机器学习中XGBoost算法调参技巧
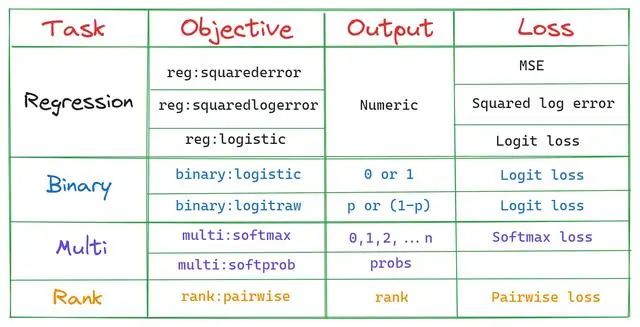
本文将详细解释XGBoost中十个最常用超参数的介绍,功能和值范围,及如何使用Optuna进行超参数调优。
对于XGBoost来说,默认的超参数是可以正常运行的,但是如果你想获得最佳的效果,那么就需要自行调整一些超参数来匹配你的数据,以下参数对于XGBoost非常重要:
-
eta -
num_boost_round -
max_depth -
subsample -
colsample_bytree -
gamma -
min_child_weight -
lambda -
alpha
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文文章由粉丝的分享、推荐,资料干货、资料分享、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
XGBoost的API有2种调用方法,一种是我们常见的原生API,一种是兼容Scikit-learn API的API,Scikit-learn API与Sklearn生态系统无缝集成。我们这里只关注原生API(也就是我们最常见的),但是这里提供一个列表,这样可以帮助你对比2个API参数,万一以后用到了呢:
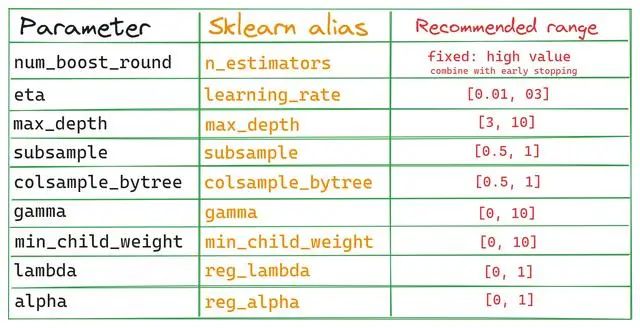
如果想使用Optuna以外的超参数调优工具,可以参考该表。下图是这些参数对之间的相互作用:

这些关系不是固定的,但是大概情况是上图的样子,因为有一些其他参数可能会对我们的者10个参数有额外的影响。
1、objective
这是我们模型的训练目标
最简单的解释是,这个参数指定我们模型要做的工作,也就是影响决策树的种类和损失函数。
2、num_boost_round - n_estimators
num_boost_round指定训练期间确定要生成的决策树(在XGBoost中通常称为基础学习器)的数量。默认值是100,但对于今天的大型数据集来说,这还远远不够。
增加参数可以生成更多的树,但随着模型变得更复杂,过度拟合的机会也会显著增加。
从Kaggle中学到的一个技巧是为num_boost_round设置一个高数值,比如100,000,并利用早停获得最佳版本。
在每个提升回合中,XGBoost会生成更多的决策树来提高前一个决策树的总体得分。这就是为什么它被称为boost。这个过程一直持续到num_boost_round轮询为止,不管是否比上一轮有所改进。
但是通过使用早停技术,我们可以在验证指标没有提高时停止训练,不仅节省时间,还能防止过拟合
有了这个技巧,我们甚至不需要调优num_boost_round。下面是它在代码中的样子:
# Define the rest of the paramsparams = {...}# Build the train/validation setsdtrain_final = xgb.DMatrix(X_train, label=y_train)dvalid_final = xgb.DMatrix(X_valid, label=y_valid)bst_final = xgb.train(params,dtrain_final,num_boost_round=100000 # Set a high numberevals=[(dvalid_final, "validation")],early_stopping_rounds=50, # Enable early stoppingverbose_eval=False,)上面的代码使XGBoost生成100k决策树,但是由于使用了早停,当验证分数在最后50轮中没有提高时,它将停止。一般情况下树的数量范围在5000-10000即可。控制num_boost_round也是影响训练过程运行时间的最大因素之一,因为更多的树需要更多的资源。
3、eta - learning_rate
在每一轮中,所有现有的树都会对给定的输入返回一个预测。例如,五棵树可能会返回以下对样本N的预测:
Tree 1: 0.57 Tree 2: 0.9 Tree 3: 4.25 Tree 4: 6.4 Tree 5: 2.1为了返回最终的预测,需要对这些输出进行汇总,但在此之前XGBoost使用一个称为eta或学习率的参数缩小或缩放它们。缩放后最终输出为:
output = eta * (0.57 + 0.9 + 4.25 + 6.4 + 2.1)大的学习率给集合中每棵树的贡献赋予了更大的权重,但这可能会导致过拟合/不稳定,会加快训练时间。而较低的学习率抑制了每棵树的贡献,使学习过程更慢但更健壮。这种学习率参数的正则化效应对复杂和有噪声的数据集特别有用。
学习率与num_boost_round、max_depth、subsample和colsample_bytree等其他参数呈反比关系。较低的学习率需要较高的这些参数值,反之亦然。但是一般情况下不必担心这些参数之间的相互作用,因为我们将使用自动调优找到最佳组合。
4、subsample和colsample_bytree
子抽样subsample它将更多的随机性引入到训练中,从而有助于对抗过拟合。
Subsample =0.7意味着集合中的每个决策树将在随机选择的70%可用数据上进行训练。值1.0表示将使用所有行(不进行子抽样)。
与subsample类似,也有colsample_bytree。顾名思义,colsample_bytree控制每个决策树将使用的特征的比例。Colsample_bytree =0.8使每个树使用每个树中随机80%的可用特征(列)。
调整这两个参数可以控制偏差和方差之间的权衡。使用较小的值降低了树之间的相关性,增加了集合中的多样性,有助于提高泛化和减少过拟合。
但是它们可能会引入更多的噪声,增加模型的偏差。而使用较大的值会增加树之间的相关性,降低多样性并可能导致过拟合。
5、max_depth
最大深度max_depth控制决策树在训练过程中可能达到的最大层次数。
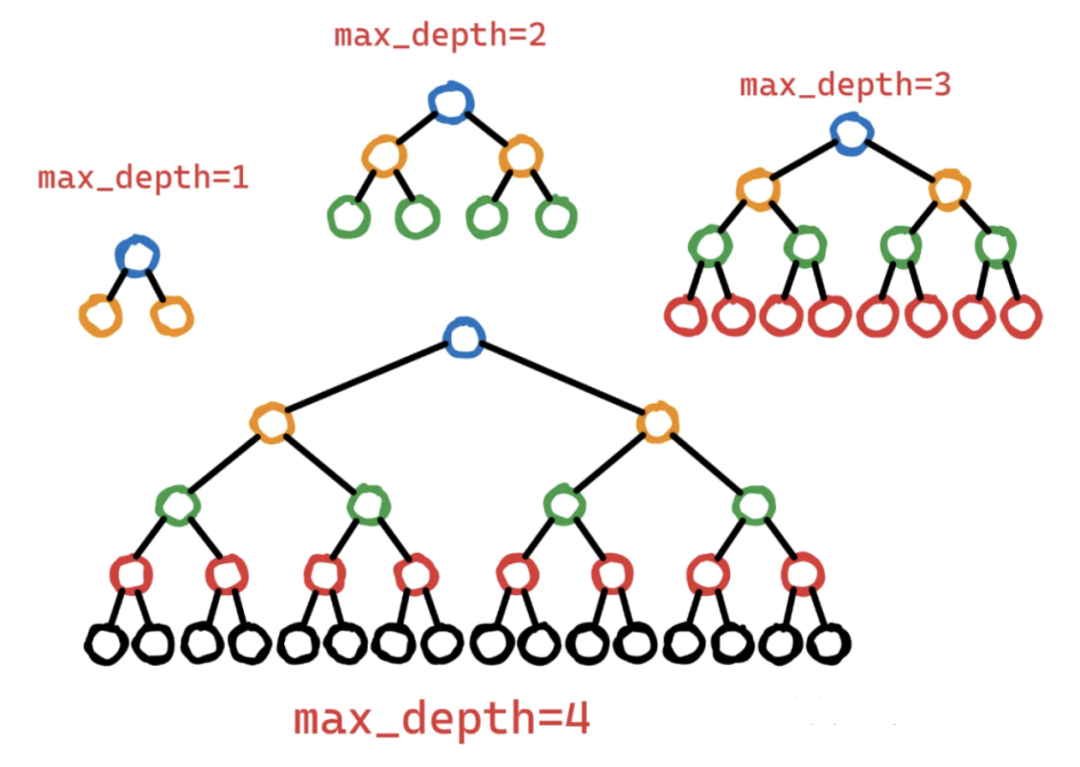
更深的树可以捕获特征之间更复杂的相互作用。但是更深的树也有更高的过拟合风险,因为它们可以记住训练数据中的噪声或不相关的模式。为了控制这种复杂性,可以限制max_depth,从而生成更浅、更简单的树,并捕获更通用的模式。
Max_depth数值可以很好地平衡了复杂性和泛化。
6、7、alpha,lambda
这两个参数一起说是因为alpha (L1)和lambda (L2)是两个帮助过拟合的正则化参数。
与其他正则化参数的区别在于,它们可以将不重要或不重要的特征的权重缩小到0(特别是alpha),从而获得具有更少特征的模型,从而降低复杂性。
alpha和lambda的效果可能受到max_depth、subsample和colsample_bytree等其他参数的影响。更高的alpha或lambda值可能需要调整其他参数来补偿增加的正则化。例如,较高的alpha值可能受益于较大的subsample值,因为这样可以保持模型多样性并防止欠拟合。
8、gamma
如果你读过XGBoost文档,它说gamma是:
在树的叶节点上进行进一步分区所需的最小损失减少。
