LLMs高效的多 GPU 计算策略Efficient multi-GPU compute strategies
很有可能在某个时候,您需要将模型训练工作扩展到超过一个GPU。在上一个视频中,我强调了当您的模型变得太大而无法适应单个GPU时,您需要使用多GPU计算策略。但即使您的模型确实适合单个GPU,使用多个GPU加速训练也有好处。即使您正在使用小型模型,了解如何跨GPU分配计算也会很有用。让我们讨论如何有效地跨多个GPU进行这种扩展。
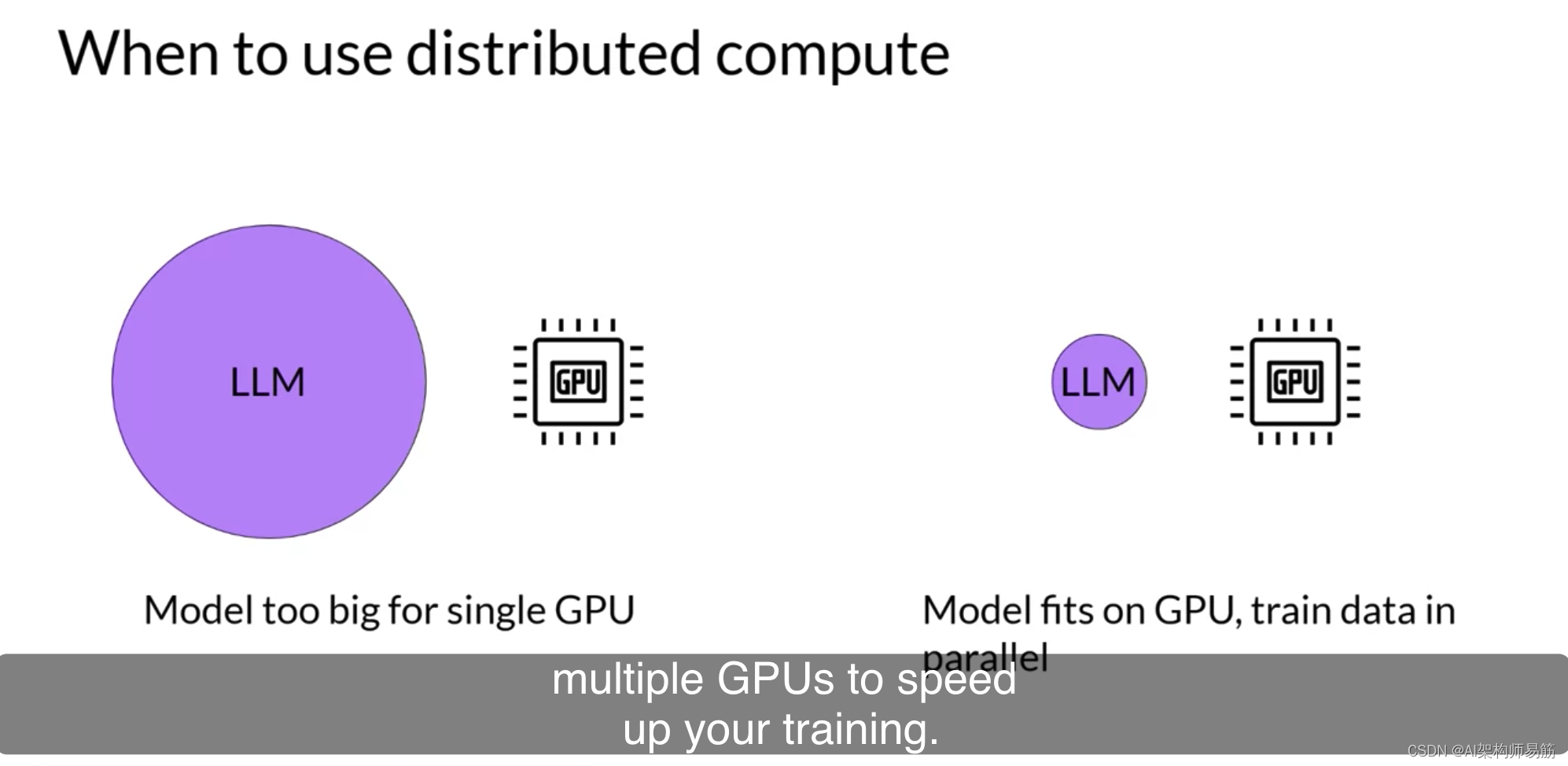
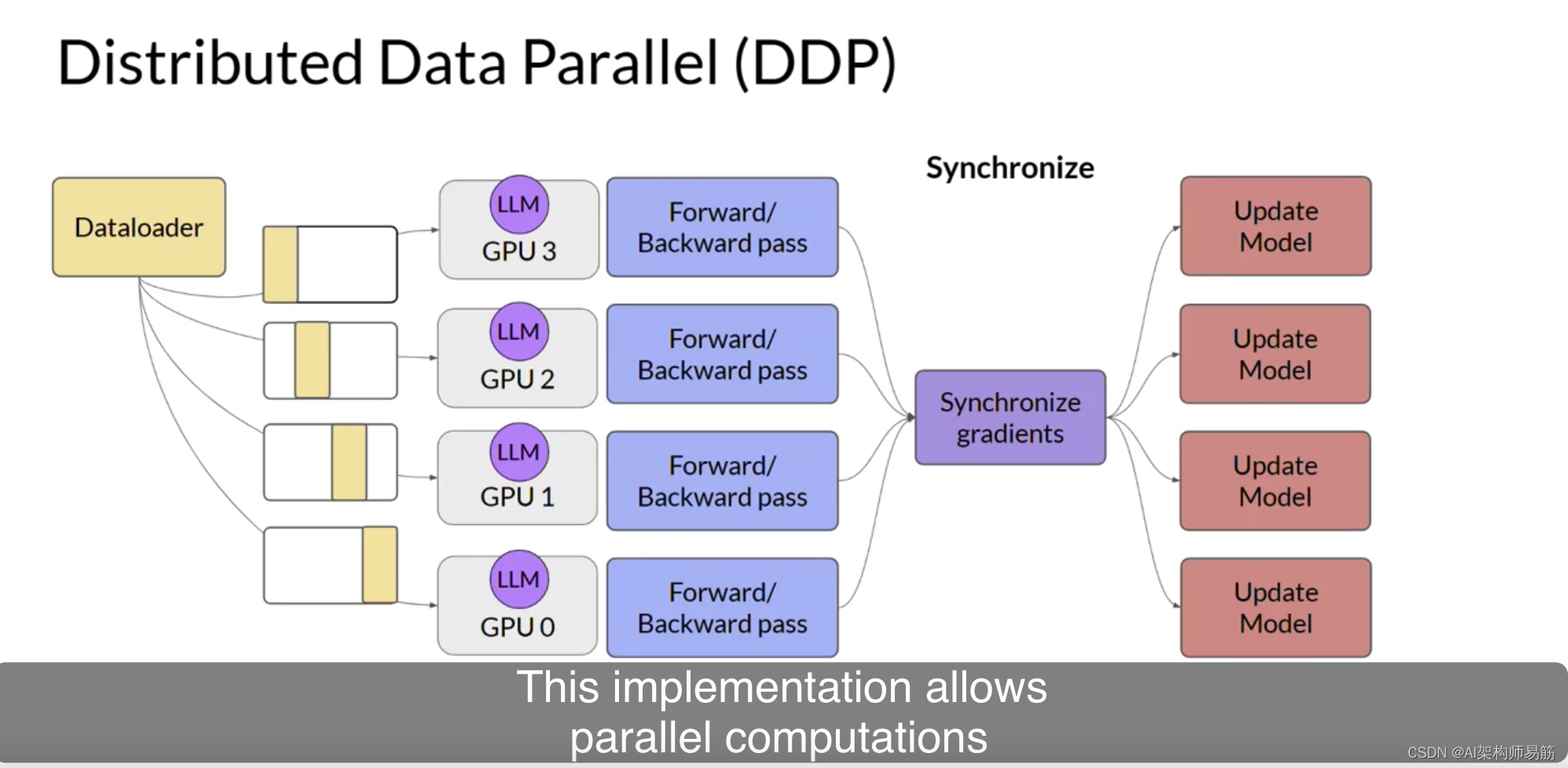
您将从考虑模型仍然适合单个GPU的情况开始。扩展模型训练的第一步是将大型数据集分布到多个GPU,并并行处理这些数据批次。这种模型复制技术的一个流行实现是PyTorch的Distributed Data Paraller分布式数据并行,或简称DDP。DDP将您的模型复制到每个GPU,并将数据批次并行发送到每个GPU。每个数据集并行处理,然后一个同步步骤组合每个GPU的结果,从而更新每个GPU上的模型,这在芯片之间始终是相同的。这种实现允许跨所有GPU进行并行计算,从而加快训练速度。请注意,DDP要求您的模型权重和所有其他训练所需的参数、梯度和优化器状态都适合单个GPU。
如果您的模型对此过大,您应该考虑另一种称为模型分片Model Sharded的技术。模型分片的一个流行实现是PyTorch的Fully Sharded Data Parallel完全分片数据并行,或简称FSDP。FSDP的动机是2019年由Microsoft研究人员发表的一篇论文,该论文提出了一种称为ZeRO的技术。ZeRO代表零冗余优化器,ZeRO的目标是通过分布或分片模型状态跨GPU与ZeRO数据重叠来优化内存。这允许您在模型不适合单个芯片的内存时,跨GPU缩放模型训练。

