Vision Transformer(ViT) 2: 应用及代码讲解
文章目录
- 1. 代码讲解
- 1.1 PatchEmbed类
- 1)`__init__ `函数
- 2) forward 过程
- 1.2 Attention类
- 1)`__init__ `函数
- 2)forward 过程
- 1.3 MLP类
- 1)`__init__ `函数
- 2)forward函数
- 1.4 Block类
- 1)`__init__ `函数
- 2)forward函数
- 1.5 Vision Transformer类
- 1)`__init__ `函数
- 2)forward 函数
- 1.6 构建各种版本的VIT模型
- 2. 使用介绍
- 参考
Vision Transformer(ViT) 的理论部分,参考我之前写的博文: Vision Transformer(ViT) 1: 理论详解
1. 代码讲解

网络详细介绍,参见博客: Vision Transformer(ViT) 1: 理论详解
模型构建的对应的代码在vit_transformer.py中:
1.1 PatchEmbed类
PatchEmbed类对应网络结构中PathEmbeding部分,它的结构很简单,由一个卷积核为16x16,步距为16的卷积实现。实现的代码如下:
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size)patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1]self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
1)__init__ 函数
- 在初始化
__init__函数中,由于传入的是RGB3通道图片,因此in_c=3(in_channel);
针对VIT-B/16模型中embed_dim=768; 参数norm_layer默认为None. num_patches等于经16x16卷积后得到的featuremap进行展平: 14 x14。定义卷积层,kernel_size为16x16,stride为16,输入channel为in_c,输出channel为embed_dim为196, 针对VIT-L/16或其他的类型embed_dim值是有变化的。
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
norm_layer默认是为None的,如果有传入norm_layer就会初始化norm_layer。如果为None,self.norm则为nn.Identity()也就是不做任何操作
2) forward 过程
- 首先判断传入的图片尺寸是否等于预先设定的尺寸,如果不是则会报错。需要
注意的是:VIT模型不像传统的CNN模型是可以更改输入尺寸的。在我们VIT模型输入图片尺寸必须是固定的。 - 接下来将数据输入卷积层,得到shape为
[ B C H W]的tensor, 然后对宽和高进行展平处理得到shape为[ B C HW], 然后再用transpose交换维度1,2的顺序,最终得到shape为[B HW C]
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)
- 最后将结果通过LayerNorm进行输出。
1.2 Attention类
Attention类就是实现多头自注意力模块(multi head self attention),完整的代码如下:
class Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]B, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return x
1)__init__ 函数
- dim 参数代表的是
embed_dim,也就是输入token的dim;num_head指的是multi head self attention模块的head数目;qkv_bias指的是生成qkv的时候,是否去使用偏执bias,默认是为False,如果为True的话就会使用该偏执;qk_sclae是计算qk的缩放因子。 head_dim:针对每个head的dimension,就等于dim // num_head。self_scale: 如果有传入qk_scale的话:self_scale = qk_scale,如果没有传入就等于 1head_dim\frac{1}{\sqrt{head\_dim}}head_dim1,参考如下公式:

qkv在网络中是通过全连接进行计算得到的,值得注意的是有些源码是通过3个全连接层分别得到q,k,v,但我们这里使用一个节点数为3*dim的全连接层,一次性得到qkv,其实这两种方式都是可以的。
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
- 然后再定义一个
drop_out层 - 紧接着,再定义一个全连接层
nn.Linear。因为在multi head self attention的理论中,会将各个head的结果进行concat拼接,然后通过与WoW^oWo相乘进行映射,这里就可以利用全连接来实现。
self.proj = nn.Linear(dim, dim)
- 接下来,再定义一个
Drop out层。
2)forward 过程
- 正向传播的输入tensor
x的shape大小为[batch_size,num_patches+1,total_embed_dim],这里的num_patches等于196,这里+1是因为加上了一个class_token - 然后利用
全连接,计算qkv的值
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
- 然后将
q,k矩阵相乘,并乘以scale,再经过softmax计算,就计算得到针对每个v的权重,最后将结果与V矩阵相乘:整个过程就是实现如下公式的计算。

attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
需要将每个head的结果进行concat拼接,这里通过reshape(B,N,C)实现,将shape由[batch_size, num_patches + 1, num_heads, embed_dim_per_head]转为[batch_size, num_patches + 1, total_embed_dim], 其中total_embed_dim = num_heads,*embed_dim_per_head
- 然后将结果通过WoW^oWo进行映射,通过这里的全连接实现。
x = self.proj(x)
- 最后通过drop_out层,得到multi head self atention的输出。
以上就是Attention类的实现过程。
1.3 MLP类
MLP 指的是Encoder Block中的MLP Block,结构比较简单。首先是一个全连接层,然后加上GELU激活函数,然后Droupout, 然后再全连接层,最后通过一个Dropout进行全连接层输出。

