YOLOv5、YOLOv8改进:SOCA注意力机制
目录
简介
2.YOLOv5使用SOCA注意力机制
2.1增加以下SOCA.yaml文件
2.2common.py配置
2.3yolo.py配置
简介
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它。例如,人们在阅读时,通常只有少量要被读取的词会被关注和处理。综上,注意力机制主要有两个方面:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。这几年有关attention的论文与日俱增,下图就显示了在包括CVPR、ICCV、ECCV、NeurIPS、ICML和ICLR在内的顶级会议中,与attention相关的论文数量的增加量。下面我将会分享Yolov5 v6.1如何添加注意力机制;
今天介绍一篇CPVR19的Oral文章,用二阶注意力网络来进行单图像超分辨率。作者来自清华深研院,鹏城实验室,香港理工大学以及阿里巴巴达摩院。
文章地址
github code
文章的出发点:现存的基于CNN的模型仍然面临一些限制:
- 大多数基于CNN的SR方法没有充分利用原始LR图像的信息,导致相当低的性能
- 大多数CNN-based models主要专注于设计更深或是更宽的网络,以学习更有判别力的高层特征,却很少发掘层间特征的内在相关性,从而妨碍了CNN的表达能
文章的大体思路:提出了一个深的二阶注意力网络SAN,以获得更好的特征表达和特征相关性学习。特别地,提出了一个二阶通道注意力机制SOCA来进行相关性学习。同时,提出了一个non-locally增强残差组NLRG来捕获长距离空间内容信息。
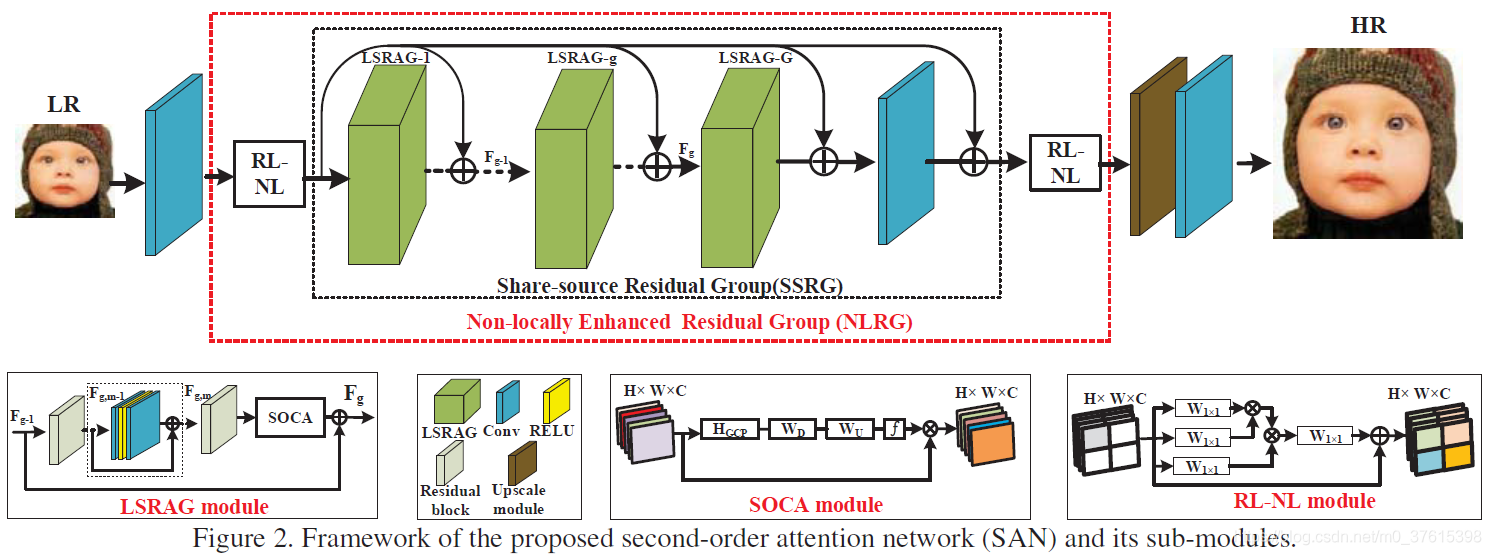
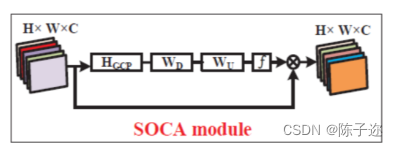
在LSRAG的末端,有一个SOCA模块,即二阶通道注意力机制。
相比于SENet里面的通道attention使用的是一阶统计信息(通过全局平均池化),本SOCA探索了二阶特征统计的attention
2.YOLOv5使用SOCA注意力机制
2.1增加以下SOCA.yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, SOCA, [1024]],[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]2.2common.py配置
./models/common.py文件增加以下模块
import numpy as np
import torch
from torch import nn
from torch.nn import initfrom torch.autograd import Functionclass Covpool(Function):@staticmethoddef forward(ctx, input):x = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]h = x.data.shape[2]w = x.data.shape[3]M = h*wx = x.reshape(batchSize,dim,M)I_hat = (-1./M/M)*torch.ones(M,M,device = x.device) + (1./M)*torch.eye(M,M,device = x.device)I_hat = I_hat.view(1,M,M).repeat(batchSize,1,1).type(x.dtype)y = x.bmm(I_hat).bmm(x.transpose(1,2))ctx.save_for_backward(input,I_hat)return y@staticmethoddef backward(ctx, grad_output):input,I_hat = ctx.saved_tensorsx = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]h = x.data.shape[2]w = x.data.shape[3]M = h*wx = x.reshape(batchSize,dim,M)grad_input = grad_output + grad_output.transpose(1,2)grad_input = grad_input.bmm(x).bmm(I_hat)grad_input = grad_input.reshape(batchSize,dim,h,w)return grad_inputclass Sqrtm(Function):@staticmethoddef forward(ctx, input, iterN):x = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]dtype = x.dtypeI3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)normA = (1.0/3.0)*x.mul(I3).sum(dim=1).sum(dim=1)A = x.div(normA.view(batchSize,1,1).expand_as(x))Y = torch.zeros(batchSize, iterN, dim, dim, requires_grad = False, device = x.device)Z = torch.eye(dim,dim,device = x.device).view(1,dim,dim).repeat(batchSize,iterN,1,1)if iterN < 2:ZY = 0.5*(I3 - A)Y[:,0,:,:] = A.bmm(ZY)else:ZY = 0.5*(I3 - A)Y[:,0,:,:] = A.bmm(ZY)Z[:,0,:,:] = ZYfor i in range(1, iterN-1):ZY = 0.5*(I3 - Z[:,i-1,:,:].bmm(Y[:,i-1,:,:]))Y[:,i,:,:] = Y[:,i-1,:,:].bmm(ZY)Z[:,i,:,:] = ZY.bmm(Z[:,i-1,:,:])ZY = 0.5*Y[:,iterN-2,:,:].bmm(I3 - Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]))y = ZY*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)ctx.save_for_backward(input, A, ZY, normA, Y, Z)ctx.iterN = iterNreturn y@staticmethoddef backward(ctx, grad_output):input, A, ZY, normA, Y, Z = ctx.saved_tensorsiterN = ctx.iterNx = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]dtype = x.dtypeder_postCom = grad_output*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)der_postComAux = (grad_output*ZY).sum(dim=1).sum(dim=1).div(2*torch.sqrt(normA))I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)if iterN < 2:der_NSiter = 0.5*(der_postCom.bmm(I3 - A) - A.bmm(der_sacleTrace))else:dldY = 0.5*(der_postCom.bmm(I3 - Y[:,iterN-2,:,:].bmm(Z[:,iterN-2,:,:])) -Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]).bmm(der_postCom))dldZ = -0.5*Y[:,iterN-2,:,:].bmm(der_postCom).bmm(Y[:,iterN-2,:,:])for i in range(iterN-3, -1, -1):YZ = I3 - Y[:,i,:,:].bmm(Z[:,i,:,:])ZY = Z[:,i,:,:].bmm(Y[:,i,:,:])dldY_ = 0.5*(dldY.bmm(YZ) - Z[:,i,:,:].bmm(dldZ).bmm(Z[:,i,:,:]) - ZY.bmm(dldY))dldZ_ = 0.5*(YZ.bmm(dldZ) - Y[:,i,:,:].bmm(dldY).bmm(Y[:,i,:,:]) -dldZ.bmm(ZY))dldY = dldY_dldZ = dldZ_der_NSiter = 0.5*(dldY.bmm(I3 - A) - dldZ - A.bmm(dldY))grad_input = der_NSiter.div(normA.view(batchSize,1,1).expand_as(x))grad_aux = der_NSiter.mul(x).sum(dim=1).sum(dim=1)for i in range(batchSize):grad_input[i,:,:] += (der_postComAux[i] \- grad_aux[i] / (normA[i] * normA[i])) \*torch.ones(dim,device = x.device).diag()return grad_input, Nonedef CovpoolLayer(var):return Covpool.apply(var)def SqrtmLayer(var, iterN):return Sqrtm.apply(var, iterN)class SOCA(nn.Module):# second-order Channel attentiondef __init__(self, channel, reduction=8):super(SOCA, self).__init__()self.max_pool = nn.MaxPool2d(kernel_size=2)self.conv_du = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),nn.Sigmoid())def forward(self, x):batch_size, C, h, w = x.shape # x: NxCxHxWN = int(h * w)min_h = min(h, w)h1 = 1000w1 = 1000if h < h1 and w < w1:x_sub = xelif h < h1 and w > w1:W = (w - w1) // 2x_sub = x[:, :, :, W:(W + w1)]elif w < w1 and h > h1:H = (h - h1) // 2x_sub = x[:, :, H:H + h1, :]else:H = (h - h1) // 2W = (w - w1) // 2x_sub = x[:, :, H:(H + h1), W:(W + w1)]cov_mat = CovpoolLayer(x_sub) # Global Covariance pooling layercov_mat_sqrt = SqrtmLayer(cov_mat,5) # Matrix square root layer( including pre-norm,Newton-Schulz iter. and post-com. with 5 iteration)cov_mat_sum = torch.mean(cov_mat_sqrt,1)cov_mat_sum = cov_mat_sum.view(batch_size,C,1,1)y_cov = self.conv_du(cov_mat_sum)return y_cov*x2.3yolo.py配置
在 models/yolo.py文件夹下
- 定位到parse_model函数中
- 对应位置 下方只需要新增以下代码
elif m is SOCA:c1, c2 = ch[f], args[0]if c2 != no:c2 = make_divisible(c2 * gw, 8)args = [c1, *args[1:]]
修改完成
如有遇到不清楚的地方欢迎评论区留言
相关文章:
YOLOv5、YOLOv8改进:SOCA注意力机制
目录 简介 2.YOLOv5使用SOCA注意力机制 2.1增加以下SOCA.yaml文件 2.2common.py配置 2.3yolo.py配置 简介 注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有…...

