深度学习神经网络基础知识(一) 模型选择、欠拟合和过拟合
专栏:神经网络复现目录
深度学习神经网络基础知识(一)
本文讲述神经网络基础知识,具体细节讲述前向传播,反向传播和计算图,同时讲解神经网络优化方法:权重衰减,Dropout等方法,最后进行Kaggle实战,具体用一个预测房价的例子使用上述方法。
文章部分文字和代码来自《动手学深度学习》
文章目录
- 深度学习神经网络基础知识(一)
- 模型选择、欠拟合和过拟合
- 1. 训练误差和泛化误差
- 2. 模型选择
- 2.1 验证集
- 2.2 K折交叉验证
- 3. 过拟合和欠拟合
- 3.1 定义
- 3.2 模型复杂度对拟合情况的影响
- 3.3 解决方法
- 指路第二节
模型选择、欠拟合和过拟合
1. 训练误差和泛化误差
训练误差(training error)指的是模型在训练数据集上表现出的误差。训练误差通常会随着训练次数的增加而逐渐降低,直到收敛到一个稳定的状态。
泛化误差(generalization error)指的是模型在测试数据集或真实环境中表现出的误差,也就是说,它是指模型对新数据的预测能力。泛化误差的大小取决于许多因素,包括模型的复杂度、训练数据集的大小和质量、模型选择和超参数调整等。泛化误差越小,说明模型的泛化能力越好,即对新数据的预测能力越强。
举个例子说明:
假设我们有一个分类问题,要用一个神经网络将一张图片分为猫和狗两类。我们有一组带标签的训练集来训练这个网络,训练集中有很多猫和狗的图片。
训练误差:在训练过程中,我们用训练集的一部分数据来训练网络,每一迭代会计算损失函数,并且通过反向传播算法更新网络参数,使得模型对训练集的数据拟合得更好。训练误差就是这个模型在训练集上的误差,即模型对训练集的数据拟合程度。
例如,如果我们训练模型100个epoch(迭代次数),每个epoch用训练集中的所有数据训练一遍,并在每个epoch的结束时计算模型在训练集上的准确率。如果训练集中有1000张猫和1000张狗的图片,那么训练误差就是模型在这2000张图片上的分类准确率。
泛化误差:在训练过程中,我们通过训练集来更新模型的参数,让模型在训练集上的表现不断提升。然而,我们真正关心的是模型对于新数据的泛化能力,即模型对于不在训练集中的数据的分类能力。泛化误差就是模型在新数据上的误差,它是我们关心的主要指标。
例如,我们在训练集上训练了一个分类器,准确率达到了90%。但是当我们将它应用到新的数据集时,发现它的准确率只有70%。这意味着模型出现了过拟合,它在训练集上表现很好,但在新数据上表现不佳。在这种情况下,我们需要采取一些措施来降低泛化误差,例如增加数据集的大小,加入正则化项等。
当我们有简单的模型和大量的数据时,我们期望泛化误差与训练误差相近。 当我们有更复杂的模型和更少的样本时,我们预计训练误差会下降,但泛化误差会增大。 模型复杂性由什么构成是一个复杂的问题。 一个模型是否能很好地泛化取决于很多因素。 例如,具有更多参数的模型可能被认为更复杂, 参数有更大取值范围的模型可能更为复杂。 通常对于神经网络,我们认为需要更多训练迭代的模型比较复杂, 而需要早停(early stopping)的模型(即较少训练迭代周期)就不那么复杂。
我们很难比较本质上不同大类的模型之间(例如,决策树与神经网络)的复杂性。 就目前而言,一条简单的经验法则相当有用: 统计学家认为,能够轻松解释任意事实的模型是复杂的, 而表达能力有限但仍能很好地解释数据的模型可能更有现实用途。 在哲学上,这与波普尔的科学理论的可证伪性标准密切相关: 如果一个理论能拟合数据,且有具体的测试可以用来证明它是错误的,那么它就是好的。 这一点很重要,因为所有的统计估计都是事后归纳。 也就是说,我们在观察事实之后进行估计,因此容易受到相关谬误的影响。 目前,我们将把哲学放在一边,坚持更切实的问题。
本节为了给出一些直观的印象,我们将重点介绍几个倾向于影响模型泛化的因素。
-
可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
-
参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
-
训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
2. 模型选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型。 这个过程叫做模型选择。 有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)。 又有时,我们需要比较不同的超参数设置下的同一类模型。
例如,训练多层感知机模型时,我们可能希望比较具有不同数量的隐藏层、不同数量的隐藏单元以及不同的激活函数组合的模型。 为了确定候选模型中的最佳模型,我们通常会使用验证集。
2.1 验证集
验证集通常用于在训练过程中评估模型的性能,以帮助选择最佳的超参数(如学习率、正则化系数等)。在训练过程中,我们使用训练集训练模型,并使用验证集评估模型的性能,以便及时调整超参数和防止过拟合。
