链表(超详细--包教包会)
目录
一、概述
二、对链表的基本操作
三、链表的分类
四、静态链表
五、动态链表
1、malloc函数
2、calloc函数
3、free函数
六、动态链表的建立
七、输出链表中的数据
八、查找节点
九、删除节点
十、插入节点
十一、整体代码
一、概述
链表存储结构是一种动态数据结构,其特点是它包含的数据对象的个数及其相互关系可以按需要改变,存储空间是程序根据需要在程序运行过程中向系统申请获得,链表也不要求逻辑上相邻的元素在物理位置上也相邻,它没有顺序存储结构所具有的弱点。
链表:由各个节点组成一种链状的结构;
链表是由节点构成;表头+结点+表尾
节点:就是一个特殊的结构体,此结构体由2部分组成,一部分是数据域,另一部分是指针域;数据域(该结点数据);指针域(下一结点的首地址)
数据域:存储结点本身的数据,信息;
指针域:保存下一个结点的首地址(指向后继结点的指针);
链表完整的结构:

(1)头指针变量head──指向链表的首结点。
(2)每个结点由2个域组成:
1)数据域──用来存储本身数据。
2)指针域──用来存储下一个结点地址或者说指向其直接后继的指针。
(3)尾结点的指针域置为“NULL(空)”,作为链表结束的标志
节点的定义:
struct STU
{//数据域int num;char name[10];//指针域struct STU *pnext; //因为下一个结点也是 struct STU *类型
//pnext存放的是struct STU *类型的变量地址
};
这样就定义了一个单链表的结构,其中char name[10]是一个用来存储姓名的字符型数组,指针*pnext是一个用来存储其直接后继的指针。
定义好了链表的结构之后,只要在程序运行的时候在数据域中存储适当的数据,如有后继结点,则把链域指向其直接后继,若没有,则置为NULL。
确定一个链表需要确定一个参数-->头指针
二、对链表的基本操作
链表的基本操作有:创建链表、查找、插入、删除和修改等。
1.创建链表:从无到有地建立起一个链表。
2.查找:按给定的结点索引号或检索条件,查找某个结点。如果找到指定的结点,则称为检索成功;否则,称为检索失败。
3.插入:在结点ki-1与ki之间插入一个新的结点k’,使表的长度增1,且逻辑关系发生如下变化:
- 插入前,ki-1是ki的前驱,ki是ki-1的后继;
- 插入后,新插入的结点k,成为ki-1的后继、ki的前驱。
4. 删除操作:删除结点ki,使链表的长度减1,且ki-1、ki和ki+1结点之间的逻辑关系发生如下变化:
1)删除前,ki是ki+1的前驱、ki-1的后继;
2)删除后,ki-1成为ki+1的前驱,ki+1成为ki-1的后继。
三、链表的分类
静态链表:每个结点所占的内存是提前分配好的,并且是固定的,不能随时被释放;
动态链表:随时可以开辟空间,也随时可以释放空间;
四、静态链表
建立一个简单的链表:它由三个学生的结点组成,输出各节点中的数据u!
#include <stdio.h>struct student
{int num;float score;struct student *next;
};
int main()
{struct student a,b,c,*head,*p;a.num=2008;a.score=88.5;b.num=2009;b.score=85;c.num=2010;c.score=90;head=&a;a.next=&b;b.next=&c;c.next=NULL;p=head;do{printf("%d,%.2f\n",p->num,p->score);p=p->next;}while(p!=NULL);
}
每个结点都属于struct student类型,它的next成员存放下一个结点的地址,这样一环扣一环,将各结节紧密的扣在一起,最后一次循环,将p=p->next是将c结点的地址赋给p,这时p指向c结点,然后将c结点的num,scorc输出,之后将p=p->next实际上是将c结点的next内容,即NULL赋给p再进行判断,P!=NULL条件不成立,循环结束。本例所有结点是在程序中定义的,不是临时开辟的,用完也不能释放,这种链表称“静态链表”。
五、动态链表
1、malloc函数
其作用是在内存的动态存储区中分配一个长度为size的连续空间。其参数是一个无符号整形数,返回值是一个指向所分配的连续存储域的起始地址的指针。还有一点必须注意的是,当函数未能成功分配存储空间(如内存不足)就会返回一个NULL指针。所以在调用该函数时应该检测返回值是否为NULL并执行相应的操作。
功能:动态的开辟空间内存,在 <stdlib.h> 头文件中
原型:(数据类型*)malloc(size);
返回值:动态开辟空间的首地址;
原理:(数据类型*)malloc(size)
动态开辟size大小的空间,空间是以字节为单位;
main()
{int *sp;sp==(int *)malloc ( n*size) pc=(char *)malloc(100);
}
开辟100个字节大小的空间
例子:一个动态分配额程序
#include <stdio.h>
#include <stdlib.h>
void main()
{ int count,*array; /*count是一个计数器,array是一个整型指针,也可以理解为指向一个整型数组的首地址*/ if((array=(int*)malloc(10*sizeof(int)))==NULL) { printf("不能成功分配存储空间。"); exit(0 ); } for(count=0;count<10;count++){array[count]=count;}for(count=0;count<10;count++){printf("%d",array[count]);}
}
上例中动态分配了10个整型存储区域,然后进行赋值并打印。例中if((array=(int *) malloc(10*sizeof(int)))==NULL)语句可以分为以下几步:
1)分配10个整型的连续存储空间,并返回一个指向其起始地址的整型指针
2)把此整型指针地址赋给array
3)检测返回值是否为NULL
2、calloc函数
功能:动态开辟内存
原型:(数据类型 *)calloc(n,size);
返回值:开辟空间的首地址;
原理:(数据类型 *)calloc(n,size);
动态开辟n块size大小的空间
Main()
{char *p;p=(char *)calloc(3,50);
}
请求3个连续的、每个长度为50的空间,若成功返回这些空间的首地址并将每个空间赋值为0,失败返回0
3、free函数
由于内存区域总是有限的,不能不限制地分配下去,而且一个程序要尽量节省资源,所以当所分配的内存区域不用时,就要释放它,以便其它的变量或者程序使用。这时我们就要用到free函数。
功能:释放空间的;
原型:free(void *);
void *:指的是用malloc或者calloc开辟空间的首地址;
此函数用来释放动态开辟的空间的;
#include<stdio.h>
#include<stdlib.h>
void main()
