Kaggle系列之CIFAR-10图像识别分类(残差网络模型ResNet-18)
CIFAR-10数据集在计算机视觉领域是一个很重要的数据集,很有必要去熟悉它,我们来到Kaggle站点,进入到比赛页面:https://www.kaggle.com/competitions/cifar-10
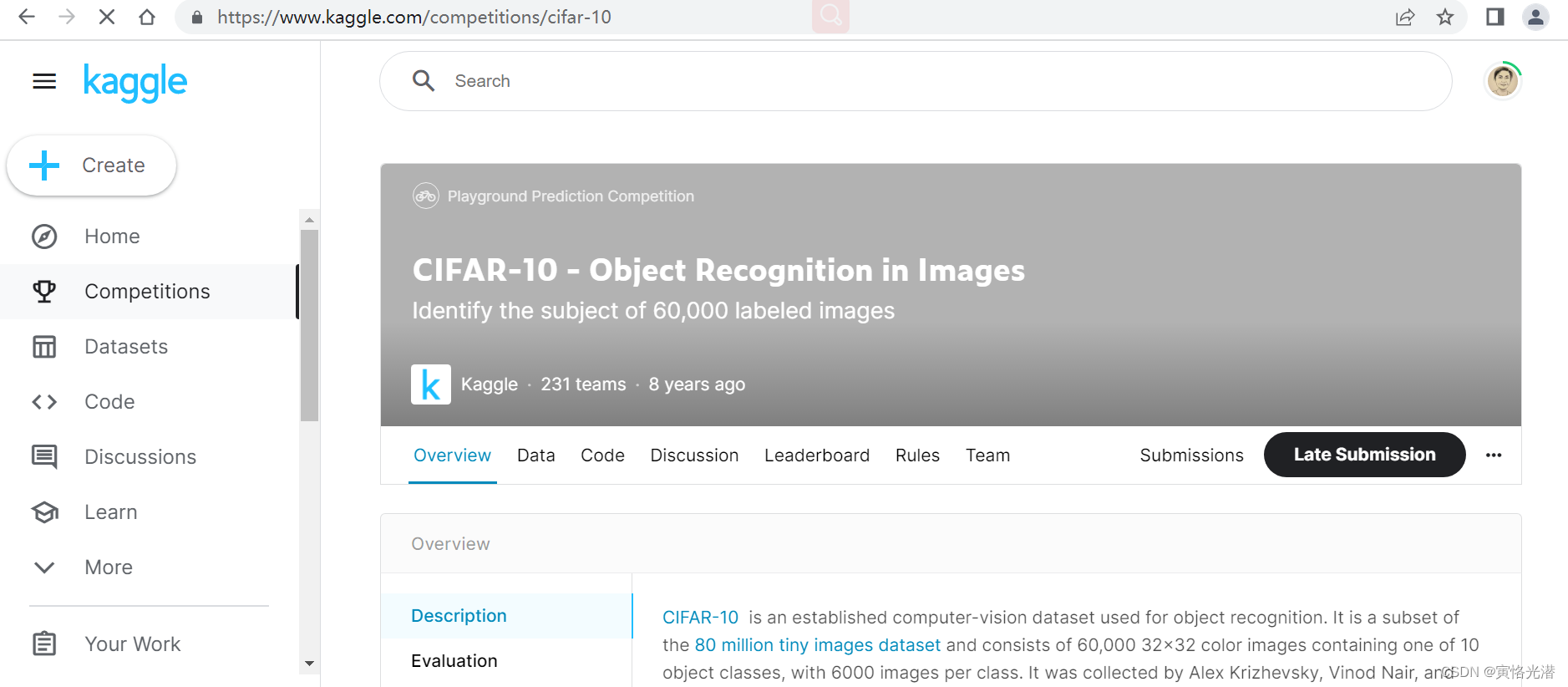
CIFAR-10是8000万小图像数据集的一个子集,由60000张32x32彩色图像组成,包含10个分类,每个类有6000张图像。
官方数据中有5万张训练图片和1万张测试图片。我们保留了原始数据集中的训练/测试分割
在Kaggle比赛提交的时候,为了阻止某些形式的作弊(比如手标),我们在测试集中添加了29万张垃圾图片。这些图像在评分时被忽略。我们还对官方的10000个测试图像进行了微小的修改,以防止通过文件散列查找它们。这些修改不应明显影响得分。您应该预测所有30万张图像的标签。
对于刷排行榜这些我们不用去管,秉持着学习为主的想法,我们来训练这个数据集。分成10个类别,分别为:airplane、automobile、bird、cat、deer、dog、frog、horse、ship、truck
这些类是完全相互排斥的,比如汽车和卡车之间没有重叠。automobile:包括轿车、suv之类的东西。truck:只包括大卡车。这两项都不包括皮卡车。
将下载的数据集放入到dataset目录,解压之后,在这个目录下面有train目录、test目录、trainLabels.csv标签文件,其中train里面是5万张图片、test里面是30万张图片
1、整理原始数据集
1.1读取训练集的标签文件
def read_label_file(data_dir,label_file,train_dir,valid_ratio):'''读取训练集的标签文件参数valid_ratio:验证集样本数与原始训练集样本数之比返回值n_train // len(labels):每个类多少张图片idx_label:50000个id:label的字典'''with open(os.path.join(data_dir,label_file),'r') as f:lines=f.readlines()[1:]tokens=[l.rstrip().split(',') for l in lines]idx_label=dict(((int(idx),label) for idx,label in tokens))#{'cat', 'ship', 'frog', 'dog', 'truck', 'deer', 'horse', 'bird', 'airplane', 'automobile'}labels=set(idx_label.values())#去重就是10个类别n_train_valid=len(os.listdir(os.path.join(data_dir,train_dir)))#50000n_train=int(n_train_valid*(1-valid_ratio))assert 0<n_train<n_train_validreturn n_train // len(labels),idx_label我们测试下,先熟悉下这个方法:
data_dir,label_file="dataset","trainLabels.csv"
train_dir,valid_ratio="train",0.1n_train_per_label,idx_label=read_label_file(data_dir,label_file,train_dir,valid_ratio)
print(n_train_per_label,idx_label)#4500,{id:label,...}读取标签文件,返回每个类有多少个训练样本(id:label这样的id对应标签的字典)
1.2切分验证数据集
上面读取标签的方法中有参数"valid_ratio",用来从原始训练集中切分出验证集,这里设定为0.1
接下来我们将切分的45000张图片用于训练,5000张图片用于验证,将它们分别存放到input_dir/train,input_dir/valid目录下面,这里的input_dir,我这里设置为train_valid_test,在train目录下面是10个分类的目录(这个将定义一个方法自动创建),每个分类目录里面是4500张所属类别的图片;在valid目录下面也是10个分类的目录(同样自动创建),每个分类目录里面是500张所属类别的图片;还有一个train_valid目录,下面同样是10个分类目录,每个类别目录包含5000张图片。
本人的路径如下:
D:\CIFAR10\dataset\train_valid_test\train\[airplane...]\[1-4500].png
D:\CIFAR10\dataset\train_valid_test\valid\[automobile...]\[1-500].png
D:\CIFAR10\dataset\train_valid_test\train_valid\[bird...]\[1-5000].png
这里定义一个辅助函数,新建不存在的路径,将递归新建目录:
#辅助函数,路径不存在就创建
def mkdir_if_not_exist(path):if not os.path.exists(os.path.join(*path)):os.makedirs(os.path.join(*path))def reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label):'''切分训练数据集,分别生成train、valid、train_valid文件夹在这些目录下面分别生成10个类别目录,遍历图片拷贝到对应的类别目录'''label_count={}#{'frog': 4500, 'cat': 4500, 'automobile': 4500,...}for train_file in os.listdir(os.path.join(data_dir,train_dir)):idx=int(train_file.split('.')[0])label=idx_label[idx]#类别mkdir_if_not_exist([data_dir,input_dir,'train_valid',label])src1=os.path.join(data_dir,train_dir,train_file)dst1=os.path.join(data_dir,input_dir,'train_valid',label)shutil.copy(src1,dst1)#将图片拷贝到train_valid_test\train_valid\类别\if label not in label_count or label_count[label]<n_train_per_label:mkdir_if_not_exist([data_dir,input_dir,'train',label])src2=os.path.join(data_dir,train_dir,train_file)dst2=os.path.join(data_dir,input_dir,'train',label)shutil.copy(src2,dst2)label_count[label]=label_count.get(label,0)+1#每个类别数量累加,小于n_train_per_label=4500else:mkdir_if_not_exist([data_dir,input_dir,'valid',label])src3=os.path.join(data_dir,train_dir,train_file)dst3=os.path.join(data_dir,input_dir,'valid',label)shutil.copy(src3,dst3)input_dir='train_valid_test'
reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label)这个图片数量比较多,拷贝过程比较耗时,所以我们可以使用进度条来显示我们拷贝的进展。
from tqdm import tqdmwith tqdm(total=len(os.listdir(os.path.join(data_dir,train_dir)))) as pbar:for train_file in tqdm(os.listdir(os.path.join(data_dir,train_dir))):......更多关于进度条的知识,可以参阅:Python中tqdm进度条的详细介绍(安装程序与耗时的迭代)最终结果是训练数据集的图片都拷贝到了各自所对应类别的目录里面。
1.3整理测试数据集
训练与验证的数据集做好,接下来做一个测试集用来预测的时候使用。
def reorg_test(data_dir,test_dir,input_dir):mkdir_if_not_exist([data_dir,input_dir,'test','unknown'])for test_file in os.listdir(os.path.join(data_dir,test_dir)):src=os.path.join(data_dir,test_dir,test_file)dst=os.path.join(data_dir,input_dir,'test','unknown')shutil.copy(src,dst)reorg_test(data_dir,'test',input_dir)这样就将dataset\test中的测试图片拷贝到了dataset\train_valid_test\test\unknown目录下面,当然简单起见直接手动拷贝过去也可以。
2、读取整理后的数据集
2.1、图像增广
为了应对过拟合,我们使用图像增广,关于图像增广在前面章节有讲过,有兴趣的也可以查阅:
计算机视觉之图像增广(翻转、随机裁剪、颜色变化[亮度、对比度、饱和度、色调])
这里我们将训练数据集做一些随机翻转、缩放裁剪与通道的标准化等处理,对测试与验证数据集只做个标准化处理
