spark代码
RDD
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
该系总共有多少学生;
val lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
val par = lines.map(row=>row.split(",")(0))
val distinct_par = par.distinct() //去重操作
distinct_par.count //取得总数
该系共开设来多少门课程;
val lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
val par = lines.map(row=>row.split(",")(1))
val distinct_par = par.distinct()
distinct_par.count
Tom 同学的总成绩平均分是多少;
val lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
val pare = lines.filter(row=>row.split(",")(0)=="Tom")
pare.foreach(println)
Tom,DataBase,26
Tom,Algorithm,12
Tom,OperatingSystem,16
Tom,Python,40
Tom,Software,60
pare.map(row=>(row.split(",")(0),row.split(",")(2).toInt)).mapValues(x=>(x,1)).reduceByKey((x,y0) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()
//res9: Array[(String, Int)] = Array((Tom,30))
求每名同学的选修的课程门数
val lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
val pare = lines.map(row=>(row.split(",")(0),row.split(",")(1)))
pare.mapValues(x => (x,1)).reduceByKey((x,y) => (" ",x._2 + y._2)).mapValues(x => x._2).foreach(println)
各门课程的平均分是多少;
val lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
val pare = lines.map(row=>(row.split(",")(1),row.split(",")(2).toInt))
pare.mapValues(x=>(x,1)).reduceByKey((x,y) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()
res0: Array[(String, Int)] = Array((Python,57), (OperatingSystem,54), (CLanguage,50), 使用累加器计算共有多少人选了 DataBase 这门课
val lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
val pare = lines.filter(row=>row.split(",")(1)=="DataBase").map(row=>(row.split(",")(1),1))
val accum = sc.longAccumulator("My Accumulator")
pare.values.foreach(x => accum.add(x))
accum.value
res19: Long = 126
DateFrame
源文件内容如下(包含 id,name,age),将数据复制保存到 ubuntu 系统/usr/local/spark 下, 命名为 employee.txt,实现从 RDD 转换得到 DataFrame,并按 id:1,name:Ella,age:36 的格式 打印出 DataFrame 的所有数据。请写出程序代码。
1,Ella,36
2,Bob,29
3,Jack,29
方法一:
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import spark.implicits._ object RDDtoDF { def main(args: Array[String]) { case class Employee(id:Long,name: String, age: Long) val employeeDF = spark.sparkContext.textFile("file:///usr/local/spark/employee.txt").map(_.split(",")).map(attributes => Employee(attributes(0).trim.toInt,attributes(1), attributes(2).trim.toInt)).toDF() employeeDF.createOrReplaceTempView("employee") val employeeRDD = spark.sql("select id,name,age from employee") employeeRDD.map(t => "id:"+t(0)+","+"name:"+t(1)+","+"age:"+t(2)).show() }
}
方法二:
import org.apache.spark.sql.types._import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Row object RDDtoDF { def main(args: Array[String]) { val employeeRDD =
spark.sparkContext.textFile("file:///usr/local/spark/employee.txt")
val schemaString = "id name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName,
StringType, nullable = true))
val schema = StructType(fields)
val rowRDD = employeeRDD.map(_.split(",")).map(attributes =>
Row(attributes(0).trim, attributes(1), attributes(2).trim))
val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results = spark.sql("SELECT id,name,age FROM employee")
results.map(t => "id:"+t(0)+","+"name:"+t(1)+","+"age:"+t(2)).show() }
}
{ “id”:1 ,“name”:" Ella",“age”:36 }
{ “id”:2,“name”:“Bob”,“age”:29 }
{ “id”:3 ,“name”:“Jack”,“age”:29 }
{ “id”:4 ,“name”:“Jim”,“age”:28 }
{ “id”:5 ,“name”:“Damon” }
{ “id”:5 ,“name”:“Damon” }
创建 DataFrame
scala> import org.apache.spark.sql.SparkSession
scala> val spark=SparkSession.builder().getOrCreate()
scala> import spark.implicits._
scala> val df = spark.read.json("file:///usr/local/spark/employee.json")
(1) 查询 DataFrame 的所有数据
答案:
scala> df.show()
(2) 查询所有数据,并去除重复的数据
答案:
scala> df.distinct().show()
(3) 查询所有数据,打印时去除 id 字段
答案:
scala> df.drop("id").show()
(4) 筛选 age>20 的记录
答案:
scala> df.filter(df("age") > 30 ).show()
(5) 将数据按 name 分组
答案:
scala> df.groupBy("name").count().show()
(6) 将数据按 name 升序排列
答案:
scala> df.sort(df("name").asc).show()
(7) 取出前 3 行数据
答案:
scala> df.take(3) 或 scala> df.head(3)
(8) 查询所有记录的 name 列,并为其取别名为 username
答案:
scala> df.select(df("name").as("username")).show()
(9) 查询年龄 age 的平均值
答案:
scala> df.agg("age"->"avg")
(10) 查询年龄 age 的最小值
答案:
scala> df.agg("age"->"min")
编程实现利用 DataFrame 读写 MySQL 的数据
(1) 在 MySQL 数据库中新建数据库 sparktest,再建表 employee,包含下列两行数据;
表 1 employee 表原有数据
id name gender age
1 Alice F 22 2 John M 25
假设当前目录为/usr/local/spark/mycode/testmysql,在当前目录下新建一个目录 mkdir -p src/main/scala , 然 后 在 目 录 /usr/local/spark/mycode/testmysql/src/main/scala 下 新 建 一 个testmysql.scala
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row object TestMySQL { def main(args: Array[String]) { val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1).trim, p(2).trim,p(3).toInt))
val employeeDF = spark.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "hadoop")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest",
sparktest.employee", prop)
val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "hadoop").load()
jdbcDF.agg("age" -> "max", "age" -> "sum") }
}
启动spark-shell
cd /usr/local/spark
./bin/spark-shell
退出spark-shell
:quit
集群里安装Spark
sudo tar -zxf ~/下载/spark-2.1.0-bin-without-hadoop.tgz -C /usr/local
cd /usr/local
sudo mv ./spark-2.1.0-bin-without-hadoop ./spark
sudo chow -R hadoop:hadoop ./spark
RDD转换操作API
| 操作 | 含义 |
|---|---|
| filter(func) | 帅选出满足函数func的元素,并返回一个新的数据集 |
| map(func) | 将每个元素传入到函数func中,并将结构返回一个新的数据集 |
| flatMap(func) | 与上类似,但每个元素都可以映射到0个或多个输出结果 |
| groupByKey() | 应用于(K,V)键值对数据集时,返回一个(K,Iterable)形式的数据集 |
| reduceByKey(func) | 应用于(K,V)键值对数据集时,返回一个新的(K,V)形式的数据集,V是每个Key传递到函数func中的聚合后的结果。 |
RDD行动操作API
| 操作 | 含义 |
|---|---|
| count() | 返回数据集中的元素个数 |
| collect() | 以数组的形式返回数据集中的所有元素 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 以数据的形式返回数据集中的前n个元素 |
| reduce(func) | 通过函数func聚合数据集中的元素 |
| foreache(func) | 将数据集中的每个元素传递到函数func中运行 |
相关文章:

spark代码
RDD Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 该系总共有多少学生; val lines sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt") val par lines.map(ro…...
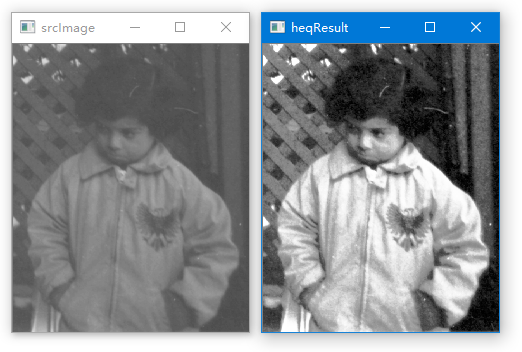
利用OpenCV的函数equalizeHist()对图像作直方图均衡化处理
如果一幅图像的灰度值集中在某个比较窄的区域,则图像的对比度会显得比较小,不便于对图像的分析和处理。 图像的直方图均衡化可以实现将原图像的灰度值范围扩大,这样图像的对比度就得到了提高,从而方便对图像进行后续的分析和处理…...

星河智联Android开发
背景:朋友内推,过了一周约面。本人 2019年毕业 20230208一面 1.自我介绍 2.为啥换工作 3.项目经历(中控面板、智能音箱、语音问的比较细) 4.问题 Handler机制原理?了解同步和异步消息吗?View事件分发…...

【C++】关联式容器——map和set的使用
文章目录一、关联式容器二、键值对三、树形结构的关联式容器1.set2.multiset3.map4.multimap四、题目练习一、关联式容器 序列式容器📕:已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C11)等,这些容器统称为…...

