DepGraph:适用任何结构的剪枝
文章目录
- 摘要
- 1、简介
- 2、相关工作
- 3、方法
- 3.1、神经网络中的依赖关系
- 3.2、依赖关系图
- 3.3、使用依赖图剪枝
- 4、实验
- 4.1、设置。
- 4.2、CIFAR的结果
- 4.3、消融实验
- 4.4、适用任何结构剪枝
- 5、结论
摘要
论文链接:https://arxiv.org/abs/2301.12900
源码:https://github.com/VainF/Torch-Pruning
结构剪枝通过从神经网络中去除结构分组参数来实现模型加速。然而,参数分组模式在不同的模型之间差异很大,这使得依赖于手动设计的分组方案的特定于体系结构的剪枝器对新的体系结构无法通用。在这项工作中,我们研究了一个极具挑战性但很少探索的任务,任何结构剪枝,以解决任意架构的一般结构剪枝,如cnn, rnn, gnn和变形金刚。实现这一雄心勃勃的目标最突出的障碍在于结构耦合,它不仅迫使不同的层同时被剪枝,而且还期望被删除的组中的所有参数始终不重要,从而避免剪枝后的显著性能下降。为了解决这一问题,我们提出了一种通用的全自动方法——依赖图(DepGraph),以显式地建模层之间的相互依赖关系和全面的组耦合参数。在这项工作中,我们在几个架构和任务上广泛评估了我们的方法,包括用于图像的ResNe(X)t, DenseNet, MobileNet和Vision transformer,用于图形的GAT,用于3D点云的DGCNN,以及用于语言的LSTM,并证明,即使使用简单的L1 norm准则,所提出的方法也始终产生令人满意的性能。
1、简介
近年来边缘计算应用的出现要求对深度神经网络进行压缩[16,22,57],而压缩深度神经网络的良好效果往往是以繁琐的网络架构为代价的[10,17,48]。在众多的网络压缩范式中,剪枝被证明是非常有效和实用的[7,11,29,30,41,54,55,66]。网络剪枝的目标是从给定的网络中去除冗余参数,以减轻其规模,并可能加快推断。主流的剪枝方法大致可以分为两种方案,结构剪枝[4,28,63]和非结构剪枝[8,13,41]。两者的核心区别在于,结构剪枝通过物理去除分组参数来改变神经网络的结构,而非结构剪枝在不修改网络结构的情况下对部分权重进行归零。与非结构剪枝相比,结构剪枝不依赖于特定的AI加速器或软件来减少内存消耗和计算成本,从而在实践中找到了更广泛的应用领域[35,61]。