完整的实现代码如下:
class Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
在:Vision Transformer(ViT) 1: 理论详解中有讲到过,第一个全连接层Linear的节点个数是输入节点个数的4倍,第二个全连接层会将节点个数还原回我们输入的节点个数。
1)__init__ 函数
- 在初始化函数中,会传入
in_features(输入节点个数);hidden_features(第一个全连接层的节点个数),一般是in_features的4倍;out_features其实和in_features是一样的。这里还有个激活函数,默认是nn.GELU激活函数。 - 如果有传入
out_features,则out_features为传入的out_features,如果没有传入则等于in_features; 同样,hidden_features如果传入hidden_features,则等于hidden_features,如果没有传入则等于in_features。 - 接下来定义全连接层1,激活函数,全连接层2,以及最后的
Dropout
2)forward函数
将输入一次传给全连接层1,激活函数,dropout,全连接层2,dropout层
1.4 Block类
这里定义的Block就是结构中的Encoder Block; 在Transforer Encoder层,就是将Encoder Block重复堆叠L次。Block类实现的Encoder Block网络结构如下:

Encoder Block 首先会通过Layer Norm,然后Multi-Head Attention,再接上Drouput层,然后再通过捷径分支进行相加,然后再通过Layer Norm和MLP Block以及Droupout层, 然后再通过一个捷径分支相加,得到Encoder Block的最终输出。 完整的实现代码如下:
class Block(nn.Module):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):super(Block, self).__init__()self.norm1 = norm_layer(dim)self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x
1)__init__ 函数
dim对应每个token的dimension;num_heads就是multi head attention中使用的head个数;mlp_ratio默认为4,定义了第一个全连接层的节点数是输入节点个数的4倍。qkv_bias默认为False,不使用bias。- 定义了
norm1层以及multi head attention结构,通过调用Attention类实现。 - 如果传入的
drop_path_ratio大于0,就会实例化一个DropPath方法。如果条件不满足就会使用nn.Identity也就是不进行任何操作 - 接下来定义
norm2,然后计算mlp_hidden_dim也就是第一个全连接层节点数:mlp_hidden_dim = int(dim * mlp_ratio) - 然后再初始化
MLP Block参数,通过调用Block类来实例化
2)forward函数
正向传播过程
- 输入x首先通过norm1,
multi head self attention以及drop_path,然后再加上我们的输入x进行shortcut相加,得到第一个捷径分支的输出x - 接下来,再将我们的结果依次通过
norm2,mlp和drop_path,然后和上面得到的x进行Add相加,得到最终的输出。
1.5 Vision Transformer类
Vision Transformer类,利用之前定义好的各个模块,实现完整的Vison Transformer结构

ViT-B/16的完整代码实现,如下:
class VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):super(VisionTransformer, self).__init__()self.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsself.num_tokens = 2 if distilled else 1norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)act_layer = act_layer or nn.GELUself.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else Noneself.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))self.pos_drop = nn.Dropout(p=drop_ratio)dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay ruleself.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim)# Representation layerif representation_size and not distilled:self.has_logits = Trueself.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:self.has_logits = Falseself.pre_logits = nn.Identity()# Classifier head(s)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight initnn.init.trunc_normal_(self.pos_embed, std=0.02)if self.dist_token is not None:nn.init.trunc_normal_(self.dist_token, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)self.apply(_init_vit_weights)def forward_features(self, x):# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_drop(x + self.pos_embed)x = self.blocks(x)x = self.norm(x)if self.dist_token is None:return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]def forward(self, x):x = self.forward_features(x)if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return x
1)__init__ 函数
- 可以看到在
__init__初始化函数中传入了很多参数。 - 首先是
img_size,默认是224x224;patch_size默认为16,in_c(in_channel)默认为3;num_classes默认为1000;embed_dim默认为768;depth默认为12,depth指的是在Transformer Encoder中重复堆叠Encoder Block的次数。representation_size对应的分类预测层MLP head中的Pre_Logits中全连接层的节点个数,representation_size默认为None,如果为None的话就不会构建MLP Head当中的Pre_Logits,此时在MLP Head中只有一个全连接层;distilled参数可以不用管,因为作者是为了搭建DeiT模型使用的。embed_layer对应embeding层,默认使用PatchEmbed层结构。 - 由于
distilled在`VIT模型中是用不到的,所以我们的num_token为1 (class_token) - 通过
PatchEmbed实例化构建patch_embed,传入img_size,patch_size以及in_c和embed_dim参数,就构建好了PatchEmbed层。 - 接下来,需要加上一个
class token它的shape为(1,768);class_token会和Patch Embeding的输出进行Concat相加。这里初始化了一个shape为(1,1,768)零矩阵,来定义cls_token,其中shape的第一个维度1,对应的是batch维度。
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
dist_token在VIT模型是使用不到的,distilled为False,对应dist_token为None- 接下来定义位置编码
pos_embed, 其中pos_embed是和concat拼接后的shape是一样的,对应VIT-B/16模型,它的shape就是(197,768)。 这里通过nn.Parameter创建一个可训练的参数,使用零矩阵进行初始化,shape大小为(1,num_patches+self.num_tokens,embed_dim),其中第一个维度1为batch维,可以不用管。 - 接下来,根据传入的
drop_path_ratio, 构造一个长度depth,从0到drop_path_ratio范围等差变化。也就是说在Transformer Encoder中每一个Encoder Block它们所采用的drop_path方法,使用的drop_path_ratio是递增的。 - 然后构建
Transormer Encoder模块,重复堆叠Encoder BlockL次。通过nn.Sequential方法将循环创建depth次的Block(Encoder Block)打包为一个整体。这样就创建好了Transormer Encoder模块,变量名为blocks。
self.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])
- 接下来,再构建一个
norm_layer, 作用于Transormer Encoder模块后。 - 构建pre_logits层:如果
representation_size有值的话,就将has_logits参数设置为True,并将representation_size赋值给num_features。然后利用nn.Sequential构建pre_logits层,它就是一个全连接层fc+ nn.Tanh()激活函数;如果representation_size为None的话,has_logits参数就为False。pre_logits就等于nn.Identity()也就是不做任何处理,相当于没有pre_logits层。 - 接下来,构建
Classifier Head,通过一个全连接层实现,输入的节点为num_features,输出为分类个数num_classes。
2)forward 函数
forward函数的代码实现如下:
def forward(self, x):x = self.forward_features(x)if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return x
正向传播过程
- 首先会将x传入给forward_feature,对应的forwar_feature实现如下:
def forward_features(self, x):# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_drop(x + self.pos_embed)x = self.blocks(x)x = self.norm(x)if self.dist_token is None:return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]
- 首先将输入传入给
patch_embed, - 然后将
cls_token通过expand方法由shape为[1,1,768], expand到(batch_size,196,768), 再将cls_token与patch_embed的输出进行concat拼接。 - 然后将
concat之后的x加上pos_embed(位置编码),shape变为(batch_size,197,768) - 紧接着再通过一个
dropout层 - 然后再将数据传给blocks,也就是我们定义好的
Transformer Encoder层 - 然后再通过
Layer_Norm层 - 然后提取class_token输出,通过x[:,0]取197中的第一个token, 然后将取出来的数据传入给
pre_logits,之前我们说到过如果representation_size为None的话,就是一个Identity层,它会直接返回cls_token作为输出。
再回到forward函数中,由于head_dist参数为None, 因此会执行到x = self.head(x)中。head对应的就是Classifier Head,用于最后分类的全连接层。以上就是整个VIT模型的搭建过程。
1.6 构建各种版本的VIT模型
根据不同的VIT配合,搭建对应的VIT模型。
在论文的Table1中有给出三个模型(Base/ Large/ Huge)的参数,在源码中除了有Patch Size为16x16的外还有32x32的。其中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的4倍),Heads代表Transformer中Multi-Head Attention的heads数。