Promise的实现原理
作用:异步问题同步化解决方案,解决回调地狱、链式操作原理: 状态:pending、fufilled reject构造函数传入一个函数,resolve进入then,reject进入catch静态方法:resolve reject all any react ne…...
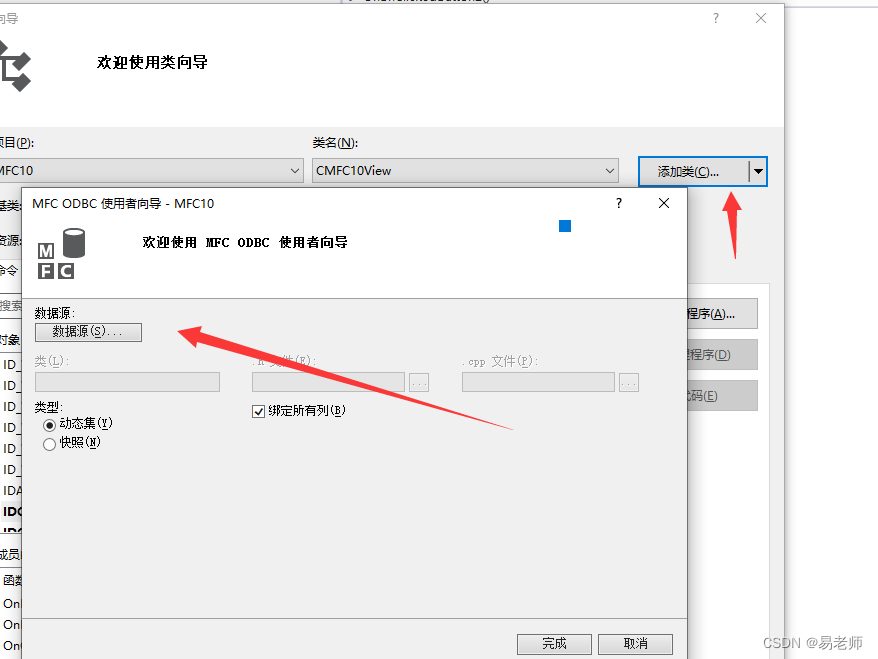
【MFC】数据库操作——ODBC(20)
ODBC:开放式数据库连接,是为解决异构数据库(不同数据库采用的数据存储方法不同)共享而产生的。ODBC API相对来说非常复杂,这里介绍MFC的ODBC类。 添加ODBC用户DSN 首先,在计算机中添加用户DSN:(WIN10下&a…...
旺店通与金蝶云星空对接集成采购入库单接口
旺店通旗舰奇门与金蝶云星空对接集成采购入库单查询连通销售退货新增V1(12-采购入库单集成方案-P)数据源系统:旺店通旗舰奇门旺店通是北京掌上先机网络科技有限公司旗下品牌,国内的零售云服务提供商,基于云计算SaaS服务模式,以体系化解决方案…...
Linux基础-学会使用命令帮助
概述使用 whatis使用 man查看命令程序路径 which总结参考资料概述Linux 命令及其参数繁多,大多数人都是无法记住全部功能和具体参数意思的。在 linux 终端,面对命令不知道怎么用,或不记得命令的拼写及参数时,我们需要求助于系统的…...
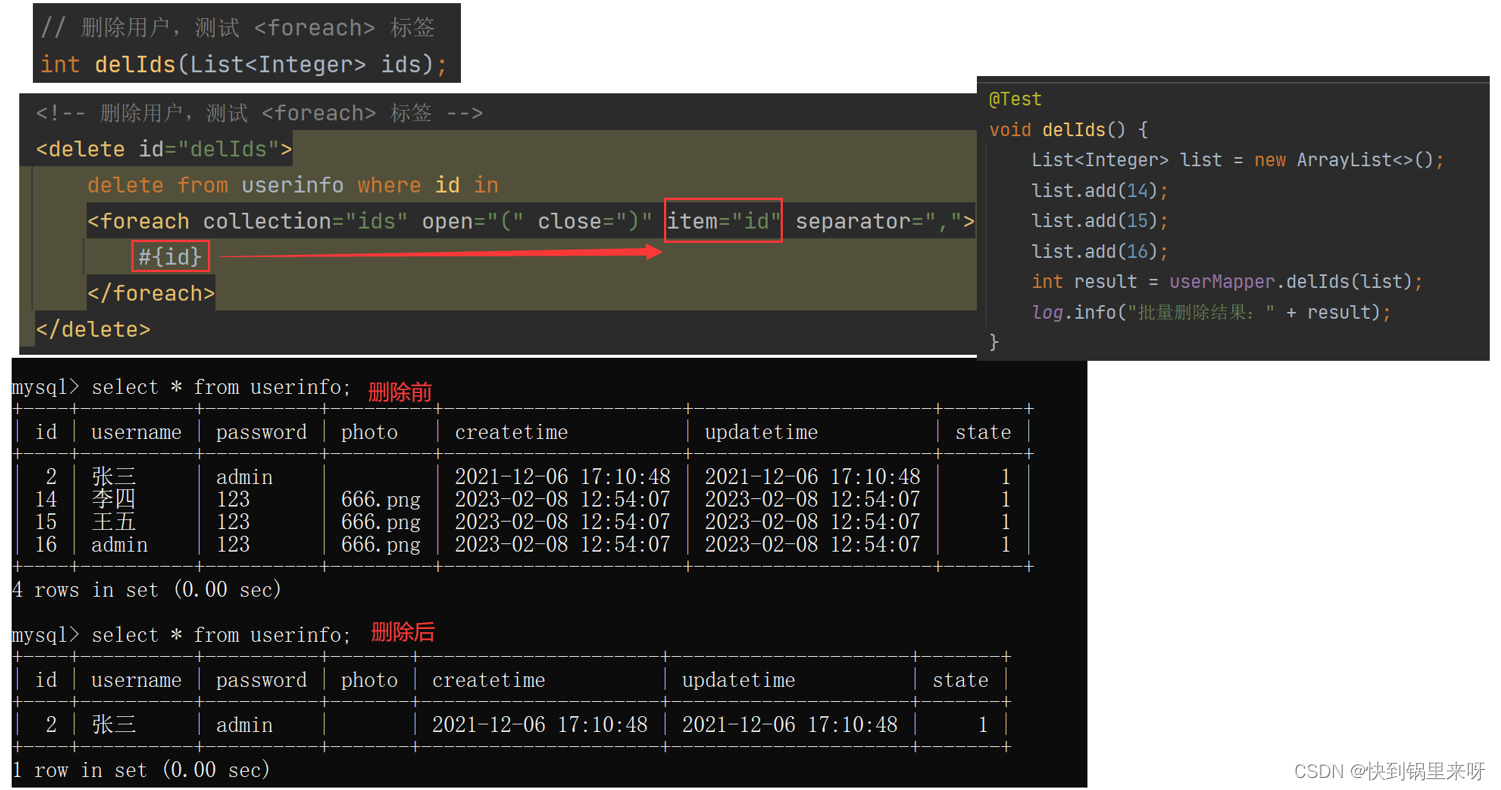
MyBatis 之四(动态SQL之 if、trim、where、set、foreach 标签)
文章目录动态 SQL1. if 标签2. trim 标签3. where 标签4. set 标签5. foreach 标签回顾一下,在上一篇 MyBatis 之三(查询操作 占位符#{} 与 ${}、like查询、resultMap、association、collection)中,学习了针对查询操作的相关知识点…...
 Practice 1006 Sign In and Sign Out)
PAT (Advanced Level) Practice 1006 Sign In and Sign Out
1006 Sign In and Sign Out题目翻译代码分数 25作者 CHEN, Yue单位 浙江大学At the beginning of every day, the first person who signs in the computer room will unlock the door, and the last one who signs out will lock the door. Given the records of signing in’…...

