数学建模大全及优缺点解读
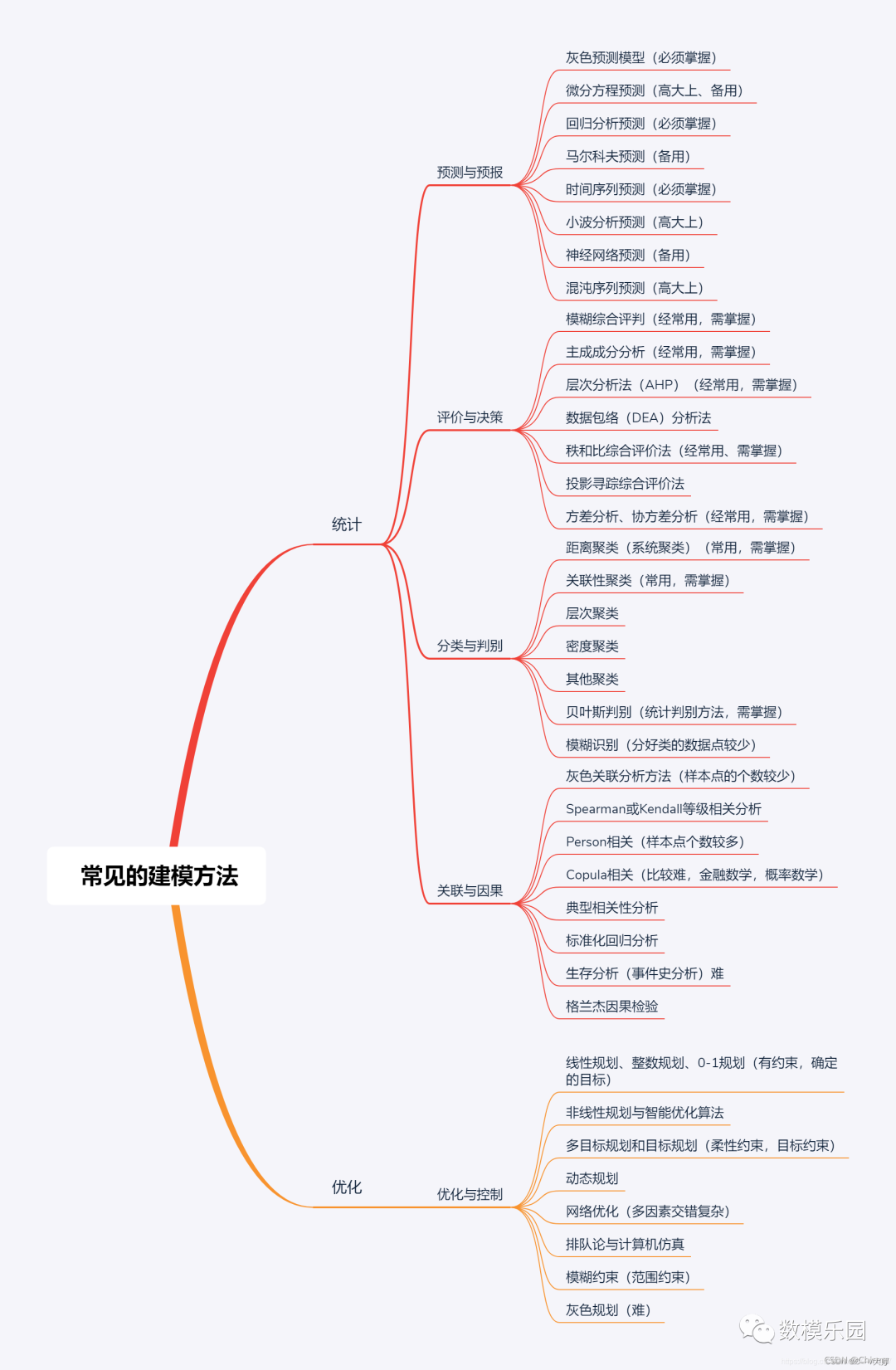
分类模型
1、距离聚类(系统聚类)(常用,需掌握)
优点:
①将一批样本数据按照他们在性质上的亲密程度在没有先验知识的情况下自动进行分类
②是一种探索性的分析方法,分类结果不一定相同
例如:主要用于样本数据的初步处理
缺点:
(1)用户需要先指定K,但到底指定K为多少是不知道的。
(2)对初值敏感。不同的初始化中心很容易导致不同的聚类结果。
(3)对于孤立点数据敏感。
2、关联性聚类(常用,需掌握)
3、层次聚类,密度聚类(DBSCAN)
6、贝叶斯判别(统计判别方法,需掌握)
7、费舍尔判别(训练的样本比较多,需掌握)
8、模糊识别(分好类的数据点比较少)
预测模型
1、灰色预测模型(必须掌握)
满足两个条件可用:
①数据样本点个数少,6-15个
②数据呈现指数或曲线的形式
例如:可以通过极值点和稳定点来预测下一次稳定点和极值点出现的时间点
灰色预测模型(Grey Forecasting Model)是一种基于数学统计方法的时间序列预测模型,用于预测具有一定规律但受到不确定因素影响的数据。它主要适用于中小样本、短期和中期的预测问题。
灰色预测模型的基本思想是将预测问题转化为灰色系统建模和参数估计的问题。它基于数据的特点,假设未来的发展趋势与过去的发展趋势相似,从而通过建立灰色微分方程来描述这种趋势。
灰色预测模型通常包括以下几个步骤:
- 数据的建模:根据已知数据,首先将数据序列进行累加得到累加序列,然后构造一阶或二阶差分序列。
- 参数估计:利用已知的数据序列,通过最小二乘法或指数累加法等方法,确定模型中的参数。
- 模型检验:利用已知的数据序列和估计的参数,检验模型的拟合程度和预测精度。
- 进行预测:根据估计的模型和已有的数据,预测未来的发展趋势。
灰色预测模型有多种形式,常见的包括GM(1,1)模型、GM(2,1)模型等。这些模型在实际应用中可以根据具体问题的特点选择合适的模型进行建模和预测。
需要注意的是,灰色预测模型是一种简化的预测方法,对于复杂的非线性系统或长期预测,可能存在一定的误差。因此,在使用灰色预测模型时需要结合实际情况和其他预测方法进行综合分析和判断。
2、微分方程预测(高大上、备用)
要求:
①无法直接找到原始数据之间的关系,但可以找到原始数据变化速度之间的关系,通过公式推导转化为原始数据的关系。
②微分方程关系较为复杂,微分方程的解比较难以得到,如果数学功底不是很好的一般不会选择使用。
③由于方程的建立是以局部规律的独立性假定为基础,当作为长期预测时,误差较大
微分方程预测是一种利用微分方程模型来预测未来的发展趋势的方法。它基于对系统动态变化规律的建模,通过解微分方程来获取未来的状态或趋势。
在微分方程预测中,常用的模型有以下几种:
-
一阶线性微分方程模型:常见的一阶线性微分方程模型可以表示为 dy/dt = f(y, t),其中 y 是变量的函数,t 是时间。通过给定初始条件以及确定的 f 函数,可以求解出 y 在未来的变化情况。
-
非线性微分方程模型:非线性微分方程模型通常包含了更复杂的系统动态,并且往往需要使用数值方法进行求解。常见的方法包括 Euler 法、Runge-Kutta 法等。
-
系统动力学模型:系统动力学是一种研究动态系统行为的方法,其中包括了微分方程、差分方程等模型。通过构建系统动力学模型,可以对系统的演化过程进行分析,并提供未来的预测。
在实际应用中,微分方程预测可以适用于许多领域,如经济学、生态学、物理学等。但需要注意的是,微分方程预测的准确性和可靠性很大程度上依赖于模型的假设和参数的估计。因此,在使用微分方程预测时,需要进行参数优化和模型验证,以提高预测的准确性和可靠性。
3、回归分析预测(必须掌握)
求一个因变量与若干自变量之间的关系,若自变量变化后,求因变量如何变化;
样本点的个数有要求:
①自变量之间的协方差比较小,最好趋近于0,自变量间的相关性小;
②样本点的个数n>3k+1,k为自变量的个数;
③因变量要符合正态分布
回归分析预测是一种常用的统计分析方法,用于建立变量之间的关系,并利用这种关系来进行未来的预测。它基于已有的数据样本,通过建立一个数学模型,来描述自变量和因变量之间的关系,然后利用该模型进行未来数值的预测。
回归分析预测的基本步骤如下:
-
数据收集:收集包含自变量和因变量的样本数据。
-
模型选择:根据数据的特点和问题的需求,选择合适的回归模型。常见的回归模型有线性回归模型、多项式回归模型、非线性回归模型等。
-
模型拟合:利用回归模型,通过最小二乘法或其他方法,拟合出模型中的参数。这些参数表示自变量对因变量的影响程度。
-
模型评估:通过各种统计指标(如决定系数R-squared、残差分析等),评估模型的拟合优度和预测能力。如果模型不够理想,可以考虑改进模型或使用其他模型。
-
预测应用:利用已拟合的回归模型,输入未来的自变量数据,预测相应的因变量值。
需要注意的是,回归分析预测在应用中具有一定的局限性。它假设数据之间的关系是稳定的,并且基于线性或非线性的关系。对于复杂的非线性系统或存在非稳定因素的情况,回归分析的准确性可能受到限制。此外,预测结果还可能受到数据质量、样本数量、变量选择等因素的影响。因此,在使用回归分析预测时,要谨慎选择模型、评估模型、验证预测结果,并结合实际情况进行综合分析。
4、马尔科夫预测(备用)
要求
1、一个序列之间没有信息的传递,前后没联系,数据与数据之间随机性强,相互不影响;(今天的温度与昨天、后台没有直接联系)
2、不仅要能够指出事件发生的各种可能结果,而且还必须给出每一种结果出现的概率(预测后天温度高、中、低的概率,只能得到概率)
3、一般计算状态转移概率,状态为定类(“畅销”、“一般”、“滞销”)丰收预测,天气预报
马尔科夫预测(Markov Forecasting)是一种基于马尔科夫链的预测方法,用于预测未来的状态或事件。马尔科夫链是一种随机过程,具有马尔科夫性质,即未来的状态只依赖于当前的状态,而与过去的状态无关。
在马尔科夫预测中,首先需要建立一个马尔科夫模型,包括状态空间、状态转移概率和初始状态概率。状态空间表示可能的状态集合,状态转移概率表示从一个状态转移到另一个状态的概率,初始状态概率表示系统的初始状态。
马尔科夫预测的基本步骤如下:
-
确定状态空间:根据预测问题的特点,确定可能的状态集合。
-
估计状态转移概率:通过历史数据,估计从一个状态转移到另一个状态的概率。可以使用最大似然估计等方法进行估计。
