PV3D: A 3D GENERATIVE MODEL FOR PORTRAITVIDEO GENERATION 【2023 ICLR】
ICLR:International Conference on Learning Representations
CCF-A 国际表征学习大会:深度学习的顶级会议
生成对抗网络(GANs)的最新进展已经证明了生成令人惊叹的逼真肖像图像的能力。虽然之前的一些工作已经将这种图像gan应用于无条件的2D人像视频生成和静态的3D人像合成,但很少有工作成功地将gan扩展到生成3D感知人像视频。在这项工作中,我们提出了PV3D,这是第一个可以合成多视图一致人像视频的生成框架。具体来说,我们的方法通过推广3D隐式神经表示来模拟时空空间,将最近的静态3D感知图像GAN扩展到视频领域。为了将运动动力学引入到生成过程中,我们开发了一个运动生成器,通过叠加多个运动层,通过调制卷积合成运动特征。为了减轻由摄像机/人体运动引起的运动歧义,我们提出了一种简单而有效的PV3D摄像机条件策略,实现了时间和多视图一致的视频生成。此外,PV3D引入了两个判别器来正则化空间和时间域,以确保生成的人像视频的可信性。这些精心设计使PV3D能够生成具有高质量外观和几何形状的3d感知运动逼真的人像视频,显着优于先前的作品。因此,PV3D能够支持下游应用程序,如静态肖像动画和视图一致的运动编辑。代码和模型可在https://showlab.github.io/pv3d上获得。
PV3D的github代码和模型![]() https://showlab.github.io/pv3d我们的目标是:通过只学习2D单眼视频来减轻创建高质量3D感知人像视频的工作量,而不需要任何3D或多视图注释
https://showlab.github.io/pv3d我们的目标是:通过只学习2D单眼视频来减轻创建高质量3D感知人像视频的工作量,而不需要任何3D或多视图注释