Android入门第64天-MVVM下瀑布流界面的完美实现-使用RecyclerView
前言 网上充满着不完善的基于RecyclerView的瀑布流实现,要么根本是错的、要么就是只知其一不知其二、要么就是一充诉了一堆无用代码、要么用的是古老的MVC设计模式。 一个真正的、用户体验类似于淘宝、抖音的瀑布流怎么实现目前基本为无解。因为本人正好自己空闲时也…...
Windows PowerShell中成功进入conda虚拟环境
本人操作系统是Windows10(输入命令cmd或在运运行中输入winver查看)在cmd命令行中大家都很熟悉,很方便进入到指定创建了的虚拟环境中,那么在PowerShell中怎么进入呢?比如在VSCode中的TERMINAL使用的是PowerShell&#x…...

【C++】类与对象理解和学习(中)
专栏放在【C知识总结】,会持续更新,期待支持🌹六大默认成员函数前言每个类中都含有六大默认成员函数,也就是说,即使这个类是个空类,里面什么都没有写,但是编译器依然会自动生成六个默认成员函数…...
大英复习单词和翻译)
每日英语学习(11)大英复习单词和翻译
2023.2.20 单词 1.contemplate 思考、沉思 2.spark 激起 3.venture 冒险 4.stunning 极好的 5.dictate 影响 6.diplomatic 外交的 7.vicious 恶性的 8.premier 首要的 9.endeavor 努力 10.bypass 绕过 11.handicaps 不利因素 12.vulnerable 脆弱的 13.temperament 气质、性格…...

x79主板M.2无法识别固态硬盘
问题描述: 这几天在装电脑,买了块M.2接口固态硬盘。装上去始终无法读取到硬盘,一开始以为是寨板Bios问题不支持M.2的设备。更新了最新的BIOS然后还是没有识别出来,然而将日常用的电脑PM510硬盘装上发现可以识别,而且日常用电脑也…...

