每天一道大厂SQL题【Day11】微众银行真题实战(一)
每天一道大厂SQL题【Day11】微众银行真题实战(一)
大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题,以每日1题的形式,带你过一遍热门SQL题并给出恰如其分的解答。
一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最有效的学习方式!
每日语录
如果外貌好能够获得他人的关注,又有钱能够支持各种娱乐活动,谁会愿意每天呆在家里打游戏,刷微博,看电视剧。

第11题:授信金额统计
需求列表
笔试题目
说明:SQL语法请使用HiveSQL/SparkSQL
1.基于附录《核额流水表》和附录2《借据表》统计下述指标,请提供统计SQL
| 指标 | 当日新增 | 昨日新增 | 历史累计 |
|---|---|---|---|
| 申请户数 | |||
| 规则通过户数 | |||
| 核额成功户数 | |||
| 授信金额 | |||
| 平均核额 | |||
| 发放金额 | |||
| 户均发放金额 |
数据准备
debt.txt文件
set spark.sql.shuffle.partitions=4;
create database webank_db;
use webank_db;
create or replace temporary view check_view (ds comment '日期分区',
sno comment '流水号', uid comment '用户id',
is_risk_apply comment '是否核额申请',
is_pass_rule comment '是否通过规则',
is_obtain_qutoa comment '是否授信成功', quota comment '授信金额',
update_time comment '更新时间')
as
values ('20201101', 's000', 'u000', 1, 1, 1, 700, '2020-11-01 08:12:12'),
('20201102', 's088', 'u088', 1, 1, 1, 888, '2020-11-02 08:12:12'),
('20201230', 's091', 'u091', 1, 1, 1, 789, '2020-12-30 08:12:12'),
('20201230', 's092', 'u092', 1, 0, 0, 0, '2020-12-30 08:12:12'),
('20201230', 's093', 'u093', 1, 1, 1, 700, '2020-12-30 08:12:12'),
('20201231', 's094', 'u094', 1, 1, 1, 789, '2020-12-31 08:12:12'),
('20201231', 's095', 'u095', 1, 1, 1, 600, '2020-12-31 08:12:12'),
('20201231', 's096', 'u096', 1, 1, 0, 0, '2020-12-31 08:12:12')
;
--创建核额流水表
drop table if exists check_t;
create table check_t (
sno string comment '流水号', uid string,
is_risk_apply bigint, is_pass_rule bigint, is_obtain_qutoa bigint, quota decimal(30,6), update_time string
) partitioned by (ds string comment '日期分区');
--动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict; insert overwrite table check_t partition (ds) select sno,
uid, is_risk_apply, is_pass_rule, is_obtain_qutoa, quota, update_time,
ds
from check_view;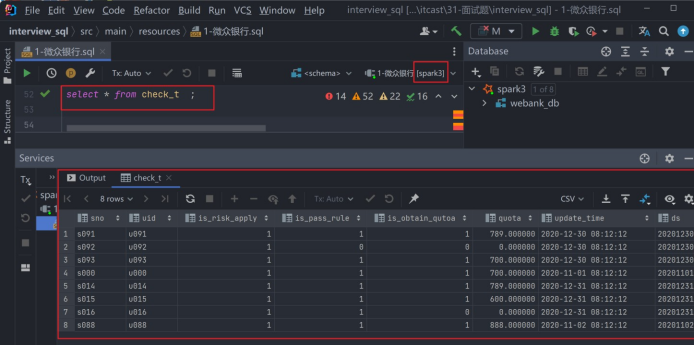
-- 创 建 借 据 表
create table debt(
duebill_id string comment '借据号',
uid string, prod_type string, putout_date string, putout_amt decimal(30, 6),
balance decimal(30, 6), is_buliang int, overduedays int
)partitioned by (ds string comment '日期分区');
--资料提供了一个34899条借据数据的文件
--下面补充如何将文件的数据导入到分区表中。需要一个中间普通表过度。drop table if exists webank_db.debt_temp;
create table webank_db.debt_temp(
duebill_id string comment '借据号', uid string,
prod_type string,
putout_date string, putout_amt decimal(30, 6),
balance decimal(30,6),
is_buliang int, overduedays int,
ds string comment '日期分区'
) row format delimited fields terminated by '\t';
load data local inpath '/root/debt.txt' overwrite into table webank_db.debt_temp;--动态分区需要设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table webank_db.debt partition (ds)
select from webank_db.debt_temp;--技巧:如果查询debt表,由于分区数太多,导致查询很慢。
-- 开发阶段,我们可以事先将表缓存起来,并且降低分区数比如为6,那么查缓存表大大提升了开发效率。
-- 上线阶段,再用实际表替换缓存表。
--首次缓存会耗时慢
cache table cache_debt as select /+ coalesce(6) / from
debt;
--第二次使用缓存会很快
select count() from cache_debt;
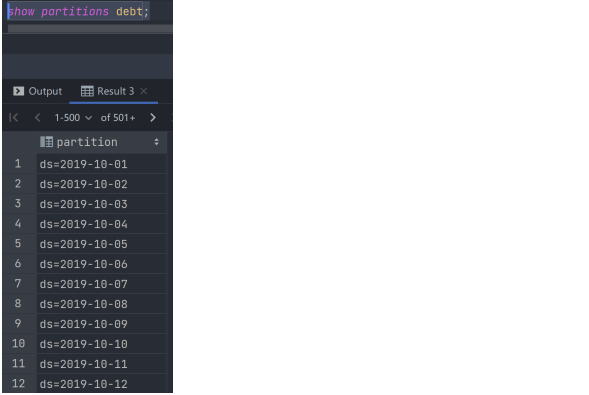
select ds,count(1) from cache_debt group by ds;
先了解表数据的分布情况,有2年多,每天都有分区,共760多个分区。