机器人的运动范围
声明 该系列文章仅仅展示个人的解题思路和分析过程,并非一定是优质题解,重要的是通过分析和解决问题能让我们逐渐熟练和成长,从新手到大佬离不开一个磨练的过程,加油! 原题链接 机器人的运动范围https://leetcode.c…...
学习笔记|基于Delay实现的LED闪烁|模块化编程|SOS求救灯光|STC32G单片机视频开发教程(冲哥)|第六集(下):实现LED闪烁
文章目录 2 函数的使用1.函数定义(需要带类型)2.函数声明(需要带类型)3.函数调用 3 新建文件,使用模块化编程新建xxx.c和xxx.h文件xxx.h格式:调用头文件验证代码调用:完整的文件结构如下&#x…...
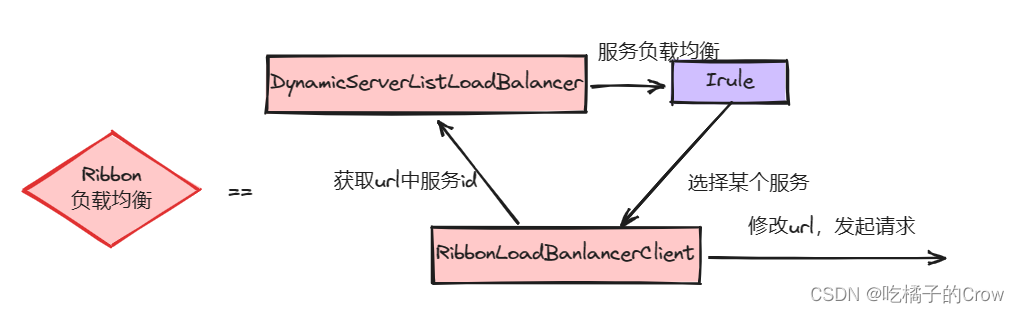
微服务-Ribbon(负载均衡)
负载均衡的面对多个相同的服务的时候,我们选择一定的策略去选择一个服务进行 负载均衡流程 Ribbon结构组成 负载均衡策略 RoundRobinRule:简单的轮询服务列表来选择服务器AvailabilityFilteringRule 对两种情况服务器进行忽略: 1.在默认情…...
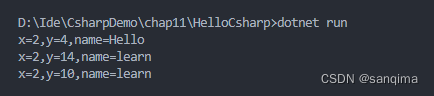
解决C#报“MSB3088 未能读取状态文件*.csprojAssemblyReference.cache“问题
今天在使用vscode软件C#插件,编译.cs文件时,发现如下warning: 图(1) C#报cache没有更新 出现该warning的原因:当前.cs文件修改了,但是其缓存文件*.csprojAssemblyReference.cache没有更新,需要重新清理一下工程&#x…...
GeoScene Pro在地图制图当中的应用
任何地理信息系统建设过程中,背景地图的展示效果对整个系统功能的实现没有直接影响;但是地图的好看与否,会间接的决定着整个项目的高度。 一幅精美的地图不仅能令人赏心悦目、眼前一亮,更能将人吸引到你的系统中,更愿意…...