配置Tomcat性能优化
配置Tomcat性能优化 📒博客主页: 微笑的段嘉许博客主页 💻微信公众号:微笑的段嘉许 🎉欢迎关注🔎点赞👍收藏⭐留言📝 📌本文由微笑的段嘉许原创! Ǵ…...
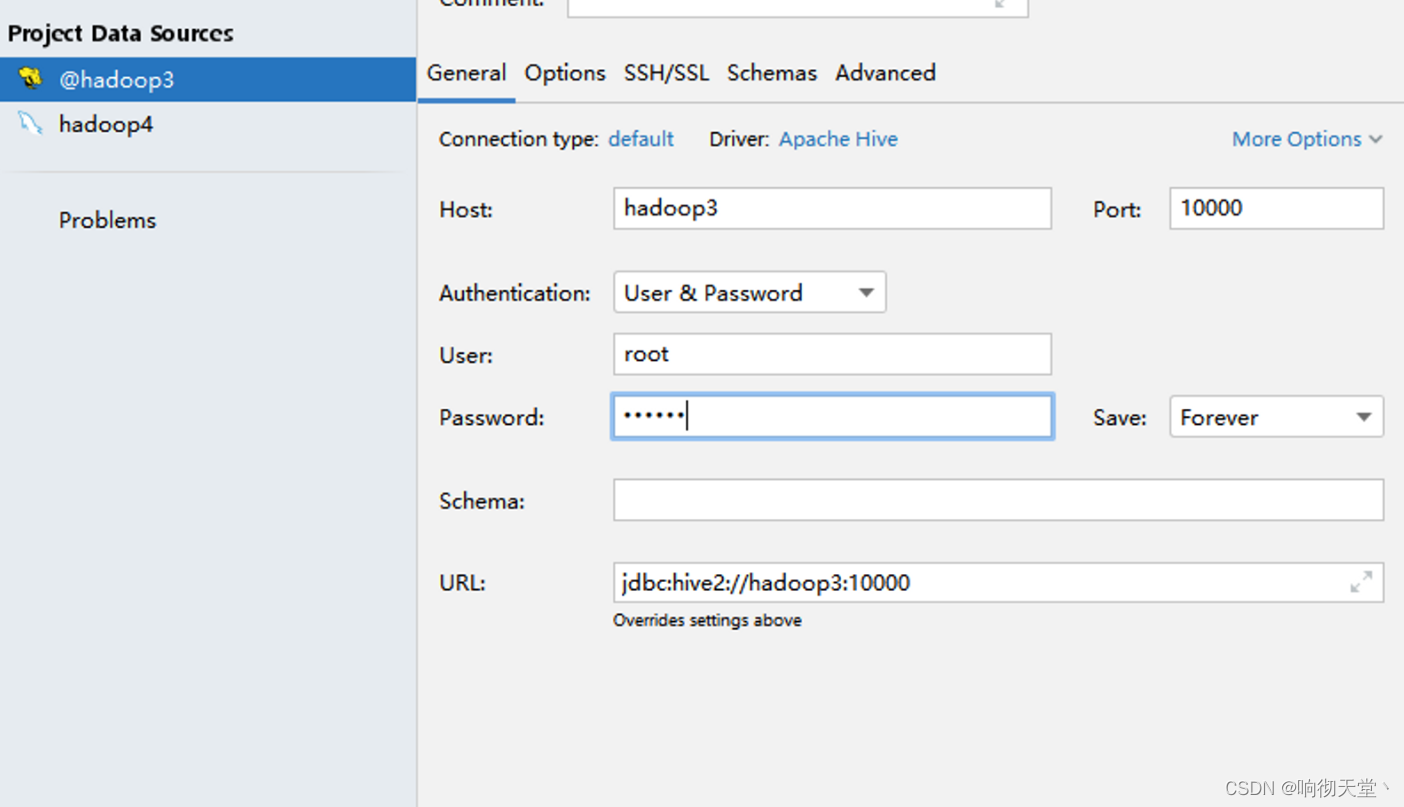
Hive3 安装方式详解,datagrid自定义驱动连接hive
1 Hive的安装方式 hive的安装一共有三种方式:内嵌模式、本地模式、远程模式。 