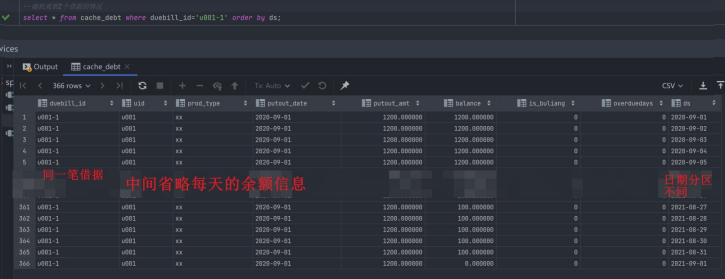
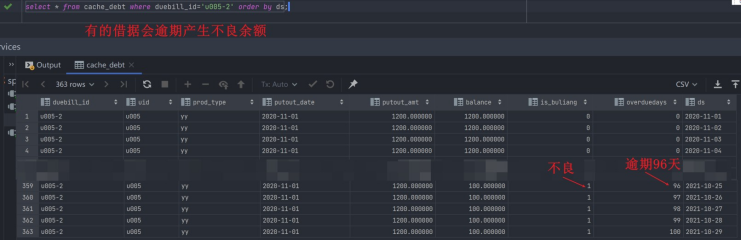
随机观察2个借据的情况
思路分析
方案1
假设当天是20201231,昨日是20201230
预先将复用分数据集缓存起来,只用加载一次源表。后面多次union all起来。cache table仅Spark支持,hive不支持。
方案2
借用stack函数,性能与方案1一样 ,都只加载一次表。
答案获取
建议你先动脑思考,动手写一写再对照看下答案,如果实在不懂可以点击下方卡片,回复:大厂sql 即可。
参考答案适用HQL,SparkSQL,FlinkSQL,即大数据组件,其他SQL需自行修改。
加技术群讨论
点击下方卡片关注 联系我进群
或者直接私信我进群
微众银行源数据表附录:
- 核额流水表
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101,每个分区有全量流水 | string |
| sno | 每个ds内主键,流水号 | string |
| uid | 户id | string |
| is_risk_apply | 是否核额申请(核额漏斗第一步)取值0和1 | bigint |
| is_pass_rule | 是否通过规则(核额漏斗第二步)取值0和1 | bigint |
| is_obtain_qutoa | 是否授信成功(核额漏斗第三步)取值0和1 | bigint |
| quota | 授信金额 | decimal(30,6) |
| update_time | 更新时间样例格式为2020-11-14 08:12:12 | string |
- 借据表
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101每个分区有全量借据 | strng |
| duebilid | 借据号(每个日期分区内的主键) | strng |
| uid | 用户id | string |
| prod_type | 产品名称仅3个枚举值XX贷YY贷ZZ贷 | string |
| putout_date | 发放日期样例格式为2020-10-10 00:10:30 | bigint |
| putout_amt | 发放金额 | decimal(30,6) |
| balance | 借据余额 | decimal(30,6) |
| is_buliang | 状态-是否不良取值0和1 | bigint |
| overduedays | 逾期天数 | bigint |
- 模型输出表
| 字段名 | 字段意义 | 字段类型 |
|---|---|---|
| ds | 日期分区,样例格式为20200101增量表部分流水记录可能有更新 | strng |
| sno | 流水号,主键 | strng |
| create time | 创建日期样例格式为2020-10-10 00:10:30与sno唯一绑定,不会变更 | strng |
| uid | 用户id | strng |
| content | son格式key值名称为V01~V06,value值取值为0和1 | strng |
| create_time | 更新日期样例格式为2020-10-1000:10:30 | strng |
文末SQL小技巧
提高SQL功底的思路。
1、造数据。因为有数据支撑,会方便我们根据数据结果去不断调整SQL的写法。
造数据语法既可以create table再insert into,也可以用下面的create temporary view xx as values语句,更简单。
其中create temporary view xx as values语句,SparkSQL语法支持,hive不支持。
2、先将结果表画出来,包括结果字段名有哪些,数据量也画几条。这是分析他要什么。
从源表到结果表,一路可能要走多个步骤,其实就是可能需要多个子查询,过程多就用with as来重构提高可读性。
3、要由简单过度到复杂,不要一下子就写一个很复杂的。
先写简单的select from table…,每个中间步骤都执行打印结果,看是否符合预期, 根据中间结果,进一步调整修饰SQL语句,再执行,直到接近结果表。
4、数据量要小,工具要快,如果用hive,就设置set hive.exec.mode.local.auto=true;如果是SparkSQL,就设置合适的shuffle并行度,set spark.sql.shuffle.partitions=4;
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12182595.html
相关文章:
每天一道大厂SQL题【Day11】微众银行真题实战(一)
每天一道大厂SQL题【Day11】微众银行真题实战(一) 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…...
 -- 不可不知的开发术语)
Cosmos 基础教程(一) -- 不可不知的开发术语
CometBFT DOC 您可以在本节中找到几个技术术语的概述,包括每个术语的解释和进一步资源的链接——在使用Cosmos SDK进行开发时,所有这些都是必不可少的。 在本节中,您将了解以下术语: Cosmos and Interchain LCD RPC Protobuf -协议缓冲…...

