机器学习算法原理之k近邻 / KNN
文章目录
- k近邻 / KNN
- 主要思想
- 模型要素
- 距离度量
- 分类决策规则
- kd树
- 主要思想
- kd树的构建
- kd树的搜索
- 总结归纳
k近邻 / KNN
主要思想
假定给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以根据其最近的 kkk 个训练实例的标签,预测新实例对应的标注信息。
具体划分,kkk 近邻又可细分为分类问题和回归问题。
分类问题:对新的实例,根据与之相邻的 kkk 个训练实例的类别,通过多数表决等方式进行预测。
回归问题:对新的实例,根据与之相邻的 kkk 个训练实例的标签,通过均值计算进行预测。
输入:训练集
T={(x1,y1),(x2,y2)⋯,(xN,yN)}T=\left\{\left(x_1, y_1\right),\left(x_2, y_2\right) \cdots,\left(x_N, y_N\right)\right\} T={(x1,y1),(x2,y2)⋯,(xN,yN)}
其中:xi∈X⊆Rn,y∈Y={c1,c2,⋯,cK}x_i \in \mathcal{X} \subseteq \mathbf{R}^n, y \in \mathcal{Y}=\left\{c_1, c_2, \cdots, c_K\right\}xi∈X⊆Rn,y∈Y={c1,c2,⋯,cK},实例 xxx ;
输出:实例 xxx 的所属的类 yyy 。
- 根据给定的距离度量,计算 xxx 与 TTT 中点的距离;
- 在 TTT 中找到与 xxx 最邻近的 kkk 个点,涵盖这 kkk 个点的 xxx 的邻域记作 Nk(x)N_k(x)Nk(x) ;
- 在 Nk(x)N_k(x)Nk(x) 中根据分类决策规则(如多数表决)决定 xxx 的类别 yyy ;
y=argmaxcj∑xi∈Nk(x)I(yi=cj),i=1,2,⋯,N;j=1,2,⋯,Ky=\underset{c_j}{\arg \max } \sum_{x_i \in N_k(x)} I\left(y_i=c_j\right), \quad i=1,2, \cdots, N ; j=1,2, \cdots, K y=cjargmaxxi∈Nk(x)∑I(yi=cj),i=1,2,⋯,N;j=1,2,⋯,K
kkk 近邻法(k-nearest neighbor,k-NN)不具有显性的学习过程(无优化算法,无训练过程),实际上利用训练数据集对特征向量空间进行划分,以其作为分类的“模型”。
模型要素
距离度量
LPL_PLP 距离:特征空间 X\mathcal{X}X 假设为 Rn,∀xi,xj∈X,xi=(xi(1),xi(2),⋯,xi(n))T,xj=(xj(1),xj(2),⋯,xj(n))T\mathbf{R}^n, \forall x_i, x_j \in \mathcal{X}, x_i=\left(x_i^{(1)}, x_i^{(2)}, \cdots, x_i^{(n)}\right)^T, x_j=\left(x_j^{(1)}, x_j^{(2)}, \cdots, x_j^{(n)}\right)^TRn,∀xi,xj∈X,xi=(xi(1),xi(2),⋯,xi(n))T,xj=(xj(1),xj(2),⋯,xj(n))T,则有
Lp(xi,xj)=(∑l=1n∣xi(l)−xj(l)∣p)1p,p≥1L_p\left(x_i, x_j\right)=\left(\sum_{l=1}^n\left|x_i^{(l)}-x_j^{(l)}\right|^p\right)^{\frac{1}{p}}, \quad p \geq 1 Lp(xi,xj)=(l=1∑nxi(l)−xj(l)p)p1,p≥1
欧氏距离(Euclidean distance) ppp = 2:
L2(xi,xj)=(∑I=1n∣xi(l)−xj(l)∣2)12L_2\left(x_i, x_j\right)=\left(\sum_{I=1}^n\left|x_i^{(l)}-x_j^{(l)}\right|^2\right)^{\frac{1}{2}} L2(xi,xj)=(I=1∑nxi(l)−xj(l)2)21
曼哈顿距离(Manhattan distance) ppp = 1:
L1(xi,xj)=∑l=1n∣xi(l)−xj(l)∣L_1\left(x_i, x_j\right)=\sum_{l=1}^n\left|x_i^{(l)}-x_j^{(l)}\right| L1(xi,xj)=l=1∑nxi(l)−xj(l)
切比雪夫距离(Chebyshev distance)ppp = ∞{\infty}∞ :
L∞(xi,xj)=maxl∣xi(l)−xj(l)∣L_{\infty}\left(x_i, x_j\right)=\max _l\left|x_i^{(l)}-x_j^{(l)}\right| L∞(xi,xj)=lmaxxi(l)−xj(l)

