ChatGPT原理与技术演进剖析
—— 要抓住一个风口,你得先了解这个风口的内核究竟是什么。本文作者:黄佳 (著有《零基础学机器学习》《数据分析咖哥十话》)
ChatGPT相关文章已经铺天盖地,剖析(现阶段或者只能说揣测)其底层原理的优秀文章也已经出现,其中就包括爱丁堡大学符尧博士的文章:How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources 以及Alan D. Thompson博士的文章:GPT-3.5 + ChatGPT: An illustrated overview。再继续等待OpenAI发表ChatGPT的官方论文之前,我也谈谈自己对他的一些肤浅理解。
当然我已经问过ChatGPT本GPT这个问题了,它的回答不外乎是一些众所周知的东西。所谓大规模、高质量的训练数据和基于Transformer的架构,以及大量计算资源的需求,那是所有预训练大模型的共性,像Google、Meta这样的公司拥有的资源也不会比OpenAI差,但是他们并没有训练出ChatGPT这样的作品。

标题成功源于反复迭代,持续优化
不过,这个答案和之前与他的某些对话过程中,有一点令我印象深刻的是,ChatGPT反复的强调它并不是突然出现的,他的出现是一个反复迭代,持续优化的过程。
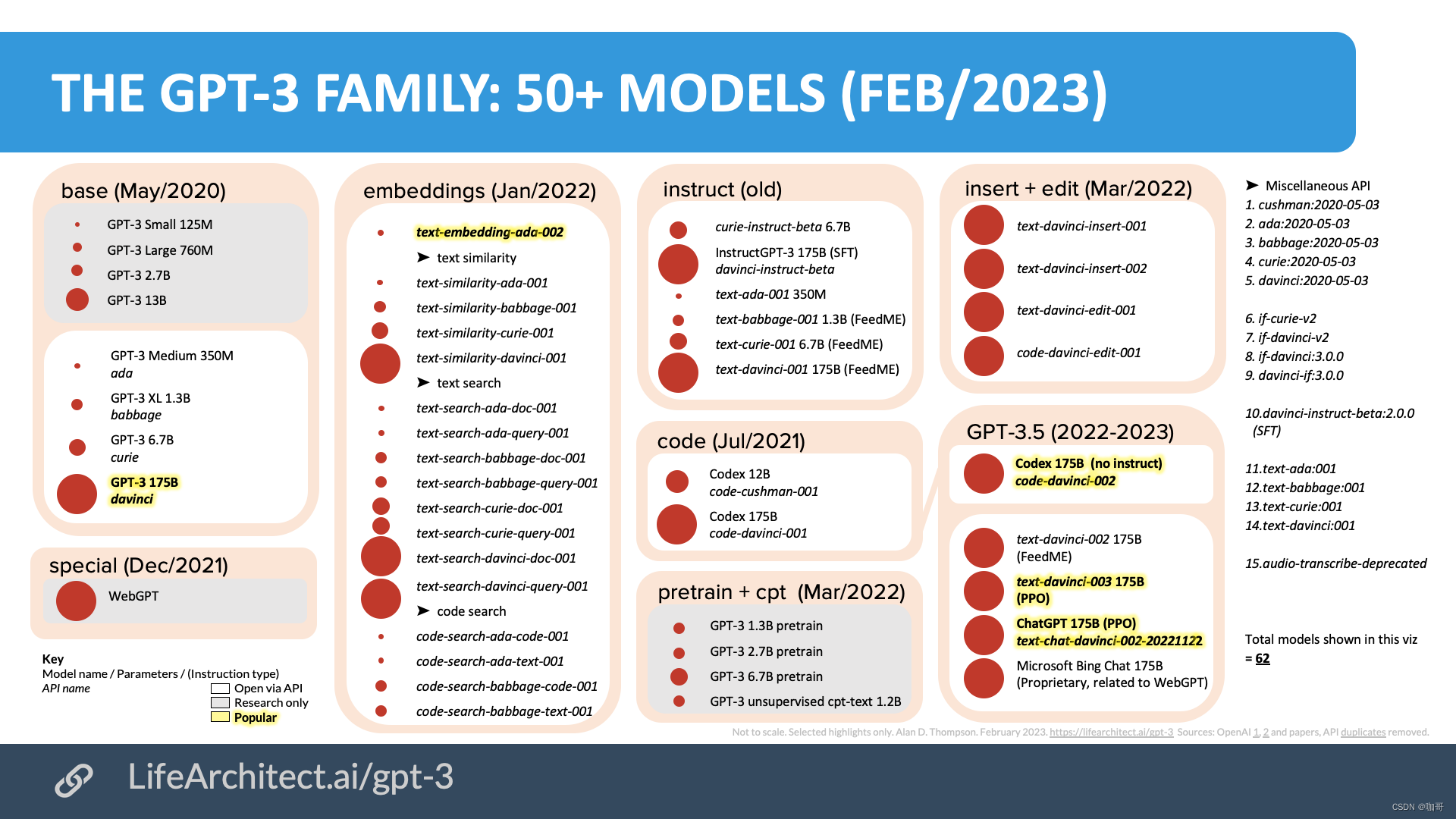
所以我们先来看一看,ChatGPT是怎样一步一步进化到现在这个程度的。如上图所示GPT-3最早发布于2020年5月,这一批模型有大有小,小的125M参数,大到有175B的davinci。基于这个175B的GPT-3,又演进出了一系列的GPT分支模型,重点解决不同类型的任务,其中与ChatGPT的演进密切相关的重要模型包括:
- text-embedding-adc-002:这个模型是用于文本嵌入的模型,可以将文本嵌入到低维向量空间中,用于语义相似度计算等任务。在ChatGPT中,这个模型用于对话历史的编码,有助于生成连贯的对话文本。
- code-davinci-002:这个模型是用于代码生成的模型,可以生成高质量的代码。在ChatGPT的改进过程中,OpenAI将code-davinci-002和GPT-3的部分结构进行了融合,用于增强模型在程序生成等任务中的表现。
- text-davinci-002:这个模型是在davinci模型基础上进行的改进,其主要特点是能够在生成文本时保持一定的一致性和连贯性。在ChatGPT的改进过程中,OpenAI采用了text-davinci-002的部分结构,用于增强模型在对话生成任务中的表现。
这样,我们不难发现,ChatGPT是高屋建瓴。GPT-3这个模型已经在生成连贯的文本、保持一致性、理解上下文等方面表现优秀,这为ChatGPT的生成能力和质量奠定了基础。而ChatGPT又进一步整合了后续的text-embedding / code-davinci / text-davinci 中的对话历史的编码、代码生成以及连贯文本生成的能力。当我们第一次见到ChatGPT的时候,他似乎已经是全能的了。
因此:
- 作为一个聊天对话机器人,他一定要有优越的上下文编码及学习的能力(context learning),这样他才能够记住之前聊了些什么。
- 代码生成能力当然是ChatGPT最令人惊艳的能力之一,这部分能力来源于code-davinci-002的遗传。
- 此外,text-davinci系列的能力来源于InstructGPT中的指令微调(instruction
tuning)功能,关于指令微调和InstructGPT,OpenAI有论文Training language models to follow instructions with human feedback。此论文,也成为了目前同学们研究(揣摩)ChatGPT的最重要指南。
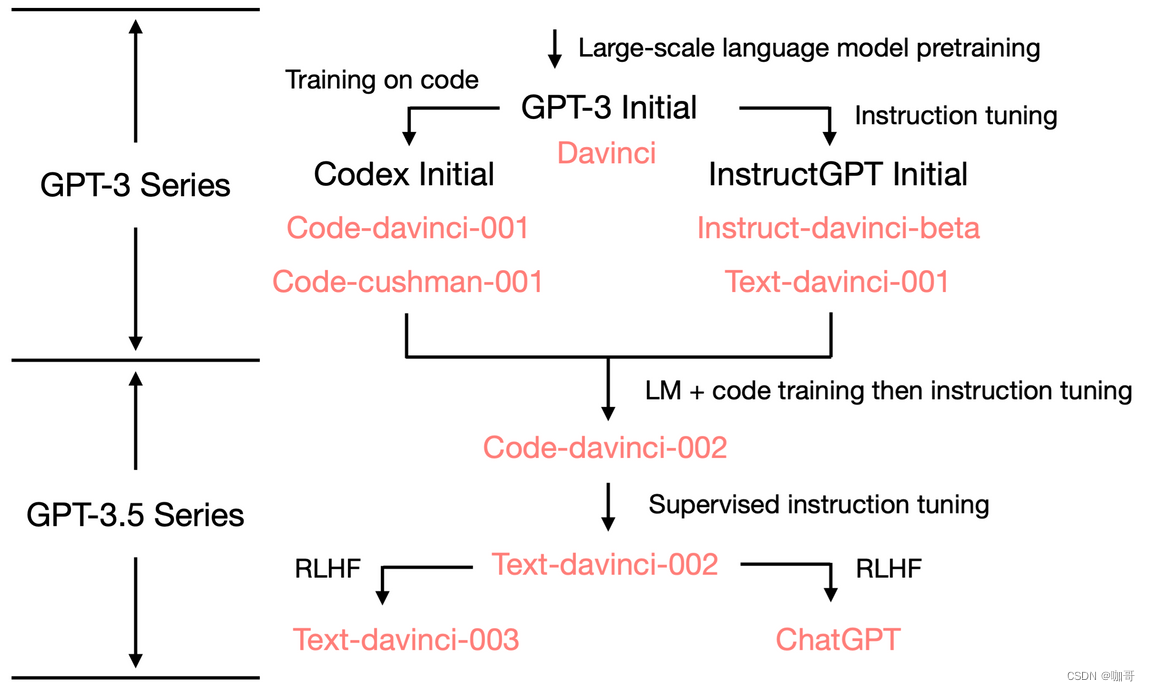
