生成式AI系列 —— DCGAN生成手写数字
1、模型构建
1.1 构建生成器
# 导入软件包
import torch
import torch.nn as nnclass Generator(nn.Module):def __init__(self, z_dim=20, image_size=256):super(Generator, self).__init__()self.layer1 = nn.Sequential(nn.ConvTranspose2d(z_dim, image_size * 32,kernel_size=4, stride=1),nn.BatchNorm2d(image_size * 32),nn.ReLU(inplace=True))self.layer2 = nn.Sequential(nn.ConvTranspose2d(image_size * 32, image_size * 16,kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(image_size * 16),nn.ReLU(inplace=True))self.layer3 = nn.Sequential(nn.ConvTranspose2d(image_size * 16, image_size * 8,kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(image_size * 8),nn.ReLU(inplace=True))self.layer4 = nn.Sequential(nn.ConvTranspose2d(image_size * 8, image_size *4,kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(image_size * 4),nn.ReLU(inplace=True))self.layer5 = nn.Sequential(nn.ConvTranspose2d(image_size * 4, image_size * 2,kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(image_size * 2),nn.ReLU(inplace=True))self.layer6 = nn.Sequential(nn.ConvTranspose2d(image_size * 2, image_size,kernel_size=4, stride=2, padding=1),nn.BatchNorm2d(image_size),nn.ReLU(inplace=True))self.last = nn.Sequential(nn.ConvTranspose2d(image_size, 3, kernel_size=4,stride=2, padding=1),nn.Tanh())# 注意:因为是黑白图像,所以只有一个输出通道def forward(self, z):out = self.layer1(z)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.layer5(out)out = self.layer6(out)out = self.last(out)return outif __name__ == "__main__":import matplotlib.pyplot as pltG = Generator(z_dim=20, image_size=256)# 输入的随机数input_z = torch.randn(1, 20)# 将张量尺寸变形为(1,20,1,1)input_z = input_z.view(input_z.size(0), input_z.size(1), 1, 1)#输出假图像fake_images = G(input_z)print(fake_images.shape)img_transformed = fake_images[0].detach().numpy().transpose(1, 2, 0)plt.imshow(img_transformed)plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M0oWDbXr-1692468683782)(E:\学习笔记\深度学习笔记\生成模型\GAN\DCGAN.assets\Figure_1.png)]](https://img-blog.csdnimg.cn/d810b0269a354a4f8032cf9c5828e986.png)
1.1 构建判别器
class Discriminator(nn.Module):def __init__(self, z_dim=20, image_size=256):super(Discriminator, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(3, image_size, kernel_size=4,stride=2, padding=1),nn.LeakyReLU(0.1, inplace=True))#注意:因为是黑白图像,所以输入通道只有一个self.layer2 = nn.Sequential(nn.Conv2d(image_size, image_size*2, kernel_size=4,stride=2, padding=1),nn.LeakyReLU(0.1, inplace=True))self.layer3 = nn.Sequential(nn.Conv2d(image_size*2, image_size*4, kernel_size=4,stride=2, padding=1),nn.LeakyReLU(0.1, inplace=True))self.layer4 = nn.Sequential(nn.Conv2d(image_size*4, image_size*8, kernel_size=4,stride=2, padding=1),nn.LeakyReLU(0.1, inplace=True))self.layer5 = nn.Sequential(nn.Conv2d(image_size*8, image_size*16, kernel_size=4,stride=2, padding=1),nn.LeakyReLU(0.1, inplace=True))self.layer6 = nn.Sequential(nn.Conv2d(image_size*16, image_size*32, kernel_size=4,stride=2, padding=1),nn.LeakyReLU(0.1, inplace=True))self.last = nn.Conv2d(image_size*32, 1, kernel_size=4, stride=1)def forward(self, x):out = self.layer1(x)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.layer5(out)out = self.layer6(out)out = self.last(out)return outif __name__ == "__main__":#确认程序执行D = Discriminator(z_dim=20, image_size=64)#生成伪造图像input_z = torch.randn(1, 20)input_z = input_z.view(input_z.size(0), input_z.size(1), 1, 1)fake_images = G(input_z)#将伪造的图像输入判别器D中d_out = D(fake_images)#将输出值d_out乘以Sigmoid函数,将其转换成0~1的值print(torch.sigmoid(d_out))