-
估计初始状态概率:通过历史数据,估计系统的初始状态概率。
-
进行预测:根据已有的状态序列和估计的状态转移概率,利用马尔科夫链的性质,预测未来的状态。
需要注意的是,马尔科夫预测假设未来的状态只与当前的状态有关,而与过去的状态无关。这种假设在某些情况下可能不成立,导致预测结果的不准确性。此外,马尔科夫预测还需要满足马尔科夫链的平稳性和遍历性等条件,才能保证预测的有效性。
马尔科夫预测在实际应用中具有广泛的应用,如天气预测、股票价格预测、自然语言处理等领域。它可以作为一种简单而有效的预测方法,但在应用时需要结合实际情况和其他预测方法进行综合分析和判断。
5、时间序列预测(必须掌握)
与马尔科夫链预测互补,至少有2个点需要信息的传递,AR模型、MA模型ARMA模型,周期模型,季节模型等
时间序列预测是一种用于预测未来趋势和模式的统计分析方法,适用于时间上连续的数据序列。它基于过去的数据,通过建立模型和分析序列中的特征,来推断未来的数值或趋势。
时间序列预测的基本步骤如下:
-
数据收集:收集包含时间标记的数据序列,通常是按照时间顺序排列的。
-
数据探索:对数据进行可视化和描述性统计分析,检查数据的趋势性、季节性、周期性等特征。
-
模型选择:根据数据的特点和问题的需求,选择适合的时间序列模型。常见的模型包括移动平均模型(MA)、自回归模型(AR)、自回归移动平均模型(ARMA)、自回归积分移动平均模型(ARIMA)等。
-
模型拟合:根据已有的时间序列数据,通过最小二乘法或最大似然估计等方法,拟合出模型中的参数。
-
模型诊断:对拟合的模型进行诊断,检查残差序列的性质,验证模型是否合适。
-
模型预测:利用已拟合的时间序列模型,输入未来的时间点或时间跨度,进行未来数值的预测。
需要注意的是,时间序列预测的准确性受到多种因素的影响,如数据质量、样本数量、模型选择、模型参数估计等。因此,在使用时间序列预测时,应结合领域知识、经验判断和其他预测方法进行综合分析和判断。
时间序列预测在许多领域都有应用,如经济学、金融学、气象学、销售预测等。它可以帮助我们了解数据中的趋势和模式,为未来的决策提供参考。
6、小波分析预测(高大上)
数据无规律,海量数据,将波进行分离,分离出周期数据、规律性数据;可以做时间序列做不出的数据,应用范围比较广
小波分析(Wavelet Analysis)是一种信号处理技术,通过将信号分解成不同频率和时间分辨率的小波基函数,可以更好地捕捉信号的局部特征和时频特性。
小波分析在预测中的应用可以通过以下步骤实现:
-
数据预处理:对待预测的时间序列进行平滑、去噪、差分等预处理操作,以提高数据的稳定性和可预测性。
-
小波分解:使用小波变换将待预测的时间序列分解为多个频带,每个频带对应不同尺度的小波基函数。
-
特征提取:对于每个频带,可以提取其特征,如能量、频率、幅度等。这些特征可以反映时间序列的不同特性。
-
建模和预测:根据分解得到的特征,可以选择合适的预测模型,如自回归模型、支持向量回归等,进行建模和预测。可以借助计算工具,如神经网络、支持向量机等方法来实现预测。
-
反变换和还原:将预测结果通过小波反变换或相关技术还原到原始的时间序列中。
小波分析在预测中具有较好的局部特征提取和时频分析能力,适用于非平稳和具有瞬时特性的时间序列预测问题。然而,小波分析的预测性能往往与数据的选择、小波基函数的选择以及预测模型的选择等因素有关,需要根据具体问题和数据的特点来选择和优化相关参数和方法。
7、神经网络预测(备用)
大量的数据,不需要模型,只需要输入和输出,黑箱处理,建议作为检验的办法评价模型
1、模糊综合评判(经常用,需掌握)
评价一个对象优良中差等层次评价,评价一个学校等,不能排序
2、主成分分析(数据降维)(经常用,需掌握)
特点:
①将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法
②主成分保留了原始变量绝大多数信息
③主成分的个数大大少于原始变量的数目
④各个主成分之间互不相关
⑤每个主成分都是原始变量的线性组合
例如:找出某个事件的前几个主要影响因素
评价多个对象的水平并排序,指标间关联性很强
3、层次分析法(AHP)(经常用,需掌握)
特点:
①层次权重决策分析
②较少的定量信息
③多目标、多准则或无结构特性
④适用于难以完全定量的复杂系统
例如:做出某种决策需要考虑多方面的因素
做决策,去哪旅游,通过指标,综合考虑做决策
4、多属性决策
特点:
①利用已有的决策信息
②对一组(有限个)备选方案进行排序或择优
③属性权重和属性值为参考值
例如:投资决策、项目评估、维修服务、武器系统性能评定、工厂选址、投标招标、产业部门发展排序和经济效益综合评价等
5、秩和比综合评价法(经常用,需掌握)
评价各个对象并排序,指标间关联性不强
6、优劣解距离法(TOPSIS法)
7、投影寻踪综合评价法
揉合多种算法,比如遗传算法、最优化理论等
8、方差分析、协方差分析等(经常用,需掌握)
方差分析:看几类数据之间有无差异,差异性影响,例如:元素对麦子的产量有无影响,差异量的多少;(1992年,作物生长的施肥效果问题)
协方差分析:有几个因素,我们只考虑一个因素对问题的影响,忽略其他因素,但注意初始数据的量纲及初始情况。(2006年,艾滋病疗法的评价及预测问题)
神经网络预测是一种基于神经网络模型的数据预测方法。通过对已知数据的学习和训练,神经网络能够对未知数据进行预测和分类。
神经网络通常由输入层、隐藏层和输出层组成。输入层接收原始数据,隐藏层通过一系列的神经元进行计算和转换,最终输出层给出预测结果。
在神经网络的训练过程中,我们会使用已知数据对模型进行训练,通过不断调整网络中各个参数的权重和偏差,使得模型能够更准确地预测出未知数据的结果。
神经网络预测可以应用于各种领域和问题,例如图像识别、语音识别、自然语言处理、股票预测等。它具有较强的非线性拟合能力和适应性,能够处理复杂的数据模式和关系,预测精度较高。
需要注意的是,神经网络预测需要大量的训练数据和计算资源,同时也容易出现过拟合和欠拟合的问题。因此,在使用神经网络进行预测时,我们需要权衡模型的复杂度、数据量和计算能力,以及对预测结果的准确度和误差容忍度的要求。
优化模型
线性规划
特点:
①用于辅助人们进行科学管理
②求线性目标函数在线性约束条件下的最大值或最小值
③三要素:决策变量、约束条件、目标函数
例如:工厂分配资源生产使得利润最大化
