Git企业开发控制理论和实操-从入门到深入(三)|分支管理
前言
那么这里博主先安利一些干货满满的专栏了!
首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。
- 高质量博客汇总
然后就是博主最近最花时间的一个专栏《Git企业开发控制理论和实操》希望大家多多关注!
- Git企业开发控制理论和实操
Git的分支管理
我们继续在上一章创建的本地仓库中继续进行分支的学习。
分支创建、切换、合并的简单尝试
git branch # 查看本地有哪些分支

前面的*是什么?
我们前面说到,HEAD一开始是指向master的,但HEAD不是只能指向master的,而是可以指向其他分支。
然后被HEAD指向的分支才是工作分支。
如何创建一个本地的分支呢?
git branch dev # 创建一个名为dev的分支

发现多了一个dev
但此时HEAD还是指向master的。我们打印一下HEAD就能看到。

同样,tree一下.git/也可以看到新建的dev

此时我们可以把dev和master的内容都打印一下。

我们知道master里面是上一次提交的commit id,我们发现dev里面也是。所以现在分支的状态如下图所示。

两个“指针”,都指向最新的提交,HEAD指向master。
然后现在我想在dev分支上进行操作,我们就要让HEAD指针指向dev,而不是master。
git checkout dev
通过这个命令可以把HEAD指向dev分支,让dev成为工作分支。

现在的工作分支就是dev了。
现在我们对README.md文件进行一下修改。

然后提交。

此时的README.md(dev分支上的)是有hello branch的。
我们切换回master分支,再看看README.md长啥样。

我们发现是没有hello branch的!
因为我们刚才的修改,在dev分支上。
刚才的这几个步骤的图示如下。

现在我们想要在master上也拿到dev上的代码,那就要合并!
注意:现在是想要在master上获得dev的分支,就是dev合并到master中,注意表达和顺序,是反过来是不一样的。
首先先要checkout到master上来。
git checkout master
然后使用合并命令。
git merge dev # 合并

我们看到这里面的Fast-forward表示快速提交。本质上就是把master的指针改一下就行了,所以是很快的。
到后面我们会讲不是Fast-forward的情况。
流程就是这个样子的。

当然,在这过程中还会存在很多的问题,我们在后面再一一解释。
删除分支
我们在上一小节,创建了dev分支,然后做一些修改,然后合并了。
意味着dev分支的使命已经结束了。我们就要删除dev分支。
git branch -d dev
注意:
- 只能在其他分支上删除分支,也就是说我们不能在
dev上删除dev分支,否则会报错。

为什么需要分支
因为创建、合并和删除分支非常快,所以Git鼓励你使用分支完成某个任务,合并后再删掉分支,这和直接在master分支上工作效果是一样的,但过程更安全。
合并冲突
合并的时候是最容易出现问题的。
比如说现在有一个README.md文件,创建dev分支后,多加了一行:bbb on dev branch
master也没闲着,也多加了一行:ccc on dev branch
那git是不知道在合并的时候保留bbb的这一行还是保留ccc的这一行的。
这种情况叫做合并冲突。
我们先把上述的情况准备好。

其实有一行命令,可以同时做到:创建分支+checkout到这个新创建的分支上。
git checkout -b dev1 # 创建dev1分支,并切换到dev1分支下
此时的状态就是这样的。

此时merge就会发生冲突,我们来试一下。

合并失败。

此时,git帮我们修改了一下代码,如图所示,把HEAD和dev1中的都放在一起了。
然后刚才的冲突提示是:Automatic merge failed; fix conflicts and then commit the result.
因此就是让我们自己手动改一下,然后重新提交。
所以现在我们选择保留bbb那一行,直接删掉其他代码就行了。