上图是Yao Fu总结的ChatGPT演进图。当然了,我们现在只是简单分析了从GPT-3到ChatGPT的演进源流,要知道,GPT-3也不是一夜之间诞生的,它也是建立在巨人的肩膀之上的。而GPT-3的爷爷GPT,那可是比BERT还要更早几个月问世的祖宗级别的模型,所以下面我们看一看GPT的初心以及从GPT到GPT3的进化。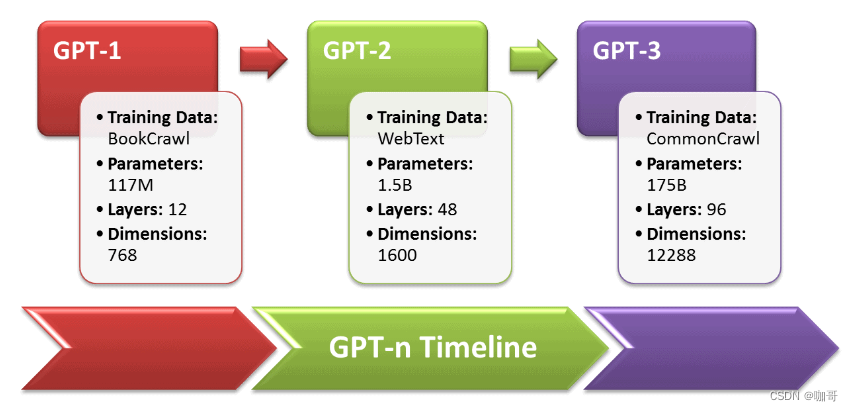
标题GPT的“不忘初心”
众所周知,有名的预训练模型,基本上(除了最早的Elmo之外)全是基于Transfromer架构的。在Google发表BERT论文的时候,GPT(初代)和ELMo已经出现了,因此,BERT论文作者将三者进行了简单的比较。
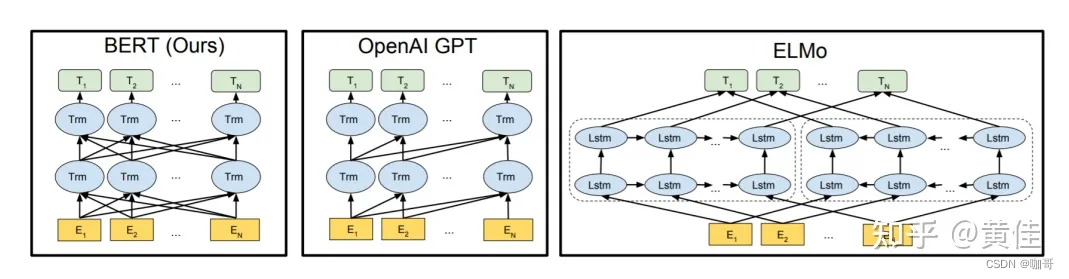
其中:
- ELMo 使用独立训练的从左向右和从右向左的LSTM模型进行拼接生成特征,用于下游任务,本质上这还是一种传统的Word Embedding。
- BERT 使用双向Transformer架构进行预训练,它可以同时考虑句子左右两侧的上下文信息。BERT只使用了Transformer的encoder部分。
- OpenAI GPT 使用单向Transformer架构进行预训练,只能考虑句子左侧的上下文信息。在GPT中,Transformer被用于解码器(decoder)部分。
- 因此,从架构上我们可以说BERT在左(encoder),GPT在右(decoder)。除了架构的区别之外,BERT和OpenAI GPT采用的是微调方法(fine-tuning approach),即在特定任务上微调预训练模型。而ELMo则是基于特征的方法(feature-based approach),即将预训练的特征用于下游任务的训练。
在BERT出现后的数年间,它毫无疑问是最具影响力的语言模型。从创新的角度来说,他所提出的掩码语言模型(Masked Language Model,MLM)的方法,也是最具创造力的。其中一部分输入token会被随机地替换成掩码(即[MASK]),模型需要通过对其它token的学习,来预测这些被掩码的token的正确标签。这种方式可以促使模型在预测时考虑到左右两侧的上下文信息,从而更好地理解句子中的语义。这使得BERT在某些任务上比其他模型表现更好。
然而!!!BERT的灵活创新当然也就同时带来了他的局限。在自然语言推理方面无所不能的BERT有什么局限?那就是 —— 其实这种考虑到左右两侧的上下文信息的“完形填空”式的训练过程其实给语言模型带来了“上帝视角”。在穆文的文章中就指出:这样训练出来的模型,在阅读理解、句子分类等任务上有天然优势,但从语言模型角度看,显然有点『变味』了,比如语言模型最常见的根据上文生成下文的能力,BERT是不具备的。
同样是基于 transformer 的 GPT系列,则初心不变地选择了坚持用Transformer做单向语言模型的道路:让全局的注意力仅限制在“过去”——也就是一个词的上文。他的目标,就是根据之前出现过的单词,来预测下一个单词的出现概率。这样,他也就保留了最纯正的“语言模型”血统。
稍微详细一点说:在GPT的预训练阶段中,输入序列是一个已经存在的文本片段,训练时,GPT仅关注左侧上下文信息,使用单向的Transformer解码器来生成每个token的表示,而模型需要预测下一个词的概率。解码器部分的Transformer架构通过对已经存在的文本片段的建模,学习文本的潜在分布,并在此基础上预测下一个词。此外,GPT的解码器还采用了一种叫做“自回归”(auto-regressive)的方法,即在生成下一个token时,依赖前面已经生成的token。这种方法保证了生成的序列的连贯性和合理性。
至此,我们不难得出结论:灵活的BERT能能够理解文本的语义,学习到上下文的双向表示,从而具有较强的自然语言推理能力,适用于完成自然语言推理任务,如文本分类、关系抽取等。而坚持了原始语言模型本质的GPT则能够在上文中推断并生成适当的下文,具有较强的文本生成能力,完成生成式的任务,例如对话生成、文本摘要和文章生成等。
而今天让我们惊艳的ChatGPT,本质上是基于上文生成下文,其能力的起源当然是GPT源于原始语言模型的文本生成能力。而且,模型越大,语料库越大,生成语言的连贯自然性就越好。这在初代GPT到GPT2,然后GPT3的演进中可见一斑。从GPT到GPT3,基本架构不变,而模型的参数翻了千倍以上。