非线性规划
整数规划
动态规划
多目标规划
线性规划(Linear Programming)是一种优化问题的数学建模方法,可以用来解决多种实际问题,例如资源分配、生产计划、运输、投资组合等。线性规划的目标是在满足一系列线性约束条件的前提下,找到使目标函数取得最大或最小值的决策变量。
一个标准的线性规划问题可以表示为:
最小化(或最大化)目标函数:
minimize (maximize) C T x subject to A x ≤ b x ≥ 0 \begin{align*} \text{minimize (maximize) } &C^T x\\ \text{subject to } &Ax \leq b\\ &x \geq 0 \end{align*} minimize (maximize) subject to CTxAx≤bx≥0
其中, C C C是目标函数的系数向量, x x x是决策变量向量, A A A是约束条件的系数矩阵, b b b是约束条件的右侧向量。约束条件可以包括等式约束、不等式约束或者不等式约束的组合。
线性规划问题的解可以通过线性规划求解算法进行求解,常用的算法包括单纯形法、内点法、启发式算法等。线性规划问题具有良好的数学性质,可以通过对偶理论和灵敏度分析等方法进行分析和优化,也可以与其他优化模型进行集成求解。
遗传算法
直接对结构对象进行操作,不存在求导和函数连续性的限定;
具有内在的隐并行性和更好的全局寻优能力;
采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
局部搜索能力强,运行时间较短
`缺点`
全局搜索能力差,容易受参数的影响
遗传算法(Genetic Algorithm)是一种启发式优化算法,通过模拟进化过程中的遗传和自然选择机制,来寻找问题的最优解。它的基本步骤包括:
-
初始化种群:随机生成一组初始解,称为种群。
-
评估适应度:对种群中的每个个体,根据问题的适应度函数进行评估,得到其适应度值。
-
选择操作:根据适应度值对种群中的个体进行选择,常用的选择操作有轮盘赌选择、锦标赛选择等。
-
交叉操作:从选择的个体中随机选择一对个体,通过某种交叉方式生成新的个体。
-
变异操作:对新生成的个体进行变异,引入随机扰动,增加种群的多样性。
-
更新种群:将新生成的个体加入种群,并根据一定的更新策略,如精英保留策略,选择一部分个体作为下一代种群。
-
终止条件判断:判断是否满足终止条件,如达到最大迭代次数或找到满足目标的解等。
-
重复步骤2-7:迭代执行步骤2-7,直到满足终止条件。
遗传算法适用于各种优化问题,尤其是那些具有复杂的搜索空间、多峰函数和约束条件的问题。然而,遗传算法的性能往往与参数的选择、编码方式的设计以及优化问题的特点有关,需要根据实际情况进行调优和改进。
模拟退火算法
优点
能很好的处理约束,
能很好的跳出局部最优,最终得到全局最优解,
全局搜索能力强;
缺点
收敛较慢,局部搜索能力较弱,运行时间长,且容易受参数的影响.
模拟退火算法(Simulated Annealing)是一种基于统计物理学的全局优化算法,用于在搜索空间中寻找最优解。它的灵感来自于固体的退火过程,通过控制搜索过程中的温度参数,模拟固体退火过程中的随机性和自适应性,从而在大范围内搜索解空间。
模拟退火算法的基本思想如下:
- 初始化:随机生成一个初始解作为当前解。
- 定义目标函数:根据问题的具体情况,定义一个目标函数来评价当前解的好坏。
- 外循环:控制模拟退火算法的迭代次数。
- 内循环:控制每次温度下的迭代次数。
- 生成新解:通过某种方式在当前解的邻域中生成一个新的解。
- 计算目标函数差:计算新解与当前解的目标函数差值。
- 判断接受条件:根据目标函数差和当前温度,以一定的概率接受新解作为当前解,或者保持当前解不变。
- 降温:通过一个降温函数来降低温度,控制接受新解的概率逐渐变小。
- 内循环:控制每次温度下的迭代次数。
模拟退火算法的核心在于接受新解的概率计算方法,一般使用Boltzmann分布来计算接受概率。通过控制温度参数和降温函数,模拟退火算法可以在搜索过程中逐渐收敛到全局最优解。
模拟退火算法可以应用于各种优化问题,特别是那些复杂度较高、连续性和非凸性较强的问题。它具有全局搜索能力和适应性,可以避免陷入局部最优解。但是,模拟退火算法的收敛速度较慢,并且需要根据问题的特性进行参数调优。
关联与因果模型
1、灰色关联分析方法(样本点的个数比较少)
特点:
①少量的、不完全的信息
②用于对未来的预测
③能够处理不确定量,使之量化,并寻求系统的运动规律
例如:在社会、经济、科学技术等诸多领域进行测、决策、评估、规划控制、系统分析与建模
2、Sperman或Kendall等级相关分析
3、Person相关(样本点的个数比较多)
4、Copula相关(比较难,金融数学,概率数学)
5、典型相关分析
(因变量组Y1234,自变量组X1234,各自变量组相关性比较强,问哪一个因变量与哪一个自变量关系比较紧密?)
6、标准化回归分析
若干自变量,一个因变量,问哪一个自变量与因变量关系比较紧密
关联模型和因果模型是统计学和机器学习中常用的两种模型,用于描述和理解变量之间的关系。它们的区别在于对变量之间关系的解释和推断方式。
关联模型(Associative Model)描述的是变量之间的相关性,即当一个变量发生改变时,另一个变量可能会随之发生改变,但不能确定哪个是原因,哪个是结果。关联模型通过计算相关系数、回归等统计方法来刻画变量之间的相互关系,常用于探索数据中的模式和规律,以及进行预测和预测。
因果模型(Causal Model)描述的是变量之间的因果关系,即一个变量的改变会导致另一个变量的改变。因果模型通过建立因果关系的假设和模型,来推断变量之间的因果关系。因果模型的建立通常需要依靠领域知识和实验设计,而且要求统计方法能够进行因果推断,如因果图模型、结构方程模型等。
需要注意的是,关联模型和因果模型是两种不同的模型,不能混淆使用。在实际应用中,根据问题的具体要求和数据的性质,选择合适的模型来描述和推断变量之间的关系是很重要的。
(参考数模乐园文章)
相关文章:
数学建模大全及优缺点解读
分类模型 1、距离聚类(系统聚类)(常用,需掌握) 优点: ①将一批样本数据按照他们在性质上的亲密程度在没有先验知识的情况下自动进行分类 ②是一种探索性的分析方法,分类结果不一定相同 例如&am…...