然而,结构剪枝本身的性质使其本身成为一项具有挑战性的任务,特别是对于具有耦合和复杂内部结构的现代深度神经网络。其基本原理在于,深度神经网络建立在大量的基本模块上,如卷积、归一化或激活,而这些模块,无论是否参数化,都通过复杂的连接内在耦合[17,23]。因此,即使我们试图从CNN中删除一个频道(如图1(a)所示),我们也必须不可避免地同时考虑它与所有层的相互依赖性,否则我们最终会得到一个破碎的网络。准确地说,剩余连接要求两个卷积层的输出共享相同数量的通道,从而迫使它们被剪枝在一起[20,37,63]。如图1(b-d)所示,在变形金刚、rnn和gnn等其他体系结构中描述的其他网络体系结构上的结构剪枝也是如此。
不幸的是,依赖性不仅出现在剩余结构中,在现代模型中可能是无限复杂的[23,43]。现有的结构方法很大程度上依赖于个案分析来处理网络中的依赖关系[28,37]。尽管取得了有希望的结果,但这种特定于网络的剪枝方法是费时的。此外,这些方法不能直接推广,这意味着手工设计的分组方案不能转移到其他网络族甚至同一家族的网络架构中,这反过来又极大地限制了其在野外条件下的工业应用。
在本文中,我们努力为任何结构剪枝提供一个通用方案,其中任意网络架构上的结构剪枝以自动方式执行。我们方法的核心是估计依赖图(DepGraph),它显式地模拟神经网络中配对层之间的相互依赖关系。我们引入DepGraph进行结构剪枝的动机来自于观察到,在一层的结构剪枝有效地“触发”了相邻层的剪枝,这进一步导致了如图1(a)所示的链式效应{BN2←Conv2→BN1→Conv1}\left\{\mathrm{BN}_{2} \leftarrow \operatorname{Conv}_{2} \rightarrow \mathrm{BN}_{1} \rightarrow \operatorname{Conv}_{1}\right\}{BN2←Conv2→BN1→Conv1}。因此,为了跟踪不同层之间的相互依赖关系,我们可以将依赖关系链分解为一个递归过程,这个递归过程自然可以归结为在图中寻找最大连接组件的过程,通过图遍历可以以O(N)复杂度求解。具体来说,对于网络中的待剪枝层,我们可以将其作为根来触发相邻耦合层上的剪枝,然后继续以被触发层为起点,递归地重复触发过程。通过这样做,可以全面收集所有耦合层以进行剪枝。
另外值得注意的是,在结构剪枝中,对分组的层同时进行剪枝,这就要求被移除的组中的参数始终不重要,这就给现有的针对单个层设计的重要性标准带来了一定的困难[20,26,28,39]。确切地说,单个层中的参数重要性由于与其他参数化层的纠缠而不再显示正确的重要性。在不同层上估计的重要性可能是不可加的,有时甚至是自相矛盾的,这使得很难选择真正不重要的组进行剪枝。为了解决这个问题,我们充分利用了由DepGraph支持的依赖项建模的综合能力来学习组内一致的稀疏性,因此可以安全地删除那些归零的稀疏性,而不会对性能造成太大的影响。通过依赖模型,我们在实验中表明,一个简单的L1范数准则可以达到与现代方法相当的性能。
为了验证DepGraph的有效性,我们将所提出的方法应用于几个流行的架构,包括cnn[23,37]、transformer[10]、RNNs[12,50]和GNNs[52],与最先进的方法[7,31,54,63]相比,在这些架构中实现了具有竞争力的性能。对于CNN剪枝,该方法在CIFAR上得到2:57×加速ResNet-56模型,准确率为93.64%,优于原模型的93.53%。在ImageNet-1k上,我们的算法在ResNet-50上达到了比2×speed-up更多的性能,只有0.32%的性能损失。更重要的是,我们的方法可以很容易地移植到各种流行的网络,包括ResNe(X)t [37,59],DenseNet [23], VGG [48], MobileNet [45], GoogleNet[51]和Vision Transformer[10],并展示了令人满意的结果。此外,我们还对非图像神经网络进行了进一步的实验,包括用于文本分类的LSTM[12],用于3D点云的DGCNN[56],用于图形数据的GAT[52],我们的方法实现了8 ~ 16倍的加速,性能没有明显下降。
总之,我们的贡献是针对任何结构剪枝的通用剪枝方案,称为依赖图(DepGraph),它允许自动参数分组,并有效地提高了结构剪枝在各种网络架构(包括cnn, rnn, gnn和视觉变形器)上的通用性。
2、相关工作
结构和非结构剪枝。剪枝在网络加速领域取得了巨大的进展[2,19 - 21,28,32,36]。根据剪枝方案,主流的剪枝方法可以分为两种:结构剪枝[4,28,31,63,63]和非结构剪枝[8,27,41,46]。结构剪枝去除结构分组的参数以降低神经网络的维数,而非结构剪枝在不修改网络结构的情况下对部分权重进行归零。具体来说,非结构化剪枝易于实现,并且自然地可以推广到各种网络。但它通常依赖于特定的AI加速器或软件来实现模型加速。另一方面,结构剪枝技术通过从网络中去除结构参数来减少模型规模和推理成本,但受到结构约束的限制[28,35]。在文献中,剪枝算法的设计空间包括但不限于剪枝方案[21,36]、参数选择[20,40,41]、层稀疏性[26,46]和训练协议[44,54]。其中,参数选择是最重要的课题之一。在过去几年中,人们提出了大量技术上合理的标准,如基于幅度的标准[20,26,62]或基于梯度的标准[31,34]。另一种方法是通过稀疏训练来区分不重要的参数[7,32],将一些参数推到零进行剪枝。与静态准则相比,稀疏训练更容易找到不重要的参数,但由于需要网络训练,因此需要消耗更多的计算资源。
剪枝分组参数。依赖关系建模是任何结构剪枝的关键和前提步骤,因为它涉及同时删除由于复杂的网络架构而在结构上相互耦合的参数[28,31,35,63,68]。剪枝分组参数的概念早在结构剪枝的早期就被研究了[28,32,36]。例如,当剪枝两个连续的卷积层时,剪枝第一层内的过滤器会导致删除后续层[28]中与该过滤器相关的内核。一旦网络架构被提出,参数的分组是确定的,并且可以单独分析每个参数,就像在以前的大多数工作中所做的那样[28,35,63]。然而,这种人工设计的方案不可避免地不能转移到新的架构上,这限制了结构剪枝在野外条件下的应用。最近,一些试点工作被提出,以解决层之间的复杂关系,并利用分组特性来提高结构剪枝性能[31,63]。不幸的是,现有的技术仍然依赖于经验规则或强大的体系结构假设,这对于任何结构剪枝来说都不够普遍。作为这项研究的一部分,我们提出了一个解决这个问题的一般框架,并证明了寻址参数分组可以为剪枝带来显著的好处。
3、方法
3.1、神经网络中的依赖关系
在这项工作中,我们专注于在参数依赖限制下的任何神经网络的结构剪枝。在不丧失通用性的情况下,我们在全连接(FC)层上开发了我们的方法。让我们从图2 (a)所示的由三个连续层组成的线性神经网络开始,分别由2- d权重矩阵wlw_{l}wl, wl+1w_{l+1}wl+1和wl+2w_{l+2}wl+2参数化。这个简单的神经网络可以通过去除神经元进行结构剪枝而变得纤细。在这种情况下,很容易发现参数之间出现了一些依赖关系,表示为wl⇔wl+1w_{l} \Leftrightarrow w_{l+1}wl⇔wl+1,这迫使wlw_{l}wl和w_{l+1}同时被剪枝。具体来说,剪枝连接wlw_{l}wl和w_{l+1}的第k个神经元,两者都是wl[k,:]w_{l}[k,:]wl[k,:]和wl+1[:,k]w_{l+1}[:, k]wl+1[:,k]将被裁减。