最近3d感知肖像生成方法通过整合内隐神经表征INRs可以产生逼真的多视图一致的结果,但是这些方法仅限于静态人像生成,很难扩展到人像视频生成:
1)如何在生成框架中有效地建模三维动态人体肖像仍然不清楚;
2)在没有三维监督的情况下学习动态三维几何是高度受限的;
3)相机运动和人类运动/表情之间的纠缠给训练过程带来了模糊性。
为此,本篇文章提出了一种3D人像视频生成模型(PV3D),这是第一种可以在纯粹从单目2D视频中学习的情况下生成具有多种动作的高质量3D人像视频的方法。PV3D通过将3D三平面表示(Chan et al, 2022)扩展到时空域来实现3D人像视频建模。在本文中,我们综合分析了各种设计选择,得出了一套新颖的设计,包括将潜在代码分解为外观和运动组件,基于时间三平面的运动生成器,适当的摄像机姿态序列调理和摄像机条件视频鉴别器,可以显着提高3D人像视频生成的视频保真度和几何质量。
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio
Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d
generative adversarial networks. In CVPR, 2022.
EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks![]() https://nvlabs.github.io/eg3d/
https://nvlabs.github.io/eg3d/
As shown in Figure 1, despite being trained from only monocular 2D videos, PV3D can generate a large variety of photo-realistic portrait videos under arbitrary viewpoints with diverse motions and high-quality 3D geometry. Comprehensive experiments on various datasets including VoxCeleb (Nagrani et al, 2017), CelebV-HQ (Zhu et al, 2022) and TalkingHead-1KH (Wang et al, 2021a) well demonstrate the superiority of PV3D over previous state-of-the-art methods, both qualitatively and quantitatively. Notably, it achieves 29.1 FVD on VoxCeleb, improving upon a concurrent work 3DVidGen (Bahmani et al, 2022) by 55.6%. PV3D can also generate high-quality 3D geometry, achieving the best multi-view identity similarity and warping error across all datasets.
Our contributions are three-fold. 1) To our best knowledge, PV3D is the first method that is capable to generate a large variety of 3D-aware portrait videos with high-quality appearance, motions, and geometry. 2) We propose a novel temporal tri-plane based video generation framework that can synthesize 3D-aware portrait videos by learning from 2D videos only. 3) We demonstrate state-ofthe-art 3D-aware portrait video generation on three datasets. Moreover, our PV3D supports several downstream applications, i.e., static image animation, monocular video reconstruction, and multiview consistent motion editing.
如图1所示,尽管PV3D仅从单眼2D视频进行训练,但它可以在任意视点下生成大量具有多种运动和高质量3D几何形状的逼真人像视频。在各种数据集上的综合实验,包括VoxCeleb (Nagrani等人,2017),CelebV-HQ (Zhu等人,2022)和TalkingHead-1KH (Wang等人,2021a),都很好地证明了PV3D在定性和定量上优于以前最先进的方法。值得注意的是,它在VoxCeleb上实现了29.1 FVD,比并发工作3DVidGen (Bahmani et al, 2022)提高了55.6%。PV3D还可以生成高质量的3D几何图形,在所有数据集上实现最佳的多视图识别相似性和翘曲误差。
我们的贡献有三方面。1)据我们所知,PV3D是第一种能够生成各种具有高质量外观,运动和几何形状的3d感知人像视频的方法。2)提出了一种新的基于时间三平面的视频生成框架,该框架仅通过学习2D视频即可合成3d感知人像视频。3)我们在三个数据集上展示了最先进的3d感知人像视频生成。此外,我们的PV3D支持几个下游应用,即静态图像动画,单目视频重建和多视图一致的运动编辑。
DATASET PREPROCESSING
VoxCeleb (Nagrani et al, 2017; Chung et al, 2018) is an audio-visual speaker verification dataset containing interview videos for more than 7,000 speakers. It provides speaker labels for each video clip. For each speaker, we sample two video clips that have the highest video resolutions.
CelebV-HQ (Zhu et al, 2022) is a large-scale face video dataset that provides high-quality video clips involving 15,653 identities. Compared with VoxCeleb, it contains diverse lighting conditions.
TalkingHead-1KH (Wang et al, 2021a) consists of talking head videos extracted from 2,900 long video conferences.
VoxCeleb (Nagrani et al, 2017;Chung等人,2018)是一个视听演讲者验证数据集,包含超过7000名演讲者的采访视频。它为每个视频剪辑提供扬声器标签。对于每个讲话者,我们采样两个具有最高视频分辨率的视频剪辑。
CelebV-HQ (Zhu et al, 2022)是一个大规模的人脸视频数据集,提供了涉及15,653个身份的高质量视频剪辑。与VoxCeleb相比,它包含了多样化的照明条件。
TalkingHead-1KH (Wang et al ., 2021a)由从2900个长视频会议中提取的talking head视频组成。
EVALUATION METRICS
FVD: Frechet Video Distance 视频距离
ID: Multi-view Identity Consistency 多视图身份一致性
CD: Chamfer Distance 倒角距离 使用正面和侧面点云之间的倒角距离来测量3D几何的多视图一致性
WE: Multi-view Image Warping Errors 多视图图像扭曲错误

我们的PV3D有几个限制:
1)PV3D是在最多包含48帧的视频剪辑上训练和测试的。该模型对长期(分钟级)动态建模的能力尚不清楚。
2) 2D视频数据集质量无法与FFHQ、CelebA等图像数据集相比。我们的模型具有灵活的架构,可以支持图像数据集的预训练或联合训练,然而这种增强策略尚未被探索,尽管它很有前途和意义。对于未来的工作,我们将探索用更适合3D视频生成的新型3D表示建模长期动态,并利用高质量的图像数据集进行数据增强。
相关文章:
PV3D: A 3D GENERATIVE MODEL FOR PORTRAITVIDEO GENERATION 【2023 ICLR】
ICLR:International Conference on Learning Representations CCF-A 国际表征学习大会:深度学习的顶级会议 生成对抗网络(GANs)的最新进展已经证明了生成令人惊叹的逼真肖像图像的能力。虽然之前的一些工作已经将这种图像gan应用于无条件的2D人像视频生…...