英文原文:the minimum loss reduction required to make a further partition on a leaf node of the tree.
我觉得除了写这句话的人,其他人都看不懂。让我们看看它到底是什么,下面是一个两层决策树:
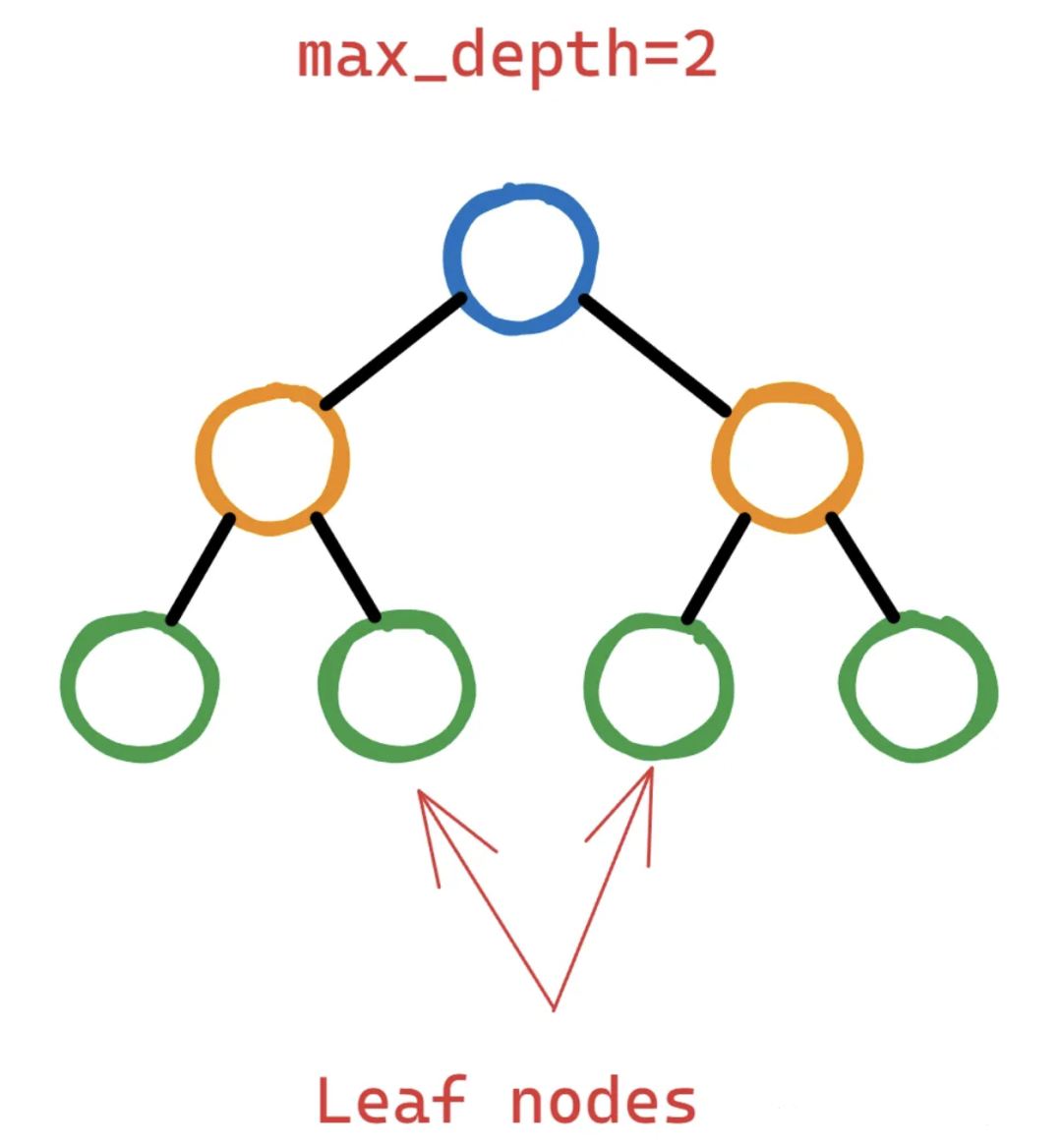
为了证明通过拆分叶节点向树中添加更多层是合理的,XGBoost应该计算出该操作能够显著降低损失函数。
但“显著是多少呢?”这就是gamma——它作为一个阈值来决定一个叶节点是否应该进一步分割。
如果损失函数的减少(通常称为增益)在潜在分裂后小于选择的伽马,则不执行分裂。这意味着叶节点将保持不变,并且树不会从该点开始生长。
所以调优的目标是找到导致损失函数最大减少的最佳分割,这意味着改进的模型性能。
9、min_child_weight
XGBoost从具有单个根节点的单个决策树开始初始训练过程。该节点包含所有训练实例(行)。然后随着 XGBoost 选择潜在的特征和分割标准最大程度地减少损失,更深的节点将包含越来越少的实例。
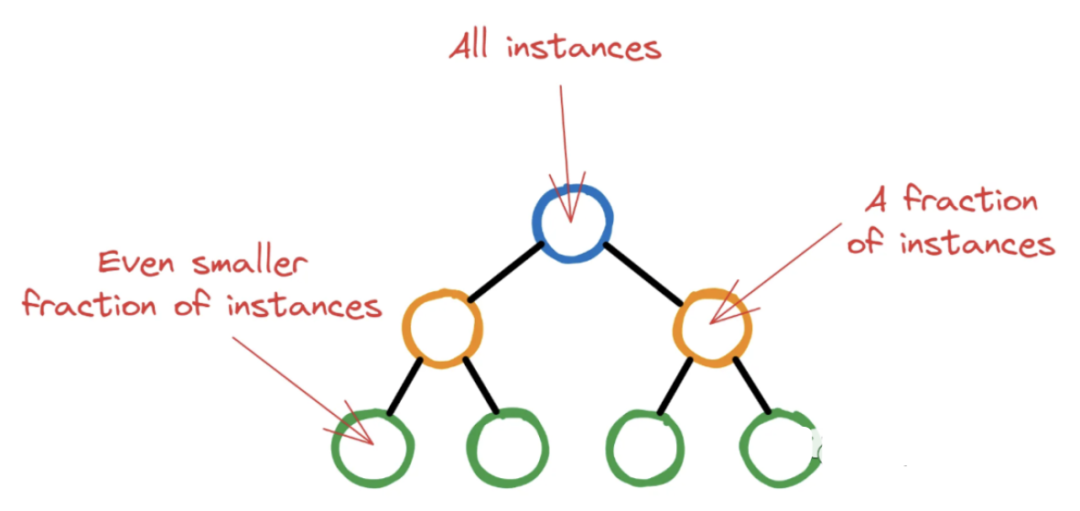
如果让XGBoost任意运行,树可能会长到最后节点中只有几个无关紧要的实例。这种情况是非常不可取的,因为这正是过度拟合的定义。
所以XGBoost为每个节点中继续分割的最小实例数设置一个阈值。通过对节点中的所有实例进行加权,并找到权重的总和,如果这个最终权重小于min_child_weight,则分裂停止,节点成为叶节点。
上面解释是对整个过程的最简化的版本,因为我们主要介绍他的概念。
总结
以上就是我们对这 10个重要的超参数的解释,如果你想更深入的了解仍有很多东西需要学习。所以建议给ChatGPT以下两个提示:
1) Explain the {parameter_name} XGBoost parameter in detail and how to choose values for it wisely.2) Describe how {parameter_name} fits into the step-by-step tree-building process of XGBoost.
它肯定比我讲的明白,对吧。
最后如果你也用optuna进行调优,请参考以下的GIST:
https://gist.github.com/BexTuychiev/823df08d2e3760538e9b931d38439a68
相关文章:
机器学习中XGBoost算法调参技巧
本文将详细解释XGBoost中十个最常用超参数的介绍,功能和值范围,及如何使用Optuna进行超参数调优。 对于XGBoost来说,默认的超参数是可以正常运行的,但是如果你想获得最佳的效果,那么就需要自行调整一些超参数来匹配你…...