具体来说,我们将训练数据集分成两部分:训练集和验证集。训练集用于模型的训练,而验证集用于模型的评估。训练集和验证集应该是互不重叠的,即同一个样本不会同时出现在训练集和验证集中。
在训练过程中,我们使用训练集训练模型,并使用验证集评估模型的性能。通过比较训练误差和验证误差,我们可以判断模型是否过拟合。如果训练误差很小,但验证误差很大,那么说明模型过拟合了;反之,如果训练误差和验证误差都很小,那么说明模型的泛化能力很好。我们可以根据验证误差来选择最佳的超参数,以提高模型的性能。
2.2 K折交叉验证
K折交叉验证用以解决训练数据较少,我们并没有办法构建一个完整的验证集的问题,是一种评估模型泛化能力的方法。
在K折交叉验证中,我们首先将数据集分为K个大小相似的互斥子集,每次选取其中一个子集作为验证集,其余K-1个子集作为训练集,进行模型训练和验证。重复K次,每次选取不同的子集作为验证集,最终将K次的验证结果取平均值作为模型的最终性能评估指标。这样可以尽可能地利用数据,减小评估误差,提高模型的稳定性和可靠性。
举个例子,假设我们有1000条数据,希望使用K折交叉验证来评估模型的性能。我们将数据分为10个子集,每个子集包含100条数据。然后依次选取其中一个子集作为验证集,其余9个子集作为训练集,进行模型训练和验证,得到第一轮的验证结果。接着选取另一个子集作为验证集,其余9个子集作为训练集,进行模型训练和验证,得到第二轮的验证结果。以此类推,重复10次,最终将10次的验证结果取平均值作为模型的最终性能评估指标。
3. 过拟合和欠拟合
3.1 定义
过拟合(overfitting)指的是模型在训练集上的表现非常好,但在测试集上表现不佳的现象。也就是说,模型对训练集过度拟合,把训练集的一些噪声也学习进去了,导致在新的数据上表现不好。过拟合的主要原因是模型过于复杂,参数过多,导致模型能够完美地拟合训练集中的每一个数据点,但却失去了对新数据的泛化能力。
欠拟合指的是模型在训练数据上的表现不够好,即训练误差较高,而测试误差也较高。通常是由于模型过于简单,无法拟合数据中的复杂关系,或者是数据集过小,无法充分反映出数据的特征。
3.2 模型复杂度对拟合情况的影响
假设我们正在研究一个线性回归问题,其中有一个因变量 y 和两个自变量 x1 和 x2。我们用训练集和测试集分别来训练和测试模型,并使用均方误差(MSE)作为损失函数。
如果我们的模型是一个低阶多项式,例如一次或二次多项式,那么就有可能欠拟合。这意味着模型不能很好地拟合训练集数据,甚至也不能很好地拟合测试集数据,即使测试集数据是从相同分布中随机采样的。
如果我们的模型是一个高阶多项式,例如 10 次多项式,那么就有可能过拟合。这意味着模型可以在训练集上拟合得非常好,但是不能很好地拟合测试集数据,因为它学习了训练集数据的一些噪声。
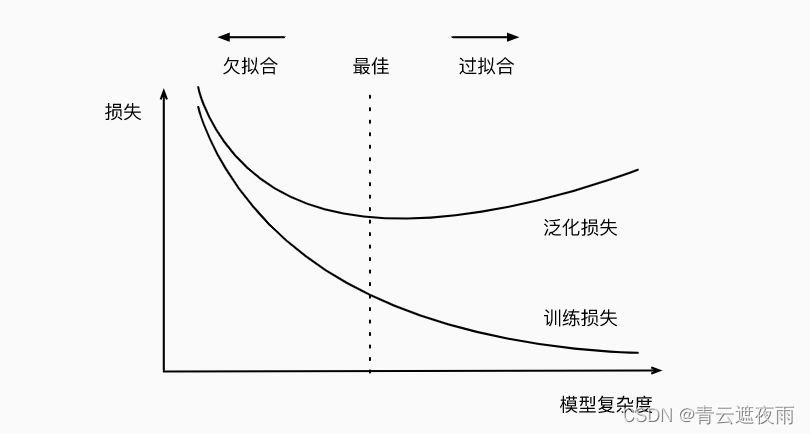
模型复杂度是指模型可以表达的函数族的复杂程度,即模型可以表示的函数的集合。模型复杂度对过拟合和欠拟合的影响非常重要。
当模型的复杂度过高时,模型容易过拟合,即在训练数据上表现良好,但在测试数据上表现较差。因为模型过于复杂,它可以拟合数据集中的任何细节和噪声,从而导致模型对数据集中的噪声产生过度敏感,无法很好地泛化到新数据集上。这种情况下,可以通过减少模型的复杂度或者增加正则化项来解决过拟合问题。
当模型的复杂度过低时,模型容易欠拟合,即在训练数据和测试数据上表现都较差。因为模型太简单,无法很好地拟合数据集中的规律和特征,从而导致无法很好地泛化到新数据集上。这种情况下,可以通过增加模型的复杂度或者增加特征数量来解决欠拟合问题。
3.3 解决方法
过拟合的解决方法,后面几节我们会讲解其具体实现:
- 数据增强(Data Augmentation):通过一些数据增强的手段,如旋转、翻转、裁剪等方式,增加数据集的多样性,减少过拟合。
- 正则化(Regularization):在损失函数中加入正则化项,如L1正则化、L2正则化等方式,惩罚权重过大的情况,限制模型复杂度。
- 提前停止(Early Stopping):在训练过程中,通过监测验证集的表现,及时停止训练,避免过拟合。
- Dropout:在神经网络中随机关闭一些神经元,减少过拟合。
欠拟合的解决方法:
- 增加模型复杂度:通过增加模型的层数或者每层的神经元数量等方式,增加模型的学习能力。
- 减少正则化:减少正则化的强度,放宽对模型复杂度的限制。
- 增加特征量:对输入数据进行特征工程,增加更多的特征量,提高模型的学习能力。
- 调整超参数:例如学习率、batch size等超参数的调整,可以影响模型的学习能力和学习速度。
指路第二节
相关文章:
深度学习神经网络基础知识(一) 模型选择、欠拟合和过拟合
专栏:神经网络复现目录 深度学习神经网络基础知识(一) 本文讲述神经网络基础知识,具体细节讲述前向传播,反向传播和计算图,同时讲解神经网络优化方法:权重衰减,Dropout等方法,最后进行Kaggle实…...