JAVA JDK 常用工具类和工具方法
目录 Pair与Triple Lists.partition-将一个大集合分成若干 List集合操作的轮子 对象工具Objects 与ObjectUtils 字符串工具 MapUtils Assert断言 switch语句 三目表达式 IOUtils MultiValueMap MultiMap JAVA各个时间类型的转换(LocalDate与Date类型&a…...
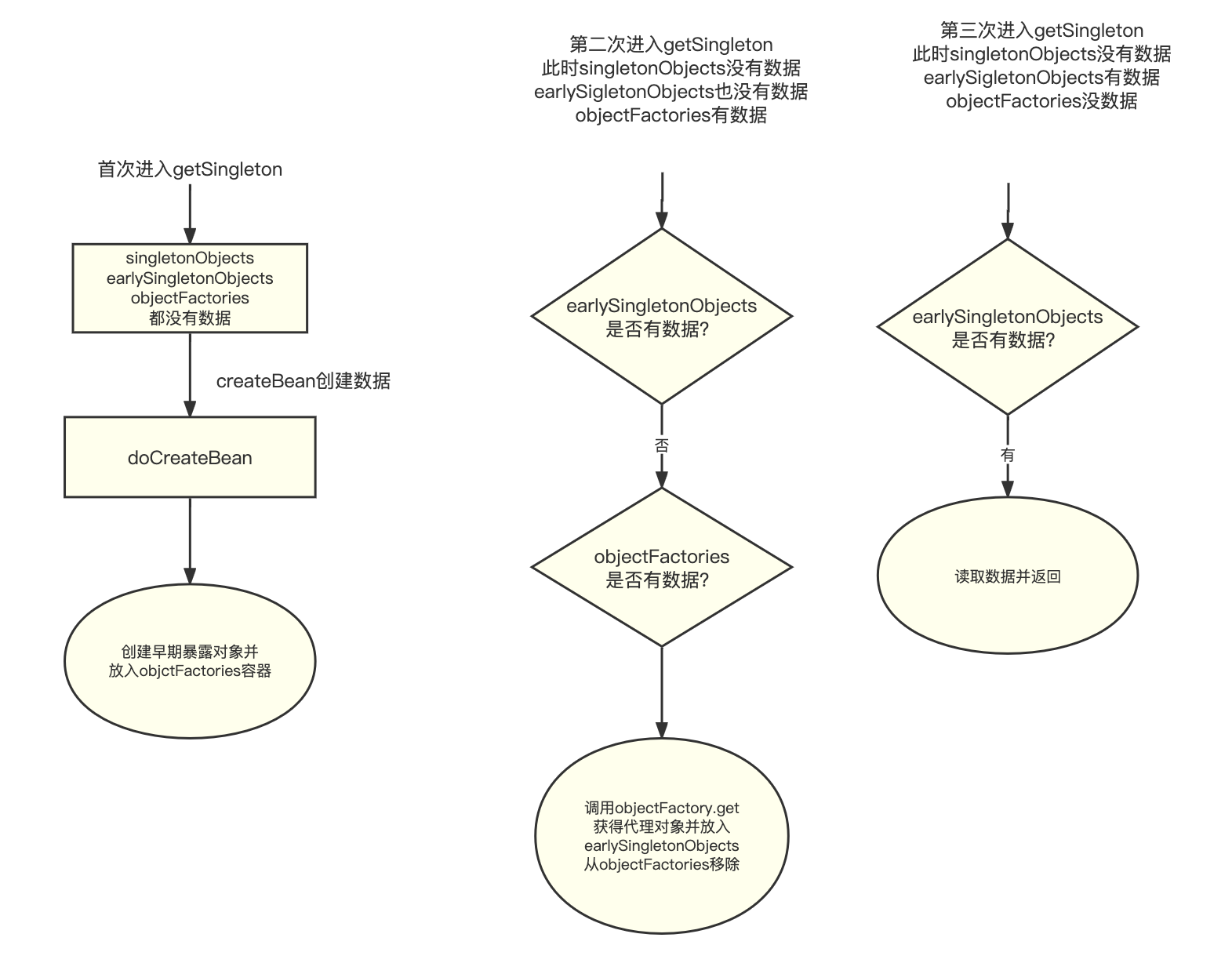
Spring Bean循环依赖
解决SpringBean循环依赖为什么需要3级缓存?回答:1级Map保存单例bean。2级Map 为了保证产生循环引用问题时,每次查询早期引用对象,都拿到同一个对象。