百度商业AI 技术创新大赛赛道二:AIGC推理性能优化TOP10之经验分享
朋友们,AIGC性能优化大赛已经结束了,看新闻很多队员已经完成了答辩和领奖环节,我根据内幕人了解到,比赛的最终代码及结果是不会分享出来的,因为办比赛的目的就是吸引最优秀的代码然后给公司节省自己开发的成本,相当于外包出去了,应该是不会公开的。抱着技术共享及开放的精神,我今天把以自己复赛排名top10的经验分享出来,希望可以给参赛的朋友提供一些有帮助的信息(个人账号:我是你的狼哥)。

首先,我把比赛的草稿版本分享出来:文本生成:AIGC推理性能优化比赛_复赛及初赛第10名经验分享 - 飞桨AI Studio
这个版本省略了很多内容,因为最原始的版本里面存在大量的临时文件、测试文件和个人代码,这个版本相当于阉割了一部分,但是我会先把具体内容给大家介绍下,这样理解起来也容易。
1、方法探索
优化模型推理,官方已经给了一些基础建议,其实最开始大家就可以按照官方去做,就有提升,这中间我也踩了很多坑,同样分享出来。
(1)调节超参数,可行
调节超参数,是最快,最便捷的一个方法,但是要注意方式方法,如果你无厘头瞎jb调,会出现一会高一会低,你要想办法去接近极限,这个可以参考用到网格搜索,下面是项目中一个简单案例,在new/new.ipynb项目中
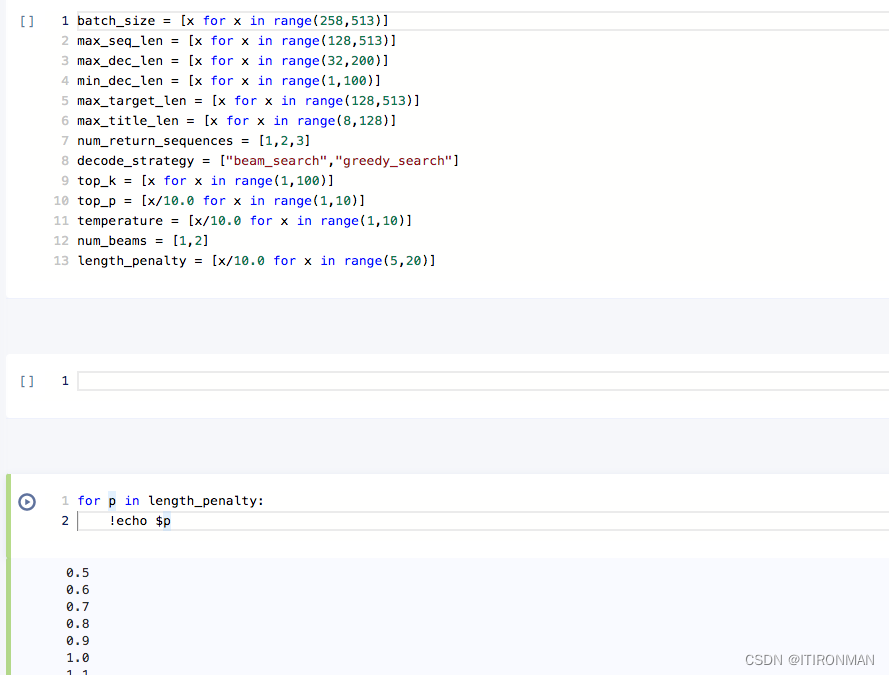
上面的代码可以自行完善,我有一个predict.py 文件,你可以挨个for循环,然后记录下最佳参数的推理速度,固化参数即可,原来我记得官方base的成绩,不调优大概是460s,如果仅通过这一项大概能优化到200s以上,但是你想再优化,那就非常难了,需要别的办法。
(2)直接调用静态库,可行
调节超参数,是挺简单的,但是他有瓶颈,你再优化可就难了,这个时候,你需要去翻paddlepaddle的源码,他推理里面就带有一些优化方法,比如
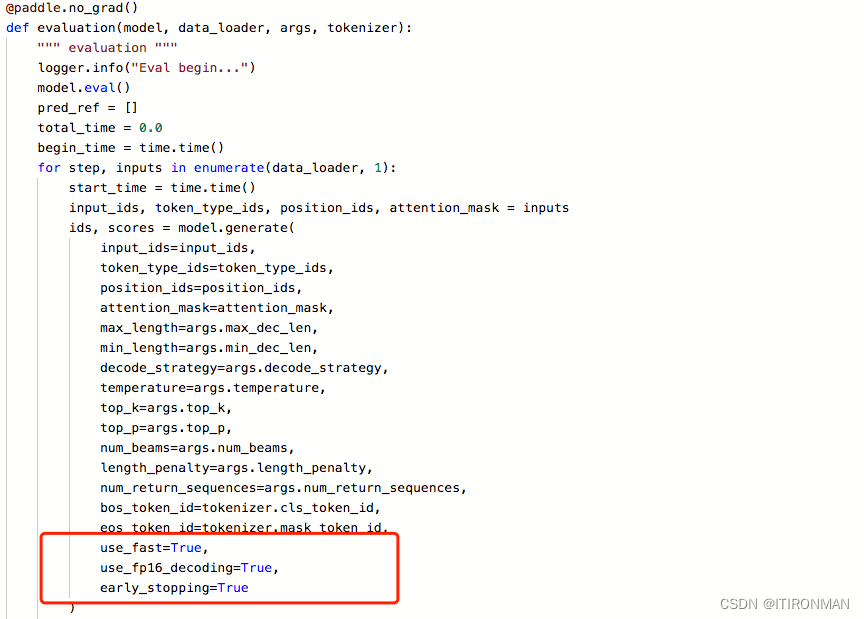
官方的run_infer.py里面,如果你在model.generate最后面三行加上这个东西,你就会发现,速度突然飞起来了,大概是能优化100s左右,好快啊!
不久,你又发现一个很奇葩的问题,你加了这个use_fast=True以后,虽然快了,但是每次第一次推理的时候,都需要重新下载、编译这个模块的静态库文件,贼慢,起码40-50s,太耗时了,不过,你翻官方文件,你会发现他只有第一次推理的时候很慢,后面就直接调用编译好的那个库文件了,会非常快!那怎么办呢?好办,我们直接把编译好的库文件找到直接调用不得了,结果证明非常可行,速度提高30-50s。
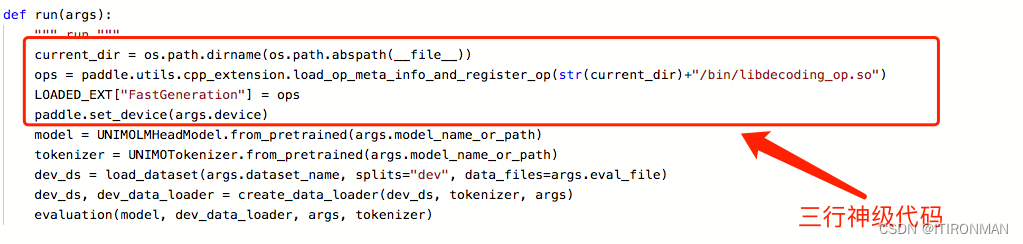
有人问了,我如何找这个so库文件,其实也很简单,你第一次推理让他原来的方式推理,推理完成后,它会自动生成这个libdecoding_op.so,直接用find全局搜就找到了,其实这是一个cpp编写的推理算子,可见cpp在这方面效率远高于python,这里还埋了一个点,后面讲。
(3)动态图转静态图推理,不可行
我估计,90%的人第一次尝试都会想着把编码阶段的动态图推理转为静态图推理,我也这么干了,并且忙活了半天,发现一个真相,速度更慢了~,没办法,试了好几次还是不行,这条路放弃了。