(2) 构建ViT-B/16模型
def vit_base_patch32_224(num_classes: int = 1000):"""ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=768,depth=12,num_heads=12,representation_size=None,num_classes=num_classes)return model
(2) 构建ViT-B/16 在imagenet21k上预训练的模型
def vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=768,depth=12,num_heads=12,representation_size=768 if has_logits else None,num_classes=num_classes)return model
num_classes:21843,代表imagenet21k的分类个数has_logits为True,表示使用了pred_logits层
(3) 构建ViT-B/32 在imagenet21k上预训练的模型
def vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=768,depth=12,num_heads=12,representation_size=768 if has_logits else None,num_classes=num_classes)return model
(3) 构建ViT-L/16模型
ef vit_large_patch16_224(num_classes: int = 1000):"""ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=1024,depth=24,num_heads=16,representation_size=None,num_classes=num_classes)return model
embed_dim:相对于VIT-B的768,增大到1024depth: 相对于VIT-B的12,增大到24num_heads: 相对于VIT-B的12,增大到16
(4) 构建ViT-L/16 在imagenet21k上预训练的模型
def vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=1024,depth=24,num_heads=16,representation_size=1024 if has_logits else None,num_classes=num_classes)return model
(5) 构建ViT-L/32 在imagenet21k上预训练的模型
def vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=1024,depth=24,num_heads=16,representation_size=1024 if has_logits else None,num_classes=num_classes)return model
(6) 构建ViT-H/14 在imagenet21k上预训练的模型
def vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.NOTE: converted weights not currently available, too large for github release hosting."""model = VisionTransformer(img_size=224,patch_size=14,embed_dim=1280,depth=32,num_heads=16,representation_size=1280 if has_logits else None,num_classes=num_classes)return model