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SEGvF8xh-1692468683784)(E:\学习笔记\深度学习笔记\生成模型\GAN\DCGAN.assets\image-20230817224333376.png)]](https://img-blog.csdnimg.cn/6ca680fce7f5474a92e8d87a0f0526bd.png)
2、数据集构建
import os
import sys
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), ".")))
import time
from PIL import Image
import torch
import torch.utils.data as data
import torch.nn as nnfrom torchvision import transforms
from model.DCGAN import Generator, Discriminator
from matplotlib import pyplot as pltdef make_datapath_list(root):"""创建用于学习和验证的图像数据及标注数据的文件路径列表。 """train_img_list = list() #保存图像文件的路径for img_idx in range(200):img_path = f"{root}/img_7_{str(img_idx)}.jpg"train_img_list.append(img_path)img_path = f"{root}/img_8_{str(img_idx)}.jpg"train_img_list.append(img_path)return train_img_listclass ImageTransform:"""图像的预处理类"""def __init__(self, mean, std):self.data_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean, std)])def __call__(self, img):return self.data_transform(img)class GAN_Img_Dataset(data.Dataset):"""图像的 Dataset 类,继承自 PyTorchd 的 Dataset 类"""def __init__(self, file_list, transform):self.file_list = file_listself.transform = transformdef __len__(self):'''返回图像的张数'''return len(self.file_list)def __getitem__(self, index):'''获取经过预处理后的图像的张量格式的数据'''img_path = self.file_list[index]img = Image.open(img_path) # [ 高度 ][ 宽度 ] 黑白# 图像的预处理img_transformed = self.transform(img)return img_transformed# 创建DataLoader并确认执行结果# 创建文件列表
root = "./img_78"
train_img_list = make_datapath_list(root)# 创建Dataset
mean = (0.5)
std = (0.5)
train_dataset = GAN_Img_Dataset(file_list=train_img_list, transform=ImageTransform(mean, std)
)# 创建DataLoader
batch_size = 2
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True
)# 确认执行结果
batch_iterator = iter(train_dataloader) # 转换为迭代器
imges = next(batch_iterator) # 取出位于第一位的元素
print(imges.size()) # torch.Size([64, 1, 64, 64])
数据请在访问链接获取:
3、train接口实现
def train_model(G, D, dataloader, num_epochs):# 确认是否能够使用GPU加速device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("使用设备:", device)# 设置最优化算法g_lr, d_lr = 0.0001, 0.0004beta1, beta2 = 0.0, 0.9g_optimizer = torch.optim.Adam(G.parameters(), g_lr, [beta1, beta2])d_optimizer = torch.optim.Adam(D.parameters(), d_lr, [beta1, beta2])# 定义误差函数criterion = nn.BCEWithLogitsLoss(reduction='mean')# 使用硬编码的参数z_dim = 20mini_batch_size = 8# 将网络载入GPU中G.to(device)D.to(device)G.train() # 将模式设置为训练模式D.train() # 将模式设置为训练模式# 如果网络相对固定,则开启加速torch.backends.cudnn.benchmark = True# 图像张数num_train_imgs = len(dataloader.dataset)batch_size = dataloader.batch_size# 设置迭代计数器iteration = 1logs = []# epoch循环for epoch in range(num_epochs):# 保存开始时间t_epoch_start = time.time()epoch_g_loss = 0.0 # epoch的损失总和epoch_d_loss = 0.0 # epoch的损失总和print('-------------')print('Epoch {}/{}'.format(epoch, num_epochs))print('-------------')print('(train)')# 以minibatch为单位从数据加载器中读取数据的循环for imges in dataloader:# --------------------# 1.