在回到FSDP之前,让我们快速看看ZeRO是如何工作的。
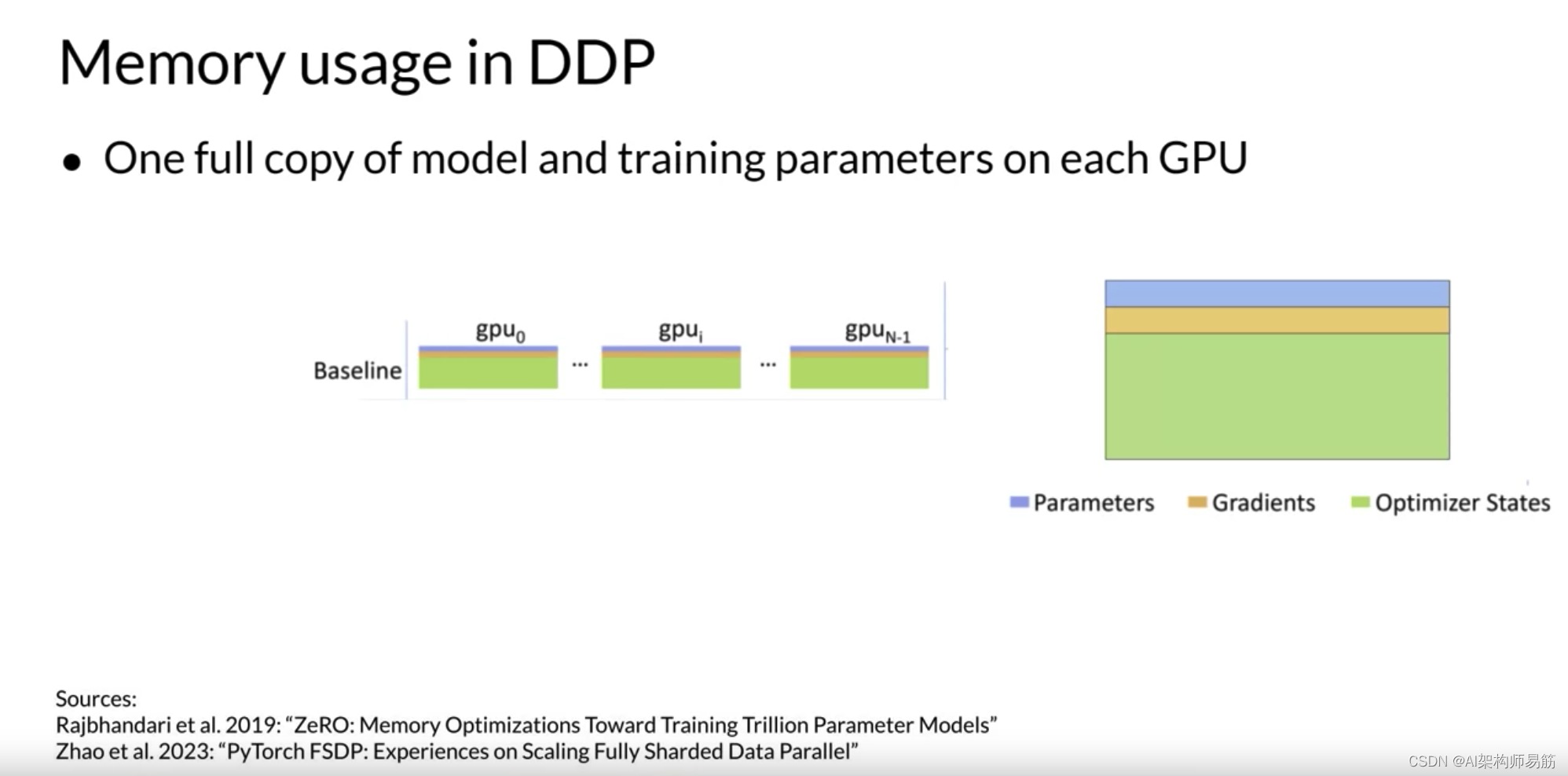
本周早些时候,您查看了训练LLM所需的所有内存组件,最大的内存需求是优化器状态,它占用的空间是权重的两倍,然后是权重本身和梯度。