{int *p,i,n;printf("请输入n的值");scanf("%d",&n);p=(int*)malloc(n*sizeof(int));//(int*)calloc(n,sizeof(int))for(i=0;i<n;i++){scanf("%d",p+i);}for(i=0;i<n;i++){printf("%d ",*(p+i));}free(p);
}
例子:分配一块区域,输入一个学生的数据
#include <stdio.h>
#include "malloc.h"
int main()
{struct STU{int num;char *name;char sex;float score;}*ps;//ps=(struct STU *) malloc(sizeof(struct STU ));ps->num=102;ps->name="zhang san";ps->sex='M';ps->score=89.9;printf("Number=%d\n Name=%s\n",ps->num,ps->name);printf("Sex=%c\n Score=%f\n",ps->sex,ps->score);
// free(ps);
}六、动态链表的建立
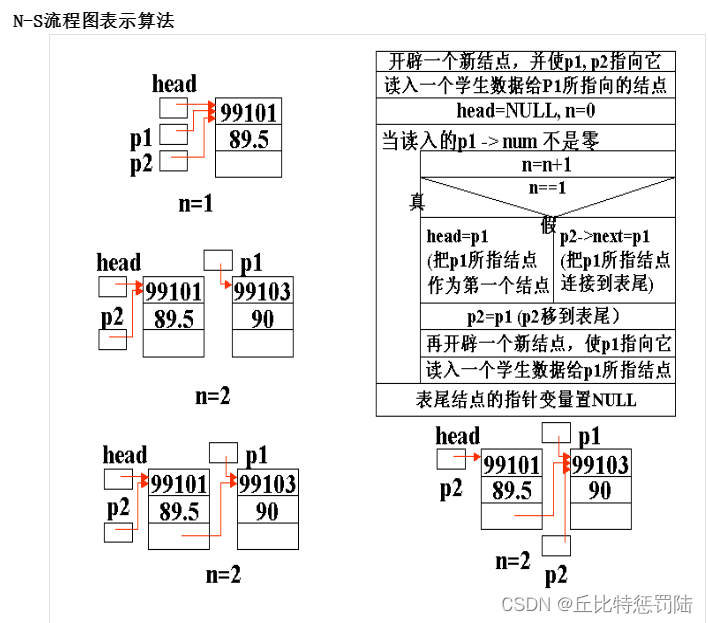
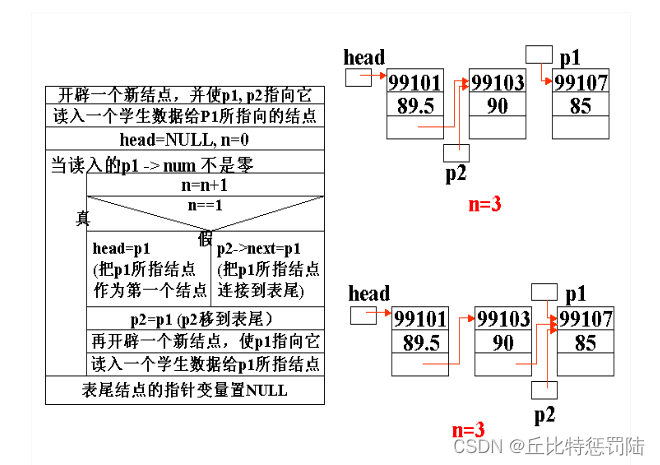
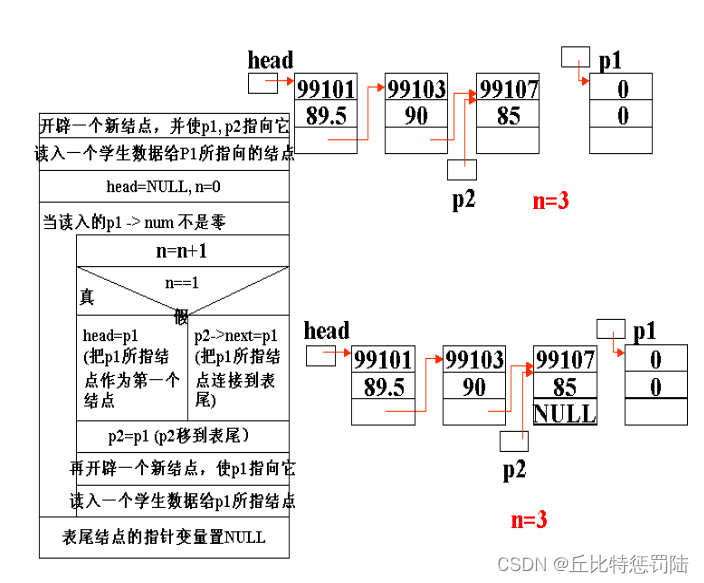 要建立一个链表,就必须先定义了一个链表的结构,如下:
要建立一个链表,就必须先定义了一个链表的结构,如下:
struct STU
{//数据域int num;char name[10];//指针域struct STU *pnext; //指向下一个结点的指针
};
其中 char name[20]是一个用来存储姓名的字符型数组, 指针*pnext是一个用来存储其直接后继的指针。
定义好了链表的结构之后, 只要在程序运行的时候在数据域中存储适当的数据, 如有后继结点, 则把链域指向其直接后继, 若没有, 则置为 NULL。
下面就来看一个建立带表头( 若未说明, 以下所指链表均带表头) 的单链表的完整程序。
例子:建立包含N个人姓名、学号的单链表
//链表的结点结构
struct STU
{//数据域int num;char name[10];//指针域struct STU *pnext; //指向下一个结点的指针
};
/*
==========================
功能:创建n个节点的链表
返回:指向链表表头的指针
==========================
*/
struct STU * Create_link(int n)
{struct STU *phead,*p,*pf; // phead为头指针(保存表头结点的指针),// p为后一结点的指针变量(指向当前节点),//pf为指向两相邻结点的前一结点的指针变量(指向当前节点的前一个节点)。int i;//计数器for(i=1;i<=n;i++){printf("输入第%d个人的数据:",i);p=(struct STU*)malloc(sizeof(struct STU));//分配结点空间if(p==NULL)//分配空间失败{printf(“分配空间失败\n”);// exit(0);break;}scanf("%d %s",&p->num,&p->name); //在当前结点p的数据域中存储姓名、学号if(i==1) //只有一个结点{ phead=p; //节点总数是1,head指向刚创建的节点ppf=p; //phead=pf=p}else{pf->pnext =p; //pf指向下一个结点的首地址(新结点)
//把p的地址赋给pf所指向的结点的链域(把p所指向的结点连接到下一个结点),这样就//把 pf和p所指向的结点连接起来了pf=p; //把p的地址留给pf,然后p产生新的结点(pf移到下一下结点) } }p->pnext=NULL; //单向链表的最后一个节点要指向NULLreturn phead; //返回创建链表的头指针
}main()
{ int n,num;struct STU *phead; //phead用来存放链表头结点的地址printf("输入节点个数:");scanf("%d",&n);phead=Create_link(n); //创建链表,把链表的头结点地址给phead
}
七、输出链表中的数据
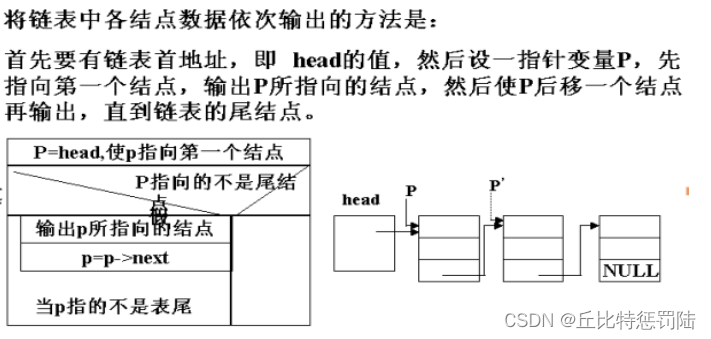
查找所有的链表,燃火输出链表的内容
例子:查询单链表的内容
void pri_link(struct STU *phead)
{struct STU *ph=phead;while(ph->pnext!=NULL) //只要不是空链表,就输出链表中所有节点{printf("%d %s\n",ph->num,ph->name);ph=ph->pnext; //移到下一个节点}printf("%d %s\n",ph->num,ph->name);
}int main()
{int n,num;struct STU *phead; //phead用来存放链表头结点的地址printf("输入节点个数:");scanf("%d",&n);phead=Create_link(n); //创建链表,把链表的头结点地址给phead//这样phead就指向一个链表了,然后就可以把整个链表给确定了pri_link(phead); //输出链表
}
八、查找节点
对单链表进行查找的思路为: 对单链表的结点依次扫描, 检测其数据域是否是我们所要查好的值, 若是返回该结点的指针, 否则返回 NULL。
因为在单链表的链域中包含了后继结点的存储地址, 所以当我们实现的时候, 只要知道该单链表的头指针,
即可依次对每个结点的数据域进行检测
例子:通过学号查找节点的信息
//查找链表的函数,
//phead 指针是链表的表头指针,
//name指针是要查找的人的姓名
//结点结构指针类型的函数( 返回找到的结点指针)
struct STU * search_link(struct STU *phead,char *name)
{//判断链表是否为空;//不为空通过比较找到此人信息//查无此人;struct STU *p; /*当前指针, 指向要与所查找的姓名比较的结点*/char *y; /*保存结点数据域内姓名的指针*/p= phead->pnext ;//后移一下节点while(p!=NULL) //节点不为空{
y=p->name; // 相当于一个地址,赋给了指针;//( name、 y 为指向的存储单元的值) /*把数据域里的姓名与//所要查找的姓名比较, 若相同则返回 0, 即条件成立*/
if(strcmp(y,name)==NULL) //输入的和原来的名字进行比较
{printf("查到此人信息为:");printf("%d %s\n",ph->num,ph->name);return(p); //返回与所要查找结点的地址
}
else p=p->pnext;}if(p==NULL) //节点为空printf("没有查找到该数据!\n");