国标混凝土结构设计规范的混凝土本构关系——基于python代码生成
文章目录 0. 背景1. 代码2. 结果测试 0. 背景 最近在梳理混凝土塔筒的计算指南,在求解弯矩曲率关系以及MN相关曲线时,需要混凝土的本构关系作为输入条件。 1. 代码 这段代码还是比较简单的。不过需要注意的是,我把受拉和受压两种状态统一了…...
)
系统架构设计-架构师之路(八)
软件架构概述 需求分析到软件设计之间的过渡过程就是软件架构。 需求分析人员整理成文档,但是开发人员对业务并不熟悉,这时候中间就需要一个即懂软件又懂业务的人,架构师来把文档整理成系统里的各个开发模块,布置开发任务。 软…...

【SA8295P 源码分析】25 - QNX Ethernet MAC 驱动 之 emac_isr_thread_handler 中断处理函数源码分析
【SA8295P 源码分析】25 - QNX Ethernet MAC 驱动 之 emac_isr_thread_handler 中断处理函数源码分析 一、emac 中断上半部:emac_isr()二、emac 中断下半部:emac_isr_thread_handler()2.1 emac 中断下半部:emac_isr_sw()系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章…...

函数栈帧的创建与销毁
目录 引言 基础知识 内存模型 寄存器的种类与功能 常用的汇编指令 函数栈帧创建与销毁 main()函数栈帧的创建 NO1. NO2. NO3. NO4. NO5. NO6. main()函数栈帧变量的创建 调用Add()函数栈帧的预备工作——传参 NO1. NO2. NO3. Add()函数栈帧的创建 …...