C++简介
文章目录 C简介C版本C11例子 C14例子 C17C20例子 C简介 C是一种高级编程语言,它是对C语言的扩展和增强。C由Bjarne Stroustrup于1980年发明,主要用于系统级编程、游戏开发、嵌入式系统等领域。 C具有许多特性,其中最重要的是面向对象编程&a…...
【广州华锐互动】3D空间编辑器:一款简洁易用的VR/3D在线编辑工具
随着虚拟现实技术的不断发展,数字孪生技术的应用已经被广泛应用于产品设计和制作中,能充分发挥企业应用3D建模的优势,凸显了三维设计的价值,在生产阶段也能够充分发挥3D模型的作用。 如今,广州华锐互动开发的3D空间编辑…...

golang云原生项目☞redis配置
配置redis适用与golang云原生架构。包括redis与数据库一致性等重要内容 1、编写redis配置文件、使用viper读取 配置文件 db.yml redis:addr: 127.0.0.1port: 6379password: tiktokRedisdb: 0 # 数据库编号读取配置文件 var (config viper.Init("db")zapL…...
C++ malloc/free/new/delete详解(内存管理)
C malloc/free/new/delete详解(内存管理) malloc/free典型用法内存分配实现过程brk和mmap申请小于128k的内存申请大于128k的内存释放内存brk和mmap的区别 new/delete典型用法 内存分配实现过程new/delete和malloc/free的区别malloc对于给每个进程分配的内…...