重新提交后即可,此时仓库的状态是这样的。

- 注意:因为是
master去merge了dev,所以master此时是最新的提交,也就是我们fix冲突后的提交,但是此时dev依旧还是刚才dev的提交。
其实 git log 可以帮我们画这些图,画给我们看。
git log --graph --abbrev-commit
效果如下所示:
(base) [yufc@ALiCentos7:~/Src/Bit-Courses/GitDevelopment/gitcode]$ git log --graph --abbrev-commit
* commit ce635d4
|\ Merge: c007412 fd4e0b0
| | Author: Yufccode <xxx@qq.com>
| | Date: Wed Aug 23 22:51:22 2023 +0800
| |
| | fix conflict
| |
| * commit fd4e0b0
| | Author: Yufccode <xxx@qq.com>
| | Date: Wed Aug 23 22:42:45 2023 +0800
| |
| | bbb on dev1
| |
* | commit c007412
|/ Author: Yufccode <xxx@qq.com>
| Date: Wed Aug 23 22:42:03 2023 +0800
|
| ccc on master
|
* commit 48cc733
| Author: Yufccode <xxx@qq.com>
| Date: Tue Aug 22 23:27:07 2023 +0800
|
| modify readme
:...skipping...
* commit ce635d4
|\ Merge: c007412 fd4e0b0
| | Author: Yufccode <xxx@qq.com>
| | Date: Wed Aug 23 22:51:22 2023 +0800
| |
| | fix conflict
| |
| * commit fd4e0b0
| | Author: Yufccode <xxx@qq.com>
| | Date: Wed Aug 23 22:42:45 2023 +0800
| |
| | bbb on dev1
| |
* | commit c007412
|/ Author: Yufccode <xxx@qq.com>
| Date: Wed Aug 23 22:42:03 2023 +0800
|
| ccc on master
|
* commit 48cc733
| Author: Yufccode <xxx@qq.com>
| Date: Tue Aug 22 23:27:07 2023 +0800
|
| modify readme
|
* commit 130a873
| Author: Yufccode <xxx@qq.com>
| Date: Mon Aug 21 23:04:55 2023 +0800
|
| modify README.md
|
* commit f42df14
:...skipping...
* commit ce635d4
|\ Merge: c007412 fd4e0b0
| | Author: Yufccode <xxx@qq.com>
| | Date: Wed Aug 23 22:51:22 2023 +0800
| |
| | fix conflict
| |
| * commit fd4e0b0
| | Author: Yufccode <xxx@qq.com>
| | Date: Wed Aug 23 22:42:45 2023 +0800
| |
| | bbb on dev1
| |
* | commit c007412
|/ Author: Yufccode <xxx@qq.com>
| Date: Wed Aug 23 22:42:03 2023 +0800
|
| ccc on master
|
* commit 48cc733
| Author: Yufccode <xxx@qq.com>
| Date: Tue Aug 22 23:27:07 2023 +0800
|
| modify readme
|
* commit 130a873
| Author: Yufccode <xxx@qq.com>
| Date: Mon Aug 21 23:04:55 2023 +0800
|
| modify README.md
|
* commit f42df14
| Author: Yufccode <xxx@qq.com>
| Date: Mon Aug 21 12:26:23 2023 +0800
|
| my second add
|
:
最上面的就是最新我们的操作。
合并模式
其实在这一章节里面,我们的实验有两次merge,分别对应了两种合并模式。
-
第一种其实就是:
Fast-forward模式,前面讲过的。 -
第二种就是第二次我们merge,需要解决冲突,称为:
no-ff模式
在Fast forward模式下,删除分支后,查看分支历史时,会丢掉分支信息,看不出来最新提交到底是merge进来的还是正常提交的。
但在合并冲突部分,我们也看到通过解决冲突问题,会再进行一次新的提交。
no-ff模式,这样的好处是,从分支历史上就可以看出分支信息。例如我们现在已经删除了在合并冲突部分创建的 dev1 分支,但依旧能看到 master 其实是由其他分支合并得到。
Git允许我们禁用Fast-forward模式。
git merge --no-ff -m "merge dev2" dev # 禁用ff模式进行merge, 因为no-ff模式需要再次进行提交,所以要-m带上提交的信息
分支策略

首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活。
那在哪干活呢? 干活都在dev分支上,也就是说,dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本;你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。
所以,团队合作的分支看起来就像这样:

因此,Git的分支功能是非常重要的!!!
BUG分支
如果master上有bug呢?
想象一种场景:master正在运行,然后dev2分支正在做开发,但是还没有提交,此时master突然出现bug了。
我们先模拟一下这种场景。

此时我们dev2分支上正在开发,然后此时master遇到了bug。
能不能在dev2分支上处理bug呢?肯定是不行的,因为dev2分支是用来开发某个功能的。
那好,现在我们就要切回去master上去处理,但是此时我dev2上还没提交,所以切过去处理我工作区的东西就不见了。所以需要一个命令,先把dev2上工作区的内容先保存一下先,然后再到master上去操作。
git stash # 暂时保存工作区的内容,注意:要保存dev2的内容,HEAD就要在dev2上

其实是保存到这里来了。
注意:git stash命令只能暂存已经被git管理的文件,因为README.md已经被git管理了,所以可以用git stash暂存。但是如果你说现在touch一个new_file让git stash去暂存是不行的。
此时我们就要checkout到master上去处理bug了。
然后创建一个bug分支。

