100天精通Python(数据分析篇)——第76天:Pandas数据类型转换函数pd.to_numeric(参数说明+实战案例)
文章目录
- 专栏导读
- 一、to_numeric参数说明
- 0. 介绍
- 1. arg
- 1)接收列表
- 2)接收一维数组
- 3)接收Series对象
- 2. errors
- 1)`errors='coerce'`
- 2)`errors = 'ignore'`
- 3. downcast
- 1)downcast='integer'
- 2)downcast='signed'
- 3)downcast='float'
- 4. 返回值
- 5. 注意事项
- 6. 相关方法
- 二、实战案例
- 0. 导入数据
- 1. 数据类型查看
- 1)各字段的数据类型
- 2)各类型有多少个字段
- 2. 错误操作
- 3. 正确操作
- 1)提取数字
- 2)再次查看类型
- 3)使用to_numeric转换类型
- 4)数值相加
专栏导读
🏆🏆作者介绍:Python领域优质创作者、CSDN/华为云/阿里云/掘金/知乎等平台专家博主
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进千人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
一、to_numeric参数说明
数据处理、分析等操作的首要操作是我们正确地设置了数据类型,经常也会遇到事先没有处理好数据类型,而造成无法进行后续操作的困扰。而Pandas提供数据转换的函数如
to_numeric(),本文将介绍to_numeric()的参数说明和实战案例
0. 介绍
to_numeric()的作用:
-
将参数转换为数字类型。
-
默认返回dtype为float64或int64, 具体取决于提供的数据。使用downcast参数获取其他dtype。
语法格式:
pandas.to_numeric(arg, errors='raise', downcast=None)
1. arg
scalar(标量),list(列表),(tuple)元组,一维数组(1-d array)或Series
1)接收列表
import numpy as np
import pandas as pda = pd.to_numeric(['1.0', '2', -3])
print(a)
print(type(a))
运行结果:

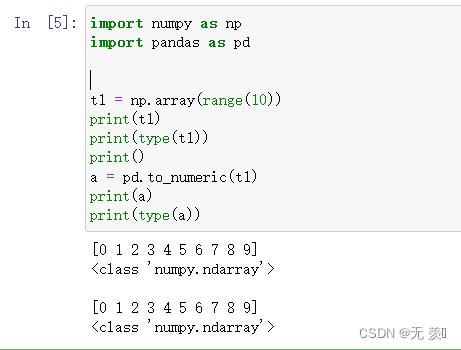
2)接收一维数组
import numpy as np
import pandas as pdt1 = np.array(range(10))
print(t1)
print(type(t1))
print()
a = pd.to_numeric(t1)
print(a)
print(type(a))
运行结果:
3)接收Series对象
import numpy as np
import pandas as pds = pd.Series(['1.0', '2', -3])
a = pd.to_numeric(s)
print(a)
print(type(a))
运行结果:

2. errors
可传入 {‘ignore’, ‘raise’, ‘coerce’}, 默认 ‘raise’,如果无法解析数据的处理方案。
'raise':如果无法解析将引发异常,通常情况下很少使用'coerce':如果无法解析将设置为 NaN'ignore':如果无效解析将返回输入
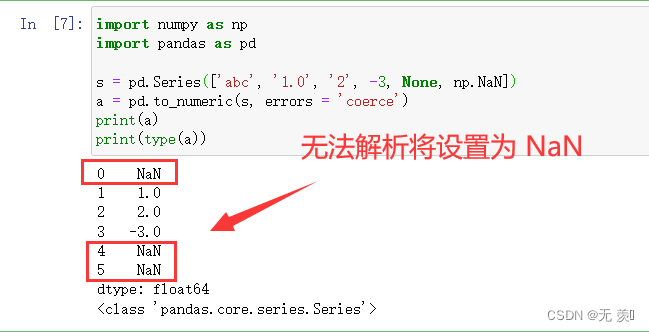
1)errors='coerce'
import numpy as np
import pandas as pds = pd.Series(['abc', '1.0', '2', -3, None, np.NaN])
a = pd.to_numeric(s, errors = 'coerce')
print(a)
print(type(a))
运行结果:
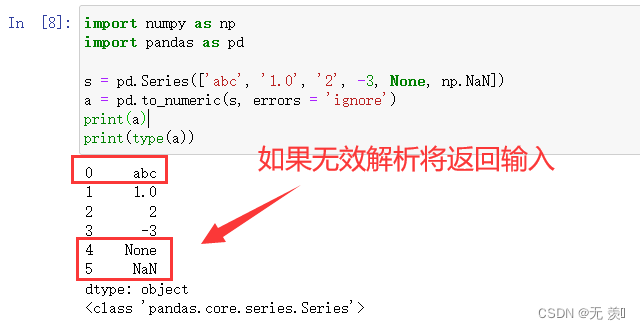
2)errors = 'ignore'
import numpy as np
import pandas as pds = pd.Series(['abc', '1.0', '2', -3, None, np.NaN])
a = pd.to_numeric(s, errors = 'ignore')
print(a)
print(type(a))
运行结果:
3. downcast
降级处理、向下转换。可传入{‘integer’,‘signed’,‘unsigned’,‘float’},默认为None。如果不是None(无),并且数据已成功转换为数字dtype(或者数据是从数字开始的),则根据以下规则将结果数据转换为可能的最小数字dtype:
'integer'或'signed':最小的有符号int dtype(最小值:np.int8)'unsigned':最小的无符号int dtype(最小值:np.uint8)'float':最小的float dtype(最小值:np.float32)注意事项:
- 由于此行为与从核心转换为数值的行为是分开的,因此无论 ‘errors’ 输入的值如何,向下转换期间引发的任何错误都会浮出水面。
- 此外,仅当结果数据的dtype的大小,严格大于要强制转换为dtype的dtype时,才会发生向下转换,因此,如果检查的所有dtype都不满足该规范,则不会对该数据执行向下转换。
- 0.19.0版中才有的新功能。
1)downcast=‘integer’
import numpy as np
import pandas as pds = pd.Series([-1, 0, 1, 2, 3], dtype="Int64")
a = pd.to_numeric(s, downcast='integer')
print(a)
print(type(a))
运行结果:

2)downcast=‘signed’
import numpy as np
import pandas as pds = pd.Series([-1, 0, 1, 2, 3], dtype="Int64")
a = pd.to_numeric(s, downcast='signed')
print(a)
print(type(a))
运行结果:

3)downcast=‘float’
import numpy as np
import pandas as pds = pd.Series([-1.0, 0.0, 1.1, 2.2, 3.3], dtype="Float64")
a = pd.to_numeric(s, downcast='float')
print(a)
print(type(a))
运行结果:

4. 返回值
解析成功时为numeric(数字)。返回类型取决于输入:
- 输入Series:返回Series
- 否则都是返回ndarray。
5. 注意事项
请注意,如果传入非常大的数字,则可能会导致精度损失。由于ndarray的内部限制,如果数字小于-9223372036854775808(np.iinfo(np.int64).min)或大于18446744073709551615(np.iinfo(np.uint64).max)传入,很有可能会将它们转换为
float以便将其存储在ndarray中。这些警告类似地适用于 Series,因为它在内部利用ndarray。
6. 相关方法
DataFrame.astype:将参数转换为指定的 dtype。
to_datetime:将参数转换为日期时间。
to_timedelta : 将参数转换为 timedelta。
numpy.ndarray.astype :将 numpy 数组转换为指定类型。
DataFrame.convert_dtypes:转换 dtypes。
二、实战案例
0. 导入数据
这里我们模拟的一份总收入数据,包含三个字段名称:
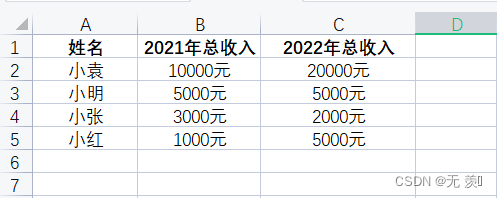
import numpy as np
import pandas as pddf = pd.read_excel(r'E:\Python学习\收入表.xlsx')
df
运行结果:
1. 数据类型查看
1)各字段的数据类型
df.dtypes # 各字段的数据类型
运行结果:

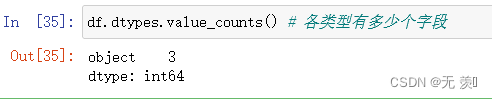
2)各类型有多少个字段
df.dtypes.value_counts() # 各类型有多少个字段
运行结果:
2. 错误操作
比如我们想在数据上进行一些操作,比如将"2021年总收入"、和"2022年总收入"的数据相加:很明显数据不是我们想要的结果。

