【STM32】串口通信乱码(认识系统时钟来源)
使用 stm32f407 与电脑主机进行串口通信时,串口助手打印乱码,主要从以下方面进行排查:
- 检查传输协议设置是否一致(波特率、数据位、停止位、校验位)
- 检查MCU外部晶振频率是否和库函数设置的一致
最终发现是外部晶振频率和库函数不一致的问题。
一、时钟分析
1、认识时钟源
我们要检查的是 APB2总线的时钟源是否设置正常,因为我们当前使用的串口 USART1 与 APB2 总线(高速总线)相连,从下图看,时钟源有三个:
- HSI:高速内部时钟,RC振荡器,频率为16MHz
- HSE:高速外部时钟,接外部时钟源,频率范围为4MHz~26MHz
- PLL:锁相环倍频输出,其时钟输入源可选择为 HSI/M、HSE/M(本质还是 由HSE或HSI控制)
就结果而言,选择的时钟源是 PLLCLK。(若想了解,可以参考最后一部分)

2、计算系统时钟
现在已经知道了选择的是 PLLCLK 作为时钟源,那么我们就可以顺着这条路线计算系统时钟的值。正点原子 stm32f407 的外设时钟频率 HSE = 8 M
① 输入 HSE
② 经过 M 分频,得到的结果为 HSE / M = 8 / M
③ ④ ⑤ ⑥ 经过 N 倍频,VCO的输出为 (HSE / M ) * N
⑦ 再次 P 分频就得到 SYSCLK = (HSE / M ) * N / P

二、解决外部晶振频率和库函数不一致的问题
从上面可知,选择的系统时钟频率 SYSCLK = (HSE / M ) * N / P,配置文件预期的 SYSCLK = 144MHz,其余参数也都指定了


实际上 HSE 需要视开发板具体情况而定,stm32f4 的 HSE 为 8 MHz,然而配置文件中配置的频率是 25 M,为了不影响原本的SYSCLK,我们需要修改 HSE 和 PLL_M。
- HSE = 8 M = 8000000
- PLL_M = (HSE / SYSCLK ) * N / P = 8
1、修改 HSE
HSE 在程序中的体现为宏定义 HSE_VALUE ,该宏定义在 stm32f4xx.h 文件中

这里有两种修改方法,可任选一种修改

2、修改 PLL_M
分频数 M 在程序中的体现是宏定义 PLL_M,该宏定义在 system_stm32f4xx.c 文件中

三、为什么可以确定时钟源为 PLLCLK 而不是 HSE
stm32 在启动的时候就会调用 SystemInit 函数,这个函数就包含了初始化外设的时钟源。这个函数定义在 system_stm32f4xx.c 中。我们直接找到 SetSysClock 函数,这之前的都是将控制寄存器位清零的操作。

