Flink流批一体计算(13):PyFlink Tabel API之SQL DDL
1. TableEnvironment
创建 TableEnvironment
from pyflink.table import Environmentsettings, TableEnvironment# create a streaming TableEnvironmentenv_settings = Environmentsettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)# or create a batch TableEnvironmentenv_settings = Environmentsettings.in_batch_mode()table_env = TableEnvironment.create(env_settings)TableEnvironment 是 Table API 和 SQL 集成的核心概念。
TableEnvironment 可以用来:
- ·创建 Table
- ·将 Table 注册成临时表
- ·执行 SQL 查询
- ·注册用户自定义的 (标量,表值,或者聚合) 函数
- ·配置作业
- ·管理 Python 依赖
- ·提交作业执行
创建 source 表
table_env.execute_sql("""CREATE TABLE datagen (id INT,data STRING) WITH ('connector' = 'datagen','fields.id.kind' = 'sequence','fields.id.start' = '1','fields.id.end' = '10')""")创建 sink 表
table_env.execute_sql("""CREATE TABLE print (id INT,data STRING) WITH ('connector' = 'print')""")2. Table
Table 是 Python Table API 的核心组件。Table 是 Table API 作业中间结果的逻辑表示。
一个 Table 实例总是与一个特定的 TableEnvironment 相绑定。
不支持在同一个查询中合并来自不同 TableEnvironments 的表,例如 join 或者 union 它们。
通过列表类型的对象创建
你可以使用一个列表对象创建一张表:
from pyflink.table import Environmentsettings, TableEnvironment# 创建 批 TableEnvironmentenv_settings = Environmentsettings.in_batch_mode()table_env = TableEnvironment.create(env_settings)table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')])table.to_pandas()==>print(table.to_pandas())table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])print(table.to_pandas())通过 DDL 创建
你可以通过 DDL 创建一张表,execute_sql(stmt) 执行指定的语句并返回执行结果。
执行语句可以是 DDL/DML/DQL/SHOW/DESCRIBE/EXPLAIN/USE。
注意,对于 "INSERT INTO" 语句,这是一个异步操作,通常在向远程集群提交作业时才需要使用。
但是,如果在本地集群或者 IDE 中执行作业时,你需要等待作业执行完成。
from pyflink.table import Environmentsettings, TableEnvironment# 创建流 TableEnvironmentenv_settings = Environmentsettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)table_env.execute_sql("""CREATE TABLE random_source (id BIGINT,data TINYINT) WITH ('connector' = 'datagen','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='3','fields.data.kind'='sequence','fields.data.start'='4','fields.data.end'='6')""")table = table_env.from_path("random_source")table.to_pandas()通过 Catalog 创建
Catalog
Catalog提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
数据处理最关键的方面之一是管理元数据。
元数据可以是临时的,例如临时表、或者通过 TableEnvironment 注册的 UDF。
元数据也可以是持久化的,例如 Hive Metastore 中的元数据。
Catalog 提供了一个统一的API,用于管理元数据,并使其可以从 Table API 和 SQL 查询语句中来访问。
Catalog类型
| GenericInMemoryCatalog | 基于内存实现的 Catalog,所有元数据只在 session 的生命周期内可用。 |
| JdbcCatalog | JdbcCatalog使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。 PostgresCatalog 是当前实现的唯一一种 JDBC Catalog。 |
| HiveCatalog | HiveCatalog 有两个用途:作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口。 |
警告 Hive Metastore 以小写形式存储所有元数据对象名称,GenericInMemoryCatalog 区分大小写。
用户自定义 Catalog
Catalog 是可扩展的,用户可以通过实现 Catalog 接口来开发自定义 Catalog。
想要在 SQL CLI 中使用自定义 Catalog,用户除了需要实现自定义的 Catalog 之外,还需要为这个 Catalog 实现对应的 CatalogFactory 接口。
CatalogFactory 定义了一组属性,用于 SQL CLI 启动时配置 Catalog。
这组属性集将传递给发现服务,在该服务中,服务会尝试将属性关联到 CatalogFactory 并初始化相应的 Catalog 实例。
创建 Flink 表并将其注册到 Catalog
使用 SQL DDL
用户可以使用 DDL 通过 Table API 或者 SQL Client 在 Catalog 中创建表。
from pyflink.table.catalog import HiveCatalog# Create a HiveCatalogcatalog = HiveCatalog("myhive", None, "<path_of_hive_conf>")# Register the catalogt_env.register_catalog("myhive", catalog)# Create a catalog databaset_env.execute_sql("CREATE DATABASE mydb WITH (...)")# Create a catalog tablet_env.execute_sql("CREATE TABLE mytable (name STRING, age INT) WITH (...)")# should return the tables in current catalog and database.t_env.list_tables()通过 SQL DDL 创建的表和视图, 例如 “create table …” 和 “create view …",都存储在 catalog 中。
你可以通过 SQL 直接访问 catalog 中的表。
使用 Java/Scala
用户可以用编程的方式使用Java 或者 Scala 来创建 Catalog 表。
from pyflink.table import *
from pyflink.table.catalog import HiveCatalog, CatalogDatabase, ObjectPath, CatalogBaseTable
from pyflink.table.descriptors import Kafka
settings = Environmentsettings.in_batch_mode()
t_env = TableEnvironment.create(settings)
# Create a HiveCatalog
catalog = HiveCatalog("myhive", None, "<path_of_hive_conf>")
# Register the catalog
t_env.register_catalog("myhive", catalog)
# Create a catalog database
database = CatalogDatabase.create_instance({"k1": "v1"}, None)
catalog.create_database("mydb", database)
# Create a catalog table
schema = Schema.new_builder() \.column("name", DataTypes.STRING()) \.column("age", DataTypes.INT()) \.build()
catalog_table = t_env.create_table("myhive.mydb.mytable", TableDescriptor.for_connector("kafka").schema(schema)// ….build())
# tables should contain "mytable"
tables = catalog.list_tables("mydb")TableEnvironment 维护了一个使用标识符创建的表的 catalogs 映射。
Catalog 中的表既可以是临时的,并与单个 Flink 会话生命周期相关联,也可以是永久的,跨多个 Flink 会话可见。
如果你要用 Table API 来使用 catalog 中的表,可以使用 “from_path” 方法来创建 Table API 对象:
from_path(path) 通过指定路径下已注册的表来创建一个表,例如通过 create_temporary_view 注册表。
相关文章:
:PyFlink Tabel API之SQL DDL)
Flink流批一体计算(13):PyFlink Tabel API之SQL DDL
1. TableEnvironment 创建 TableEnvironment from pyflink.table import Environmentsettings, TableEnvironment# create a streaming TableEnvironmentenv_settings Environmentsettings.in_streaming_mode()table_env TableEnvironment.create(env_settings)# or create…...