patch_size:为14x14,不是原来的16x16embed_dim:是1280depth: 为32
不建议使用VIT-H/14,因为模型太大了,下载预训练权重就有将近1个G, 这里不同模型都给出了预训练权重的下载链接 .
建议大家在训练的时候,使用预训练权重,对于VIT模型如果不使用预训练权重,它的效果示很差的。原论文指出,VIT模型直接在imagenet上预训练,其他它的效果其实并不好,它只有在非常大的数据集训练之后,才会有比较好的效果。所以建议使用预训练权重,进行迁移学习训练。
2. 使用介绍
- (1)下载好数据集,代码中默认使用的是花分类数据集,下载地址: https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz, 如果下载不了的话可以通过百度云链接下载: https://pan.baidu.com/s/1QLCTA4sXnQAw_yvxPj9szg 提取码:58p0
- (2)在
train.py脚本中将--data-path设置成解压后的flower_photos文件夹绝对路径 - (3)下载预训练权重,在
vit_model.py文件中每个模型都有提供预训练权重的下载地址,根据自己使用的模型下载对应预训练权重 - (4)在
train.py脚本中将--weights参数设成下载好的预训练权重路径 - (5)设置好数据集的路径
--data-path以及预训练权重的路径--weights就能使用train.py脚本开始训练了(训练过程中会自动生成class_indices.json文件) - (6)在
predict.py脚本中导入和训练脚本中同样的模型,并将model_weight_path设置成训练好的模型权重路径(默认保存在weights文件夹下) - (7)在
predict.py脚本中将img_path设置成你自己需要预测的图片绝对路径 - (8)设置好权重路径
model_weight_path和预测的图片路径img_path就能使用predict.py脚本进行预测了 - (9)如果要使用自己的数据集,请按照花分类数据集的文件结构进行摆放(即一个类别对应一个文件夹),并且将训练以及预测脚本中的num_classes设置成你自己数据的类别数
完整代码:
参考
1. Vision Transformer详解
2.Group Normalization详解
3. Layer Normalization解析
相关文章:
Vision Transformer(ViT) 2: 应用及代码讲解
文章目录1. 代码讲解1.1 PatchEmbed类1)__init__ 函数2) forward 过程1.2 Attention类1)__init__ 函数2)forward 过程1.3 MLP类1)__init__ 函数2)forward函数1.4 Block类1)__init__ 函数2)forwa…...
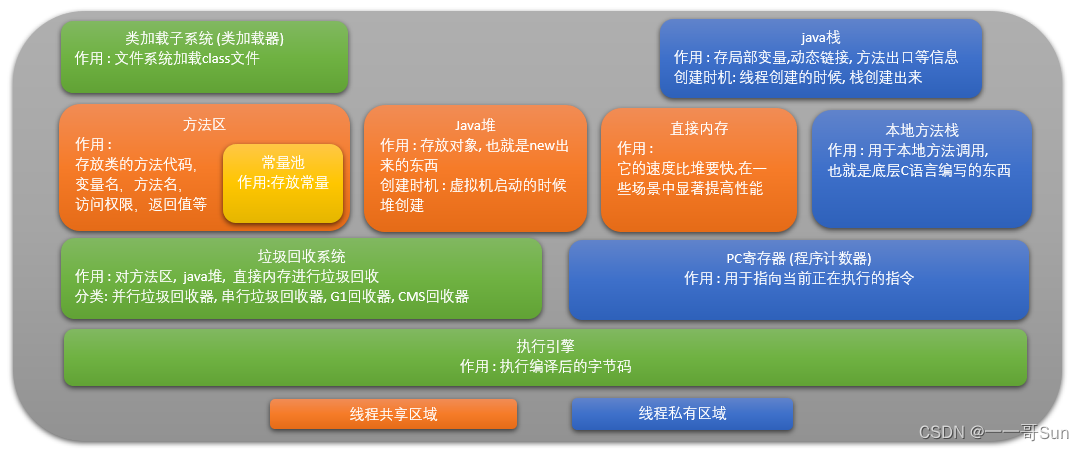
高频面试题|JVM虚拟机的体系结构是什么样的?
一. 前言最近有很多小伙伴都在找工作,他们在面试时经常被面试官问到一个问题:请说说JVM虚拟机的体系结构是什么样的?很多小伙伴都能说出堆、栈等相关内容,但面试官紧接着又问,你还知道其他内容吗?这时不少小伙伴就语塞…...
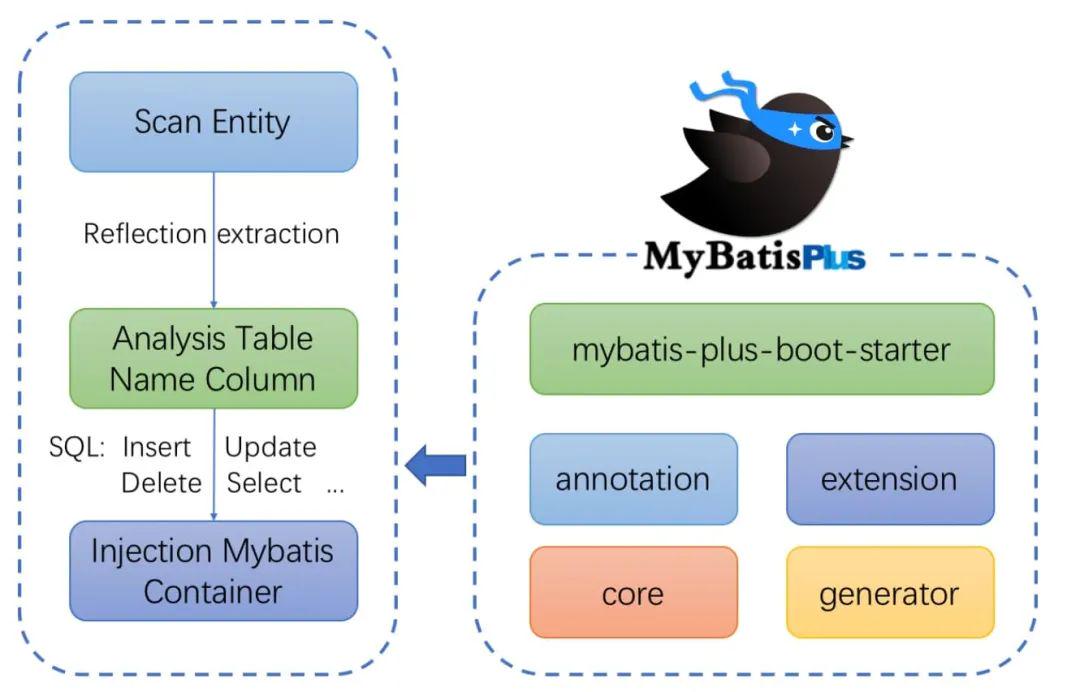
MyBatis-Plus详细讲解(整合spring Boot)
哈喽,大家好,今天带大家了解的是MyBatis-Plus(简称 MP),是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。首先说一下MyBatis-Plus的愿景是什么&…...