然后去修复bug。

此时的状态就是,在fix_bug分支上,bug已经被修复了,master上还是bug,然后dev2在做某项开发。
此时就要让master上的bug也被修复,就是合并一下fix_bug分支。

此时我们的bug修复完了
此时我们要切回dev2分支继续进行开发。
此时我们工作区的内容在stash里面,所以先把stash的东西放出来先。
git stash list # 这个命令可以显示stash里面有哪些内容
git stash pop # 把stash里面的内容放出来,恢复到工作区中

但是此时dev2分支还是处于一个bug未修复的状态的,不过没关系,master已经修复了。
继续对dev2进行开发。

提交一下。

此时仓库的状态是这样的。

此时如果合并,可能会出现问题。

如果我们合并,我们就要手动解决冲突,如果手动改代码,就有可能会改出master的bug,怎么办?
所以此时我们一般这么办。
- 让
dev2去合并master,而不是master合并dev2,然后在本地测试dev2,把所有问题排除。 - 然后让
master去合并dev2,此时这次合并就不需要解决冲突了!


这种处理方式,才是正确的处理方式!
我们现在就来模拟这个过程。




这个就是整套流程!
这就是工作中开发中比较好的流程!
强制删除分支
设想开发中的一个场景:
产品经理:你给我新增一个功能
我:好。我现在开始做
然后我就拉了一个dev分支开始做这个功能
开发到一半
产品经理:算了,这个功能取消了。
我:… 好的。
那我就只能删除这个dev分支。
我们之前学的git branch -d 是merge之后删,git是允许我们删的。
但是现在我在dev分支上做了若干commit了,git是会保护我们的分支的,不让删。
此时要用强制删除命令:
git branch -D dev # 把-d改成-D就是强制删除,当然还是要记得切到master上才能删dev
相关文章:
Git企业开发控制理论和实操-从入门到深入(三)|分支管理
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总 然后就是博主最近最花时间的一个专栏…...

【VsCode】SSH远程连接Linux服务器开发,搭配cpolar内网穿透实现公网访问(1)
文章目录 前言1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...
LC-1267. 统计参与通信的服务器(枚举 + 计数)
1267. 统计参与通信的服务器 中等 这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。 如果两台服务器位于同一行或者同一列,我们就认为它们之间可以进行通信。 请…...
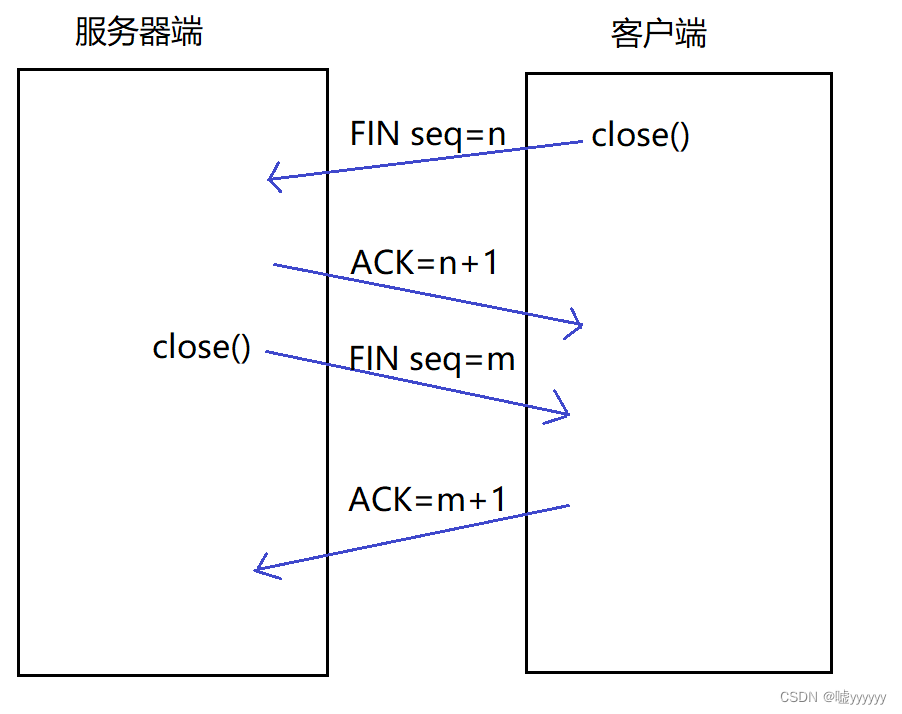
Linux TCP协议——三次握手,四次挥手
一、TCP协议介绍 TCP协议是可靠的、面向连接的、基于字节流的传输层通信协议。 TCP的头部结构: 源/目的端口号: 表示数据是从哪个进程来, 到哪个进程去;(tcp是传输层的协议,端与端之间的数据传输,在TCP和UDP协议当中不会体现出I…...
人机对抗智能-部分可观测异步智能体协同(POAC)
环境链接:数据中心-人机对抗智能 (ia.ac.cn)http://turingai.ia.ac.cn/data_center/show/10 1.环境配置 Ubuntu 20.04 Anaconda python版本3.6 1.1 安装torch0.4.1失败 参考文章: 安装torch0.4.1的神坑_torch0.4.1_DEMO_Tian的博客-CSDN博客 co…...
数学——七桥问题——图论
当涉及数学,有很多不同的话题可以讨论。你是否有特定的数学领域、概念或问题想要了解更多?以下是一些常见的数学领域和主题,你可以选择一个或者告诉我你感兴趣的具体内容,我将很乐意为你提供更多信息: 代数学ÿ…...