java笔试手写算法面试题大全含答案
1.统计一篇英文文章单词个数。 public class WordCounting { public static void main(String[] args) { try(FileReader fr new FileReader("a.txt")) { int counter 0; boolean state false; int currentChar; while((currentChar fr.read()) ! -1) { i…...
点云平面拟合和球面拟合
一、介绍 In this tutorial we learn how to use a RandomSampleConsensus with a plane model to obtain the cloud fitting to this model. 二、代码 #include <iostream> #include <thread> #include <pcl/point_types.h> #include <pcl/common/io.…...
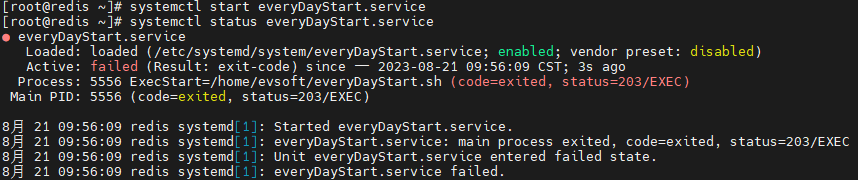
部署问题集合(十九)linux设置Tomcat、Docker,以及使用脚本开机自启(亲测)
前言 因为不想每次启动虚拟机都要手动启动一遍这些东西,所以想要设置成开机自启的状态 设置Tomcat开机自启 创建service文件 vi /etc/systemd/system/tomcat.service添加如下内容,注意修改启动脚本和关闭脚本的地址 [Unit] DescriptionTomcat9068 A…...
视觉SLAM:一直在入门,如何能精通,CV领域的绝境长城,
目录 前言 福利:文末有chat-gpt纯分享,无魔法,无限制 1 什么是SLAM? 2 为什么用SLAM? 3 视觉SLAM怎么实现? 4 前端视觉里程计 5 后端优化 6 回环检测 7 地图构建 8 结语 前言 上周的组会上&…...