# 训练集图像增广
transform_train = gdata.vision.transforms.Compose([gdata.vision.transforms.Resize(40),gdata.vision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),gdata.vision.transforms.RandomFlipLeftRight(),gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])#测试集图像增广
transform_test = gdata.vision.transforms.Compose([gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])2.2、读取数据集
读取增广后的数据集,使用ImageFolderDataset实例来读取整理之后的文件夹里的图片数据集,其中每个数据样本包括图像和标签。
#ImageFolderDataset加载存储在文件夹结构中的图像文件的数据集
train_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train'), flag=1)
valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'valid'), flag=1)
train_valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train_valid'), flag=1)
test_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'test'), flag=1)
print(train_ds.items[0:2],train_ds.items[-2:])
'''
[('dataset\\train_valid_test\\train\\airplane\\10009.png', 0), ('dataset\\train_valid_test\\train\\airplane\\10011.png', 0)]
[('dataset\\train_valid_test\\train\\truck\\5235.png', 9), ('dataset\\train_valid_test\\train\\truck\\5236.png', 9)]
'''打印的items来看,返回的是列表,里面的元素是元组对,分别是图片路径与标签(类别)值。
然后我们使用DataLoader实例,指定增广之后的数据集,返回小批量数据。在训练时,我们仅用验证集评价模型,因此需要保证输出的确定性。在预测时,我们将在训练集和验证集的并集上训练模型,以充分利用所有标注的数据。
#DataLoader从数据集中加载数据并返回小批量数据
batch_size = 128
train_iter = gdata.DataLoader(train_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
valid_iter = gdata.DataLoader(valid_ds.transform_first(transform_test), batch_size, shuffle=True, last_batch='keep')
train_valid_iter = gdata.DataLoader(train_valid_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
test_iter = gdata.DataLoader(test_ds.transform_first(transform_test), batch_size, shuffle=False, last_batch='keep')3、定义模型
数据集处理好了之后,我们就可以开始定义合适的模型了,我们选用残差网络ResNet-18模型,在此之前我们先使用基于HybridBlock类构建残差块:
#定义残差块
class Residual(nn.HybridBlock):def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):super(Residual, self).__init__(**kwargs)self.conv1 = nn.Conv2D(num_channels, kernel_size=3,padding=1, strides=strides)self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2D(num_channels, kernel_size=1, strides=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm()self.bn2 = nn.BatchNorm()def hybrid_forward(self, F, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)return F.relu(Y+X)
定义好了残差块,就可以方便的构建残差网络了。
#ResNet-18模型
def resnet18(num_classes):net = nn.HybridSequential()net.add(nn.Conv2D(64, kernel_size=3, strides=1, padding=1),nn.BatchNorm(), nn.Activation('relu'))def resnet_block(num_channels, num_residuals, first_block=False):blk = nn.HybridSequential()for i in range(num_residuals):if i == 0 and not first_block:blk.add(Residual(num_channels, use_1x1conv=True, strides=2))else:blk.add(Residual(num_channels))return blknet.add(resnet_block(64, 2, first_block=True), resnet_block(128, 2), resnet_block(256, 2), resnet_block(512, 2))net.add(nn.GlobalAvgPool2D(), nn.Dense(num_classes))return net定义好了模型,在训练之前我们使用Xavier随机初始化,我们这里是CIFAR10数据集,有10个分类,所以最终的稠密层我们输出的是10:
def get_net(ctx):num_classes = 10net = resnet18(num_classes)net.initialize(ctx=ctx, init=init.Xavier())return net
loss=gloss.SoftmaxCrossEntropyLoss()4、训练模型
模型初始化好了之后,就可以对其进行训练了,定义一个训练函数train:
def train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay):trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr, 'momentum': 0.9, 'wd': wd})for epoch in range(num_epochs):train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()if epoch > 0 and epoch % lr_period == 0:trainer.set_learning_rate(trainer.learning_rate*lr_decay)for X, y in train_iter:y = y.astype('float32').as_in_context(ctx)with autograd.record():y_hat = net(X.as_in_context(ctx))l = loss(y_hat, y).sum()l.backward()trainer.step(batch_size)train_l_sum += l.asscalar()train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar()n += y.sizetime_s = "time %.2f sec" % (time.time()-start)if valid_iter is not None:# 评估给定数据集上模型的准确性《使用验证集》valid_acc = d2l.evaluate_accuracy(valid_iter, net, ctx)epoch_s = ("epoch %d,loss %f,train acc %f,valid acc %f," %(epoch+1, train_l_sum/n, train_acc_sum/n, valid_acc))else:epoch_s = ("epoch %d,loss %f,train acc %f," %(epoch+1, train_l_sum/n, train_acc_sum/n))print(epoch_s+time_s+',lr '+str(trainer.learning_rate))定义好了train函数,就可以进行训练了
# 开始训练
ctx, num_epochs, lr, wd = d2l.try_gpu(), 1, 0.1, 5e-4
lr_period, lr_decay, net = 80, 0.1, get_net(ctx)
net.hybridize()
train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay)这里我们可以简单的将num_epochs设置为1,只迭代一次看下程序有没有什么bug与运行的怎么样:
epoch 1,loss 2.033364,train acc 0.294133,valid acc 0.345600,time 288.89 sec,lr 0.1
运行是没有什么问题,接下来就正式进入到分类的主题了