下面是转换代码
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.import argparse
import os
from pprint import pprintimport paddlefrom paddlenlp.ops import FasterUNIMOText
from paddlenlp.transformers import UNIMOLMHeadModel, UNIMOTokenizer
from paddlenlp.utils.log import loggerdef parse_args():parser = argparse.ArgumentParser()parser.add_argument("--model_name_or_path",default="/home/aistudio/ad_generator/model_final",type=str,help="The model name to specify the Pegasus to use. ",)parser.add_argument("--export_output_dir", default="./inference_model", type=str, help="Path to save inference model of Pegasus. ")parser.add_argument("--topk", default=80, type=int, help="The number of candidate to procedure top_k sampling. ")parser.add_argument("--topp", default=0.8, type=float, help="The probability threshold to procedure top_p sampling. ")parser.add_argument("--max_out_len", default=128, type=int, help="Maximum output length. ")parser.add_argument("--min_out_len", default=6, type=int, help="Minimum output length. ")parser.add_argument("--num_return_sequence", default=1, type=int, help="The number of returned sequence. ")parser.add_argument("--temperature", default=0.8, type=float, help="The temperature to set. ")parser.add_argument("--num_return_sequences", default=2, type=int, help="The number of returned sequences. ")parser.add_argument("--use_fp16_decoding", action="store_true", help="Whether to use fp16 decoding to predict. ")parser.add_argument("--decoding_strategy",default="beam_search",choices=["beam_search"],type=str,help="The main strategy to decode. ",)parser.add_argument("--num_beams", default=2, type=int, help="The number of candidate to procedure beam search. ")parser.add_argument("--diversity_rate", default=0.0, type=float, help="The diversity rate to procedure beam search. ")parser.add_argument("--length_penalty",default=1.2,type=float,help="The exponential penalty to the sequence length in the beam_search strategy. ",)args = parser.parse_args()return argsdef do_predict(args):place = "gpu:0"place = paddle.set_device(place)model_name_or_path = args.model_name_or_pathmodel = UNIMOLMHeadModel.from_pretrained(model_name_or_path)tokenizer = UNIMOTokenizer.from_pretrained(model_name_or_path)unimo_text = FasterUNIMOText(model=model, use_fp16_decoding=args.use_fp16_decoding, trans_out=True)# Set evaluate modeunimo_text.eval()# Convert dygraph model to static graph modelunimo_text = paddle.jit.to_static(unimo_text,input_spec=[# input_idspaddle.static.InputSpec(shape=[None, None], dtype="int64"),# token_type_idspaddle.static.InputSpec(shape=[None, None], dtype="int64"),# attention_maskpaddle.static.InputSpec(shape=[None, 1, None, None], dtype="float32"),# seq_lenpaddle.static.InputSpec(shape=[None], dtype="int64"),args.max_out_len,args.min_out_len,args.topk,args.topp,args.num_beams, # num_beams. Used for beam_search.args.decoding_strategy,tokenizer.cls_token_id, # cls/bostokenizer.mask_token_id, # mask/eostokenizer.pad_token_id, # padargs.diversity_rate, # diversity rate. Used for beam search.args.temperature,args.num_return_sequences,],)# Save converted static graph modelpaddle.jit.save(unimo_text, os.path.join(args.export_output_dir, "unimo_text"))logger.info("UNIMOText has been saved to {}.".format(args.export_output_dir))if __name__ == "__main__":args = parse_args()pprint(args)do_predict(args)(4)系统参数优化,可行
还是那句话,看paddlepaddle源码,你会有很多惊喜,源码里面有系统调优的方法,主要是对显卡调优的,于是,你可以加上下面这段神代码。