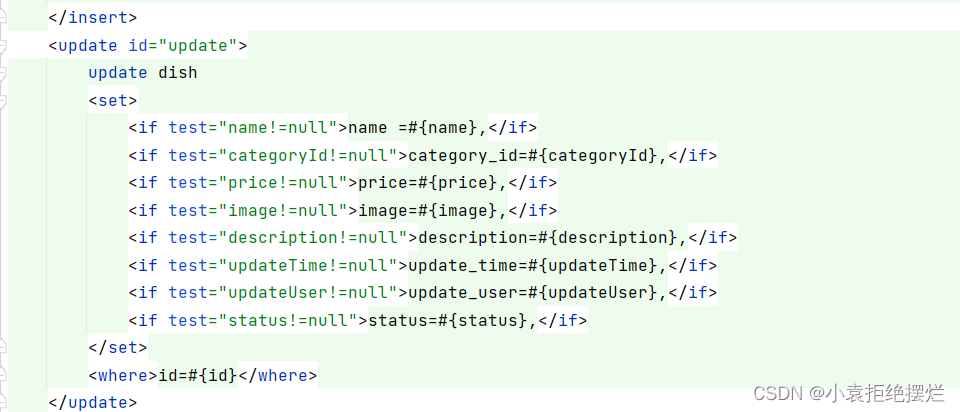
SpringBoot中Mapper.xml的入参方式
在SpringBoot开发过程中,我们使用 ***Mapper.xml***Mapper.java 来封装对数据库表的 CURD 操作,正常每张表会有一组对应的文件。 一、Mapper常见用法 下面例举一个查询操作: 数据表t_sap_customer,表中有字段id、code、name、c…...

