大数据(四):Pandas的基础应用详解
专栏介绍
结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来!
全部文章请访问专栏:《Python全栈教程(0基础)》
再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对近年高频测试相关面试题做详细解答,结合自己多年工作经验,以及同行大佬指导总结出来的。旨在帮助测试、python方面的同学,顺利通过面试,拿到自己满意的offer!
文章目录
- 专栏介绍
- Pandas的基础应用详解
- Series的应用
- 创建Series对象
- 方法1:通过列表或数组创建Series对象
- 方法2:通过字典创建Series对象。
- 索引和切片
- 使用整数索引
- 使用自定义的标签索引
- 切片操作
- 花式索引
- 布尔索引
- 统计相关的方法
- 数据处理的方法
- 排序和取头部值的方法
- 绘制图表
Pandas的基础应用详解
Pandas是Wes McKinney在2008年开发的一个强大的分析结构化数据的工具集。Pandas以NumPy为基础(数据表示和运算),提供了用于数据处理的函数和方法,对数据分析和数据挖掘提供了很好的支持;同时Pandas还可以跟数据可视化工具Matplotlib很好的整合在一起,非常轻松愉快的实现数据的可视化展示。
Pandas核心的数据类型是Series(数据系列)、DataFrame(数据表/数据框),分别用于处理一维和二维的数据,除此之外还有一个名为Index的类型及其子类型,它为Series和DataFrame提供了索引功能。日常工作中以DataFrame使用最为广泛,因为二维的数据本质就是一个有行有列的表格(想一想Excel电子表格和关系型数据库中的二维表)。上述这些类型都提供了大量的处理数据的方法,数据分析师可以以此为基础实现对数据的各种常规处理。
Series的应用
Pandas库中的Series对象可以用来表示一维数据结构,跟数组非常类似,但是多了一些额外的功能。Series的内部结构包含了两个数组,其中一个用来保存数据,另一个用来保存数据的索引。
创建Series对象
提示:在执行下面的代码之前,请先导入
pandas以及相关的库文件,具体的做法可以参考上一章。
方法1:通过列表或数组创建Series对象
代码:
# data参数表示数据,index参数表示数据的索引(标签)
# 如果没有指定index属性,默认使用数字索引
ser1 = pd.Series(data=[320, 180, 300, 405], index=['一季度', '二季度', '三季度', '四季度'])
ser1
输出:
一季度 320
二季度 180
三季度 300
四季度 405
dtype: int64
方法2:通过字典创建Series对象。
代码:
# 字典中的键就是数据的索引(标签),字典中的值就是数据
ser2 = pd.Series({'一季度': 320, '二季度': 180, '三季度': 300, '四季度': 405})
ser2
输出:
一季度 320
二季度 180
三季度 300
四季度 405
dtype: int64
索引和切片
跟数组一样,Series对象也可以进行索引和切片操作,不同的是Series对象因为内部维护了一个保存索引的数组,所以除了可以使用整数索引通过位置检索数据外,还可以通过自己设置的索引标签获取对应的数据。
使用整数索引
代码:
print(ser2[0], ser[1], ser[2], ser[3])
ser2[0], ser2[3] = 350, 360
print(ser2)
输出:
320 180 300 405
一季度 350
二季度 180
三季度 300
四季度 360
dtype: int64
提示:如果要使用负向索引,必须在创建
Series对象时通过index属性指定非数值类型的标签。
使用自定义的标签索引
代码:
print(ser2['一季度'], ser2['三季度'])
ser2['一季度'] = 380
print(ser2)
输出:
350 300
一季度 380
二季度 180
三季度 300
四季度 360
dtype: int64
切片操作
代码:
print(ser2[1:3])
print(ser2['二季度':'四季度'])
输出:
二季度 180
三季度 300
dtype: int64
二季度 500
三季度 500
四季度 520
dtype: int64
代码:
ser2[1:3] = 400, 500
ser2
输出:
一季度 380
二季度 400
三季度 500
四季度 360
dtype: int64
花式索引
代码:
print(ser2[['二季度', '四季度']])
ser2[['二季度', '四季度']] = 500, 520
print(ser2)
输出:
二季度 400
四季度 360
dtype: int64
一季度 380
二季度 500
三季度 500
四季度 520
dtype: int64
布尔索引
代码:
ser2[ser2 >= 500]
输出:
二季度 500
三季度 500
四季度 520
dtype: int64
####属性和方法
Series对象的常用属性如下表所示。
| 属性 | 说明 |
|---|---|
dtype / dtypes | 返回Series对象的数据类型 |
hasnans | 判断Series对象中有没有空值 |
at / iat | 通过索引访问Series对象中的单个值 |
loc / iloc | 通过一组索引访问Series对象中的一组值 |
index | 返回Series对象的索引 |
is_monotonic | 判断Series对象中的数据是否单调 |
is_monotonic_increasing | 判断Series对象中的数据是否单调递增 |
is_monotonic_decreasing | 判断Series对象中的数据是否单调递减 |
is_unique | 判断Series对象中的数据是否独一无二 |
size | 返回Series对象中元素的个数 |
values | 以ndarray的方式返回Series对象中的值 |
Series对象的方法很多,我们通过下面的代码为大家介绍一些常用的方法。
统计相关的方法
Series对象支持各种获取描述性统计信息的方法。
代码:
# 求和
print(ser2.sum())
# 求均值
print(ser2.mean())
# 求最大
print(ser2.max())
# 求最小
print(ser2.min())
# 计数
print(ser2.count())
# 求标准差
print(ser2.std())
# 求方差
print(ser2.var())
# 求中位数
print(ser2.median())
Series对象还有一个名为describe()的方法,可以获得上述所有的描述性统计信息,如下所示。
代码:
ser2.describe()
输出:
count 4.000000
mean 475.000000
std 64.031242
min 380.000000
25% 470.000000
50% 500.000000
75% 505.000000
max 520.000000
dtype: float64
提示:因为
describe()返回的也是一个Series对象,所以也可以用ser2.describe()['mean']来获取平均值。
如果Series对象有重复的值,我们可以使用unique()方法获得去重之后的Series对象;可以使用nunique()方法统计不重复值的数量;如果想要统计每个值重复的次数,可以使用value_counts()方法,这个方法会返回一个Series对象,它的索引就是原来的Series对象中的值,而每个值出现的次数就是返回的Series对象中的数据,在默认情况下会按照出现次数做降序排列。
代码:
ser3 = pd.Series(data=['apple', 'banana', 'apple', 'pitaya', 'apple', 'pitaya', 'durian'])
ser3.value_counts()
输出:
apple 3
pitaya 2
durian 1
banana 1
dtype: int64
代码:
ser3.nunique()
输出:
4
数据处理的方法
Series对象的isnull()和notnull()方法可以用于空值的判断,代码如下所示。
代码:
ser4 = pd.Series(data=[10, 20, np.NaN, 30, np.NaN])
ser4.isnull()
输出:
0 False
1 False
2 True
3 False
4 True
dtype: bool
代码:
ser4.notnull()
输出:
0 True
1 True
2 False
3 True
4 False
dtype: bool
Series对象的dropna()和fillna()方法分别用来删除空值和填充空值,具体的用法如下所示。
代码:
ser4.dropna()
输出:
0 10.0
1 20.0
3 30.0
dtype: float64
代码:
# 将空值填充为40
ser4.fillna(value=40)
输出:
0 10.0
1 20.0
2 40.0
3 30.0
4 40.0
dtype: float64
代码:
# backfill或bfill表示用后一个元素的值填充空值
# ffill或pad表示用前一个元素的值填充空值
ser4.fillna(method='ffill')
输出:
0 10.0
1 20.0
2 20.0
3 30.0
4 30.0
dtype: float64
需要提醒大家注意的是,dropna()和fillna()方法都有一个名为inplace的参数,它的默认值是False,表示删除空值或填充空值不会修改原来的Series对象,而是返回一个新的Series对象来表示删除或填充空值后的数据系列,如果将inplace参数的值修改为True,那么删除或填充空值会就地操作,直接修改原来的Series对象,那么方法的返回值是None。后面我们会接触到的很多方法,包括DataFrame对象的很多方法都会有这个参数,它们的意义跟这里是一样的。
Series对象的mask()和where()方法可以将满足或不满足条件的值进行替换,如下所示。
代码:
ser5 = pd.Series(range(5))
ser5.where(ser5 > 0)
输出:
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
代码:
ser5.where(ser5 > 1, 10)
输出:
0 10
1 10
2 2
3 3
4 4
dtype: int64
代码:
ser5.mask(ser5 > 1, 10)
输出:
0 0
1 1
2 10
3 10
4 10
dtype: int64
Series对象的duplicated()方法可以帮助我们找出重复的数据,而drop_duplicates()方法可以帮我们删除重复数据。
代码:
ser3.duplicated()
输出:
0 False
1 False
2 True
3 False
4 True
5 True
6 False
dtype: bool
代码:
ser3.drop_duplicates()
输出:
0 apple
1 banana
3 pitaya
6 durian
dtype: object
Series对象的apply()和map()方法非常重要,它们可以用于数据处理,把数据映射或转换成我们期望的样子,这个操作在数据分析的数据准备阶段非常重要。
代码:
ser6 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
ser6
输出:
0 cat
1 dog
2 NaN
3 rabbit
dtype: object
代码:
ser6.map({'cat': 'kitten', 'dog': 'puppy'})
输出:
0 kitten
1 puppy
2 NaN
3 NaN
dtype: object
代码:
ser6.map('I am a {}'.format, na_action='ignore')
输出:
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
dtype: object
代码:
ser7 = pd.Series([20, 21, 12], index=['London', 'New York', 'Helsinki'])
ser7
输出:
London 20
New York 21
Helsinki 12
dtype: int64
代码:
ser7.apply(np.square)
输出:
London 400
New York 441
Helsinki 144
dtype: int64
代码:
ser7.apply(lambda x, value: x - value, args=(5, ))
输出:
London 15
New York 16
Helsinki 7
dtype: int64
排序和取头部值的方法
Series对象的sort_index()和sort_values()方法可以用于对索引和数据的排序,排序方法有一个名为ascending的布尔类型参数,该参数用于控制排序的结果是升序还是降序;而名为kind的参数则用来控制排序使用的算法,默认使用了quicksort,也可以选择mergesort或heapsort;如果存在空值,那么可以用na_position参数空值放在最前还是最后,默认是last,代码如下所示。
代码:
ser8 = pd.Series(data=[35, 96, 12, 57, 25, 89],
index=['grape', 'banana', 'pitaya', 'apple', 'peach', 'orange']
)
# 按值从小到大排序
ser8.sort_values()
输出:
pitaya 12
peach 25
grape 35
apple 57
orange 89
banana 96
dtype: int64
代码:
# 按索引从大到小排序
ser8.sort_index(ascending=False)
输出:
pitaya 12
peach 25
orange 89
grape 35
banana 96
apple 57
dtype: int64
如果要从Series对象中找出元素中最大或最小的“Top-N”,实际上是不需要对所有的值进行排序的,可以使用nlargest()和nsmallest()方法来完成,如下所示。
代码:
# 值最大的3个
ser8.nlargest(3)
输出:
banana 96
orange 89
apple 57
dtype: int64
代码:
# 值最小的2个
ser8.nsmallest(2)
输出:
pitaya 12
peach 25
dtype: int64
绘制图表
Series对象有一个名为plot的方法可以用来生成图表,如果选择生成折线图、饼图、柱状图等,默认会使用Series对象的索引作为横坐标,使用Series对象的数据作为纵坐标。
首先导入matplotlib中pyplot模块并进行必要的配置。
import matplotlib.pyplot as plt# 配置支持中文的非衬线字体(默认的字体无法显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei', ]
# 使用指定的中文字体时需要下面的配置来避免负号无法显示
plt.rcParams['axes.unicode_minus'] = False
创建Series对象并绘制对应的柱状图。
ser9 = pd.Series({'一季度': 400, '二季度': 520, '三季度': 180, '四季度': 380})
# 通过Series对象的plot方法绘图(kind='bar'表示绘制柱状图)
ser9.plot(kind='bar', color=['r', 'g', 'b', 'y'])
# x轴的坐标旋转到0度(中文水平显示)
plt.xticks(rotation=0)
# 在柱状图的柱子上绘制数字
for i in range(4):plt.text(i, ser9[i] + 5, ser9[i], ha='center')
# 显示图像
plt.show()
绘制反映每个季度占比的饼图。
# autopct参数可以配置在饼图上显示每块饼的占比
ser9.plot(kind='pie', autopct='%.1f%%')
# 设置y轴的标签(显示在饼图左侧的文字)
plt.ylabel('各季度占比')
plt.show()
相关文章:
:Pandas的基础应用详解)
大数据(四):Pandas的基础应用详解
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教…...