于是,你又可以提高1-3s,又是个小里程碑进步。
(5)推理代码全部改写cpp,可行但不会
在(2)的时候我埋了个点,我说后面讲,其实就是你可以把整个推理的代码也就是model.generate,全部改写为cpp,这个肯定会有大幅度提高,但是呢,我不会!我不会写cpp啊,这个只能留着自己私下尝试了,并且我问了内幕人,这个肯定可行的,私下自己试试吧,这个跟模型没关系了,是个工程的活,展开讲也没啥意思,就是个翻译过程,自己搞吧!
(6)tensorRT优化,未知
其实还有个tensorRT优化的办法,这个我试了个demo,代码里面可能有些demo尝试,效果不明显,就没往下尝试,这个效果未知,自己试试吧。
2、整体总结
上面是我整个项目的尝试,具体细节信息各位赛友自己跑一跑我的代码才知道,里面有很多错误尝试,包括我甚至还尝试了内存共享技术、多线程技术、多进程技术和异步处理等等,都不是很理想,可能你们尝试后会有提高,这里面提升最大的还得是超参优化和so库调用。
相关文章:
百度商业AI 技术创新大赛赛道二:AIGC推理性能优化TOP10之经验分享
朋友们,AIGC性能优化大赛已经结束了,看新闻很多队员已经完成了答辩和领奖环节,我根据内幕人了解到,比赛的最终代码及结果是不会分享出来的,因为办比赛的目的就是吸引最优秀的代码然后给公司节省自己开发的成本…...

微服务时代java异常捕捉
一、尽量不要使用e.printStackTrace(),而是使用log打印。 反例: try{ // do what you want }catch(Exception e){ e.printStackTrace(); } 正例: try{ // do what you want }catch(Exception e){ log.info("你的程序有异常啦,{}",e)…...

Hadoop支持LZO压缩
LZO(Lempel-Ziv-Oberhumer)是一种快速压缩算法,特别适用于大数据处理。在Hadoop生态系统中,LZO压缩通常用于Hadoop MapReduce作业的输入和输出数据,以减少存储空间和数据传输的开销。 以下是在Hadoop中使用LZO压缩的一般步骤: 安装LZO库和工具: 首先,需要在Hadoop集群…...

vue3 01-setup函数
1.setup函数的作用: 1.是组合式api的入口2.比beforeCreate 执行更早3.没有this组件实例一开始创建vue3页面的时候是这样的 <template></template> <script> export default{setup(){return{ }} } </script>给容器传参在页面中显示 数据给模板使用,以…...

iOS swift 类似AirDrop的近场数据传输 MultipeerConnectivity 框架
文章目录 1.github上的demo 1.github上的demo insidegui/MultipeerDemo – github insidegui/MultipeerKit – github...