【报错】yarn --version Unrecognized option: --version Error...
文章目录 问题分析解决问题 在使用 npm install -g yarn 全局安装 yarn 后,查看yarn 的版本号,报错如下 PS D:\global-data-display> yarn --version Unrecognized option: --version Error: Could...
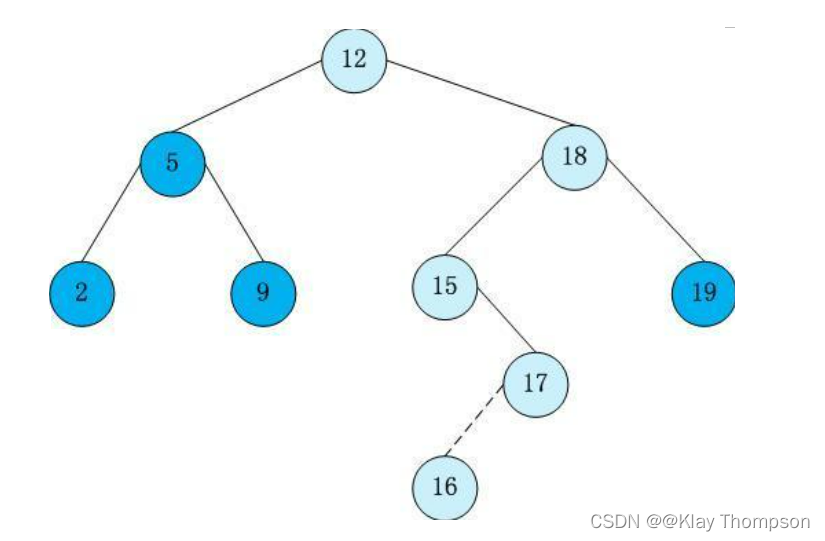
二叉搜索树的(查找、插入、删除)
一、二叉搜索树的概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 1、若它的左子树不为空,则左子树上所有节点的值都小于根节点的值; 2、若它的右子树不为空,则右子树上所有节点的值都…...

电力虚拟仿真 | 高压电气试验VR教学系统
在科技进步的推动下,我们的教育方式也在发生着翻天覆地的变化。其中,虚拟现实(VR)技术的出现,为我们提供了一种全新的、富有沉浸感的学习和培训方式。特别是在电力行业领域,例如,电力系统的维护…...

innovus如何设置size only
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 给instance设置size only属性命令如下: dbset [dbGet top.inst.name aa/bb -p] .dontTouch sizeOk 给一个module设置size only需要foreach循环一下: foreach inst [dbGet top.…...