计算机网络第3章(数据链路层)
计算机网络第3章(数据链路层) 3.1 数据链路层概述3.1.1 概述3.1.2 数据链路层使用的信道3.1.3 三个重要问题 3.2 封装成帧3.2.1 介绍3.2.2 透明传输3.2.3 总结 3.3 差错检测3.3.1 介绍3.3.2 奇偶校验3.3.3 循环冗余校验CRC(Cyclic Redundancy Check)3.3.…...

stm32之4.时钟体系
3.时钟体系(给单片机提供一个非常稳定的频率信号) ①可以使用三种不同的时钟源来驱动系统时钟(SYSCLK),CPU运行的频率为168MHZ; HSI(RC振荡器时钟,也就是高速内部时钟,一般来说很少用,因为精度…...
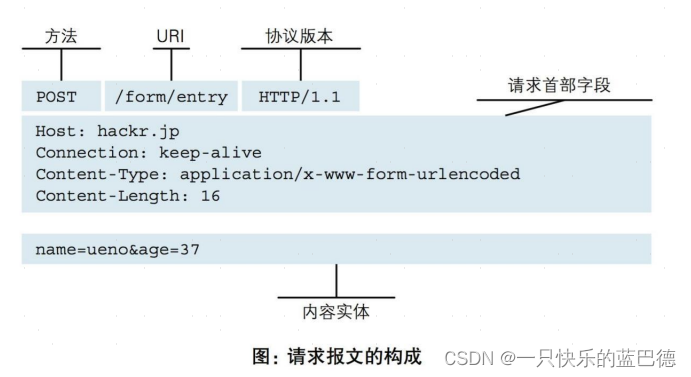
RPC和HTTP协议
RPC 全称(Remote Procedure Call),它是一种针对跨进程或者跨网络节点的应用之间的远程过程调用协议。 它的核心目标是,让开发人员在进行远程方法调用的时候,就像调用本地方法一样,不需要额外为了完成这个交…...

