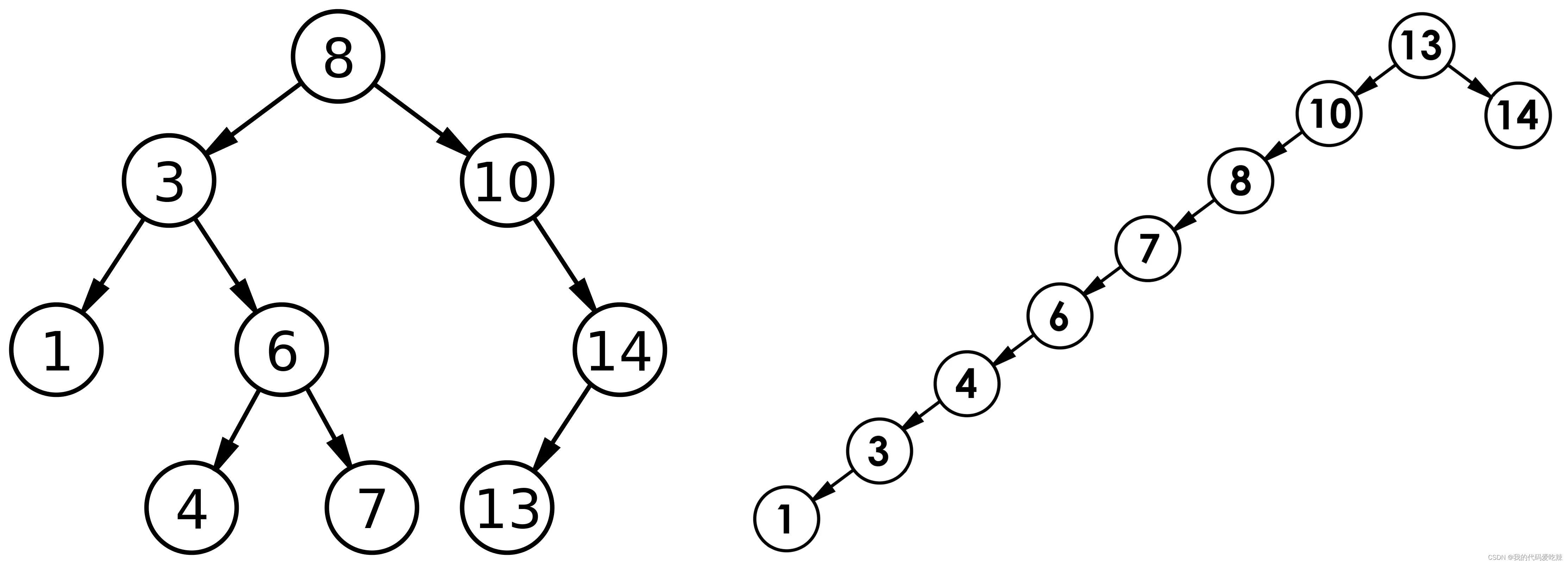
二叉树搜索
✅<1>主页:我的代码爱吃辣📃<2>知识讲解:数据结构——二叉搜索树☂️<3>开发环境 :Visual Studio 2022💬<4>前言:在之前的我们已经学过了普通二叉树,了解了基本的二叉树…...
【先进PID控制算法(ADRC,TD,ESO)加入永磁同步电机发电控制仿真模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
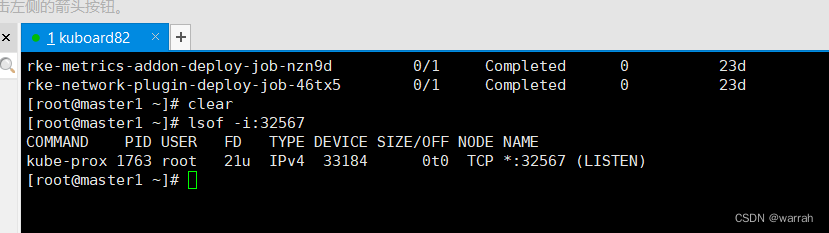
k8s集群生产环境的问题处理
2 k8s上的服务均无法访问 执行命令kubectl get pods -ALL,k8s集群中的服务均是running状态 1 kuboard 网页无法访问 kuboard无法通过浏览器访问,但是查看端口是被占用的...
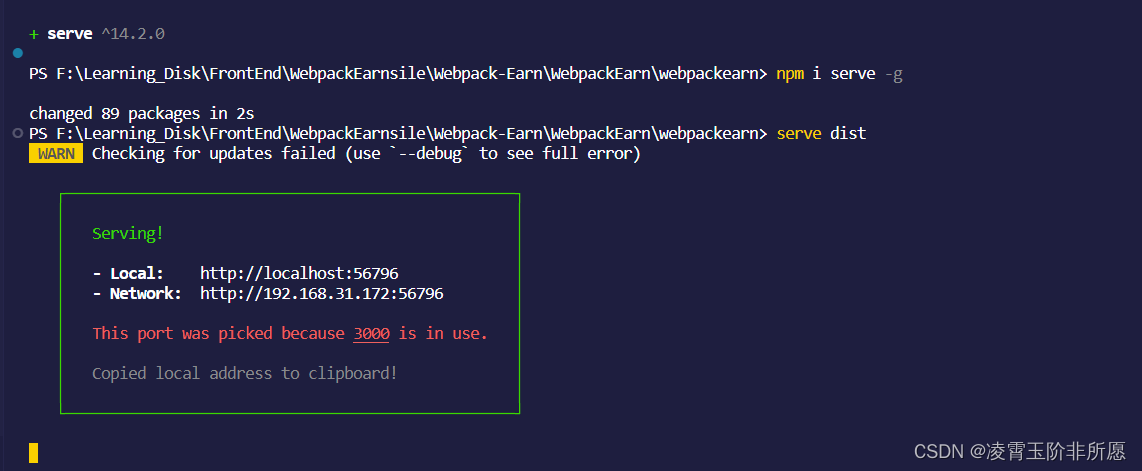
serve : 无法将“serve”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
1、在学习webpack打包的时候,需要 serve用来启动开发服务器来部署代码查看效果的。安装完之后运行出现以下错误: 2、使用命令查看安装目录: npm list -g我们已经安装过了 3、解决: 我们看到上图路径在:C:\Users\qiy…...
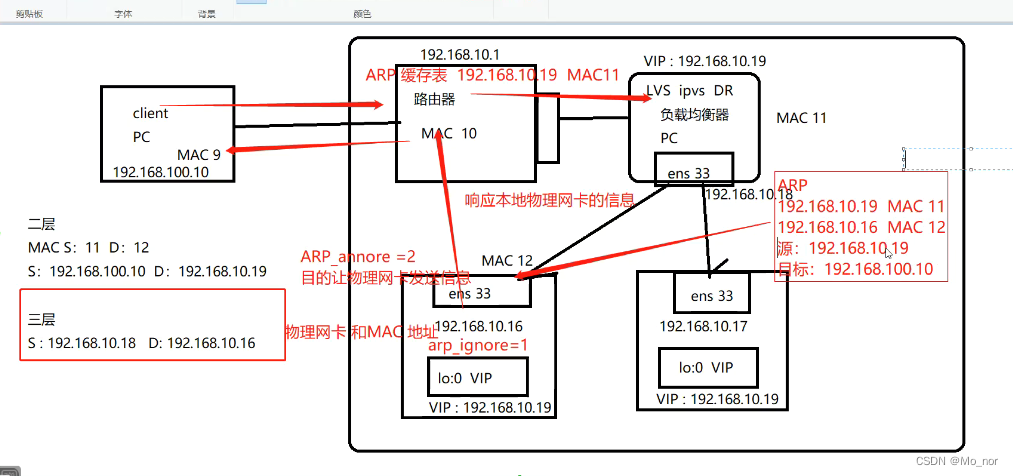