判别器D的学习# --------------------# 如果小批次的尺寸设置为1,会导致批次归一化处理产生错误,因此需要避免if imges.size()[0] == 1:continue# 如果能使用GPU,则将数据送入GPU中imges = imges.to(device)# 创建正确答案标签和伪造数据标签# 在epoch最后的迭代中,小批次的数量会减少mini_batch_size = imges.size()[0]label_real = torch.full((mini_batch_size,), 1).to(device)label_fake = torch.full((mini_batch_size,), 0).to(device)# 对真正的图像进行判定d_out_real = D(imges)# 生成伪造图像并进行判定input_z = torch.randn(mini_batch_size, z_dim).to(device)input_z = input_z.view(input_z.size(0), input_z.size(1), 1, 1)fake_images = G(input_z)d_out_fake = D(fake_images)# 计算误差d_loss_real = criterion(d_out_real.view(-1), label_real.to(torch.float))d_loss_fake = criterion(d_out_fake.view(-1), label_fake.to(torch.float))d_loss = d_loss_real + d_loss_fake# 反向传播处理g_optimizer.zero_grad()d_optimizer.zero_grad()d_loss.backward()d_optimizer.step()# --------------------# 2.生成器G的学习# --------------------# 生成伪造图像并进行判定input_z = torch.randn(mini_batch_size, z_dim).to(device)input_z = input_z.view(input_z.size(0), input_z.size(1), 1, 1)fake_images = G(input_z)d_out_fake = D(fake_images)# 计算误差g_loss = criterion(d_out_fake.view(-1), label_real.to(torch.float))# 反向传播处理g_optimizer.zero_grad()d_optimizer.zero_grad()g_loss.backward()g_optimizer.step()# --------------------# 3.记录结果# --------------------epoch_d_loss += d_loss.item()epoch_g_loss += g_loss.item()iteration += 1# epoch的每个phase的loss和准确率t_epoch_finish = time.time()print('-------------')print('epoch {} || Epoch_D_Loss:{:.4f} ||Epoch_G_Loss:{:.4f}'.format(epoch, epoch_d_loss / batch_size, epoch_g_loss / batch_size))print('timer: {:.4f} sec.'.format(t_epoch_finish - t_epoch_start))t_epoch_start = time.time()return G, D
4、训练
G = Generator(z_dim=20, image_size=64)
D = Discriminator(z_dim=20, image_size=64)
# 定义误差函数
criterion = nn.BCEWithLogitsLoss(reduction='mean')
num_epochs = 200
G_update, D_update = train_model(G, D, dataloader=train_dataloader, num_epochs=num_epochs
)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EvqY6h3G-1692468683786)(E:\学习笔记\深度学习笔记\生成模型\GAN\DCGAN.assets\image-20230820020234209.png)]](https://img-blog.csdnimg.cn/346d93a8b5c94483b7b6461afb89d8f5.png)
5、测试
# 将生成的图像和训练数据可视化
# 反复执行本单元中的代码,直到生成感觉良好的图像为止device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 生成用于输入的随机数
batch_size = 8
z_dim = 20
fixed_z = torch.randn(batch_size, z_dim)
fixed_z = fixed_z.view(fixed_z.size(0), fixed_z.size(1), 1, 1)# 生成图像
fake_images = G_update(fixed_z.to(device))# 训练数据
imges = next(iter(train_dataloader)) # 取出位于第一位的元素# 输出结果
fig = plt.figure(figsize=(15, 6))
for i in range(0, 5):# 将训练数据放入上层plt.subplot(2, 5, i + 1)plt.imshow(imges[i][0].cpu().detach().numpy(), 'gray')# 将生成数据放入下层plt.subplot(2, 5, 5 + i + 1)plt.imshow(fake_images[i][0].cpu().detach().numpy(), 'gray')