第1章:计算机网络体系结构
文章目录 1.1 计算机网络 概述1.概念2.组成3.功能4.分类5.性能指标1.2 计算机网络 体系结构&参考模型1.分层结构2.协议、接口、服务3.ISO/OSI模型4.TCP/IP模型1.1 计算机网络 概述 1.概念 2.组成 1.组成部分&...
三(115))
【Java 动态数据统计图】动态数据统计思路Demo(动态,排序,containsKey)三(115)
上代码: import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedList; import java.util.List; import java.util.Map;public class day10 {public static void main(String[] args) {List<Map<String,O…...

【游戏评测】河洛群侠传一周目玩后感
总游戏时长接近100小时,刚好一个月。 这两天费了点劲做了些成就,刷了等级,把最终决战做了。 总体感觉还是不错的。游戏是开放世界3D游戏,Unity引擎,瑕疵很多,但胜在剧情扎实,天赋系统、秘籍功法…...

java新特性之Lambda表达式
函数式编程 关注做什么,不关心是怎么实现的。为了实现该思想,java有了一种新的语法格式,Lambda表达式。Lambda本质是匿名内部类对象,是一个函数式接口。函数式接口表示接口内部只有一个抽象方法。使用该语法可以大大简化代码。 …...
向量组相关性与线性表示的性质,向量组的等价、极大线性无关组与秩)
【考研数学】线形代数第三章——向量 | 2)向量组相关性与线性表示的性质,向量组的等价、极大线性无关组与秩
文章目录 引言二、向量组的相关性与线性表示2.3 向量组相关性与线性表示的性质 三、向量组等价、向量组的极大线性无关组与秩3.1 基本概念 写在最后 引言 承接前文,我们来学习学习向量组相关性与线性表示的相关性质 二、向量组的相关性与线性表示 2.3 向量组相关性…...