回归预测 | MATLAB实现WOA-RBF鲸鱼优化算法优化径向基函数神经网络多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现WOA-RBF鲸鱼优化算法优化径向基函数神经网络多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现WOA-RBF鲸鱼优化算法优化径向基函数神经网络多输入单输出回归预测(多指标,多图&#…...

浅析Python爬虫ip程序延迟和吞吐量影响因素
作为一名资深的爬虫程序员,今天我们很有必要来聊聊Python爬虫ip程序的延迟和吞吐量,这是影响我们爬取效率的重要因素。这里我们会提供一些实用的解决方案,让你的爬虫程序飞起来! 网络延迟 首先,让我们来看看网络延迟对…...
)
【100天精通python】Day43:python网络爬虫开发_爬虫基础(urlib库、Beautiful Soup库、使用代理+实战代码)
目录 1 urlib 库 2 Beautiful Soup库 3 使用代理 3.1 代理种类 HTTP、HTTPS 和 SOCKS5 3.2 使用 urllib 和 requests 库使用代理 3.3 案例:自建代理池 4 实战 提取视频信息并进行分析 1 urlib 库 urllib 是 Python 内置的标准库,用于处理URL、发送…...
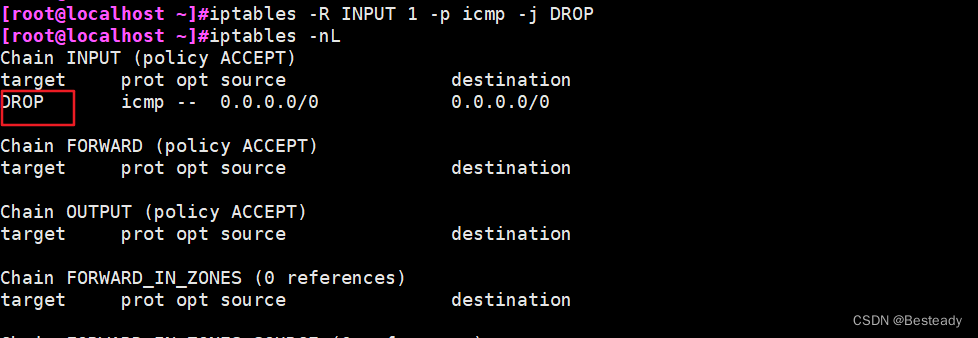
Linux:安全技术与防火墙
目录 一、安全技术 1.安全技术 2.防火墙的分类 3.防水墙 4.netfilter/iptables关系 二、防火墙 1、iptables四表五链 2、黑白名单 3.iptables命令 3.1查看filter表所有链 iptables -L 编辑3.2用数字形式(fliter)表所有链 查看输出结果 iptables -nL 3.3 清空所有链…...