相关文章:
生成式AI系列 —— DCGAN生成手写数字
1、模型构建 1.1 构建生成器 # 导入软件包 import torch import torch.nn as nnclass Generator(nn.Module):def __init__(self, z_dim20, image_size256):super(Generator, self).__init__()self.layer1 nn.Sequential(nn.ConvTranspose2d(z_dim, image_size * 32,kernel_s…...

vscode-vue项目格式化+语法检验-草稿
Vue学习笔记7 - 在Vscode中配置Vetur,ESlint,Prettier_vetur规则_Myron.Maoyz的博客-CSDN博客...

【Java从0到1学习】10 Java常用类汇总
1. System类 System类对读者来说并不陌生,因为在之前所学知识中,需要打印结果时,使用的都是“System.out.println();”语句,这句代码中就使用了System类。System类定义了一些与系统相关的属性和方法,它所提供的属性和…...

第三届人工智能与智能制造国际研讨会(AIIM 2023)
第三届人工智能与智能制造国际研讨会(AIIM 2023) The 3rd International Symposium on Artificial Intelligence and Intelligent Manufacturing 第三届人工智能与智能制造国际研讨会(AIIM 2023)将于2023年10月27-29日在成都召开…...

层次分析法
目录 一:问题的引入 二:模型的建立 1.分析系统中各因素之间的关系,建立系统的递阶层次结构。 2.对于同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,构造两两比较矩阵(判断矩阵)。 3.由判…...

Error Handling
有几个特定的异常类允许用户代码对与CAN总线相关的特定场景做出反应: Exception (Python standard library)+-- ...+-- CanError (python-can)+-- CanInterfaceNotImplementedError+-- CanInitializationError...
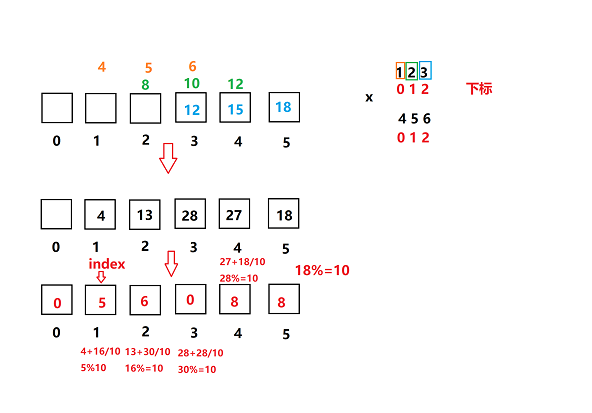
leetcode:字符串相乘(两种方法)
题目: 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。 注意:不能使用任何内置的 BigInteger 库或直接将输入转换为整数。 示例 1: 输入: num1 "2", nu…...
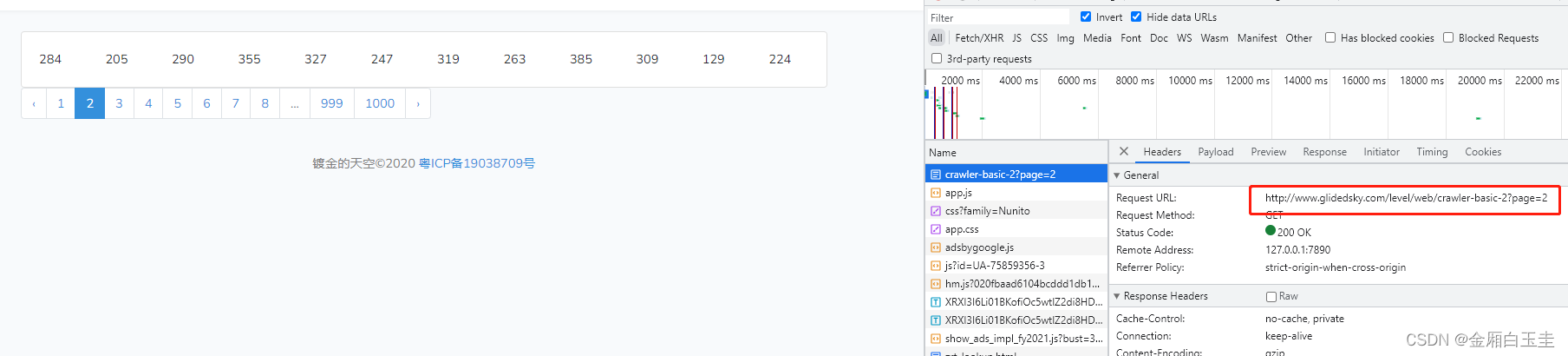
【爬虫练习之glidedsky】爬虫-基础2
题目 链接 爬虫往往不能在一个页面里面获取全部想要的数据,需要访问大量的网页才能够完成任务。 这里有一个网站,还是求所有数字的和,只是这次分了1000页。 思路 找到调用接口 可以看到后面有个参数page来控制页码 代码实现 import reques…...