我们进入到 SetSysClock 函数,首先是HSE使能,等待时钟准备就绪。刚上电的时候 HSE 晶振不稳定,需要等待 6 个晶振时钟周期。

PLL 使能,等待时钟准备就绪。一开始 PLL 处于被锁定状态,这里需要等待 PLL 解锁。

一切准备就绪,然后将 PLL 设为系统时钟。

参考文章:
在串口通信实验中出现通信乱码怎么办-电子发烧友网 (elecfans.com)
相关文章:
【STM32】串口通信乱码(认识系统时钟来源)
使用 stm32f407 与电脑主机进行串口通信时,串口助手打印乱码,主要从以下方面进行排查: 检查传输协议设置是否一致(波特率、数据位、停止位、校验位)检查MCU外部晶振频率是否和库函数设置的一致 最终发现是外部晶振频…...
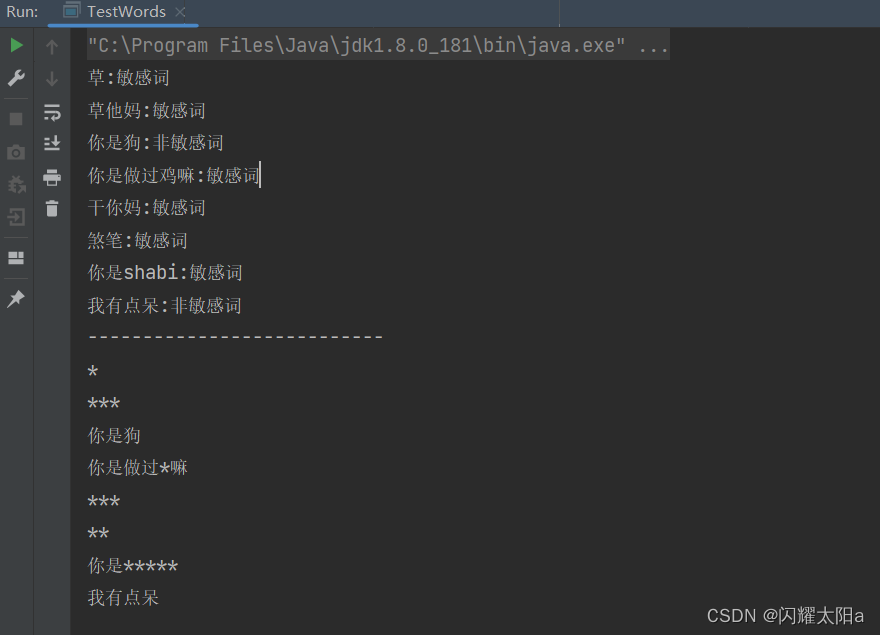
Java实现敏感词过滤功能
敏感词过滤功能实现 1.GitHub上下载敏感词文件 2.将敏感词文件放在resources目录下 在业务中可以将文本中的敏感词写入数据库便于管理。 3.提供实现类demo 代码编写思路如下:1.将敏感词加载到list中,2.添加到StringSearch中,3.校验&#x…...

大数据向量检索的细节问题
背景:现有亿级别数据(条数),其文本大小约为150G,label为字符串,content为文本。用于向量检索,采用上次的试验进行,但有如下问题需要面对: 1、向量维度及所需空间 向量维度一版采用768的bert系列的模型推理得到,openai也有类似的功能,不过是2倍的维度(即1536),至…...
如何让智能搜索引擎更灵活、更高效?
随着互联网的发展和普及,搜索引擎已经成为人们获取信息、解决问题的主要工具之一。 然而,传统的搜索引擎在面对大数据时,往往存在着搜索效率低下、搜索结果精准度不够等问题。 为了解决这些问题,越来越多的企业开始采用智能搜索技…...