3级Map保存ObjectFactory对象。数据结构1级Map singletonObjects2级Map earlySi…...
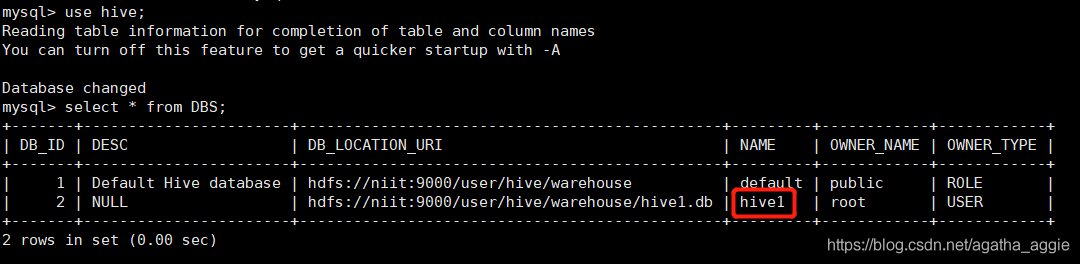
Hive 2.3.0 安装部署(mysql 8.0)
Hive安装部署 一.Hive的安装 1、下载apache-hive-2.3.0-bin.tar.gz 可以自行下载其他版本:http://mirror.bit.edu.cn/apache/hive/ 2.3.0版本链接:https://pan.baidu.com/s/18NNVdfOeuQzhnOHVcFpnSw 提取码:xc2u 2、用mobaxterm或者其他连接…...

