Redis缓存问题(穿透, 击穿, 雪崩, 污染, 一致性)
目录
1.什么是Redis缓存问题?
2.缓存穿透
3.缓存击穿
4.缓存雪崩
5.缓存污染(或满了)
5.1 最大缓存设置多大
5.2 缓存淘汰策略
6.数据库和缓存一致性
6.1 4种相关模式
6.2 方案:队列+重试机制
6.3 方案:异步更新缓存(基于订阅binlog的同步机制)
1.什么是Redis缓存问题?
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问Mysql等数据库。这样可以大大缓解数据库的压力。
当缓存库出现时,必须要考虑如下问题:
- 缓存穿透
- 缓存穿击
- 缓存雪崩
- 缓存污染(或者满了)
- 缓存和数据库一致性
2.缓存穿透
什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。

举个例子:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。也就是说这些请求最终都落到了数据库上,对数据库造成了巨大的压力。
有什么解决办法吗?
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
1)缓存无效 key
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下:SET key value EX 10086 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
如果用 Java 代码展示的话,差不多是下面这样的:
public Object getObjectInclNullById(Integer id) {// 从缓存中获取数据Object cacheValue = cache.get(id);// 缓存为空if (cacheValue == null) {// 从数据库中获取Object storageValue = storage.get(key);// 缓存空对象cache.set(key, storageValue);// 如果存储数据为空,需要设置一个过期时间(300秒)if (storageValue == null) {// 必须设置过期时间,否则有被攻击的风险cache.expire(key, 60 * 5);}return storageValue;}return cacheValue;
}
2)布隆过滤器
布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,是不是感觉布隆过滤器就是我们想要找的那个正确答案?。
具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
加入布隆过滤器之后的缓存处理流程图如下。

但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!
我们先来看一下,当一个元素加入布隆过滤器中的时候,会进行哪些操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
我们再来看一下,当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
然后,一定会出现这样一种情况:不同的字符串可能哈希出来的位置相同。 (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
3.缓存击穿
什么是缓存击穿?
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。

举个例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
有什么解决办法吗?
- 设置热点数据永不过期或者过期时间比较长。
- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
缓存穿透和缓存击穿有什么区别?
缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。
4.缓存雪崩
什么是缓存雪崩?
实际上,缓存雪崩描述的就是这样一个简单的场景:缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。

举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
有哪些解决办法?
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
针对热点缓存失效的情况:
- 设置不同的失效时间比如随机设置缓存的失效时间。
- 缓存永不失效(不太推荐,实用性太差)。
- 设置二级缓存。
缓存雪崩和缓存击穿有什么区别?
缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在与缓存中(通常是因为缓存中的那份数据已经过期)。
5.缓存污染(或满了)
缓存污染问题说的是缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。
缓存污染会随着数据的持续增加而逐渐显露,随着服务的不断运行,缓存中会存在大量的永远不会再次被访问的数据。缓存空间是有限的,如果缓存空间满了,再往缓存里写数据时就会有额外开销,影响Redis性能。这部分额外开销主要是指写的时候判断淘汰策略,根据淘汰策略去选择要淘汰的数据,然后进行删除操作。
5.1 最大缓存设置多大
系统的设计选择是一个权衡的过程:大容量缓存是能带来性能加速的收益,但是成本也会更高,而小容量缓存不一定就起不到加速访问的效果。一般来说,我会建议把缓存容量设置为总数据量的 15% 到 30%,兼顾访问性能和内存空间开销。
对于 Redis 来说,一旦确定了缓存最大容量,比如 4GB,你就可以使用下面这个命令来设定缓存的大小了:

不过,缓存被写满是不可避免的, 所以需要数据淘汰策略。
5.2 缓存淘汰策略
Redis共支持八种淘汰策略,分别是noeviction、volatile-random、volatile-ttl、volatile-lru、volatile-lfu、allkeys-lru、allkeys-random 和 allkeys-lfu 策略。
怎么理解呢?主要看分三类看:
- 不淘汰
- noeviction (v4.0后默认的)
- 对设置了过期时间的数据中进行淘汰
- 随机:volatile-random
- ttl:volatile-ttl
- lru:volatile-lru
- lfu:volatile-lfu
- 全部数据进行淘汰
- 随机:allkeys-random
- lru:allkeys-lru
- lfu:allkeys-lfu
具体分析如下:
1.noeviction
该策略是Redis的默认策略。在这种策略下,一旦缓存被写满了,再有写请求来时,Redis 不再提供服务,而是直接返回错误。这种策略不会淘汰数据,所以无法解决缓存污染问题。一般生产环境不建议使用。
其他七种规则都会根据自己相应的规则来选择数据进行删除操作。
2.volatile-random
这个算法比较简单,在设置了过期时间的键值对中,进行随机删除。因为是随机删除,无法把不再访问的数据筛选出来,所以可能依然会存在缓存污染现象,无法解决缓存污染问题。
3.volatile-ttl
这种算法判断淘汰数据时参考的指标比随机删除时多进行一步过期时间的排序。Redis在筛选需删除的数据时,越早过期的数据越优先被选择。
4.volatile-lru
LRU算法:LRU 算法的全称是 Least Recently Used,按照最近最少使用的原则来筛选数据。这种模式下会使用 LRU 算法筛选设置了过期时间的键值对。
详细LRU算法可看此博客:LRU缓存淘汰算法详解与实现_北~笙的博客-CSDN博客
Redis优化的LRU算法实现:
Redis会记录每个数据的最近一次被访问的时间戳。在Redis在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。通过随机读取待删除集合,可以让Redis不用维护一个巨大的链表,也不用操作链表,进而提升性能。
Redis 选出的数据个数 N,通过 配置参数 maxmemory-samples 进行配置。个数N越大,则候选集合越大,选择到的最久未被使用的就更准确,N越小,选择到最久未被使用的数据的概率也会随之减小。
5.volatile-lfu
会使用 LFU 算法选择设置了过期时间的键值对。
LFU 算法:LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。 Redis的LFU算法实现:
当 LFU 策略筛选数据时,Redis 会在候选集合中,根据数据 lru 字段的后 8bit 选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据 lru 字段的前 16bit 值大小,选择访问时间最久远的数据进行淘汰。
Redis 只使用了 8bit 记录数据的访问次数,而 8bit 记录的最大值是 255,这样在访问快速的情况下,如果每次被访问就将访问次数加一,很快某条数据就达到最大值255,可能很多数据都是255,那么退化成LRU算法了。所以Redis为了解决这个问题,实现了一个更优的计数规则,并可以通过配置项,来控制计数器增加的速度。
6.allkeys-lru
使用 LRU 算法在所有数据中进行筛选。具体LFU算法跟上述 volatile-lru 中介绍的一致,只是筛选的数据范围是全部缓存,这里就不在重复。
7.allkeys-random
从所有键值对中随机选择并删除数据。volatile-random 跟 allkeys-random算法一样,随机删除就无法解决缓存污染问题。
8.allkeys-lfu 使用 LFU 算法在所有数据中进行筛选。具体LFU算法跟上述 volatile-lfu 中介绍的一致,只是筛选的数据范围是全部缓存,这里就不在重复。
allkeys-lfu 策略是 Redis 4.0 后新增。
6.数据库和缓存一致性
- 问题来源
使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库:

读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
6.1 4种相关模式
更新缓存的的Design Pattern有四种:Cache aside Pattern, Read through, Write through, Write behind caching;
这里主要来看最常用的Cache Aside Pattern, 总结来说就是
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
其具体逻辑如下:
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。

