Prompt-“设计提示模板:用更少数据实现预训练模型的卓越表现,助力Few-Shot和Zero-Shot任务”
Prompt任务(Prompt Tasks)
通过设计提示(prompt)模板,实现使用更少量的数据在预训练模型(Pretrained Model)上得到更好的效果,多用于:Few-Shot,Zero-Shot 等任务。
1.背景介绍
prompt 是当前 NLP 中研究小样本学习方向上非常重要的一个方向。举例来讲,今天如果有这样两句评论:
- 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
- 这破笔记本速度太慢了,卡的不要不要的。
现在我们需要根据他们描述的商品类型进行一个分类任务,
即,第一句需要被分类到「水果」类别中;第二句则需要分类到「电脑」类别中。
一种直觉的方式是将该问题建模成一个传统文本分类的任务,通过人工标注,为每一个类别设置一个 id,例如:
{'电脑': 0,'水果': 1,....
}这样一来,标注数据集就长这样:
什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃! 1
这破笔记本速度太慢了,卡的不要不要的。 0
...这种方法是可行的,但是需要「较多的标注数据」才能取得不错的效果。
由于大多数预训练模型(如 BRET)在 pretrain 的时候都使用了 [MASK] token 做 MLM 任务,而我们在真实下游任务中往往是不会使用到 [MASK] 这个 token,这就意味着今天我们在训练下游任务时需要较多的数据集去抹平上下游任务不一致的 gap。
那,如果我们没有足够多的训练数据怎么办呢?
prompt learning 的出现就是为了解决这一问题,它将 [MASK] 的 token 引入到了下游任务中,将下游任务构造成和 MLM 类似的任务。
举例来讲,我们可以将上述评论改写为:
这是一条[MASK][MASK]评论:这破笔记本速度太慢了,卡的不要不要的。然后让模型去预测两个 [MASK] token 的真实值是什么,那模型根据上下文能推测出被掩码住的词应该为「电脑」。
由于下游任务中也使用了和预训练任务中同样的 MLM 任务,这样我们就可以使用更少的训练数据来进行微调了。
但,这还不是 P-tuning。
通过上面的例子我们可以观察到,构建句子最关键的部分是在于 prompt 的生成,即:
「这是一条[MASK][MASK]评论:」(prompt) + 这破笔记本速度太慢了,卡的不要不要的。(content)被括号括起来的前缀(prompt)的生成是非常重要的,不同 prompt 会极大影响模型对 [MASK] 预测的正确率。
那么这个 prompt 怎么生成呢?
我们当然可以通过人工去设计很多不同类型的前缀 prompt,我们把他们称为 prompt pattern,例如:
这是一条[MASK][MASK]评论:
下面是一条描述[MASK][MASK]的评论:
[MASK][MASK]:
...但是人工列这种 prompt pattern 非常的麻烦,不同的数据集所需要的 prompt pattern 也不同,可复用性很低。
那么,我们能不能通过机器自己去学习 prompt pattern 呢?
这,就是 P-Tuning。
1.1 P-Tuning
人工构建的模板对人类来讲是合理的,但是在机器眼中,prompt pattern 长成什么样真的关键吗?
机器对自然语言的理解和人类对自然语言的理解很有可能不尽相同,我们曾经有做一个 model attention 和人类对语言重要性的理解的对比实验,发现机器对语言的理解和人类是存在一定的偏差的。
那么,我们是不是也不用特意为模型去设定一堆我们觉得「合理」的 prompt pattern,而是让模型自己去找它们认为「合理」的 prompt pattern 就可以了呢?