IPD术语表
简称英文全称中文ABPannual business plan年度商业计划ABCactivity -based costing基于活动的成本估算ABMactivity -based management基于活动的管理ADCPavailability decision check point可获得性决策评审点AFDanticipatory failure determination预防错误决定AMEadvanced ma…...

目标检测损失函数 yolos、DETR为例
yolos和DETR,除了yolos没有卷积层以外,几乎所有操作都一样。 HF官方文档 因为目标检测模型,实际会输出几百几千个“框”,所以损失函数计算比较复杂。损失函数为偶匹配损失 bipartite matching loss,参考此blog targe…...
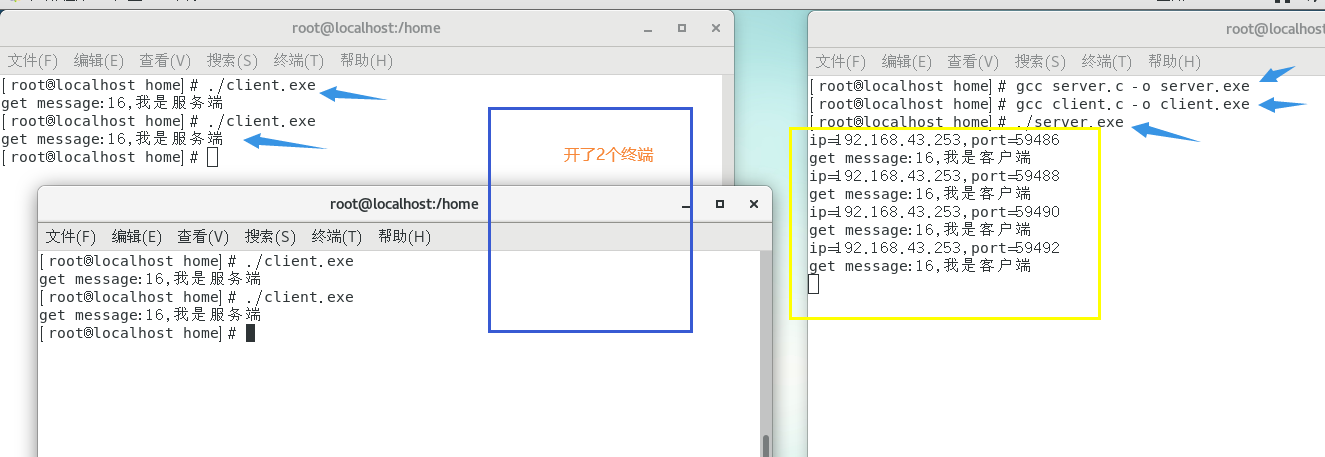
linux系统编程2--网络编程socket
在linux系统编程中网络编程是使用socket(套接字),socket这个词可以表示很多概念:在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通讯中的一个进程,“IP地址端口号”就称为socket。在TCP协议中&#…...

FPGA纯Verilog实现任意尺寸图像缩放,串口指令控制切换,贴近真实项目,提供工程源码和技术支持
目录1、前言2、目前主流的FPGA图像缩放方案3、本方案的优越性4、详细设计方案5、vivado工程详解6、上板调试验证并演示7、福利:工程源码获取1、前言 代码使用纯verilog实现,没有任何ip,可在Xilinx、Intel、国产FPGA间任意移植; 图…...
| 代码+思路+重要知识点)
华为OD机试题 - 最长合法表达式(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

L1-005 考试座位号
L1-005 考试座位号 每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试…...