5、测试集分类
模型训练没有什么问题,超参数什么的也设置好了,我们使用所有训练数据集(包括验证集)重新训练模型,对测试集进行分类,这里我使用5个迭代来看下效果会是怎么样的:
num_epochs, preds = 5, []
net.hybridize()
train(net, train_valid_iter, None, num_epochs,lr, wd, ctx, lr_period, lr_decay)
for X, _ in test_iter:y_hat = net(X.as_in_context(ctx))preds.extend(y_hat.argmax(axis=1).astype(int).asnumpy())
sorted_ids = list(range(1, len(test_ds)+1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.synsets[x])
df.to_csv('submission.csv', index=False)'''
epoch 1,loss 2.192931,train acc 0.253960,time 346.49 sec,lr 0.1
epoch 2,loss 1.663164,train acc 0.390080,time 118.79 sec,lr 0.1
epoch 3,loss 1.493299,train acc 0.456140,time 118.91 sec,lr 0.1
epoch 4,loss 1.356744,train acc 0.509440,time 117.40 sec,lr 0.1
epoch 5,loss 1.235666,train acc 0.556580,time 114.41 sec,lr 0.1
'''可以看到损失在降低,精度在增加,一切正常,训练完毕将生成一个提交文件:submission.csv
然后将这个submission.csv文件提交看下打分与排名,当然这里可以将迭代次数调大,准确度也是会上来的,我迭代了100次然后提交看下分数如何,结果还是不错的
附上全部代码:
import pandas as pd
import d2lzh as d2l
import os
from mxnet import autograd,gluon,init
from mxnet.gluon import data as gdata,loss as gloss,nn
import shutil
import timedef read_label_file(data_dir,label_file,train_dir,valid_ratio):'''读取训练集的标签文件参数valid_ratio:验证集样本数与原始训练集样本数之比返回值n_train // len(labels):每个类多少张图片idx_label:50000个id:label的字典'''with open(os.path.join(data_dir,label_file),'r') as f:lines=f.readlines()[1:]tokens=[l.rstrip().split(',') for l in lines]idx_label=dict(((int(idx),label) for idx,label in tokens))#{'cat', 'ship', 'frog', 'dog', 'truck', 'deer', 'horse', 'bird', 'airplane', 'automobile'}labels=set(idx_label.values())#去重就是10个类别n_train_valid=len(os.listdir(os.path.join(data_dir,train_dir)))#50000n_train=int(n_train_valid*(1-valid_ratio))assert 0<n_train<n_train_validreturn n_train // len(labels),idx_labeldata_dir,label_file="dataset","trainLabels.csv"
train_dir,valid_ratio="train",0.1n_train_per_label,idx_label=read_label_file(data_dir,label_file,train_dir,valid_ratio)
#print(n_train_per_label,len(idx_label))#辅助函数,路径不存在就创建
def mkdir_if_not_exist(path):if not os.path.exists(os.path.join(*path)):os.makedirs(os.path.join(*path))def reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label):'''切分训练数据集,分别生成train、valid、train_valid文件夹在这些目录下面分别生成10个类别目录,遍历图片拷贝到对应的类别目录'''label_count={}#{'frog': 4500, 'cat': 4500, 'automobile': 4500,...}from tqdm import tqdmwith tqdm(total=len(os.listdir(os.path.join(data_dir,train_dir)))) as pbar:for train_file in tqdm(os.listdir(os.path.join(data_dir,train_dir))):idx=int(train_file.split('.')[0])label=idx_label[idx]#类别mkdir_if_not_exist([data_dir,input_dir,'train_valid',label])src1=os.path.join(data_dir,train_dir,train_file)dst1=os.path.join(data_dir,input_dir,'train_valid',label)#shutil.copy(src1,dst1)#将图片拷贝到train_valid_test\train_valid\类别\if label not in label_count or label_count[label]<n_train_per_label:mkdir_if_not_exist([data_dir,input_dir,'train',label])src2=os.path.join(data_dir,train_dir,train_file)dst2=os.path.join(data_dir,input_dir,'train',label)#shutil.copy(src2,dst2)label_count[label]=label_count.get(label,0)+1#每个类别数量累加,小于n_train_per_label=4500else:mkdir_if_not_exist([data_dir,input_dir,'valid',label])src3=os.path.join(data_dir,train_dir,train_file)dst3=os.path.join(data_dir,input_dir,'valid',label)#shutil.copy(src3,dst3)input_dir='train_valid_test'
#reorg_train_valid(data_dir,train_dir,input_dir,n_train_per_label,idx_label)def reorg_test(data_dir,test_dir,input_dir):mkdir_if_not_exist([data_dir,input_dir,'test','unknown'])for test_file in os.listdir(os.path.join(data_dir,test_dir)):src=os.path.join(data_dir,test_dir,test_file)dst=os.path.join(data_dir,input_dir,'test','unknown')#shutil.copy(src,dst)#reorg_test(data_dir,'test',input_dir)# 训练集图像增广
transform_train = gdata.vision.transforms.Compose([gdata.vision.transforms.Resize(40),gdata.vision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),gdata.vision.transforms.RandomFlipLeftRight(),gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])#测试集图像增广
transform_test = gdata.vision.transforms.Compose([gdata.vision.transforms.ToTensor(),gdata.vision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])#读取增广后的数据集
#ImageFolderDataset加载存储在文件夹结构中的图像文件的数据集
train_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train'), flag=1)
valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'valid'), flag=1)
train_valid_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'train_valid'), flag=1)
test_ds = gdata.vision.ImageFolderDataset(os.path.join(data_dir, input_dir, 'test'), flag=1)