元数据服务(metastore)作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接…...
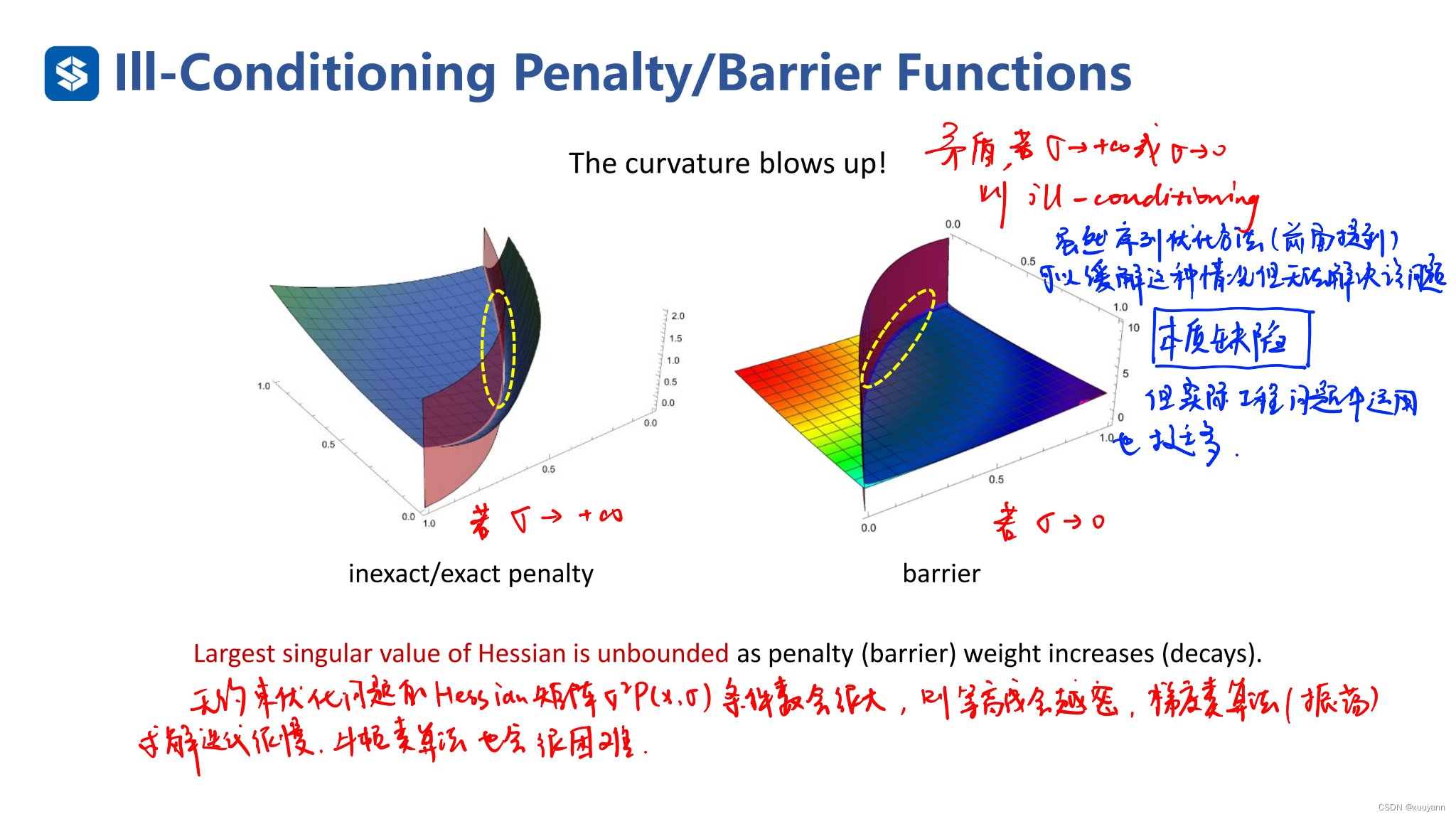
约束优化:约束优化的三种序列无约束优化方法(罚函数法)
文章目录约束优化:约束优化的三种序列无约束优化方法(罚函数法)外点罚函数法L2-罚函数法:非精确算法对于等式约束对于不等式约束L1-罚函数法:精确算法内点罚函数法:障碍函数法参考文献约束优化:…...

