目标检测损失函数 yolos、DETR为例
yolos和DETR,除了yolos没有卷积层以外,几乎所有操作都一样。
HF官方文档
因为目标检测模型,实际会输出几百几千个“框”,所以损失函数计算比较复杂。损失函数为偶匹配损失 bipartite matching loss,参考此blog
target为class_label和box组成的字典。假设对于一张图片,我们有5个target框。
num_detection_tokens为模型对一张图最多可以产生的box的数量
简单阐述loss计算流程
-
vit 模型,输入经过预处理的图片,输出最后隐含层状态, 大小为 [batchsize,seq_len,hidden_size]
-
取最后num_detection_tokens个token的隐藏状态,变为
[batchsize,num_detection_tokens,hidden_size] -
由于输出了num_detection_tokens个box,而target为5个box,所以需要进行一对一的匹配,
-
匹配过程:
- 先计算3个cost矩阵,shape均为【num_detection_tokens,num_target_box】,矩阵元素代表loss,矩阵代表对所有pred和target之间两两计算一次loss。
- 3个cost矩阵分别代表标签loss(交叉熵损失)、坐标loss(表示一个框的4个值的L1损失)、GIoU loss(框与框之间计算GIoU)
- 三个cost矩阵加权得到总体cost矩阵,大小为【num_detection_tokens,num_target_box】
- 对此矩阵进行linear_sum_assignment操作,得到一个匹配,此匹配下cost最小(即cost矩阵中找到不同行且不同列的5个元素,这5个元素之和最小)。匹配表示为长度为min(num_detection_tokens,num_target_box)的索引对。本例长度为5。
-
根据此匹配,pred和target之间计算一次loss(本例中一共计算5次loss并求和),最重loss就是上面说的3种loss的加权和
-
其实还有两种loss:
- “cardinality” loss,表示输出的num_detection_tokens个class_label中,class_label不为“无目标”的个数,与num_target_box的个数,的L1 loss. 说白了就是,除了5个框有实际的class以外,其他框应尽可能分类为“无目标”,避免检测出来目标过多。但之一loss不产生梯度,仅仅用于评估。
- mask loss:功能暂时不清楚
官方匹配函数,匈牙利算法
# Copied from transformers.models.detr.modeling_detr.DetrHungarianMatcher with Detr->Yolos
class YolosHungarianMatcher(nn.Module):"""This class computes an assignment between the targets and the predictions of the network.For efficiency reasons, the targets don't include the no_object. Because of this, in general, there are morepredictions than targets. In this case, we do a 1-to-1 matching of the best predictions, while the others areun-matched (and thus treated as non-objects).Args:class_cost:The relative weight of the classification error in the matching cost.bbox_cost:The relative weight of the L1 error of the bounding box coordinates in the matching cost.giou_cost:The relative weight of the giou loss of the bounding box in the matching cost."""def __init__(self, class_cost: float = 1, bbox_cost: float = 1, giou_cost: float = 1):super().__init__()requires_backends(self, ["scipy"])self.class_cost = class_costself.bbox_cost = bbox_costself.giou_cost = giou_costif class_cost == 0 and bbox_cost == 0 and giou_cost == 0:raise ValueError("All costs of the Matcher can't be 0")@torch.no_grad()def forward(self, outputs, targets):"""Args:outputs (`dict`):A dictionary that contains at least these entries:* "logits": Tensor of dim [batch_size, num_queries, num_classes] with the classification logits* "pred_boxes": Tensor of dim [batch_size, num_queries, 4] with the predicted box coordinates.targets (`List[dict]`):A list of targets (len(targets) = batch_size), where each target is a dict containing:* "class_labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number ofground-truthobjects in the target) containing the class labels* "boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates.Returns:`List[Tuple]`: A list of size `batch_size`, containing tuples of (index_i, index_j) where:- index_i is the indices of the selected predictions (in order)- index_j is the indices of the corresponding selected targets (in order)For each batch element, it holds: len(index_i) = len(index_j) = min(num_queries, num_target_boxes)"""batch_size, num_queries = outputs["logits"].shape[:2]# We flatten to compute the cost matrices in a batchout_prob = outputs["logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]# Also concat the target labels and boxestarget_ids = torch.cat([v["class_labels"] for v in targets])target_bbox = torch.cat([v["boxes"] for v in targets])# Compute the classification cost. Contrary to the loss, we don't use the NLL,# but approximate it in 1 - proba[target class].# The 1 is a constant that doesn't change the matching, it can be ommitted.class_cost = -out_prob[:, target_ids]# Compute the L1 cost between boxesbbox_cost = torch.cdist(out_bbox, target_bbox, p=1)# Compute the giou cost between boxesgiou_cost = -generalized_box_iou(center_to_corners_format(out_bbox), center_to_corners_format(target_bbox))# Final cost matrixcost_matrix = self.bbox_cost * bbox_cost + self.class_cost * class_cost + self.giou_cost * giou_costcost_matrix = cost_matrix.view(batch_size, num_queries, -1).cpu()sizes = [len(v["boxes"]) for v in targets]indices = [linear_sum_assignment(c[i]) for i, c in enumerate(cost_matrix.split(sizes, -1))]return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
目标检测还有很多细节问题,以后更新
相关文章:

目标检测损失函数 yolos、DETR为例
yolos和DETR,除了yolos没有卷积层以外,几乎所有操作都一样。 HF官方文档 因为目标检测模型,实际会输出几百几千个“框”,所以损失函数计算比较复杂。损失函数为偶匹配损失 bipartite matching loss,参考此blog targe…...
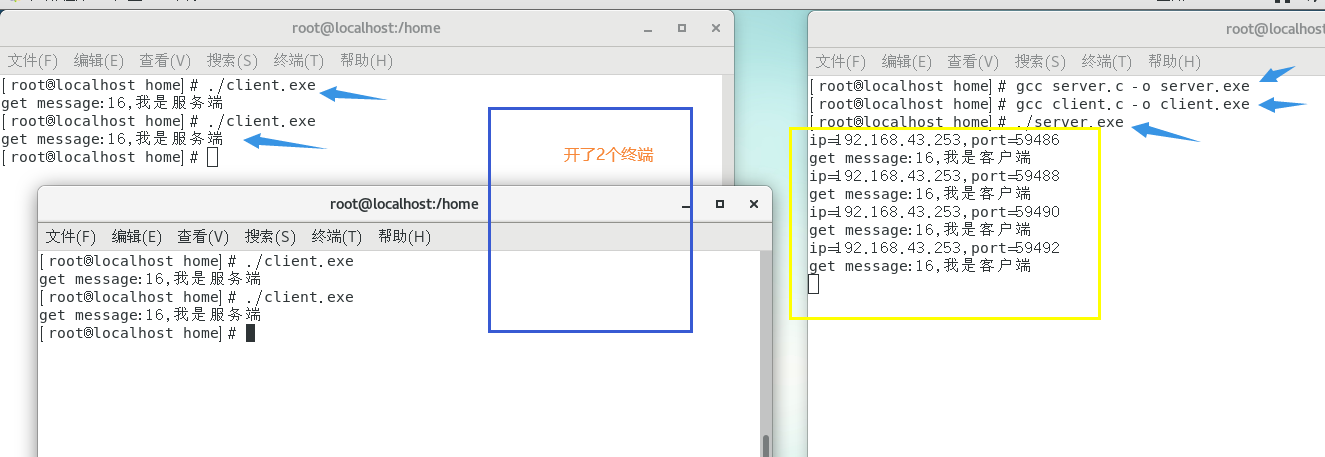
linux系统编程2--网络编程socket
在linux系统编程中网络编程是使用socket(套接字),socket这个词可以表示很多概念:在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通讯中的一个进程,“IP地址端口号”就称为socket。在TCP协议中&#…...