}
九、删除节点
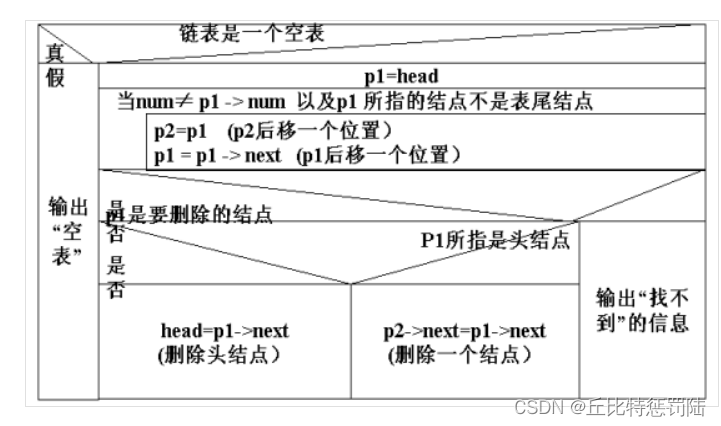
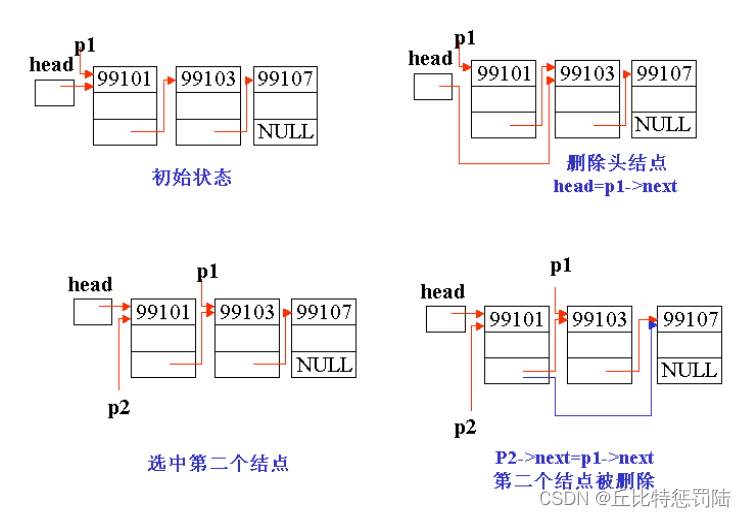
例子:通过学生的学号删除节点
/*
==========================功能:删除指定节点phead 指针是链表的表头指针, num 指针是要查找的人的学号返回:指向链表表头的指针
==========================
*/
struct STU * delet_link(struct STU *phead,int num)
{struct STU *ph=phead,*pf;if(ph==NULL) //空链表{printf("此链表为空链表!\n");}else{
//ph指向的节点不是所要查找的,并且它不是最后一个节点,就继续往下找while(ph->pnext!=NULL&&ph->num!=num){pf=ph; //保存当前节点的地址ph=ph->pnext; //后移一个节点}if(ph->num==num) //找到了{if(ph==phead)//如果要删除的节点是第一个节点{
//头指针指向第一个节点的后一个节点,也就是第二个节点。这样第一个节点就//不在链表中,即删除phead=ph->pnext;}else if(ph->pnext==NULL) //下个节点为空{pf->pnext =NULL;}
//如果是其它节点,则让原来指向当前节点的指针,指向它的下一个节点,完成//删除else{pf->pnext=ph->pnext;}printf("找到此人\n");free(ph); //释放当前节点printf("删除成功!\n"); }else{printf("查无此人\n");ph=NULL;}}return phead;
}
int main()
{int n,num;struct STU *phead; //phead用来存放链表头结点的地址printf("输入节点个数:");scanf("%d",&n);phead=Create_link(n); //创建链表,把链表的头结点地址给phead//这样phead就指向一个链表了,然后就可以把整个链表给确定了pri_link(phead); //输出链表printf("输入要删除的学号:");scanf("%d",&num);phead=delet_link(phead,num); //删除结点pri_link(phead); //输出结点
}
例子:通过学生的姓名删除节点
/*
==========================功能:删除指定节点phead 指针是链表的表头指针, name指针是要查找的人的学号返回:指向链表表头的指针
==========================
*/
struct STU * delet_link(struct STU *phead,char* name)
{struct STU *ph=phead,*pf;if(ph==NULL) //空链表{printf("此链表为空链表!\n");}else{
//ph指向的节点不是所要查找的,并且它不是最后一个节点,就继续往下找while(ph->pnext!=NULL&&strcmp(name,ph->name)!=0){pf=ph; //保存当前节点的地址ph=ph->pnext; //后移一个节点}if(strcmp(name,ph->name)==0) //找到了{if(ph==phead)//如果要删除的节点是第一个节点{
//头指针指向第一个节点的后一个节点,也就是第二个节点。这样第一个节点就//不在链表中,即删除phead=ph->pnext;}else if(ph->pnext==NULL) //下个节点为空{pf->pnext =NULL;}
//如果是其它节点,则让原来指向当前节点的指针,指向它的下一个节点,完成//删除else{pf->pnext=ph->pnext;}printf("找到此人\n");free(ph); //释放当前节点printf("删除成功!\n"); }else{printf("查无此人\n");ph=NULL;}}return phead;
}
int main()
{int n,num;struct STU *phead; //phead用来存放链表头结点的地址printf("输入节点个数:");scanf("%d",&n);phead=Create_link(n); //创建链表,把链表的头结点地址给phead//这样phead就指向一个链表了,然后就可以把整个链表给确定了pri_link(phead); //输出链表printf("输入要删除的学号:");scanf("%d",&num);phead=delet_link(phead,num); //删除结点pri_link(phead); //输出结点
}
十、插入节点
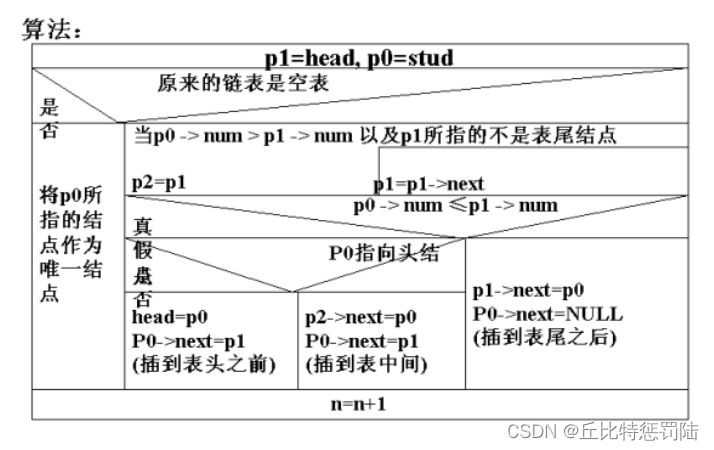
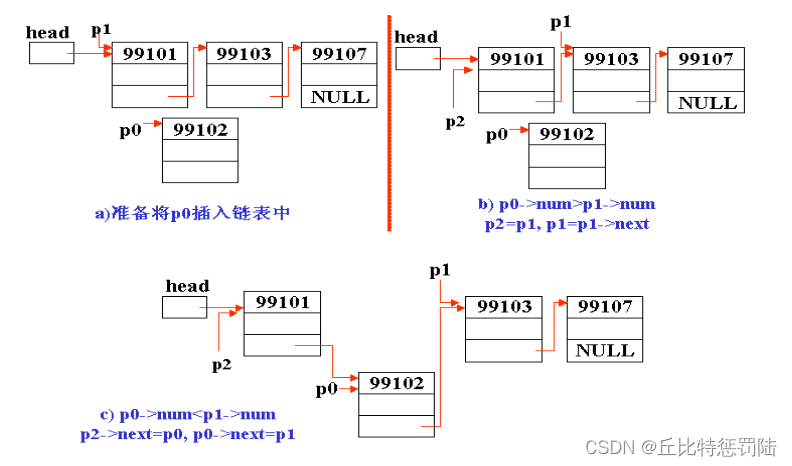
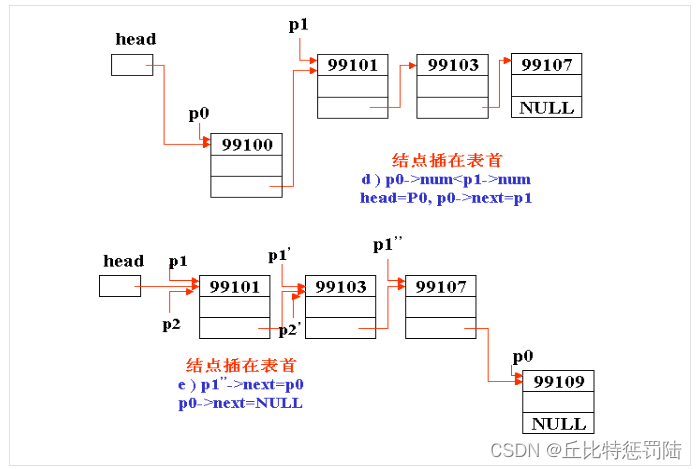
/*
==========================功能:插入指定节点的后面返回:指向链表表头的指针
==========================
*/
struct STU* insert_link(struct STU* phead)
{struct STU *ph,*pf,*p;ph=phead;p=(struct STU *)malloc(sizeof(struct STU));printf("输入插入的数据:");scanf("%d %s",&p->num,p->name);if(phead==NULL){phead=p; // 既是头结点,又是尾结点p->pnext ==NULL; }else{while((p->num)>(ph->num)&&ph->pnext!=NULL){pf=ph; //保存当前节点的地址ph=ph->pnext; //后移一个节点}if(ph==phead)//头节点插入{p->pnext=phead; // p->pnext 新插入的节点指向原来的头结点phead=p;//新插入的节点为新的头结点}else if(p->num<=ph->num){pf->pnext=p;p->pnext=ph;}else{ph->pnext =p;p->pnext ==NULL; }}return phead;
}
十一、整体代码
#include<stdio.h>
#include<stdlib.h>struct STU
{//数据域int num;char name[10];//指针域struct STU *pnext;//pnext指向下一个结点的指针
};
//p->pnext ;//p把指向结构体变量中的pnext成员本身
//函数声明
struct STU * Create_link(int n);
void pri_link(struct STU *phead);
struct STU * search_link(struct STU *phead,int num);