【LVS】2、部署LVS-DR群集
LVS-DR数据包的流向分析 1.客户端发送请求到负载均衡器,请求的数据报文到达内核空间; 2.负载均衡服务器和正式服务器在同一个网络中,数据通过二层数据链路层来传输; 3.内核空间判断数据包的目标IP是本机VIP,此时IP虚…...
)
设计模式 -- 单例模式(传统面向对象与JavaScript 的对比实现)
单例模式 – 传统面向对象与JavaScript 的对比实现 文章目录 单例模式 -- 传统面向对象与JavaScript 的对比实现传统的面向对象的实现定义实现思路初级实现缺点 透明的单例模式实现目的(实现效果)实现缺点 用代理实现单例模式优点 JavaScript 中的单例模…...
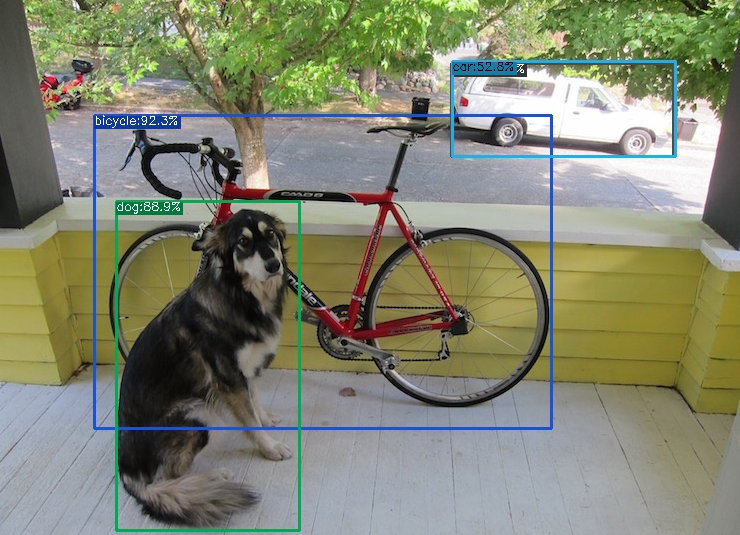
YOLOX算法调试记录
YOLOX是在YOLOv3基础上改进而来,具有与YOLOv5相媲美的性能,其模型结构如下: 由于博主只是要用YOLOX做对比试验,因此并不需要对模型的结构太过了解。 先前博主调试过YOLOv5,YOLOv7,YOLOv8,相比而言,YOLOX的环…...
基于小程序的汽车俱乐部系统的设计与实现(论文+源码)_kaic
目录 前 言 1 系统概述 1.1 系统主要功能 1.2 开发及运行环境 2 系统分析和总体设计 2.1 需求分析 2.2 可行性分析 2.3 设计目标 2.4 项目规划 2.5 系统开发语言简介 2.6 系统功能模块图 3 系统数据库设计 3.1 数据库开发工具简介 3.2 数据库需求分析 3.3 数据库…...