Obsidian + remotely save + 坚果云:实现电脑端和手机端的同步
写在前面:近年来某象笔记广告有增无减,不堪其扰,便转投其它笔记,Obsidian、OneNote、Notion、flomo都略有使用,本人更偏好obsidian操作简单,然其官方同步资费甚高,囊中羞涩,所幸可通…...
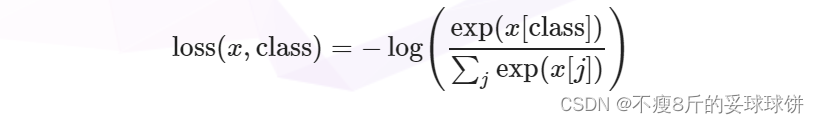
对比学习MoCo损失函数infoNCE理解(附代码)
MoCo loss计算采用的损失函数是InfoNCE: 下面是MoCo的伪代码,MoCo这个loss的实现就是基于cross entropy loss。 将k作为q的正样本,因为k与q是来自同一张图像的不同视图;将queue作为q的负样本,因为queue中含有大量…...
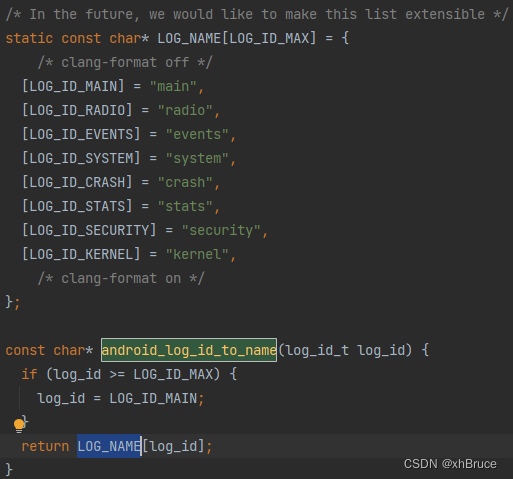
logd守护进程
logd守护进程1、adb logcat命令2、logd守护进程启动2.1 logd文件目录2.2 main方法启动3、LogBuffer缓存大小3.1 缓存大小优先级设置3.2 缓存大小相关代码位置android12-release1、adb logcat命令 命令功能adb bugreport > bugreport.txtbugreport 日志adb shell dmesg >…...
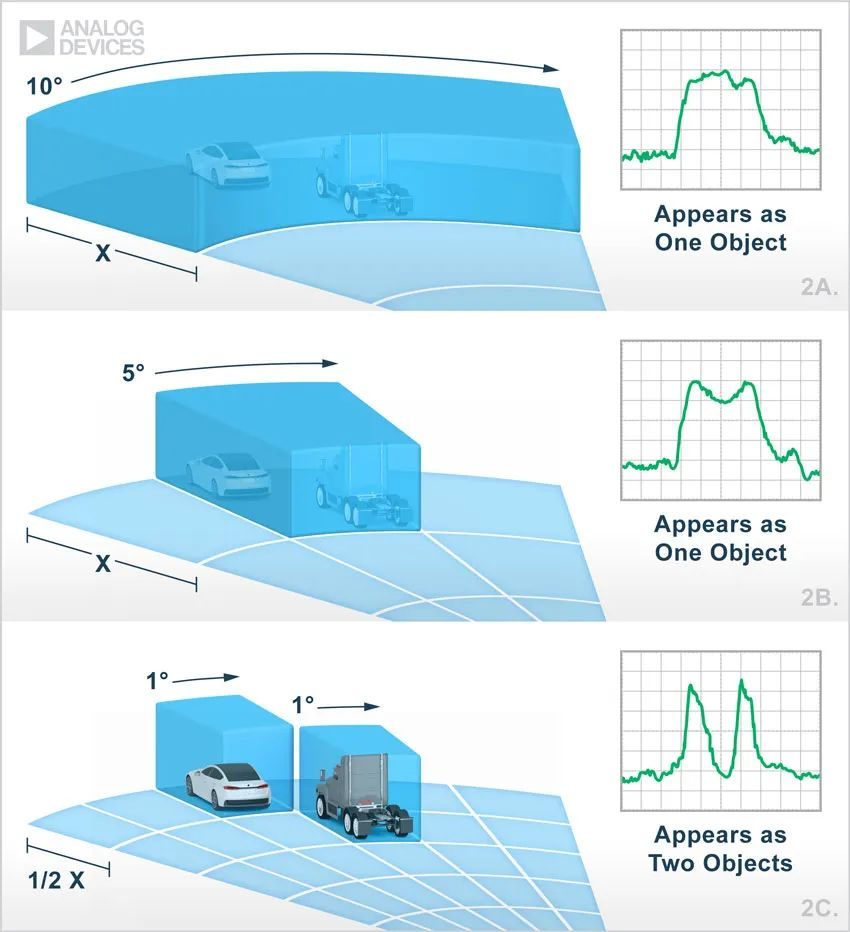
【汽车雷达通往自动驾驶的关键技术】
本文编辑:调皮哥的小助理 现代汽车雷达装置比手机还小,能探测前方、后方或侧方的盲点位置是否存在障碍物,但这还不百分之百实现全自动驾驶的。传统的汽车雷达分辨率都不高,只能“看到”一团东西,可以检测到汽车周围存在…...