C++set集合与并查集map映射,哈希表应用实例B3632 集合运算 1P1918 保龄球
集合的性质 无序性互异性确定性 B3632 集合运算 1 题面 题目背景 集合是数学中的一个概念,用通俗的话来讲就是:一大堆数在一起就构成了集合。 集合有如下的特性: 无序性:任一个集合中,每个元素的地位都是相同的&…...
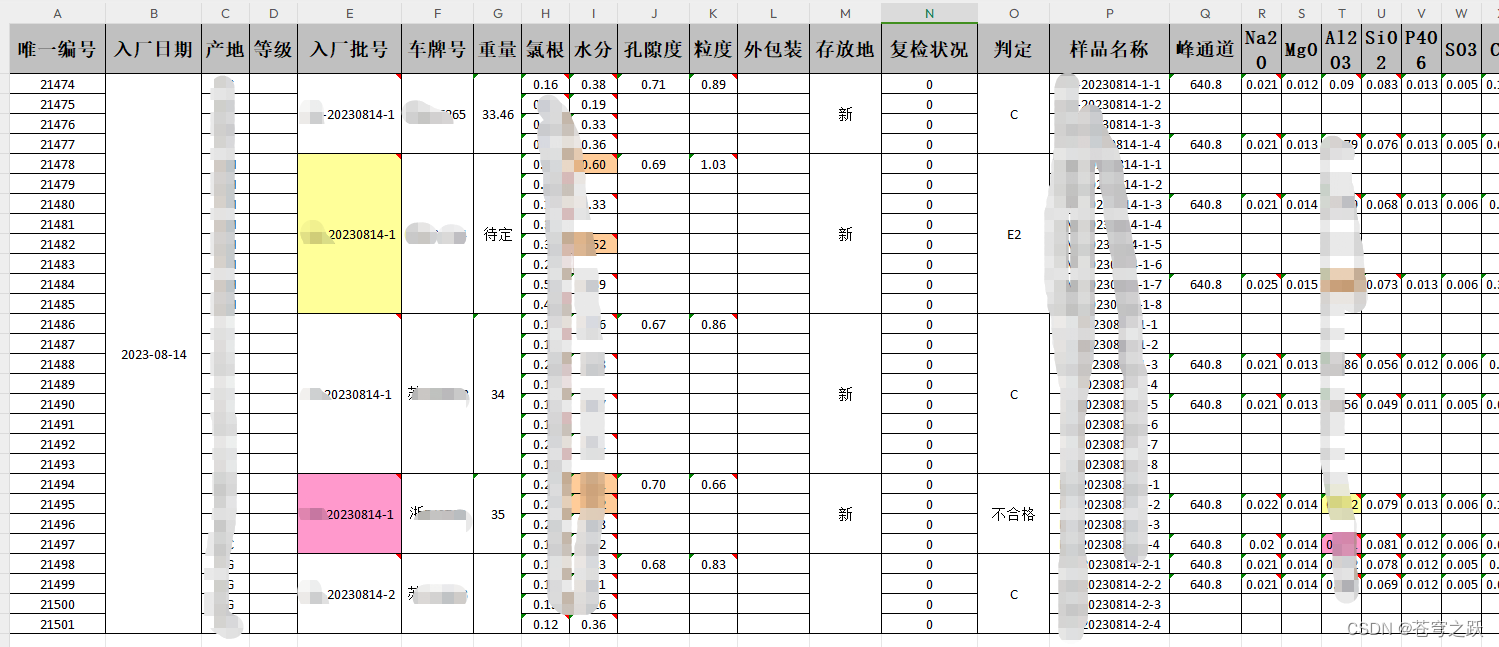
easyexcel合并单元格底色
一、效果图 二、导出接口代码 PostMapping("selectAllMagicExport")public void selectAllMagicExport(HttpServletRequest request, HttpServletResponse response) throws IOException {ServiceResult<SearchResult<TestMetLineFe2o3Export>> result …...

OpenCV图片校正
OpenCV图片校正 背景几种校正方法1.傅里叶变换 霍夫变换 直线 角度 旋转3.四点透视 角度 旋转4.检测矩形轮廓 角度 旋转参考 背景 遇到偏的图片想要校正成水平或者垂直的。 几种校正方法 对于倾斜的图片通过矫正可以得到水平的图片。一般有如下几种基于opencv的组合方…...
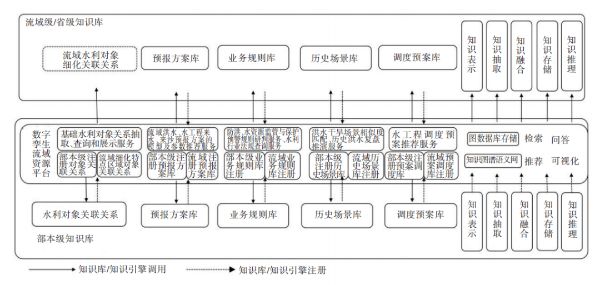
数字孪生流域共建共享相关政策解读
当前数字孪生技术在水利方面的应用刚起步,2021年水利部首次提出“数字孪生流域”概念,即以物理流域为单元、时空数据为底座、数学模型为核心、水利知识为驱动,对物理流域全要素和水利治理管理活动全过程的数字映射、智能模拟、前瞻预演&#…...
FSC147数据集格式解析
一. 引言 在研究很多深度学习框架的时候,往往需要使用到FSC147格式数据集,若要是想在自己的数据集上验证深度学习框架,就需要自己制作数据集以及相关标签,在论文Learning To Count Everything中,该数据集首次被提出。 …...

el-element中el-tabs案例的使用
el-element中el-tabs的使用 代码呈现 <template><div class"enterprise-audit"><div class"card"><div class"cardTitle"><p>交易查询</p></div><el-tabs v-model"activeName" tab-cl…...

tomcat结构目录有哪些?
bin 启动,关闭和其他脚本。这些 .sh文件(对于Unix系统)是这些.bat文件的功能副本(对于 Windows系统)。由于Win32命令行缺少某些功能,因此此处包含一些其他文件。 比如说:windows下启动tomcat用的…...