根本原因:这两个字段是字符类型,进行+操作,是直接将里面的内容拼接在一起,而不是里面数值的相加。
3. 正确操作
1)提取数字
先把这两个字段中的数字单独提取出来
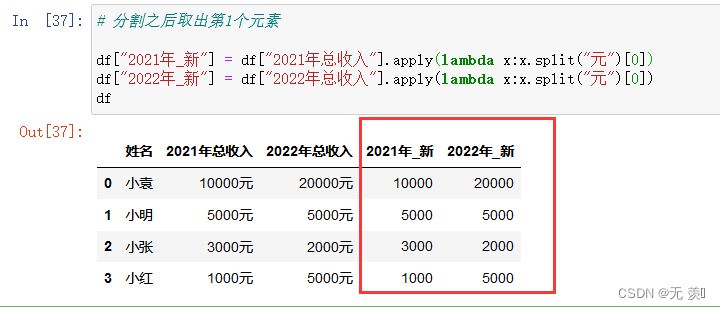
# 分割之后取出第1个元素df["2021年_新"] = df["2021年总收入"].apply(lambda x:x.split("元")[0])
df["2022年_新"] = df["2022年总收入"].apply(lambda x:x.split("元")[0])
df
运行结果:
2)再次查看类型
生成的两个新字段仍然是object类型,不能直接相加
df.dtypes # 各字段的数据类型
运行结果:

3)使用to_numeric转换类型
将数字表现型的字符型数据转成数值型
df['2021年_新'] = pd.to_numeric(df['2021年_新'])
df['2022年_新'] = pd.to_numeric(df['2022年_新'])
df.dtypes # 各字段的数据类型
运行结果:

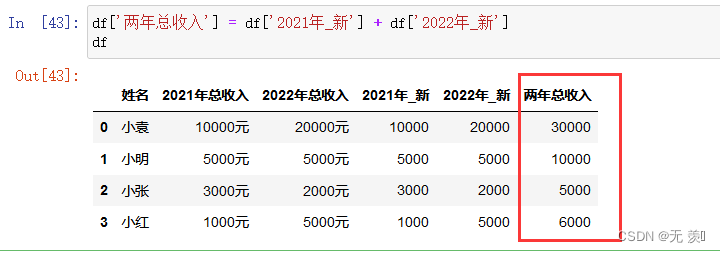
4)数值相加
df['两年总收入'] = df['2021年_新'] + df['2022年_新']
df
运行结果:
相关文章:
100天精通Python(数据分析篇)——第76天:Pandas数据类型转换函数pd.to_numeric(参数说明+实战案例)
文章目录专栏导读一、to_numeric参数说明0. 介绍1. arg1)接收列表2)接收一维数组3)接收Series对象2. errors1)errorscoerce2)errors ignore3. downcast1)downcastinteger2)downcastsigned3&…...
链表(超详细--包教包会)
目录 一、概述 二、对链表的基本操作 三、链表的分类 四、静态链表 五、动态链表 1、malloc函数 2、calloc函数 3、free函数 六、动态链表的建立 七、输出链表中的数据 八、查找节点 九、删除节点 十、插入节点 十一、整体代码 一、概述 链表存储结构是一种动态数据…...

爬虫基本知识的认知(爬虫流程 HTTP构建)| 爬虫理论课,附赠三体案例
爬虫是指通过程序自动化地从互联网上获取数据的过程。 基本的爬虫流程可以概括为以下几个步骤: 发送 HTTP 请求:通过 HTTP 协议向指定的 URL 发送请求,获取对应的 HTML 页面。解析 HTML 页面:使用 HTML 解析器对获取的 HTML 页面…...
Ubuntu20.04如何安装虚拟机(并安装Android)
安装虚拟机(KVM)这种KVM只能安装windows无法安装安卓(From https://phoenixnap.com/kb/ubuntu-install-kvm)A type 2 hypervisor enables users to run isolated instances of other operating systems inside a host system. As a Linux based OS, Ubun…...

【腾讯一面】我对我的Java基础不自信了
我对我的Java基础不自信了1、List和set的区别?2、HashSet 是如何保证不重复的3、HashMap是线程安全的吗,为什么不是线程安全的?4、HashMap的扩容过程5、Java获取反射的三种方法6、Redis持久化机制原理7、redis持久化的方式各有哪些优缺点1、L…...