分类决策规则
分类函数:
f:Rn→{c1,c2,⋯,cK}f: \mathbf{R}^n \rightarrow\left\{c_1, c_2, \cdots, c_K\right\} f:Rn→{c1,c2,⋯,cK}
0-1 损失函数:
L(Y,f(X))={1,Y≠f(X)0,Y=f(X)L(Y, f(X))= \begin{cases}1, & Y \neq f(X) \\ 0, & Y=f(X)\end{cases} L(Y,f(X))={1,0,Y=f(X)Y=f(X)
误分类概率:
P(Y≠f(X))=1−P(Y=f(X))P(Y \neq f(X))=1-P(Y=f(X)) P(Y=f(X))=1−P(Y=f(X))
给定实例 x∈Xx \in \mathcal{X}x∈X ,相应的 kkk 邻域 Nk(x)N_k(x)Nk(x) ,类别为 cjc_jcj ,误分类率:
1k∑xi∈Nk(x)I(yi≠cj)=1−1k∑xi∈Nk(x)I(yi=cj)\frac{1}{k} \sum_{x_i \in N_k(x)} I\left(y_i \neq c_j\right)=1-\frac{1}{k} \sum_{x_i \in N_k(x)} I\left(y_i=c_j\right) k1xi∈Nk(x)∑I(yi=cj)=1−k1xi∈Nk(x)∑I(yi=cj)
最小化误分析率,等价于:
argmax∑xi∈Nk(x)I(yi=cj)\underset{}{\arg \max } \sum_{x_i \in N_k(x)} I\left(y_i=c_j\right) argmaxxi∈Nk(x)∑I(yi=cj)
kd树
主要思想
kd 树是一种对 kkk 维空间中的实例点进行储存以便对其进行快速检索的树形数据结构。
本质:二叉树,表示对 kkk 维空间的一个划分。
构造过程:不断地用垂直于坐标轴的超平面将 kkk 维空间切分,形成 kkk 维超矩形区域。
kd 树的每一个结点对应于一个 kkk 维超矩形区域。
kd树的构建
输入: kkk 维空间数据集:
T={x1,x2,⋯,xN}T=\left\{x_1, x_2, \cdots, x_N\right\} T={x1,x2,⋯,xN}
其中,xi=(xi(1),xi(2),⋯,xi(k))Tx_i=\left(x_i^{(1)}, x_i^{(2)}, \cdots, x_i^{(k)}\right)^Txi=(xi(1),xi(2),⋯,xi(k))T
输出:kd 树
- 开始:构造根结点。
- 选取 x(1)x^{(1)}x(1) 为坐标轴,以训练集中的所有数据 x(1)x^{(1)}x(1) 坐标中的中位数(数据集为偶数时,中位数+1)作为切分点,将超矩形区域切割成两个子区域,将该切分点作为根结点。
由根结点生出深度为 1 的左右子结点,左结点对应坐标小于切分点,右结点对应坐标大于切分点。
- 选取 x(1)x^{(1)}x(1) 为坐标轴,以训练集中的所有数据 x(1)x^{(1)}x(1) 坐标中的中位数(数据集为偶数时,中位数+1)作为切分点,将超矩形区域切割成两个子区域,将该切分点作为根结点。
- 重复:
- 对深度为 jjj 的结点,选择 x(l)x^{(l)}x(l) 为切分坐标轴(切分应垂直于坐标轴),l=j(modk)+1l = j(\ mod \ k) + 1l=j( mod k)+1 ,以该结点区域中所有实例 x(1)x^{(1)}x(1) 坐标的中位数作为切分点,将区域分为两个子区域。
生成深度为 j+1j+1j+1 的左、右子结点。左结点对应坐标小于切分点,右结点对应坐标大于切分点。
- 对深度为 jjj 的结点,选择 x(l)x^{(l)}x(l) 为切分坐标轴(切分应垂直于坐标轴),l=j(modk)+1l = j(\ mod \ k) + 1l=j( mod k)+1 ,以该结点区域中所有实例 x(1)x^{(1)}x(1) 坐标的中位数作为切分点,将区域分为两个子区域。
- 直到两个子区域没有实例时停止。
kd树的搜索
输入:已构造的 kd 树,目标点 xxx
输出:xxx 的最近邻
- 寻找“当前最近点“
- 从根结点出发,递归访问 kd 树,找出包含 xxx 的叶结点(kd 树的每一个结点对应一个超矩形区域);
- 以此叶结点为"当前最近点";
- 回溯
