oracle分析函数学习
0、建表及插入测试数据
--CREATE TEST TABLE AND INSERT TEST DATA.
create table students
(id number(15,0),
area varchar2(10),
stu_type varchar2(2),
score number(20,2));insert into students values(1, '111', 'g', 80 );
insert into students values(1, '111', 'j', 80 );
insert into students values(1, '222', 'g', 89 );
insert into students values(1, '222', 'g', 68 );
insert into students values(2, '111', 'g', 80 );
insert into students values(2, '111', 'j', 70 );
insert into students values(2, '222', 'g', 60 );
insert into students values(2, '222', 'j', 65 );
insert into students values(3, '111', 'g', 75 );
insert into students values(3, '111', 'j', 58 );
insert into students values(3, '222', 'g', 58 );
insert into students values(3, '222', 'j', 90 );
insert into students values(4, '111', 'g', 89 );
insert into students values(4, '111', 'j', 90 );
insert into students values(4, '222', 'g', 90 );
insert into students values(4, '222', 'j', 89 );
commit;col score format 999999999999.991、GROUP BY子句的增强
A、GROUPING SETS
select id,area,stu_type,sum(score) score
from students
group by grouping sets((id,area,stu_type),(id,area),id)
order by id,area,stu_type;--------理解grouping sets
select a, b, c, sum( d ) from t
group by grouping sets ( a, b, c )
等效于
select * from (
select a, null, null, sum( d ) from t group by a
union all
select null, b, null, sum( d ) from t group by b
union all
select null, null, c, sum( d ) from t group by c
)
B、ROLLUP
select id,area,stu_type,sum(score) score
from students
group by rollup(id,area,stu_type)
order by id,area,stu_type;--------理解rollup
select a, b, c, sum( d )
from t
group by rollup(a, b, c);
等效于
select * from (
select a, b, c, sum( d ) from t group by a, b, c
union all
select a, b, null, sum( d ) from t group by a, b
union all
select a, null, null, sum( d ) from t group by a
union all
select null, null, null, sum( d ) from t
)
C、CUBE
select id,area,stu_type,sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type;--------理解cube
select a, b, c, sum( d ) from t
group by cube( a, b, c)
等效于
select a, b, c, sum( d ) from t
group by grouping sets(
( a, b, c ),
( a, b ), ( a ), ( b, c ),
( b ), ( a, c ), ( c ),
() )
D、GROUPING函数
从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,如何来区分到底是根据那个字段做的汇总呢,grouping函数判断是否合计列!
select decode(grouping(id),1,'all id',id) id,
decode(grouping(area),1,'all area',to_char(area)) area,
decode(grouping(stu_type),1,'all_stu_type',stu_type) stu_type,
sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type; 2、OVER()函数的使用
A、RANK()、DENSE_RANK() 、ROW_NUMBER()、CUME_DIST()、MAX()、AVG()
break on id skip 1
select id,area,score from students order by id,area,score desc;select id,rank() over(partition by id order by score desc) rk,score from students;--允许并列名次、名次不间断
select id,dense_rank() over(partition by id order by score desc) rk,score from students;--即使SCORE相同,ROW_NUMBER()结果也是不同
select id,row_number() over(partition by ID order by SCORE desc) rn,score from students;select cume_dist() over(order by id) a, --该组最大row_number/所有记录row_number
row_number() over (order by id) rn,id,area,score from students;select id,max(score) over(partition by id order by score desc) as mx,score from students;select id,area,avg(score) over(partition by id order by area) as avg,score from students; --注意有无order by的区别--按照ID求AVG
select id,avg(score) over(partition by id order by score desc rows between unbounded preceding
and unbounded following ) as ag,score from students;B、SUM()
select id,area,score from students order by id,area,score desc;select id,area,score,
sum(score) over (order by id,area) 连续求和, --按照OVER后边内容汇总求和
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;select id,area,score,
sum(score) over (partition by id order by area ) 连id续求和, --按照id内容汇总求和
sum(score) over (partition by id) id总和, --各id的分数总和
100*round(score/sum(score) over (partition by id),4) "id份额(%)",
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;C、LAG(COL,n,default)、LEAD(OL,n,default) --取前后边N条数据
select id,lag(score,1,0) over(order by id) lg,score from students;select id,lead(score,1,0) over(order by id) lg,score from students;D、FIRST_VALUE()、LAST_VALUE()
select id,first_value(score) over(order by id) fv,score from students;
select id,last_value(score) over(order by id) fv,score from students; --而对于last_value() over(order by id),结果是有问题的,因为我们没有按照id分区,所以应该出来的效果应该全部是90(最后一条)
--再看个例子
select id,last_value(score) over(order by rownum),score from students;--当使用last_value分析函数的时候,缺省的WINDOWING范围是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,在进行比较的时候从当前行向前进行比较,所以会出现上边的结果。加上如下的参数,结果就正常了。呵呵。默认窗口范围为所有处理结果。
select id,last_value(score) over(order by rownum RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING),score from students;相关文章:

oracle分析函数学习
0、建表及插入测试数据 --CREATE TEST TABLE AND INSERT TEST DATA. create table students (id number(15,0), area varchar2(10), stu_type varchar2(2), score number(20,2));insert into students values(1, 111, g, 80 ); insert into students values(1, 111, j, 80 ); …...

代码随想录训练营day17|110.平衡二叉树 257. 二叉树的所有路径 404.左叶子之和 v...
TOC 前言 代码随想录算法训练营day17 一、Leetcode 110.平衡二叉树 1.题目 给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 示例 1&#x…...

C# Thread用法
C# 中的线程(Thread)是一种并发执行的机制,允许同时执行多个代码块,从而提高程序的性能和响应性。下面是关于如何使用 C# 线程的一些基本用法: 1. 创建线程: 使用 System.Threading 命名空间中的 Thread 类…...
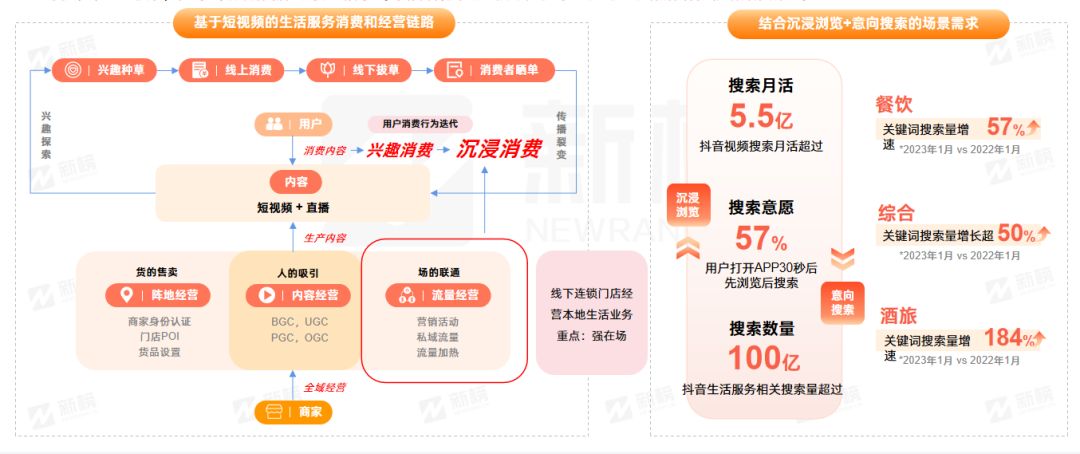
新榜 | CityWalk本地生活商业价值洞察报告
如果说现在有人问,最新的网络热词是什么? “CityWalk”,这可能是大多数人的答案。 近段时间,“CityWalk”刷屏了各种社交媒体,给网友们带来了一场“城市漫步”之旅。 脱离群体狂欢,这个在社交媒体引发热议的词汇背后又…...
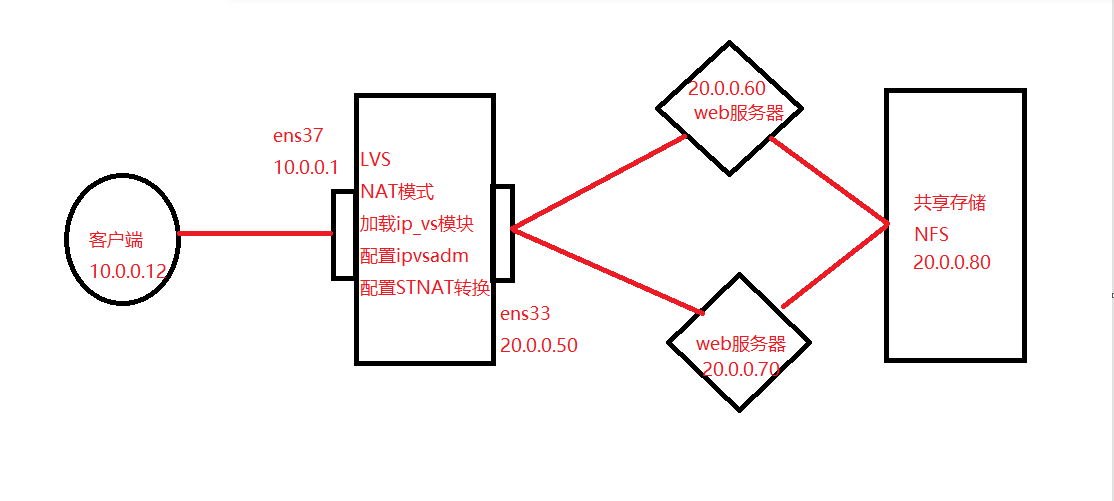
LVS负载均衡集群-NAT模式部署
集群 集群:将多台主机作为一个整体,然后对外提供相同的服务 集群使用场景:高并发的场景 集群的分类 1.负载均衡器集群 减少响应延迟,提高并发处理的能力 2,高可用集群 增强系统的稳定性可靠性&…...