你真的会做APP UI自动化测试吗?我敢打赌百分之九十的人都不知道这个思路
目录 前言 一,开发语言选择 二,UI测试框架选择 1,Appium 2,Airtest 3,选择框架 三,单元测试框架选择 四,测试环境搭建 1,测试电脑选择 2,测试手机选择 3&#…...
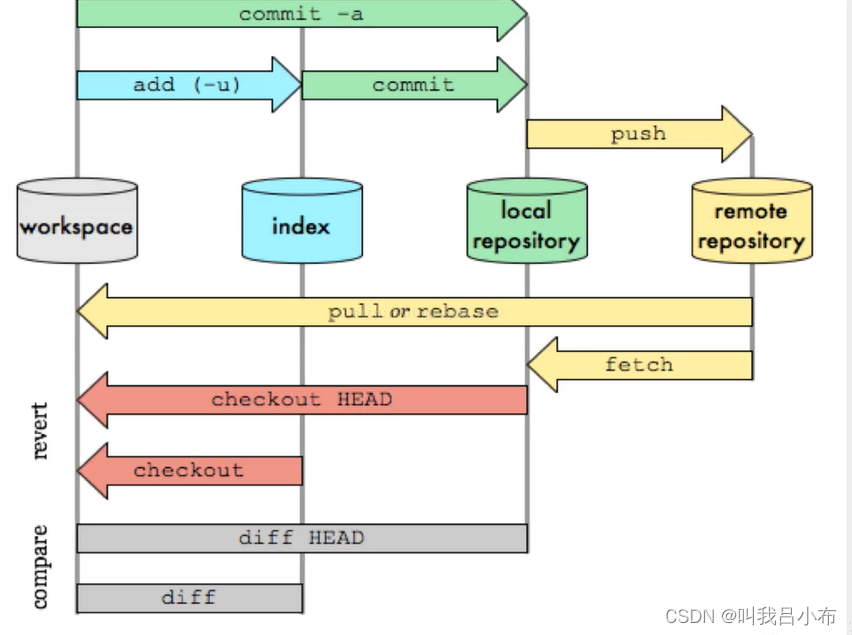
GIT:【基础三】Git工作核心原理
目录 一、Git本地四个工作区域 二、Git提交文件流程 一、Git本地四个工作区域 工作目录(Working Directory):电脑上存放开发代码的地方。暂存区(Stage/Index):用于l临时存放改动的文件,本质上只是一个文件,保存即将提交到文件列…...