ProgrammingArduino物联网
programming_arduino_ed2 IO 延时闪灯 void setup() {pinMode(13, OUTPUT); }void loop() {digitalWrite(13, HIGH);delay(500);digitalWrite(13, LOW);delay(500); }// sketch 03-02 加入变量 int ledPin 13; int delayPeriod 500;void setup() {pinMode(ledPin, OUTPUT)…...

SSM框架的学习与应用(Spring + Spring MVC + MyBatis)-Java EE企业级应用开发学习记录(第一天)Mybatis的学习
SSM框架的学习与应用(Spring Spring MVC MyBatis)-Java EE企业级应用开发学习记录(第一天)Mybatis的学习 一、当前的主流框架介绍(这就是后期我会发出来的框架学习) Spring框架 Spring是一个开源框架,是为了解决企业应用程序开发复杂…...

Programming abstractions in C阅读笔记: p118-p122
《Programming Abstractions In C》学习第49天,p118-p122,总结如下: 一、技术总结 1.随机数 (1)seed p119,“The initial value–the value that is used to get the entire process start–is call a seed for the random ge…...

2023国赛数学建模思路 - 案例:ID3-决策树分类算法
文章目录 0 赛题思路1 算法介绍2 FP树表示法3 构建FP树4 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模…...
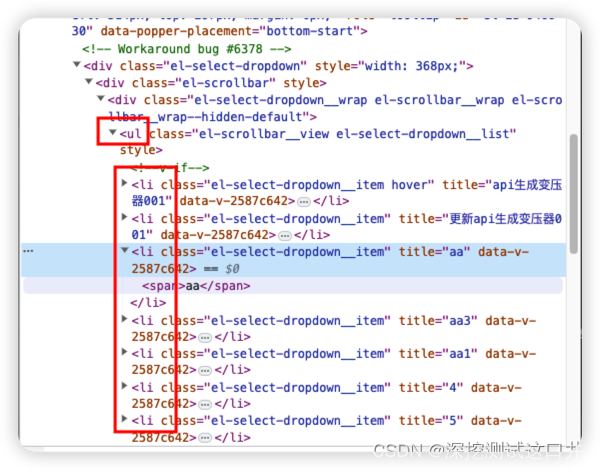
selenium 选定ul-li下拉选项中某个指定选项
场景:selenium的下拉选项是ul-li模式,选定某个指定的选项。 from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 显示等待def select_li(self, text, *ul_locator):"…...