注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
6.2 方案:队列+重试机制
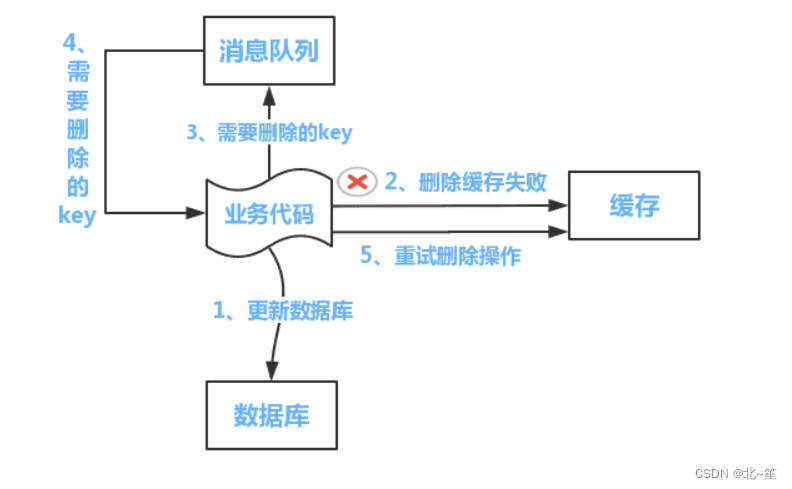
流程如下所示
- 更新数据库数据;
- 缓存因为种种问题删除失败
- 将需要删除的key发送至消息队列
- 自己消费消息,获得需要删除的key
- 继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
6.3 方案:异步更新缓存(基于订阅binlog的同步机制)
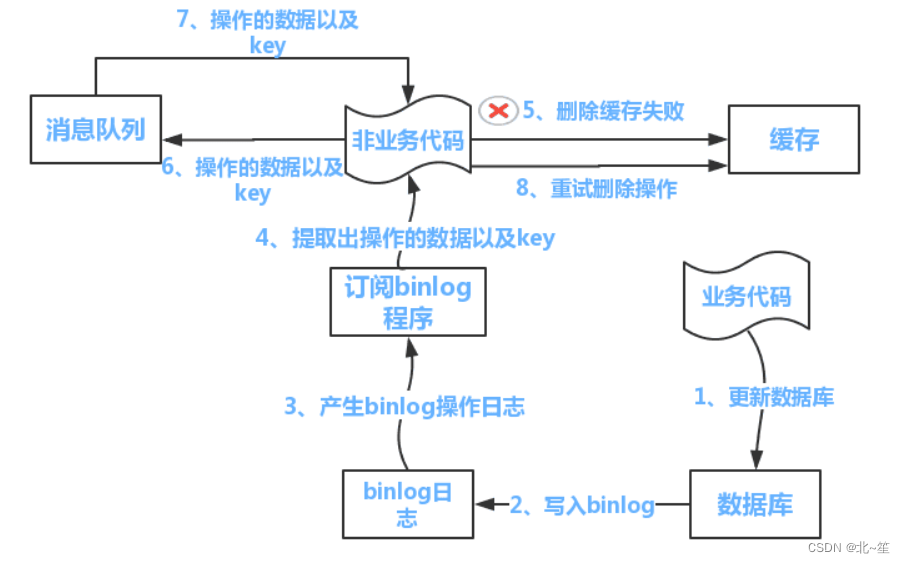
整体思路:
MySQL binlog增量订阅消费+消息队列+增量数据更新到redis
1)读Redis:热数据基本都在Redis
2)写MySQL: 增删改都是操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
Redis更新
1)数据操作主要分为两大块:
- 一个是全量(将全部数据一次写入到redis)
- 一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delate变更数据。
2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
相关文章:
Redis缓存问题(穿透, 击穿, 雪崩, 污染, 一致性)
目录 1.什么是Redis缓存问题? 2.缓存穿透 3.缓存击穿 4.缓存雪崩 5.缓存污染(或满了) 5.1 最大缓存设置多大 5.2 缓存淘汰策略 6.数据库和缓存一致性 6.1 4种相关模式 6.2 方案:队列重试机制 6.3 方案:异步更新缓…...

网络时代拟态环境的复杂化
信息在网络上的制作、编码、传播机制和传统媒介有本质的区别,即传播者和 受传者的角色交叉,而且互联网本身可看作另一个有别于现实环境的虚拟世界,因 此网络媒介所营造出的拟态环境在一定程度上独立于传统大众传播的拟态环境。 一个是传统…...

湘潭大学 湘大 XTU OJ 1055 整数分类 题解(非常详细)
链接 整数分类 题目 Description 按照下面方法对整数x进行分类:如果x是一个个位数,则x属于x类;否则将x的各位上的数码累加,得到一个新的x,依次迭代,可以得到x的所属类。比如说24,246&#…...

什么是视频的编码和解码
这段描述中,视频解码能力和视频编码能力指的是不同的处理过程。视频解码是将压缩过的视频数据解开并还原为可播放的视频流,而视频编码是将原始视频数据压缩成更小的尺寸,以减少存储空间和传输带宽。在这个上下文中,解码能力和编码…...

LeetCode 2681. Power of Heroes【排序,数学,贡献法】2060
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
AVL树的讲解
算法拾遗三十八AVL树 AVL树AVL树平衡性AVL树加入节点AVL删除节点AVL树代码 AVL树 AVL树具有最严苛的平衡性,(增、删、改、查)时间复杂度为O(logN),AVL树任何一个节点,左树的高度和右树的高度差…...