骨传导耳机是不是智商税?骨传导耳机真的不伤耳吗?
很多人对骨传导耳机是具有一定的了解,但是对骨传导耳机还是有一定的刻板印象,那么骨传导耳机到底是不是智商税呢?主要还是要从骨传导耳机传声原理上讨论。 骨传导耳机是属于固体传声的一种方式,通过骨骼传递声音,在使用…...
模拟实现string
目录 1、基本成员变量 2、默认成员函数 构造函数 析构函数 拷贝构造函数(深拷贝) 赋值运算符重载 3、容量与大小相关的函数 size capacity 4、字符串访问相关函数 operator [ ]重载 迭代器 5、增加的相关函数 reserve扩容 resize push_back追加字符 appe…...
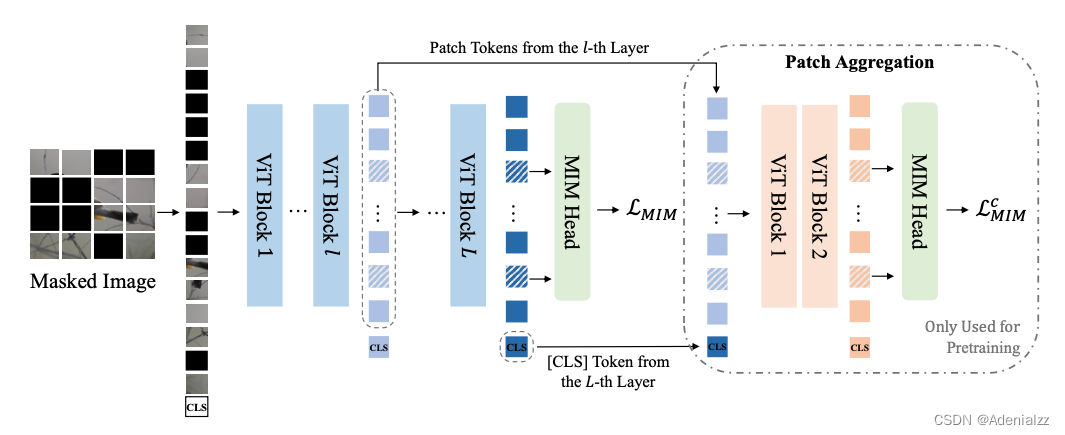
自监督表征预训练之掩码图像建模
自监督表征预训练之掩码图像建模 前言 目前,在计算机视觉领域,自监督表征预训练有两个主流方向,分别是对比学习(contrastive learning)和掩码图像建模(masked image modeling)。两个方向在近几…...
| 代码+思路+重要知识点)
华为OD机试题 - 磁盘容量(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