关于上述结论详情参考Open AI的GPT-3的官方论文:Language Models are Few-Shot Learners,该论文展示了只要将语言模型的规模扩大,就可以极大地提高任务无关的少样本学习性能。
标题从GPT-3到基于GPT3.5的Chat-GPT
上面我们分析了GPT相对于BERT来说,更容易成为完美的对话机器人的天然优势所在(BERT的架构决定了他是不容易实现聊天对话功能的),下面我们着重分析从GPT-3到基于GPT3.5的Chat-GPT,还有哪些需要具体完善之处。
ChatGPT 如何运作?
关于ChatGPT如何运作的官方说法是:ChatGPT 是根据 GPT-3.5 进行微调的,GPT-3.5 是一种经过训练可生成文本的语言模型。ChatGPT 通过使用人类反馈强化学习 (RLHF) 针对对话进行了优化——一种使用人类演示和偏好比较来引导模型朝着期望的行为发展的方法。
从GPT3到改进版3.5
GPT-3在自然语言处理任务中的表现已经非常出色,能够生成连贯自然的文本,并在一定程度上具有推理和理解文本的能力。然而,GPT-3仍然存在一些问题,例如:缺乏对世界知识的理解,无法进行多轮对话等等。最重要的一点:很多时候生成的对话还是给人以“语无伦次”之感,对话者会感觉AI并没有真正的理解人类的意图。
针对于此,GPT-3.5在GPT-3的基础上进行了一系列改进和增强,主要解决以下几个问题:
- 对于实体和事件的理解:GPT-3.5通过增加对常识知识和常用数据集的了解,使得模型能够更好地理解实体和事件,从而提高了它在问题回答、阅读理解等任务中的表现。
- 对于多轮对话的支持:通过“上下文管理器”(Context Manager),它可以帮助模型管理多轮对话中的上下文信息,从而更好地处理复杂的对话场景。
- 对于文本生成的控制:通过人类反馈强化学习(RLHF),让用户更好地控制模型生成的文本内容和形式,从而使得生成的文本更加符合用户的需求。而且,作为一个公众可以访问的聊天机器人,他需要安全,合规,不能说不该说的话。
- 另外,GPT-3.5 是在 2021年第四季度之前,使用选定的文本和代码的混合物进行了训练,因此它同时具有文本和代码的生成能力。
在上面介绍的几点中,我感觉最解决问题的,可以说是**上下文学习(context learning)的能力,以及人类反馈强化学习(RLHF)**的方法。
上下文学习和管理(context learning and management)
如果一个聊天机器人只能对当前对话进行回应,但是不能记住当前对话之前的Conversation,那么这个聊天机器人是相当让人失望的。而就我们目前的感受来看,ChatGPT显然记住了很先前的对话内容。
ChatGPT说(注意,这是ChatGPT说的,无其它验证源):为了更好地支持多轮对话,ChatGPT引入了一种称为“Context Manager”的机制。Context Manager是一个基于堆栈的上下文管理器,它可以帮助ChatGPT跟踪和管理多轮对话中的上下文信息。在对话中,ChatGPT通过上下文记忆来理解用户的意图,并根据先前的对话内容生成响应。当ChatGPT接收到一个新的对话时,它将当前上下文压入堆栈中,并开始处理新的对话。当ChatGPT需要回应用户时,它可以通过查看堆栈中的上下文信息,并把它嵌入一个Context Embedding来理解用户的意图和之前的对话内容,并根据此生成响应。
除了堆栈,Context Manager还包括一些其他的组件,如上下文ID、上下文层数和上下文长度等。这些组件可以帮助ChatGPT更好地管理上下文信息,并提高模型在多轮对话场景中的表现。
在多轮对话中,ChatGPT还会根据用户的输入和之前的对话历史生成回复。为了实现上下文的理解和管理,ChatGPT通常需要将用户输入和之前的对话历史进行对齐,将相应的信息对应起来,从而确定用户的意图和之前的对话上下文。例如,当用户输入“我想要一杯咖啡”,ChatGPT会将这句话与之前的对话历史进行对齐,从而确定“一杯咖啡”的意图和上下文。