Apache BeanUtils工具介绍
beanutils,顾名思义,是java bean的一个工具类,可以帮助我们方便的读取(get)和设置(set)bean属性值、动态定义和访问bean属性;细心的话,会发现其实JDK已经提供了一个java.beans包,同样可以实现以上功能&…...

java 原子操作 笔记
目录 java 变量原子操作 java byte[] 原子操作 java 变量原子操作 public class Counter {private int count 0;public synchronized void increment() {count;}public synchronized int getCount() {return count;} } java byte[] 原子操作 public class SharedArray {pr…...

什么是线程安全性问题?Java中有哪些常用的同步机制来解决线程安全性问题?
线程安全性问题是指在多线程环境下,多个线程同时访问和修改共享数据时可能引发的数据不一致、竞态条件和并发访问异常等问题。线程安全性问题的主要原因是多个线程之间的并发执行,导致数据的访问和修改顺序不确定,从而产生不一致的结果。 为…...
Gitlab 安装全流程
Version:gitlab-ce:16.2.4-ce.0 简介 Gitlab 是一个开源的 Git 代码仓库系统,可以实现自托管的 Github 项目,即用于构建私有的代码托管平台和项目管理系统。系统基于 Ruby on Rails 开发,速度快、安全稳定。它拥有与 Github 类似…...
pdf转word最简单方法~
pdf转word最简单方法!pdf转word最简单方法我们都知道,PDF文件是一种只读文件格式,无法按照需求对PDF文件进行更改与编辑,从而影响到了PDF文件的使用。所以,我们需要将PDF文件转换为word文档,以此来保证文件…...

Android 9.0 WiFi 扫描结果上报和获取流程
本文是对wifi扫描结果上报和获取过程的java层代码流程梳理总结。 我们先分析扫描成功的上报和获取过程。 一、WiFi扫描成功的上报和获取过程 WiFi扫描成功的上报和获取大致是由三条不连贯流程组成的,分别是通知framework和WifiTracker获取扫描结果以及应用主动获取…...