因此,P-Tuning 的训练一共分为:prompt token(s) 生成、mask label 生成、mlm loss 计算 三个步骤。
1.1.1 prompt token(s) 生成
既然现在我们不用人工去构建 prompt 模板,我们也不清楚机器究竟喜欢什么样的模板……
那不如我们就随便凑一个模板丢给模型吧。
听起来很草率,但确实就是这么做的。
我们选用中文 BERT 作为 backbon 模型,选用 vocab.txt 中的 [unused] token 作为构成 prompt 模板的元素。
[unused] 是 BERT 词表里预留出来的未使用的 token,其本身没有什么含义,随意组合也不会产生很大的语义影响,这也是我们使用它来构建 prompt 模板的原因。
那么,构建出来的 prompt pattern 就长这样:
[unused1][unused2][unused3][unused4][unused5][unused6] 1.1.2 mask label 生成
完成 prompt 模板的构建后,我们还需要把 mask label 给加到句子中,好让模型帮我们完成标签预测任务。
我们设定 label 的长度为 2(‘水果’、‘电脑’,都是 2 个字的长度),并将 label 塞到句子的开头位置:
[CLS][MASK][MASK]这破笔记本速度太慢了,卡的不要不要的。[SEP]其中 [MASK] token 就是我们需要模型帮我们预测的标签 token,现在我们把两个部分拼起来:
[unused1][unused2][unused3][unused4][unused5][unused6][CLS][MASK][MASK]这破笔记本速度太慢了,卡的不要不要的。[SEP]这就是我们最终输入给模型的样本。
1.1.3 mlm loss 计算
下面就要开始进行模型微调了,我们喂给模型这样的数据:
[unused1][unused2][unused3][unused4][unused5][unused6][CLS][MASK][MASK]这破笔记本速度太慢了,卡的不要不要的。[SEP]并获得模型预测 [MASK] token 的预测结果,并计算和真实标签之间的 CrossEntropy Loss。
P-Tuning 中标签数据长这样:
水果 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
电脑 这破笔记本速度太慢了,卡的不要不要的。
...也就是说,我们需要计算的是模型对 [MASK] token 的输出与「电脑」这两个标签 token 之间的 CrossEntropy Loss,以教会模型在这样的上下文中,被 [MASK] 住的标签应该被还原成「物品类别」。
1.1.4 实验
我们选用 63 条评论(8 个类别)的评论作为训练数据,在 417 条评论上作分类测试,模型 F1 能收敛在 76%。通过实验结果我们可以看到,基于 prompt 的方式即使在训练样本数较小的情况下模型也能取得较为不错的效果。相比于传统的分类方式,P-Tuning 能够更好的缓解模型在小样本数据下的过拟合,从而拥有更好的鲁棒性。
论文链接:https://arxiv.org/pdf/2103.10385.pdf
2.PET (PatternExploiting Training)
- 环境安装
本项目基于pytorch+transformers实现,运行前请安装相关依赖包:
pip install -r ../../requirements.txt
2.1 数据集准备
2.1.1 标签数据准备
项目中提供了一部分示例数据,根据用户评论预测用户评论的物品类别(分类任务),数据在 data/comment_classify 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
水果 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
书籍 为什么不认真的检查一下, 发这么一本脏脏的书给顾客呢!
酒店 性价比高的酒店,距离地铁近,邻华师大,环境好。
...
每一行用 \t 分隔符分开,前半部分为标签(label),后半部分为原始输入。
2.1.2 Verbalizer准备
Verbalizer用于定义「真实标签」到「标签预测词」之间的映射。
在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
"日本爆冷2-1战胜德国"是一则[MASK][MASK]新闻。 体育
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
体育 -> 足球,篮球,网球,棒球,乒乓,体育
...
项目中提供了一部分示例数据在 data/comment_classify/verbalizer.txt 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
电脑 电脑
水果 水果
平板 平板
衣服 衣服
酒店 酒店
洗浴 洗浴
书籍 书籍
蒙牛 蒙牛
手机 手机
在例子中我们使用 1 对 1 的verbalizer,若想定义一对多的映射,只需要在后面用 ',' 分隔即可, e.g.:
...
水果 苹果,香蕉,橘子
...
2.1.3 Prompt设定
promot是人工构建的模板,项目中提供了一部分示例数据在 data/comment_classify/prompt.txt 。
这是一条{MASK}评论:{textA}。
其中,用大括号括起来的部分为「自定义参数」,可以自定义设置大括号内的值。
示例中 {MASK} 代表 [MASK] token 的位置,{textA} 代表评论数据的位置。
你可以改为自己想要的模板,例如想新增一个 {textB} 参数:
{textA}和{textB}是{MASK}同的意思。
此时,除了修改 prompt 文件外,还需要在 utils.py 文件中 convert_example() 函数中修改 inputs_dict 用于给对应的给每一个「自定义参数」赋值:
...
content = content[:max_seq_len-10] # 防止当[MASK]在尾部的时候被截掉inputs_dict={ # 传入对应prompt的自定义参数'textA': content, 'MASK': '[MASK]','textB' = ... # 给对应的自定义字段赋值
}
...
2.2. 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python pet.py \--model "bert-base-chinese" \--train_path "data/comment_classify/train.txt" \--dev_path "data/comment_classify/dev.txt" \--save_dir "checkpoints/comment_classify/" \--img_log_dir "logs/comment_classify" \--img_log_name "BERT" \--verbalizer "data/comment_classify/verbalizer.txt" \ # verbalizer文件位置--prompt_file "data/comment_classify/prompt.txt" \ # prompt_file文件位置--batch_size 8 \--max_seq_len 256 \--valid_steps 40 \--logging_steps 5 \--num_train_epochs 200 \--max_label_len 2 \ # 子标签最大长度--rdrop_coef 5e-2 \--device "cuda:0" # 指定使用GPU
正确开启训练后,终端会打印以下信息:
...