Java中调用Linux脚本
在Java中,可以使用ProcessBuilder类来调用Linux脚本。以下是一个简单的示例,展示了如何在Java中调用Linux脚本: 创建一个Linux脚本文件(例如:myscript.sh),并在其中编写需要执行的命令。确保脚…...
Nexus 如何配置 Python 的私有仓库
Nexus 可作为一个代理来使用。 针对一些网络环境不好的公司,可以通过配置 Nexus 来作为远程的代理。 Group 概念 Nexus 有一个 Group 的概念,我们可以认为一个 Nexus 仓库的 Group 就是很多不同的仓库的集合。 从下面的配置中我们可以看到࿰…...
Maven 配置文件修改及导入第三方jar包
设置java和maven的环境变量 修改maven配置文件 (D:\app\apache-maven-3.5.0\conf\settings.xml,1中环境变量对应的maven包下的conf) 修改131行左右的mirror,设置阿里云的仓库地址 <mirror> <id>alimaven</id&g…...
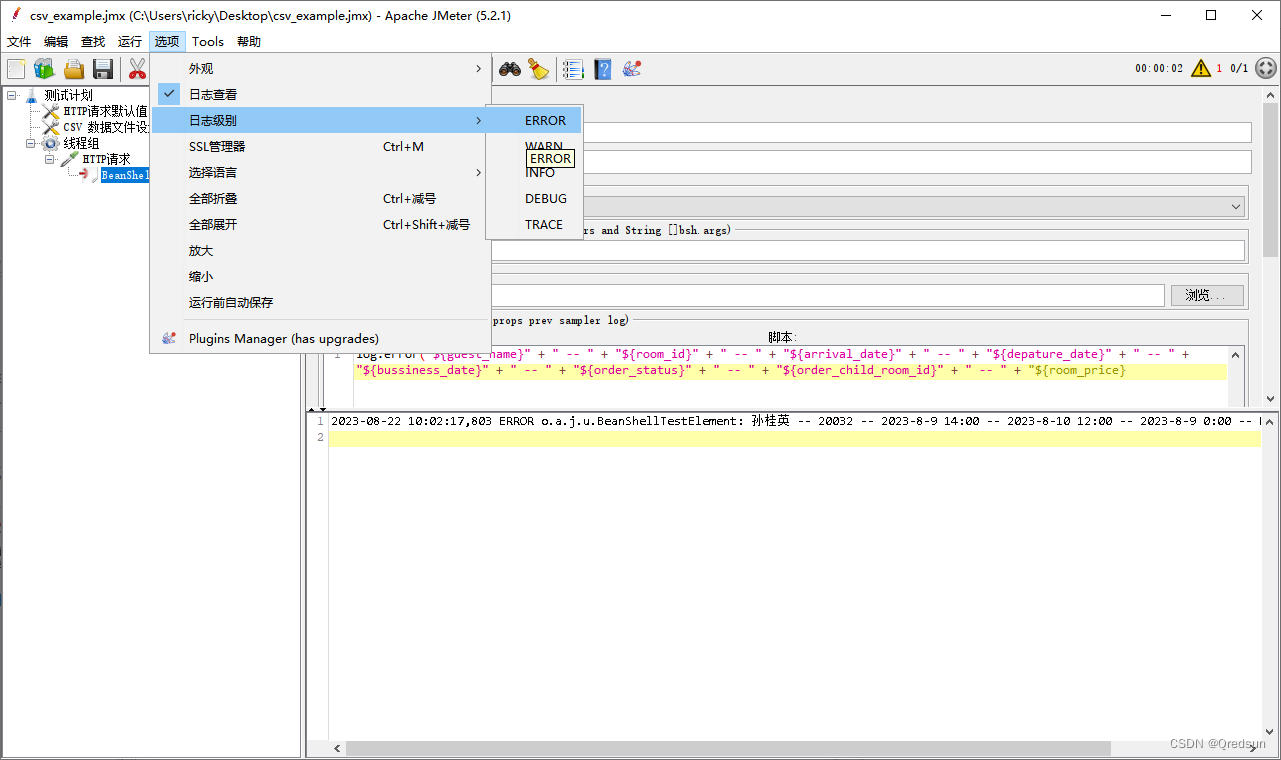
jmeter CSV 数据文件设置
创建一个CSV数据文件:使用任何文本编辑器创建一个CSV文件,将测试数据按照逗号分隔的格式写入文件中。例如: room_id,arrival_date,depature_date,bussiness_date,order_status,order_child_room_id,guest_name,room_price 20032,2023-8-9 14:…...

【SA8295P 源码分析】20 - GVM Android Kernel NFS Support 配置
【SA8295P 源码分析】20 - GVM Android Kernel NFS Support 配置 系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》 本文链接:《【SA8295P 源码分析】20 - GVM Android Kernel NFS Support 配置》 # make menuconfigFile systems ---> [*] Network File Sy…...

c++都补了c语言哪些坑?
目录 1.命名空间 1.1 定义 1.2 使用 2.缺省参数 2.1 概念 2.2 分类 3.函数重载 4.引用 4.1 概念 4.2 特性 4.3 常引用 4.4 引用和指针的区别 5.内联函数 1.命名空间 在 C/C 中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将…...

【C语言】C语言用数组算平均数,并输出大于平均数的数
题目 让用户输入一系列的正整数,最后输入“-1”表示输入结束,然后程序计算出这些数的平均数,最后输出输入数字的个数和平均数以及大于平均数的数 代码 #include<stdio.h> int main() {int x;double sum 0;int cnt 0;int number[100…...

「UG/NX」Block UI 体收集器BodyCollector
✨博客主页何曾参静谧的博客📌文章专栏「UG/NX」BlockUI集合📚全部专栏「UG/NX」NX二次开发「UG/NX」BlockUI集合「VS」Visual Studio「QT」QT5程序设计「C/C+&#...