Java 项目日志实例:Log4j2
点击下方关注我,然后右上角点击...“设为星标”,就能第一时间收到更新推送啦~~~ Apache Log4j 2 是对 Log4j 的升级,与其前身 Log4j 1.x 相比有了显着的改进,并提供了许多 Logback 可用的改进,同时支持 JCL 以及 SLF4J…...
)
Effective C++条款14——在资源管理类中小心coping行为(资源管理)
条款13导入这样的观念:“资源取得时机便是初始化时机”(Resource Acquisitionls Initialization; RAII),并以此作为“资源管理类”的脊柱,也描述了auto_ ptr和tr1::shared ptr如何将这个观念表现在 heap-based资源上。然而并非所有资源都是heap-based&am…...
【网络教程】如何创建/添加钉钉机器人以及如何获取机器人的Token/Secret
文章目录 创建钉钉机器人添加钉钉机器人获取机器人的Token/Secret相关网站创建钉钉机器人 这里以PC端的操作为例,按照如下操作进行 访问 钉钉开放平台选择机器人选项卡,点击右上角的创建应用,这里会有一个弹窗,我这里选择的是继续使用旧版,如图按照要求填写相关信息创建自…...
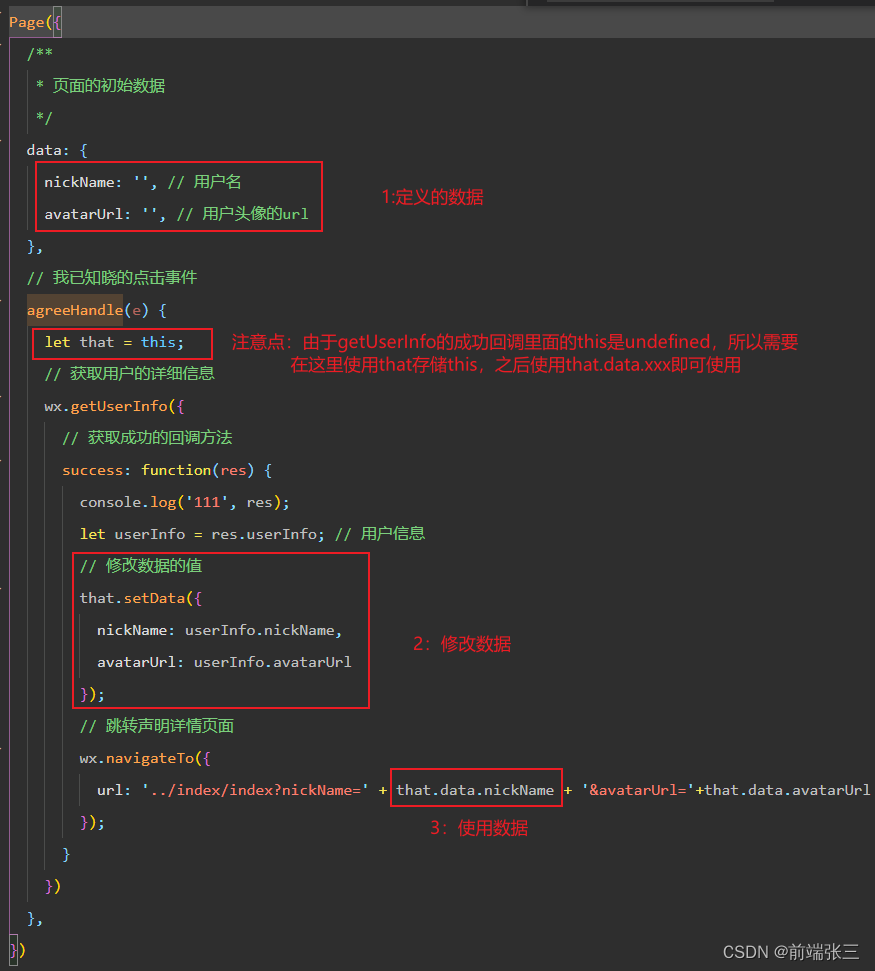
wx原生微信小程序入门常用总结
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、定义值和修改值1、定义值2、修改值(1)代码(2)代码说明(3)注意点 二、点击事件三、微…...
制作一个专属于安防监控业的小程序商城
随着科技的发展和人们生活水平的提高,安防监控设备在我们的日常生活中起到了越来越重要的作用。因此,建立一个安防监控设备商城小程序就变得尤为重要。下面将介绍如何建立这样一个小程序。 第一步,登录乔拓云平台后台,进入商城管理…...

基于java羽毛球馆管理系统设计与实现
摘 要 时代的变化速度实在超出人类的所料,21世纪,计算机已经发展到各行各业,各个地区,它的载体媒介-计算机,大众称之为的电脑,是一种特高速的科学仪器,比人类的脑袋要灵光无数倍,什么…...

安装elasticsearch8.9.0及修改配置
安装es流程 打开文件,添加以下行 vim /etc/sysctl.conf vm.max_map_count=262144重启生效 sysctl -p创建用户 useradd es passwd es修改es目录所属用户 chown -R es:es /opt/elasticsearch-8.9.0如果内存不足,可以修改es的初始化内存和Max内存,修改文件/opt/elasticsearch-8…...
如何构建高效的接口自动化测试框架?看完你就会了...
在选择接口测试自动化框架时,需要根据团队的技术栈和项目需求来综合考虑。对于测试团队来说,使用Python相关的测试框架更为便捷。无论选择哪种框架,重要的是确保 框架功能完备,易于维护和扩展,提高测试效率和准确性。今…...