在ChatGPT中,对齐通常使用的是注意力机制,即通过计算不同输入序列中元素之间的相似度来进行匹配和映射。注意力机制是一种有效的方法,可以帮助ChatGPT实现对话上下文的理解和管理,并在多轮对话中生成连贯自然的回复。
当然,虽然 ChatGPT 能够记住用户早些时候在对话中说过的话,但它可以保留的信息量是有限的。该模型能够从当前对话中引用最多大约 3000 个单词(或 4000 个标记)——超出此范围的任何信息都不会被存储。
人类反馈强化学习 (RLHF)
下面我们就要详细说说GPT-3.5中增加的人类反馈强化学习 (RLHF,Reinforcement Learning with Human Feedback)。这是一种基于强化学习的方法,用于指导机器学习模型的行为。与传统的强化学习方法不同,RLHF使用人类反馈来指导模型的决策过程,从而帮助模型更好地适应不同的环境和任务。
首先,Open AI官方说法:我们使用与InstructGPT相同的方法,使用来自人类反馈的强化学习 (RLHF) 来训练该模型,但数据收集设置略有不同。我们使用监督微调训练了一个初始模型:人类 AI 训练员提供对话,他们在对话中扮演双方——用户和 AI 助手。我们让培训师可以访问模型编写的建议,以帮助他们撰写回复。我们将这个新的对话数据集与 InstructGPT 数据集混合,我们将其转换为对话格式。
为了创建强化学习的奖励模型,我们需要收集比较数据,其中包含两个或多个按质量排序的模型响应。为了收集这些数据,我们收集了 AI 培训师与聊天机器人的对话。我们随机选择了一条模型编写的消息,抽取了几个备选的完成方式,并让 AI 培训师对它们进行排名。使用这些奖励模型,我们可以使用近端策略优化来微调模型。我们对这个过程进行了几次迭代。
具体来说,ChatGPT 模型由 OpenAI 团队采用三步法进行训练:
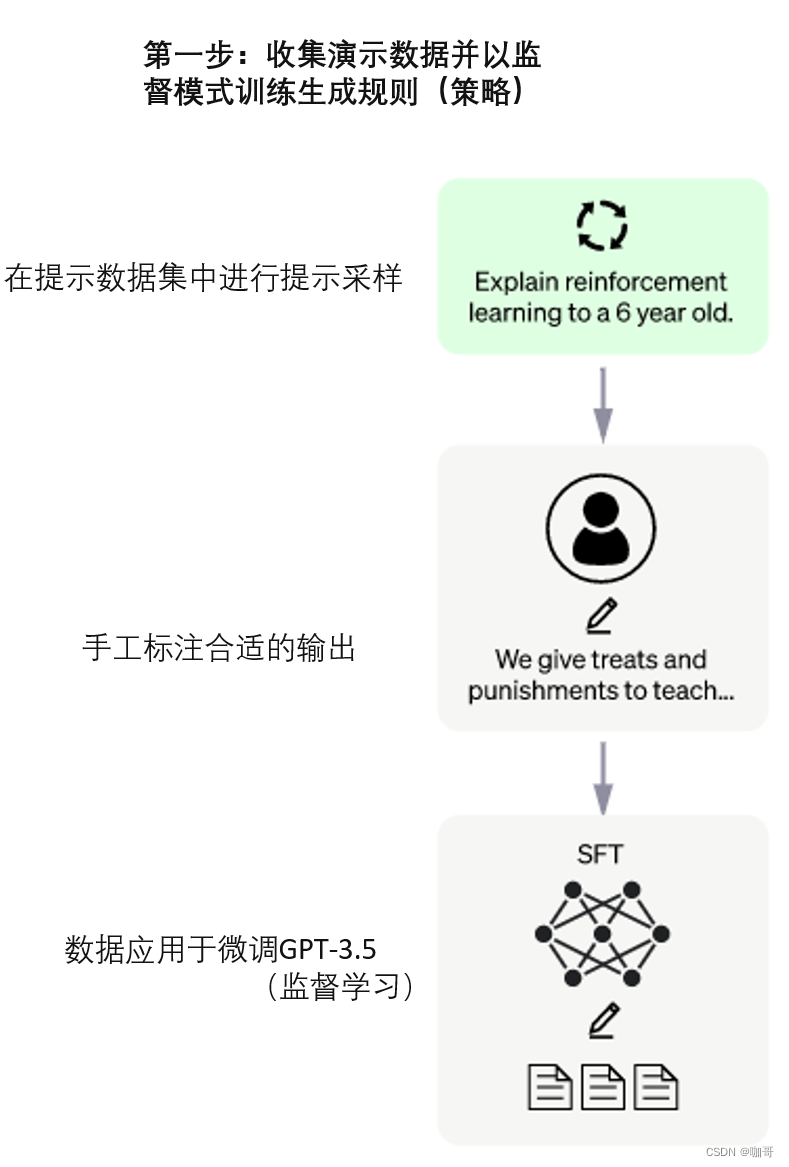
第一步:收集演示数据并以监督模式训练生成规则(策略)。第一步对应于通过监督学习获得的 GPT-3.5 模型的微调。这种调整是使用问题/答案对完成的。问题由系统从问题数据库中自动提供,AI 培训师(标注员)负责回答问题。他们让培训师获得建议(来自模型)以帮助他们撰写答案。该团队选择的方法是有监督的 Fune-Tuning,它通过对输入和输出数据的拟合来改进网络,调整模型的参数。
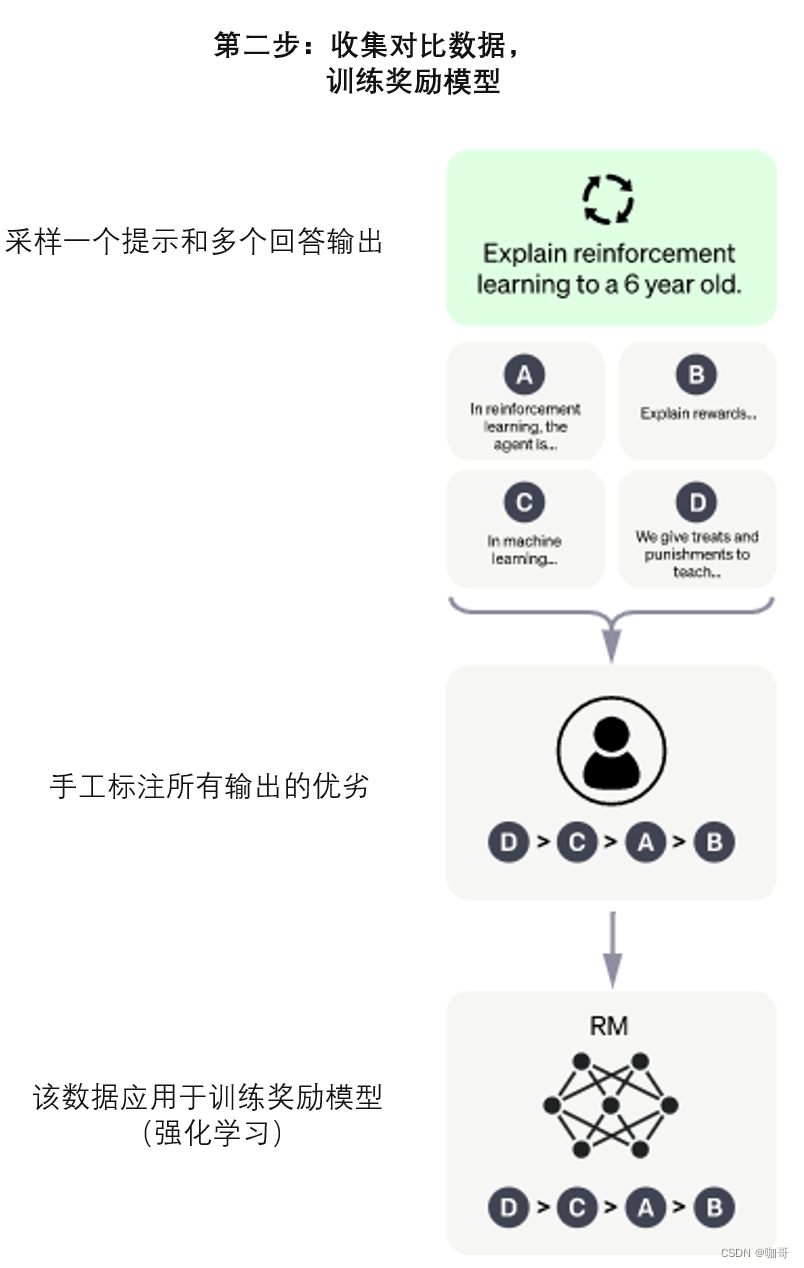
第二步:收集对比数据,训练奖励模型。第二步包括自动生成问题/答案对,并让 AI 培训师按照偏好对答案进行排序。系统生成两个答案,AI 培训师必须按质量降序排列。选择的方法是学习奖励模型,该模型根据生成的答案和 AI 培训师提供的命令工作。数据来自 AI 培训师与聊天机器人的对话。这些消息是随机选择的;抽取了几种可能的完成方式,并要求 AI 培训师对它们进行排名。
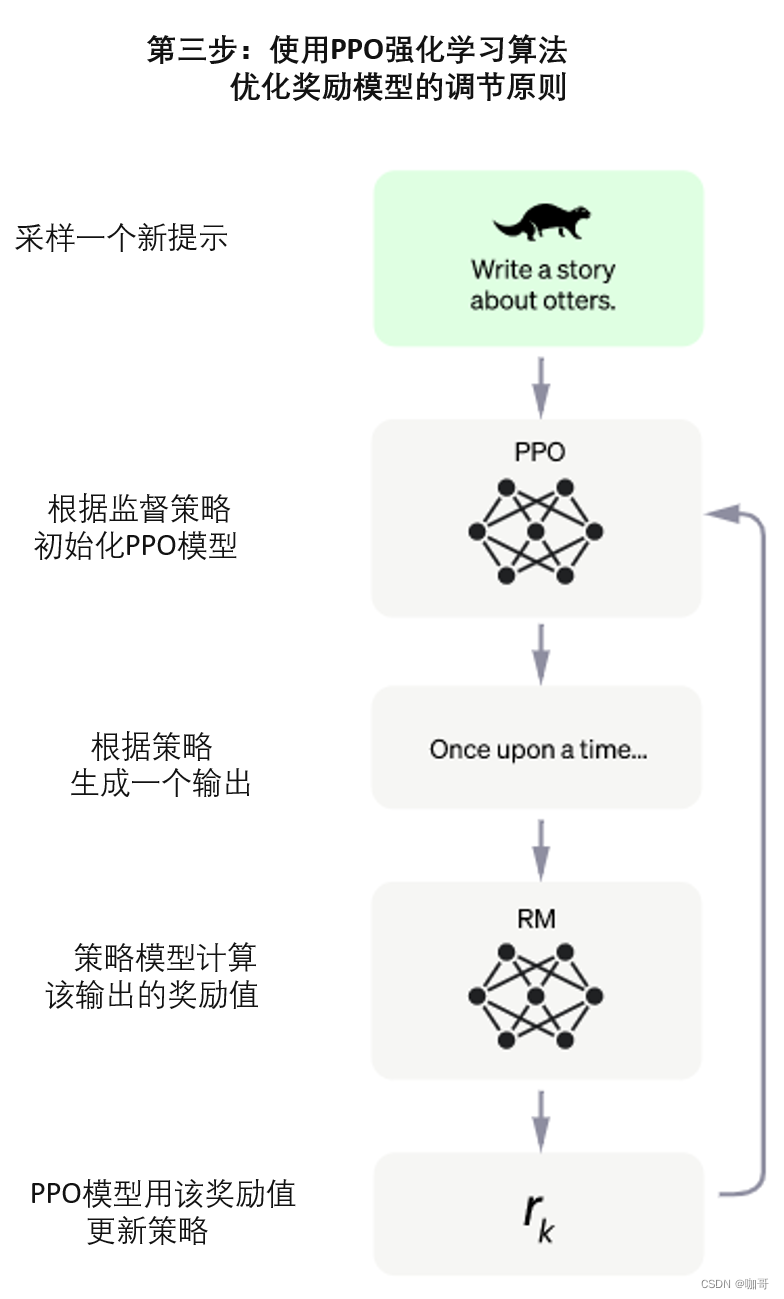
第三步也是最后一步:是使用强化学习机制,通过小步骤管理模型的规则和生成原则,这被称为近端策略优化 (PPO,Proximal Policy Optimization) 模型。模型的输入是来自数据库的问题,该模型生成由奖励模型评估的输出,然后将奖励注入生成规则管理模型以提高其性能。
这个过程的更多细节,参考OpenAI关于Instruct GPT的论文:Training language models to follow instructions with human feedback 。
总的来说,基于GPT 3所擅长的文本生成能力,再加上后续模型引入的代码生成和代码理解能力,再加上强大的对话上下文管理能力,再通过人类反馈强化学习 (RLHF),使ChatGPT可以从人类反馈中不断优化自己的表现,从而生成更加贴近人类需求和期望的对话回复,所以ChatGPT就演进成了今天我们看到的样子。
好,这就是我目前对ChatGPT这个令人敬佩的产品的认知与理解,后面我们期待开源的ChatGPT的到来,让我们更清楚的了解他的全部真相。
最后一点私心,夹带两个广告,都是我自己写的书,图片并茂,生动活泼,有趣有料。大家可以看一看是否需要。