Unity 之 Input类
文章目录 总述具体介绍 总述 Input 类是 Unity 中用于处理用户输入的重要工具,它允许您获取来自键盘、鼠标、触摸屏和控制器等设备的输入数据。通过 Input 类,您可以轻松地检测按键、鼠标点击、鼠标移动、触摸、控制器按钮等用户输入事件。以下是关于 I…...
亚信科技AntDB数据库连年入选《中国DBMS市场指南》代表厂商
近日,全球权威ICT研究与顾问咨询公司Gartner发布了2023年《Market Guide for DBMS, China》(即“中国DBMS市场指南”),该指南从市场份额、技术创新、研发投入等维度对DBMS供应商进行了调研。亚信科技是领先的数智化全栈能力提供商…...
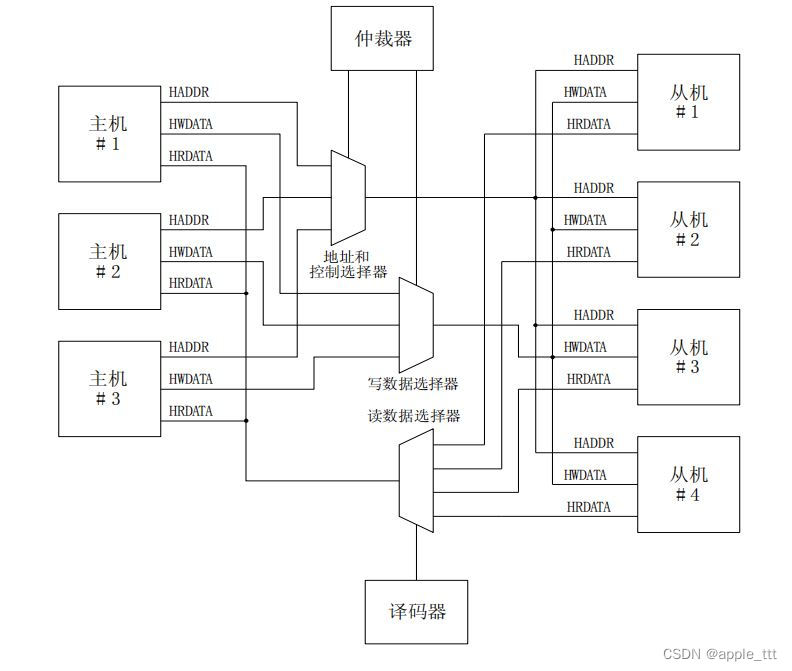
AMBA总线协议(3)——AHB(一)
目录 一、前言 二、什么是AHB总线 1、概述 2、一个典型的基于AHB总线的微处理器架构 3、基本的 AHB 传送特性 三、AMBA AHB总线互联 四、小结 一、前言 在之前的文章中我们初步的了解了一下AMBA总线中AHB,APB,AXI的信号线及其功能,从本文开始我们…...

Git commit与pull的先后顺序
Git commit与pull的先后顺序_git先pull再commit_Mordor Java Girl的博客-CSDN博客 编辑yucoang2020.04.21 回复 28 先pull再commit的话, 你的commit也就不再纯粹了. 这一个commit不再是"你所编辑的xxx功能, 而是"别人所编辑的你所编辑的xxx". 我认为提交历…...
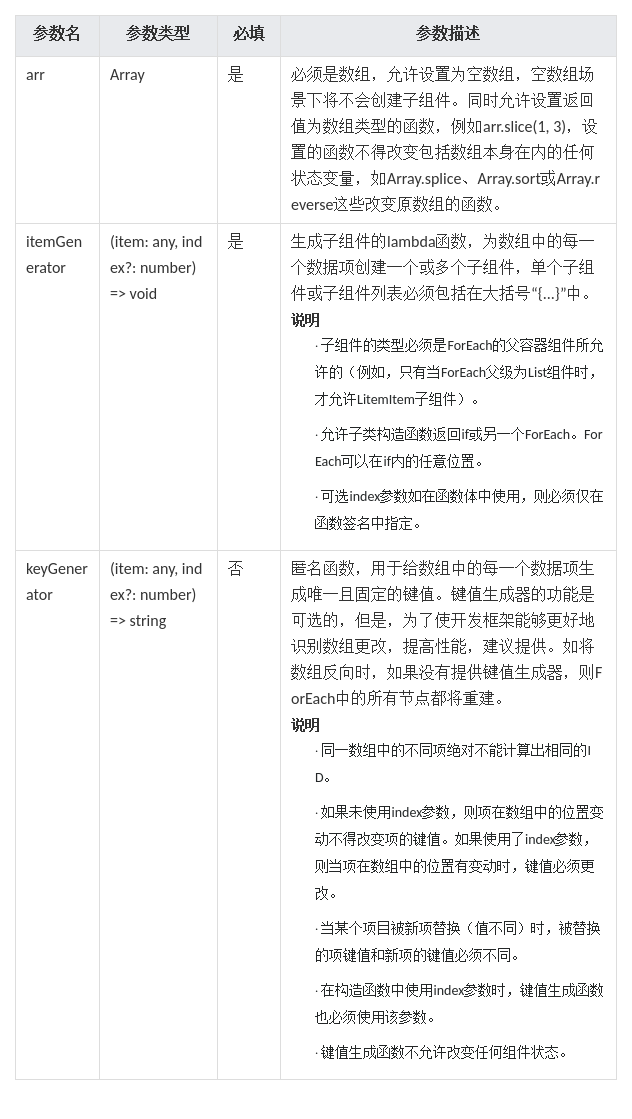
HarmonyOS/OpenHarmony应用开发-ArkTS语言渲染控制ForEach循环渲染
ForEach基于数组类型数据执行循环渲染。说明,从API version 9开始,该接口支持在ArkTS卡片中使用。 一、接口描述 ForEach(arr: any[], itemGenerator: (item: any, index?: number) > void,keyGenerator?: (item: any, index?: number) > stri…...