Confluent kafka 异常退出rd_tmpabuf_alloc0: rd kafka topic info_new_with_rack
rd_tmpabuf_alloc0: rd kafka topic info_new_with_rack 根据网上的例子,做了一个测试程序。 C# 操作Kafka_c# kafka_Riven Chen的博客-CSDN博客 但是执行下面一行时,弹出上面的异常,闪退。 consumer.Subscribe(queueName) 解决方案&…...
最新ChatGPT网站程序源码+AI系统+详细图文搭建教程/支持GPT4.0/AI绘画/H5端/Prompt知识库
一、前言 SparkAi系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。 那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!…...

chatGPT-对话柏拉图
引言: 古希腊哲学家柏拉图,在他的众多著作中,尤以《理想国》为人所熟知。在这部杰作中,他勾勒了一个理想的政治制度,提出了各种政体,并阐述了他对于公正、智慧以及政治稳定的哲学观点。然而,其…...
Java项目-苍穹外卖-Day04
公共字段自动填充 这些字段在每张表基本都有,手动进行填充效率低,且后期维护更改繁琐 使用到注解AOP主要 先答应一个AutoFill注解 再定义一个切面类进行通知 对应代码 用到了枚举类和反射 package com.sky.aspect; /*** 自定义切面类,…...

SQL递归获取完整的树形结构数据
在 SQL 中,WITH RECURSIVE 用于创建递归查询,它允许在查询中引用自身。这种查询通常用于处理具有层次结构的数据,例如树形结构。 以下是使用 WITH RECURSIVE 创建递归查询的一般语法: WITH RECURSIVE [alias] ([column1], [colu…...

如何使用营销活动,提升小程序用户的参与度
在当今数字化时代,小程序已成为企业私域营销的重要一环。然而,仅仅拥有小程序还不足以吸引用户的兴趣和参与。营销活动作为推动用户参与的有效手段,可以在激烈的市场竞争中脱颖而出。本文将深入探讨如何使用营销活动,提升小程序用…...
IDEA中使用Docker插件构建镜像并推送至私服Harbor
一、开启Docker服务器的远程访问 1.1 开启2375远程访问 默认的dokcer是不支持远程访问的,需要加点配置,开启Docker的远程访问 # 首先查看docker配置文件所在位置 systemctl status docker# 会输出如下内容: ● docker.service - Docker Ap…...

第7章 高性能门户首页构建
mini商城第7章 高性能门户首页构建 一、课题 高性能门户建设 二、回顾 1、了解文件存储系统的概念 2、了解常用文件服务器的区别 3、掌握Minio的应用 三、目标 1、OpenResty 百万并发站点架构 OpenResty 特性介绍 搭建OpenResty Web站点动静分离方案剖析 2、多级缓存架…...
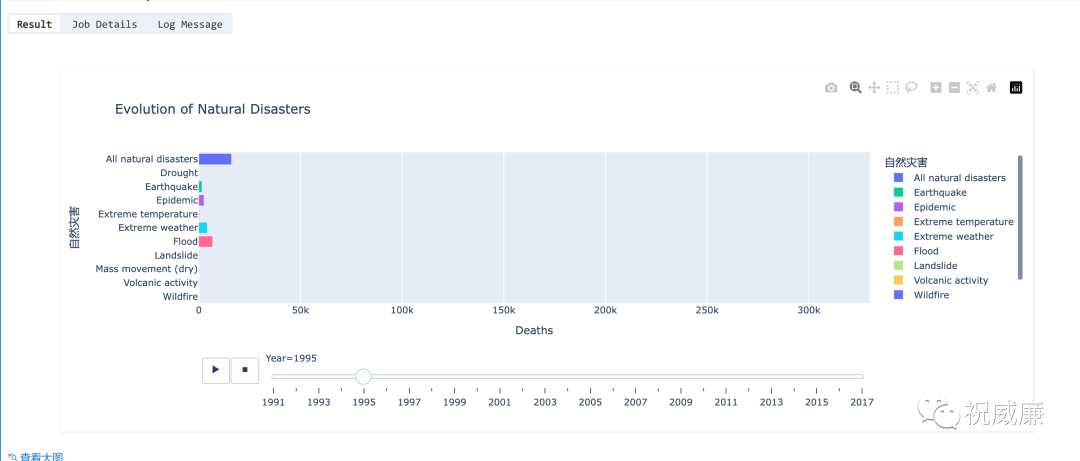
用加持了大模型的 Byzer-Notebook 做数据分析是什么体验
Byzer-Notebook 是专门为 SQL 而研发的一款 Web Notebook。他的第一公民是 SQL,而 Jupyter 则是是以 Python 为第一公民的。 随着 Byzer 引擎对大模型能力的支持日渐完善, Byzer-Notebook 也在不自觉中变得更加强大。我和小伙伴在聊天的过程中才发现他已…...
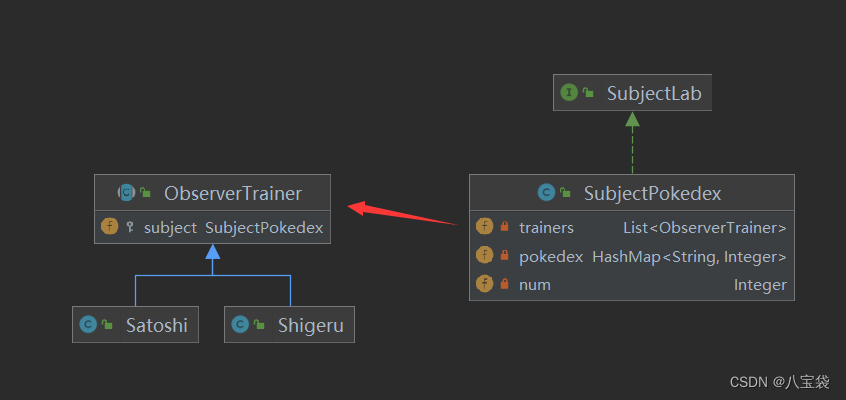
学习设计模式之观察者模式,但是宝可梦
前言 作者在准备秋招中,学习设计模式,做点小笔记,用宝可梦为场景举例,有错误欢迎指出。 观察者模式 观察者模式定义了一种一对多的依赖关系,一个对象的状态改变,其他所有依赖者都会接收相应的通知。 所…...