#print(train_ds.items[0:2],train_ds.items[-2:])
'''
[('dataset\\train_valid_test\\train\\airplane\\10009.png', 0), ('dataset\\train_valid_test\\train\\airplane\\10011.png', 0)]
[('dataset\\train_valid_test\\train\\truck\\5235.png', 9), ('dataset\\train_valid_test\\train\\truck\\5236.png', 9)]
'''#DataLoader从数据集中加载数据并返回小批量数据
batch_size = 128
train_iter = gdata.DataLoader(train_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
valid_iter = gdata.DataLoader(valid_ds.transform_first(transform_test), batch_size, shuffle=True, last_batch='keep')
train_valid_iter = gdata.DataLoader(train_valid_ds.transform_first(transform_train), batch_size, shuffle=True, last_batch='keep')
test_iter = gdata.DataLoader(test_ds.transform_first(transform_test), batch_size, shuffle=False, last_batch='keep')#-----------------定义模型--------------------
#定义残差块
class Residual(nn.HybridBlock):def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):super(Residual, self).__init__(**kwargs)self.conv1 = nn.Conv2D(num_channels, kernel_size=3, padding=1, strides=strides)self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2D(num_channels, kernel_size=1, strides=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm()self.bn2 = nn.BatchNorm()def hybrid_forward(self, F, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)return F.relu(Y+X)#ResNet-18模型
def resnet18(num_classes):net = nn.HybridSequential()net.add(nn.Conv2D(64, kernel_size=3, strides=1, padding=1),nn.BatchNorm(), nn.Activation('relu'))def resnet_block(num_channels, num_residuals, first_block=False):blk = nn.HybridSequential()for i in range(num_residuals):if i == 0 and not first_block:blk.add(Residual(num_channels, use_1x1conv=True, strides=2))else:blk.add(Residual(num_channels))return blknet.add(resnet_block(64, 2, first_block=True), resnet_block(128, 2), resnet_block(256, 2), resnet_block(512, 2))net.add(nn.GlobalAvgPool2D(), nn.Dense(num_classes))return netdef get_net(ctx):num_classes = 10net = resnet18(num_classes)net.initialize(ctx=ctx, init=init.Xavier())return net
loss=gloss.SoftmaxCrossEntropyLoss()#---------------------训练函数---------------------
def train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay):trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr, 'momentum': 0.9, 'wd': wd})for epoch in range(num_epochs):train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()if epoch > 0 and epoch % lr_period == 0:trainer.set_learning_rate(trainer.learning_rate*lr_decay)for X, y in train_iter:y = y.astype('float32').as_in_context(ctx)with autograd.record():y_hat = net(X.as_in_context(ctx))l = loss(y_hat, y).sum()l.backward()trainer.step(batch_size)train_l_sum += l.asscalar()train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar()n += y.sizetime_s = "time %.2f sec" % (time.time()-start)if valid_iter is not None:# 评估给定数据集上模型的准确性《使用验证集》valid_acc = d2l.evaluate_accuracy(valid_iter, net, ctx)epoch_s = ("epoch %d,loss %f,train acc %f,valid acc %f," %(epoch+1, train_l_sum/n, train_acc_sum/n, valid_acc))else:epoch_s = ("epoch %d,loss %f,train acc %f," %(epoch+1, train_l_sum/n, train_acc_sum/n))print(epoch_s+time_s+',lr '+str(trainer.learning_rate))# 开始训练
ctx, num_epochs, lr, wd = d2l.try_gpu(), 1, 0.1, 5e-4
lr_period, lr_decay, net = 80, 0.1, get_net(ctx)
#net.hybridize()
#train(net, train_iter, valid_iter, num_epochs, lr, wd, ctx, lr_period, lr_decay)num_epochs, preds = 100, []
net.hybridize()
train(net, train_valid_iter, None, num_epochs,lr, wd, ctx, lr_period, lr_decay)
for X, _ in test_iter:y_hat = net(X.as_in_context(ctx))preds.extend(y_hat.argmax(axis=1).astype(int).asnumpy())
sorted_ids = list(range(1, len(test_ds)+1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
#apply应用synsets方法,将0~9的数字分别转换为airplane、automobile...对应的类别
#synsets方法大家可以看定义,就是获取文件夹名称(类别)
df['label'] = df['label'].apply(lambda x: train_valid_ds.synsets[x])
df.to_csv('submission.csv', index=False)相关文章:
Kaggle系列之CIFAR-10图像识别分类(残差网络模型ResNet-18)
CIFAR-10数据集在计算机视觉领域是一个很重要的数据集,很有必要去熟悉它,我们来到Kaggle站点,进入到比赛页面:https://www.kaggle.com/competitions/cifar-10CIFAR-10是8000万小图像数据集的一个子集,由60000张32x32彩…...
ESP-C3入门11. 创建最基本的HTTP请求
ESP-C3入门11. 创建最基本的HTTP请求一、menuconfig配置二、配置 CMakeLists1. 设置项目的额外组件目录2. 设置头文件搜索目录三、在 ESP32 上执行 HTTP 请求的基本步骤1. 创建 TCP 连接2. 设置 HTTP 请求3. 发送 HTTP 请求4. 接收 HTTP 响应5. 处理 HTTP 响应6. 关闭 TCP 连接…...
K8S+Jenkins+Harbor+Docker+gitlab集群部署
K8SJenkinsHarborDockergitlab服务器集群部署 目录K8SJenkinsHarborDockergitlab服务器集群部署1.准备以下服务器2.所有服务器统一处理执行2.1 关闭防火墙2.2 关闭selinux2.3 关闭swap(k8s禁止虚拟内存以提高性能)2.4 更新yum (看需要更新)2.5 时间同步2…...