struct STU * delet_link(struct STU *phead,int num);
struct STU* insert_link(struct STU* phead);int main()
{int n,num;struct STU *phead; //phead用来存放链表头结点的地址printf("输入节点个数:");scanf("%d",&n);phead=Create_link(n); //创建链表,把链表的头结点地址给phead//这样phead就指向一个链表了,然后就可以把整个链表给确定了pri_link(phead); //输出链表printf("输入要查找人的学号:");scanf("%d",&num);search_link(phead,num); //查找结点printf("输入要删除的学号:");scanf("%d",&num);phead=delet_link(phead,num); //删除结点pri_link(phead); //输出结点phead=insert_link(phead); //插入结点pri_link(phead); //输出链表return 0;
}/*
==========================
功能:创建n个节点的链表
返回:指向链表表头的指针
==========================
*/
struct STU * Create_link(int n)
{struct STU *phead,*p,*pf; // phead为头指针,p为后一结点的指针变量,//pf为指向两相邻结点的前一结点的指针变量。int i;for(i=1;i<=n;i++){printf("输入第%d个人的数据:",i);//分配了一个不存放有效数据的头结点p=(struct STU*)malloc(sizeof(struct STU));scanf("%d %s",&p->num,&p->name);if(i==1) //只有一个结点{phead=p; //节点总数是1,phead指向刚创建的节点ppf=p;}else{pf->pnext =p; //指向下一个结点的首地址(新结点)pf=p; //把p的地址留给pf,然后p产生新的结点} }p->pnext=NULL; //单向链表的最后一个节点要指向NULLreturn phead; //返回创建链表的头指针
}//输出链表中的数据
void pri_link(struct STU *phead)
{struct STU *ph=phead; //phead->pnext等价于(*phead).pnextwhile(ph->pnext!=NULL) //只要不是空链表,就输出链表中所有节点{ //此时ph指向了第一个有效节点printf("%d %s\n",ph->num,ph->name);//输出ph指向的数据域的数据ph=ph->pnext; //移到下一个节点,不能写ph++}printf("%d %s\n",ph->num,ph->name);
}//通过学号查找学生的信息
struct STU * search_link(struct STU *phead,int num)
{//判断链表是否为空;//不为空通过比较找到此人信息//查无此人;struct STU *ph=phead;if(ph==NULL) //空链表{printf("此链表为空链表!\n");}else{
//ph指向的节点不是所要查找的,并且它不是最后一个节点,就继续往下找while(ph->pnext!=NULL&&ph->num!=num){ph=ph->pnext; //后移一个节点}if(ph->num==num) //找到了{printf("查到此人信息为:");printf("%d %s\n",ph->num,ph->name);}else{printf("查无此人\n");ph=NULL;}}return ph;
}//删除节点struct STU * delet_link(struct STU *phead,int num)
{struct STU *ph,*pf;ph=phead;if(ph==NULL) //空链表{printf("此链表为空链表!\n");goto end;}else{//ph指向的节点不是所要删除的,并且它不是最后一个节点,就继续往下找while((ph->num!=num)&&(ph->pnext!=NULL)){pf=ph; //保存当前节点的地址ph=ph->pnext; //后移一个节点}if(ph->num==num) //找到了{if(ph==phead)//如果要删除的节点是第一个节点{//头指针指向第一个节点的后一个节点,也就是第二个节点。//这样第一个节点就不在链表中,即删除phead=ph->pnext;}else if(ph->pnext==NULL) //最后一个结点{pf->pnext =NULL;}else{//如果是其它节点,则让原来指向当前节点的指针,//指向它的下一个节点,完成删除pf->pnext=ph->pnext; }printf("找到此人\n");free(ph); //释放当前节点,这上步不能少printf("删除成功!\n"); }else{printf("查无此人\n");ph=NULL;}}
end:return phead;
}//插入节点
struct STU* insert_link(struct STU* phead)
{struct STU *ph,*pf,*p;ph=phead;p=(struct STU *)malloc(sizeof(struct STU));printf("输入插入的数据:");scanf("%d %s",&p->num,p->name);if(phead==NULL) //头链表为空链表时{phead=p;p->pnext ==NULL;}else{while((p->num)>(ph->num)&&(ph->pnext!=NULL)) //查询p->num是否<=链表中某个结节{pf=ph;ph=ph->pnext;}if(ph==phead) //在链表首插入{p->pnext=phead;phead=p;}else if((p->num)<=(ph->num)) //判断是否有符合条件的结点{pf->pnext=p; //在两个结点中间插入结点p->pnext=ph;}else //插入在尾结点{ph->pnext =p;p->pnext ==NULL; }}return phead;
}
数组:
优点:存取速度快;缺点:需要一个连续的,很大的内存,插入和删除元素效率很低。
链表:
优点:插入删除元素效率高,不需要一个连续的很大的内存;缺点:查找某个位置的元素效率低。
相关文章:
链表(超详细--包教包会)
目录 一、概述 二、对链表的基本操作 三、链表的分类 四、静态链表 五、动态链表 1、malloc函数 2、calloc函数 3、free函数 六、动态链表的建立 七、输出链表中的数据 八、查找节点 九、删除节点 十、插入节点 十一、整体代码 一、概述 链表存储结构是一种动态数据…...