在文献中,研究人员使用手工设计和模型特定的方案处理层依赖性,并在深度神经网络上实现结构剪枝[21,28]。然而,有许多种类的依赖关系,如图2 (b-d)所示。在某种程度上,以逐案的方式手动分析所有这些依赖关系是难以处理的,更不用说可以嵌套或组合简单的依赖关系来形成更复杂的模式了。为了解决结构剪枝中的依赖关系问题,本文引入了依赖关系图,它提供了一种通用的、全自动的依赖关系建模机制。
3.2、依赖关系图
分组。为了实现结构剪枝,我们首先需要根据相互依赖性对不同的层进行分组。形式上,我们的目标是找到一个分组矩阵G∈RL×LG \in R^{L \times L}G∈RL×L,其中L表示待剪枝网络的深度,Gij=1G_{i j}=1Gij=1表示第i层和第j层之间存在依赖关系。为了方便,我们让Diag(G)=11×L\operatorname{Diag}(G)=\mathbf{1}^{1 \times L}Diag(G)=11×L来实现自我依赖。利用分组矩阵,很容易找到那些与第i层相互依赖的耦合层,即找到组g(i)g(i)g(i):
g(i)={j∣Gij=1}(1)g(i)=\left\{j \mid G_{i j}=1\right\} \tag{1} g(i)={j∣Gij=1}(1)
然而,从神经网络中估计群体通常不是简单的,因为现代深度网络可能由数千个具有复杂连接的层组成,导致一个大而密集的分组矩阵g。在这个矩阵中,GijG_{ij}Gij不仅由第i层和第j层决定,而且还受到连接它们的中间层的影响。这种非局部关系不显式,大多数情况下不能用简单的规则处理。在这方面,我们没有直接估计分组矩阵G,并提出了一种等效但易于估计的方法,即依赖图,从中可以有效地推导出G。
依赖图。首先,让我们考虑一个组g={w1,w2,w3}g= \left\{w_{1}, w_{2}, w_{3}\right\}g={w1,w2,w3},有依赖关系w1⇔w2,w2⇔w3w_{1} \Leftrightarrow w_{2}, w_{2} \Leftrightarrow w_{3}w1⇔w2,w2⇔w3和w1⇔w3w_{1} \Leftrightarrow w_{3}w1⇔w3。在这个依赖关系建模中很容易发现一些冗余,即依赖关系w1⇔w3w_{1} \Leftrightarrow w_{3}w1⇔w3可以从w1⇔w2w_{1} \Leftrightarrow w_{2}w1⇔w2和w2⇔w3w_{2} \Leftrightarrow w_{3}w2⇔w3推导出来。具体来说,我们可以将此推导建模为一个递归过程:我们可以将w1作为起点,并检查它对其他层(例如w1⇔w2w_{1} \Leftrightarrow w_{2}w1⇔w2)的依赖关系。此外,w2提供了递归扩展依赖项的新起点,这将进一步“触发”w2⇔w3w_{2} \Leftrightarrow w_{3}w2⇔w3。这个递归过程最终以一个传递关系w1⇔w2⇔w3w_{1} \Leftrightarrow w_{2}\Leftrightarrow w_{3}w1⇔w2⇔w3结束。在这种情况下,我们只需要两个依赖项来描述g组中的关系。同样,第3.2节中讨论的分组矩阵也包含大量冗余,可以压缩成一个更紧凑的矩阵,具有更少的边,但关于层依赖项的信息相同。在这项工作中,我们证明了测量相邻层之间的局部相互依赖关系的图D,称为依赖图,可以有效地约简分组矩阵G。D与G的不同之处在于,它只记录具有直接连接的相邻层之间的依赖关系。实际上,依赖图可以看作是G的传递约简[1],G包含相同的顶点,但从G的边尽可能少,以至于当Gij=1G_{ij} = 1Gij=1时,D中i到j之间存在一条路径。因此,可以通过检查D中顶点i和j之间是否存在路径来推导GijG_{ij}Gij。
网络分解。然而,我们发现在层级别上构建依赖关系图是有问题的,因为一些基本层,如全连接层,有两种剪枝方案,就像第3.1节提到的那样。除了这些参数化的层,神经网络还包含诸如跳过连接等非参数化操作,这也会影响层之间的依赖关系[37]。我们表明,这些问题可以通过开发一个新的符号来描述网络来补救。具体来说,我们分解一个网络F(x;w)\mathcal{F}(x ; w)F(x;w)先进入基本层,记为F={f1,f2,…,fL}\mathcal{F}=\left\{f_{1}, f_{2}, \ldots, f_{L}\right\}F={f1,f2,…,fL},其中每个f指一个参数化层(如卷积)或一个非参数化层(如ReLU)。我们不再对层级关系建模,而是将重点放在层输入和输出之间的细粒度关系上。具体地说,我们将fif_{i}fi的输入和输出分别称为fi−f_{i}^{-}fi−和fi+f_{i}^{+}fi+。对于任何网络,我们都可以得到网络的精细-大分解,即F={f1−,f1+,…,fL−,fL−}\mathcal{F}=\left\{f_{1}^{-}, f_{1}^{+}, \ldots, f_{L}^{-}, f_{L}^{-}\right\}F={f1−,f1+,…,fL−,fL−}。使用这种符号,依赖关系建模将变得更容易,因为它允许我们用不同的方案剪枝输入fi−f_{i}^{-}fi−和输出fi+f_{i}^{+}fi+。
依赖关系建模。利用这一符号,我们将神经网络重新绘制为公式2,从中我们可以发现两种一般依赖关系,即层间依赖关系和层内依赖关系,如下所示:
(f1−,f1+)↔(f2−⏟Inter-later Dep ,f2+)⋯↔(fL−,fL+)⏟Intra-layer Dep (2)(f_{1}^{-}, \underbrace{\left.f_{1}^{+}\right) \leftrightarrow\left(f_{2}^{-}\right.}_{\text {Inter-later Dep }}, f_{2}^{+}) \cdots \leftrightarrow \underbrace{\left(f_{L}^{-}, f_{L}^{+}\right)}_{\text {Intra-layer Dep }} \tag{2} (f1−,Inter-later Dep f1+)↔(f2−,f2+)⋯↔Intra-layer Dep (fL−,fL+)(2)
其中↔\leftrightarrow↔表示相邻两层之间的连通性。我们可以用非常简单的规则来检测这些依赖关系:
- 层间依赖:依赖fi−⇔fj+f_{i}^{-} \Leftrightarrow f_{j}^{+}fi−⇔fj+总是出现在fi−↔fj+f_{i}^{-} \leftrightarrow f_{j}^{+}fi−↔fj+的连接层中。
- 层内依赖:依赖fi−⇔fi+f_{i}^{-} \Leftrightarrow f_{i}^{+}fi−⇔fi+当且仅当fi−f_{i}^{-}fi−和fi+f_{i}^{+}fi+共享相同的剪枝方案时存在,记为sch(fi−)=sch(fi+)\operatorname{sch}\left(f_{i}^{-}\right)=\operatorname{sch}\left(f_{i}^{+}\right)sch(fi−)=sch(fi+)。
如果已知网络的拓扑结构,层间依赖关系就很容易估计。对于连接的fi−↔fj+f_{i}^{-} \leftrightarrow f_{j}^{+}fi−↔fj+层,依赖关系始终存在,因为fi−f_{i}^{-}fi−和fj+f_{j}^{+}fj+在这种情况下对应于网络的相同中间特征。下一步是阐明层内依赖关系。层内依赖关系要求同时剪枝单个层的输入和输出。网络中有许多层满足这个条件,例如批处理规范化或按元素划分的操作,其输入和输出被剪枝在一起。这种现象主要是由于输入和输出之间的共享剪枝方案,即sch(fi−)=sch(fi+)\operatorname{sch}\left(f_{i}^{-}\right)=\operatorname{sch}\left(f_{i}^{+}\right)sch(fi−)=sch(fi+)。如图3所示,批处理归一化是逐个元素的操作,其输出和输入具有相同的剪枝方案。当涉及到卷积等层时,它们的输入和输出会以不同的方式剪枝,即w[:,k,:,:]w[:, k,:,:]w[:,k,:,:]和w[k,:,:,:]w[k,:,:,:]w[k,:,:,:]如图3所示,得到sch(fi−)≠sch(fi+)\operatorname{sch}\left(f_{i}^{-}\right) \neq \operatorname{sch}\left(f_{i}^{+}\right)sch(fi−)=sch(fi+)。在这种情况下,像卷积这样的层的输入和输出之间不存在依赖关系
使用上述规则,我们可以形式化依赖关系建模如下:
D(fi−,fj+)=1[fi−↔fj+]⏟Inter-layer Dep ∨1[i=j∧sch(fi−)=sch(fj+)]⏟Intra-layer Dep (3)D\left(f_{i}^{-}, f_{j}^{+}\right)=\underbrace{1\left[f_{i}^{-} \leftrightarrow f_{j}^{+}\right]}_{\text {Inter-layer Dep }} \vee \underbrace{1\left[i=j \wedge s c h\left(f_{i}^{-}\right)=\operatorname{sch}\left(f_{j}^{+}\right)\right]}_{\text {Intra-layer Dep }} \tag{3} D(fi−,fj+)=Inter-layer Dep 1[fi−↔fj+]∨Intra-layer Dep 1[i=j∧sch(fi−)=sch(fj+)](3)
其中∨\vee∨和∧\wedge∧表示逻辑“或”和“与”操作,1是一个指示函数,如果条件成立,则返回“True”。第一项研究了网络连接引起的层间依赖关系,第二项研究了层内依赖关系,这是由共享剪枝方案在层输入和输出之间引入的。值得注意的是,DepGraph是一个具有D(fi−,fj+)=D(fj+,fi−)D(f_{i}^{-},f_{j}^{+})\,=\,D(f_{j}^{+},f_{i}^{-})D(fi−,fj+)=D(fj+,fi−)。因此,我们可以检查所有输入和输出对来估计依赖关系图。作为结论,我们在图3中可视化了一个DepGraph示例。公式1和2总结了图构造和参数分组的算法。