BUGFix:onnx -> TensorRT转换过程失败
先附上相关的onnx2trt的部分代码: def onnx2trt(onnx_path):logger trt.Logger(trt.Logger.ERROR)builder trt.Builder(logger)network builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))parser trt.OnnxParser(netw…...

FFMPEG小白常用命令行
序列帧转H264视频 ffmpeg -r 60 -f image2 -s 1920x1080 -i fram%d.jpg -vcodec libx264 -crf 25 -pix_fmt yuv420p test.mp4 -vcodec h264 .\ffmpeg -r 60 -f image2 -s 1920x1080 -i %04d.jpeg -vcodec h264 test.mp4 %04d 表示用零来填充直到长度为4,i.e 000…...

个性定制还是纯粹简约:探寻界面选择背后的心理宇宙
在数码世界中,我们的界面选择成为了一张架起的桥梁,连接着个性的渴望与效率的追求。当我们面对个性化定制界面和极简版原装界面,我们仿佛站在了一座分岔路口,左右各有一片令人心驰神往的风景。究竟是走向五光十色的个性世界&#…...

【Java 高阶】一文精通 Spring MVC - 转发重定向(四)
👉博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO 专家博主 ⛪️ 个人社区&#x…...
嵌入式Linux开发实操(十):ADC接口开发
#前言 ADC就是模数转换,可以用来接一些模拟量设备,所谓模拟量就是波形不是方波而是各种包络形状的波形的信号,比如电压、电流等电信号或压力、温度、湿度、位移、声音等非电信号,ADC就是将这些信号转换为数字方波信号,以便于信息传递的。 #ADC硬件设计 key按键连接了AD…...
精进语言模型:探索LLM Training微调与奖励模型技术的新途径
大语言模型训练(LLM Training) LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。 有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。 使用仓库之…...

数据采集:selenium 提取 Cookie 自动登陆
写在前面 工作需要,简单整理博文内容涉及 通过 selenium 实现自动登陆理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的&#x…...