工业安全生产平台在面粉行业的应用分享
一、背景介绍 面粉行业是一个传统的工业行业,安全生产问题一直备受关注。然而,由于生产过程中存在的各种安全隐患和风险,如粉尘爆炸、机械伤害等,使得面粉行业的安全生产形势依然严峻。为了解决这一问题,工业安全生产…...
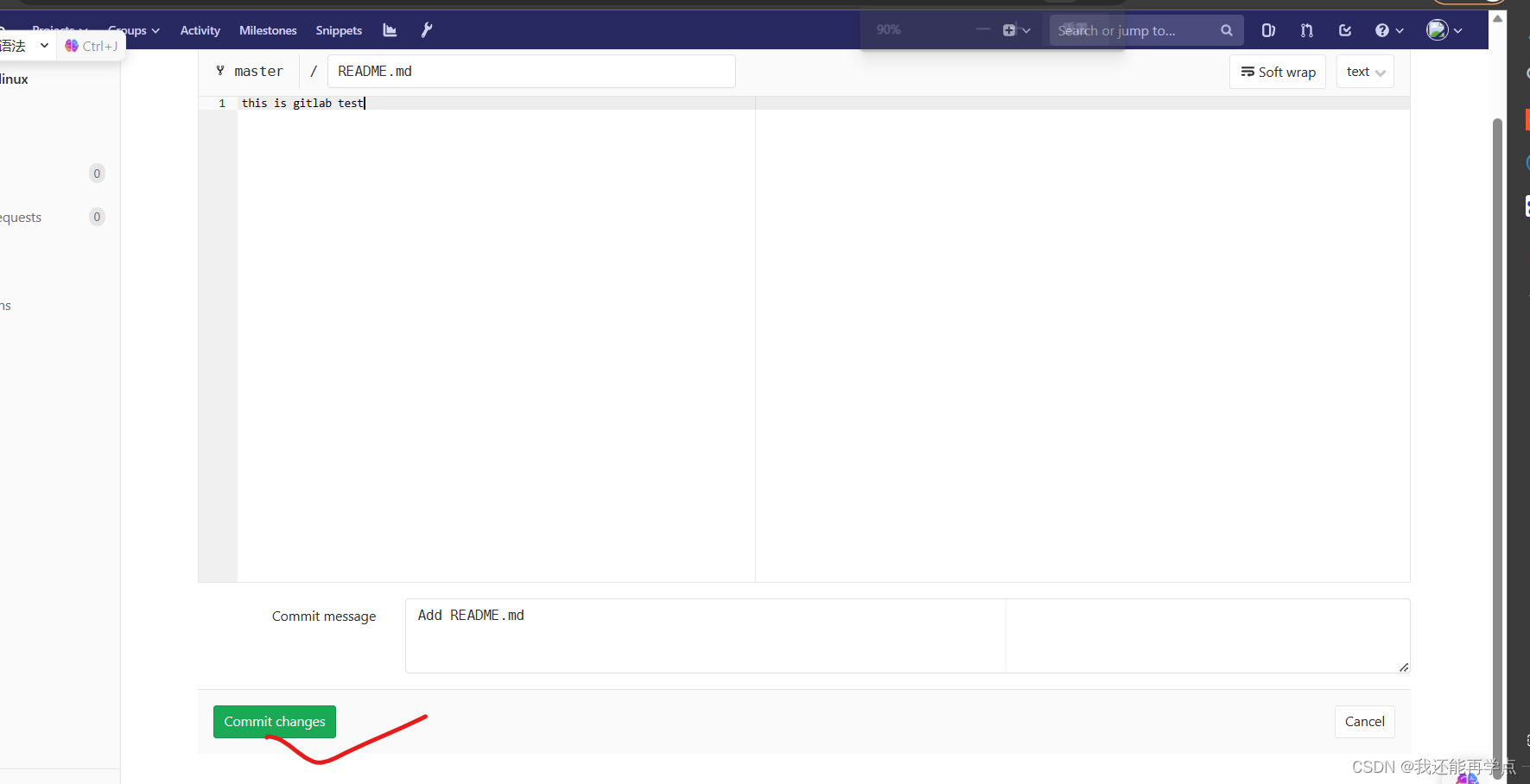
Gitlab服务部署及应用
目录 Gitlab简介 Gitlab工作原理 Gitlab服务构成 Gitlab环境部署 安装依赖包 启动postfix,并设置开机自启 设置防火墙 下载安装gitlab rpm包 