回归预测 | MATLAB实现FA-SVM萤火虫算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现FA-SVM萤火虫算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现FA-SVM萤火虫算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本介绍…...
使用pytorch 的Transformer进行中英文翻译训练
下面是一个使用torch.nn.Transformer进行序列到序列(Sequence-to-Sequence)的机器翻译任务的示例代码,包括数据加载、模型搭建和训练过程。 import torch import torch.nn as nn from torch.nn import Transformer from torch.utils.data im…...

解决element的select组件创建新的选项可多选且opitions数据源中有数据的情况下,回车不能自动选中创建的问题
前言 最近开发项目使用element-plus库内的select组件,其中有提供一个创建新的选项的用法,但是发现一些小问题,在此记录 版本 “element-plus”: “^2.3.9”, “vue”: “^3.3.4”, 问题 1、在options数据源中无数据的时候,在输入框…...
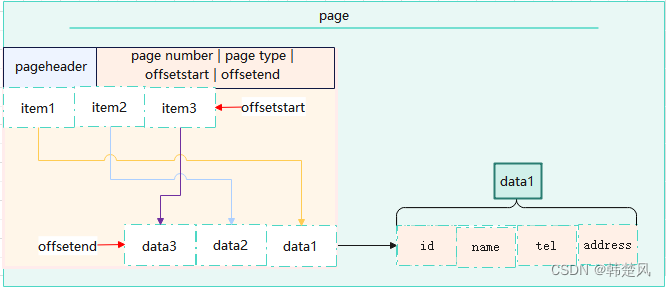
人工智能大模型加速数据库存储模型发展 行列混合存储下的破局
数据存储模型 专栏内容: postgresql内核源码分析手写数据库toadb并发编程toadb开源库 个人主页:我的主页 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. 概述 在数据库的发展过程中,关…...
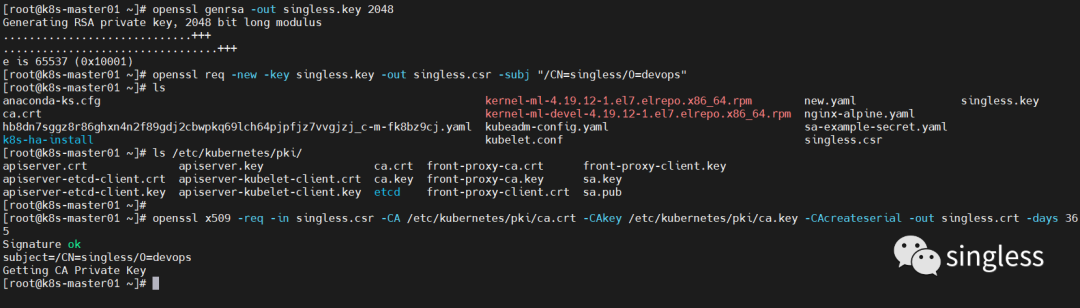
K8S用户管理体系介绍
1 K8S账户体系介绍 在k8s中,有两类用户,service account和user,我们可以通过创建role或clusterrole,再将账户和role或clusterrole进行绑定来给账号赋予权限,实现权限控制,两类账户的作用如下。 server acc…...
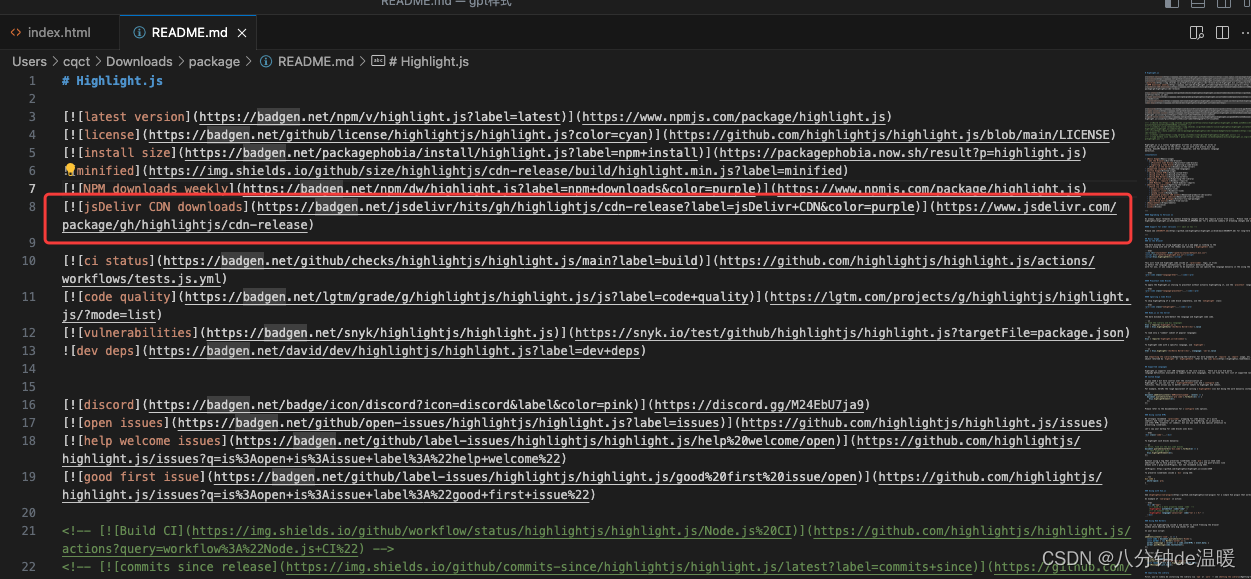
实现chatGPT 聊天样式
效果图 代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Chat Example</title&g…...