零基础学机器学习

数据分析咖哥十话
《零基础学机器学习》,也是以咖哥为主人公,出版一年多以来,广受读者喜爱,已经是7次重印,豆瓣评分高达9.1分。作为一本入门书籍,实属佳作。而《数据分析咖哥十话》一书,沿袭了风趣、幽默、轻松的风格,写法上更上一层楼,把数据分析技术融入故事和实操当中,二者结合的更为巧妙。
相关文章:
ChatGPT原理与技术演进剖析
—— 要抓住一个风口,你得先了解这个风口的内核究竟是什么。本文作者:黄佳 (著有《零基础学机器学习》《数据分析咖哥十话》) ChatGPT相关文章已经铺天盖地,剖析(现阶段或者只能说揣测)其底层原…...
Retrofit+Hilt后端请求小项目1--项目介绍
简介 本项目根据 youtube 对应教程实现而来 将会对对应代码以及依赖(如 Hilt、retrofit、coil)进行详细的分析与解读,同时缕清项目结构安排 如文章有叙述不清晰的,请直接查看原教程:https://www.youtube.com/watch?…...
实际项目角度优化App性能
前言:前年替公司实现了一个在线检疫App,接下来一年时不时收到该App的需求功能迭代,部分线下问题跟进。随着新冠疫情防控政策放开,该项目也是下线了。 从技术角度来看,有自己的独特技术处理特点。下面我想记录一下该App…...
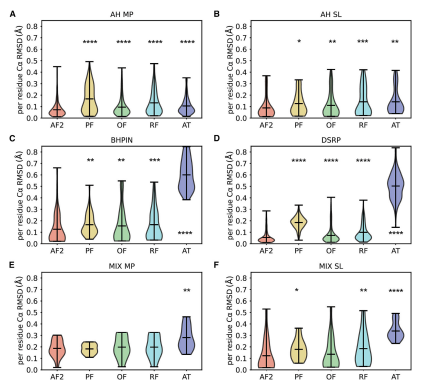
Structure|Alphafold2在肽结构预测任务上的基准实验
题目:Benchmarking AlphaFold2 on peptide structureprediction 文献来源:2023, Structure 31, 1–9 代码:基准实验,比较了比较多的模型 1.背景介绍 由2-50个氨基酸构成的聚合物可以称为肽。但是关于肽和蛋白质之间的差异还是…...

Simple XML
简介 官网:https://simple.sourceforge.net/home.php Github:https://github.com/ngallagher/simplexml Simple 是用于 Java 的高性能 XML 序列化和配置框架。它的目标是提供一个 XML 框架,使 XML 配置和通信系统的快速开发成为可能。该框架…...

在代码质量和工作效率的矛盾间如何取舍?
这个问题的答案是,在很短的一段时期,编写高质量代码似乎会拖慢我们的进度。与按照头脑中首先闪现的念头编写代码相比,高质量的代码需要更多的思考和努力。但如果我们编写的不仅仅是运行一次就抛之脑后的小程序,而是更有实质性的软…...

rabbitMq安装(小短文)--未完成
rabbitMq是在activeMq的基础上创造的,有前者的功能,比前者强,属于后来居上。系统环境:windows10首先下载相关软件Erlang,因为他是这个语言写的。https://www.erlang.org/downloads然后安装,并且弄到环境变量里验证是否…...

Python调用MMDetection实现AI抠图去背景
这篇文章的内容是以 《使用MMDetection进行目标检测、实例和全景分割》 为基础,需要安装好 MMDetection 的运行环境,同时完成目标检测、实例分割和全景分割的功能实践,之后再看下面的内容。 想要实现AI抠图去背景的需求,我们需要…...
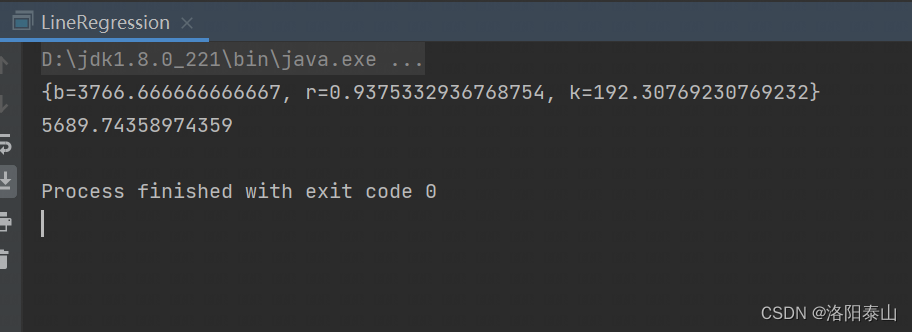
Java代码使用最小二乘法实现线性回归预测
最小二乘法简介最小二乘法是一种在误差估计、不确定度、系统辨识及预测、预报等数据处理诸多学科领域得到广泛应用的数学工具。它通过最小化误差(真实目标对象与拟合目标对象的差)的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数…...