C++学习笔记总结练习:effective 学习日志
准则 1.少使用define define所定义的常量会在预处理的时候被替代,出错编译器不容易找到错误。而且还没有作用范围限制,推荐使用constdefine宏定义的函数,容易出错,而且参数需要加上小括号,推荐使用inline有的类中例如…...

Vue教程(五):样式绑定——class和style
1、样式代码准备 样式提前准备 <style>.basic{width: 400px;height: 100px;border: 1px solid black;}.happy{border: 4px solid red;background-color: rgba(255, 255, 0, 0.644);background: linear-gradient(30deg, yellow, pink, orange, yellow);}.sad{border: 4px …...
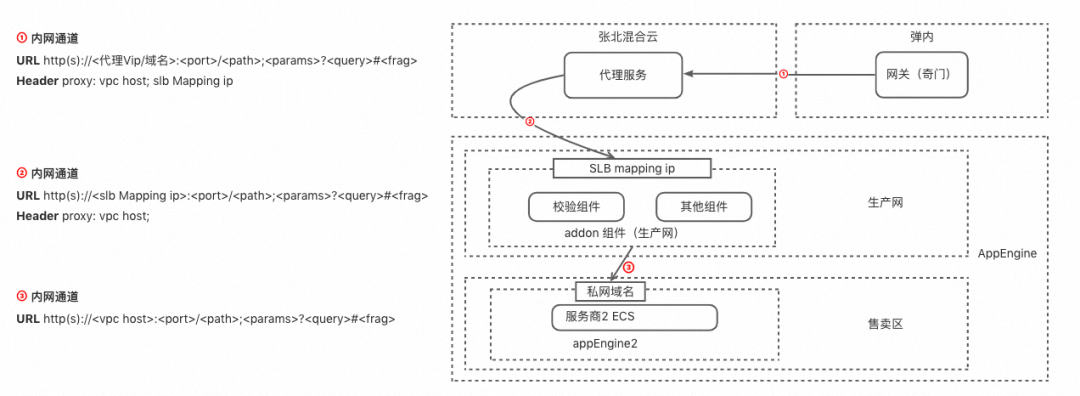
开放网关架构演进
作者:庄文弘(弘智) 淘宝开放平台是阿里与外部生态互联互通的重要开放途径,通过开放的产品技术把阿里经济体一系列基础服务,像水、电、煤一样输送给我们的商家、开发者、社区媒体以及其他合作伙伴,推动行业的…...