看见统计——第四章 统计推断:频率学派
看见统计——第四章 统计推断:频率学派 接下来三节的主题是中心极限定理的应用。在不了解随机变量序列 {Xi}\{X_i\}{Xi} 的潜在分布的情况下,对于大样本量,中心极限定理给出了关于样本均值的声明。例如,如果 YYY 是一个 N(0&am…...
2023年2月访问学者博士后热门国家出入境政策变化汇总
近期关于出国的咨询量日益增多,出入境政策也是其中之一。所以本期知识人网小编汇总了最新访问学者和博士后关注的热门国家及地区入境政策变化,提供给大家。目前各国入境政策大致分为三种:一、 无法入境的国家如:摩洛哥、朝鲜等。二…...

“离开浪浪山”是假象,80%年轻人下班后还在学习,真实是想先上个山。
最近,又有一个关于年轻人与职场的新词横空出世—— 浪浪山。 什么是浪浪山? 每个人心中都有一座浪浪山。 浪浪山,其实是人生的一种状态,步入社会时满腔热血,然而很快就被现实给修理了一顿;想要辞职不干出去…...

Kotlin 33. CompileSdkVersion 和 targetSdkVersion 有什么区别?
CompileSdkVersion 和 targetSdkVersion 有什么区别? 在 build.gradle (Module) 文件中,我们通常会看到 CompileSdkVersion 和 targetSdkVersion 的使用,比如下面是一个完整的 build.gradle (Module) 文件: plugins {id com.and…...