爬虫基本知识的认知(爬虫流程 HTTP构建)| 爬虫理论课,附赠三体案例
爬虫是指通过程序自动化地从互联网上获取数据的过程。 基本的爬虫流程可以概括为以下几个步骤: 发送 HTTP 请求:通过 HTTP 协议向指定的 URL 发送请求,获取对应的 HTML 页面。解析 HTML 页面:使用 HTML 解析器对获取的 HTML 页面…...
Ubuntu20.04如何安装虚拟机(并安装Android)
安装虚拟机(KVM)这种KVM只能安装windows无法安装安卓(From https://phoenixnap.com/kb/ubuntu-install-kvm)A type 2 hypervisor enables users to run isolated instances of other operating systems inside a host system. As a Linux based OS, Ubun…...

【腾讯一面】我对我的Java基础不自信了
我对我的Java基础不自信了1、List和set的区别?2、HashSet 是如何保证不重复的3、HashMap是线程安全的吗,为什么不是线程安全的?4、HashMap的扩容过程5、Java获取反射的三种方法6、Redis持久化机制原理7、redis持久化的方式各有哪些优缺点1、L…...

前端都在聊什么 - 第 2 期
Hello 小伙伴们早上、中午、下午、晚上、深夜好,我是爱折腾的 jsliang~「前端都在聊什么」是 jsliang 日常写文章/做视频/玩直播过程中,小伙伴们的提问以及我的解疑整理。本期对应 2023 年的 01.16-01.31 这个时间段。本期针对「规划」「工作」「学习」「…...
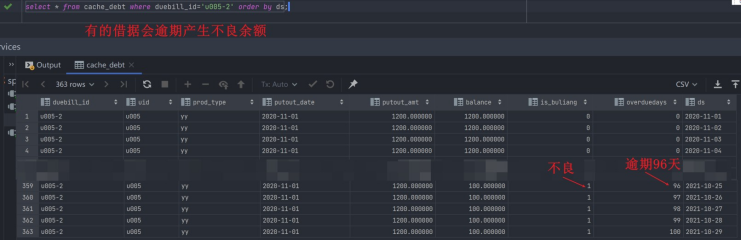
每天一道大厂SQL题【Day11】微众银行真题实战(一)
每天一道大厂SQL题【Day11】微众银行真题实战(一) 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…...
 -- 不可不知的开发术语)
Cosmos 基础教程(一) -- 不可不知的开发术语
CometBFT DOC 您可以在本节中找到几个技术术语的概述,包括每个术语的解释和进一步资源的链接——在使用Cosmos SDK进行开发时,所有这些都是必不可少的。 在本节中,您将了解以下术语: Cosmos and Interchain LCD RPC Protobuf -协议缓冲…...