03.有监督算法——决策树
1.决策树算法 决策树算法可以做分类,也可以做回归 决策树的训练与测试: 训练阶段:从给定的训练集构造出一棵树(从根节点开始选择特征,如何进行特征切分) 测试阶段:根据构造出来的树模型从上…...
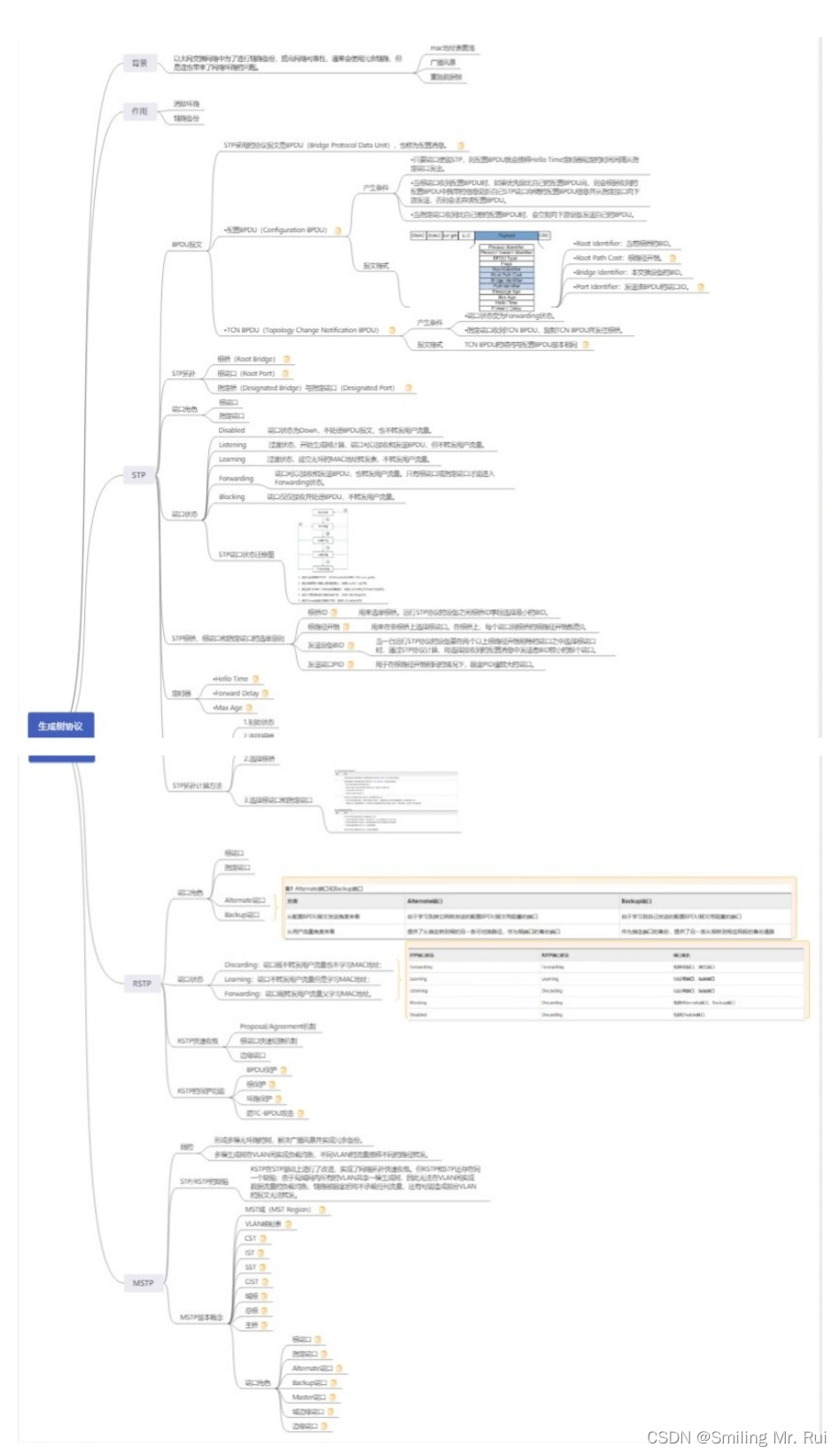
网络协议详解之STP
目录 一、STP协议(生成树) 1.1 生成树协议核心知识点: 1.2 生成树协议与导致问题: 生成树含义: 1.3 802.1D 规则: 802.1D 缺点: 1.4 PVST cisco私有 1.5 PVST 1.6 快速生成树 快速的原…...
Eltima USB Network Gate 10.0 Crack
USB Network Gate -通过网络共享USB 设备 USB Network Gate (前身为以太网USB控制器USB) 轻松的通过网络(Internet/LAN/WAN)分享您的一个或者多个连接到您计算机的USB设备。 无论您身处异国还是近在隔壁办公室,您都可以轻松使用远程扫描仪、打印机、摄像头、调制解…...
)
SpringCloudGateway网关实战(一)
SpringCloudGateway网关实战(一) 目前对cloud的gateway功能还是不太熟悉,因此特意新建了对应的应用来尝试网关功能。 网关模块搭建 首先我们新建一个父模块用于添加对应的springboot依赖和cloud依赖。本模块我们的配置读取使用的是nacos&a…...
django中使用ajax发送请求
1、ajax简单介绍 浏览器向网站发送请求时 是以URL和表单的形式提交的post 或get 请求,特点是:页面刷新 除此之外,也可以基于ajax向后台发送请求(异步) 依赖jQuery 编写ajax代码 $.ajax({url: "发送的地址"…...