金九银十面试题之《JVM》
🐮🐮🐮 辛苦牛,掌握主流技术栈,包括前端后端,已经7年时间,曾在税务机关从事开发工作,目前在国企任职。希望通过自己的不断分享,可以帮助各位想或者已经走在这条路上的朋友…...

wireshark | 过滤筛选总结
wireshark 是一款开源抓包工具。比如与服务器的请求响应、tcp三次握手/四次挥手 场景:在linux环境下使用tcpdump -w 然后把爬的数据写入指定的XXX.pcap 然后在wireshark中导入该文件XXX.pcap 使用下面的过滤方式进行过滤 分析数据就可以了 #直接看 不需要硬背 和s…...
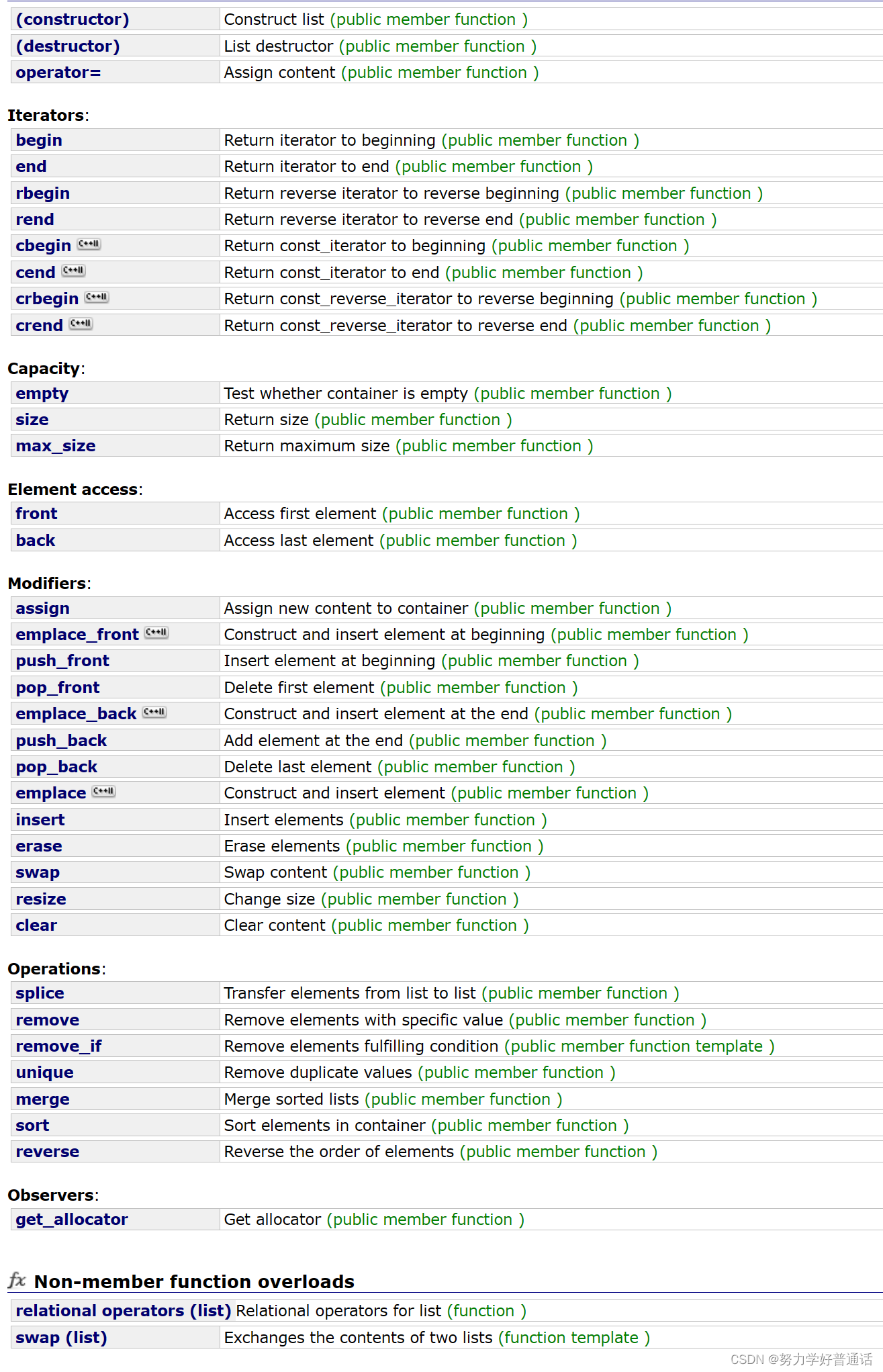
list使用
list的使用于string的使用都类似,首先通过查阅来看list有哪些函数: 可以看到函数还是蛮多的,我们值重点一些常用的和常见的: 1.关于push_back,push_front,和对应迭代器的使用 //关于push_back和push_front void test_list1() {l…...