2023实习面经
实习面经 秋招笔试面试全记录 字节-电商 字节实习一面: 二分类的损失函数是什么,怎么算?多分类的损失函数怎么算?如果文本分类的标签有多个,比如一个文本同时属于多个label那怎么办?如果文本分类里面的…...

linux shell 入门学习笔记2shell脚本
什么是shell脚本 当命令或者程序语句写在文件中,我们执行文件,读取其中的代码,这个程序就称之为shell脚本。 有了shell脚本肯定是要有对应的解释器了,常见的shell脚本解释器有sh、python、perl、tcl、php、ruby等。一般这种使用文…...
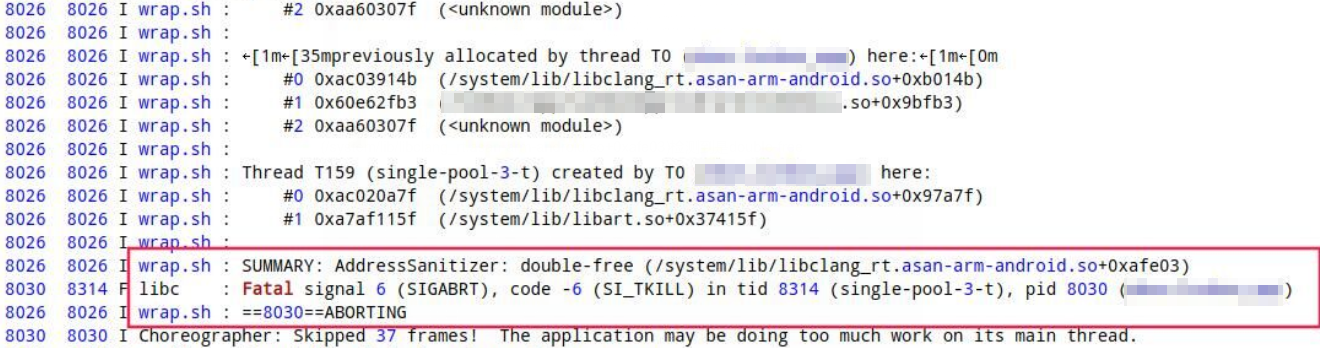
Android稳定性系列-01-使用 Address Sanitizer检测原生代码中的内存错误
前言想必大家曾经被各种Native Crash折磨过,本地测试没啥问题,一到线上或者自动化测试就出现各种SIGSEGV、SIGABRT、SIGILL、SIGBUS、SIGFPE异常,而且堆栈还是崩溃到libc.so这种,看起来跟我们的代码没啥关系,关键还不好…...

HyperOpt-quniform 范围问题
在使用 quniform 的时候,可能会出现超出指定范围的值,例如对于 GBDT 设置参数空间为 learning_rate:hp.quniform(learning_rate,0.05,2.05,0.2),但是仍然会报错 ValueError: learning_rate must be greater than 0 but was 0.0,但…...