- 若该结点比“当前最近点”的距离目标更近,更新“当前最近点”;
- 当前最近点一定存在于该结点一个子结点对应的区域,检查子结点的父结点的另一子结点(子结点的兄弟结点)对应的区域是否有更近的点。
- 当回退到根结点时,搜索结束,最后的“当前最近点”即为 xxx 的最近邻点。
目标点的最近邻一定在以目标点为中心并通过当前最近点的超球体的内部。
如果父结点的另一个子结点的超矩形区域与超球体相交,那么在相交的区域内寻找与目标点更近的实例点。
总结归纳
- 较小的 kkk 值,学习的近似误差减小,但估计误差增大,敏感性增强,而且模型复杂,容易过拟合。
较大的 kkk 值,减少学习的估计误差,但近似误差增大,而且模型简单。 - kkk 的取值可通过交叉验证来选择,一般低于训练集样本量的平方根。
- 分类决策规则使用 0-1 损失函数,因为分类问题只有分类正确和分类错误两种可能。
- kd 树构建时对于超平面的划分,二位空间划分为矩形,三维空间划分为长方体。
- 构建完成的 kd 树,类似于二叉排序树,每一层代表着一个维度。
- kd 树的搜索,类似于二叉排序树的搜索过程。
- kkk 近邻算法对于高维数据的处理略显缓慢,此时可以考虑数据降维以及 kd 树。
- kd 树更适用于训练实例数远大于空间维数时的 kkk 近邻搜索。
相关文章:
机器学习算法原理之k近邻 / KNN
文章目录k近邻 / KNN主要思想模型要素距离度量分类决策规则kd树主要思想kd树的构建kd树的搜索总结归纳k近邻 / KNN 主要思想 假定给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以根据其最近的 kkk 个训练实例的标签,…...
【期末复习】例题说明Prim算法与Kruskal算法
点睛Prim与Kruskal算法是用来求图的最小生成树的算法。最小生成树有n个顶点,n-1条边,不能有回路。Prim算法Prim算法的特点是从个体到整体,随机选定一个顶点为起始点出发,然后找它的权值最小的边对应的另一个顶点,这两个…...
AtCoder Beginner Contest 290 A-E F只会n^2
ABC比较简单就不再复述 D - Marking 简要题意 :给你一个长度为nnn的数组,下标为0到n−10 到 n-10到n−1,最初指针位于0,重复执行n-1次操作,每次操作的定义为将当前指针加上ddd,如果该位置为空(未填数),否则我们向右找到第一个为空…...
springMvc源码解析
入口:找到springboot的自动配置,将DispatcherServlet和DispatcherServletRegistrationBean注入spring容器(DispatcherServletRegistrationBean间接实现了ServletContextInitializer接口,最终ServletContextInitializer的onStartup…...
采用aar方式将react-native集成到已有安卓APP
关于react-native和android的开发环境搭建、环境变量配置等可以查看官方文档。 官方文档地址 文章中涉及的node、react等版本: node:v16.18.1 react:^18.1.0 react-native:^0.70.6 gradle:gradle-7.2开发工具:VSCode和android studio 关于react-native和…...
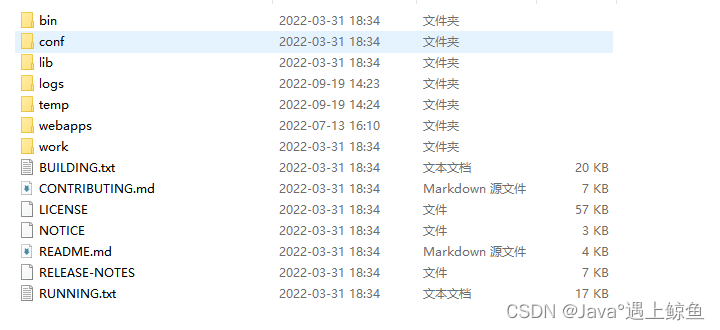
Tomcat目录介绍,结构目录有哪些?哪些常用?
bin 启动,关闭和其他脚本。这些 .sh文件(对于Unix系统)是这些.bat文件的功能副本(对于Windows系统)。由于Win32命令行缺少某些功能,因此此处包含一些其他文件。 比如说:windows下启动tomcat用的…...
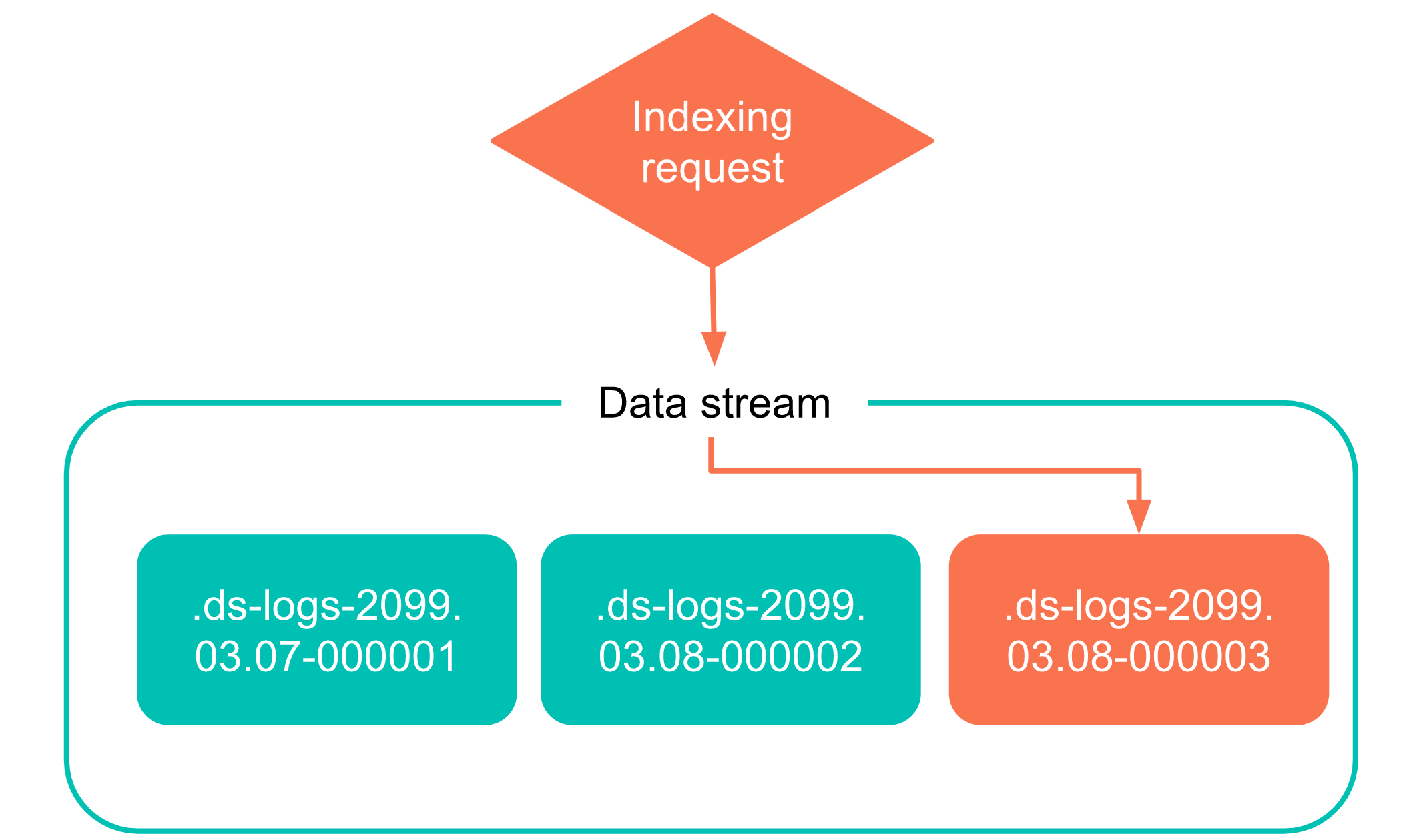
Elasticsearch也能“分库分表“,rollover实现自动分索引
一、自动创建新索引的方法 MySQL的分库分表大家是非常熟悉的,在Elasticserach中有存在类似的场景需求。为了不让单个索引太过于庞大,从而引发性能变差等问题,我们常常有根据索引大小、时间等创建新索引的需求,解决方案一般有两个…...