Java之继承详解二
3.7 方法重写 3.7.1 概念 方法重写 :子类中出现与父类一模一样的方法时(返回值类型,方法名和参数列表都相同),会出现覆盖效果,也称为重写或者复写。声明不变,重新实现。 3.7.2 使用场景与案例…...
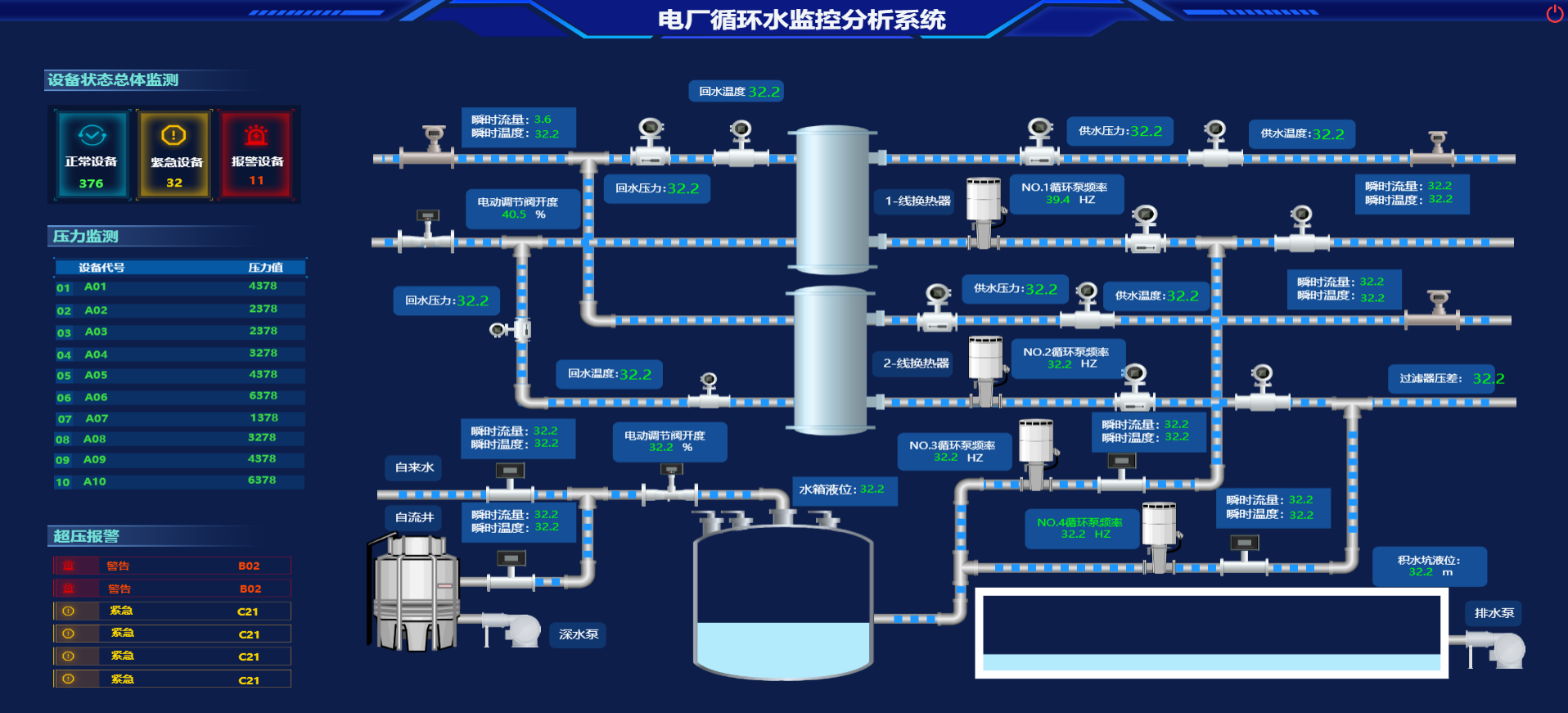
国内常见的几款可视化Web组态软件
组态软件是一种用于控制和监控各种设备的软件,也是指在自动控制系统监控层一级的软件平台和开发环境。这类软件实际上也是一种通过灵活的组态方式,为用户提供快速构建工业自动控制系统监控功能的、通用层次的软件工具。通常用于工业控制,自动…...
通过 git上传到 gitee 仓库
介绍 Git是目前世界上最先进的分布式版本控制系统,有这么几个特点: 分布式 :是用来保存工程源代码历史状态的命令行工具。保存点 :保存点可以追溯源码中的文件,并能得到某个时间点上的整个工程项目额状态;…...
设置Windows主机的浏览器为wls2的默认浏览器