实用调试技巧——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容是实用调试技巧,其实小雅兰一开始,也不知道调试到底是什么,一遇到问题,首先就是观察程序,改改这里改改那里,最后导致bug越修越多,或者是问别…...
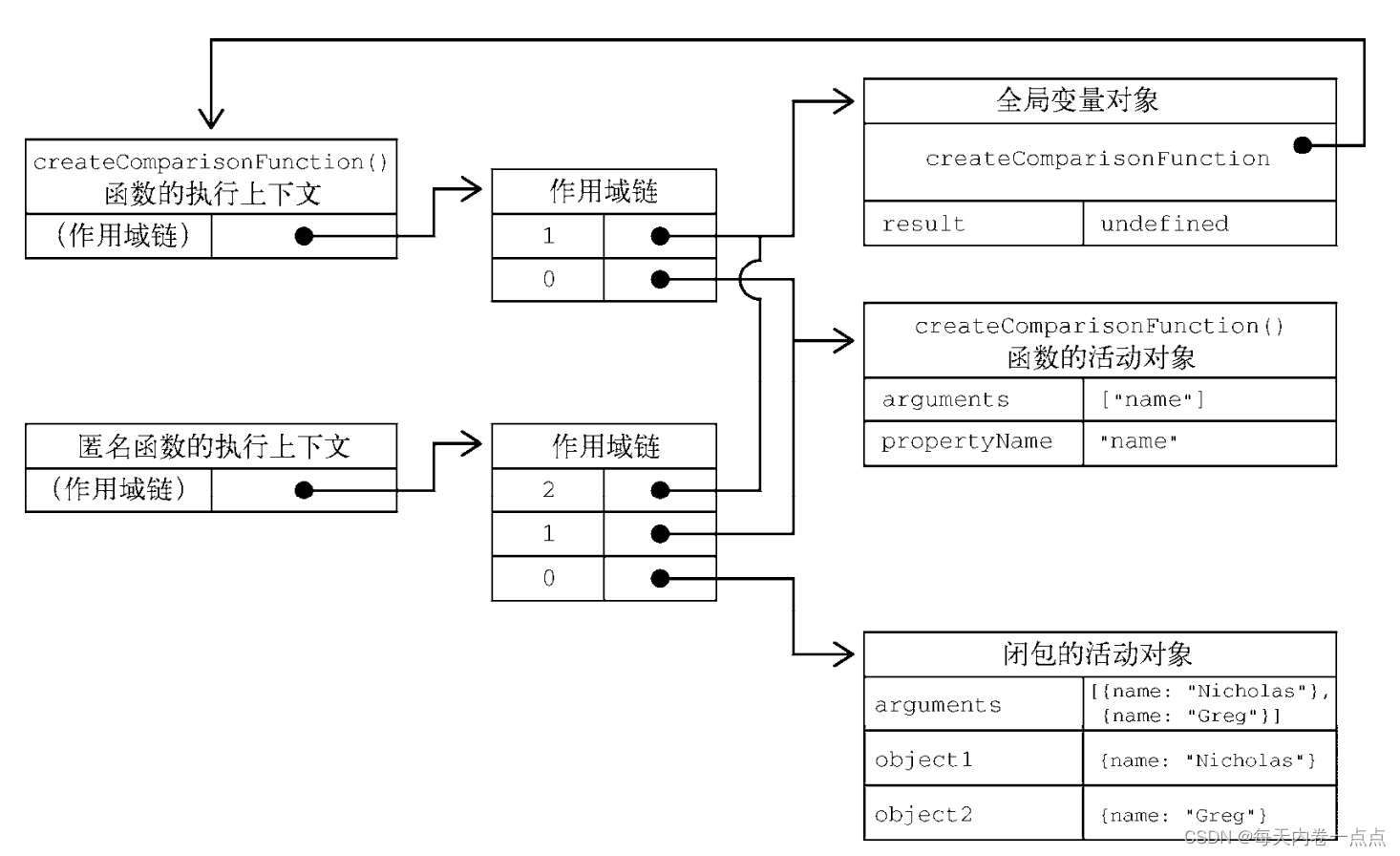
JavaScript - 函数
文章目录一、箭头函数二、函数名三、理解参数3.1 箭头函数中的参数四、没有重载五、默认参数值5.1 默认参数作用域与暂时性死区六、参数扩展与收集6.1 扩展参数6.2 收集参数七、函数声明与函数表达式八、函数作为值九、函数内部9.1 arguments9.2 this9.3 caller9.4 new.target十…...
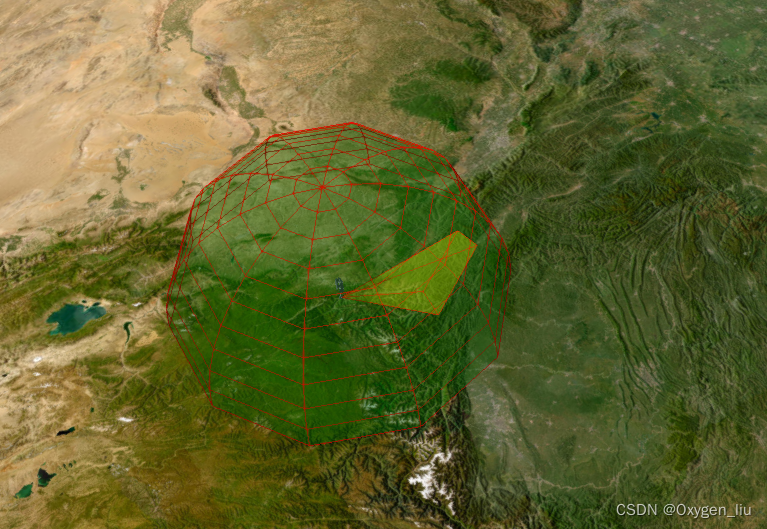
Cesium 卫星轨迹、卫星通信、卫星过境,模拟数据传输。
起因:看了cesium官网卫星通信示例发现只有cmzl版本的,决定自己动手写一个。欢迎大家一起探讨,评论留言。 效果 全部代码在最后 起步 寻找卫星轨迹数据,在网站space-track上找的,自己注册账号QQ邮箱即可。 卫星轨道类…...