KSA工具实战:5分钟搞定内网穿透,无需公网IP也能远程办公
KSA工具实战:5分钟搞定内网穿透,无需公网IP也能远程办公 远程办公已成为现代职场的新常态,但许多人在家访问公司内网资源时,常被复杂的网络配置和公网IP需求劝退。想象一下,周五晚上突然需要调取公司服务器上的方案文件…...

高效掌控Mem Reduct:智能多语言界面切换完全指南
高效掌控Mem Reduct:智能多语言界面切换完全指南 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 你是否曾…...

效率倍增:用快马平台自动化测试openclaw多模型性能
最近在开发机器人抓取算法时,经常需要对比不同模型的性能表现。传统方法需要手动切换模型、反复运行测试脚本,效率实在太低。经过一番摸索,我在InsCode(快马)平台上搭建了一个自动化测试工具,效果提升显著,分享下具体实…...

专业级PDF自动化解决方案:如何构建高效文档工作流
专业级PDF自动化解决方案:如何构建高效文档工作流 【免费下载链接】clawPDF Open Source Virtual (Network) Printer for Windows that allows you to create PDFs, OCR text, and print images, with advanced features usually available only in enterprise solu…...

Win11Debloat完全指南:3步打造纯净高效的Windows 11系统
Win11Debloat完全指南:3步打造纯净高效的Windows 11系统 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

拒绝文献堆砌:如何打造逻辑严密的基金立项依据?
在基金申报的征途中,许多科研人员常陷入一个误区:认为立项依据就是文献的简单叠加。于是,我们花费大量时间搜集资料,将数十篇参考文献的摘要机械地罗列在一起。然而,这样的做法往往导致一个致命的弱点:缺乏…...

告别手动造数据!用JMeter JSR223预处理程序+Groovy脚本,5分钟搞定接口签名和AES加密
告别手动造数据!用JMeter JSR223预处理程序Groovy脚本,5分钟搞定接口签名和AES加密 性能测试工程师最头疼的莫过于每次执行测试前,都要手动计算接口签名、拼接参数、加密敏感数据。这种重复性工作不仅耗时耗力,还容易出错。想象一…...

Qt for Android串口通信实战:usb-serial-for-android库的完整集成指南
Qt for Android串口通信实战:usb-serial-for-android库的完整集成指南 在工业控制、物联网设备调试等场景中,串口通信仍然是设备间可靠数据传输的首选方案。当我们需要在Android设备上通过Qt框架实现串口通信时,却发现Qt官方并未提供原生的A…...

Cursor AI破解免费VIP 2025终极完整教程:轻松解除试用限制,畅享专业功能
Cursor AI破解免费VIP 2025终极完整教程:轻松解除试用限制,畅享专业功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro …...