3.3、使用依赖图剪枝
在前面的章节中,我们建立了一个分析神经网络依赖关系的通用方法,产生了几个组{g1,g2,…,gL}\left\{g_{1}, g_{2}, \ldots, g_{L}\right\}{g1,g2,…,gL}与不同的小组规模。估计分组参数的重要性是一项具有挑战性的任务。给定一个预先定义的标准,如LpL_pLp Norm KaTeX parse error: Undefined control sequence: \cal at position 2: {\̲c̲a̲l̲ ̲I}(w)\,=||w||_{… ,一个自然的解决方案是将聚合分数I(g) = Pw2g I(w),忽略不同层之间的分布差异。不幸的是,在单个层上独立估计的重要性分数很可能是不可靠的,有时还会相互冲突,因为经过剪枝的组可能同时包含重要的和不重要的权重。为了解决这个问题,我们引入了一种简单但足够通用的方法,它利用DepGraph的分组能力来全面稀疏每个组内的所有参数化层,包括但不限于卷积、批量归一化和全连接层。如图4 ©所示,我们的目标是在所有分组层上学习一致的稀疏性,同时将一些维度归零。我们将分组参数平化并合并为一个大参数矩阵wg,其中wg [k]检索属于第k个可重构维的所有参数,如CNN块的第k个通道。现在,一致的稀疏性可以通过简单的加权收缩来提升:
R(g,k)=∑w∈wg[k]γk∥w∥22(4)\mathcal{R}(g, k)=\sum_{w \in w_{g}[k]} \gamma_{k}\|w\|_{2}^{2} \tag{4} R(g,k)=w∈wg[k]∑γk∥w∥22(4)
其中γk\gamma_{k}γk对不同的尺寸赋予不同的收缩强度。我们使用一个简单而可控的指数策略来确定γ\gammaγ如下:
γk=2α(Igmax−Ig,k)/(Igmax−Igmin)(4)\gamma_{k}=2^{\alpha\left(I_{g}^{\max }-I_{g, k}\right) /\left(I_{g}^{\max }-I_{g}^{\min }\right)} \tag{4} γk=2α(Igmax−Ig,k)/(Igmax−Igmin)(4)
其中Ig,kI_{g, k}Ig,k为k维的总得分,IgI_{g}Ig为各组的重要性得分向量。超参数α控制收缩强度,范围从[20,2α]\left[2^{0}, 2^{\alpha}\right][20,2α]。在这项工作中,我们使用α=4\alpha=4α=4的所有实验。值得注意的是,强收缩将被分配给那些不重要的维度,以迫使一致的稀疏性。在稀疏训练后,我们使用归一化分数I^g=k×Ig/∑{top−k(Ig)}\hat{I}_{g}= k \times I_{g} / \sum\left\{\right. top-k \left.\left(I_{g}\right)\right\}I^g=k×Ig/∑{top−k(Ig)}来去除参数,这揭示了这些重要维度的相对分数。在这项工作中,我们展示了这样一个简单的剪枝方法,当与依赖关系建模相结合时,可以达到与现代方法相当的性能。