python 模块lxml 处理 XML 和 HTML 数据
xpath:https://blog.csdn.net/randy521520/article/details/132432903 一、安装 XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。 pip install lxml二、使用案例 from lxml impo…...

SpringBoot 统⼀功能处理
统⼀功能处理 1. 拦截器2. 统⼀异常处理3. 统⼀数据返回格式 1. 拦截器 Spring 中提供了具体的实现拦截器:HandlerInterceptor,拦截器的实现分为以下两个步骤: 创建⾃定义拦截器,实现 HandlerInterceptor 接⼝的 preHandle&…...

hadoop 报错 java.io.IOException: Inconsistent checkpoint fields
背景: 使用了格式化,导致首重了新的集群ID org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /work1/home/hadoop/dfs/data/current/BP-1873526852-172.16.21.30-1692769875005 is in an inconsistent state: namespaceID is incompatible with …...
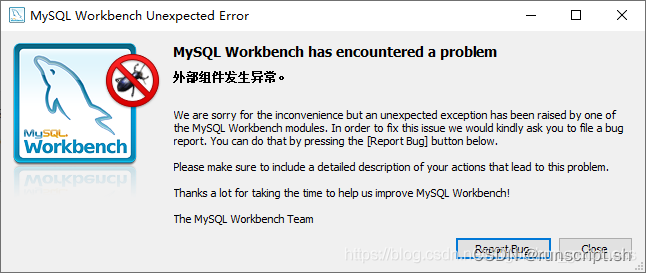
workbench连接MySQL8.0错误 bad conversion 外部组件 异常
阿里云搭建MySQL实用的版本是8.0 本地安装的版本是: workbench 6.3 需要升级到: workbench 8.0 https://dev.mysql.com/downloads/workbench/...
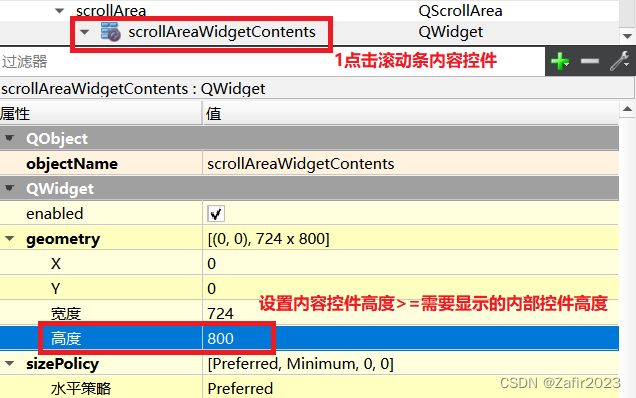
Qt Scroll Area控件设置,解决无法显示全部内容,且无法滚动显示问题。
前言,因为要显示很多条目的内容,原来是用Vertical Layout控件里面嵌套Horizontal layout显示了很多行控件,发现最简单的方法就是使用滚动条控件,但是无论如何调整需要滚动的控件高度,始终无法滚动显示内容。也就是说添…...
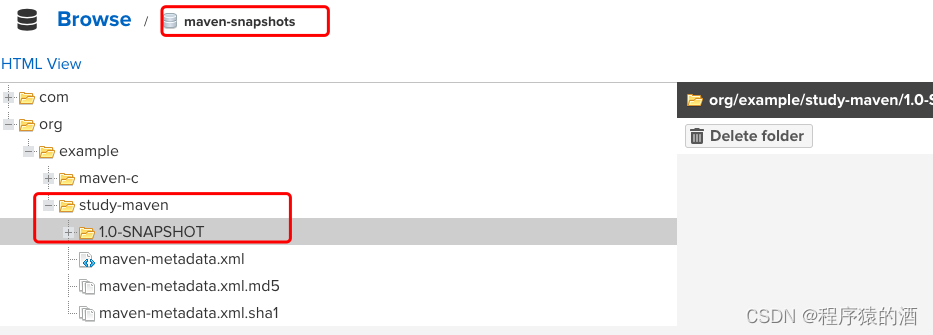
【Java架构-包管理工具】-Maven私服搭建-Nexus(三)
本文摘要 Maven作为Java后端使用频率非常高的一款依赖管理工具,在此咱们由浅入深,分三篇文章(Maven基础、Maven进阶、私服搭建)来深入学习Maven,此篇为开篇主要介绍Maven私服搭建-Nexus 文章目录 本文摘要1. Nexus安装…...