前端都在聊什么 - 第 2 期
Hello 小伙伴们早上、中午、下午、晚上、深夜好,我是爱折腾的 jsliang~「前端都在聊什么」是 jsliang 日常写文章/做视频/玩直播过程中,小伙伴们的提问以及我的解疑整理。本期对应 2023 年的 01.16-01.31 这个时间段。本期针对「规划」「工作」「学习」「…...
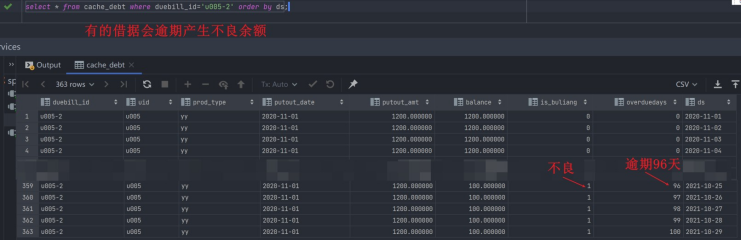
每天一道大厂SQL题【Day11】微众银行真题实战(一)
每天一道大厂SQL题【Day11】微众银行真题实战(一) 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…...
 -- 不可不知的开发术语)
Cosmos 基础教程(一) -- 不可不知的开发术语
CometBFT DOC 您可以在本节中找到几个技术术语的概述,包括每个术语的解释和进一步资源的链接——在使用Cosmos SDK进行开发时,所有这些都是必不可少的。 在本节中,您将了解以下术语: Cosmos and Interchain LCD RPC Protobuf -协议缓冲…...