DatasetDict({train: Dataset({features: ['text'],num_rows: 63})dev: Dataset({features: ['text'],num_rows: 590})
})
Prompt is -> 这是一条{MASK}评论:{textA}。
100%|████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 12.96ba/s]
100%|████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2.55ba/s]
global step 5, epoch: 0, loss: 3.74432, speed: 2.67 step/s
global step 10, epoch: 1, loss: 3.06417, speed: 5.86 step/s
global step 15, epoch: 1, loss: 2.51641, speed: 5.73 step/s
global step 20, epoch: 2, loss: 2.12264, speed: 5.84 step/s
global step 25, epoch: 3, loss: 1.80121, speed: 5.82 step/s
global step 30, epoch: 3, loss: 1.52964, speed: 5.78 step/s
...
在 logs/sentiment_classification 文件下将会保存训练曲线图:

2.3. 模型预测
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
...
contents = ['地理环境不错,但对面一直在盖楼,门前街道上打车不方便。','跟好朋友一起凑单买的,很划算,洗发露是樱花香的,挺好的。。。'] # 自定义评论
res = inference(contents) # 推测评论类型
...
运行推理程序:
python inference.py
得到以下推理结果:
Prompt is -> 这是一条{MASK}评论:{textA}。
Used 0.47s.
inference label(s): ['酒店', '洗浴']
3.P-tuning:Auto Learning prompt pattern
- 环境安装
本项目基于pytorch+transformers实现,运行前请安装相关依赖包:
pip install -r ../../requirements.txttorch
transformers==4.22.1
datasets==2.4.0
evaluate==0.2.2
matplotlib==3.6.0
rich==12.5.1
scikit-learn==1.1.2
requests==2.28.1
3.1 数据集准备
3.1.1 标签数据准备
项目中提供了一部分示例数据,根据用户评论预测用户评论的物品类别(分类任务),数据在 data/comment_classify 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
水果 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
书籍 为什么不认真的检查一下, 发这么一本脏脏的书给顾客呢!
酒店 性价比高的酒店,距离地铁近,邻华师大,环境好。
...
每一行用 \t 分隔符分开,前半部分为标签(label),后半部分为原始输入。
3.1.2 Verbalizer准备
Verbalizer用于定义「真实标签」到「标签预测词」之间的映射。
在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
"日本爆冷2-1战胜德国"是一则[MASK][MASK]新闻。 体育
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
体育 -> 足球,篮球,网球,棒球,乒乓,体育
...
项目中提供了一部分示例数据在 data/comment_classify/verbalizer.txt 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
电脑 电脑
水果 水果
平板 平板
衣服 衣服
酒店 酒店
洗浴 洗浴
书籍 书籍
蒙牛 蒙牛
手机 手机
在例子中我们使用 1 对 1 的verbalizer,若想定义一对多的映射,只需要在后面用 ',' 分隔即可, e.g.:
...
水果 苹果,香蕉,橘子
...
3.2 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python p_tuning.py \--model "bert-base-chinese" \ # backbone--train_path "data/comment_classify/train.txt" \--dev_path "data/comment_classify/dev.txt" \--verbalizer "data/comment_classify/verbalizer.txt" \ # verbalizer存放地址--save_dir "checkpoints/comment_classify/" \--img_log_dir "logs/comment_classify" \ # loss曲线图存放地址--img_log_name "BERT" \ # loss曲线图文件名--batch_size 16 \--max_seq_len 128 \--valid_steps 20 \--logging_steps 5 \--num_train_epochs 50 \--max_label_len 2 \ # 标签最大长度--p_embedding_num 15 \ # p_token长度--device "cuda:0" # 指定使用哪块gpu
正确开启训练后,终端会打印以下信息:
...
global step 5, epoch: 1, loss: 6.50529, speed: 4.25 step/s
global step 10, epoch: 2, loss: 4.77712, speed: 6.36 step/s
global step 15, epoch: 3, loss: 3.55371, speed: 6.19 step/s
global step 20, epoch: 4, loss: 2.71686, speed: 6.38 step/s
Evaluation precision: 0.70000, recall: 0.69000, F1: 0.69000
best F1 performence has been updated: 0.00000 --> 0.69000
global step 25, epoch: 6, loss: 2.20488, speed: 6.21 step/s
global step 30, epoch: 7, loss: 1.84836, speed: 6.22 step/s
global step 35, epoch: 8, loss: 1.58520, speed: 6.22 step/s
global step 40, epoch: 9, loss: 1.38746, speed: 6.27 step/s
Evaluation precision: 0.75000, recall: 0.75000, F1: 0.75000
best F1 performence has been updated: 0.69000 --> 0.75000
global step 45, epoch: 11, loss: 1.23437, speed: 6.14 step/s
global step 50, epoch: 12, loss: 1.11103, speed: 6.16 step/s
...