让我们将参数表示为这个蓝色框,梯度为黄色,优化器状态为绿色。

我之前展示的模型复制策略的一个限制是您需要在每个GPU上保留一个完整的模型副本,这导致了冗余的内存消耗。您在每个GPU上存储相同的数字。
另一方面,ZeRO通过分布也称为分片模型参数、梯度和优化器状态跨GPU,而不是复制它们,从而消除了这种冗余。与此同时,沉没模型状态的通信开销接近之前讨论的Distributed Data Paraller (DDP)。
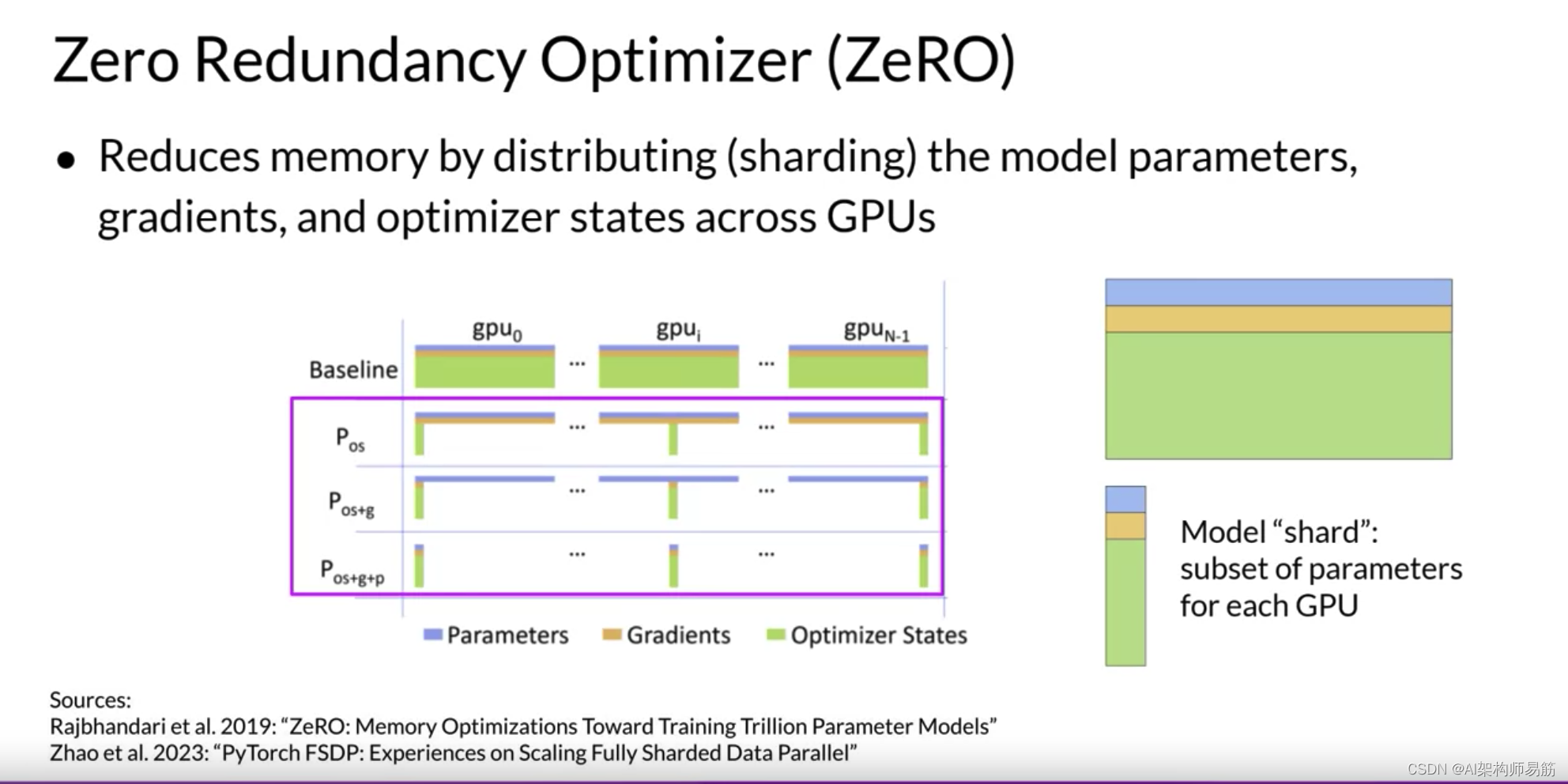
ZeRO提供了三个优化阶段。ZeRO阶段1仅跨GPU分片Optimizer States优化器状态,这可以将您的内存占用减少到四分之一。
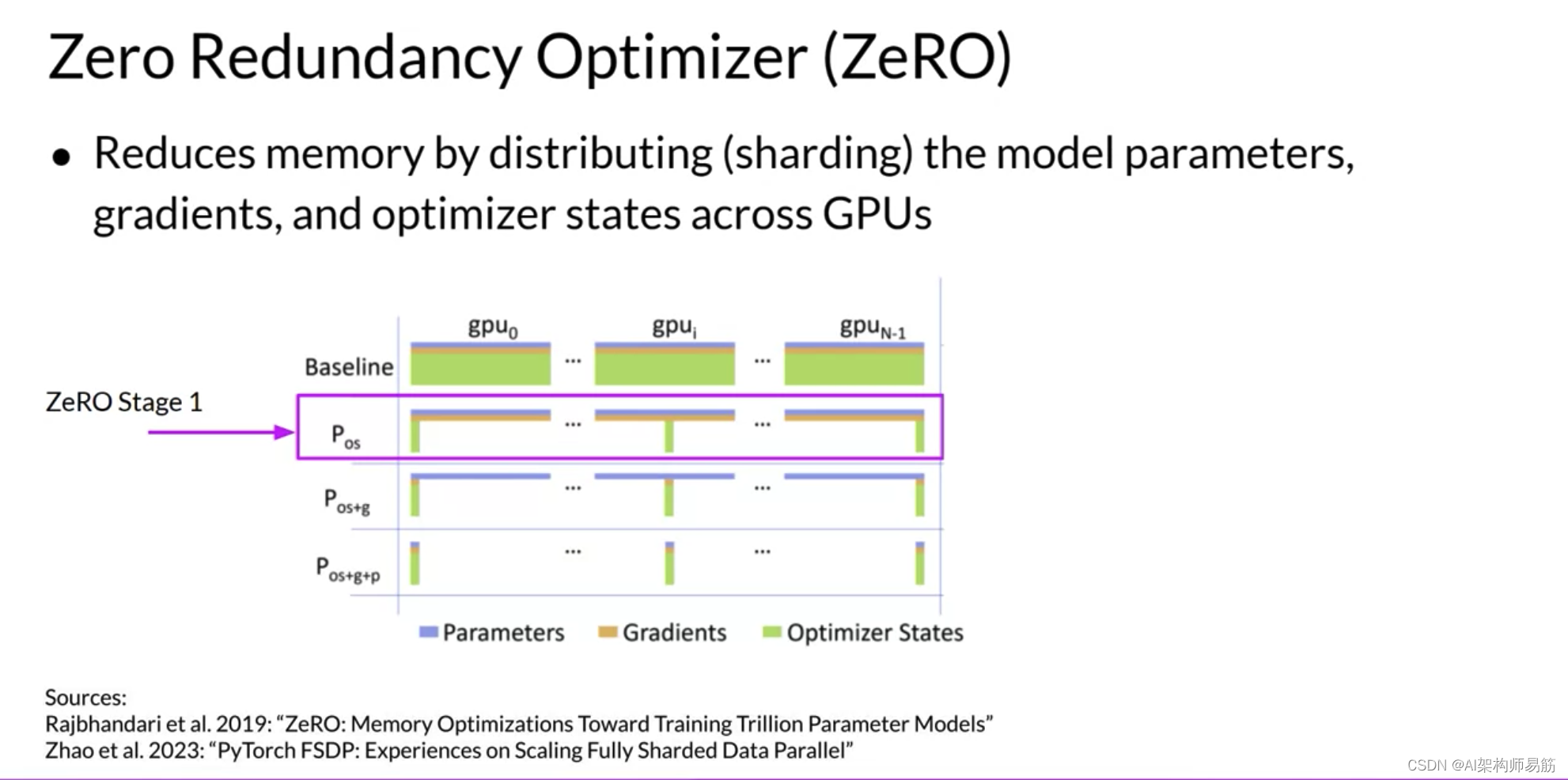
ZeRO阶段2还将Gradient梯度分片到芯片上。与阶段1一起应用时,这可以将您的内存占用减少到八倍。
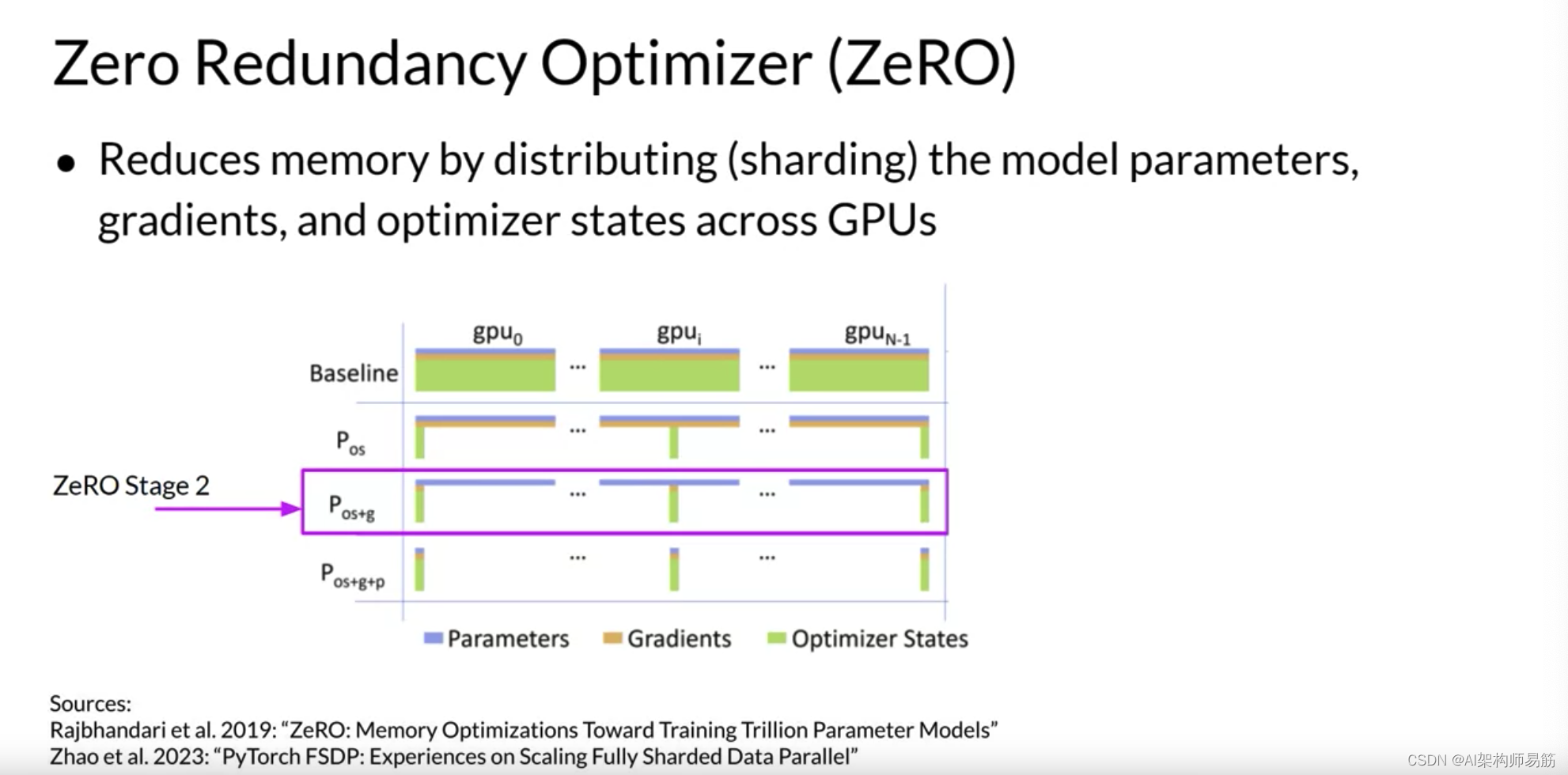
最后,ZeRO阶段3将所有组件(包括模型参数Parameters)分片到GPU上。与阶段1和2一起应用时,内存减少与GPU数量成线性关系。例如,跨64个GPU的分片可以将您的内存减少64倍。