4、实验
4.1、设置。
本文以基础分类任务为重点,使用CIFAR[25]和ImageNet[3]进行图像分类,PPI[14]进行图形分类,ModelNet[58]进行3D点云分类,AGNews[67]进行文本分类等多种数据集进行了大量实验。对于每个数据集,我们使用最具代表性的架构来评估我们的方法,包括ResNe(X)t [37,59], VGG [48], DenseNet [23], MobileNet [45], GoogleNet [51], Vision transformer [10],LSTM [12], DGCNNs[56]和Graph Attention Networks[52]。为了进行ImageNet实验,我们使用Torchvision[38]的现成模型,并为其他数据集预训练我们自己的模型。剪枝后,模型按照与预训练类似的配置进行微调,但学习率更小,迭代次数更少。关于超参数的详细信息可以在补充材料中找到。
4.2、CIFAR的结果
性能。CIFAR[25]是一个微型图像数据集,广泛用于验证剪枝算法的有效性。我们根据已有工作[7,54],在CIFAR-10上剪枝一个ResNet-56,在CIFAR-100上剪枝一个VGG网络,如表1所示。我们比较了剪枝模型的精度以及剪枝前原始模型的精度和理论估计的加速比()。注意,像ResRep [7], GReg[54]这样的基线也部署稀疏训练进行剪枝。我们的算法与现有基于稀疏性的算法之间的一个关键区别是,我们在所有分组层上一致地促进稀疏,包括我们实验中的卷积、批量归一化和全连接层。通过这种改进,我们能够充分利用分组结构来学习更好的稀疏模型,从而提高剪枝精度。

组稀疏。如前所述,一致的稀疏群对于剪枝很重要。我们可视化了使用我们的方法和基线方法学习到的不同组的稀疏性,基线方法在不考虑层的分组特征的情况下独立地稀疏层。分组参数的L2范数如图5所示。很容易发现,我们的方法在组层面产生了很强的稀疏性,而基线方法并没有产生一致的重要性,尽管每一层都已经局部稀疏化了。特别是,组#0包含两种算法都难以稀疏的浅层,因此不会进行严格的剪枝。值得注意的是,我们的算法能够与更强大的稀疏学习技术相结合,如增长正则化[54]或重新参数化[7],但在本文中,我们只考虑简单的范数剪枝器,以使我们的方法尽可能一般地处理不同的网络。
4.3、消融实验
分组策略。为了进一步验证分组的有效性,我们在各种卷积网络上评估了不同的分组策略。策略主要包括:
1)不分组:在单个卷积层上独立执行稀疏学习和重要性评估;
2)纯卷积分组:组内所有卷积层以一致的方式稀疏化。
3)全分组:一个组内的所有可训练层,如卷积、批处理归一化和全连接层,一致地稀疏化。

如表2所示,当我们忽略神经网络中的分组信息,孤立地稀疏每一层时,我们的方法的性能会显著下降,在某些情况下甚至会因为过度剪枝而崩溃。从convononly分组的结果来看,在组中加入更多的参数有利于最终的性能,但是组中一些有用的信息仍然被忽略了。采用全分组策略可以进一步提高剪枝精度。
层稀疏。在剪枝方面,层稀疏性被认为是一个重要的设计空间,它决定了剪枝神经网络的结构。表2还提供了一些关于层稀疏性的有用结果。这项工作主要集中在两种类型的稀疏性:均匀稀疏性和学习稀疏性。使用均匀稀疏性,神经网络被均匀缩放,假设冗余分布均匀。然而,图5中先前的实验表明,不同的层并不具有相同的可重构性。在大多数情况下,习得稀疏性优于均匀稀疏性,如表2所示。因此,我们允许稀疏性学习算法自己确定层的稀疏性。

DepGraph的泛化性。表2中的结果也证明了我们的框架的可泛化性,它能够处理各种卷积神经网络。此外,我们强调了我们的方法与DenseNet和GoogleNet兼容,这是一种包含密集连接和并行结构的网络。在下面的小节中,我们将进一步演示我们的框架适用于更多的体系结构。
4.4、适用任何结构剪枝
可视化的DepGraph。由于分组参数的复杂性,剪枝大型神经网络可能具有挑战性。然而,使用依赖关系图,所有这些组都很容易获得,不需要任何额外的人力。我们在图6中可视化了DenseNet-121[23]、ResNet-18和Vision transformer[10]的依赖关系图以及派生分组。这个分组矩阵是由方法中描述的依赖关系图导出的,其中G[i;J] = 1表示第i层和第J层在同一组。DenseNet-121表现出来自同一致密块的层之间的高度相关性,这导致在结构剪枝过程中出现大的耦合组。当涉及复杂网络时,所提出的依赖关系图将是非常重要的,因为很难分析这些网络中的所有依赖关系。

ImageNet。表3展示了在ImageNet上对几种架构的剪枝结果,包括ResNet、DenseNet、MobileNet、ResNeXt和Vision transformer。这项工作的目的不是为各种模型提供最先进的结果,因此我们没有在稀疏学习和重要性估计中引入太多强大的技术。相反,我们展示了一个简单的L1范数,当与依赖模型相结合时,可以实现与使用强大标准[31,63]或更好的训练技术[54]的现代方法相当的性能。此外,我们的方法对于实际应用中的各种网络具有足够的通用性。

文本,3D点云,图形和更多。除了cnn和Transformer,我们的方法也很容易适用于其他架构。这部分包括对文本、图形、3D点云等多种数据的实验,如表4所示。我们利用LSTM进行文本分类,通过研究DepGraph在递归结构上的有效性,其中参数化层由于元素级操作而耦合。DepGraph还在包含3D点云耦合聚合操作的动态图cnn上进行了测试。此外,我们用图形数据进行实验,这需要完全不同于用于其他任务的架构。在这个实验中,我们专注于图注意网络的加速,每个GNN层中都有几个耦合层。考虑到在这些数据集上剪枝工作的不足,我们将DepGraph与cnn中的一些经典剪枝方法结合起来建立所有基线。我们的结果表明,我们的方法确实可以推广到各种各样的体系结构。

5、结论
在这项工作中,我们引入了依赖图来实现各种神经网络上的任何结构剪枝。据我们所知,我们的工作是第一次尝试开发一种通用算法,可以应用于各种架构,包括cnn、rnn、gnn和transformer。虽然我们的方法可以处理大多数深度学习结构,但也有一些异常情况,例如ShuffleNet中的洗牌操作,需要在未来进一步研究。
相关文章:
DepGraph:适用任何结构的剪枝
文章目录摘要1、简介2、相关工作3、方法3.1、神经网络中的依赖关系3.2、依赖关系图3.3、使用依赖图剪枝4、实验4.1、设置。4.2、CIFAR的结果4.3、消融实验4.4、适用任何结构剪枝5、结论摘要 论文链接:https://arxiv.org/abs/2301.12900 源码:https://gi…...
【结构体版】通讯录
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:项目 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&#x…...