linux-rockchip-音频相关
一、查看当前配置声卡状态 cat /proc/asound/cards二、查看当前声卡工作状态 声卡分两种通道,一种是Capture、一种是Playback。Capture是输入通道,Playback是输出通道。例如pcm0p属于声卡输出通道,pcm0c属于声卡输入通道。 ls /proc/asoun…...
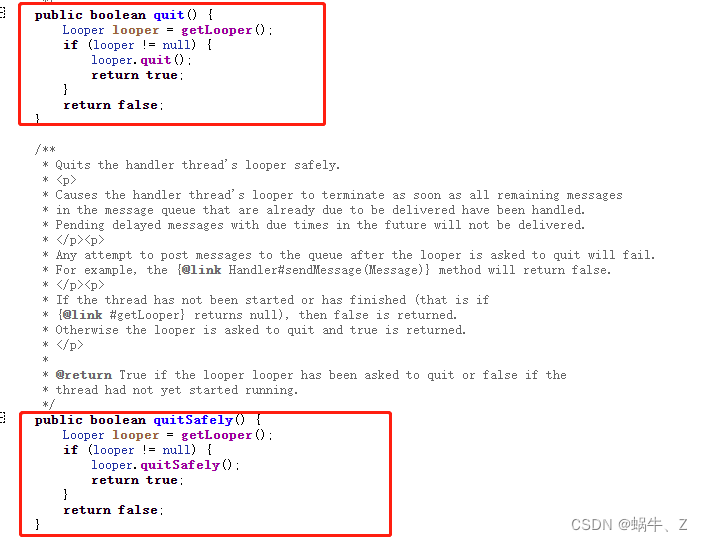
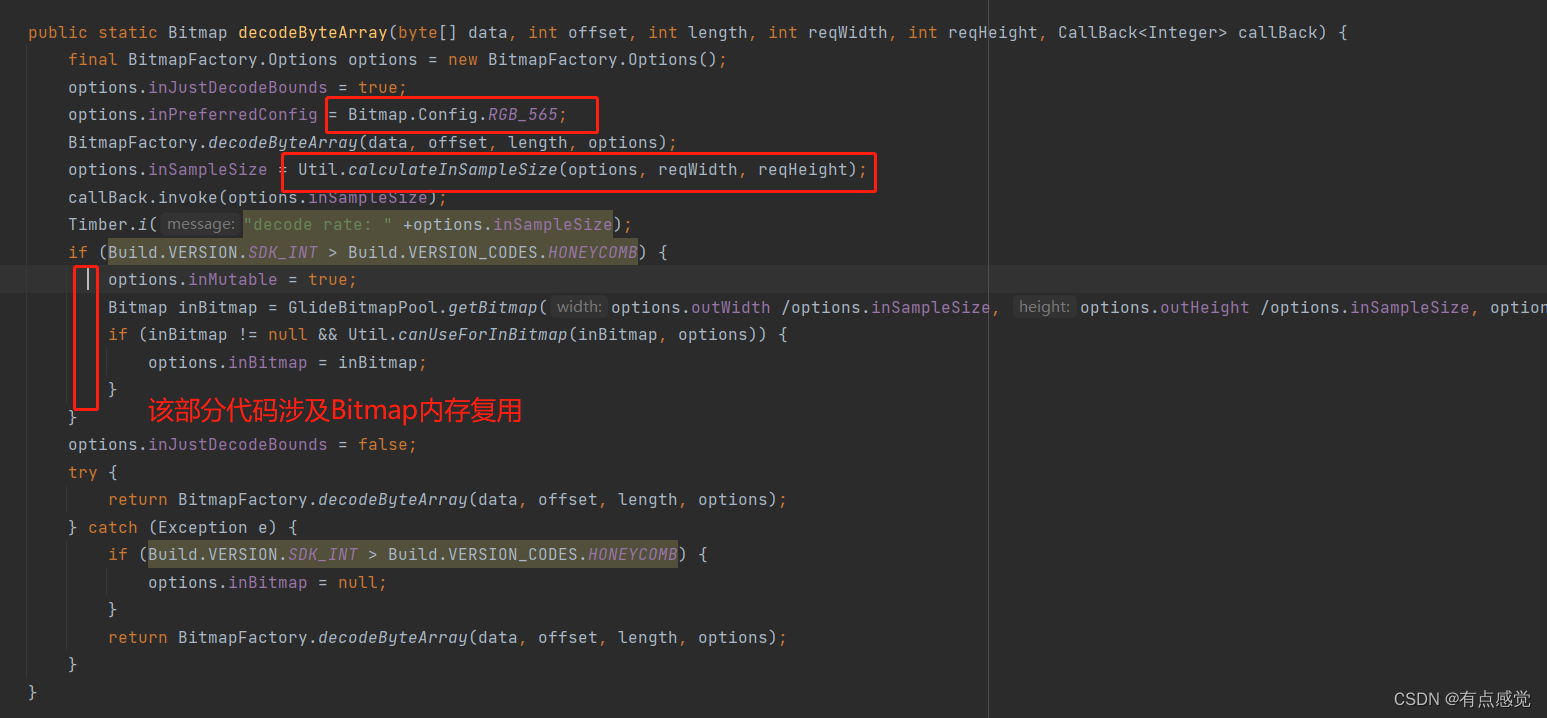
Android Handler的内存抖动以及子线程创建Handler
一、介绍 Handler,作为一个在主线程存活的消息分发工具,在App开发过程使用频率很高,也是面试问的比较多的。 面试常见的比如:子线程如何创建?Handler的机制是什么?内存抖动等,接下来我们会针对H…...