torch一些操作
Pytorch文档 Pytorch 官方文档 https://pytorch.org/docs/stable/index.html pytorch 里的一些基础tensor操作讲的不错 https://blog.csdn.net/abc13526222160/category_8614343.html 关于pytorch的Broadcast,合并与分割,数学运算,属性统计以及高阶操作 https://blog.csd…...
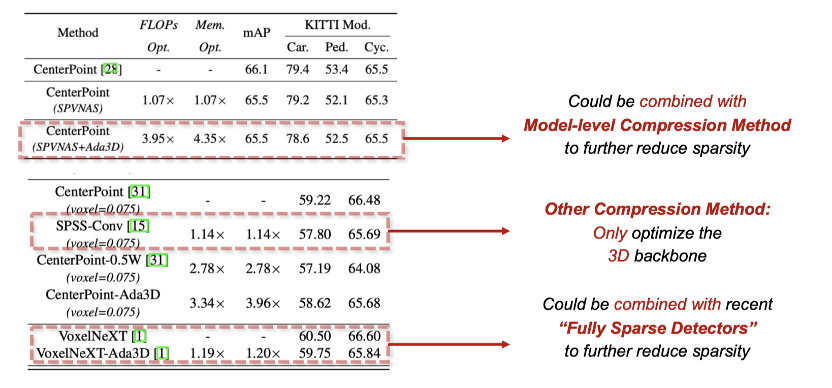
ICCV23 | Ada3D:利用动态推理挖掘3D感知任务中数据冗余性
论文地址:https://arxiv.org/abs/2307.08209 项目主页:https://a-suozhang.xyz/ada3d.github.io/ 01. 背景与动因 3D检测(3D Detection)任务是自动驾驶任务中的重要任务。由于自动驾驶任务的安全性至关重要(safety-critic),对感知算法的延…...