守护进程(精灵进程)
目录 前言 1.如何理解前台进程和后台进程 2.守护进程的概念 3.为什么会存在守护进程 4.如何实现守护进程 5.测试 总结 前言 今天我们要介绍的是关于守护进程如何实现,可能有小伙伴第一次听到守护进程这个概念,感觉很懵,知道进程的概念&…...
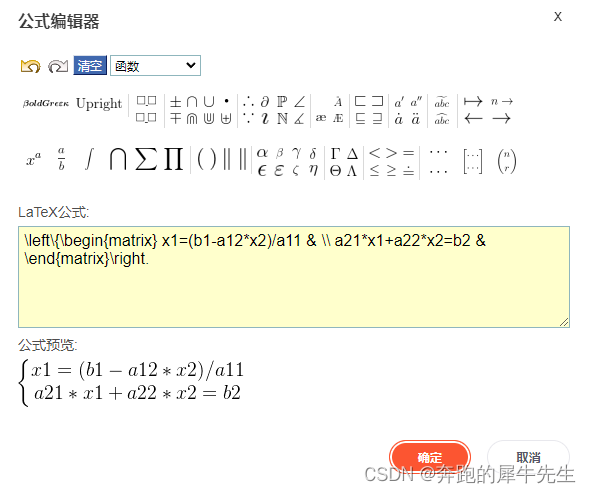
csdn冷知识:如何在csdn里输入公式或矩阵
目录 1 输入公式 2 输入矩阵 3 如何输入复杂公式 4 如何修改,已经生成的公式 1 输入公式 进入编辑模式点击右边的菜单:公式然后进入公式编辑器,选择右边的 ... 可以选择大括号等,右边还有矩阵符号选择后你需要创建几行几列的…...

【前端】CSS技巧与样式优化
目录 一、前言二、精灵图1、什么是精灵图2、为什么需要精灵图3、精灵图的使用①、创建CSS精灵图的步骤1)、选择合适的图标2)、合并图片3)、设置背景定位 ②、优化CSS精灵图的技巧1)、维护方便2)、考虑Retina屏幕3&…...
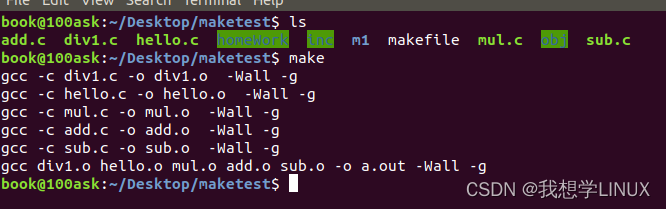
Linux下的系统编程——makefile入门
前言: 或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员,makefile还是要懂。这就好像现在有这么多的HTML的编辑器,但如果你想成为一个专…...

redis常用五种数据类型详解
目录 前言: string 相关命令 内部编码 应用场景 hash 相关命令 内部编码 应用场景 list 相关命令 内部编码 应用场景 set 相关命令 内部编码 应用场景 Zset 相关命令 内部编码 应用场景 渐进式遍历 前言: redis有多种数据类型&…...

Python代理池健壮性测试 - 压力测试和异常处理
大家好!在构建一个可靠的Python代理池时,除了实现基本功能外,我们还需要进行一系列健壮性测试来确保其能够稳定运行,并具备应对各种异常情况的能力。本文将介绍如何使用压力测试工具以及合适的异常处理机制来提升Python代理池的可…...