机器学习算法原理之k近邻 / KNN
文章目录k近邻 / KNN主要思想模型要素距离度量分类决策规则kd树主要思想kd树的构建kd树的搜索总结归纳k近邻 / KNN 主要思想 假定给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以根据其最近的 kkk 个训练实例的标签,…...
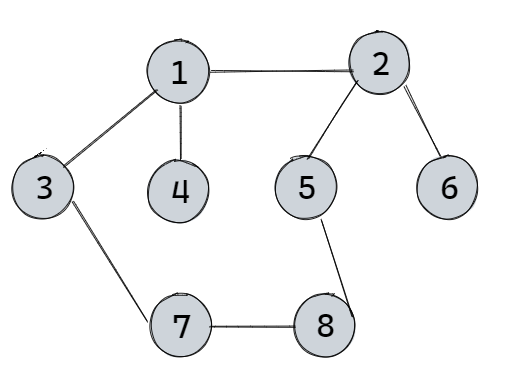
【期末复习】例题说明Prim算法与Kruskal算法
点睛Prim与Kruskal算法是用来求图的最小生成树的算法。最小生成树有n个顶点,n-1条边,不能有回路。Prim算法Prim算法的特点是从个体到整体,随机选定一个顶点为起始点出发,然后找它的权值最小的边对应的另一个顶点,这两个…...
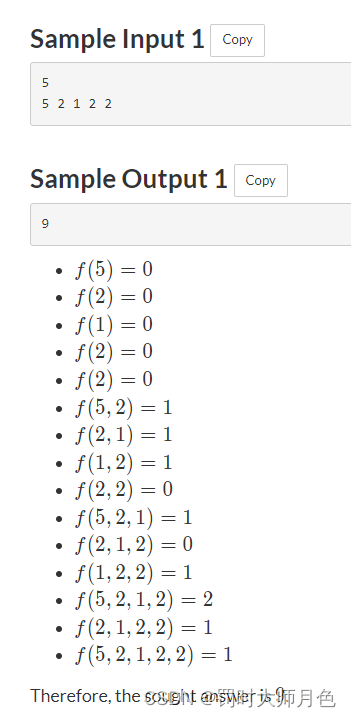
AtCoder Beginner Contest 290 A-E F只会n^2
ABC比较简单就不再复述 D - Marking 简要题意 :给你一个长度为nnn的数组,下标为0到n−10 到 n-10到n−1,最初指针位于0,重复执行n-1次操作,每次操作的定义为将当前指针加上ddd,如果该位置为空(未填数),否则我们向右找到第一个为空…...
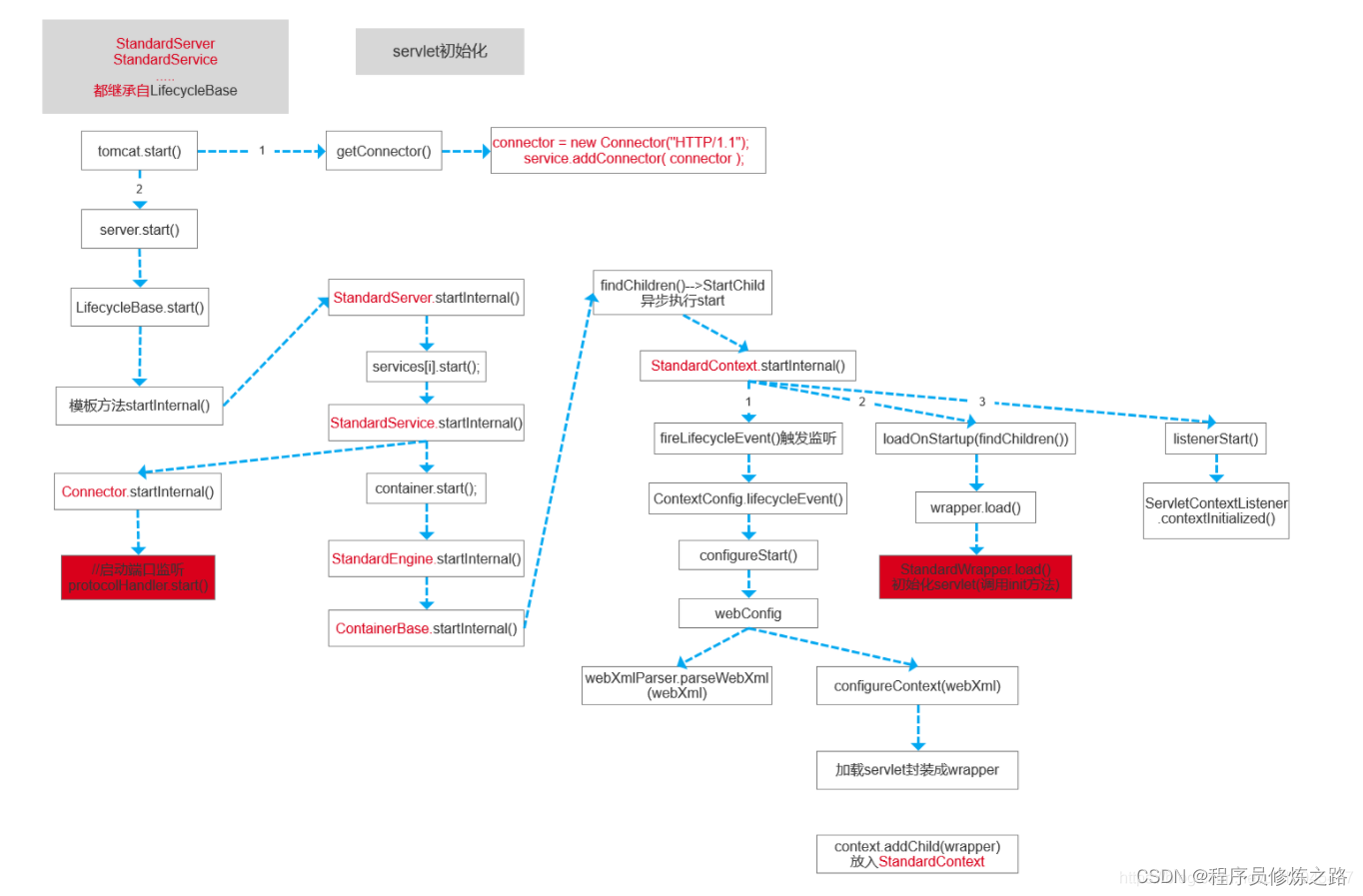
springMvc源码解析
入口:找到springboot的自动配置,将DispatcherServlet和DispatcherServletRegistrationBean注入spring容器(DispatcherServletRegistrationBean间接实现了ServletContextInitializer接口,最终ServletContextInitializer的onStartup…...
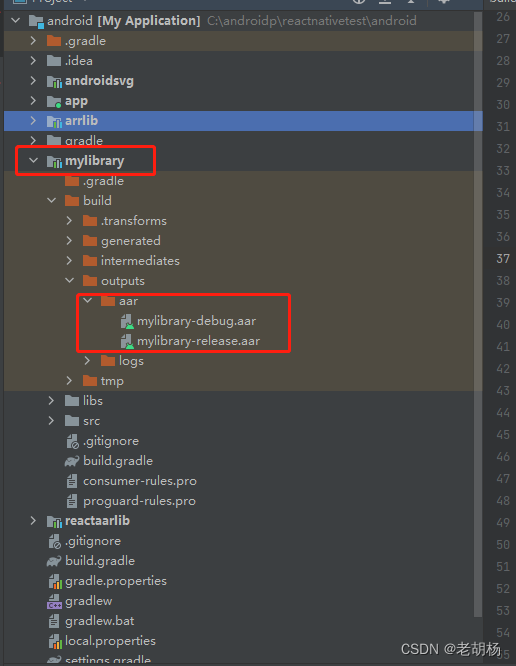
采用aar方式将react-native集成到已有安卓APP
关于react-native和android的开发环境搭建、环境变量配置等可以查看官方文档。 官方文档地址 文章中涉及的node、react等版本: node:v16.18.1 react:^18.1.0 react-native:^0.70.6 gradle:gradle-7.2开发工具:VSCode和android studio 关于react-native和…...
Tomcat目录介绍,结构目录有哪些?哪些常用?
bin 启动,关闭和其他脚本。这些 .sh文件(对于Unix系统)是这些.bat文件的功能副本(对于Windows系统)。由于Win32命令行缺少某些功能,因此此处包含一些其他文件。 比如说:windows下启动tomcat用的…...
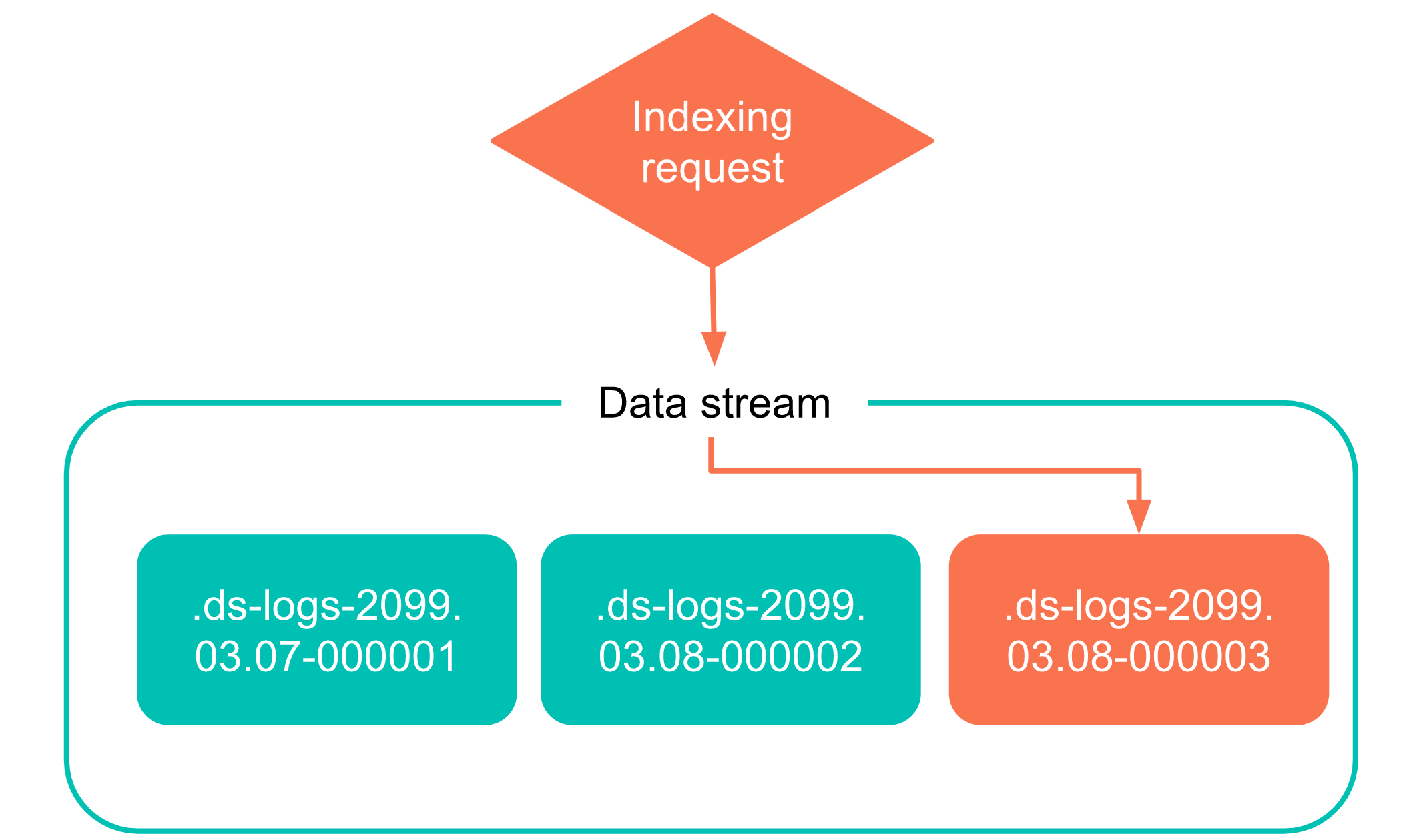
Elasticsearch也能“分库分表“,rollover实现自动分索引
一、自动创建新索引的方法 MySQL的分库分表大家是非常熟悉的,在Elasticserach中有存在类似的场景需求。为了不让单个索引太过于庞大,从而引发性能变差等问题,我们常常有根据索引大小、时间等创建新索引的需求,解决方案一般有两个…...