JAVA JDK 常用工具类和工具方法
目录 Pair与Triple Lists.partition-将一个大集合分成若干 List集合操作的轮子 对象工具Objects 与ObjectUtils 字符串工具 MapUtils Assert断言 switch语句 三目表达式 IOUtils MultiValueMap MultiMap JAVA各个时间类型的转换(LocalDate与Date类型&a…...
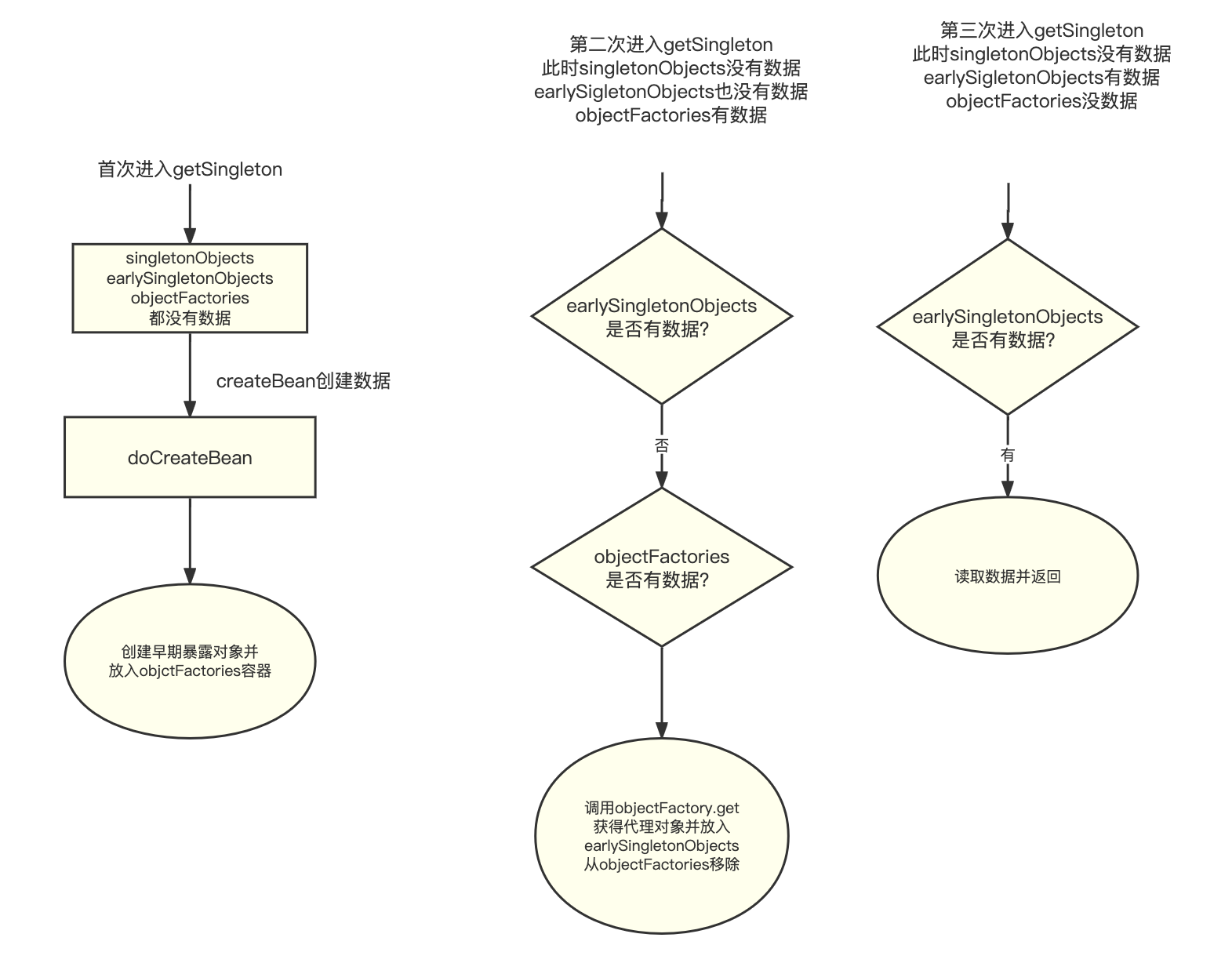
Spring Bean循环依赖
解决SpringBean循环依赖为什么需要3级缓存?回答:1级Map保存单例bean。2级Map 为了保证产生循环引用问题时,每次查询早期引用对象,都拿到同一个对象。3级Map保存ObjectFactory对象。数据结构1级Map singletonObjects2级Map earlySi…...
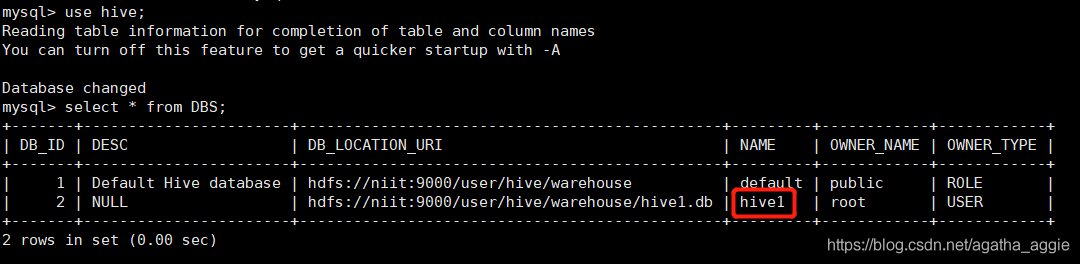
Hive 2.3.0 安装部署(mysql 8.0)
Hive安装部署 一.Hive的安装 1、下载apache-hive-2.3.0-bin.tar.gz 可以自行下载其他版本:http://mirror.bit.edu.cn/apache/hive/ 2.3.0版本链接:https://pan.baidu.com/s/18NNVdfOeuQzhnOHVcFpnSw 提取码:xc2u 2、用mobaxterm或者其他连接…...