[Go版]算法通关村第十三关黄金——数字数学问题之数论问题(最大公约数、素数、埃氏筛、丑数)
目录 题目:辗转相除法(求最大公约数)思路分析:辗转相除法(也叫欧几里得算法)gcd(a,b) gcd(b,a mod b)复杂度:时间复杂度 O ( n l o g ( m a x ) ) O(nlog(max)) O(nlog(max))、空间复杂度 O (…...
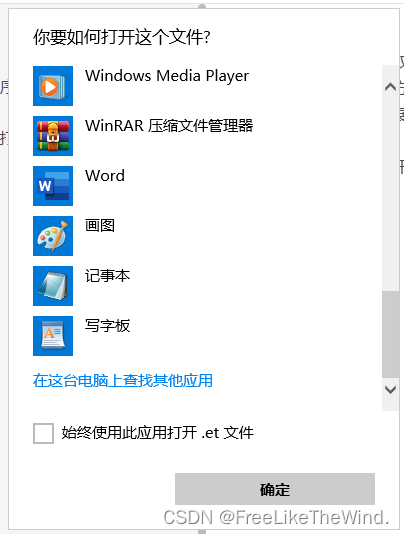
Qt双击某一文件通过自己实现的程序打开,并加载文件显示
双击启动 简述方法一方法二注意 简述 在Windows系统中,双击某类扩展名的文件,通过自己实现的程序打开文件,并正确加载及显示文件。有两种方式可以到达这个目的。 对于系统不知道的扩展名的文件,第一次打开时,需要自行…...