让我们将这个概念应用到GDP的可视化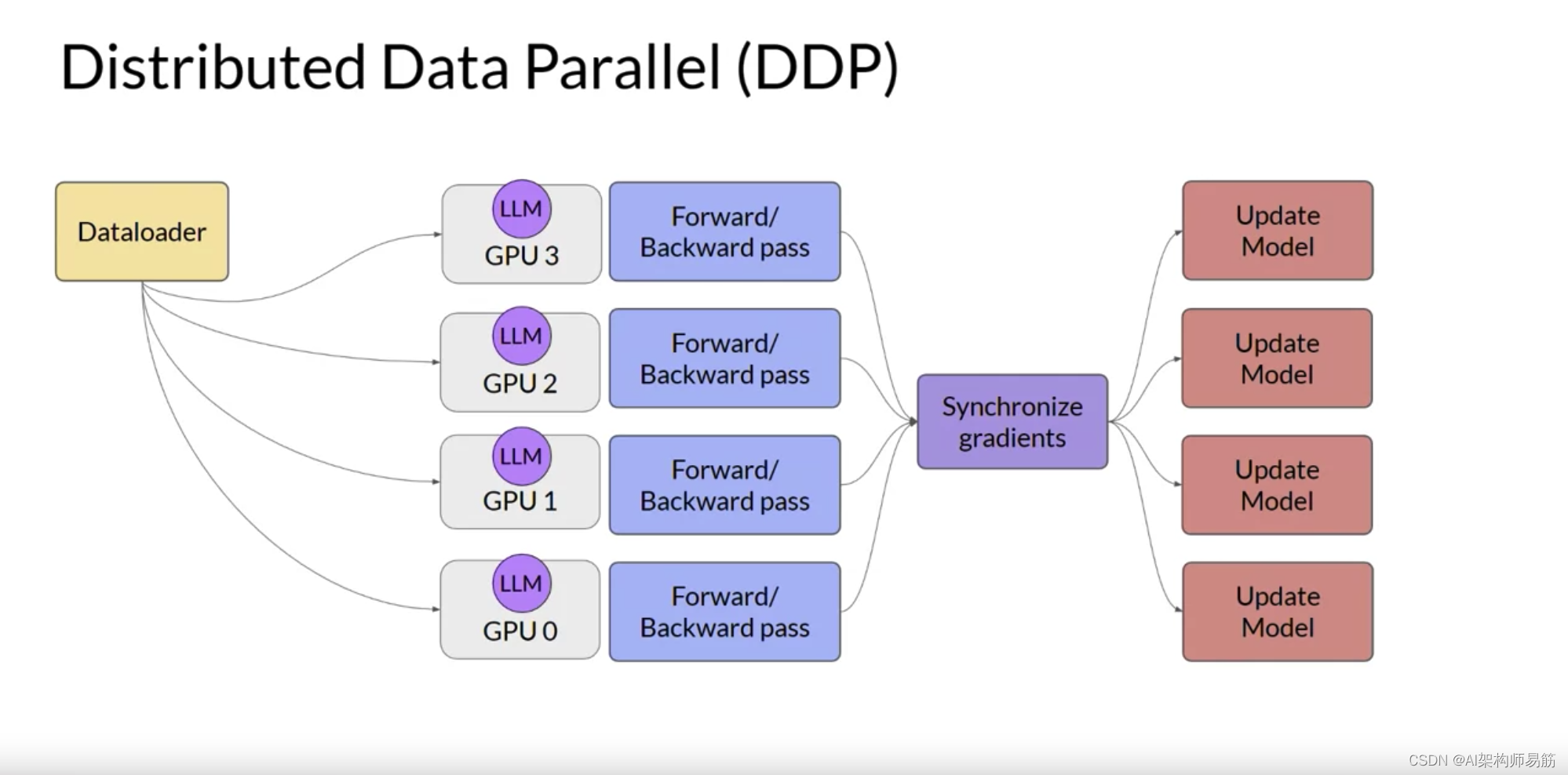
,
并用模型参数、梯度和优化器状态的内存表示替换LLM。当您使用FSDP时,您将数据分布到多个GPU,如您在DDP中看到的那样。
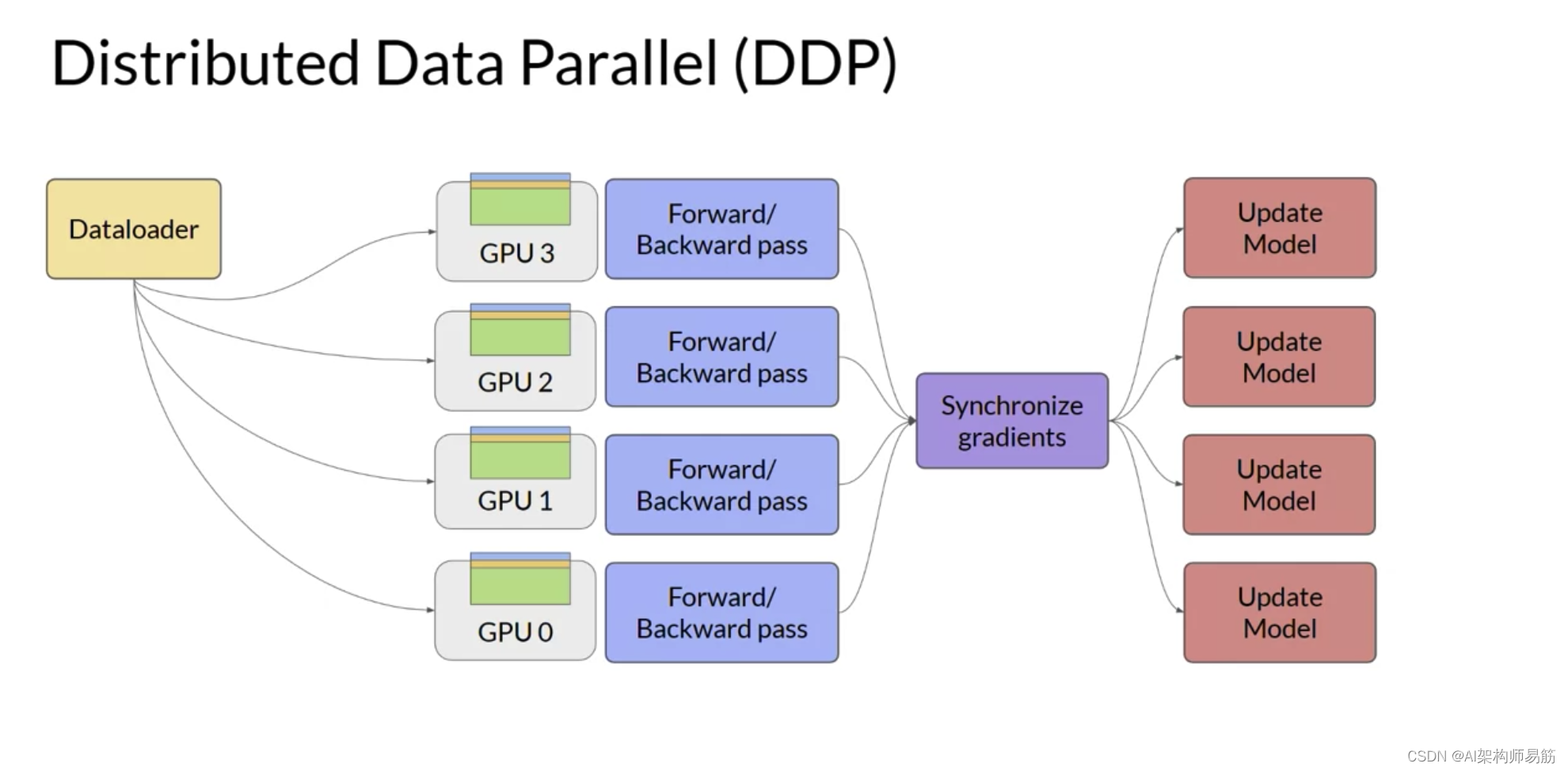
但是,使用FSDP,您还可以使用ZeRO论文中指定的策略之一,将模型参数、梯度和优化状态分布或分片到GPU节点上。使用这种策略,您现在可以使用太大而无法适应单个芯片的模型。
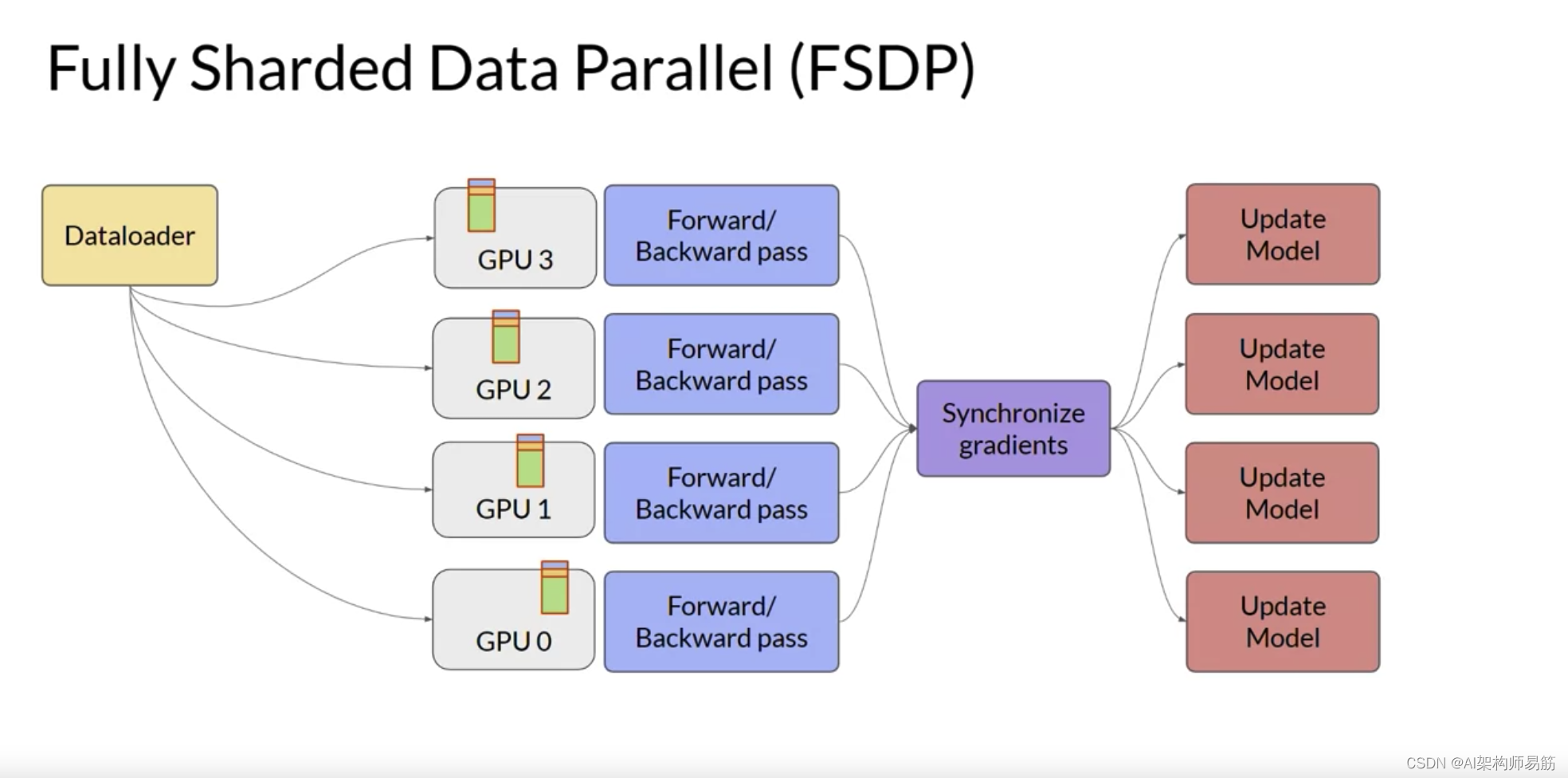
