juc基础(三)
目录
一、读写锁
1、读写锁介绍
2、ReentrantReadWriteLock
3、例子
4、小结
二、阻塞队列
1、BlockingQueue 简介
2、BlockingQueue 核心方法
3、案例
4、常见的 BlockingQueue
(1)ArrayBlockingQueue(常用)
(2)LinkedBlockingQueue(常用)
(3)DelayQueue
(4)PriorityBlockingQueue
(5)SynchronousQueue
(6)LinkedTransferQueue
(7)LinkedBlockingDeque
一、读写锁
1、读写锁介绍
- 没有其他线程的写锁
- 没有写请求, 或者有写请求,但调用线程和持有锁的线程是同一个(可重入锁)。
- 没有其他线程的读锁
- 没有其他线程的写锁
2、ReentrantReadWriteLock
public class ReentrantReadWriteLock implements ReadWriteLock,java.io.Serializable {/*** 读锁*/private final ReentrantReadWriteLock.ReadLock readerLock;/*** 写锁*/private final ReentrantReadWriteLock.WriteLock writerLock;final Sync sync;/*** 使用默认(非公平)的排序属性创建一个新的* ReentrantReadWriteLock*/public ReentrantReadWriteLock() {this(false);}/*** 使用给定的公平策略创建一个新的 ReentrantReadWriteLock*/public ReentrantReadWriteLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();readerLock = new ReadLock(this);writerLock = new WriteLock(this);}/*** 返回用于写入操作的锁*/public ReentrantReadWriteLock.WriteLock writeLock() {returnwriterLock;}/*** 返回用于读取操作的锁*/public ReentrantReadWriteLock.ReadLock readLock() {returnreaderLock;}abstract static class Sync extends AbstractQueuedSynchronizer {}static final class NonfairSync extends Sync {}static final class FairSync extends Sync {}public static class ReadLock implements Lock, java.io.Serializable {}public static class WriteLock implements Lock, java.io.Serializable {}
}3、例子
//资源类
class MyCache {//创建map集合private volatile Map<String,Object> map = new HashMap<>();//创建读写锁对象private ReadWriteLock rwLock = new ReentrantReadWriteLock();//放数据public void put(String key,Object value) {//添加写锁rwLock.writeLock().lock();try {System.out.println(Thread.currentThread().getName()+" 正在写操作"+key);//暂停一会TimeUnit.MICROSECONDS.sleep(300);//放数据map.put(key,value);System.out.println(Thread.currentThread().getName()+" 写完了"+key);} catch (InterruptedException e) {e.printStackTrace();} finally {//释放写锁rwLock.writeLock().unlock();}}//取数据public Object get(String key) {//添加读锁rwLock.readLock().lock();Object result = null;try {System.out.println(Thread.currentThread().getName()+" 正在读取操作"+key);//暂停一会TimeUnit.MICROSECONDS.sleep(300);result = map.get(key);System.out.println(Thread.currentThread().getName()+" 取完了"+key);} catch (InterruptedException e) {e.printStackTrace();} finally {//释放读锁rwLock.readLock().unlock();}return result;}
}public class ReadWriteLockDemo {public static void main(String[] args) throws InterruptedException {MyCache myCache = new MyCache();//创建线程放数据for (int i = 1; i <=5; i++) {final int num = i;new Thread(()->{myCache.put(num+"",num+"");},String.valueOf(i)).start();}TimeUnit.MICROSECONDS.sleep(300);//创建线程取数据for (int i = 1; i <=5; i++) {final int num = i;new Thread(()->{myCache.get(num+"");},String.valueOf(i)).start();}}
}4、小结
二、阻塞队列
1、BlockingQueue 简介
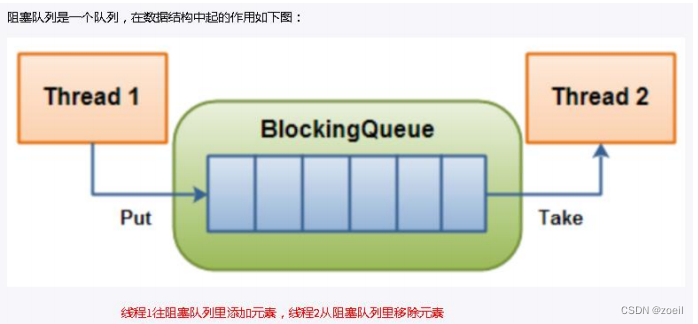
- 先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能。 从某种程度上来说这种队列也体现了一种公平性