ChatGPT:“抢走你工作的不会是 AI ,而是先掌握 AI 能力的人”
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! ChatGPT:“抢走你工作的不会是 AI ,而是先掌握 AI 能力的人” ChatGPT:美国OpenAI 研发的聊天机器人程序,人工智能技术…...

数据结构与算法(Java版) | 线性结构和非线性结构
之前,我们说过,数据结构是算法的基础,因此接下来在这一讲我就要来给大家重点介绍一下数据结构了。 首先,大家需要知道的是,数据结构包括两部分,即线性结构和非线性结构。知道这点之后,接下来我…...
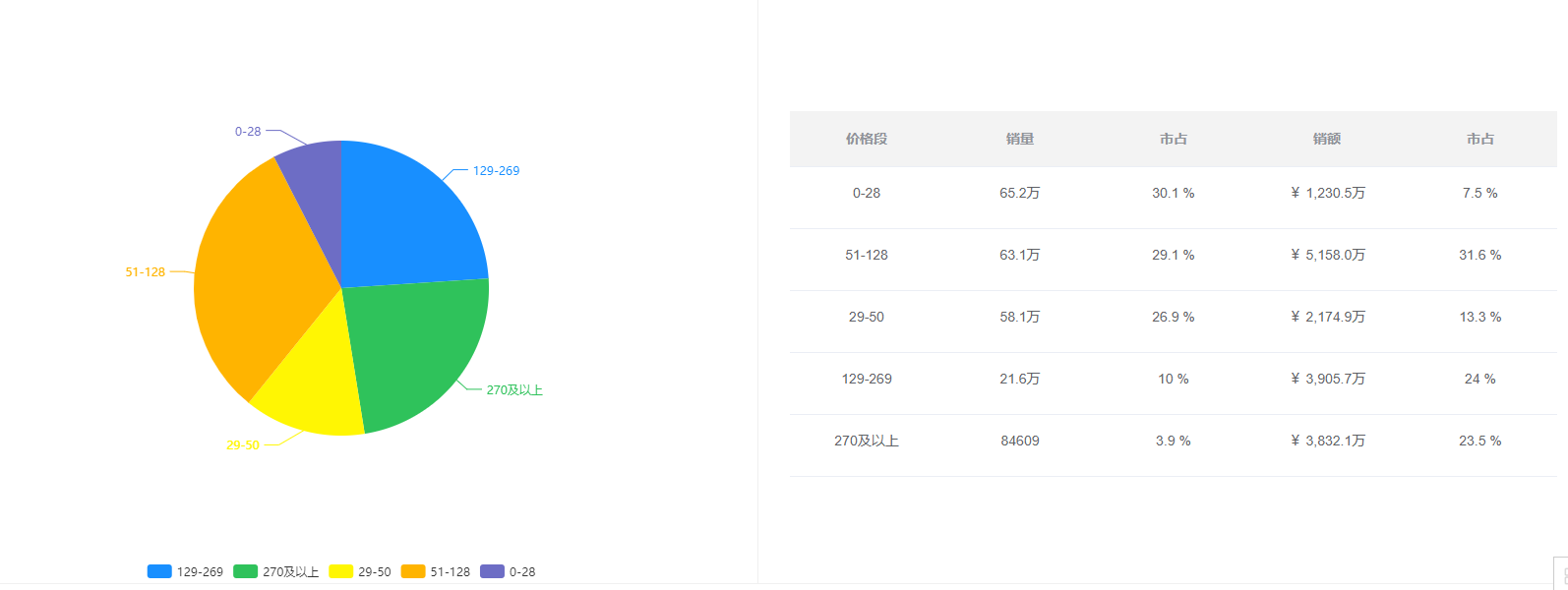
电商数据查询平台:母婴行业妈妈用品全网热销,头部品牌格局初现
以往,奶粉、纸尿裤这类产品基本就代表了整体母婴市场中的消费品。而如今,随着母婴行业的高速发展和消费升级,母婴商品的种类日益丰富,需求也不断深入。 在京东平台,母婴大品类中除了包含婴童相关的食品(奶粉…...
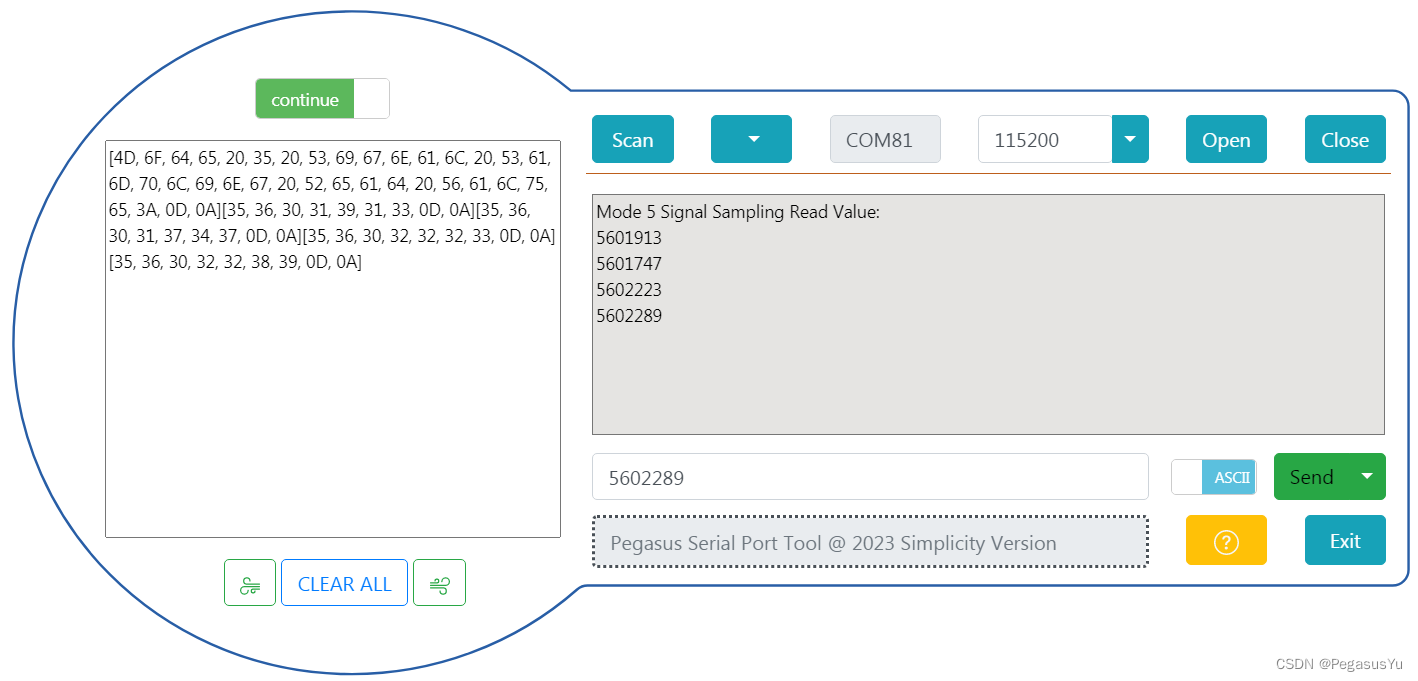
STM32模拟SPI协议获取24位模数转换(24bit ADC)芯片AD7791电压采样数据
STM32模拟SPI协议获取24位模数转换(24bit ADC)芯片AD7791电压采样数据 STM32大部分芯片只有12位的ADC采样性能,如果要实现更高精度的模数转换如24位ADC采样,则需要连接外部ADC实现。AD7791是亚德诺(ADI)半导体一款用于低功耗、24…...
| 代码+思路+重要知识点)
华为OD机试题 - 交换字符(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