Lnton羚通云算力平台OpenCV-PythonCanny边缘检测教程
Canny 边缘检测是一种经典的边缘检测算法,由 John F. Canny 在 1986 年提出。它被广泛应用于计算机视觉和图像处理领域,用于检测图像中的边缘。 【原理】 1. 去噪 由于边缘检测非常容易收到图像的噪声影响,第一步使用 5x5 高斯滤波去除图…...

2023-8-23 滑动窗口
题目链接:滑动窗口 #include <iostream>using namespace std;const int N 1000010;int n, k; int a[N], q[N];int main() {scanf("%d%d", &n, &k);for(int i 0; i < n; i) scanf("%d", &a[i]);int hh 0, tt -1;for(…...
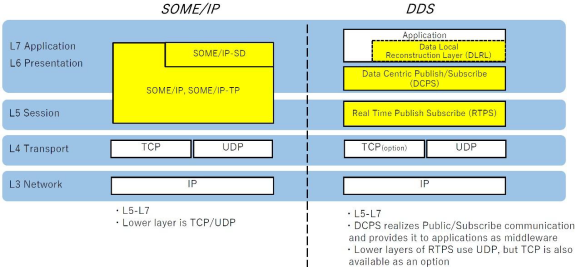
SOA通信中间件常用的通信协议
摘要: SOA(面向服务的架构)的软件设计原则之一是模块化。 前言 SOA(面向服务的架构)的软件设计原则之一是模块化。模块化可以提高软件系统的可维护性和代码重用性,并且能够隔离故障。举例来说,…...
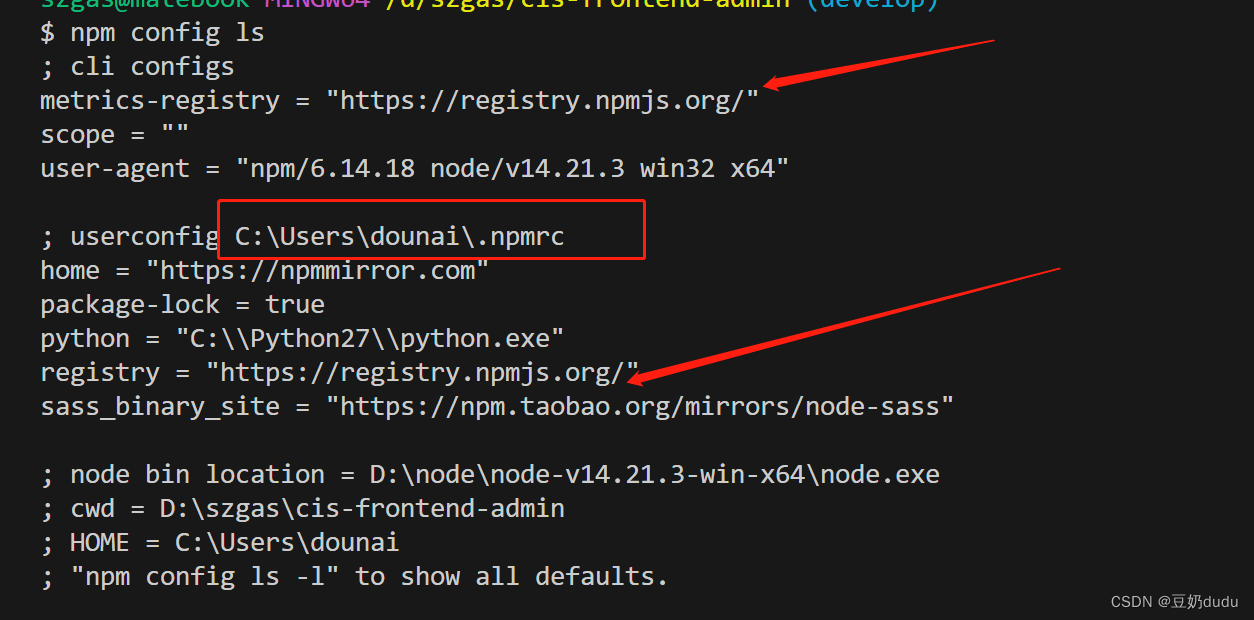
解决npm安装依赖失败,node和node-sass版本不匹配的问题