修改配置文件/etc/gitlab/gitlab.rb,生产环境下可以根据需求修改 重新加载配置文件 浏览器登录Gitlab输…...
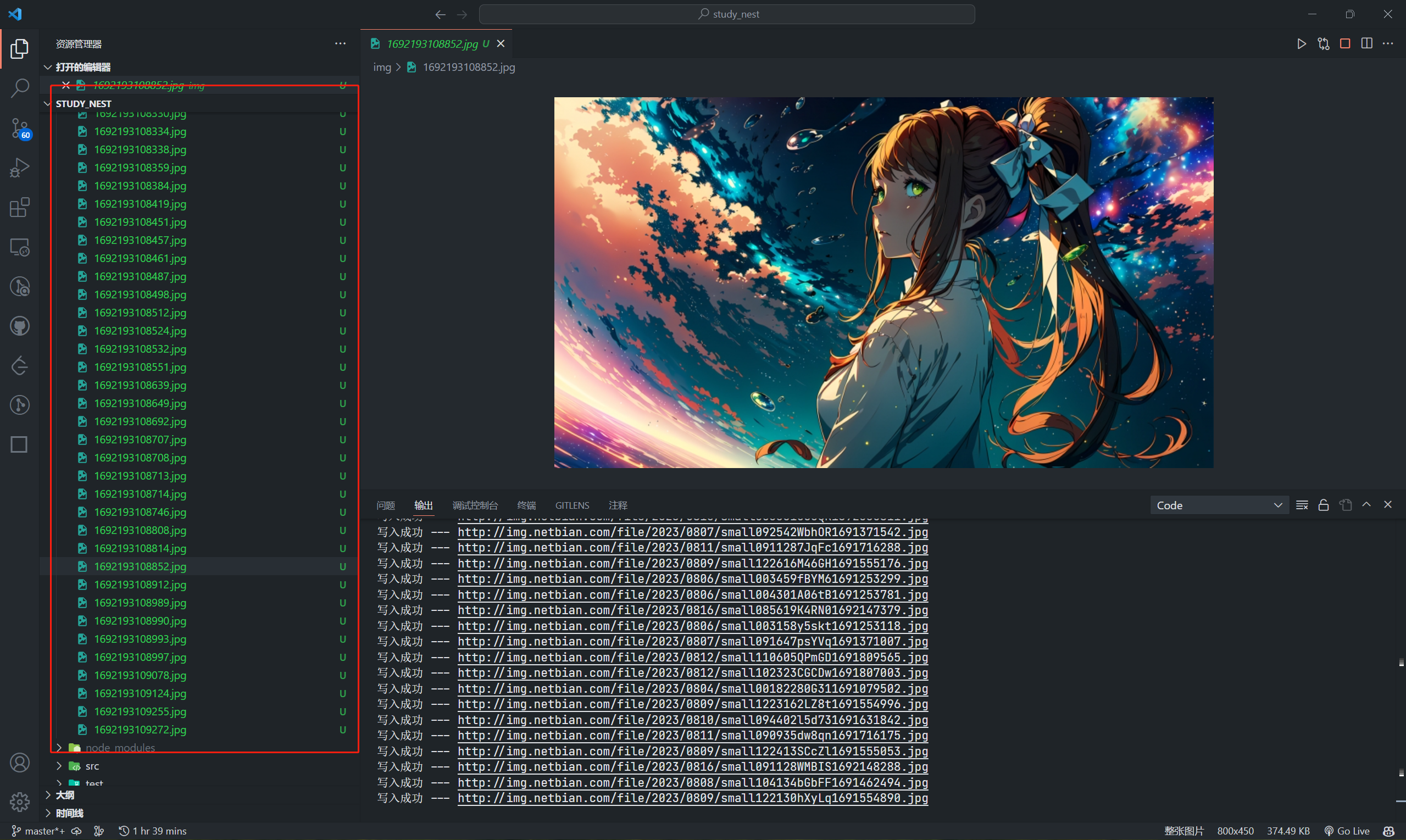
【nodejs】用Node.js实现简单的壁纸网站爬虫
1. 简介 在这个博客中,我们将学习如何使用Node.js编写一个简单的爬虫来从壁纸网站获取图片并将其下载到本地。我们将使用Axios和Cheerio库来处理HTTP请求和HTML解析。 2. 设置项目 首先,确保你已经安装了Node.js环境。然后,我们将创建一个…...