同样做软件测试,为什么有人月入3k-5k,有人能拿到17-20k?
同样做软件测试,为什么有人月入3k-5k,有人能拿到17-20k? 虽然各大培训机构一直鼓吹软件测试行业薪资高,但是依旧有一些拿着3-5k薪资,甚至找不到软件测试工作的人。 先来看一些例子: 小A在一家培训机构学完…...

如何运行YOLOv5的代码,实现目标识别
YOLOv5和v8都由Ultralytics这家创业公司开发的https://github.com/ultralytics/yolov5环境配置git clone https://github.com/ultralytics/yolov5.git作者要求python3.6(我用的3.8也能跑通)torch1.7.0pip install -r requirements_my_version.txtrequire…...
【正点原子FPGA连载】第十四章SD卡读写TXT文本实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第十四章SD卡读写…...

【人工智能AI :Open AI】我想写一本书,书名是《中国文学史》,帮我列一下目录,细化到三级目录,不少于2000字。
我想写一本书,书名是《中国文学史》,帮我列一下目录,细化到三级目录,不少于2000字。 中国文学史 第一章 经典文学 1.1 先秦文学 1.1.1 先秦诗歌 1.1.1.1 小雅 1.1.1.2 大雅 1.1.1.3 颂 1.1…...

「文档数据库之争」MongoDB和CouchDB的比较
MongoDB和CouchDB都是基于文档的NoSQL数据库类型。文档数据库又称mdocument store,通常用于存储半结构化数据的文档格式及其详细描述。它允许创建和更新程序,而不需要引用主模式。移动应用程序中的内容管理和数据处理是可以应用文档存储的两个字段。Mong…...
c++11 标准模板(STL)(std::unordered_set)(三)
定义于头文件 <unordered_set> template< class Key, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator<Key> > class unordered_set;(1)(C11 起)namespace pmr { templ…...