Pycharm搭建一个Django项目
File->new project 点击create, 等待一下即可 查看安装 Django 版本: 在 Pycharm 底部选择 Terminal 然后在里面输入:python -m django --version 启动项目: 在 Terminal 里面输入: python manage.py runserver 查看文件目…...
)
数字电子技术实验(高效学习指南)
1. 数字电子技术实验的痛点与突破方向 第一次接触数字电子技术实验的同学,常常会遇到这样的困境:面对实验箱上密密麻麻的芯片和导线不知所措,实验指导书上的原理图看了半天还是云里雾里,等到终于摸清门道时却发现下课铃已经响起。…...
阿里Live Avatar数字人:从部署到生成视频的完整流程
阿里Live Avatar数字人:从部署到生成视频的完整流程 1. 引言:认识Live Avatar数字人 Live Avatar是阿里巴巴联合高校开源的一款先进数字人视频生成模型。这个强大的工具可以将静态图片、音频和文字描述转化为生动的数字人视频,实现逼真的口…...

MacOS下Homebrew国内源配置全攻略:阿里、清华、中科大镜像一键切换
1. 为什么需要切换Homebrew国内镜像源? 如果你经常在MacOS上使用Homebrew安装软件,大概率遇到过下载速度慢到让人抓狂的情况。我刚开始用brew安装Python时,眼睁睁看着进度条像蜗牛爬行,一个200MB的包下了半小时还没完。后来才发现…...

带行星传动装置的电动螺旋拆卸器设计【说明书 cad图纸 solidworks三维】
在机械维修与设备拆解领域,传统工具常因扭矩不足或操作空间受限,导致螺栓卡滞、部件损坏等问题。带行星传动装置的电动螺旋拆卸器通过集成行星齿轮系统与电动驱动模块,有效解决了这一痛点。其核心作用在于利用行星齿轮的行星轮系结构…...
)
天地图性能优化实践:uniapp中用leaflet实现百万级点位渲染(附动态加载方案)
百万级点位地图渲染优化:uniappleaflet性能提升全方案 在移动应用开发中,地图功能已成为许多应用的核心组件。当面对海量点位数据时,传统渲染方式往往导致应用卡顿、内存飙升甚至崩溃。本文将深入探讨uniapp框架下结合leaflet地图库实现百万级…...

东莞故意伤害罪律师在线咨询
在东莞遇到故意伤害罪相关法律问题,别慌!广东秦仪律师团队为您提供专业且贴心的在线咨询服务。我们拥有经验丰富的律师,他们不仅是广东省律师协会会员,还在法律领域深耕多年,有着扎实的法律知识和丰富的实战经验。曾在…...

DeOldify在档案修复中的应用:老照片数字化上色企业落地实战案例
DeOldify在档案修复中的应用:老照片数字化上色企业落地实战案例 1. 引言:当黑白记忆遇见彩色未来 想象一下,你手里有一张泛黄的黑白老照片,那是你爷爷年轻时的样子。照片里的他意气风发,但黑白影像总让人觉得少了点什…...

使用openclaw龙虾采集电商数据
最近openclaw养龙虾的热潮带动了skill的爆发,github上各种skill层出不穷,可以解决繁杂的办公自动化任务,比如生成ppt、运营媒体账号、审查代码等,skill已经成为ai时代的“万能软件”。 刚好有个朋友是做跨境3D打印业务࿰…...

TypeScript类型体操进阶:复杂场景类型推导实战
TypeScript类型体操进阶:复杂场景类型推导实战 在中大型前端项目中,TypeScript的静态类型检查已经成为保障代码健壮性的核心手段。但随着业务复杂度提升,简单的基础类型和接口声明已无法满足动态场景的类型约束需求——比如表单数据的动态校验…...

7个OpenClaw+Phi-3-vision-128k-instruct实用场景:从学术研究到内容创作
7个OpenClawPhi-3-vision-128k-instruct实用场景:从学术研究到内容创作 1. 引言:当多模态模型遇上自动化框架 第一次看到Phi-3-vision-128k-instruct模型解析PDF论文中的图表并生成完整分析报告时,我就意识到这不再是简单的"看图说话&…...