软件工程模型-架构师之路(四)
软件工程模型 敏捷开发: 个体和交互 胜过 过程和工具、可以工作的软件 胜过 面面俱到的文件、客户合作胜过合同谈判、响应变化 胜过 循序计划。(适应需求变化,积极响应) 敏捷开发与其他结构化方法区别特点:面向人的…...
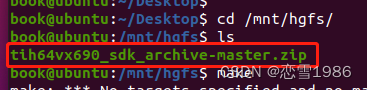
ubuntu20.04共享文件夹—— /mnt/hgfs里没有共享文件夹
参考文章:https://blog.csdn.net/Edwinwzy/article/details/129580636 虚拟机启用共享文件夹后,/mnt/hgfs下面为空,使用 vmware-hgfsclient 查看设置的共享文件夹名字也是为空。 解决方法: 1. 重新安装vmware tools. 在菜单…...
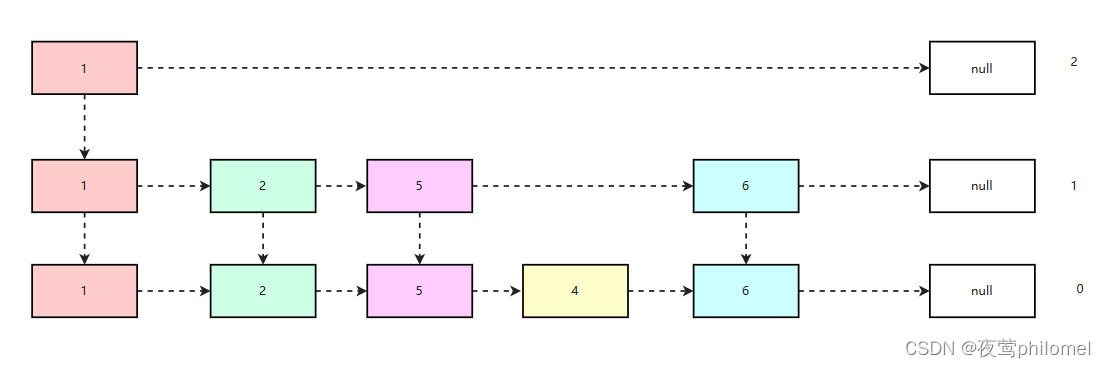
Redis中的有序集合及其底层跳表
前言 本文着重介绍Redis中的有序集合的底层实现中的跳表 有序集合 Sorted Set Redis中的Sorted Set 是一个有序的无重复值的集合,他底层是使用压缩列表和跳表实现的,和Java中的HashMap底层数据结构(1.8)链表红黑树异曲同工之妙…...
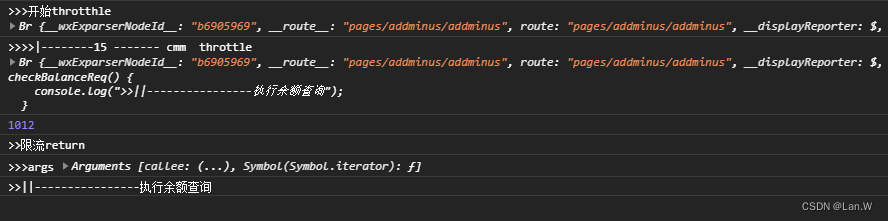
js 小程序限流函数 return闭包函数执行不了
问题: 调用限流 ,没走闭包的函数: checkBalanceReq() loadsh.js // 限流 const throttle (fn, context, interval) > {console.log(">>>>cmm throttle", context, interval)let canRun…...

【数据结构】堆的初始化——如何初始化一个大根堆?
文章目录 源码是如何插入的?扩容向上调整实现大根堆代码: 源码是如何插入的? 扩容 在扩容的时候,如果容量小于64,那就2倍多2的扩容;如果大于64,那就1.5倍扩容。 还会进行溢出的判断,…...

【韩顺平 零基础30天学会Java】程序流程控制(2days)
day1 程序流程控制:顺序控制、分支控制、循环控制 顺序控制:从上到下逐行地执行,中间没有任何判断和跳转。 Java中定义变量时要采用合法的前向引用。 分支控制if-else:单分支、双分支和多分支。 单分支 import java.util.Scann…...

从入门到精通Python隧道代理的使用与优化
哈喽,Python爬虫小伙伴们!今天我们来聊聊如何从入门到精通地使用和优化Python隧道代理,让我们的爬虫程序更加稳定、高效!今天我们将对使用和优化进行一个简单的梳理,并且会提供相应的代码示例。 1. 什么是隧道代理&…...