事件循环机制eventLoop?Js事件流?JavaScript如何实现异步编程?
单线程模式:由用户交互和修改dom的问题,只能决定js就是单线程任务异步模式诞生:同步模式遇到耗时操作页面便会阻塞,就像图片加载,接口获取,页面会一直等待;在执行主线程时,先执行同步…...

视频播放器倍速、清晰度切换、m3u8下载
视频上很容易就可以做到倍速播放,一般的视频格式都是每秒固定的帧数,按比例跳帧就可以了。音频上其实也可以用这种方式来直接删除一些周期,因为电脑里的音频也是数字化离散化地储存的。但是为了使声音不失真,应该都用了稍复杂一点…...
)
将Nginx 核心知识点扒了个底朝天(五)
什么叫 CDN 服务? CDN ,即内容分发网络。 其目的是,通过在现有的 Internet中 增加一层新的网络架构,将网站的内容发布到最接近用户的网络边缘,使用户可就近取得所需的内容,提高用户访问网站的速度。 一般…...

【基础算法】差分
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...
【LeetCode】剑指 Offer(5)
目录 写在前面: 题目: 题目的接口: 解题思路1: 代码: 过啦!!! 解题思路2: 代码: 过啦!!! 写在最后:…...
外包出来,朋友内推我去一家公司,问的实在是太...
外包出来,没想到算法死在另一家厂子,自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有…...

刷题记录:牛客NC54585小魂和他的数列 [线段树卡常,真恶心]
传送门:牛客 题目描述: 一天,小魂正和一个数列玩得不亦乐乎。 小魂的数列一共有n个元素,第i个数为Ai。 他发现,这个数列的一些子序列中的元素是严格递增的。 他想知道,这个数列一共有多少个长度为K的子序列是严格递增的。 请你帮…...

2019蓝桥杯真题旋转 C语言/C++
题目描述 图片旋转是对图片最简单的处理方式之一,在本题中,你需要对图片顺时针旋转 90 度。 我们用一个 nm 的二维数组来表示一个图片,例如下面给出一个 34 的 图片的例子: 1 3 5 7 9 8 7 6 3 5 9 7 这个图片顺时针旋转 90 度…...
<JVM上篇:内存与垃圾回收篇>11 - 垃圾回收相关算法
对象存活判断 在堆里存放着几乎所有的 Java 对象实例,在 GC 执行垃圾回收之前,首先需要区分出内存中哪些是存活对象,哪些是已经死亡的对象。只有被标记为己经死亡的对象,GC 才会在执行垃圾回收时,释放掉其所占用的内存…...
狂飙Linux平台,软件部署大全
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...
积分球原理及积分球类型介绍
标题积分球标准型积分球LED积分球均匀光源便携式高亮度积分球均匀光源微光积分球均匀光源积分球均匀光源iSphere高光谱响应光学积分球其他分类积分球 积分球原理:由于球体内整涂有白色漫反射材料的空腔球体,球壁上开有采样口,当待测样品光源进入积分球的…...

Vision Transformer(ViT) 2: 应用及代码讲解
文章目录1. 代码讲解1.1 PatchEmbed类1)__init__ 函数2) forward 过程1.2 Attention类1)__init__ 函数2)forward 过程1.3 MLP类1)__init__ 函数2)forward函数1.4 Block类1)__init__ 函数2)forwa…...
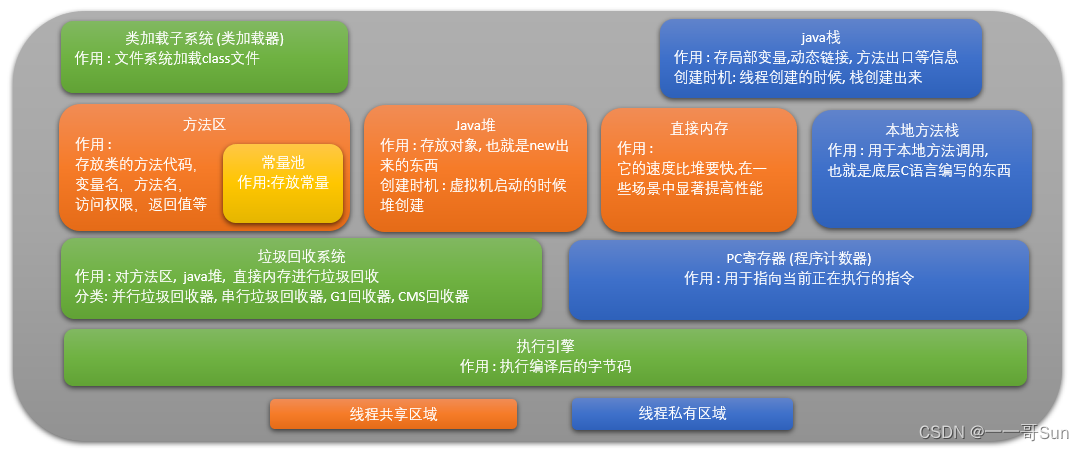
高频面试题|JVM虚拟机的体系结构是什么样的?
一. 前言最近有很多小伙伴都在找工作,他们在面试时经常被面试官问到一个问题:请说说JVM虚拟机的体系结构是什么样的?很多小伙伴都能说出堆、栈等相关内容,但面试官紧接着又问,你还知道其他内容吗?这时不少小伙伴就语塞…...