【图解】多层感知器(MLP)
图片是一个多层感知器(MLP)的示意图,它是一种常见的神经网络模型,用于从输入到输出进行非线性映射。图片中的网络结构如下:...
React(8)
千锋学习视频https://www.bilibili.com/video/BV1dP4y1c7qd?p72&spm_id_frompageDriver&vd_sourcef07a5c4baae42e64ab4bebdd9f3cd1b3 1.React 路由 1.1 什么是路由? 路由是根据不同的 url 地址展示不同的内容或页面。 一个针对React而设计的路由解决方案…...

ssm社区管理与服务系统源码和论文
ssm社区管理与服务的设计与实现031 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 研究背景 当今时代是飞速发展的信息时代。在各行各业中离不开信息处理,这正是计算机被广泛应用于信息管理系统的…...

基于Rust构建AI智能体平台:架构设计与工程实践
1. 从零到一:构建你自己的AI智能体平台最近几年,大语言模型(LLM)的爆发式发展,让“智能体”(Agent)从一个学术概念,迅速变成了提升工作效率的利器。你可能用过一些现成的AI工具&…...

用PLC控制Labview自动运行
博图软件设置注意数据位正确下图为Labview读取CSV文件的位置测试数据如下图所示实现方法:在1分支内创建好条件,当PLC心跳为True那么就去跑True里面的流程(CSM框架)...

Arm编译器在嵌入式开发中的优化实践
1. Arm编译器嵌入式开发环境概述在嵌入式系统开发领域,工具链的选择往往决定了最终产品的性能上限。作为Arm架构的"原生"编译器,Arm Compiler for Embedded凭借其深度优化的代码生成能力,在物联网设备、工业控制器等资源受限场景中…...
)
从“能用”到“愿用”:Lovable Serverless平台的6大心理学设计法则(基于87家头部企业DevOps调研数据)
更多请点击: https://intelliparadigm.com 第一章:从“能用”到“愿用”:Lovable Serverless平台的认知跃迁 Serverless 并非仅关于函数执行与自动扩缩——真正的分水岭在于开发者是否**主动选择、持续信任并乐于传播**该平台。当运维负担归…...

从ShareGPT项目拆解现代全栈开发:Next.js、Serverless与Chrome扩展实战
1. 项目概述与核心价值如果你和我一样,经常在ChatGPT里进行一些天马行空的对话,从构思一部科幻小说的世界观,到一步步推导一个复杂的编程问题,再到让它扮演苏格拉底和你辩论哲学,这些对话记录本身就是宝贵的数字资产。…...

AI与建模仿真融合:数字孪生从静态镜像到智能决策的演进
1. 项目概述:当AI遇见建模仿真,数字孪生正在经历什么?最近几年,无论是工业制造、智慧城市还是医疗健康,但凡提到数字化转型,总绕不开“数字孪生”这个词。它就像一个在虚拟世界里为物理实体打造的“克隆体”…...

票据的采集,更新业务 todo 抽空迁移并废弃掉
采集过程 用户校验 参数校验部分 代码号码开票日期校验码(普票或电票必须)金额 是否有id,有id说明已存在,则应该是更新(该用更新接口)如果能查到,说明重复采集了查不到,新增存库...

软银携手DeltaX建储能基地,2027年量产应对AI算力电力挑战
软银与DeltaX合作:储能系统建设的新布局品玩5月12日消息,据The Elec报道,软银集团选定韩国初创公司DeltaX,负责在日本大阪建设数据中心储能系统(ESS)的开发与制造。双方计划于今年下半年在大阪堺市原夏普工…...

工业通信网络实战:从工业以太网、IO-Link到智能工厂连接架构设计
1. 项目概述:智能工厂的“神经网络”革命如果你最近参观过任何一家现代化的汽车装配线或是消费电子产品的贴片车间,可能会被那些高度协同、几乎无人干预的自动化流程所震撼。机械臂精准地抓取、焊接、组装,AGV小车沿着无形的轨道穿梭运送物料…...

从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设
从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设 在FPGA和数字IC设计领域,AMBA总线协议就像城市中的交通网络,负责协调各个功能模块之间的数据流动。而APB(Advanced Peripheral Bus)作为AMBA家族…...