6 大经典机器学习数据集,3w+ 用户票选得出,建议收藏
内容一览:本期汇总了超神经下载排名众多的 6 个数据集,涵盖图像识别、机器翻译、遥感影像等领域。这些数据集质量高、数据量大,经历人气认证值得收藏码住。 关键词:数据集 机器翻译 机器视觉 数据集是机器学习模型训练的基础&…...

Logview下载
Logview下载 之前一直用的NotePad 后来偶尔的看到作者有发布不当言论 就卸载了又去下载了NotePad– 但是,其实不管是 还是 – 打开大一些的文件都会卡死 所以就搜了这个logview 用起来还不错,目前我这再大的文件 这个软件都是秒打开 但是也会有一点点小…...
macos 下载 macOS 系统安装程序及安装U盘制作方法
01 下载 macOS 系统安装程序的方法 本文来自: https://discussionschinese.apple.com/docs/DOC-250004259 简介 Mac 用户时不时会需要下载 macOS 的安装程序,目的不同,或者升级或者降级,或者研究或者收藏。为了方便不同用户,除…...
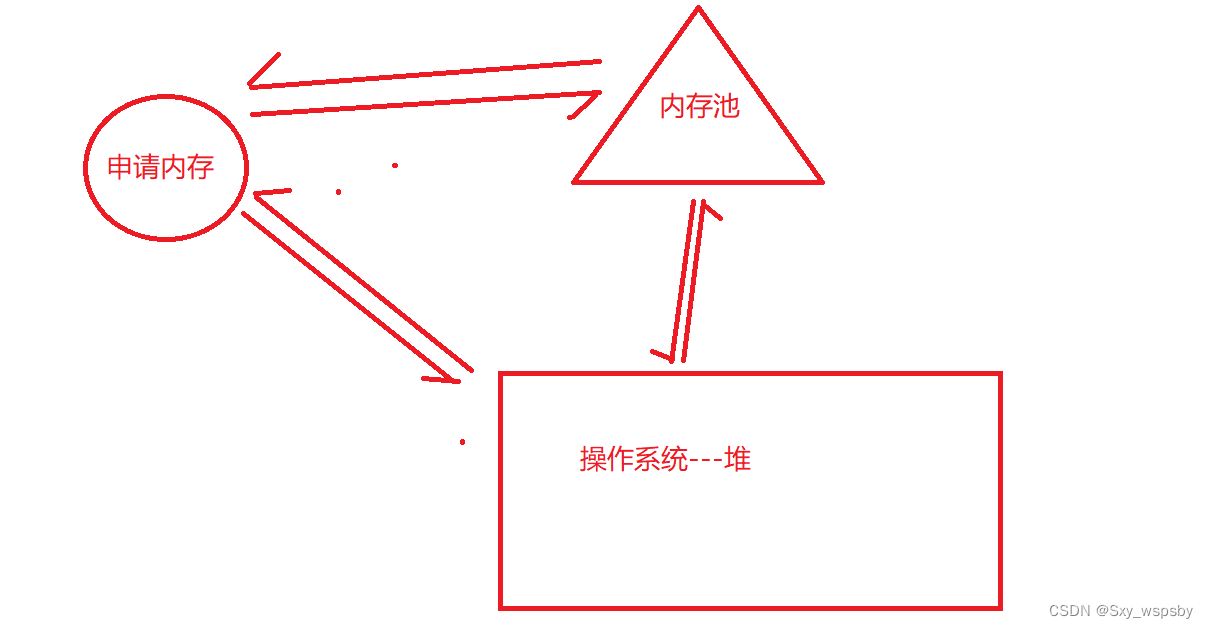
c++动态内存分布以及和C语言的比较
文章目录 前言一.c/c内存分布 C语言的动态内存管理方式 C内存管理方式 operator new和operator delete函数 malloc/free和new/delete的区别 定位new 内存泄漏的危害总结前言 c是在c的基础上开发出来的,所以关于内存管理这一方面是兼容c的&…...