2023年湖北中级职称(工程类建筑类)报名条件和要求是什么?
2023年湖北中级职称(工程类建筑类)报名条件和要求是什么? 中级职称分为计算机类、医药类、卫生类、教师类、工程类、经济类等各大类,今天主要就是跟大家说一下工程类中级职称评审的一个条件和要求,这也是评职称人员应该…...

socket编程复习
再次用到socket编程,将socket相关的知识点做了简单整理,根据网络上大家的整理,又做了一些调整和汇总。 API列表 sokect常见的API大致有列表里面这么多,不同平台的实现可能有些微的差别,下面对常用API的参数和用法做了…...
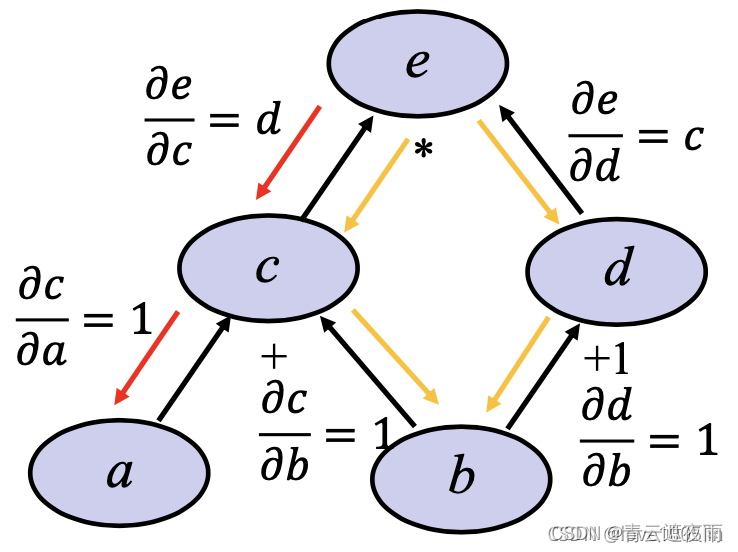
深度学习神经网络基础知识(三)前向传播,反向传播和计算图
专栏:神经网络复现目录 深度学习神经网络基础知识(三) 本文讲述神经网络基础知识,具体细节讲述前向传播,反向传播和计算图,同时讲解神经网络优化方法:权重衰减,Dropout等方法,最后进行Kaggle实…...
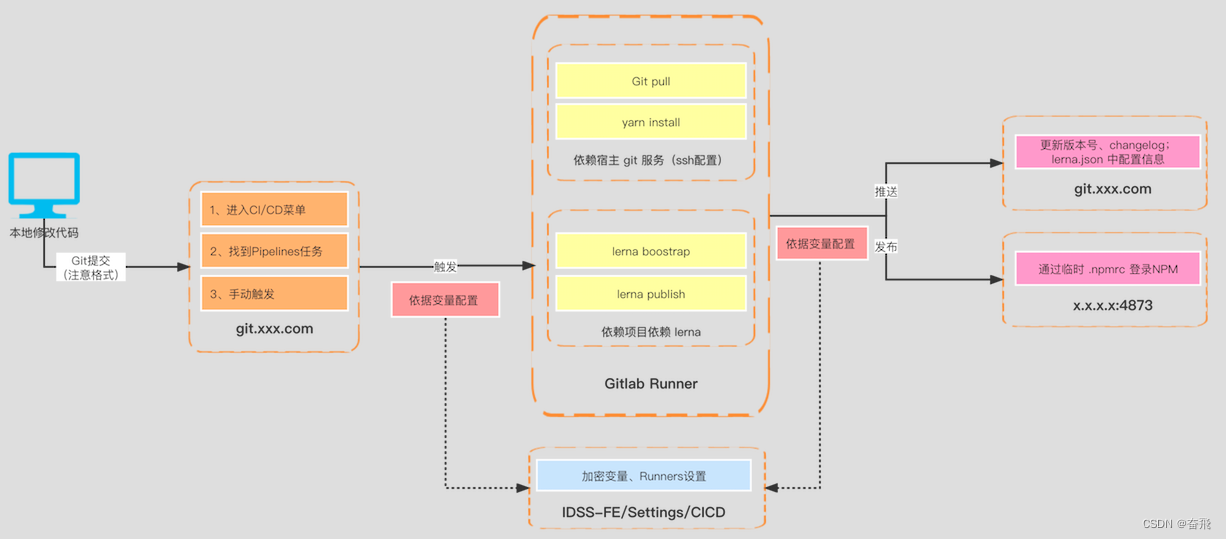
一图说明 monorepo 落地流程方案
关于 monorepo 初次讨论已有2年载,目前团队已经沉淀了成熟的技术方案且经受住了实战考验。所以特梳理相关如下: 也算是关于之前发起的 monorepo–依赖 的解答篇。 上图为目前团队贡献的主流程:① 本地开发 > ② 提交Git仓库 > ③ 触发…...

SAP ABAP WRITE语法大全
列表是ABAP/4报表程序数据的输出媒介。每个ABAP/4报表程序将其输出数据传递到直接与该程序连接的列表中。每个程序最多生成21个列表:1个基本列表和20个辅助列表。 将数据写入列表的基本ABAP/4语句是WRITE、SKIP和ULINE输出语句。 一、标准列表结构 (1&…...