暗黑3自动化工具终极指南:如何用智能技能宏提升游戏效率
暗黑3自动化工具终极指南:如何用智能技能宏提升游戏效率 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神…...

vibe coding实战:利用快马平台为诗歌朗诵会打造沉浸式互动网页
最近帮朋友策划了一场线上诗歌朗诵会,需要制作一个能实时互动的沉浸式网页。这个项目最有趣的地方在于,它不仅要展示诗歌内容,还要通过视觉和交互传递诗歌的情感氛围。这种强调"氛围编码"(vibe coding)的场景…...

STM32主控的三相逆变器及单相/三相逆变程序实现
三相逆变 单相/三相逆变器 SPWM ---stm32主控(输入、输出具体可根据需要设定),本逆变器可以二次开发。 本内容只包括 逆变程序,实现变频(0~100Hz)、变压调节,均有外接按键控制(使用C…...

告别重复造轮子:用快马生成高效配对模块提升开发效率
在开发智能硬件或物联网项目时,设备配对功能几乎是每个项目都绕不开的基础模块。但每次从零开始实现蓝牙、Wi-Fi等设备的配对逻辑时,总免不了要重复处理扫描过滤、状态管理、错误重试这些"轮子"。最近尝试用InsCode(快马)平台生成标准化配对模…...
:HiFloat8高效低比特推理)
HiFloat8高效训推技术报告(2):HiFloat8高效低比特推理
1. 低比特推理背景知识深度学习模型在训练和推理阶段通常使用 FP32 (32位浮点数) 或 BF16/FP16 (16位浮点数) 格式。然而,随着模型规模的不断增大(尤其是大型语言模型 LLM),对计算效率、显存占用和能耗的要求也越来越高。低比特推…...

告别卡顿!用华为云ECS搭建高性能eNSP Pro服务器,支持大规模组网实验
华为云ECS深度优化指南:解锁eNSP Pro大规模组网实验的终极性能 当你在本地PC上运行eNSP Pro进行网络实验时,是否遇到过这样的困境:模拟5台设备就开始卡顿,复杂拓扑直接崩溃,或者保存配置时进度条像蜗牛爬行?…...
)
1520上市公司企业短期并购绩效和长期并购绩效数据+dofile(2008-2022)
数据来源参考《管理世界》陈仕华老师的做法,详情点击查看更多详情信息时间跨度2008-2022区域跨度企业数据格式dta/excel数据简介今天数据皮皮侠团队为大家分享一份最新的上市公司企业短期并购绩效和长期并购绩效数据,供大家研究使用。数据指标上市公司企…...

有限元分析避坑指南:四边形等参元高斯积分计算中的5个常见错误
有限元分析避坑指南:四边形等参元高斯积分计算中的5个常见错误 有限元分析作为工程仿真领域的核心技术,其精度和效率直接影响产品设计的可靠性。在众多单元类型中,四边形等参元因其良好的适应性和计算效率被广泛应用,但高斯积分环…...

外卖系统订单模块设计避坑指南:地址簿管理与状态流转实战
外卖系统订单模块设计避坑指南:地址簿管理与状态流转实战 中午12点,写字楼里的白领们纷纷打开外卖APP下单午餐。短短几分钟内,系统需要处理成千上万笔订单——验证用户地址、确认支付状态、通知商家接单。这背后是一套复杂的订单系统在支撑&a…...

VSCode插件Console Ninja详解:把DevTools搬进编辑器,调试效率翻倍
作为前端/Node.js开发者,我们每天都会和console.log打交道——调试时写日志、看输出、找错误,却总被“切换窗口”困扰:一边是VSCode编辑器,一边是浏览器DevTools或终端,来回切换不仅打断思路,还浪费大量时间…...