- 后进先出(LIFO):后插入队列的元素最先出队列,这种队列优先处理最近发 生的事件(栈)
2、BlockingQueue 核心方法
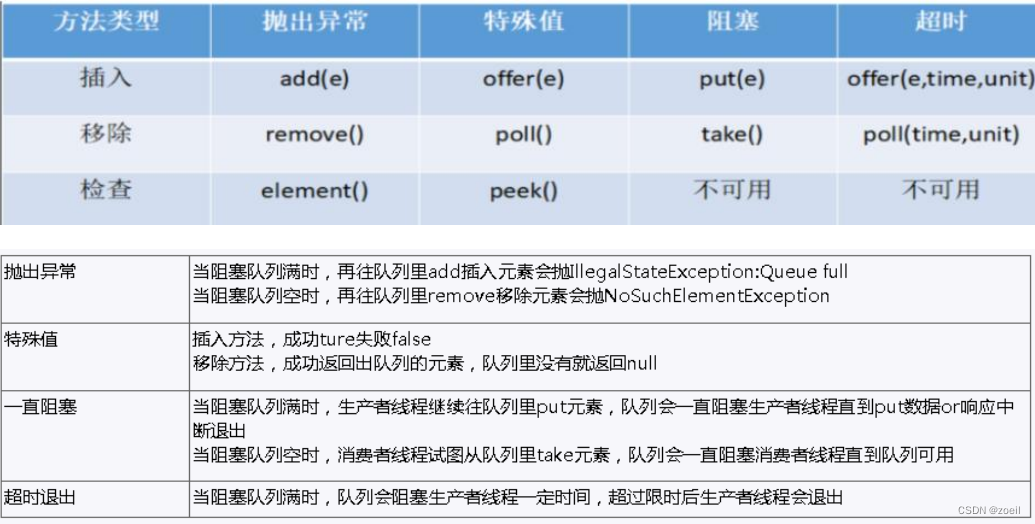
- offer(anObject):表示如果可能的话,将 anObject 加到 BlockingQueue 里,即如果 BlockingQueue 可以容纳,则返回 true,否则返回 false.(本方法不阻塞当前执行方法的线程)
- offer(E o, long timeout, TimeUnit unit):可以设定等待的时间,如果在指定的时间内,还不能往队列中加入 BlockingQueue,则返回失败
- put(anObject):把 anObject 加到 BlockingQueue 里,如果 BlockQueue 没有空间,则调用此方法的线程被阻断直到 BlockingQueue 里面有空间再继续.
(2)获取数据
- poll(time): 取走 BlockingQueue 里排在首位的对象,若不能立即取出,则可以等time 参数规定的时间,取不到时返回 null
- poll(long timeout, TimeUnit unit):从 BlockingQueue 取出一个队首的对象,如果在指定时间内,队列一旦有数据可取,则立即返回队列中的数据。否则知道时间超时还没有数据可取,返回失败。
- take(): 取走 BlockingQueue 里排在首位的对象,若 BlockingQueue 为空,阻断进入等待状态直到 BlockingQueue 有新的数据被加入;
- drainTo(): 一次性从 BlockingQueue 获取所有可用的数据对象(还可以指定获取数据的个数),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
3、案例
//阻塞队列
public class BlockingQueueDemo {public static void main(String[] args) throws InterruptedException {//创建阻塞队列BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);//第一组
// System.out.println(blockingQueue.add("a"));System.out.println(blockingQueue.add("b"));System.out.println(blockingQueue.add("c"));//System.out.println(blockingQueue.element());//System.out.println(blockingQueue.add("w")); // 队列满,报异常System.out.println(blockingQueue.remove());System.out.println(blockingQueue.remove());System.out.println(blockingQueue.remove());System.out.println(blockingQueue.remove()); // 队列空,报异常//第二组
// System.out.println(blockingQueue.offer("a"));
// System.out.println(blockingQueue.offer("b"));
// System.out.println(blockingQueue.offer("c"));
// System.out.println(blockingQueue.offer("www")); // 队列满,返回false不报错
//
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll());
// System.out.println(blockingQueue.poll()); //队列空,返回null//第三组
// blockingQueue.put("a");
// blockingQueue.put("b");
// blockingQueue.put("c");
// //blockingQueue.put("w"); // 队列满,阻塞当前线程,等待队列有空位放进去
//
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take());
// System.out.println(blockingQueue.take()); // 队列空,阻塞当前线程,等待队列不为空取数据//第四组System.out.println(blockingQueue.offer("a"));System.out.println(blockingQueue.offer("b"));System.out.println(blockingQueue.offer("c"));System.out.println(blockingQueue.offer("w",3L, TimeUnit.SECONDS));}
}4、常见的 BlockingQueue
(1)ArrayBlockingQueue(常用)
(2)LinkedBlockingQueue(常用)
(3)DelayQueue
(4)PriorityBlockingQueue
(5)SynchronousQueue
(6)LinkedTransferQueue
(7)LinkedBlockingDeque
- 插入元素时: 如果当前队列已满将会进入阻塞状态,一直等到队列有空的位置时再讲该元素插入,该操作可以通过设置超时参数,超时后返回 false 表示操作失败,也可以不设置超时参数一直阻塞,中断后抛出 InterruptedException 异常
- 读取元素时: 如果当前队列为空会阻塞住直到队列不为空然后返回元素,同样可以通过设置超时参数
相关文章:
juc基础(三)
目录 一、读写锁 1、读写锁介绍 2、ReentrantReadWriteLock 3、例子 4、小结 二、阻塞队列 1、BlockingQueue 简介 2、BlockingQueue 核心方法 3、案例 4、常见的 BlockingQueue (1)ArrayBlockingQueue(常用) (2)Li…...
c语言函数指针和指针函数的区别,以及回调函数的使用。
函数指针是什么,函数指针本质也是指针,不过是指向函数的指针,存储的是函数的地址。 指针函数是什么,指针函数其实就是返回值是指针的函数,本质是函数。 函数指针是如何定义的呢,如下 void (*pfun)(int a,int b) 这…...