回文子串-中心拓展
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不…...

2023.8各大浏览器11家对比:Edge/Chrome/Opera/Firefox/Tor/Vivaldi/Brave,安全性,速度,体积,内存占用
测试环境:全默认设置的情况下,均在全新的系统上进行测试,系统并未进行任何改动,没有杀毒软件,浏览器进程全部在后台,且为小窗模式,小窗分辨率均为浏览器厂商默认缩放大小(变量不唯一)࿰…...

手把手教你用MATLAB图形放大法找方程根:从画图到定位,解决迭代法初值难题
手把手教你用MATLAB图形放大法找方程根:从画图到定位,解决迭代法初值难题 在数值计算的世界里,寻找方程的根就像在黑暗森林中探险——没有地图的指引,盲目选择起点可能导致算法陷入无限循环或收敛到错误解。而MATLAB的图形放大法&…...
)
从‘盲人摸象’到‘全局视野’:手把手教你用MATLAB/Simulink仿真PSO-MPPT对抗光伏遮荫(避坑指南)
从‘盲人摸象’到‘全局视野’:手把手教你用MATLAB/Simulink仿真PSO-MPPT对抗光伏遮荫(避坑指南) 光伏发电系统在局部遮荫条件下,功率-电压特性曲线会呈现多峰值现象,传统MPPT算法容易陷入局部最优。粒子群优化&#x…...

2026降AI率工具红黑榜:降AIGC工具怎么选?照着用就行!
2026年论文降AI率工具竞争激烈,千笔AI、ThouPen、豆包凭借精准适配国内高校AI率检测规范成为红榜首选。黑榜需警惕低质免费工具、无正规检测对接、改写痕迹生硬的产品。选择时应综合考量(降AI效果 - 学术合规性 - 使用成本)三维模型ÿ…...

谷歌搜索重大更新:更智能个性化,多项新功能即将上线!
谷歌搜索迈向更智能、更个性化时代曾几何时,谷歌搜索简洁易用,只需在搜索框输入关键词,浏览蓝色链接列表即可。然而,如今人工智能已层层覆盖搜索模式。2026 年谷歌 I/O 大会上,谷歌宣布一系列搜索更新,使搜…...

华为鸿蒙与欧拉操作系统:全场景战略下的技术架构与生态构建
1. 从“备胎”到“主干”:华为操作系统的战略突围之路 最近科技圈里关于华为的消息,大家讨论得最多的,除了孟晚舟女士的归国,可能就是华为在软件领域接连放出的几个“大招”了。作为一名在ICT行业摸爬滚打了十几年的老兵ÿ…...

将JSON文件作为Python的配置文件,读取和使用的写法
import osimport json#获取配置path os.getcwd() os.sep "config.json"conf Nonewith open(path, "r", encoding"utf-8") as f:if conf is None:conf json.loads(f.read())heard {"_token": f"{conf[token]}"}...

C语言编程实战:ASCII码表的深度解析与应用
1. ASCII码表:程序员的字符密码本 第一次接触ASCII码表时,我盯着那张密密麻麻的数字字符对照表发呆了半小时。直到在调试程序时发现字母A居然能用数字65代替,才突然意识到:这简直就是程序员世界的摩斯密码。ASCII(Amer…...
)
保姆级教程:从驱动安装到一键烧录,用JLink和JFlash给STM32烧程序(附常见连接失败解决方法)
从零玩转JLink与JFlash:STM32烧录全流程实战指南 第一次拿到JLink调试器时,我盯着那个黑色的小盒子看了足足五分钟——USB接口该插电脑哪一端?驱动安装失败怎么办?芯片型号选错会烧毁设备吗?作为过来人,我完…...
)
蓝桥杯单片机备赛:AT24C02读写避坑指南(附STC15完整工程)
蓝桥杯单片机备赛:AT24C02读写避坑指南(附STC15完整工程) 在蓝桥杯单片机竞赛中,AT24C02这颗小小的EEPROM芯片常常成为决定胜负的关键。作为参赛选手,你可能已经掌握了I2C协议的基本原理,但在紧张的比赛环境…...

Symfony String测试指南:如何编写高质量的字符串操作测试用例
Symfony String测试指南:如何编写高质量的字符串操作测试用例 【免费下载链接】string Provides an object-oriented API to strings and deals with bytes, UTF-8 code points and grapheme clusters in a unified way 项目地址: https://gitcode.com/gh_mirrors…...