最好的工程师像投资者一样思考,而不是建设者
我在大学期间住在图书馆。“我学习的教科书理论越多,我就会成为一名更好的工程师,”我想。然而,当我开始工作时,我注意到业内最优秀的工程师并不一定比应届毕业生了解更多的理论。他们只是带来了不同的心态,即投资者的…...
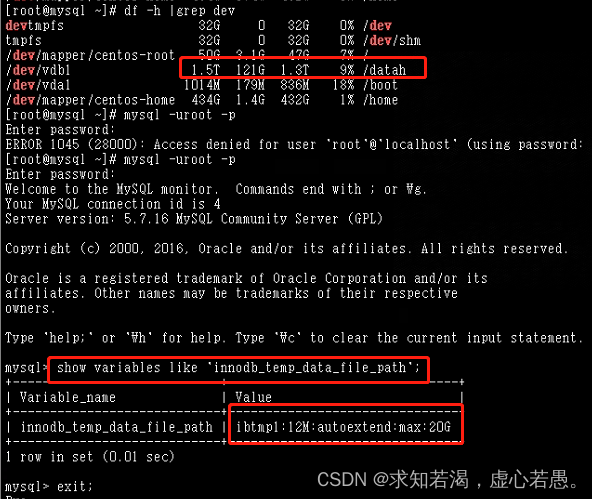
Mysql里的ibtmp1文件太大,导致磁盘空间被占满
目录 一、查看磁盘的时候发现磁盘空间100% 二、 排查的时候:查看是什么文件占用的时候,发现是数据库临时表空间增长的 三、为了避免以后再次出现ibtmp1文件暴涨,限制其大小,需在配置文件加入 四、重启Mysql实例(重启后…...
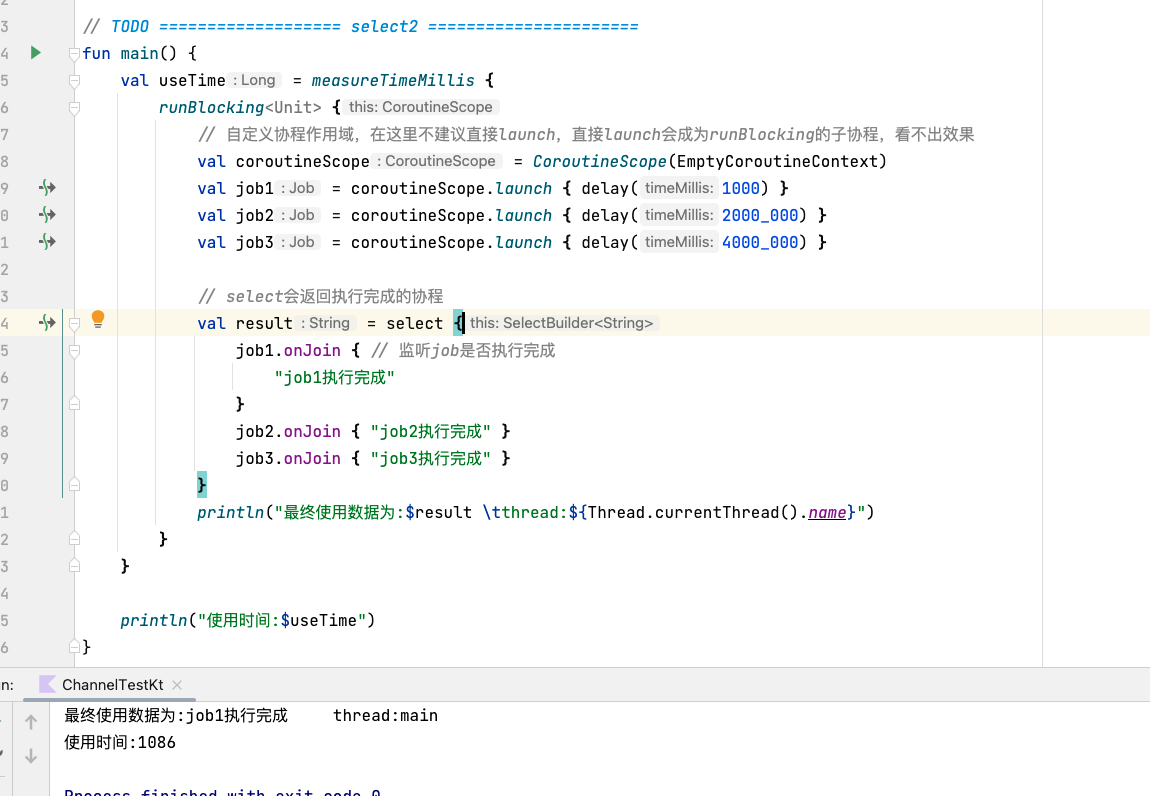
android kotlin 协程(四) 协程间的通信
android kotlin 协程(四) 协程间的通信 学完本篇你将会了解到: channelproduceactorselect 先来通过上一篇的简单案例回顾一下挂起于恢复: fun main() {val waitTime measureTimeMillis {runBlocking<Unit> {println("main start") // 1 // …...