1. 准备工作 wsl是可以使用Windows主机上安装的exe程序,出于安全考虑,默认情况下改功能是无法使用。要使用的话,终端需要以管理员权限启动。 我这里以Windows Terminal为例,介绍如何默认使用管理员权限打开终端,具体…...
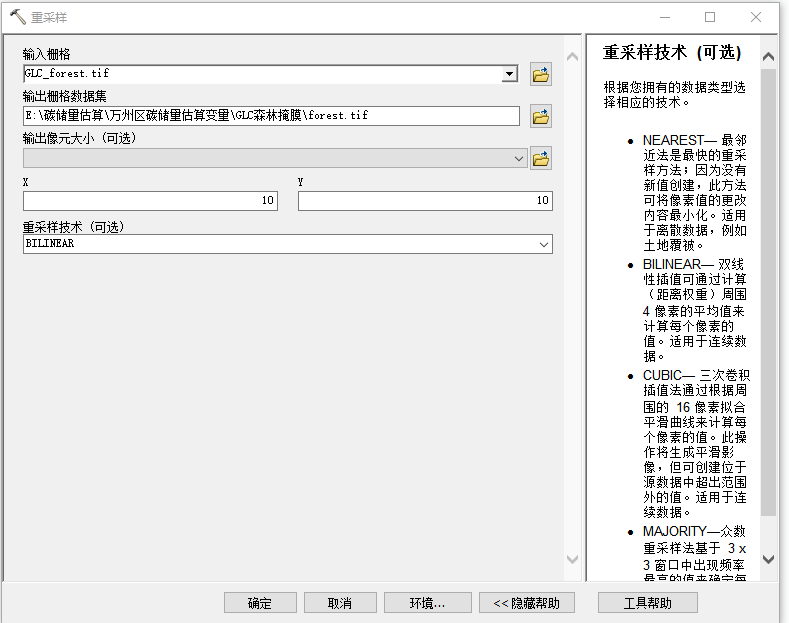
森林生物量(蓄积量)估算全流程
python森林生物量(蓄积量)估算全流程 一.哨兵2号获取/去云处理/提取参数1.1 影像处理与下载1.2 导入2A级产品1.3导入我们在第1步生成的云掩膜文件1.4.SNAP掩膜操作1.5采用gdal计算各类植被指数1.6 纹理特征参数提取 二.哨兵1号获取/处理/提取数据2.1 纹理…...
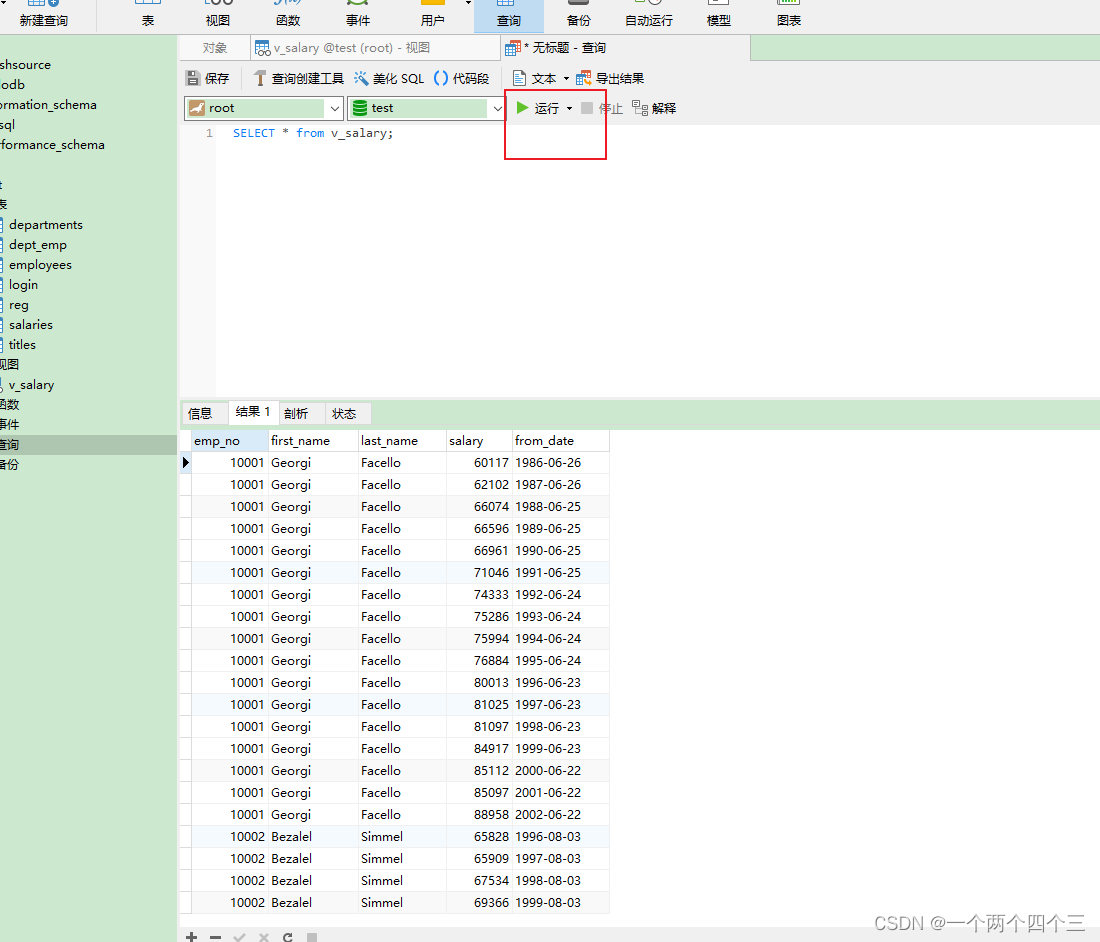
MySQL数据库概述
MySQL数据库概述 1 SQL SQL语句大小写不敏感。 SQL语句末尾应该使用分号结束。 1.1 SQL语句及相关操作示例 DDL:数据定义语言,负责数据库定义、数据库对象定义,由CREATE、ALTER与DROP三个语法所组成DML:数据操作语言ÿ…...