53 | 金融行业股票销售指标分析
金融行业股票销售指标分析 引言: 金融行业中的股票销售指标分析是评估股票市场表现、投资者行为以及交易平台效果的重要手段。通过深入分析关键的销售指标,投资者、金融机构和交易平台可以更好地了解市场趋势,作出明智的投资决策,优化交易策略。本文将探讨金融行业股票销售…...

qiuzhiji1
前言:记录一下毕业后的求职历程 背景:18级 湖北理工学院计算机学院(黄石) 网络工程 本文初次撰写于2023年8月17日,正处于离职找工作的空档期,部分经历可能记不清了。所有内容尽量保证了客观,主要是分享一下自己的经历,顺带锻炼文字能力。 文章会不定期更新,较新的日期会…...
使用VisualStudio制作上位机(二)
文章目录 使用VisualStudio制作上位机(二)第三部分:GUI内部函数设计使用VisualStudio制作上位机(二) Author:YAL 第三部分:GUI内部函数设计 事件添加 给窗体或窗体按钮相关的操作添加事件有两种方式,事件的名字直白的表面了这是什么事件。 直接双击界面,自动生成窗…...
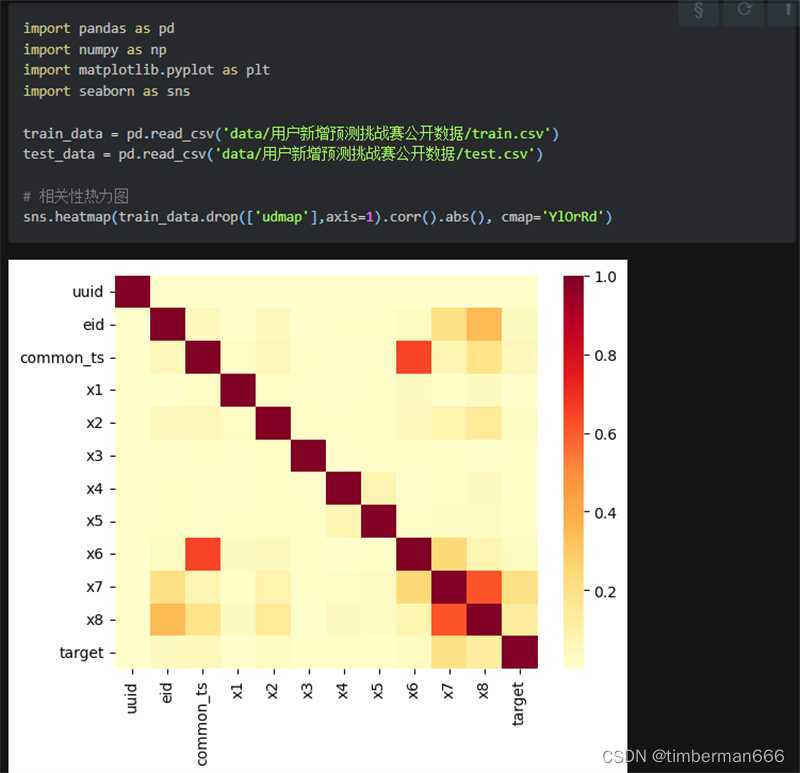
Datawhale AI夏令营 - 用户新增预测挑战赛 | 学习笔记
数据分析与可视化 为了拟合出更好的结果就要了解训练数据之间的相互关系,进行数据分析是必不可少的一步 导入必要的库 # 导入库 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns pandas库是一个强大的分析结构化…...
卡片开发AbilityStage组件容器)
HarmonyOS/OpenHarmony(Stage模型)卡片开发AbilityStage组件容器
AbilityStage是一个Module级别的组件容器,应用的HAP在首次加载时会创建一个AbilityStage实例,可以对该Module进行初始化等操作。 AbilityStage与Module一一对应,即一个Module拥有一个AbilityStage。 DevEco Studio默认工程中未自动生成Abilit…...