与DDP相反,其中每个GPU都有本地化处理每批数据所需的所有模型状态,FSDP要求您在前向和后向传递之前从所有GPU收集此数据。
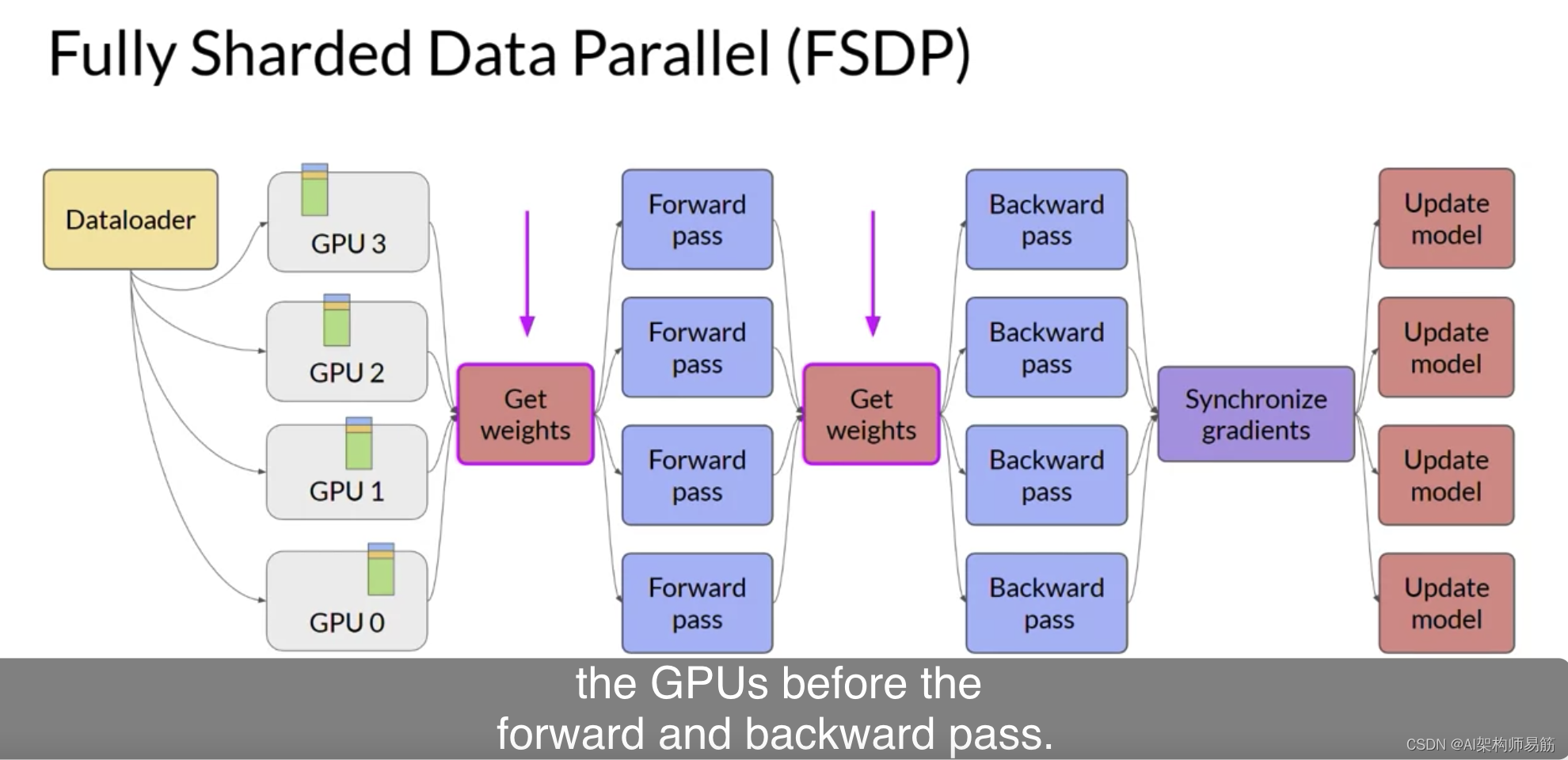
每个CPU按需从其他GPU请求数据,将分片数据转化为非分片数据以供操作使用。操作后,您将非分片的非本地数据释放回其他GPU作为原始分片数据。您还可以选择在后向传递期间为未来的操作保留它。注意,这需要更多的GPU RAM,这是一个典型的性能与内存权衡决策。
在后向传递后的最后一步,FSDP与DDP相同地跨GPU同步梯度。