6 大经典机器学习数据集,3w+ 用户票选得出,建议收藏
内容一览:本期汇总了超神经下载排名众多的 6 个数据集,涵盖图像识别、机器翻译、遥感影像等领域。这些数据集质量高、数据量大,经历人气认证值得收藏码住。 关键词:数据集 机器翻译 机器视觉 数据集是机器学习模型训练的基础&…...

Logview下载
Logview下载 之前一直用的NotePad 后来偶尔的看到作者有发布不当言论 就卸载了又去下载了NotePad– 但是,其实不管是 还是 – 打开大一些的文件都会卡死 所以就搜了这个logview 用起来还不错,目前我这再大的文件 这个软件都是秒打开 但是也会有一点点小…...

【2026新版】 DirectX Repair 修复工具操作步骤【图文教程】,DirectX修复工具彻底解决DirectX报错与游戏闪退
DLL缺失、游戏闪退及DirectX错误 要怎么处理?DirectX修复工具可以快速修复DLL缺失、游戏闪退及DirectX错误,支持一键扫描和自动修复。DirectX修复工具是一款专门给 Windows 系统打补丁的小程序,可以把电脑里缺失或损坏的 DirectX 文件重新补全…...

结合YOLOv8的目标检测:为LiuJuan生成画作智能添加题跋与印章
结合YOLOv8的目标检测:为AI生成画作智能添加题跋与印章 1. 引言 想象一下,你刚用AI工具生成了一幅意境优美的山水画,画中山水空灵,笔触细腻,颇有几分古意。但总觉得少了点什么——对,就是那种传统国画特有…...

零基础新手如何借助快马ai编程迈出代码第一步
作为一个零编程基础的新手,第一次接触代码时难免会感到迷茫。最近尝试用InsCode(快马)平台搭建个人博客网站,发现整个过程比想象中简单很多。下面分享我的实践过程,希望能帮助同样想入门的朋友。 理解基础概念 刚开始连"框架"是什么…...

实测Nanbeige 4.1-3B WebUI:浅灰蓝波点背景+呼吸阴影效果惊艳
实测Nanbeige 4.1-3B WebUI:浅灰蓝波点背景呼吸阴影效果惊艳 1. 极简美学与功能设计的完美融合 第一次打开这个WebUI时,最直观的感受就是它完全颠覆了我对本地大模型界面的刻板印象。传统的部署方案往往只关注功能实现,界面设计几乎都是千篇…...

电子系统设计中7种经典电路接口详解与应用
1. 电路接口概述:信号传输的关键桥梁在电子系统设计中,不同模块间的数据交换就像城市间的交通网络,需要标准化的"道路规则"来确保信息高效流通。实际工程中常遇到三大类信号传输问题:时序不同步(如CPU与外设…...

C++模板元编程在编译期计算与类型安全泛型设计中的应用实践
C模板元编程在编译期计算与类型安全泛型设计中的应用实践 C模板元编程(TMP)作为现代C的核心技术之一,通过将计算从运行时转移到编译期,显著提升了程序性能和类型安全性。尤其在泛型设计中,TMP能够实现复杂的类型推导与…...

OpenClaw会议小秘书:Qwen3.5-9B自动生成待办事项
OpenClaw会议小秘书:Qwen3.5-9B自动生成待办事项 1. 为什么需要会议自动化助手 每周三下午的组会结束后,我的记事本上总是密密麻麻写满了待办事项。但问题在于——这些潦草的手写笔记有30%的概率会丢失,50%的概率会忘记执行截止时间。直到上…...
)
JDK 1.8 vs JDK 17:jvisualvm 安装配置全攻略(附Visual GC插件避坑指南)
JDK 1.8 vs JDK 17:jvisualvm 安装配置全攻略(附Visual GC插件避坑指南) 在Java开发的世界里,JVM性能调优一直是开发者进阶的必修课。而jvisualvm作为Oracle官方提供的免费性能分析工具,可以说是我们窥探JVM内部运行状…...

永磁同步电机PMSM无感FOC控制:扩展卡尔曼滤波器EKF观测器,代码运行无错,支持无感启动...
永磁同步电机pmsm无感foc控制,观测器采用扩展卡尔曼滤波器ekf,代码运行无错误,支持无感启动,代码移植性强,可以移植到国产mcu上.—— 从“功能”视角看透 ARM 官方 5 套 demo 一、写作目的 很多开发者拿到 CMSIS-DSP 例…...

基于STM32的简易示波器设计与实现
1. 项目概述 这个基于STM32的开源简易示波器项目,是我最近用正点原子精英板完成的一个实用工具开发。作为一个嵌入式开发者,我经常需要观察各种信号波形,但专业示波器价格昂贵且不便携。于是决定自己动手做一个成本低廉、功能实用的简易示波器…...