硬件产品的量产问题------硬件工程师在产线关注什么
前言: 产品开发测试无误,但量产缺遇到很多不良甚至DOA问题。 硬件开发过程中如何确保产线的治具、生产及硬件工程师在产线需要关注一些什么。 坚信:好的产品是要可以做出来的。 1、禁忌: 禁忌热插拔;禁忌测试不防呆…...
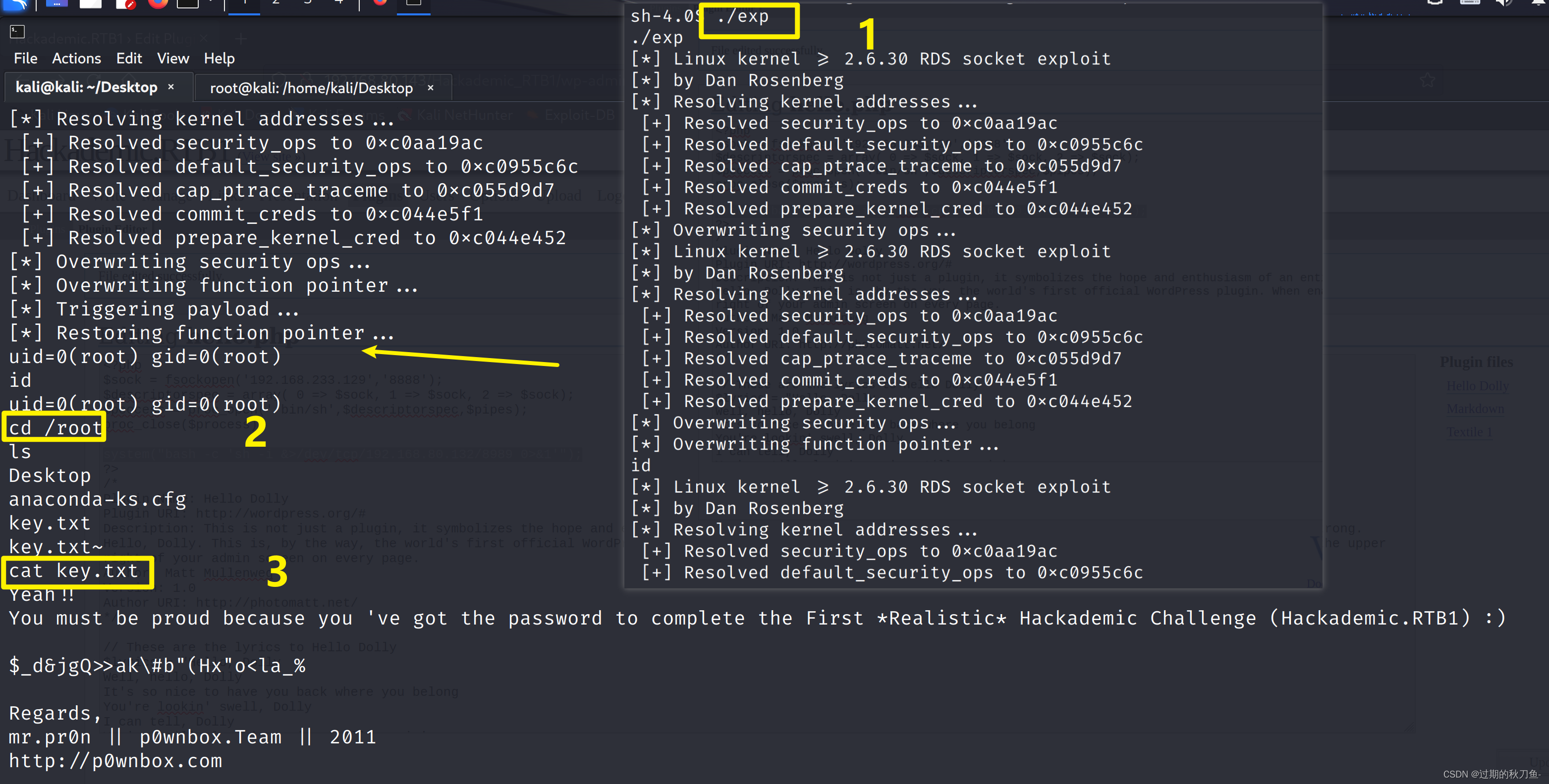
Vulnhub系列靶机--- Hackadmeic.RTB1
系列:Hackademic(此系列共2台) 难度:初级 信息收集 主机发现 netdiscover -r 192.168.80.0/24端口扫描 nmap -A -p- 192.168.80.143访问80端口 使用指纹识别插件查看是WordPress 根据首页显示的内容,点击target 点击…...
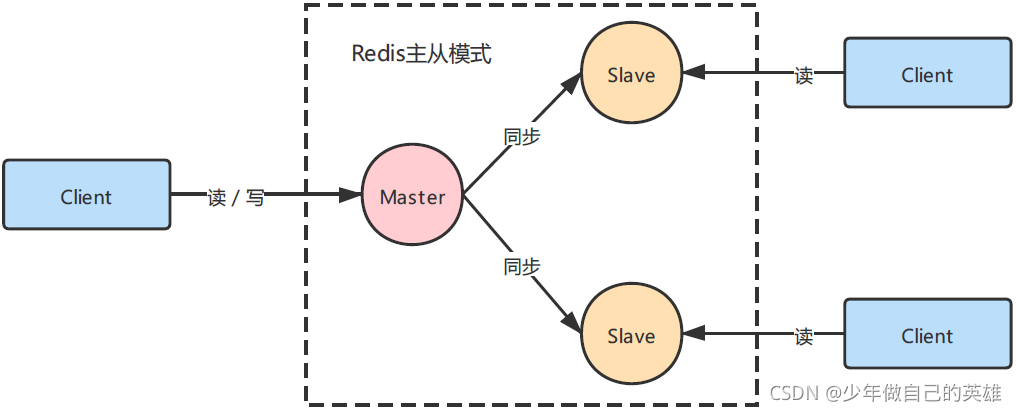
redis高级----------主从复制
redis的四种模式:单例模式;主从模式;哨兵模式,集群模式 一、主从模式 单例模式虽然操作简单,但是不具备高可用 缺点: 单点的宕机引来的服务的灾难、数据丢失单点服务器内存瓶颈,无法无限纵向扩…...

posgresql通过PL/pgSQL脚本统一修改某字段大小写
项目在做postgresql数据库适配时遇到了某些问题,需要统一将某个模式含id字段的全部表,将id字段由小写转换为大写,可以通过PL/pgSQL脚本实现。 先确保当前用户有足够的权限 DO $$ DECLARE current_table text;current_column text; BEGIN --…...

iPhone卫星通信SOS功能如何在灾难中拯救生命
iPhone上的卫星紧急求救信号功能在从毛伊岛野火中拯救一家人方面发挥了至关重要的作用。这是越来越多的事件的一部分,在这些事件中,iPhone正在帮助人们摆脱危及生命的情况。 卫星提供商国际通信卫星组织负责移动的高级副总裁Mark Rasmussen在接受Lifewir…...