C++之std::list<string>::iterator迭代器应用实例(一百七十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...

VSCode好用的插件
文章目录 前言1.Snippet Creator & easy snippet(自定义代码)2.Indent Rainbow(代码缩进)3.Chinese (Simplified) Language Pack(中文包)4.Path Intellisense(路径提示)5.Beauti…...
)
js实现滚轮滑动到底部自动加载(完整版)
这里我们用vue实现(原生js相似), 这里我们用一个div当作一个容器; <div class="JL" @scroll="onScroll" ref="inin"> <div v-for="(item,index) in this.list" :key="index" > ....…...
如何限制PDF打印?限制清晰度?
想要限制PDF文件的打印功能,想要限制PDF文件打印清晰度,都可以通过设置限制编辑来达到目的。 打开PDF编辑器,找到设置限制编辑的界面,切换到加密状态,然后我们就看到 有印刷许可。勾选【权限密码】输入一个PDF密码&am…...

python计算模板图像与原图像各区域的相似度
目录 1、解释说明: 2、使用示例: 3、注意事项: 1、解释说明: 在Python中,我们可以使用OpenCV库进行图像处理和计算机视觉任务。其中,模板匹配是一种常见的方法,用于在一幅图像中识别出与给定…...
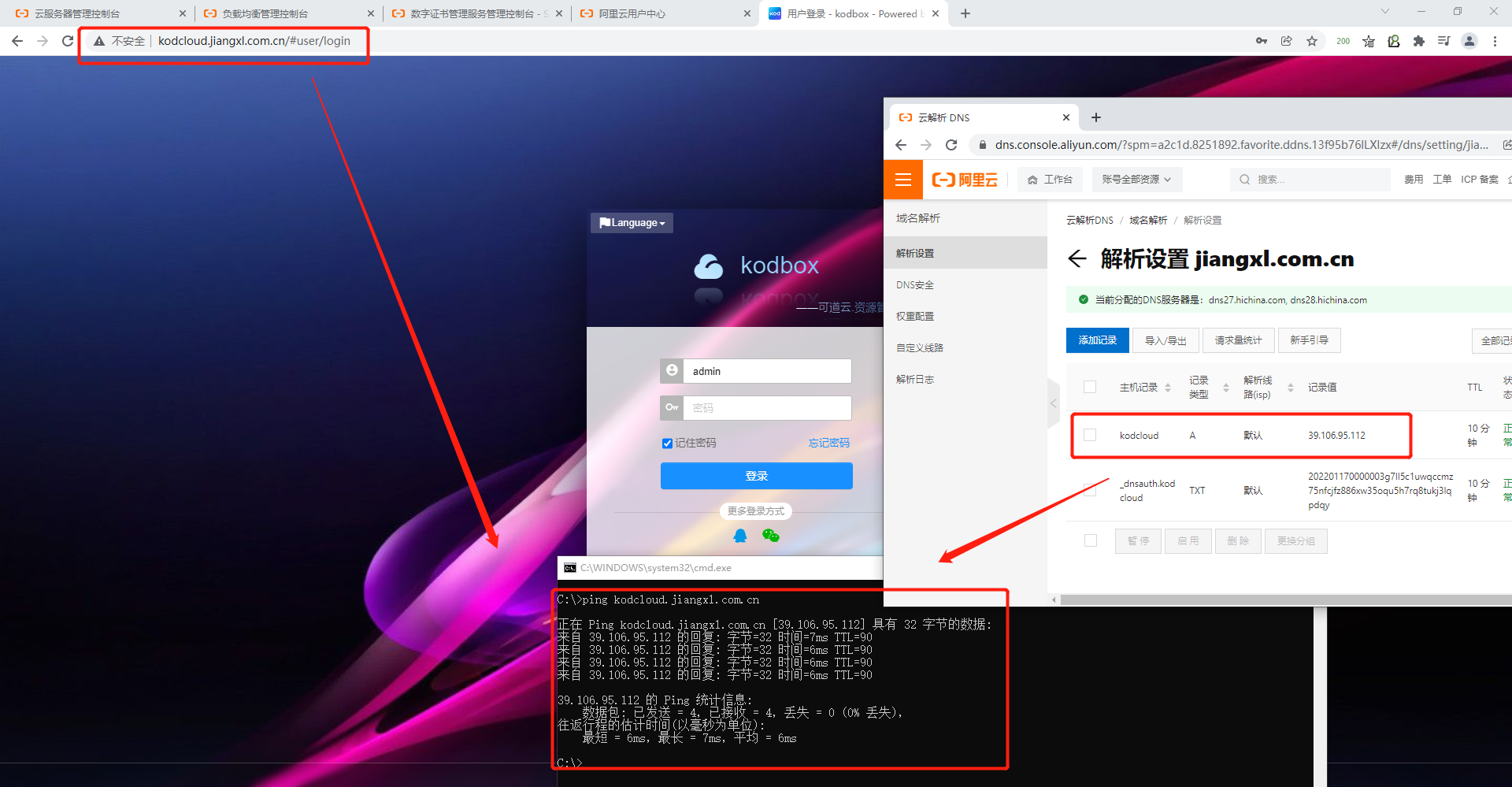
阿里云云解析DNS核心概念与应用
文章目录 1.DNS解析基本概念1.1.DNS基本介绍1.2.域名的分层结构1.3.DNS解析原理1.4.DNS递归查询和迭代查询的区别1.5.DNS常用的解析记录 2.使用DNS云解析将域名与SLB公网IP进行绑定2.1.进入云解析DNS控制台2.2.添加域名解析记录2.3.验证解析是否生效 1.DNS解析基本概念 DNS官方…...
计算机竞赛 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录 0 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 垃圾邮件(短信)分类算…...