微信小程序自定义全局组件showModal
开发过程中微信提供的showmodal样式不符合ui风格,又不想写成组件用的页面都引入,就考虑模拟showmodal写一个自定义的弹框组件 一,在components中新建一个navModal组件 navModal.wxml <view class="modal_mask" hidden={{hidden}}><view class="mo…...

4|无线传感器网络与应用|无线传感器网络原理及方法-许毅版|考试知识点
《无线传感器网络原理及方法》第1章无线传感器网络概述1.1无线传感器网络的基本概念1.2无线传感器网络的特征1.2.1与现有无线网络的区别1.2.2与现场总线的区别1.2.3传感器节点的限制1.2.4传感器组网的特点1.3无线传感器网络的关键性能指标1.4无线传感器网络的应用1.5无线传感器…...

startForegroundService与startService 使用浅析
一. 了解服务(Service)的概念 service是安卓开发中一个很重要组件,意为“服务”。与我们常见的activity不同,“服务”是默默的在背后进行工作的,通常,它用于在后台为我们执行一些耗时,或者需要…...
django项目实战三(django+bootstrap实现增删改查)进阶分页
目录 一、分页 1、修改case_list.html页面 2、修改views.py的case_list方法(分页未封装) 二、分页封装 1、新建类Pagination 2、修改views.py的case_list方法 三、再优化,实现搜索分页qing情况 四、优化其他查询页面实现分页和查询 五…...

Python 之 Pandas DataFrame 数据类型的简介、创建的列操作
文章目录一、DataFrame 结构简介二、DataFrame 对象创建1. 使用普通列表创建2. 使用嵌套列表创建3 指定数值元素的数据类型为 float4. 字典嵌套列表创建5. 添加自定义的行标签6. 列表嵌套字典创建 DataFrame 对象7. Series 创建 DataFrame 对象三、DataFrame 列操作1. 选取数据…...

BAAI/bge-m3新手指南:无需代码基础,也能玩转高级语义分析模型
BAAI/bge-m3新手指南:无需代码基础,也能玩转高级语义分析模型 1. 什么是BAAI/bge-m3语义分析引擎 1.1 模型的基本功能 BAAI/bge-m3是一个强大的语义分析工具,它能理解文本背后的含义而不仅仅是表面的词语。想象一下,当你说&quo…...

OpenClaw多任务管道:Phi-3-mini-128k-instruct串联处理复杂工作流
OpenClaw多任务管道:Phi-3-mini-128k-instruct串联处理复杂工作流 1. 为什么需要多任务管道? 上个月我需要处理一批英文技术文档的本地化工作,包含三个关键步骤:文档翻译、格式转换和邮件发送。最初我尝试手动操作——先用翻译工…...

React Router路由配置详解:单页面应用导航的完整实现
React Router路由配置详解:单页面应用导航的完整实现 【免费下载链接】django-react-redux-base Seedstars Labs Base Django React Redux Project 项目地址: https://gitcode.com/gh_mirrors/dj/django-react-redux-base React Router是现代React应用中不可…...

OOMMF实战避坑指南:从编译报错到高级功能解析
1. OOMMF编译安装常见问题解析 第一次接触OOMMF的开发者,90%的时间都花在了环境配置和编译上。作为一个用C和Tcl混合编写的开源软件,OOMMF的编译过程确实存在不少"坑"。最常见的就是双击oommf.tcl后弹出的各种报错窗口——这往往意味着你需要…...
的目标连续感知与主动控制技术体系研究与应用:专家评审18问18答)
三维空间智能体(3D Spatial Agent)的目标连续感知与主动控制技术体系研究与应用:专家评审18问18答
一、学术与原理类(1–6)Q1:你们所谓“像素即坐标”,在理论上如何成立?误差如何界定?A: 基于多视角几何与相机内外参标定,将像素反投影为空间射线,通过多视角交汇…...

什么叫低代码?低代码平台能做什么?国内十大低代码平台盘点
在数字化转型浪潮席卷全球的今天,软件开发效率成为企业竞争的关键因素。低代码(Low-Code)作为一种革命性的开发模式,正以惊人速度改变着传统软件开发的格局,让"人人都是开发者"的愿景逐渐成为现实。本文将深…...

问题1 开播后 观众端第一次进直播间 直播间没有画面 需要 主播重新进直播页面 观众端才有画面问题2 上面的流程走完 观众重新进直播间 直播间看不到画面问题3 不能多观众收看直播啊
需要docker srs webrtc websockdocker cmd 中 启动 srsset CANDIDATElongwen.natapp1.cc && docker run --rm -it -p 1935:1935 -p 1985:1985 -p 8000:8000/udp -p 8000:8000/tcp --env CANDIDATE%CANDIDATE% --env SRS_RTC_TCP_ENABLEDon --env SRS_RTC_TCP_PORT8000 …...

萌新梦开始的地方
大家好,我是一名双非本科的大一新生,目前就读于计算机科学与技术这个专业,平时的兴趣爱好就是听听歌,健健身,这是我写的第一篇博客,我想以此来作为我学习编程的开始,同同时也以此来见证我在编程…...

MPR121电容触摸传感器驱动与抗干扰工程实践
1. MPR121电容式接近/触摸传感器控制器深度技术解析 MPR121是由NXP Semiconductors(原Freescale)推出的12通道电容式触摸与接近感应专用协处理器芯片,广泛应用于STM32、ESP32、nRF52等主流MCU平台的嵌入式人机交互系统中。该器件并非通用IC外…...

内存屏障与volatile:并发编程的核心机制解析
1. 内存屏障与volatile的核心概念解析在并发编程领域,内存屏障和volatile是两个至关重要的底层技术。它们看似简单,却直接影响着程序的正确性和性能表现。理解这两个概念需要从计算机体系结构的多个层面进行分析。1.1 volatile关键字的本质作用volatile在…...