npm安装依赖报错: npm ERR! cb() never called! npm ERR! This is an error with npm itself. 一. 问题描述 用npm安装依赖报错: npm ERR! cb() never called! npm ERR! This is an error with npm itself. Please report this error at: npm ERR! …...
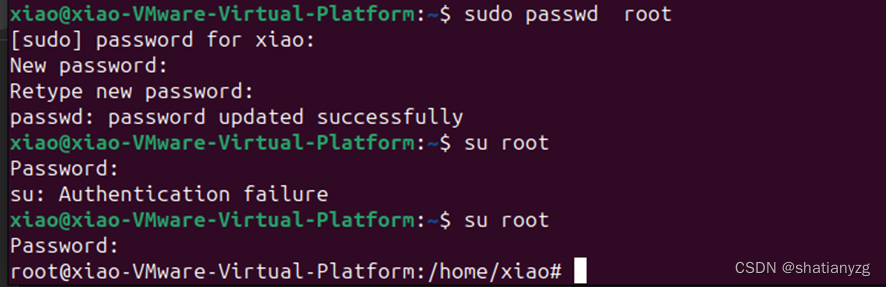
2023 网络建设与运维 X86架构计算机操作系统安装与管理题解
任务描述: 随着信息技术的快速发展,集团计划2023年把部分业务由原有的X86架构服务器上迁移到ARM架构服务器上,同时根据目前的部分业务需求进行了部分调整和优化。 一、X86架构计算机操作系统安装与管理 1.PC1系统为ubuntu-desktop-amd64系统(已安装,语言为英文),登录用户…...
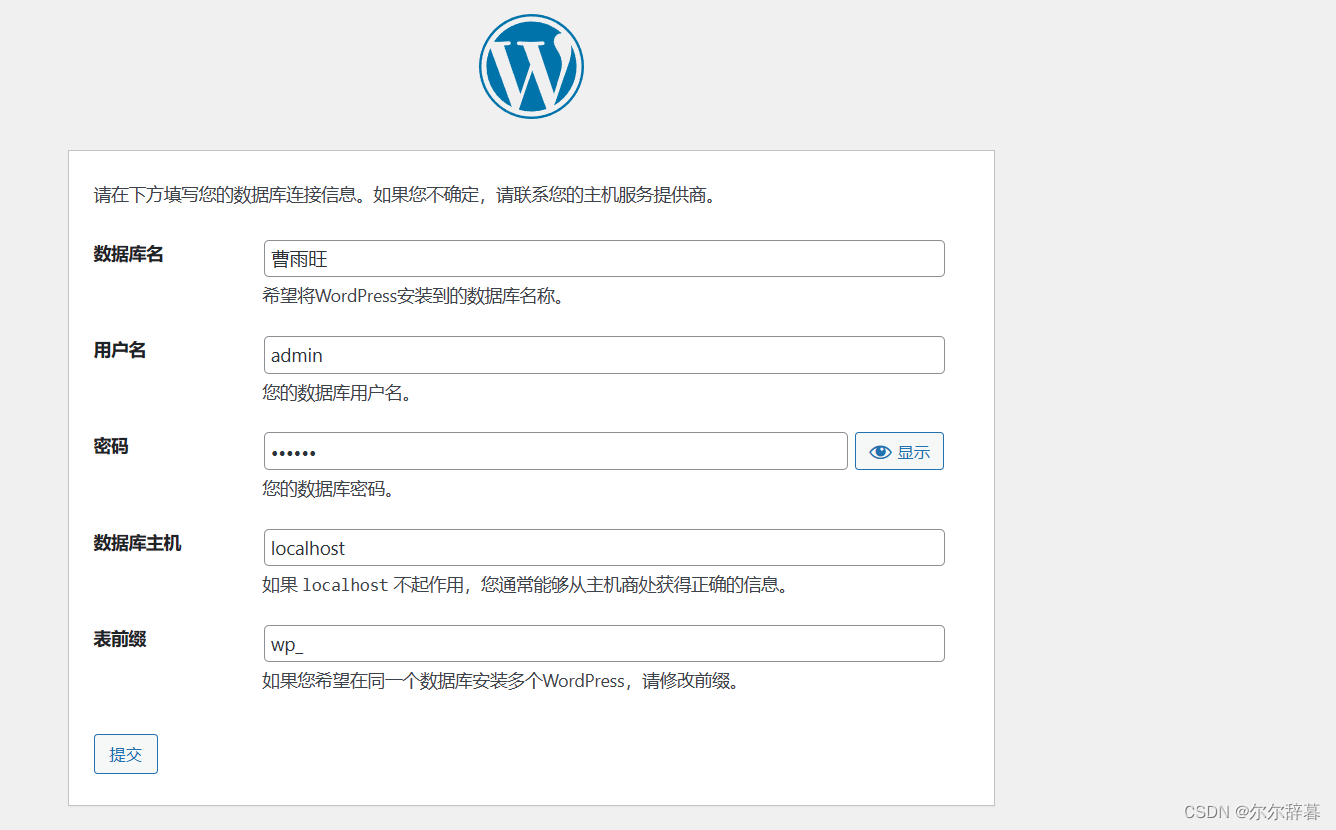
LAMP 架构及Discuz论坛与Wordpress博客搭建
目录 1 LAMP 配置与应用 1.1动态资源与语言 1.2 LAMP 架构的组成 1.2.1 主要功能 2 编译安装Apache http 服务 2.1 环境准备 2.1.1 关闭防火墙及selinux服务 2.1.2 安装依赖环境 2.2 安装软件包 2.2.1 解压软件包 2.2.2 移动apr包 apr-util包到安装目录中,并…...