xlsx xlsx-style file-saver 导出json数据到excel文件并设置标题字体加粗
xlsx:用于处理Excel文件。xlsx-style:用于添加样式到Excel文件中。file-saver:用于将生成的Excel文件保存到用户的计算机上 npm install xlsx xlsx-style file-saver// 导入所需库 const XLSX require(xlsx); const XLSXStyle require(xls…...

Win11游戏高性能模式怎么开
1、点击桌面任务栏上的“开始”图标,在打开的应用中,点击“设置”; 2、“设置”窗口,左侧找到“游戏”选项,在右侧的选项中,找到并点击打开“游戏模式”; 3、打开的“游戏模式”中,找…...
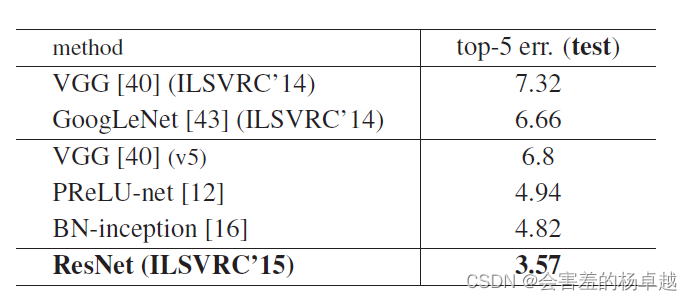
深度学习最强奠基作ResNet《Deep Residual Learning for Image Recognition》论文解读(上篇)
1、摘要 1.1 第一段 作者说深度神经网络是非常难以训练的,我们使用了一个残差学习框架的网络来使得训练非常深的网络比之前容易得很多。 把层作为一个残差学习函数相对于层输入的一个方法,而不是说跟之前一样的学习unreferenced functions 作者提供了…...

第22次CCF计算机软件能力认证
第一题:灰度直方图 解题思路: 哈希表即可 #include<iostream> #include<cstring>using namespace std;const int N 610; int a[N]; int n , m , l;int main() {memset(a , 0 , sizeof a);cin >> n >> m >> l;for(int …...
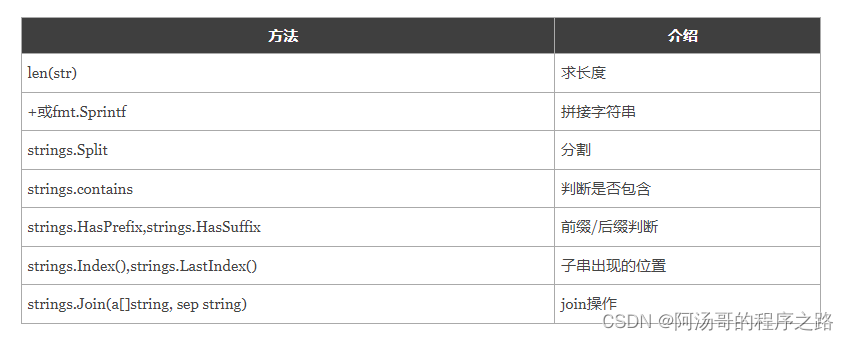
Go语言基础之基本数据类型
Go语言中有丰富的数据类型,除了基本的整型、浮点型、布尔型、字符串外,还有数组、切片、结构体、函数、map、通道(channel)等。Go 语言的基本类型和其他语言大同小异。 基本数据类型 整型 整型分为以下两个大类: 按…...

Linux Tracing Technologies
目录 1. Linux Tracing Technologies 1. Linux Tracing Technologies Linux Tracing TechnologieseBPFXDPDPDK...

iOS自定义下拉刷新控件
自定义下拉刷新控件 概述 用了很多的别人的下拉刷新控件,想写一个玩玩,自定义一个在使用的时候也会比较有意思。使应用更加的灵动一些,毕竟谁不喜欢各种动画恰到好处的应用呢。 使用方式如下: tableview.refreshControl XRef…...