从Nautilus案看专利权利要求撰写:如何避免模糊性陷阱
1. 专利权利要求“模糊性”的边界:从Nautilus案看撰写核心 在科技行业,尤其是半导体、硬件和软件开发领域,专利是保护创新、构筑商业壁垒的生命线。但你是否想过,你或你的公司赖以生存的那份专利文件,其核心——权利要…...

贾子理论体系:公理化东方智慧与现代科学工程化的认知范式
贾子理论体系:公理化东方智慧与现代科学工程化的认知范式摘要 贾子(本名贾龙栋,笔名Kucius)于2025–2026年间构建以“1-2-3-4-5”公理架构为核心的跨学科认知体系,涵盖思想主权元公理、两大规律、三大定律、四大支柱与…...
)
保姆级教程:用Sigrity PowerSI提取5GHz内单端S参数(附DDR4仿真实例)
从零掌握Sigrity PowerSI:5GHz单端S参数提取与DDR4实战解析 在高速PCB设计中,信号完整性问题往往成为工程师的"隐形杀手"。当DDR4内存接口速率突破2400MHz时,传统时域分析方法已难以捕捉信号在传输过程中的微妙变化。散射参数&…...

静态前端项目实战:从营销页到现代化门户的架构与实现
1. 项目概述:一个纯粹的静态前端项目最近在GitHub上看到了一个名为“Vibe Code”的项目,它的README写得非常漂亮,充满了各种炫酷的特性介绍,比如支持Claude Code、OpenAI Codex等AI编程助手,还有深色/亮色主题切换、多…...

QT实战:利用QAxObject与QAxWidget实现Office文档自动化,从数据填充到格式定制
1. 为什么需要Office文档自动化? 在企业日常运营中,文档处理是绕不开的环节。我见过太多同事每天花几个小时手动复制粘贴数据到Word报告和Excel表格里,不仅效率低下,还容易出错。想象一下,财务部门每月要生成上百份报…...

5分钟上手Sticky:Linux桌面终极便签管理工具完全指南
5分钟上手Sticky:Linux桌面终极便签管理工具完全指南 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 你是否厌倦了在电脑桌面上寻找重要信息的混乱体验?是否曾因为忘记…...

基于LLM的MBTI人格模拟对话实验:从系统设计到工程实践
1. 项目概述:当MBTI遇上AI,一次关于人格的深度对话实验最近在GitHub上看到一个挺有意思的项目,叫“Kali-Hac/ChatGPT-MBTI”。光看名字,你可能觉得这又是一个用ChatGPT玩MBTI性格测试的简单脚本。但当我真正clone下来,…...

AnyFlip下载器:3分钟将在线翻页电子书变为永久PDF收藏
AnyFlip下载器:3分钟将在线翻页电子书变为永久PDF收藏 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否曾在AnyFlip网站上发现一本精彩的电子书,想要…...

Proxmox VE – 修复 LVM Thin Pool “pve/data” 激活失败
逐步诊断与恢复操作指南适用范围:PVE 宿主机,LVM thin pool pve/data 状态异常,错误信息: TASK ERROR: activating LV pve/data failed: Check of pool pve/data failed (status:1). Manual repair required! 风险提示:…...

ARM Cortex-R52 GIC架构详解与中断管理实践
1. Cortex-R52 GIC架构概述ARM Cortex-R52处理器采用的通用中断控制器(GIC)架构是嵌入式实时系统的中断管理核心。作为GICv2架构的实现,它通过硬件级的中断路由和优先级管理机制,为多核实时应用提供了确定性的中断响应能力。在汽车电子和工业控制领域&am…...