软考高级信息系统项目管理师系列之三十一:项目变更管理
软考高级信息系统项目管理师系列之三十一:项目变更管理 一、项目变更管理内容二、项目变更管理基本概念1.项目变更管理定义2.项目变更产生的原因3.项目变更的分类三、项目变更管理的原则和工作流程1.项目变更管理的原则2.变更管理的组织机构3.变更管理的工作程序四、项目变更管…...
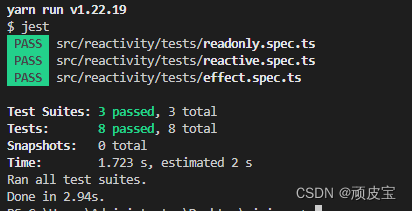
【Vue3源码】第二章 effect功能的完善补充
【Vue3源码】第二章 effect功能的完善补充 前言 上一章节我们实现了effect函数的功能stop和onstop,这次来优化下stop功能。 优化stop功能 之前我们的单元测试中,stop已经可以成功停止了响应式更新(清空了收集到的dep依赖) st…...
)
CHAPTER 2 Web Server - apache(httpd)
Web Server - httpd2.1 http2.1.1 协议版本2.1.2 http报文2.1.3 web资源(web resource)2.1.4 一次完整的http请求处理过程2.1.5 接收请求的模型2.2 httpd配置2.2.1 MPM(多进程处理模块)1. 工作模式2. 切换MPM3. MPM参数配置2.2.2 主配置文件1. 基本配置2. 站点访问控制常见机制…...
【Vagrant】下载安装与基本操作
文章目录概述软件安装安装VirtualBox安装Vagrant配置环境用Vagrant创建一个VMVagrantfile文件配置常用命令概述 Vagrant是一个创建虚拟机的技术,是用来创建和管理虚拟机的工具,本身自己并不能创建管理虚拟机。创建和管理虚拟机必须依赖于其他的虚拟化技…...
常用类(五)System类
(1)System类常见方法和案例: (1)exit:退出当前程序 我们设计的代码如下所示: package com.ypl.System_;public class System_ {public static void main(String[] args) {//exit: 退出当前程序System.out.println("ok1"…...