【仅限首批200名开发者】DeepSeek毒性检测白皮书V3.1泄露版:含未公开的multilingual bias benchmark结果
更多请点击: https://intelliparadigm.com 第一章:DeepSeek毒性检测模型的演进与V3.1泄露事件全景 DeepSeek Toxicity Detection(DTDD)系列模型自2022年发布初版以来,持续迭代强化对中文语境下隐性偏见、诱导性话术、…...

3步解决JavaScript精度问题:decimal.js高精度计算完整指南
3步解决JavaScript精度问题:decimal.js高精度计算完整指南 【免费下载链接】decimal.js An arbitrary-precision Decimal type for JavaScript 项目地址: https://gitcode.com/gh_mirrors/de/decimal.js 在JavaScript开发中,你是否经常遇到这样的…...

从Hello-World到Nginx:5个真实案例详解如何让Docker容器在后台稳定运行
从Hello-World到Nginx:5个真实案例详解如何让Docker容器在后台稳定运行 当你在终端输入docker run后,容器却像一阵风一样消失无踪——这种"闪退"现象往往是Docker新手遭遇的第一个认知颠覆点。不同于传统虚拟机,容器本质上是隔离的…...

基于LLM的MBTI人格模拟对话实验:从系统设计到工程实践
1. 项目概述:当MBTI遇上AI,一次关于人格的深度对话实验最近在GitHub上看到一个挺有意思的项目,叫“Kali-Hac/ChatGPT-MBTI”。光看名字,你可能觉得这又是一个用ChatGPT玩MBTI性格测试的简单脚本。但当我真正clone下来,…...

毕业答辩 PPT,让 AI 替你打工:百考通 AI 如何帮你告别排版内耗与逻辑焦虑
又是一年毕业季,论文写完了,查重过了,导师点头了,你以为可以松口气了? 不,还有一座大山叫“答辩 PPT”。 曾经,我也以为 PPT 只是论文的“精简版”,复制粘贴就能搞定。直到我熬…...

CodeMaker终极指南:如何5分钟掌握IntelliJ IDEA智能代码生成插件
CodeMaker终极指南:如何5分钟掌握IntelliJ IDEA智能代码生成插件 【免费下载链接】CodeMaker A idea-plugin for Java/Scala, support custom code template. 项目地址: https://gitcode.com/gh_mirrors/co/CodeMaker 还在为重复的Java和Scala编码工作而烦恼…...

Sonic搜索集群终极指南:从单机到高可用的完整部署方案
Sonic搜索集群终极指南:从单机到高可用的完整部署方案 【免费下载链接】sonic 🦔 Fast, lightweight & schema-less search backend. An alternative to Elasticsearch that runs on a few MBs of RAM. 项目地址: https://gitcode.com/gh_mirrors/…...

增量式编码器驱动开发实战:从原理到FPGA高速计数
1. 增量式编码器核心原理剖析 第一次接触增量式编码器时,我完全被它精妙的设计震撼到了。这种看似简单的装置,竟然能同时测量转速、转向和位置信息。拆开我们实验室的欧姆龙E6B2编码器,你会发现它的核心就是三个部分:发光二极管、…...

CodeContext:基于MCP协议与AI模式检测,让AI编程助手深度适配你的代码库
1. 项目概述:让AI助手真正“懂”你的代码库如果你和我一样,每天都在用Cursor或者GitHub Copilot这类AI编程助手,那你肯定也经历过这种时刻:AI给你生成了一段看起来功能正确的代码,但它的错误处理方式、导入风格、命名习…...

滑块验证码的轨迹反欺诈:从原理到QCaptcha企业级防护实战
摘要:本文深度剖析滑块验证码的反欺诈技术,从第一代纯位移校验到第三代复合验证的演进过程。重点讲解QCaptcha平台如何通过前端SDK内置轨迹采集后端票据校验实现企业级防护,并提供不同场景的配置建议和实测数据对比。一、黑产自动化攻击现状在…...