GPU流水线设计:提升深度学习计算效率的关键技术
1. GPU流水线设计基础概念现代GPU架构为深度学习工作负载提供了强大的并行计算能力,但传统的批量同步并行(BSP)执行模型存在资源利用率低下的问题。GPU流水线技术通过将计算图分解为多个阶段并在其间插入队列节点,实现了计算与通信的重叠执行。1.1 传统B…...

Vinkius Cloud扩展:在IDE中无缝管理MCP AI网关运行时
1. 项目概述:在IDE中管理你的AI网关运行时如果你正在开发或使用基于MCP(Model Context Protocol)的AI应用,那么你很可能已经体会过在多个AI客户端(比如Cursor、Claude Desktop、Windsurf)之间管理和维护后端…...

repo2txt:从Git仓库到结构化文本的自动化提取工具详解
1. 项目概述:从代码仓库到纯文本的自动化提取最近在整理个人技术笔记和搭建内部知识库时,我遇到了一个挺普遍但有点烦人的问题:如何把分散在多个Git仓库里的代码、文档和配置文件,快速、完整地转换成结构清晰的纯文本文件…...

告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境
告别硬件依赖:用Virtual ZPL Printer构建完整的标签打印测试环境 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh…...

FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程
FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程 第一次在ModelSim 10.6d环境下配置FPGA仿真库时,我花了整整三天时间排查各种路径错误和权限问题。直到现在,我还清楚地记得那个深夜——当仿…...

知识付费浪潮下的技术学习:是捷径,还是新的信息茧房?
当“知识”成为一种商品打开手机,各类技术公众号、知识星球、极客时间专栏、慕课网实战课、B站充电视频……铺天盖地的“测试开发进阶”“性能测试大师班”“自动化测试框架实战”正以9.9元、199元、3999元的价格被明码标价。作为一名软件测试工程师,我们…...

2026年5月PLC厂家:十大品牌专业评测解决工厂自动化选型难
摘要当制造业加速迈向智能化和柔性生产,PLC作为工业自动化的核心控制单元,其选型直接决定了产线效率、系统稳定性与长期运营成本。然而,面对众多品牌在技术路线、开放程度、生态兼容性上的显著分化,决策者常陷入“性能与成本如何平…...

Claude Code 多项目 API 配置管理实践
背景 Claude Code 的项目级配置文件 .claude/settings.json 中包含 API 提供商相关的环境变量。当同时维护多个项目,每个项目使用不同的 API 提供商(Anthropic 直连、OpenRouter 代理、自建转发等)时,每次切换项目都需要手动修改…...

基于大语言模型与RAG的AI小说生成:从技术原理到工程实践
1. 项目概述:当AI开始“阅读”与“创作”最近在内容创作和小说爱好者圈子里,一个名为“auto-novel”的项目引起了我的注意。简单来说,这是一个利用人工智能技术,实现从“阅读”现有小说到“模仿创作”新内容的自动化工具。它的核心…...

2026绍兴本地GEO优化公司实测:服务规范与效果验证全解析
引言随着AI搜索算法的不断迭代,绍兴本地企业对GEO(生成式引擎优化)服务的需求日益增长。为了帮助这些企业在选择GEO优化服务商时做出明智决策,本测评以客观、中立的态度,基于EEAT原则(经验、专业性、权威性…...