Navicat Premium 安装 注册
Navicat Premium 一.Navicat Premium的安装 1.暂时关闭windows的病毒与威胁防护弄完再开,之后安装打开过程中弹窗所有警告全部允许,不然会被拦住 2.下载安装包,解压 链接:https://pan.baidu.com/s/1X24VPC4xq586YdsnasE5JA?pwdu4vi 提取码…...
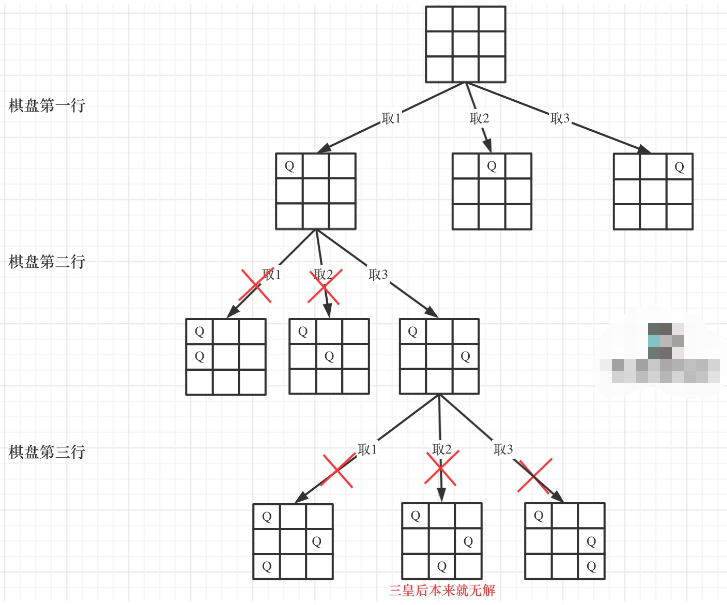
回溯算法总结
首先回溯算法本身还是一个纯暴力的算法,只是回溯过程可能比较抽象,导致大家总是感觉看到的相关题目做的不是很顺畅,回溯算法一般来说解决的题目有以下几类:组合问题:lq77、lq17、lq39、lq40、lq216、切割问题ÿ…...
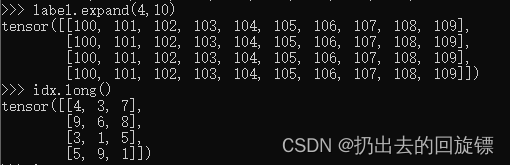
ccc-pytorch-基础操作(2)
文章目录1.类型判断isinstance2.Dimension实例3.Tensor常用操作4.索引和切片5.Tensor维度变换6.Broadcast自动扩展7.合并与分割8.基本运算9.统计属性10.高阶OP大伙都这么聪明,注释就只写最关键的咯1.类型判断isinstance 常见类型如下: a torch.randn(…...