Debezium系列之:基于debezium采集数据到kafka,再从kafka将数据流式传输到下游数据库
Debezium系列之:基于debezium采集数据到kafka,再从kafka将数据流式传输到下游数据库 一、需求背景二、准备Debezium集群和相关jar包的详细步骤三、查看插件是否加载成功四、源数据库表结构五、根据源数据库表结构准备目标数据库的表六、基于debezium采集数据到kafka七、查看c…...

【2023】华为OD机试真题Java-题目0217-上班之路
上班之路 题目描述 Jungle生活在美丽的蓝鲸城,大马路都是方方正正,但是每天马路的封闭情况都不一样。 地图由以下元素组成: . — 空地,可以达到;* — 路障,不可达到;S — Jungle的家;T — 公司. 其中我们会限制Jungle拐弯的次数,同时Jungle可以清除给定个数的路障,现在…...
)
基于spring生态的基础后端开发及渗透测试流程(二)
基于spring生态的基础后端开发及渗透测试流程(二)安全设备IDS蜜罐安全加固渗透测试信息收集子域名域名注册信息企业信息端口扫描源码泄露路径扫描真实ip探测js扫描设备检测蜜罐识别waf识别社工爆破漏洞扫描系统扫描web扫描应急响应继上次写了一份基于spr…...
)
Python语言零基础入门教程(二十六)
Python OS 文件/目录方法 Python语言零基础入门教程(二十五) 51、Python os.stat_float_times() 方法 概述 os.stat_float_times() 方法用于决定stat_result是否以float对象显示时间戳。 语法 stat_float_times()方法语法格式如下: os.s…...

人们最想看到的是:你在坚持什么?
【人们最想看到的是:你在坚持什么】 长远规划才能对抗不确定性 品牌也能够对抗不确定性 想想这么多年东搞搞,西搞搞 最后缺乏正向积累的【厚度】 趣讲大白话:把每滴水尽量接到碗里 人吃的是饭,拉出来的是信息 *********** 人们在频…...

300行代码手写spring初体验v1.0版本
70%猜想30%验证 spring:IOC 、DI、AOP、MVC MVC作为入口 web.xml 内部依赖一个DispathcheServlet这样一个接口 先来说一下springMVC的一些基础知识 整体的一个思路: 在web.xml里面进行了一个核心servlet的一个配置 核心就是这个DispatcherServlet …...
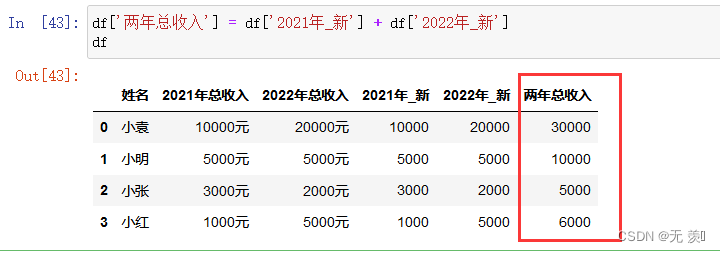
100天精通Python(数据分析篇)——第76天:Pandas数据类型转换函数pd.to_numeric(参数说明+实战案例)
文章目录专栏导读一、to_numeric参数说明0. 介绍1. arg1)接收列表2)接收一维数组3)接收Series对象2. errors1)errorscoerce2)errors ignore3. downcast1)downcastinteger2)downcastsigned3&…...
链表(超详细--包教包会)
目录 一、概述 二、对链表的基本操作 三、链表的分类 四、静态链表 五、动态链表 1、malloc函数 2、calloc函数 3、free函数 六、动态链表的建立 七、输出链表中的数据 八、查找节点 九、删除节点 十、插入节点 十一、整体代码 一、概述 链表存储结构是一种动态数据…...

爬虫基本知识的认知(爬虫流程 HTTP构建)| 爬虫理论课,附赠三体案例
爬虫是指通过程序自动化地从互联网上获取数据的过程。 基本的爬虫流程可以概括为以下几个步骤: 发送 HTTP 请求:通过 HTTP 协议向指定的 URL 发送请求,获取对应的 HTML 页面。解析 HTML 页面:使用 HTML 解析器对获取的 HTML 页面…...
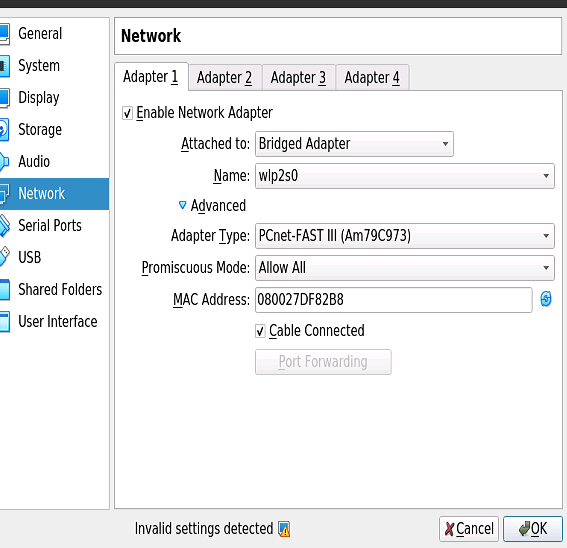
Ubuntu20.04如何安装虚拟机(并安装Android)
安装虚拟机(KVM)这种KVM只能安装windows无法安装安卓(From https://phoenixnap.com/kb/ubuntu-install-kvm)A type 2 hypervisor enables users to run isolated instances of other operating systems inside a host system. As a Linux based OS, Ubun…...