苹果手机通讯录突然没了怎么恢复?
手机成为生活中的必需品,都会存储着各种数据文件,比如我们使用过的APP、音乐、照片、通讯录等通常都是存在这里面的。但我们的操作难免会有意外,有的是手动不小心删的,有的是误删的,有的是自己孩子删的等,却…...

BI知识全解,值得收藏
2021年度,中国商业软件市场的增长趋势是快速增长的,达到7.8亿美元,同比增长34.9%。商业智能BI在企业应用中具有巨大的价值,并逐渐成为现代企业信息化和数字化转型的基础。所以,全面了解BI,对于企业管理是非…...

【机器学习】GBDT
1.什么是GBDT GBDT(Gradient Boosting Decision Tree),梯度提升树。它是一种基于决策树的集成算法。其中Gradient Boosting 是集成方法boosting中的一种算法,通过梯度下降来对新的学习器进行迭代。它是利用损失函数的负梯度方向在当前模型的值作为残差的…...

C#开发的OpenRA游戏高性能内存访问的方法
C#开发的OpenRA游戏高性能内存访问的方法 一个游戏性能往往是比较关键的, 因为游戏很多时候是比拼的是人的速度和技巧。 比如王者荣耀里,一个大招是否及时地放得出来,就会影响到一场比赛的关键。 而这个大招的释放,又取决于游戏运行在手机上的性能。 如果游戏太耗性能,导致…...
【elasticsearch】elasticsearch es读写原理
一、前言: 今天来学习下 es 的写入原理。 Elasticsearch底层使用Lucene来实现doc的读写操作: Luence 存在的问题: 没有并发设计 lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量…...

新手入门指南:在快马平台上用openclaw重启版本实现首个爬虫项目
最近在学习网络爬虫,发现openclaw重启版本对新手特别友好,于是尝试在InsCode(快马)平台上做了一个简单的新闻头条抓取项目。整个过程比想象中顺利,分享下我的学习路径和踩坑经验。 环境准备与库安装 传统爬虫项目最头疼的就是环境配置&#x…...

5分钟上手BilibiliDown:Windows/Mac/Linux三平台通用的B站视频下载神器
5分钟上手BilibiliDown:Windows/Mac/Linux三平台通用的B站视频下载神器 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.…...
)
GIL移除倒计时?Python 3.13+无锁生态成本迁移路线图(含遗留系统改造代价评估矩阵)
第一章:GIL移除的技术本质与无锁Python并发范式跃迁 Python长期以来受全局解释器锁(GIL)制约,其核心矛盾并非线程安全本身,而是CPython运行时对内存管理器(如引用计数)、字节码调度器及对象分配…...

夜神模拟器抓包微信小程序实战指南
1. 环境准备与基础配置 想要抓取微信小程序的数据包,首先得搭建好工作环境。我推荐使用夜神模拟器的安卓7版本,这个版本稳定性好,兼容性强,而且自带root权限,省去了很多麻烦。安装完模拟器后,你会发现系统已…...

告别重复造轮子:用快马一键生成可扩展的高效ibbot开发框架
最近在开发一个智能对话机器人(ibbot)时,发现每次从零开始搭建框架都要重复处理很多基础工作。经过一番探索,我发现用InsCode(快马)平台可以快速生成可扩展的项目框架,效率提升非常明显。下面分享下我的实践心得&#…...
)
GPCC数据不止看趋势:手把手教你用MATLAB做降水信号的谐波分析(附周年振幅相位代码)
GPCC数据不止看趋势:手把手教你用MATLAB做降水信号的谐波分析(附周年振幅相位代码) 长江流域的降水变化对农业生产、水资源管理和生态保护都具有重要意义。当我们拿到GPCC的月尺度降水数据时,除了绘制时间序列图观察趋势外&#x…...

基于 LangChain 1.0 的 LangGraph 高级应用
基于 LangChain 1.0 的 LangGraph 高级应用 文章目录基于 LangChain 1.0 的 LangGraph 高级应用1. 深度对比:Workflow vs Agent1.1 Workflow 实现示例(内容审核)1.2 Agent 实现示例(内容审核)2. 高级状态管理ÿ…...

G-Helper终极指南:5分钟掌握华硕笔记本性能控制
G-Helper终极指南:5分钟掌握华硕笔记本性能控制 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, an…...

猫抓浏览器扩展:网页资源嗅探的终极解决方案与完整实施指南
猫抓浏览器扩展:网页资源嗅探的终极解决方案与完整实施指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容爆炸的时代&…...
)
保姆级教程:手把手教你用欧空局新版哥白尼系统下载Sentinel-2影像(含波段预览与无云影像合成)
零基础实战指南:新版哥白尼系统Sentinel-2影像全流程获取与处理 第一次接触欧空局的哥白尼数据下载系统时,面对琳琅满目的功能和专业术语,难免会感到无从下手。本文将带你一步步完成从注册到下载再到基础处理的全过程,特别针对Se…...