JAVA JDK 常用工具类和工具方法
目录 Pair与Triple Lists.partition-将一个大集合分成若干 List集合操作的轮子 对象工具Objects 与ObjectUtils 字符串工具 MapUtils Assert断言 switch语句 三目表达式 IOUtils MultiValueMap MultiMap JAVA各个时间类型的转换(LocalDate与Date类型&a…...
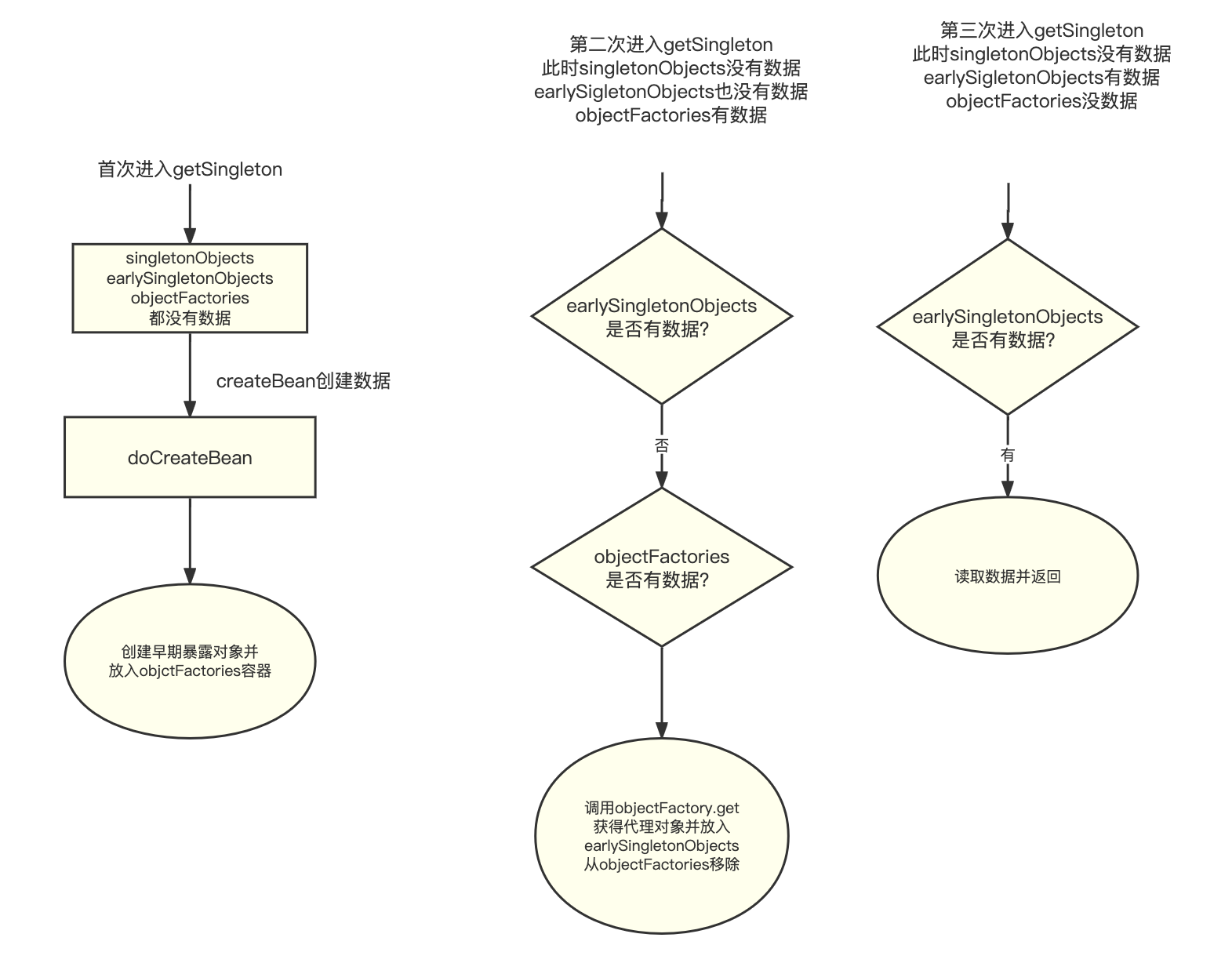
Spring Bean循环依赖
解决SpringBean循环依赖为什么需要3级缓存?回答:1级Map保存单例bean。2级Map 为了保证产生循环引用问题时,每次查询早期引用对象,都拿到同一个对象。3级Map保存ObjectFactory对象。数据结构1级Map singletonObjects2级Map earlySi…...
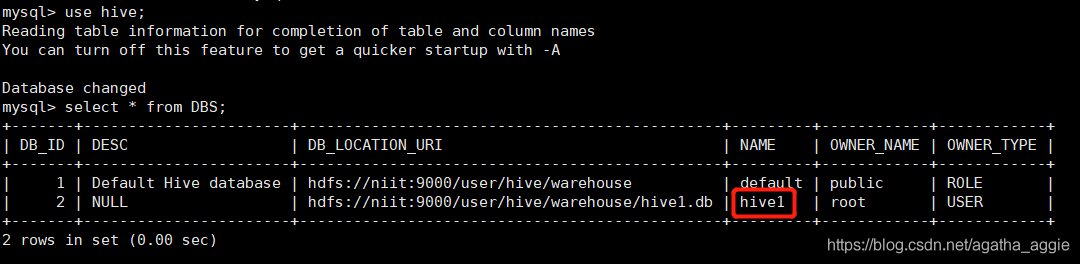
Hive 2.3.0 安装部署(mysql 8.0)
Hive安装部署 一.Hive的安装 1、下载apache-hive-2.3.0-bin.tar.gz 可以自行下载其他版本:http://mirror.bit.edu.cn/apache/hive/ 2.3.0版本链接:https://pan.baidu.com/s/18NNVdfOeuQzhnOHVcFpnSw 提取码:xc2u 2、用mobaxterm或者其他连接…...

IPD术语表
简称英文全称中文ABPannual business plan年度商业计划ABCactivity -based costing基于活动的成本估算ABMactivity -based management基于活动的管理ADCPavailability decision check point可获得性决策评审点AFDanticipatory failure determination预防错误决定AMEadvanced ma…...