考研C语言进阶题库——更新51-60题
目录 51.银行系中有很多恒星,H 君晚上无聊,便爬上房顶数星星,H 君将整个银河系看做一个平面,左上角为原点(坐标为(1, 1))。现在有 n 颗星星,他给每颗星星都标上坐标&…...

智能算法挑战赛决赛题目——初中组
题目 1. 判断是否存在重复的子序列 从 m 个字符中选取字符,生成 n 个符号的序列,使得其中没有 2 个相邻的子序列相同。如从 1,2,3,生成长度为 5 的序列,序列“12321”是合格的,而“12323”和“…...
一分钟学算法-递归-斐波那契数列递归解法及优化
一分钟学一个算法题目。 今天我们要学习的是用递归算法求解斐波那契数列。 首先我们要知道什么是斐波那契数列。 斐波那契数列,又称黄金分割数列,是一个经典的数学数列,其特点是第一项,第二项为1,后面每个数字都是前…...

选择Rust,并在Ubuntu上使用Rust
在过去的 8 年里,Rust 一直是开发人员最喜欢的语言,并且越来越被各种规模的软件公司采用。然而,它的许多高级规则和抽象创造了一个陡峭的初始学习曲线,这可能会给人留下 Rust 是少数人的保留的印象,但这与事实相去甚远…...

SVM详解
公式太多了,就用图片用笔记呈现,SVM虽然算法本质一目了然,但其中用到的数学推导还是挺多的,其中拉格朗日约束关于α>0这块证明我看了很长时间,到底是因为悟性不够。对偶问题也是,用了一个简单的例子才明…...
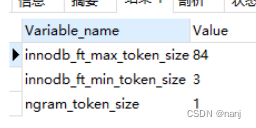
mysql全文检索使用
数据库数据量10万左右,使用like %test%要耗费30秒左右,放弃该办法 使用mysql的全文检索 第一步:建立索引 首先修改一下设置: my.ini中ngram_token_size 1 可以通过 show variables like %token%;来查看 接下来建立索引:alter table 表名 add f…...