生成式AI系列 —— DCGAN生成手写数字
1、模型构建 1.1 构建生成器 # 导入软件包 import torch import torch.nn as nnclass Generator(nn.Module):def __init__(self, z_dim20, image_size256):super(Generator, self).__init__()self.layer1 nn.Sequential(nn.ConvTranspose2d(z_dim, image_size * 32,kernel_s…...

vscode-vue项目格式化+语法检验-草稿
Vue学习笔记7 - 在Vscode中配置Vetur,ESlint,Prettier_vetur规则_Myron.Maoyz的博客-CSDN博客...

【Java从0到1学习】10 Java常用类汇总
1. System类 System类对读者来说并不陌生,因为在之前所学知识中,需要打印结果时,使用的都是“System.out.println();”语句,这句代码中就使用了System类。System类定义了一些与系统相关的属性和方法,它所提供的属性和…...

第三届人工智能与智能制造国际研讨会(AIIM 2023)
第三届人工智能与智能制造国际研讨会(AIIM 2023) The 3rd International Symposium on Artificial Intelligence and Intelligent Manufacturing 第三届人工智能与智能制造国际研讨会(AIIM 2023)将于2023年10月27-29日在成都召开…...

层次分析法
目录 一:问题的引入 二:模型的建立 1.分析系统中各因素之间的关系,建立系统的递阶层次结构。 2.对于同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,构造两两比较矩阵(判断矩阵)。 3.由判…...

Error Handling
有几个特定的异常类允许用户代码对与CAN总线相关的特定场景做出反应: Exception (Python standard library)+-- ...+-- CanError (python-can)+-- CanInterfaceNotImplementedError+-- CanInitializationError...
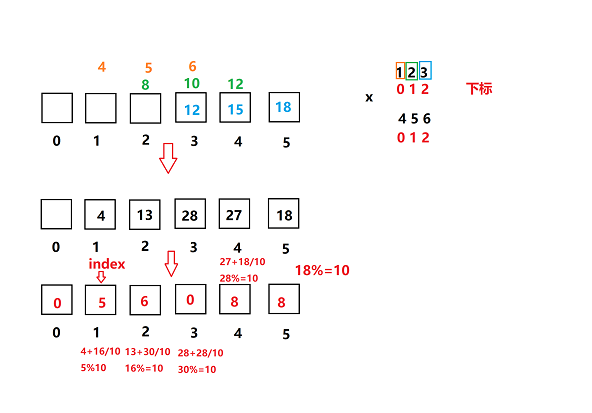
leetcode:字符串相乘(两种方法)
题目: 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。 注意:不能使用任何内置的 BigInteger 库或直接将输入转换为整数。 示例 1: 输入: num1 "2", nu…...
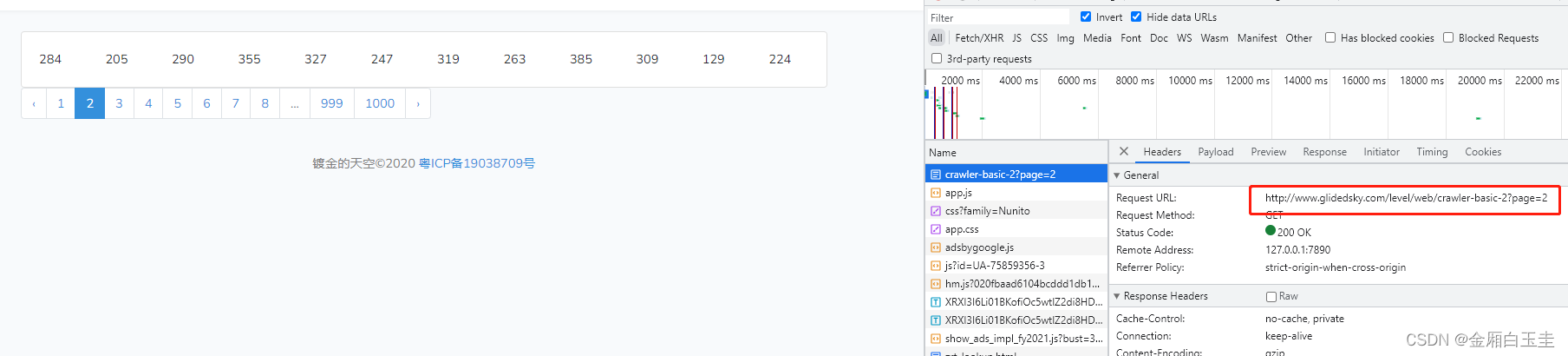
【爬虫练习之glidedsky】爬虫-基础2
题目 链接 爬虫往往不能在一个页面里面获取全部想要的数据,需要访问大量的网页才能够完成任务。 这里有一个网站,还是求所有数字的和,只是这次分了1000页。 思路 找到调用接口 可以看到后面有个参数page来控制页码 代码实现 import reques…...