如FSDP所描述的模型分片
- 允许您减少整体GPU内存使用。
- 您还可以选择让FSDP将部分训练计算卸载到GPU,以进一步减少GPU内存使用。
- 为了管理性能与内存使用之间的权衡,您可以使用FSDP的sharding factor分片因子配置分片级别。
分片因子为1基本上删除了分片并复制了与DDP类似的完整模型。

如果您将分片因子设置为可用GPU的最大数量,您将打开完整的分片。这节省了最多的内存,但增加了GPU之间的通信量。

中间的任何分片因子都启用了超分片。

让我们看看FSDP与DDP在每个GPU的teraflops上的性能如何。这些测试使用最多512个NVIDIA V100 GPU执行,每个GPU有80GB的内存。注意,一个teraflop对应于每秒一万亿次 1 0 12 10^{12} 1012浮点运算。第一个数字显示了不同大小T5模型的FSDP性能。您可以看到FSDP的不同性能数字,完整分片为蓝色,超分片为橙色,完整复制为绿色。作为参考,DDP性能以红色显示。
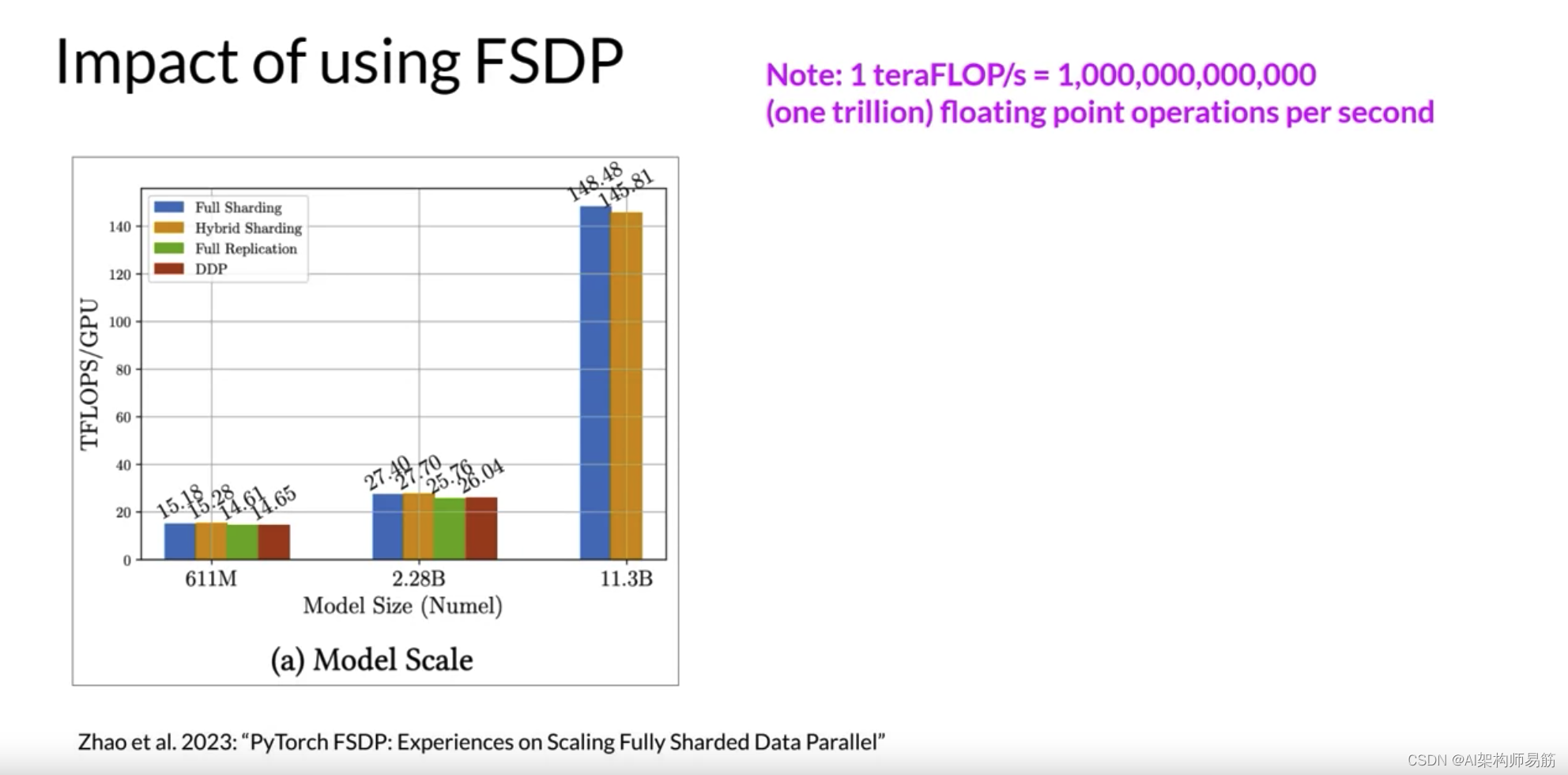
对于首先有611百万参数和22.8亿参数的25个模型,FSDP和DDP的性能相似。现在,如果您选择超过22.8亿的模型大小,例如25个模型有113亿参数,DDP会遇到内存不足的错误。另一方面,FSDP可以轻松处理这种大小的模型,并在将模型的精度降低到16位时获得更高的teraflops。
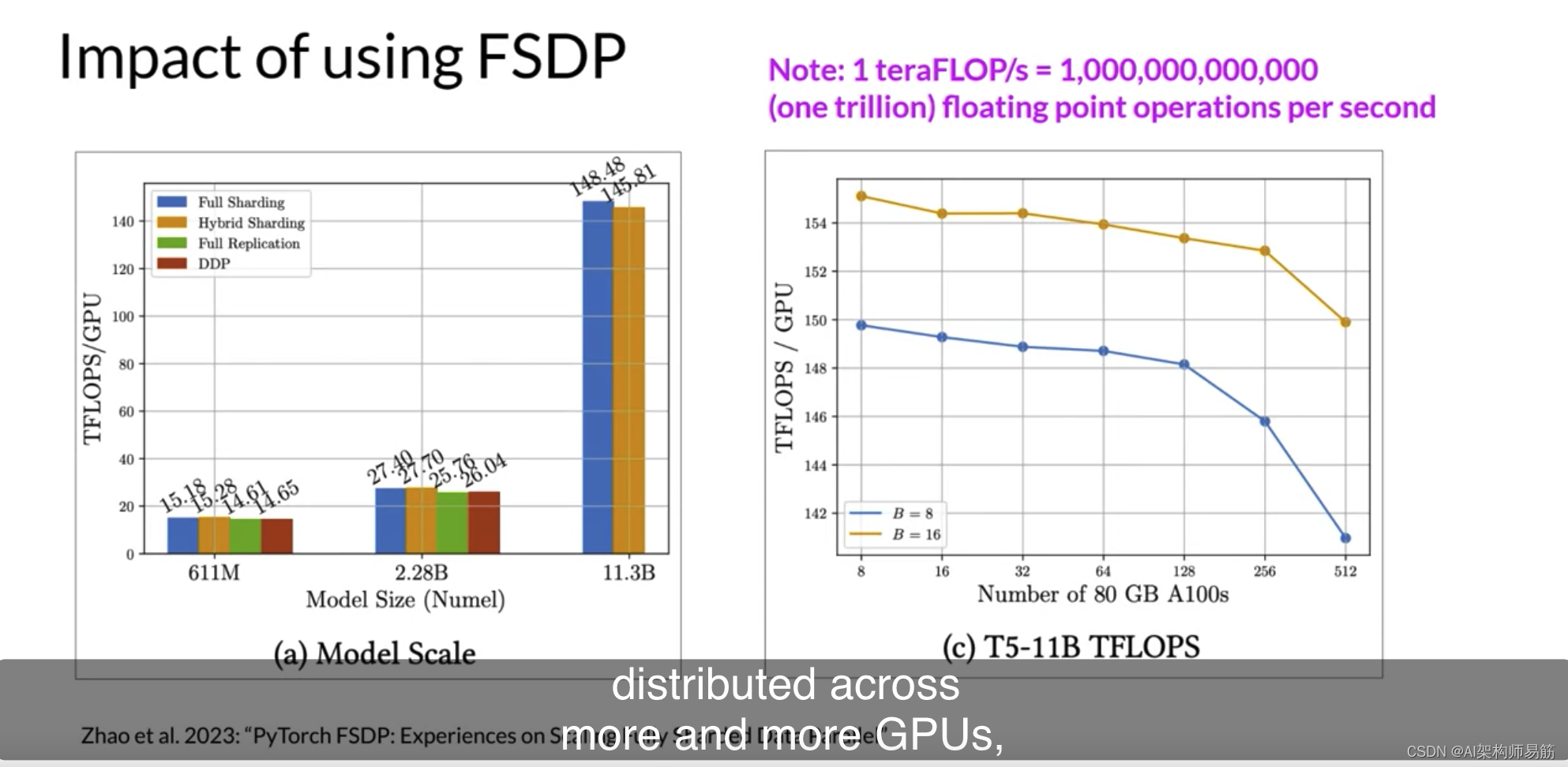
第二个数字显示了当增加GPU数量从8-512为11亿T5模型时,每个GPU teraflops减少了7%,
这里使用了批量大小为16的橙色和批量大小为8的蓝色。随着模型在大小上增长并分布到越来越多的GPU上,芯片之间的通信量增加开始影响性能,减慢计算。
总之,这表明您可以使用FSDP进行小型和大型模型,并无缝地跨多个GPU扩展模型训练。
我知道这次讨论非常技术性,我想强调的是,您不需要记住所有的细节。最重要的是,当训练LLM时,了解数据、模型参数和训练计算如何跨进程共享。鉴于跨GPU训练模型的费用和技术复杂性,一些研究人员一直在探索如何使用较小的模型实现更好的性能。在下一个视频中,您将了解有关计算最佳模型的研究。让我们继续看下去。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/e8hbI/optional-video-efficient-multi-gpu-compute-strategies
相关文章:
LLMs高效的多 GPU 计算策略Efficient multi-GPU compute strategies
很有可能在某个时候,您需要将模型训练工作扩展到超过一个GPU。在上一个视频中,我强调了当您的模型变得太大而无法适应单个GPU时,您需要使用多GPU计算策略。但即使您的模型确实适合单个GPU,使用多个GPU加速训练也有好处。即使您正在…...
jvm-类加载子系统
1.内存结构概述 类加载子系统负责从文件系统或网络中加载class文件,class文件在文件开头有特定的文件标识 ClassLoader只负责class文件的加载,至于它是否运行,则由Execution Engine决定 加载的类信息存放于一块称为方法区的内存空间ÿ…...
【实例分割】(一)Mask R-CNN详细介绍带python代码
目录 1.🍀🍀实例分割定义 2.🍀🍀Mask R-CNN 3.🍀🍀经典的实例分割算法 4.🍀🍀Mask R-CNN python代码 整理不易,欢迎一键三连!!!…...
面试官问我Redis怎么测,我一脸懵逼!
有些测试朋友来问我,redis要怎么测试?首先我们需要知道,redis是什么?它能做什么? redis是一个key-value类型的高速存储数据库。 redis常被用做:缓存、队列、发布订阅等。 所以,“redis要怎么测试…...