opencv 进阶17-使用K最近邻和比率检验过滤匹配(图像匹配)
K最近邻(K-Nearest Neighbors,简称KNN)和比率检验(Ratio Test)是在计算机视觉中用于特征匹配的常见技术。它们通常与特征描述子(例如SIFT、SURF、ORB等)一起使用,以在图像中找到相似…...
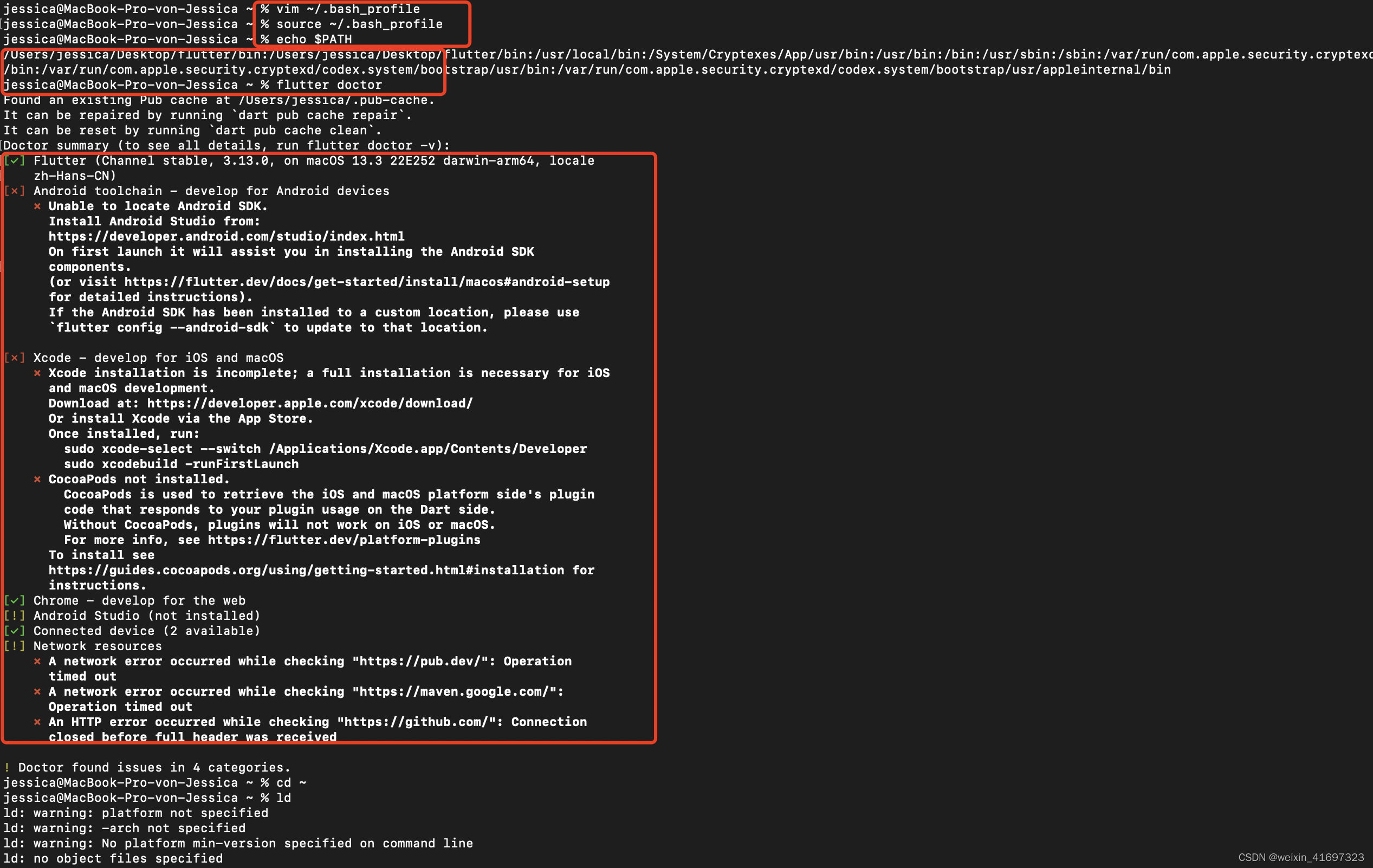
Mac Flutter web环境搭建
获取 Flutter SDK 下载以下安装包来获取最新的 stable Flutter SDK将文件解压到目标路径, 比如: cd ~/development $ unzip ~/Downloads/flutter_macos_3.13.0-stable.zip 配置 flutter 的 PATH 环境变量: export PATH"$PATH:pwd/flutter/bin" // 这个命…...
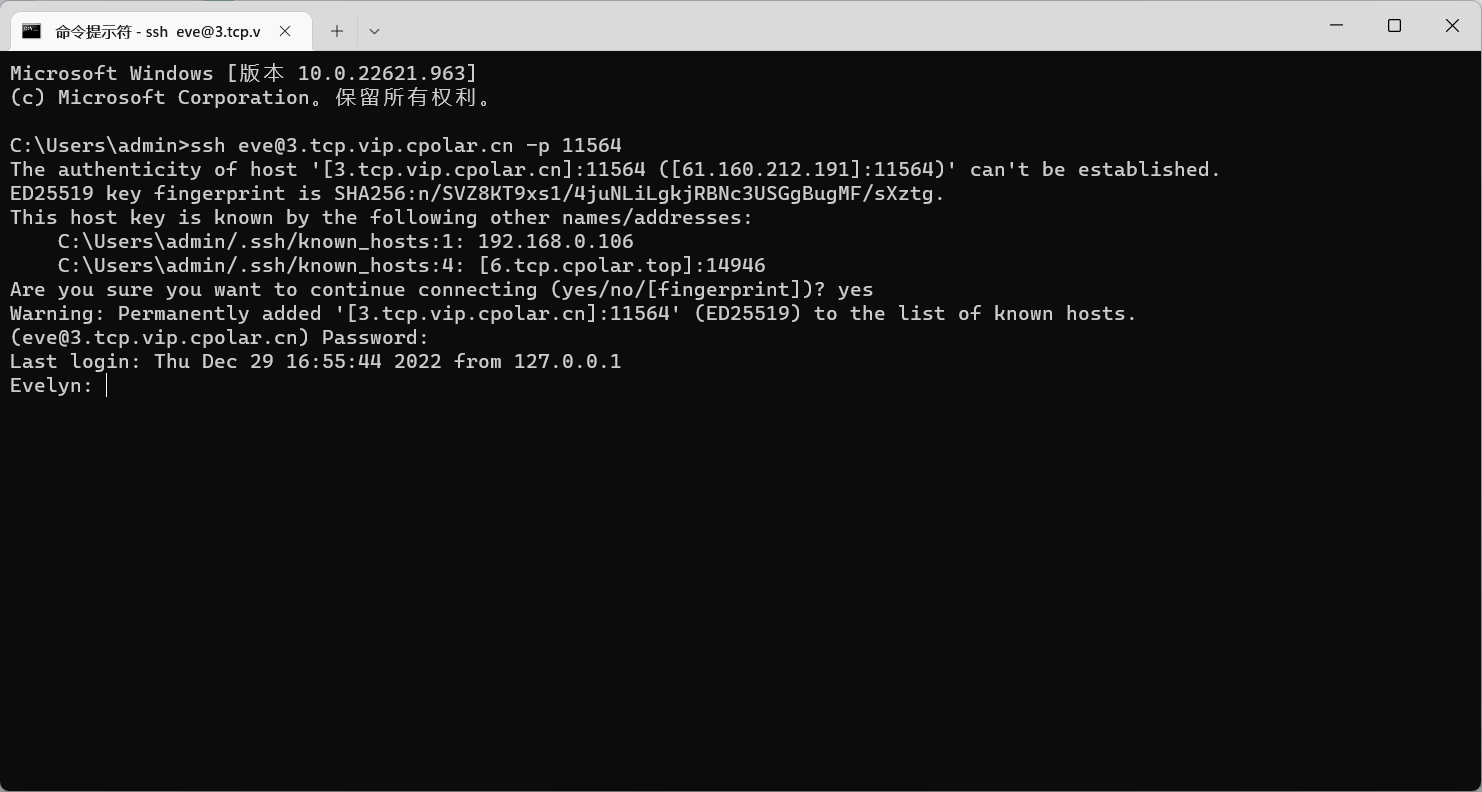
在外SSH远程连接macOS服务器
文章目录 前言1. macOS打开远程登录2. 局域网内测试ssh远程3. 公网ssh远程连接macOS3.1 macOS安装配置cpolar3.2 获取ssh隧道公网地址3.3 测试公网ssh远程连接macOS 4. 配置公网固定TCP地址4.1 保留一个固定TCP端口地址4.2 配置固定TCP端口地址 5. 使用固定TCP端口地址ssh远程 …...