03.有监督算法——决策树
1.决策树算法 决策树算法可以做分类,也可以做回归 决策树的训练与测试: 训练阶段:从给定的训练集构造出一棵树(从根节点开始选择特征,如何进行特征切分) 测试阶段:根据构造出来的树模型从上…...

大语言模型剪枝技术:Týr-the-Pruner框架解析
1. 大语言模型剪枝技术背景与挑战在自然语言处理领域,大语言模型(LLMs)如Llama、GPT等已经展现出惊人的能力,但其庞大的参数量(通常达到数十亿甚至上千亿)带来了显著的部署挑战。以Llama-3.1-70B为例&#…...

SpringBoot多环境配置全解+配置优先级管控
企业级SpringBoot项目开发流程分为开发环境、测试环境、预发布环境、生产环境四大核心场景,不同环境数据库连接地址、端口号、日志级别、接口域名、加密密钥、线程池参数等配置完全不同。若所有环境共用一套配置,每次环境切换手动修改配置参数࿰…...

基于Next.js urborepo的企业级电商全栈架构实战解析
1. 项目概述与核心价值最近在梳理企业级电商项目的技术选型与架构方案,发现了一个非常值得深入研究的开源项目——Blazity/enterprise-commerce。这不仅仅是一个简单的电商模板,而是一个基于Next.js 14、TypeScript和Turborepo构建的现代化、全栈式企业级…...

RAG和向量索引
为特定用例设计代理时,需要确保语言模型已建立基础并使用与用户所需内容相关的事实信息。 虽然语言模型针对大量数据进行了训练,但它们可能无权访问你想要向用户提供的知识。 若要确保代理基于特定数据提供准确且特定于域的响应,可使用检索增…...

如何用开源视频字幕工具VideoSrt在3分钟内完成专业字幕制作
如何用开源视频字幕工具VideoSrt在3分钟内完成专业字幕制作 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows 你是否还在为视频字幕制作…...

外卖点餐连锁店餐饮生鲜奶茶外卖店内扫码点餐源码同城外卖校园外卖源码的扫码逻辑
📱 扫码点餐系统 - 完整扫码逻辑 源码示例外卖点餐 | 连锁店 | 餐饮生鲜 | 奶茶 | 店内扫码点餐 | 同城外卖 | 校园外卖🎯 扫码业务场景总览场景扫码后行为核心逻辑🍽️ 店内扫码点餐进入店铺菜单页识别店铺ID → 加载菜单🏃 外卖…...

终极指南:3分钟学会用Video-subtitle-extractor高效提取视频硬字幕
终极指南:3分钟学会用Video-subtitle-extractor高效提取视频硬字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检…...

5分钟掌握Nexus Mods App:告别模组管理烦恼的终极解决方案
5分钟掌握Nexus Mods App:告别模组管理烦恼的终极解决方案 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为游戏模组冲突、依赖缺失而烦恼吗?N…...

XOutput 终极指南:让老旧游戏手柄重获新生的完整教程
XOutput 终极指南:让老旧游戏手柄重获新生的完整教程 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput XOutput 是一个强大的开源工具,专门解决 Windows 平台上游戏控制器兼容性难题…...

NeumAI向量检索平台:构建生产级RAG应用的端到端Pipeline实践
1. 项目概述:从“Neum”到“AI”,一个向量检索系统的诞生最近在折腾RAG(检索增强生成)应用,发现向量检索这块的性能和成本,简直是决定项目成败的“命门”。自己从零开始搭一套,从数据清洗、向量…...