目标检测损失函数 yolos、DETR为例
yolos和DETR,除了yolos没有卷积层以外,几乎所有操作都一样。 HF官方文档 因为目标检测模型,实际会输出几百几千个“框”,所以损失函数计算比较复杂。损失函数为偶匹配损失 bipartite matching loss,参考此blog targe…...
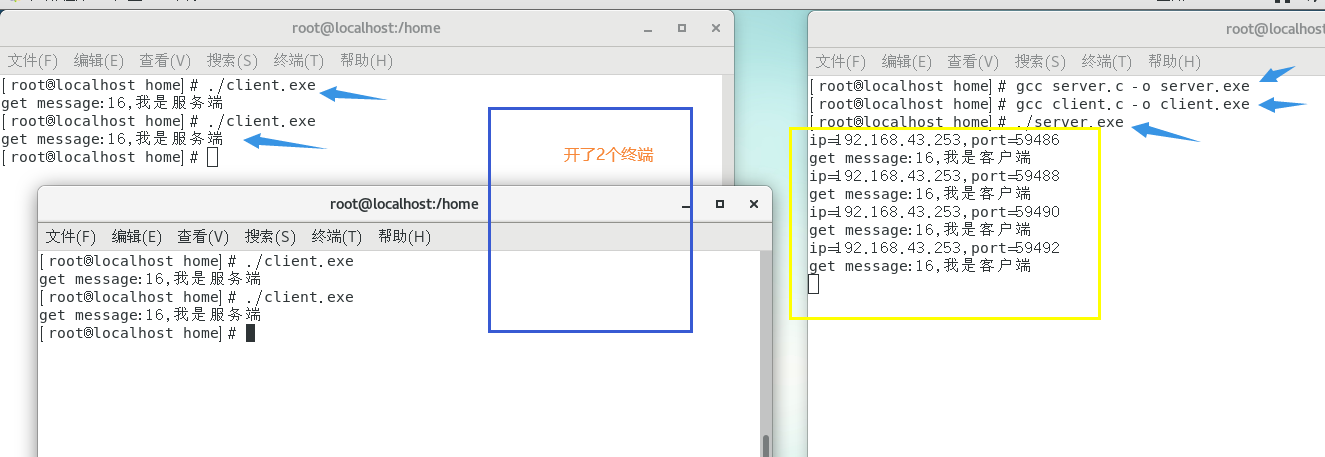
linux系统编程2--网络编程socket
在linux系统编程中网络编程是使用socket(套接字),socket这个词可以表示很多概念:在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通讯中的一个进程,“IP地址端口号”就称为socket。在TCP协议中&#…...

FPGA纯Verilog实现任意尺寸图像缩放,串口指令控制切换,贴近真实项目,提供工程源码和技术支持
目录1、前言2、目前主流的FPGA图像缩放方案3、本方案的优越性4、详细设计方案5、vivado工程详解6、上板调试验证并演示7、福利:工程源码获取1、前言 代码使用纯verilog实现,没有任何ip,可在Xilinx、Intel、国产FPGA间任意移植; 图…...
| 代码+思路+重要知识点)
华为OD机试题 - 最长合法表达式(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

L1-005 考试座位号
L1-005 考试座位号 每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试…...

Obsidian + remotely save + 坚果云:实现电脑端和手机端的同步
写在前面:近年来某象笔记广告有增无减,不堪其扰,便转投其它笔记,Obsidian、OneNote、Notion、flomo都略有使用,本人更偏好obsidian操作简单,然其官方同步资费甚高,囊中羞涩,所幸可通…...
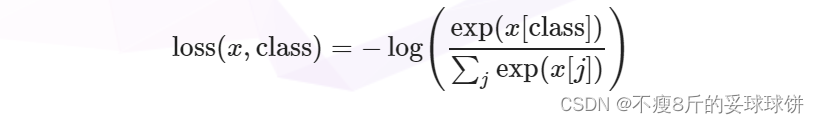
对比学习MoCo损失函数infoNCE理解(附代码)
MoCo loss计算采用的损失函数是InfoNCE: 下面是MoCo的伪代码,MoCo这个loss的实现就是基于cross entropy loss。 将k作为q的正样本,因为k与q是来自同一张图像的不同视图;将queue作为q的负样本,因为queue中含有大量…...
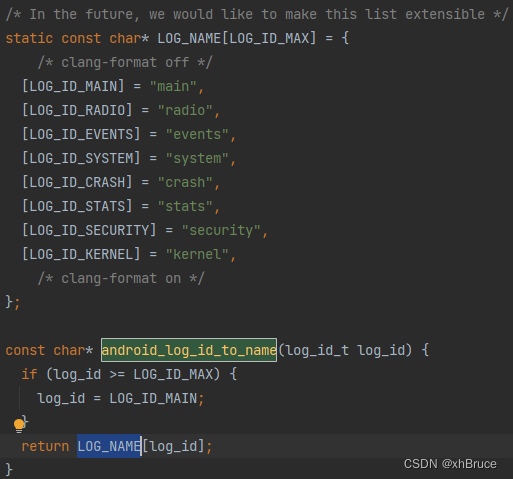
logd守护进程
logd守护进程1、adb logcat命令2、logd守护进程启动2.1 logd文件目录2.2 main方法启动3、LogBuffer缓存大小3.1 缓存大小优先级设置3.2 缓存大小相关代码位置android12-release1、adb logcat命令 命令功能adb bugreport > bugreport.txtbugreport 日志adb shell dmesg >…...