IPD术语表
简称英文全称中文ABPannual business plan年度商业计划ABCactivity -based costing基于活动的成本估算ABMactivity -based management基于活动的管理ADCPavailability decision check point可获得性决策评审点AFDanticipatory failure determination预防错误决定AMEadvanced ma…...

目标检测损失函数 yolos、DETR为例
yolos和DETR,除了yolos没有卷积层以外,几乎所有操作都一样。 HF官方文档 因为目标检测模型,实际会输出几百几千个“框”,所以损失函数计算比较复杂。损失函数为偶匹配损失 bipartite matching loss,参考此blog targe…...
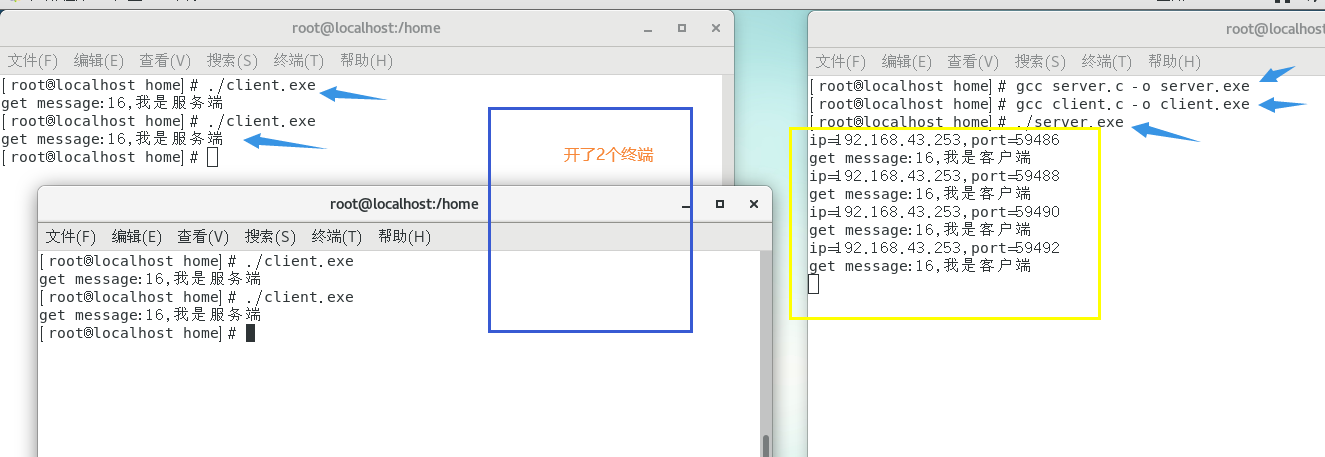
linux系统编程2--网络编程socket
在linux系统编程中网络编程是使用socket(套接字),socket这个词可以表示很多概念:在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通讯中的一个进程,“IP地址端口号”就称为socket。在TCP协议中&#…...

FPGA纯Verilog实现任意尺寸图像缩放,串口指令控制切换,贴近真实项目,提供工程源码和技术支持
目录1、前言2、目前主流的FPGA图像缩放方案3、本方案的优越性4、详细设计方案5、vivado工程详解6、上板调试验证并演示7、福利:工程源码获取1、前言 代码使用纯verilog实现,没有任何ip,可在Xilinx、Intel、国产FPGA间任意移植; 图…...
| 代码+思路+重要知识点)
华为OD机试题 - 最长合法表达式(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

L1-005 考试座位号
L1-005 考试座位号 每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试…...