什么是服务端渲染?前后端分离的优点和缺点?
一.概念 服务端渲染简单点就是服务端直接返回给客户端一个完整的页面,也就是一个完整的html页面,这个页面上已经有数据了。说到这里你可能会觉得后端怎么写页面啊,而且服务端返回页面不是加载更慢吗?错了,因为我们现在…...

【Java】优化重复冗余代码的8种方式
文章目录 前言1. 抽取公用方法2. 抽工具类3. 反射4.泛型5. 继承与多态6.使用设计模式7.自定义注解(或者说AOP面向切面)8.函数式接口和Lambda表达式 前言 日常开发中,我们经常会遇到一些重复代码。大家都知道重复代码不好,它主要有这些缺点:可…...
rabbitmq卸载重新安装3.8版本
卸载之前的版本的rabbitmq 卸载rabbitmq 卸载前先停止rabbitmq服务 /usr/lib/rabbitmq/bin/rabbitmqctl stop查看rabbitmq安装的相关列表 yum list | grep rabbitmq卸载rabbitmq相关内容 yum -y remove rabbitmq-server.noarch 卸载erlang 查看erlang安装的相关列表 …...

MyBatis分页思想和特殊字符
目录 一、MyBatis分页思想 1.1 使用场景 1.2 代码演示 二、MyBatis特殊字符 2.1代码演示 一、MyBatis分页思想 1.1 使用场景 Mybatis分页应用场景: MyBatis是一个Java持久层框架,它提供了一种将SQL查询和结果映射到Java对象的简单方式。分页是MyBa…...

设计模式大白话——命令模式
命令模式 一、概述二、经典举例三、代码示例(Go)四、总结 一、概述 顾名思义,命令模式其实和现实生活中直接下命令的动作类似,怎么理解这个命令是理解命令模式的关键!!!直接说结论是很不负责…...
[线程/C++(11)]线程池
文章目录 一、C实现线程池1. 头文件2. 测试部分 二、C11实现线程池1. 头文件2. 测试部分 一、C实现线程池 1. 头文件 #define _CRT_SECURE_NO_WARNINGS #pragma once #include<iostream> #include<string.h> #include<string> #include<pthread.h> #…...

VR防地质灾害安全教育:增强自然灾害知识,提高自我保护意识
VR防地质灾害安全教育系统是一种虚拟仿真技术,可以通过虚拟现实技术模拟地震、泥石流、滑坡等地质灾害的发生和应对过程,帮助人们提高应对突发自然灾害的能力。这种系统的优势在于可以增强自然灾害知识,提高自我保护意识,锻炼人们…...