19万字智慧城市总体规划与设计方案WORD
导读:原文《19万字智慧城市总体规划与设计方案WORD》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 感知基础设施 感知基础设施架构由感知范围、感知手…...
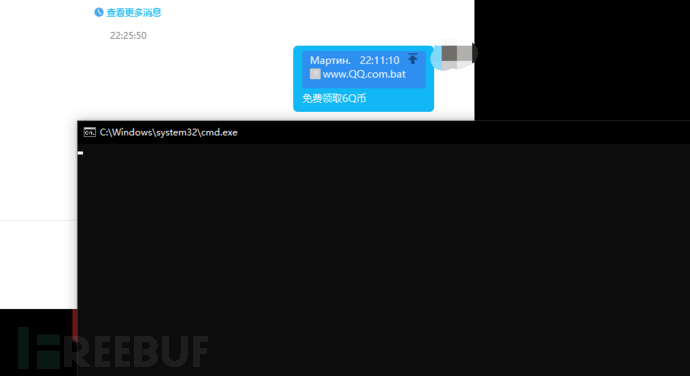
[赛博昆仑] 腾讯QQ_PC端,逻辑漏洞导致RCE漏洞
简介 !! 内容仅供学习,请不要进行非法网络活动,网络不是法外之地!! 赛博昆仑是国内一家较为知名的网络安全公司,该公司今日报告称 Windows 版腾讯 QQ 桌面客户端出现高危安全漏洞,据称“黑客利用难度极低、危害较大”,腾讯刚刚已经紧急发布…...
python Requests
Requests概述 官方文档:http://cn.python-requests.org/zh_CN/latest/,Requests是python的HTTP的库,我们可以安全的使用 Requests安装 pip install Requests -i https://pypi.tuna.tsinghua.edu.cn/simple Requests的使用 Respose的属性 属性说明url响…...

Termius v7.0.1汉化踩坑实录:从修改entry.js到完美中文界面的完整流程
Termius v7.0.1深度汉化实战:从逆向分析到完美本地化的技术探索 Termius作为一款广受开发者喜爱的SSH客户端,其v7.0.1版本在功能和性能上都有显著提升。但对于中文用户而言,官方未提供完整的本地化支持始终是个遗憾。本文将带你深入Termius内…...
·面经深度解析)
前端八股文面经大全:上海威派格前端实习(2026-05-07)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...

GLIGEN图像空间控制:用边界框实现像素级精准生成
1. GLIGEN:不是又一个“AI画图玩具”,而是图像生成控制权的真正移交你有没有试过对着 Stable Diffusion 的提示词框反复修改半小时,就为了把一只猫准确地放在沙发左边、让咖啡杯稳稳立在桌面上、让窗外的梧桐树只出现在画面右上角——结果生成…...

外科医生AI认知变迁:从技术好奇到价值驱动的全球调查
1. 项目概述:一场关于外科医生与AI认知变迁的全球对话作为一名长期关注技术与医疗交叉领域的从业者,我始终对一个问题抱有浓厚兴趣:当一项颠覆性技术从实验室走向临床,真正使用它的医生们究竟在想什么?他们的期待、困惑…...

如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题
如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了喜欢的歌曲,却发现…...

多模态大模型在光谱分析中的应用:温度参数调优与性能评估
1. 项目概述:当光谱分析遇上多模态大模型光谱分析,无论是红外、拉曼还是近红外光谱,一直是材料科学、生物医药、环境监测等领域的“火眼金睛”。它能通过物质与光的相互作用,揭示出样品的成分、结构乃至状态信息。然而,…...

解密智能图片分层:掌握Layerdivider提升设计效率的实战指南
解密智能图片分层:掌握Layerdivider提升设计效率的实战指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 在数字创意领域,我们常…...

基于Python与aiogram构建多模型AI助手:集成GPT-4、Claude与Gemini的Telegram机器人开发实践
1. 项目概述:一个多模型AI助手的自研之路 最近在折腾一个挺有意思的玩意儿,我把它叫做“AIAssistantBot”。简单来说,这是一个跑在Telegram上的机器人,但它不是那种只会回复固定指令的“傻”机器人。它的核心是整合了市面上几家主…...

5个常见照片管理难题,ExifToolGUI一站式解决
5个常见照片管理难题,ExifToolGUI一站式解决 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你有没有遇到过这样的情况?旅行归来,几百张照片的拍摄时间全乱了,…...

物理网卡down了?虚拟机还能通信吗?看teaming策略就够了
在ESXi虚拟化运维中,物理网卡(vmnic)故障、网线松动、网卡损坏导致网卡down(宕机),是常见的硬件故障场景。很多新手遇到这种情况,会下意识认为所有虚拟机都会断网,但实际并非如此。核…...