Powered by Paraverse | 平行云助力彼真科技打造演出“新物种”
01 怎么看待虚拟演出 彼真科技 我们怎么看待虚拟演出? 虚拟演出给音乐人或者音乐行业带来了哪些新的机会?通过呈现一场高标准的虚拟演出,我们的能力延伸点在哪里? 先说一下我们认知里的虚拟演出的本质: 音乐演出是一…...
企微配置回调服务
1、企微配置可信域名 2、企微获取成员userID 3、企微获取用户敏感数据 4、企微配置回调服务 文章目录 一、简介1、概述2、相关文档地址 二、企微配置消息服务器1、配置消息接收参数2、参数解析3、参数拼接规则 三、代码编写—使用已有库1、代码下载2、代码修改3、服务代码编写 …...

机器人远程控制软件设计
机器人远程控制软件设计 That’s all....
:React中的虚拟DOM是什么?)
面试题-React(二):React中的虚拟DOM是什么?
一、什么是虚拟DOM? 虚拟DOM是React的核心概念之一,它是一个轻量级的JavaScript对象树,用于表示真实DOM的状态。在React中,当数据发生变化时,首先会在虚拟DOM上执行DOM更新,而不是直接操作真实DOM。然后&a…...

分布式链路追踪——Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
要解决的问题 如何记录请求经过多个分布式服务的信息,以便分析问题所在?如何保证这些信息得到完整的追踪?如何尽可能不影响服务性能? 追踪 当用户请求到达前端A,将会发送rpc请求给中间层B、C;B可以立刻作…...

【IEEE会议】第二届IEEE云计算、大数据应用与软件工程国际学术会议 (CBASE2023)
第二届IEEE云计算、大数据应用与软件工程国际学术会议 (CBASE2023) 随着大数据时代的到来,对数据获取的随时性和对计算的需求也在逐渐增长。为推动大数据时代的云计算与软件工程的发展,促进该领域学术交流,在CBASE 2022成功举办的…...