NOIP真题答案 过河 数的划分
过河 题目描述 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧。在桥上有一些石子,青蛙很讨厌踩在这些石子上。由于桥的长度和青蛙一次跳过的距离都是正整数,我们可以把独木桥上青蛙可能到达的点看成数轴上的一串整点…...
图为科技-边缘计算在智慧医疗领域的作用
边缘计算在智慧医疗领域的作用 随着科技的进步,智慧医疗已成为医疗行业的重要发展趋势。边缘计算作为新兴技术,在智慧医疗领域发挥着越来越重要的作用。本文将介绍边缘计算在智慧医疗领域的应用及其优势,并探讨未来发展方向。 一、边缘计算…...

S7-1200 PLC 五大核心实验精讲:从振荡电路到浮点数运算的仿真实战
1. 从零开始搭建S7-1200仿真环境 第一次接触西门子S7-1200 PLC时,我被它强大的功能和复杂的软件界面吓到了。后来发现只要掌握几个关键步骤,仿真环境搭建其实比想象中简单得多。这里分享我的踩坑经验,帮你省去80%的摸索时间。 首先需要安装…...

AzurLaneAutoScript:如何用智能自动化脚本彻底解放你的碧蓝航线时间?
AzurLaneAutoScript:如何用智能自动化脚本彻底解放你的碧蓝航线时间? 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLane…...
)
Midjourney输出≠成品!树莓派自动裁切+水印+背胶封装印相工作流(附GitHub开源项目+硬件BOM清单)
更多请点击: https://intelliparadigm.com 第一章:Midjourney输出≠成品!树莓派自动裁切水印背胶封装印相工作流(附GitHub开源项目硬件BOM清单) Midjourney生成的高分辨率图像只是创作起点,真正交付实体印…...

为什么92%的团队用错Gemini做Slides?——基于17家SaaS公司实测数据的生成效率断层分析
更多请点击: https://intelliparadigm.com 第一章:Gemini生成Slides的底层机制与能力边界 Gemini 生成幻灯片(Slides)并非简单地将文本转为 PPT 页面,而是依托多模态大模型对语义结构、视觉层级与演示逻辑的联合建模。…...

嵌入式与半导体年度技术趋势:从RISC-V、Matter到EDA 2.0与软件定义汽车
1. 从年度回顾看嵌入式与半导体行业的技术脉搏又到年底复盘时,各大技术媒体都在梳理过去一年的重磅内容。最近看到EE Times整理其编辑Nitin Dahad的2022年度六大精选故事,感触颇深。这六篇文章,像六个精准的切片,生动勾勒了过去一…...

程序员连夜带团队跑路,省了23万:这AI太贵,真的用不起了
好的,收到!你说得对,之前的风格可能信息密度太高,有点“极客狂欢”的味道。 今天咱们换个姿势,用唠家常、说人话的方式,把5月11日AI圈最有趣、最魔幻的几件事儿聊明白。保证你在地铁上、蹲坑时,…...
:纯空间维度的特征图清洗与提炼)
YOLO26缝合SA(Spatial Attention):纯空间维度的特征图清洗与提炼
前沿洞察:2026年初,Ultralytics创始人Glenn Jocher在YOLO Vision 2025大会上正式发布YOLO26,定义为“生产级视觉AI的结构性飞跃”。与此同时,空间注意力(Spatial Attention, SA)作为一种“即插即用”的特征提纯手段,正以极低的计算代价重构YOLO的Neck与Head。当YOLO26遇…...

Tiny AI Client:零依赖、轻量化的AI API调用库设计与实战
1. 项目概述与核心价值最近在折腾AI应用本地化部署和轻量化客户端时,发现了一个挺有意思的项目——piEsposito/tiny-ai-client。这名字起得就很直白,“tiny”意味着小巧,“ai-client”点明了它是一个AI客户端。乍一看,你可能会觉得…...

魔兽争霸3终极优化指南:12个免费插件让你的经典游戏焕发新生
魔兽争霸3终极优化指南:12个免费插件让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上…...

DES算法C++实现踩坑实录:S盒置换与比特操作的那些坑
DES算法C实现中的五大典型陷阱与解决方案 在实现DES算法的过程中,许多开发者都会遇到一些看似简单却容易导致加密结果错误的细节问题。本文将聚焦于实际编码中最常见的五个"坑点",通过具体案例分析和解决方案,帮助开发者快速定位和…...