FPGA纯Verilog实现任意尺寸图像缩放,串口指令控制切换,贴近真实项目,提供工程源码和技术支持
目录1、前言2、目前主流的FPGA图像缩放方案3、本方案的优越性4、详细设计方案5、vivado工程详解6、上板调试验证并演示7、福利:工程源码获取1、前言 代码使用纯verilog实现,没有任何ip,可在Xilinx、Intel、国产FPGA间任意移植; 图…...
| 代码+思路+重要知识点)
华为OD机试题 - 最长合法表达式(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

L1-005 考试座位号
L1-005 考试座位号 每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试…...

Obsidian + remotely save + 坚果云:实现电脑端和手机端的同步
写在前面:近年来某象笔记广告有增无减,不堪其扰,便转投其它笔记,Obsidian、OneNote、Notion、flomo都略有使用,本人更偏好obsidian操作简单,然其官方同步资费甚高,囊中羞涩,所幸可通…...
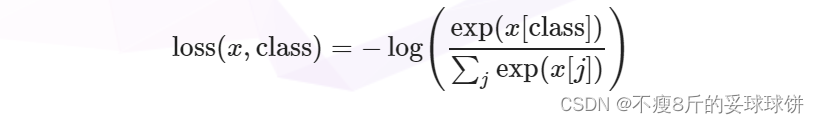
对比学习MoCo损失函数infoNCE理解(附代码)
MoCo loss计算采用的损失函数是InfoNCE: 下面是MoCo的伪代码,MoCo这个loss的实现就是基于cross entropy loss。 将k作为q的正样本,因为k与q是来自同一张图像的不同视图;将queue作为q的负样本,因为queue中含有大量…...
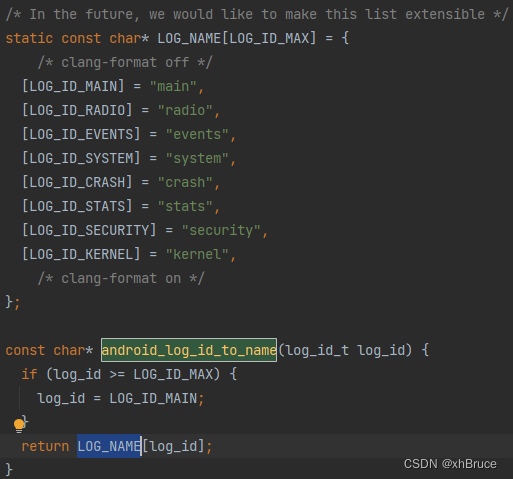
logd守护进程
logd守护进程1、adb logcat命令2、logd守护进程启动2.1 logd文件目录2.2 main方法启动3、LogBuffer缓存大小3.1 缓存大小优先级设置3.2 缓存大小相关代码位置android12-release1、adb logcat命令 命令功能adb bugreport > bugreport.txtbugreport 日志adb shell dmesg >…...
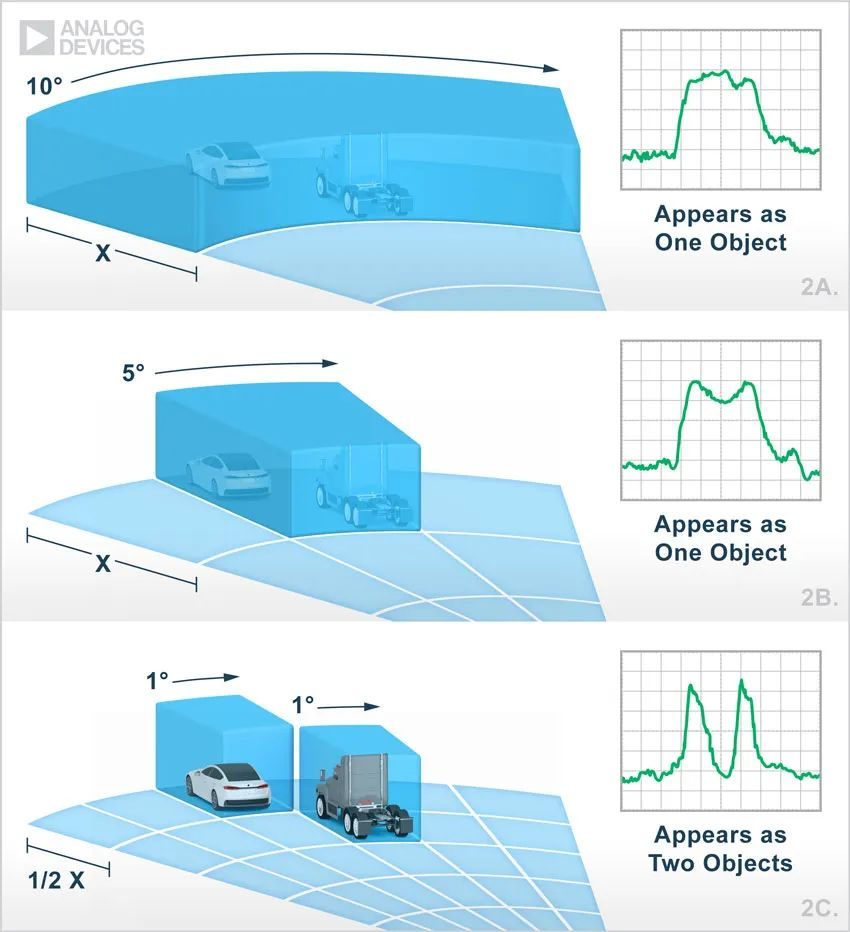
【汽车雷达通往自动驾驶的关键技术】
本文编辑:调皮哥的小助理 现代汽车雷达装置比手机还小,能探测前方、后方或侧方的盲点位置是否存在障碍物,但这还不百分之百实现全自动驾驶的。传统的汽车雷达分辨率都不高,只能“看到”一团东西,可以检测到汽车周围存在…...