GLM-4.1V-9B-Base企业实操:教育行业试卷图像内容解析落地案例
GLM-4.1V-9B-Base企业实操:教育行业试卷图像内容解析落地案例 1. 教育行业的痛点与解决方案 在教育行业,试卷批改和内容分析一直是耗时费力的工作。传统方式需要教师人工阅卷,不仅效率低下,还容易出现主观偏差。特别是在大规模考…...

PM2 服务器服务运维入门指南
PM2 服务器服务运维入门指南 一、PM2 简介 PM2 是一个 Node.js 应用的进程管理器,支持守护进程、监控、日志管理等功能,也支持运行 Python、Shell 等脚本。 二、常用命令速查 1. 查看运行状态 pm2 ps # 查看所有运行中的服务…...

Qwen3-VL-4B Pro效果实测:看图说话、细节识别有多准?
Qwen3-VL-4B Pro效果实测:看图说话、细节识别有多准? 1. 4B模型的视觉理解能力有多强? 当谈到视觉语言模型时,很多人会问:4B参数的模型到底能看懂多少图片细节?我们通过一系列实测发现,Qwen3-…...

java凉了?985硕士都在偷偷学的大模型
Java就算了吧,太卷了,尤其现在大环境下,更卷了。连外包要求本科了,还要求经验,经验再多又不行了,因为触碰35红线了。。。 加上现在低代码平台正在吃掉CRUD基础岗,也就是说Java的话你一毕业就很难…...

MacBook安装OpenClaw:M系列芯片运行Kimi-VL-A3B-Thinking优化指南
MacBook安装OpenClaw:M系列芯片运行Kimi-VL-A3B-Thinking优化指南 1. 为什么要在M系列MacBook上部署OpenClaw 去年我入手了M2 Max芯片的MacBook Pro,原本只是用来做日常开发,直到发现它能流畅运行多模态大模型。作为一个长期被Windows平台G…...

YA-Wiegand:轻量级事件驱动Wiegand协议解析库
1. 项目概述Yet Another Arduino Wiegand Library(以下简称 YA-Wiegand)是一个专为嵌入式平台设计的轻量级、事件驱动型 Wiegand 协议解析库。它并非简单封装硬件抽象层,而是聚焦于协议语义层的健壮性实现——在不依赖特定 MCU 外设ÿ…...

Qtile配置终极指南:10个Python配置文件编写技巧
Qtile配置终极指南:10个Python配置文件编写技巧 【免费下载链接】qtile :cookie: A full-featured, hackable tiling window manager written and configured in Python (X11 Wayland) 项目地址: https://gitcode.com/gh_mirrors/qt/qtile Qtile是一款功能全…...
:并发编程的最高礼仪——两阶段终止模式)
告别 Thread.stop():并发编程的最高礼仪——两阶段终止模式
告别 Thread.stop():并发编程的最高礼仪——两阶段终止模式各位正在死磕并发编程的同学们,大家平时在学习多线程时,可能都看到过书上的一句警告:“千万不要使用 Thread.stop() 来停止线程,它是极其危险且已被废弃的”。…...

GEO监测是什么?2026年品牌主必须了解的AI可见度追踪工具
一、从一个真实场景说起 2026年,某消费品品牌的市场总监做了一个测试。 她打开DeepSeek,输入:"XX行业哪些品牌比较值得信赖?" AI给出了五个品牌,她们公司不在其中。 她换了一个问法,再问一次…...

SEO AI在网站内容创作和优化中的作用是什么
SEO AI在网站内容创作和优化中的重要性 在当前数字化时代,网站内容创作和优化已成为企业在竞争中脱颖而出的关键。在这其中,SEO AI(搜索引擎优化人工智能)正扮演着越来越重要的角色。SEO AI在网站内容创作和优化中的作用是什么呢…...