Mybatis多对多查询案例!
在MyBatis中执行多对多查询需要使用两个主要表和一个连接表(通常称为关联表)来演示。在这个示例中,我们将使用一个示例数据库模型,其中有三个表:students、courses 和 student_courses,它们之间建立了多对多…...
Android OpenCV(七十五): 看看刚”转正“的条形码识别
前言 2021年,我们写过一篇《OpenCV 条码识别 Android 平台实践》,当时的条形码识别模块位于 opencv_contrib 仓库,但是 OpenCV 4.8.0 版本开始, 条形码识别模块已移动到 OpenCV 主仓库,至此我们无需自行编译即可轻松地调用条形码识别能力。 Bar code detector and decoder…...
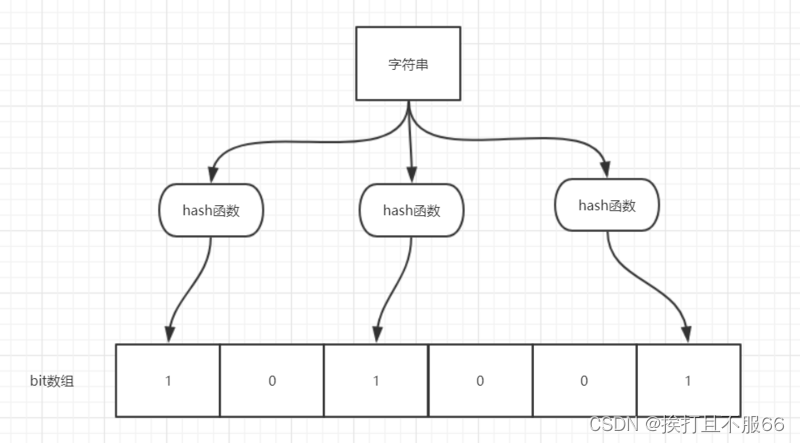
数据结构——布隆计算器
文章目录 1.什么是布隆过滤器?2.布隆过滤器的原理介绍3.布隆过滤器使用场景4.通过 Java 编程手动实现布隆过滤器5.利用Google开源的 Guava中自带的布隆过滤器6.Redis 中的布隆过滤器6.1介绍6.2使用Docker安装6.3常用命令一览6.4实际使用 1.什么是布隆过滤器…...

金融学复习博迪(第6-9章)
第6章 投资项目分析 学习目的:解释资本预算;资本预算基本法则 资本预算过程包含三个基本要素: 一提出针对投资项目的建议 一对这些建议进行评价 一决定接受和拒绝哪些建议 6.1项目分析的特性 资本预算的过程中的基本单位是单个的投资项目。投…...
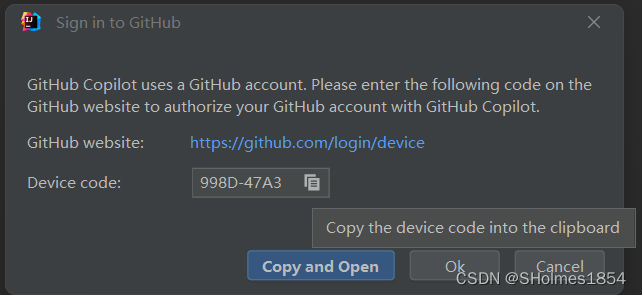
解决idea登录github copilot报错问题
试了好多方案都没用,但是这个有用, 打开idea-help-edit custonm vm options 然后在这个文件里面输入 -Dcopilot.agent.disabledtrue再打开 https://github.com/settings/copilot 把这个设置成allow,然后重新尝试登录copilot就行就行 解决方…...

什么是Flex布局?请列举一些Flex布局的常用属性。
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ Flex布局(Flexible Box Layout)⭐ Flex布局的常用属性⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之…...

React + TypeScript + antd 常见开发场景
时间戳转格式 // 获取当前时间戳(示例) const timestamp Date.now(); // 或者使用特定的时间戳值// 创建一个新的Date对象,并传入时间戳 const date new Date(timestamp);// 获取年、月、日的值 const year date.getFullYear(); const mon…...
前端基础踩坑记录
前言:在做vue项目时,有时代码没有报错,但运行时却各种问题,没有报错排查起来就很费劲,本人感悟:写前端,需要好的眼神!!!谨以此博客记录下自己的踩坑点。 一、…...

k8s删除pod镜像没响应marking for deletion pod TaintManagerEviction
使用命令强制删除 Pod的状态为"Marking for deletion"表示该Pod正在被标记为待删除状态,但实际上并没有被删除。这可能是因为以下原因之一: 删除操作被阻塞:可能是由于某些资源或容器正在使用该Pod,导致删除操作被阻塞…...