独居老人一键式报警器
盾王居家养老一键式报警系统,居家养老一键式报警设备 ,一键通紧急呼救设备,一键通紧急呼救系统,一键通紧急呼救器 ,一键通紧急呼救终端,一键通紧急呼救主机终端产品简介: 老人呼叫系统主要应用于…...

软件测试新方法:利用Lingbot-Depth-Pretrain-ViTL-14进行GUI界面立体元素测试
软件测试新方法:利用Lingbot-Depth-Pretrain-ViTL-14进行GUI界面立体元素测试 你有没有遇到过这种情况?一个软件界面看起来功能都正常,按钮能点,输入框能输,但用起来就是感觉“不对劲”。比如,一个弹窗好像…...

Intv_AI_MK11 Java开发环境快速搭建:从JDK安装到模型调用
Intv_AI_MK11 Java开发环境快速搭建:从JDK安装到模型调用 1. 前言:为什么选择Java调用AI模型 Java作为企业级开发的主流语言,在AI应用开发中同样能发挥重要作用。Intv_AI_MK11作为新一代AI模型,提供了完善的Java SDK支持&#x…...

网络资源获取困境如何通过猫抓实现高效解决方案?
网络资源获取困境如何通过猫抓实现高效解决方案? 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字时代,网络资源获取已…...

地理信息系统知识点03---空间数据模型
一、地理空间与空间抽象1. 地理空间地理空间是 GIS 的描述与分析对象,泛指地球表层空间及其相关的关联空间,既包含具有地理位置的实体、现象,也涵盖它们之间的相互作用与分布规律。从内涵上,地理空间具有区域性、多维性、随机性、…...

DeepSeek-R1蒸馏模型入门:1.5B版本本地部署完整教程
DeepSeek-R1蒸馏模型入门:1.5B版本本地部署完整教程 1. 引言 1.1 为什么选择DeepSeek-R1 1.5B版本 DeepSeek-R1 1.5B版本是专为本地CPU环境优化的轻量级推理模型,它通过知识蒸馏技术保留了原版70B参数模型的核心推理能力,同时将参数量压缩…...

从安装到出图:Anything V5 Stable Diffusion 完整入门流程详解
从安装到出图:Anything V5 Stable Diffusion 完整入门流程详解 1. 环境准备与快速部署 1.1 系统要求 在开始使用Anything V5之前,请确保您的系统满足以下最低配置要求: 操作系统:Linux (推荐Ubuntu 20.04)GPU:NVID…...

探索16极18槽轴向磁通永磁电机:基于Maxwell的模型解析
基于maxwell的16极18槽轴向磁通永磁电机模型,功率1500w,外径190mm。 输出转矩3.7Nm.可用于轴向电机设计学习。 大致参数波形见图。最近在研究轴向磁通永磁电机,今天和大家分享基于Maxwell搭建的一款16极18槽轴向磁通永磁电机模型,这款电机功率…...

自动化内容创作:OpenClaw+Qwen3.5-9B批量处理游记照片生成博客
自动化内容创作:OpenClawQwen3.5-9B批量处理游记照片生成博客 1. 为什么需要自动化内容创作流水线 去年夏天我从西藏旅行回来,手机里存了800多张照片。当我坐在电脑前准备写游记时,面对海量素材突然感到无从下手——每张照片都需要回忆拍摄…...
)
别再暴力求素数了!用C++实现埃氏筛和欧拉筛,性能提升百倍(附完整代码)
素数筛法性能优化实战:从暴力枚举到欧拉筛的百倍飞跃 在算法竞赛和工程开发中,素数筛选是一个经典问题。当数据规模达到百万级别时,传统的暴力枚举方法往往力不从心。本文将深入探讨三种素数筛选算法——暴力枚举、埃拉托斯特尼筛法ÿ…...

极验滑动验证码自动化实战:背景提取、缺口定位与Playwright滑动模拟
滑动验证码自动化实战:背景提取、缺口定位与Playwright滑动模拟 一、前言 在爬虫自动化、Web端自动化测试、业务流程自动化等场景中,人机验证是保障系统安全的重要防线,也是自动化流程中最常见的“拦路虎”。极验(Geetest&#…...