【Spring Boot】四种核心类的依赖关系:实体类、数据处理类、业务处理类、控制器类
//1.配置项目环境,创建Spring Boot项目。 //2.数据库设置,配置数据库。 //3.创建实体类,映射到数据库。 //4.创建数据处理层类,Repository //5.创建业务处理类,Service类 //6.创建控制器类,Controller类 Ar…...

opencv 进阶15-检测DoG特征并提取SIFT描述符cv2.SIFT_create()
前面我们已经了解了Harris函数来进行角点检测,因为角点的特性,这些角点在图像旋转的时候也可以被检测到。但是,如果我们放大或缩小图像时,就可能会丢失图像的某些部分,甚至有可能增加角点的质量。这种损失的现象需要一…...

ES5 的构造函数和 ES6 的类有什么区别
文章目录 语法不同方法定义方式不同继承方式不同类内部的this指向不同静态成员定义方式不同访问器属性类的类型检查 在JavaScript中,类和构造函数都被用来创建对象,接下来会从以下几点说说两者的区别: 语法不同 构造函数使用函数来定义类使用…...
AUTOSAR配置与实践(配置篇) 如何条件控制PDU外发
AUTOSAR配置与实践(配置篇)如何条件控制PDU外发 一、需求1.1 需求简要分析1.2 需求进一步分析二、流程实现和具体配置一、需求 需要针对特定的PDU(外发)进行条件控制,这里要通过不同配置字进行PDU是否外发的控制 1.1 需求简要分析 正常PDU分组时分为两组,接收报文组和…...

2023年湖北中级工程师职称申报专业有哪些?甘建二告诉你
中级职称职称申报专业:环境工程、 土木建筑、土建结构、土建监理、土木工程、岩石工程、岩土、土岩方、风景园林、园艺、园林、园林建筑、园林工程、园林绿化、古建筑园林、工民建、工民建安装、建筑、建筑管理、建筑工程、建筑工程管理、建筑施工、建筑设计、建筑装…...

记录:ubuntu20.04+ORB_SLAM2_with_pointcloud_map+ROS noetic
由于相机实时在线运行需要ROS,但Ubuntu22.04只支持ROS2,于是重装Ubuntu20.04。上一篇文章跑通的是官方版本的ORB_SLAM2,不支持点云显示。高翔修改版本支持RGB-D相机的点云显示功能。 高翔修改版本ORB_SLAM2:https://github.com/ga…...
文心问数Sugar Bot :大模型+BI,多轮会话自动生成可视化图表与数据结论
Sugar BI 的文心问数功能是基于大语言模型实现的,支持您使用自然语言,通过多轮会话的方式,获取实时数据的图表展现,也可以自动为您总结与图表相关的业务结论。 文心问数功能邀测中,欢迎CSDN的用户前来报名:…...

21、WEB漏洞-文件上传之后端黑白名单绕过
目录 前言验证/绕过 前言 关于文件上传的漏洞,目前在网上的常见验证是验证三个方面: 后缀名,文件类型,文件头,其中这个文件头是属于文件内容的一个验证 后缀名:黑名单,白名单 文件类型…...

windows的django项目部署到linux的docker上
编辑dockerfile文件,可以自行寻找相关教程 创建镜像 docker bulid -t imagename:tag .查看镜像 docker images 如果想自己先试一下,那就需要运行容器 docker run -it -d -p 8000:8000 --name volume_name imagename:tag 查看容器 docker ps -a 进…...