2023实习面经
实习面经 秋招笔试面试全记录 字节-电商 字节实习一面: 二分类的损失函数是什么,怎么算?多分类的损失函数怎么算?如果文本分类的标签有多个,比如一个文本同时属于多个label那怎么办?如果文本分类里面的…...

linux shell 入门学习笔记2shell脚本
什么是shell脚本 当命令或者程序语句写在文件中,我们执行文件,读取其中的代码,这个程序就称之为shell脚本。 有了shell脚本肯定是要有对应的解释器了,常见的shell脚本解释器有sh、python、perl、tcl、php、ruby等。一般这种使用文…...
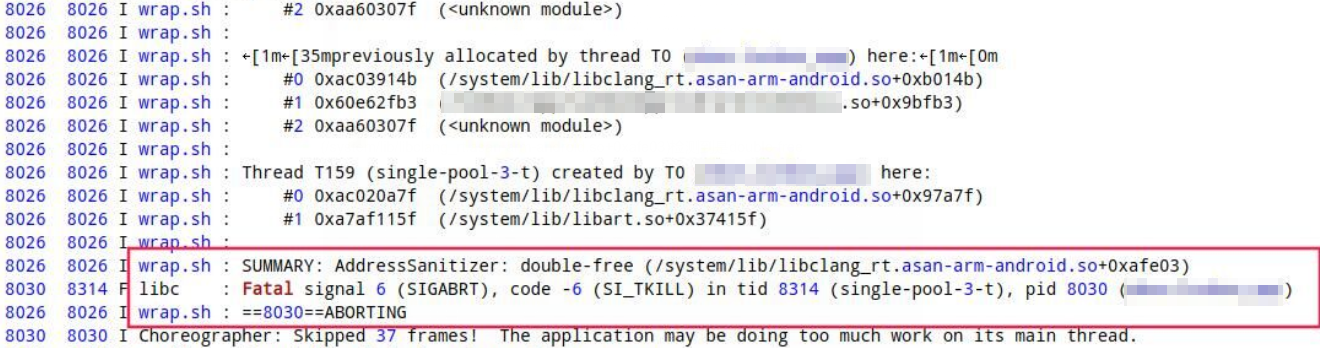
Android稳定性系列-01-使用 Address Sanitizer检测原生代码中的内存错误
前言想必大家曾经被各种Native Crash折磨过,本地测试没啥问题,一到线上或者自动化测试就出现各种SIGSEGV、SIGABRT、SIGILL、SIGBUS、SIGFPE异常,而且堆栈还是崩溃到libc.so这种,看起来跟我们的代码没啥关系,关键还不好…...