冠珠瓷砖×莫氏鸡煲×叠滘东胜东队,德叔有请,莫叔掌勺,“力撑”叠滘龙船传承
5月10日,2026叠滘龙船漂移大赛金牌合作伙伴冠珠瓷砖品牌代表、新明珠集团董事长叶德林“德叔”有请,莫氏鸡煲创始人“莫叔”掌勺,携火爆全网的莫氏祛湿鸡煲、紫洞黄皮酒,探班叠滘东胜东队训练场。当天下午,德叔、莫叔还…...

扣图操作方法完全指南:一键去背景,从小白到高手只需3步
每次看到朋友圈里别人的证件照、商品图、头像背景都换得很专业,你是不是也想试试?但一提到"扣图",很多人的第一反应就是打开Photoshop,结果被复杂的工具栏劝退了。其实,现在扣图已经不是什么高技术门槛的事儿…...

Aura包管理器与Faur元数据服务器:了解Arch Linux包管理的终极解决方案
Aura包管理器与Faur元数据服务器:了解Arch Linux包管理的终极解决方案 【免费下载链接】aura A multilingual package manager for Arch Linux and the AUR. 项目地址: https://gitcode.com/gh_mirrors/aur/aura Aura是一个多语言包管理器,专为Ar…...

Box64:让你的ARM设备也能畅玩x86_64游戏的魔法引擎
Box64:让你的ARM设备也能畅玩x86_64游戏的魔法引擎 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 还在为树莓派…...

AI浪潮下,普通程序员如何避免沦为“提示词工程师”?
一、从“提示词执行者”到“质量架构师”:重新定义测试的价值锚点AI之所以能替代大量重复性测试工作,是因为它擅长处理“已知的已知”——那些规则明确、边界清晰的测试场景。然而,软件测试的真正价值,从来不在执行层面࿰…...

怀旧服WLK:10人NAXX教官拉苏维奥斯保姆级攻略,暗牧控制与学员轮换时间轴详解
怀旧服WLK:10人NAXX教官拉苏维奥斯保姆级攻略,暗牧控制与学员轮换时间轴详解 在《魔兽世界》怀旧服巫妖王之怒版本中,纳克萨玛斯军事区的教官拉苏维奥斯堪称团队配合的"试金石"。这个看似机制简单的BOSS,却因学员控制与…...

AD9361快速切频点秘籍:不用复杂计算,一张2400-2480MHz的查表配置表直接拿去用
AD9361射频芯片极速切频实战:2400-2480MHz预计算配置表与查表法优化 在Wi-Fi 6E和蓝牙5.3设备爆发式增长的今天,射频工程师每天需要处理数百次频段切换测试。传统AD9361配置流程中,每次切换频点都要重新计算VCO分频比、电荷泵电流等12个关键参…...

测试工程师的副业指南:利用专业技能实现月入过万
一、解锁测试工程师的副业潜力在软件行业高速发展的今天,测试工程师早已不再是仅仅围绕着“找bug”打转的角色。他们凭借着对软件质量把控的专业能力、对各类系统架构的深入理解以及严谨的逻辑思维,在副业领域拥有着得天独厚的优势。越来越多的测试工程师…...

从零到一:手把手教你用LabelImg高效构建VOC与YOLO数据集
1. 为什么你需要掌握LabelImg标注工具 刚接触计算机视觉时,我最头疼的就是数据准备环节。记得第一次尝试训练目标检测模型,花了两周时间收集了上千张图片,却在标注环节卡住了——手动画框太慢,格式转换出错,反复返工差…...

NextPy全栈框架:用Python构建AI智能体Web应用
1. 项目概述:当AI智能体遇上全栈Web开发最近在开源社区里,一个名为dot-agent/nextpy的项目引起了我的注意。作为一名长期在Web开发和AI应用落地之间“反复横跳”的开发者,我深知将AI能力,特别是智能体(Agent࿰…...