Nginx 使用 lua-nginx-module 来获取post请求中的request和response信息
如果想要在nginx中打印出 http request 的所有 header,需要在编译nginx时开启 1、安装编译所需的依赖 apt-get install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev2、创建下载路径 mkdir -p /opt/download3、下载所需的文件 # 不要下载…...
函数(1))
【Opencv】三维重建之cv::recoverPose()函数(1)
官网链接 从估计的本质矩阵和两幅图像中的对应点恢复相机之间的旋转和平移,使用光束法则进行检验。返回通过检验的内点数目。 #include <opencv2/calib3d.hpp>int cv::recoverPose ( InputArray E, InputArray points1, InputArray points2, InputArray …...

终极指南:10分钟将WinForms应用升级为现代化Material Design界面
终极指南:10分钟将WinForms应用升级为现代化Material Design界面 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin 你是否厌倦了传…...
)
用LAMMPS做材料分析?手把手教你用Ovito绘制应力、温度、速度云图(附完整脚本)
从LAMMPS到Ovito:材料模拟数据可视化的全流程实战指南 在计算材料科学领域,分子动力学模拟产生的海量数据如何转化为直观、可发表的科学图表,一直是研究者面临的挑战。本文将系统介绍从LAMMPS模拟到Ovito可视化的完整工作流,重点解…...

安装部署Keystone
一、以下命令安装了Keystone组件的必要软件包。 [rootcontroller ~]# yum -y install openstack-keystone httpd mod_wsgi 二、MariaDB数据库配置 [rootcontroller ~]# mysql -uroot -p000000 查看当前已有数据库: show databases;第2步,新建“keyston…...

告别手动Coding:用EB tresos Studio配置TC3xx芯片MCAL的保姆级图文指南
告别手动Coding:用EB tresos Studio配置TC3xx芯片MCAL的保姆级图文指南 当TC3xx系列芯片遇上AUTOSAR架构,传统寄存器级开发方式正在被图形化配置彻底革新。对于每天需要面对微控制器底层驱动的嵌入式工程师而言,EB tresos Studio提供的可视化…...
)
从YOLOv5到昇腾NPU:一份避坑无数的PyTorch模型迁移实战笔记(含性能调优)
从YOLOv5到昇腾NPU:一份避坑无数的PyTorch模型迁移实战笔记(含性能调优) 去年接手一个工业质检项目时,客户要求在昇腾NPU上部署YOLOv5模型。本以为只是简单的环境适配,没想到从驱动安装到性能调优,整整踩了…...

Lusca CSP策略完全指南:构建安全的内容安全策略
Lusca CSP策略完全指南:构建安全的内容安全策略 【免费下载链接】lusca Application security for express apps. 项目地址: https://gitcode.com/gh_mirrors/lu/lusca Lusca是一款专为Express应用打造的安全中间件,提供了全面的内容安全策略&…...

Commit Mono版本管理指南:如何优雅地升级和回滚字体版本
Commit Mono版本管理指南:如何优雅地升级和回滚字体版本 【免费下载链接】commit-mono Commit Mono is an anonymous and neutral programming typeface. 项目地址: https://gitcode.com/gh_mirrors/co/commit-mono Commit Mono是一款匿名且中性的编程字体&a…...

科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单
更多请点击: https://codechina.net 第一章:科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单 在论文投稿前的关键窗口期,快速定位权威参考文献是提升学术严谨性与跨学科说服力的核心能力。…...
)
保姆级教程:用Unity+OpenCVSharp插件实现摄像头实时轮廓检测与交互(附完整C#代码)
Unity与OpenCVSharp实战:从摄像头捕捉到交互式轮廓检测全流程解析 在游戏开发与计算机视觉的交叉领域,实时图像处理正成为增强玩家沉浸感的新 frontier。想象一下:玩家只需在摄像头前挥动手势,游戏中的角色就能同步做出反应&#…...

【设计模式 09】桥接:两条路各走各的
这一课讲桥接模式。什么在变:多个维度各自独立变化,绑在一起会组合爆炸。怎么挡:拆成独立体系,用组合连接,各自扩展互不影响。陈敏把组织架构图展开在会议桌上的时候,在场所有人都看到了问题。 产品线三条&…...