【腾讯一面】我对我的Java基础不自信了
我对我的Java基础不自信了1、List和set的区别?2、HashSet 是如何保证不重复的3、HashMap是线程安全的吗,为什么不是线程安全的?4、HashMap的扩容过程5、Java获取反射的三种方法6、Redis持久化机制原理7、redis持久化的方式各有哪些优缺点1、L…...

前端都在聊什么 - 第 2 期
Hello 小伙伴们早上、中午、下午、晚上、深夜好,我是爱折腾的 jsliang~「前端都在聊什么」是 jsliang 日常写文章/做视频/玩直播过程中,小伙伴们的提问以及我的解疑整理。本期对应 2023 年的 01.16-01.31 这个时间段。本期针对「规划」「工作」「学习」「…...
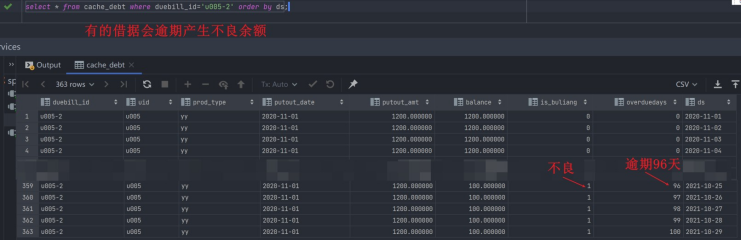
每天一道大厂SQL题【Day11】微众银行真题实战(一)
每天一道大厂SQL题【Day11】微众银行真题实战(一) 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…...
 -- 不可不知的开发术语)
Cosmos 基础教程(一) -- 不可不知的开发术语
CometBFT DOC 您可以在本节中找到几个技术术语的概述,包括每个术语的解释和进一步资源的链接——在使用Cosmos SDK进行开发时,所有这些都是必不可少的。 在本节中,您将了解以下术语: Cosmos and Interchain LCD RPC Protobuf -协议缓冲…...

JAVA JDK 常用工具类和工具方法
目录 Pair与Triple Lists.partition-将一个大集合分成若干 List集合操作的轮子 对象工具Objects 与ObjectUtils 字符串工具 MapUtils Assert断言 switch语句 三目表达式 IOUtils MultiValueMap MultiMap JAVA各个时间类型的转换(LocalDate与Date类型&a…...
Spring Bean循环依赖
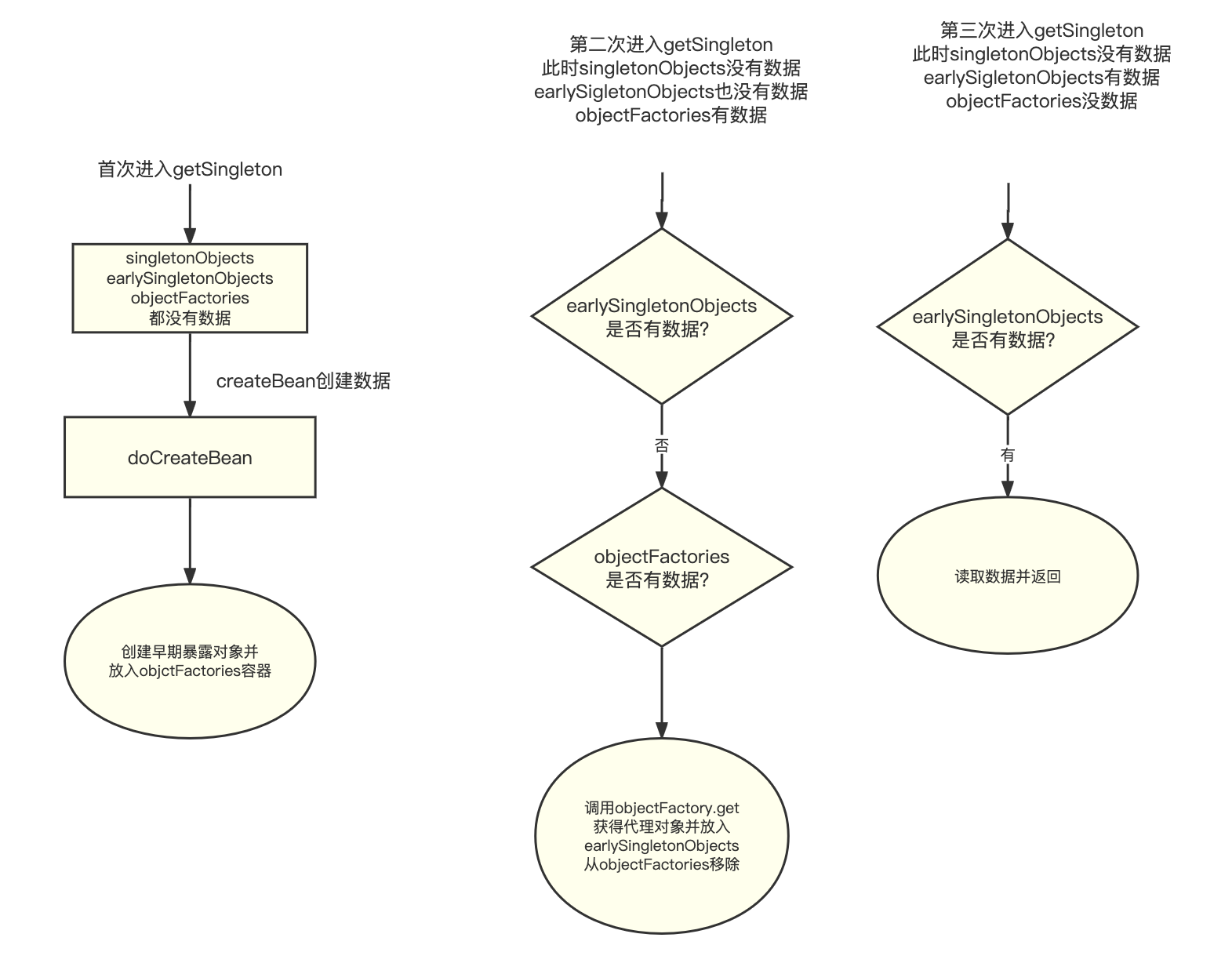
解决SpringBean循环依赖为什么需要3级缓存?回答:1级Map保存单例bean。2级Map 为了保证产生循环引用问题时,每次查询早期引用对象,都拿到同一个对象。3级Map保存ObjectFactory对象。数据结构1级Map singletonObjects2级Map earlySi…...
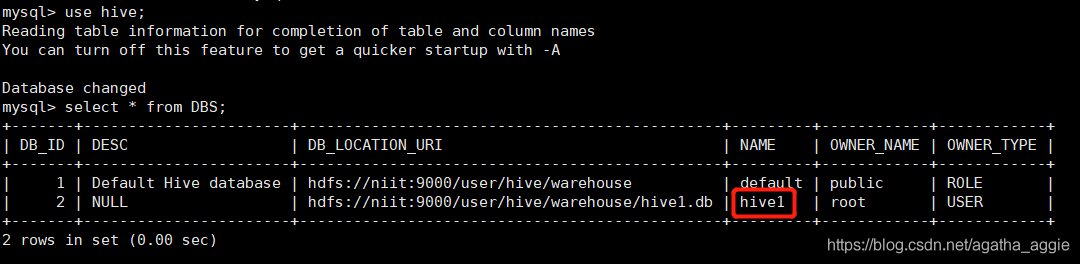
Hive 2.3.0 安装部署(mysql 8.0)
Hive安装部署 一.Hive的安装 1、下载apache-hive-2.3.0-bin.tar.gz 可以自行下载其他版本:http://mirror.bit.edu.cn/apache/hive/ 2.3.0版本链接:https://pan.baidu.com/s/18NNVdfOeuQzhnOHVcFpnSw 提取码:xc2u 2、用mobaxterm或者其他连接…...