Obsidian + remotely save + 坚果云:实现电脑端和手机端的同步
写在前面:近年来某象笔记广告有增无减,不堪其扰,便转投其它笔记,Obsidian、OneNote、Notion、flomo都略有使用,本人更偏好obsidian操作简单,然其官方同步资费甚高,囊中羞涩,所幸可通…...
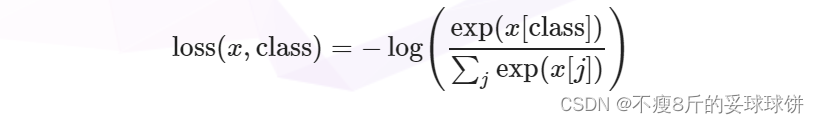
对比学习MoCo损失函数infoNCE理解(附代码)
MoCo loss计算采用的损失函数是InfoNCE: 下面是MoCo的伪代码,MoCo这个loss的实现就是基于cross entropy loss。 将k作为q的正样本,因为k与q是来自同一张图像的不同视图;将queue作为q的负样本,因为queue中含有大量…...
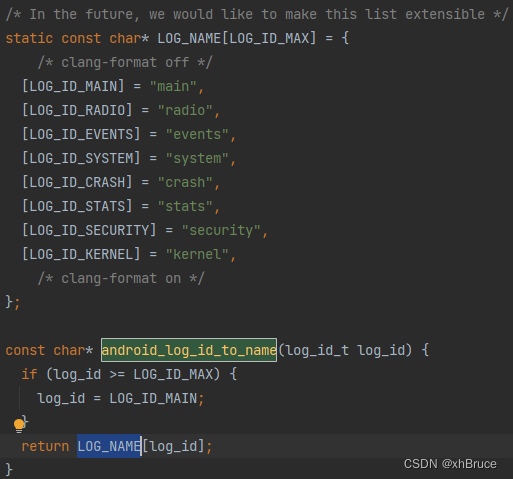
logd守护进程
logd守护进程1、adb logcat命令2、logd守护进程启动2.1 logd文件目录2.2 main方法启动3、LogBuffer缓存大小3.1 缓存大小优先级设置3.2 缓存大小相关代码位置android12-release1、adb logcat命令 命令功能adb bugreport > bugreport.txtbugreport 日志adb shell dmesg >…...
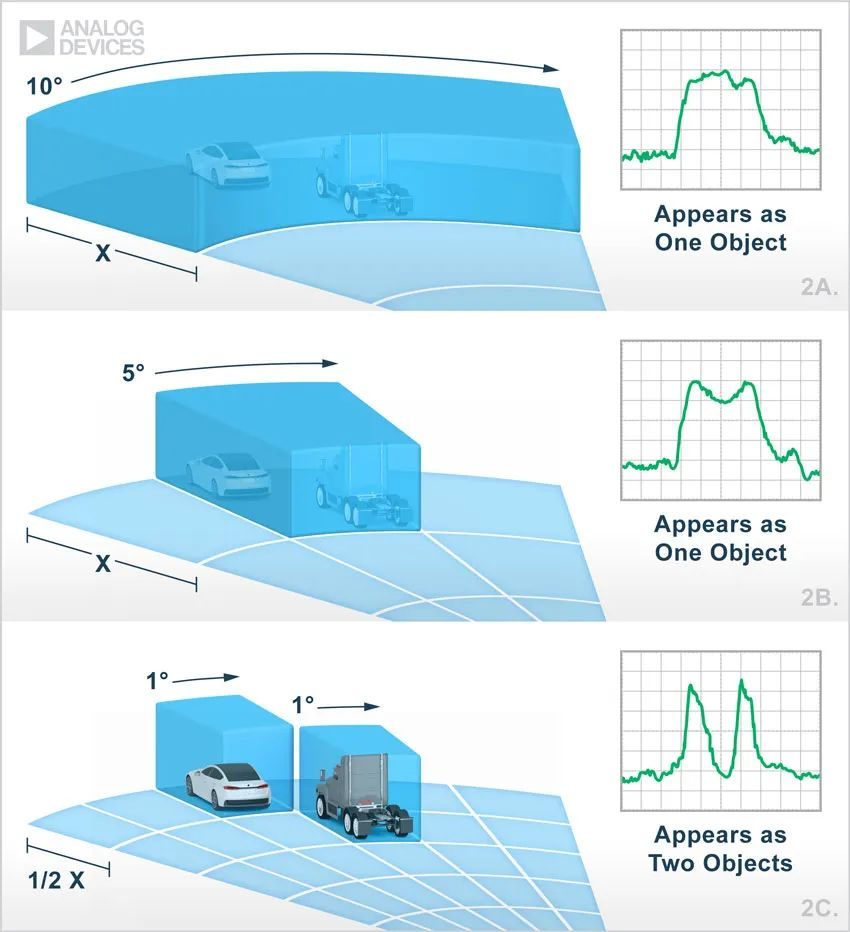
【汽车雷达通往自动驾驶的关键技术】
本文编辑:调皮哥的小助理 现代汽车雷达装置比手机还小,能探测前方、后方或侧方的盲点位置是否存在障碍物,但这还不百分之百实现全自动驾驶的。传统的汽车雷达分辨率都不高,只能“看到”一团东西,可以检测到汽车周围存在…...

AudioSeal实战案例:无障碍AI语音服务中水印与无障碍元数据共存方案
AudioSeal实战案例:无障碍AI语音服务中水印与无障碍元数据共存方案 1. 项目背景与价值 在AI语音服务快速发展的今天,如何平衡内容保护与无障碍访问成为一个重要课题。AudioSeal作为Meta开源的语音水印系统,为解决这一问题提供了创新方案。 …...

快速搭建AI绘画平台:基于图图的嗨丝造相与阿里云GPU的完整解决方案
快速搭建AI绘画平台:基于图图的嗨丝造相与阿里云GPU的完整解决方案 1. 项目概述与准备工作 1.1 什么是图图的嗨丝造相-Z-Image-Turbo 图图的嗨丝造相-Z-Image-Turbo是一个基于Z-Image-Turbo模型的LoRA变体,专门针对特定服饰风格(如大网渔网…...

DCT-Net安全加固:防范对抗样本攻击的防御方案
DCT-Net安全加固:防范对抗样本攻击的防御方案 1. 当卡通化遇上安全威胁:为什么DCT-Net需要防护 最近帮几个做数字人业务的朋友部署DCT-Net时,他们提了一个让我思考很久的问题:“我们用它生成卡通头像、做社交娱乐、甚至用于隐私…...

OpenClaw+Qwen3.5-9B:学术论文阅读助手开发实录
OpenClawQwen3.5-9B:学术论文阅读助手开发实录 1. 项目背景与需求 作为一名经常需要阅读大量学术论文的研究人员,我长期被两个问题困扰:一是PDF文献的快速消化效率低下,二是跨领域专业术语的理解成本高昂。传统解决方案要么依赖…...

Betterlockscreen缓存机制解析:为什么它比传统锁屏更快
Betterlockscreen缓存机制解析:为什么它比传统锁屏更快 【免费下载链接】betterlockscreen 🍀 sweet looking lockscreen for linux system 项目地址: https://gitcode.com/gh_mirrors/be/betterlockscreen Betterlockscreen是一款为Linux系统设计…...

如何快速上手AssetStudio:Unity游戏资源提取的终极指南
如何快速上手AssetStudio:Unity游戏资源提取的终极指南 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additional…...

Hunyuan模型支持蒙古语吗?少数民族语言翻译案例
Hunyuan模型支持蒙古语吗?少数民族语言翻译案例 1. 引言 随着全球化进程的加速,语言多样性保护和文化交流变得愈发重要。对于蒙古族同胞、语言学研究者和跨文化交流工作者来说,一个关键问题常常被提及:当前主流的大语言模型是否…...
TranslateGemma快速部署:两张显卡搞定120亿参数翻译模型
TranslateGemma快速部署:两张显卡搞定120亿参数翻译模型 1. 引言:当翻译遇上大模型,本地部署的挑战 想象一下,你需要翻译一份技术合同、一篇前沿的学术论文,或者一份包含大量专业术语的产品手册。你打开在线翻译工具…...

应对“中年危机”的前置策略:留学生入职第一天就该考虑的事情——如何建立你的“被动求职”网络?
在 2026 年的北美科技职场,拿到全职 Offer 签下字的那一刻,许多留学生会如释重负地认为自己终于进入了“保险箱”。然而,在残酷的宏观经济周期和快速迭代的 AI 浪潮面前,传统的“绝对稳定”早已不复存在。 无论是硅谷巨头…...
)
基于SpringBoot + Vue的鲜花销售系统(角色:用户、商家、管理员)
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...