Streamlit项目:基于讯飞星火认知大模型开发Web智能对话应用
文章目录 1 前言2 API获取3 官方文档的调用代码4 Streamlit 网页的搭建4.1 代码及效果展示4.2 Streamlit相关知识点 5 结语 1 前言 科大讯飞公司于2023年8月15日发布了讯飞认知大模型V2.0,这是一款集跨领域知识和语言理解能力于一体的新一代认知智能大模型。前日&a…...
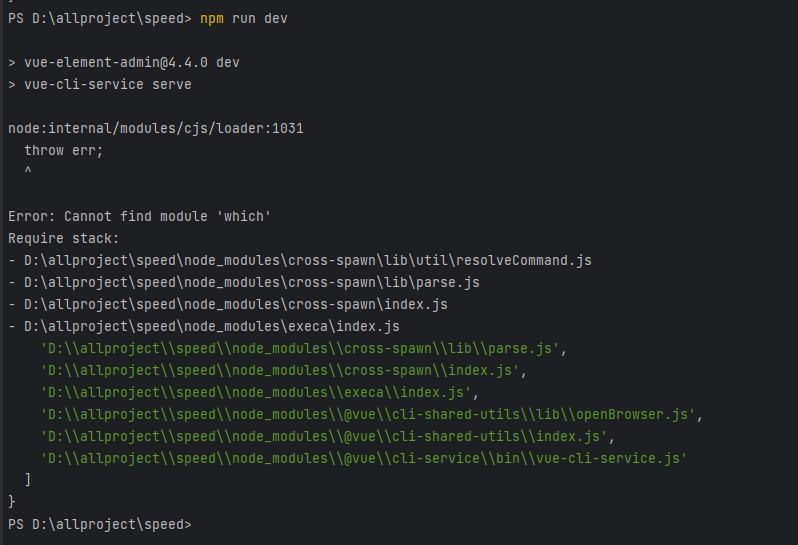
[Vue]解决npm run dev报错node:internal/modules/cjs/loader:1031 throw err;
解决: 有2中方法,建议先尝试第一种,不行再第二种 第一种: 重新安装依赖环境 删除项目的node_modules文件夹,重新执行 # 安装依赖环境 npm install# 运行 npm run dev 我只用了第一种方法就可以了 ,第二种方法从别的博主那看到…...
nginx反向代理后实现nginx和apache两种web服务器能够记录客户端的真实IP地址
一.构建环境 二.配置反向代理 1.基于源码安装的nginx环境下修改nginx.conf(设备1) 2.通过windows powershell进行修改hosts文件并测试 3.设备2和设备3上查看日志,可以看到访问来源都是代理服务器(2.190)而不是真实…...
的三种手动确认模式实战:basicAck、basicNack、basicReject到底怎么选?)
SpringBoot项目里RabbitMQ消息确认(ACK)的三种手动确认模式实战:basicAck、basicNack、basicReject到底怎么选?
SpringBoot项目中RabbitMQ消息确认模式的深度实战指南 1. 消息确认机制的核心价值与业务场景 在分布式系统中,消息队列承担着解耦生产者和消费者的重要职责。RabbitMQ作为最流行的消息中间件之一,其消息确认机制(ACK)是确保数据…...

STM32模拟I2C驱动TCS34725实现环境光与颜色识别
1. 环境光与颜色识别的硬件搭档 当我们需要让设备感知周围环境的光线强弱,或者识别物体的具体颜色时,TCS34725这颗传感器绝对是性价比之选。它不仅能测量环境光强度,还能通过RGB三原色的比例来判断颜色,这在智能家居和工业检测中特…...

如何5分钟掌握Jump:从安装到高效使用的完整教程
如何5分钟掌握Jump:从安装到高效使用的完整教程 【免费下载链接】jump Jump helps you navigate faster by learning your habits. ✌️ 项目地址: https://gitcode.com/gh_mirrors/ju/jump Jump是一款能够通过学习用户习惯来加速导航的命令行工具࿰…...
)
别再乱改网段了!深入理解 VMware NAT 与桥接模式:根据你的真实需求选择网络配置(附场景对比)
深度解析VMware网络模式:NAT与桥接的实战选择指南 虚拟化技术已成为现代开发与测试环境的核心基础设施,而网络配置的选择往往决定了整个工作流的顺畅程度。许多用户在初次接触VMware Workstation时,面对NAT、桥接等模式常感到困惑——究竟哪种…...

终极图片去重指南:用AntiDupl.NET轻松释放存储空间,告别重复图片困扰
终极图片去重指南:用AntiDupl.NET轻松释放存储空间,告别重复图片困扰 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾为电脑里堆积如山…...

博彩业税收支持STEM教育的风险与可持续筹资方案探讨
1. 项目概述:当教育经费与博彩业挂钩作为一名长期关注科技教育领域发展的从业者,我时常需要追踪全球范围内STEM(科学、技术、工程和数学)教育的政策与资金动向。最近在梳理历史资料时,一篇2012年的旧文再次引起了我的注…...

通过API Key管理与审计日志功能增强企业AI应用安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过API Key管理与审计日志功能增强企业AI应用安全 在将大模型能力集成到企业业务流程时,安全与合规是首要考量。直接使…...

MIKE IO 终极指南:Python高效处理MIKE水文数据的完整教程
MIKE IO 终极指南:Python高效处理MIKE水文数据的完整教程 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio MIKE IO 是DHI集团推出的专业Python开源库…...

HiveWE:现代魔兽争霸III地图编辑器终极指南
HiveWE:现代魔兽争霸III地图编辑器终极指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版地图编辑器的缓慢加载和复杂操作而烦恼吗?HiveWE作为一款专注于速度…...

Axure中文汉化终极指南:3分钟搞定英文界面,让原型设计更顺手
Axure中文汉化终极指南:3分钟搞定英文界面,让原型设计更顺手 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...