IPD术语表
简称英文全称中文ABPannual business plan年度商业计划ABCactivity -based costing基于活动的成本估算ABMactivity -based management基于活动的管理ADCPavailability decision check point可获得性决策评审点AFDanticipatory failure determination预防错误决定AMEadvanced ma…...

SpreadJS ReportSheet 与 DataManager 实现 Token 鉴权
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

MacOS下Homebrew国内源配置全攻略:阿里、清华、中科大镜像一键切换
1. 为什么需要切换Homebrew国内镜像源? 如果你经常在MacOS上使用Homebrew安装软件,大概率遇到过下载速度慢到让人抓狂的情况。我刚开始用brew安装Python时,眼睁睁看着进度条像蜗牛爬行,一个200MB的包下了半小时还没完。后来才发现…...
 从CameraService到HAL:getCameraIdList的跨层调用与状态同步机制)
Android Camera(四) 从CameraService到HAL:getCameraIdList的跨层调用与状态同步机制
1. 从CameraManager到CameraService的调用链 当我们在Android应用中调用CameraManager.getCameraIdList()时,这个看似简单的API背后隐藏着跨越四层架构的复杂通信机制。让我们先看看Java框架层发生了什么: 在CameraManager.java中,实际工作交…...

Qwen3-VL:30B系统部署:U盘启动盘制作与安装
Qwen3-VL:30B系统部署:U盘启动盘制作与安装 1. 引言 在AI大模型快速发展的今天,本地化部署多模态模型成为许多开发者和企业的迫切需求。Qwen3-VL:30B作为强大的视觉语言模型,能够在离线环境下提供出色的多模态理解能力。但在开始模型部署之…...

OpenClaw配置备份指南:千问3.5-27B环境快速迁移
OpenClaw配置备份指南:千问3.5-27B环境快速迁移 1. 为什么需要配置备份 上周我的主力开发机突然硬盘故障,不得不更换新设备。当我重新部署OpenClaw时,发现要重新配置模型地址、飞书通道、技能列表等十几项参数,整整花了两小时才…...
)
numpy+pandas核心操作全总结:详细代码注释(数组/Series/DataFrame完整指南)
📢 更多数据分析干货,关注公众号:船长Talk,每天分享 Python/SQL 实战技巧!两个重要的包:numpy、pandas,是数据分析师的必备基础。本文做全面总结,每段代码都有详细注释,建…...

利用Aspera高效上传16S rDNA数据至NCBI的完整指南
1. 为什么选择Aspera上传16S rDNA数据 第一次尝试向NCBI上传16S rDNA测序数据时,我像大多数人一样直接使用网页上传工具。结果一个2GB的fastq文件传了整整8小时,中途还断连了3次。后来改用Aspera命令行工具,同样的文件只用了12分钟就稳定传完…...

大麦APP抢票协议分析:从‘掌密网络’代码看移动端API安全防护
大麦APP抢票协议安全防护体系深度解析 1. 移动端API安全防护的现状与挑战 在移动互联网时代,API作为应用与服务器通信的核心通道,其安全性直接关系到业务系统的稳定性和用户数据的安全。大麦APP作为国内领先的票务平台,面临着巨大的抢票压力和…...

音频算法可视化实战:用Android自定义View绘制专业级EQ/DRC曲线图
音频算法可视化实战:用Android自定义View绘制专业级EQ/DRC曲线图 在音频处理领域,EQ(均衡器)和DRC(动态范围控制)是两大核心算法。对于已经掌握这些算法原理的开发者来说,如何将它们直观地呈现给…...

AI图片清晰修复:给模糊的照片配一副“眼镜”
谁手里没存过几张模糊到让人无奈的照片?家里的老照片泛黄发糊,岁月的痕迹让亲人的眉眼变得模糊不清;随手拍下的风景、人像,稍微放大一点就满屏噪点,细节全被糊成一团;工作中存的资料图、会议截图࿰…...