2026最权威的降重复率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 降低人工智能部署以及应用阶段的优化,需要从算力调度、算法剪枝以及参数压缩这三…...

专利价值评估实战:从技术保护到商业竞争的核心方法论
1. 专利资产价值评估:从“纸面权利”到“商业武器”的实战拆解在科技行业摸爬滚打十几年,我见过太多公司手握一堆专利证书,却说不清它们到底值多少钱。这感觉就像你家里藏了一箱古董,只知道它们“可能很值钱”,但具体哪…...

从Arduino官网的‘eagle-files’说起:给硬件新手的Autodesk Eagle PCB设计入门指南
从Eagle文件到PCB设计:开源硬件爱好者的实战入门指南 在开源硬件社区里,Arduino项目的"eagle-files"文件夹常常让新手感到困惑又好奇。这些文件背后隐藏着一个强大的工具链——Autodesk Eagle,它是欧美开源硬件生态中PCB设计的通用…...

审判直击:奥特曼与马斯克的控制权之争,谁在说谎?谁在惩罚谁?
审判中的奥特曼与马斯克 奥特曼表示,他们付出巨大努力创建的慈善机构不容窃取,还猜测马斯克两次试图搞垮它。在审判中,奥特曼展现出 "圣路易斯好小伙" 形象,一开始作证时有些紧张,后放松下来,其证…...

BaiduNetdiskPlugin-macOS:三步破解百度网盘限速,实现SVIP级别下载体验
BaiduNetdiskPlugin-macOS:三步破解百度网盘限速,实现SVIP级别下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百…...

南京数字化申报实战开启:提交材料后,如何确保您的技术底座不被“合规性审计”一票否决?
【行动指南:从填报到过审】截至 2026年5月12日,南京市中小企业数字化转型城市试点的线上申报通道已正式运行。在首批提交材料的企业反馈中,一个核心细节引起了市场的高度关注:申报系统不仅要求填写投入金额,更强化了对…...

搞懂这6个核心问题,程序员转智能体开发少走3年弯路
文章目录前言问题一:我只会写CRUD,真的能转智能体开发吗?问题二:转智能体开发,到底需要学哪些技术?2.1 基础层:Python 提示词工程2.2 核心层:RAG 工具调用 记忆管理2.3 进阶层&am…...
到底怎么设)
告别调参玄学:深入解读Frenet轨迹规划中评价函数权重(K_J, K_T, K_D)到底怎么设
Frenet轨迹规划中评价函数权重的科学调参方法论 在自动驾驶系统的开发过程中,轨迹规划算法的调参工作常常被工程师们戏称为"玄学实验"。这种现象在Frenet坐标系下的动态轨迹规划中尤为明显——当面对K_J、K_T、K_D等一系评价函数权重参数时,不…...

改进人工势场多无人机三维航迹规划【附代码】
✨ 长期致力于航迹规划、多无人机、目标分配、人工势场算法、三维空间研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多目标任务分配与人工势场基础&…...

从收音机到5G:OFDM技术的前世今生,以及它为何成为Wi-Fi和5GNR的基石
从收音机到5G:OFDM技术的前世今生,以及它为何成为Wi-Fi和5GNR的基石 想象一下,你正用手机流畅播放4K视频,同时下载大文件——这背后是一套诞生于上世纪60年代的技术在支撑。OFDM(正交频分复用)的传奇之处在…...