【力扣】70. 爬楼梯 <动态规划>
【力扣】70. 爬楼梯 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2. …...
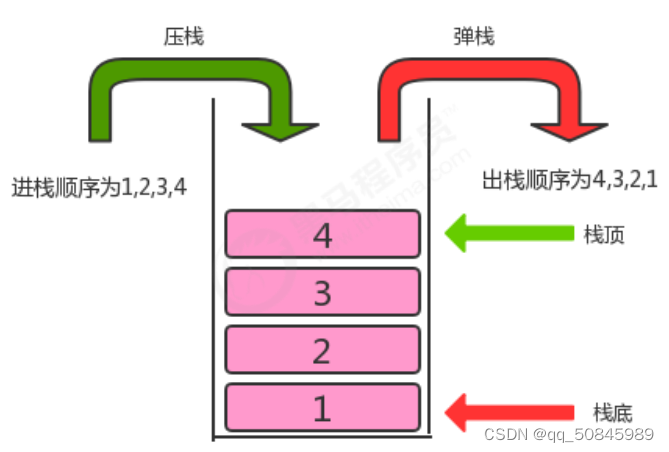
数据结构(3)
线性表是多个具有相同特征的数据的有限序列。 前驱元素:A在B前面,称A为B的前驱元素。 后继元素:B在A后面,称B为A的后继元素。 线性表特征: 1.一个元素没有前驱元素,就是头结点; 2.最后一个…...

深入浅出Pytorch函数——torch.nn.init.xavier_uniform_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...
工程师)
优橙内推安徽专场——5G网络优化(中高级)工程师
可加入就业QQ群:801549240 联系老师内推简历投递邮箱:hrictyc.com 内推公司1:浙江省邮电工程建设有限公司 内推公司2:北京宜通华瑞科技有限公司 内推公司3:浙江明讯网络技术有限公司 浙江省邮电工程建设有限公司 …...
2023年计算机设计大赛国三 数据可视化 (源码可分享)
2023年暑假参加了全国大学生计算机设计大赛,并获得了国家三等奖(国赛答辩出了点小插曲)。在此分享和记录本次比赛的经验。 目录 一、作品简介二、作品效果图三、设计思路四、项目特色 一、作品简介 本项目实现对农产品近期发展、电商销售、灾…...
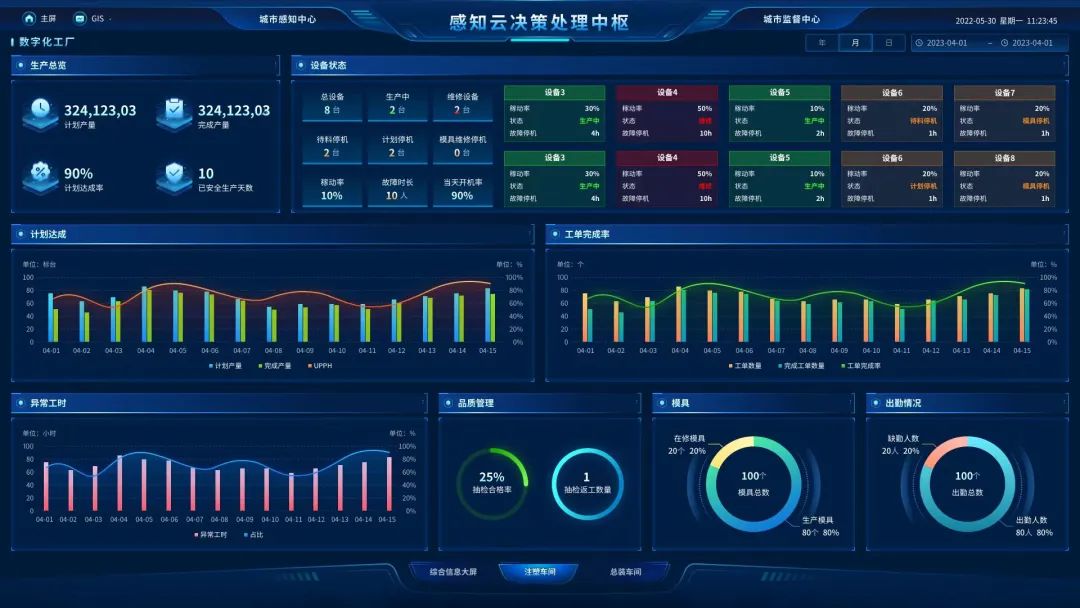
工业生产全面感知!工业感知云来了
面向工业企业数字化转型需求,天翼物联基于感知云平台创新能力和5G工业物联数采能力,为客户提供工业感知云服务,包括工业泛协议接入、感知云工业超轻数采平台、工业感知数据治理、工业数据看板四大服务,构建工业感知神经系统新型数…...

Lnton羚通关于Optimization在【PyTorch】中的基础知识
OPTIMIZING MODEL PARAMETERS (模型参数优化) 现在我们有了模型和数据,是时候通过优化数据上的参数来训练了,验证和测试我们的模型。训练一个模型是一个迭代的过程,在每次迭代中,模型会对输出进行猜测&…...

Maven项目实战:手动部署Oracle JDBC驱动的本地仓库配置指南
1. 为什么需要手动安装Oracle JDBC驱动 遇到Maven项目提示"Missing artifact com.oracle:ojdbc6:jar:11.2.0.3"时,很多Java开发者都会一头雾水。我刚开始接触Maven时也踩过这个坑,后来才明白这是因为Oracle的JDBC驱动(ojdbc&#x…...
)
从零搭建AI-ready数据管道:2026奇点大会现场复刻的3小时极速部署流水线(含LLM元数据自动标注模块)
更多请点击: https://intelliparadigm.com 第一章:AI原生数据管道搭建:2026奇点智能技术大会数据工程实践 在2026奇点智能技术大会上,核心数据平台团队首次全栈落地了真正意义上的AI原生数据管道(AI-Native Data Pipe…...

Go语言服务网格负载均衡策略
Go语言服务网格负载均衡策略 1. 负载均衡算法 package loadbalancetype LoadBalancer interface {Select([]string) string }type RoundRobin struct {index intmu sync.Mutex }func NewRoundRobin() *RoundRobin {return &RoundRobin{} }func (r *RoundRobin) Select(e…...

Noto字体库:构建全球化数字产品的字体基石
Noto字体库:构建全球化数字产品的字体基石 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 在全球化的数字时代,字体选择已不再是简单的美学决策,而是直…...

如何通过手机APP远程控制微信自动化:wxauto移动端管理完整指南
如何通过手机APP远程控制微信自动化:wxauto移动端管理完整指南 【免费下载链接】wxauto Windows版本微信客户端(非网页版)自动化,可实现简单的发送、接收微信消息,简单微信机器人 项目地址: https://gitcode.com/gh_…...

大规模可观测性:构建云原生系统的感知能力
大规模可观测性:构建云原生系统的感知能力 一、大规模可观测性概述 1.1 可观测性的定义 可观测性是指通过外部输出推断系统内部状态的能力。在云原生环境中,可观测性通过收集和分析指标、日志和追踪数据,帮助开发者理解系统的行为和性能。 1.…...
Transformer架构优化实战2026:注意力机制、KV Cache与推理加速完整指南
Transformer架构诞生已近十年,但它的工程优化故事才刚刚开始。2026年,理解并掌握Transformer的核心优化技术,是每个LLM工程师的必修课。一、为什么Transformer的优化如此重要一个7B参数的LLM在A100上推理时,如果没有优化ÿ…...

OpenClaw插件实战:为Telegram审批消息添加一键操作按钮
1. 项目概述:为OpenClaw的Telegram频道添加一键审批按钮如果你正在使用OpenClaw,并且像我一样,把Telegram作为主要的交互和通知渠道,那你肯定对下面这个场景不陌生:AI助手在执行某个需要授权的命令(比如exe…...
)
告别恼人的JDK版本警告!手把手教你为IDEA+Maven项目永久锁定Java 8(保姆级避坑图解)
彻底根治IDEAMaven项目的JDK版本警告:从项目配置到环境锁定的终极方案 每次打开IntelliJ IDEA,那个刺眼的黄色警告"Warning:java: 源值1.5已过时"就像代码世界里的蟑螂,虽然无害但令人极度不适。作为有代码洁癖的开发者,…...

QtMqtt模块编译实战:从源码到集成的关键步骤与排错指南
1. 为什么需要手动编译QtMqtt模块 MQTT协议在物联网领域应用广泛,但Qt官方发行版中并不包含MQTT模块。这就好比买了一台组装电脑,却发现显卡需要自己另外安装。QtMqtt模块作为Qt的扩展组件,目前需要通过源码编译的方式集成到开发环境中。 我去…...