从HEX到芯片:使用J-Flash实现高效固件烧录与生产级加密
1. 认识J-Flash:你的芯片烧录好帮手 第一次接触J-Flash时,我正为一个量产项目发愁——需要给500片GD32F103烧录固件。手动用IDE一个个烧?效率太低;找代工厂?成本太高。直到同事推荐了J-Flash,我才发现原来烧…...
终极配置指南:5步打造专业级网络视频传输系统)
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否曾为OBS Stud…...
)
大模型学习指南:小白也能轻松掌握AI,提升效率与收入(收藏版)
本文针对想学习大模型的普通用户,破除学习AI的常见误区,提供实用学习路径。文章强调从实际应用场景出发,而非深入技术原理,介绍了如何利用AI提升办公效率、进行内容创作、结合本职工作以及构建个人智能体助手。此外,文…...

被AI欺骗啦:一个有趣的三极直接耦合放大电路的调整
简 介: 本文探讨了一个三极直接耦合放大电路的设计问题。初始使用AI工具设计的电路参数看似可行,但仿真显示Q1晶体管处于异常工作状态(BC结正向偏置)。通过重新调整电阻参数,特别是将反馈电阻R8设为10MΩ后,…...

如何免费获取全球50+图书馆古籍资源:BookGet数字古籍下载完整指南
如何免费获取全球50图书馆古籍资源:BookGet数字古籍下载完整指南 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget 还在为寻找古籍文献而烦恼吗?想要从哈佛、国会图书馆等全球知名…...

Windows驱动存储深度管理:DriverStore Explorer专业指南
Windows驱动存储深度管理:DriverStore Explorer专业指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 在Windows系统维护的众多任务中,驱动程序管理往往是最容…...

Unlock Music:3种创新用法让你重新掌控被加密的音乐收藏
Unlock Music:3种创新用法让你重新掌控被加密的音乐收藏 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...

为什么92%的AI企业还没部署TEE for AI?,20年系统安全专家亲历的4类认知盲区与2026合规倒计时应对清单
更多请点击: https://intelliparadigm.com 第一章:AI原生可信执行环境:2026奇点智能技术大会TEE for AI 在2026奇点智能技术大会上,TEE for AI(AI-Native Trusted Execution Environment)正式成为下一代AI…...

PHP怎么处理Eloquent Attribute Harmonization属性协调_Laravel解决数据冲突【教程】
Eloquent 属性协调失败源于 $casts、访问器、序列化逻辑等机制作用域与执行顺序不一致;应优先用 $casts 处理类型转换,访问器仅用于动态计算,JSON 字段需显式标记 dirty 或拆分为关联模型。PHP 中 Eloquent 的 “Attribute Harmonization” 并…...

Shinkai Node:无代码AI智能体平台架构解析与实战部署
1. 项目概述:Shinkai Node,一个无需代码的AI智能体构建平台 最近在折腾AI智能体(AI Agent)的时候,发现了一个挺有意思的开源项目—— Shinkai Node 。它来自dcSpark团队,核心目标非常明确: …...