HyperOpt-quniform 范围问题
在使用 quniform 的时候,可能会出现超出指定范围的值,例如对于 GBDT 设置参数空间为 learning_rate:hp.quniform(learning_rate,0.05,2.05,0.2),但是仍然会报错 ValueError: learning_rate must be greater than 0 but was 0.0,但…...

Pycharm搭建一个Django项目
File->new project 点击create, 等待一下即可 查看安装 Django 版本: 在 Pycharm 底部选择 Terminal 然后在里面输入:python -m django --version 启动项目: 在 Terminal 里面输入: python manage.py runserver 查看文件目…...

浅析前端工程化中的一部曲——模块化
在日益复杂和多元的 Web 业务背景下,前端工程化经常会被提及。工程化的目的是高性能、稳定性、可用性、可维护性、高效协同,只要是以这几个角度为目标所做的操作,都可成为工程化的一部分。工程化是软件工程中的一种思想,当下的工程…...

新版bing(集成ChatGPT)申请通过后在谷歌浏览器(Chrome)上的使用方法
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…...
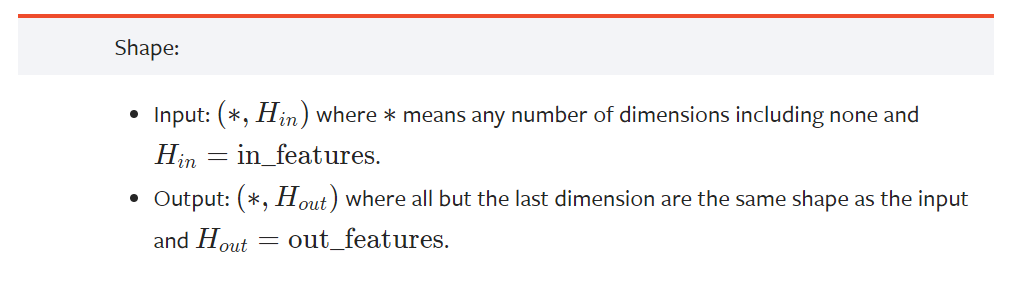
Time-distributed 的理解
前言 今天看到论文中用到 Time-distributed CNN,第一次见到 Time-distributed,不理解是什么含义,看到代码实现也很懵。不管什么网络结构,外面都能套一个TimeDistributed。看了几个博客,还是不明白,问了问C…...

matlab 计算矩阵的Moore-Penrose 伪逆
目录 一、Moore-Penrose 伪逆1、主要函数2、输入输出参数二、代码示例使用伪逆求解线性方程组一、Moore-Penrose 伪逆 Moore-Penrose 伪逆是一种矩阵,可在不存在逆矩阵的情况下作为逆矩阵的部分替代。此矩阵常被用于求解没有唯一解或有许多解的线性方程组。 对于任何矩阵…...

简历制作方面的经验与建议
专栏推荐:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 专栏首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 专栏内容: 笔试复盘篇 2023秋招过程中整理的笔试题,来源包括我自己求职笔试以及整理其他同学的笔试。包含华为、中兴、联发科、AMD、大…...