2023年国赛数学建模思路 - 案例:退火算法
文章目录 1 退火算法原理1.1 物理背景1.2 背后的数学模型 2 退火算法实现2.1 算法流程2.2算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 退火算法原理 1.1 物理背景 在热力学上&a…...

怎么借助ChatGPT处理数据结构的问题
目录 使用ChatGPT进行数据格式化转换 代码示例 ChatGPT格式化数据提示语 代码示例 批量格式化数据提示语 代码示例 ChatGPT生成的格式化批处理代码 使用ChatGPT合并不同数据源的数据 合并数据提示语 自动合并数据提示语 ChatGPT生成的自动合并代码 结论 数据合并是…...
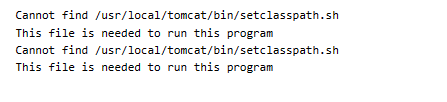
Docker容器无法启动 Cannot find /usr/local/tomcat/bin/setclasspath.sh
报错信息如下 解决办法 权限不够 加上--privileged 获取最大权限 docker run --privileged --name lenglianerqi -p 9266:8080 -v /opt/docker/lenglianerqi/webapps:/usr/local/tomcat/webapps/ -v /opt/docker/lenglianerqi/webapps/userfile:/usr/local/tomcat/webapps/u…...

Pytorch-day08-模型进阶训练技巧-checkpoint
PyTorch 模型进阶训练技巧 自定义损失函数动态调整学习率 典型案例:loss上下震荡 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BndMyRX0-1692613806232)(attachment:image-2.png)] 1、自定义损失函数 1、PyTorch已经提供了很多常用…...
:样式(Style)和符号(Symbol))
【ArcGIS Pro二次开发】(61):样式(Style)和符号(Symbol)
在 ArcGIS Pro SDK 中,地图要素符号(Symbol)和符号样式(Style)是2个很重要的概念。 【Symbol】是用于表示地图上不同类型的要素(如点、线、面)的图形化表示。 在地图中,各种要素都…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器
SOCD Cleaner终极指南:彻底解决游戏键盘方向冲突的免费开源神器 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 还在为格斗游戏中同时按下W和S导致角色卡顿而烦恼吗?或者在射击游戏急停转…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

AI 术语通俗词典:计算图
计算图是深度学习、自动微分、神经网络训练和人工智能框架中非常重要的一个术语。它用来描述:把一次数学计算过程表示成由节点和边组成的图结构。换句话说,计算图是在回答:模型中的输入、参数、运算和输出之间,到底是如何一步步连…...

构建团队技能仓库:从知识管理到可执行技能包的系统化实践
1. 项目概述:从“技能包”到高效能工具箱最近在梳理团队内部的技术资产时,我反复思考一个问题:如何让那些散落在个人电脑、项目文档和口头交流中的“隐性知识”和“高效技能”,变成一个团队可以随时取用、持续进化的公共资产&…...

模拟WiFi反向散射技术:无电池物联网通信新突破
1. 项目概述:模拟WiFi反向散射技术的革新突破在物联网设备爆炸式增长的今天,电池续航已成为制约大规模部署的关键瓶颈。传统传感器节点即使采用低功耗设计,其电池寿命也鲜有超过3-5年。而Leggiero提出的模拟WiFi反向散射技术,则开…...

Linux权限继承与umask配置实践
Linux权限继承与umask配置实践很多协作目录问题并不是因为当前权限错了,而是因为新建文件的默认权限总是不符合预期。背后的核心变量之一就是 umask。中级阶段如果不理解默认权限是怎么生成的,就会陷入“每次都手工 chmod”的低效循环。一、默认权限不是…...

大语言模型分步推理与自我验证框架:提升AI生成准确性的工程实践
1. 项目概述:当AI学会“自我验证”最近在开源社区里,一个名为“Lets-Verify-Step-by-Step”的项目引起了我的注意。这个项目直指当前大语言模型(LLM)应用中的一个核心痛点:如何让模型在生成复杂答案时,能像…...

MCP服务器生产级部署:从Docker到Kubernetes的完整工程化实践
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或使用一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且为如何将其优雅、可靠地部署到生产环境而头疼,那么你很可能需要的…...