C语言--static、const、volatile关键字
Static static修饰局部变量改变了变量的生命周期,让静态局部变量出了作用域依然存在,到程序结束,生命周期才结束。 static 修饰局部变量 改变局部变量的生命周期,本质上是改变了局部变量的存储位置,让局部变量不再是…...

StructBERT中文语义匹配实战:Kubernetes集群中StructBERT服务弹性伸缩配置
StructBERT中文语义匹配实战:Kubernetes集群中StructBERT服务弹性伸缩配置 在自然语言处理的实际应用中,语义相似度判断是一个高频且核心的需求。无论是智能客服中的问题匹配、内容平台上的文本查重,还是知识库里的同义句检索,都…...

CYBER-VISION智能助盲系统部署指南:Dify平台保姆级教学
CYBER-VISION智能助盲系统部署指南:Dify平台保姆级教学 1. 项目背景与核心价值 CYBER-VISION智能助盲系统是一款基于YOLO分割算法的高精度目标识别工具,专为视障人群设计。系统通过实时解构视觉信号,将周围环境转化为可理解的导航信息&…...

WeChatExporter数据备份安全指南:微信聊天记录完整导出解决方案
WeChatExporter数据备份安全指南:微信聊天记录完整导出解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 数据丢失的风险与应对 2023年某科技公司员工…...

Intv_AI_MK11深入LSTM时间序列预测:模型原理与代码实现详解
Intv_AI_MK11深入LSTM时间序列预测:模型原理与代码实现详解 1. 为什么需要LSTM? 时间序列数据在我们的生活中无处不在——股票价格波动、天气变化、设备传感器读数...这些数据都有一个共同特点:当前时刻的值往往与过去一段时间的值相关。传…...

seo网络公司如何进行外链建设
SEO网络公司如何进行外链建设 在当今数字营销的世界里,外链建设是一个至关重要的环节。对于SEO网络公司来说,如何高效、合规地进行外链建设,不仅能提升网站的权重,还能带来更多的流量和业务机会。本文将深入探讨SEO网络公司如何进…...

STM8单片机外部晶振配置与故障排查指南
1. STM8单片机外部晶振配置基础STM8系列单片机作为意法半导体推出的8位微控制器,在工业控制、消费电子等领域应用广泛。其时钟系统设计灵活,支持内部RC振荡器和外部晶振两种时钟源。当我们需要更高精度的时钟信号或更高的工作频率时,通常会选…...

STC8H8K32U工控板 电机正反转
本文摘要: 该代码实现了一个基于STC8H单片机的自动化控制系统,主要功能包括: 通过I2C接口驱动OLED显示屏,显示"气缸前进/后退"、"电机前进/停止"等状态信息 控制4路气缸(前/后气缸的进/退)和…...

Ostrakon-VL像素特工部署实战:Python入门者的3步环境搭建指南
Ostrakon-VL像素特工部署实战:Python入门者的3步环境搭建指南 1. 为什么选择Ostrakon-VL 如果你刚接触Python又想尝试AI图像处理,Ostrakon-VL是个不错的起点。这个模型特别适合处理图像扫描和基础视觉任务,对硬件要求不高,部署过…...

程序员转型AI:大模型时代算法工程师的三种发展路径
程序员转型AI:大模型时代算法工程师的三种发展路径时代变了:从"稀缺资源"到"工业级生产资料" 在没有大模型的时代(其实也就两三年前),算法工程师是干嘛的?那时候,模型是&qu…...

推荐6款AI论文降重工具,智能改写提升原创度,减少重复率。
开头总结工具对比(技能4) �� 根据实际使用案例分析,从处理效率、降重能力和核心功能三个关键指标对六款主流AI论文辅助平台进行横向评测,结果显示各平台在文本处理速度、重复率降低幅度及特色功能方面存在显…...