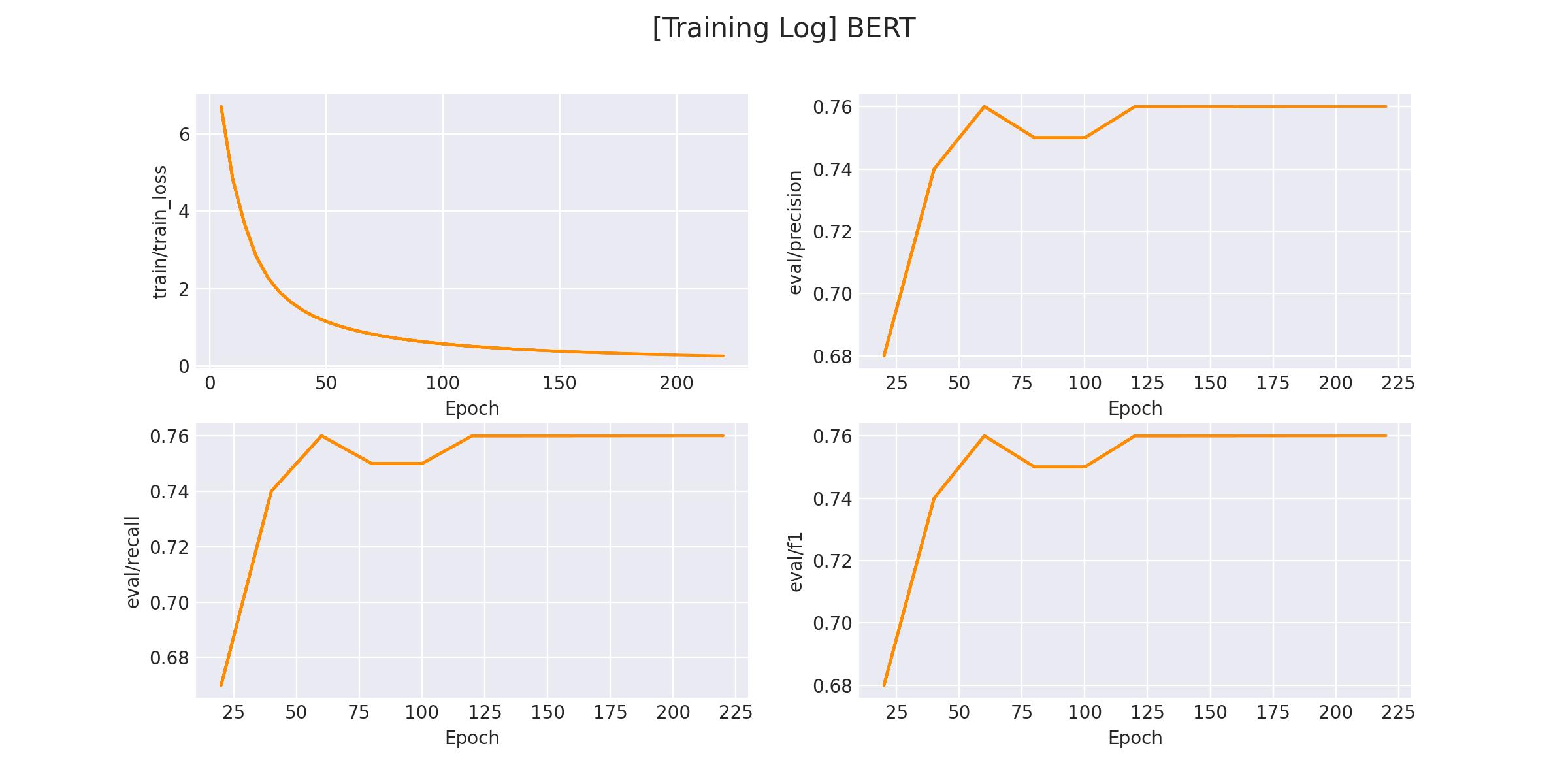
在 logs/sentiment_classification 文件下将会保存训练曲线图:
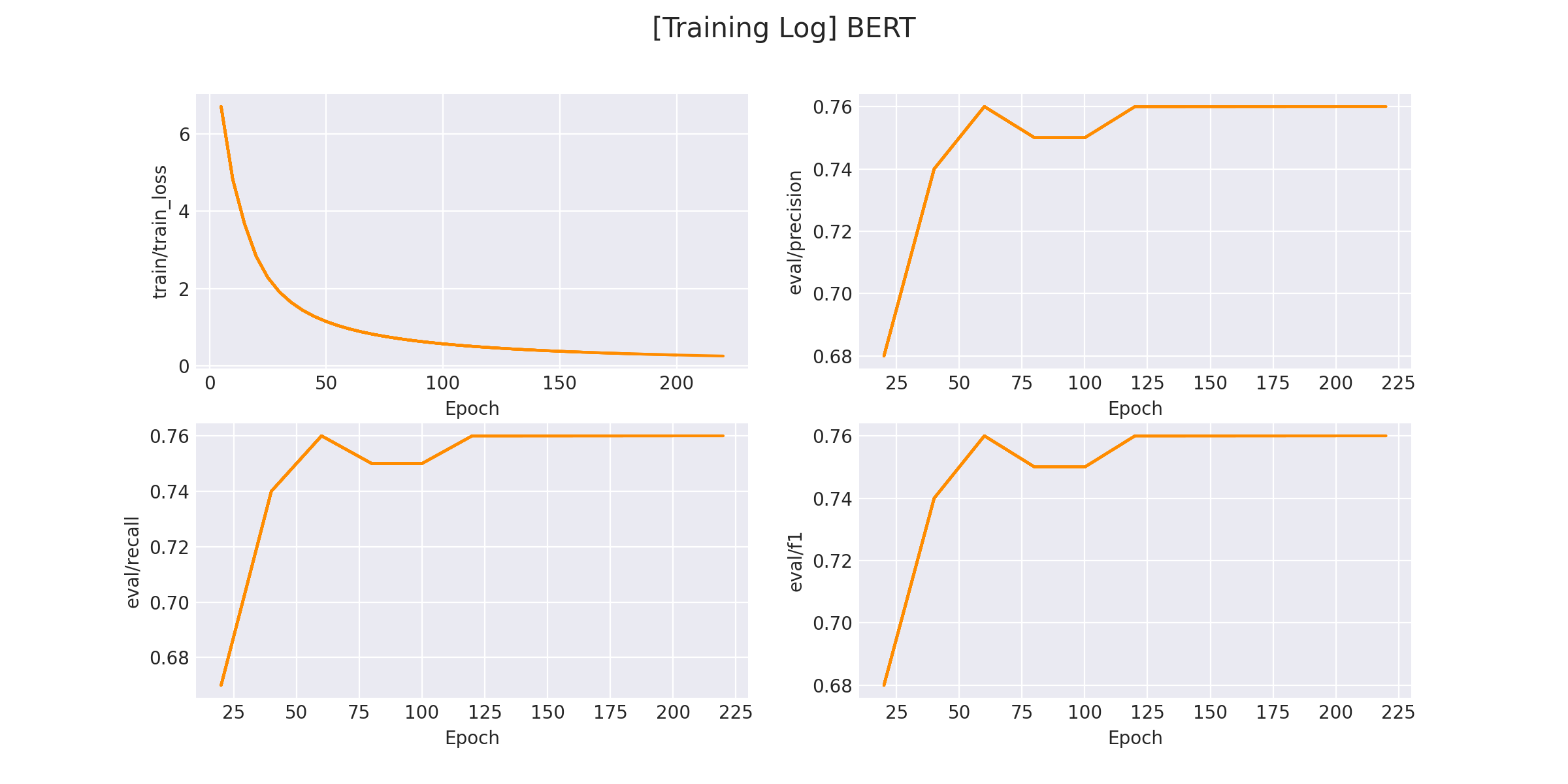
3.3 模型预测
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
...
contents = ["苹果卖相很好,而且很甜,很喜欢这个苹果,下次还会支持的", "这破笔记本速度太慢了,卡的不要不要的"
] # 自定义评论
res = inference(contents) # 推测评论类型
...
运行推理程序:
python inference.py
得到以下推理结果:
inference label(s): ['水果', '电脑']
参考链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/prompt_tasks/p-tuning
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

相关文章:
Prompt-“设计提示模板:用更少数据实现预训练模型的卓越表现,助力Few-Shot和Zero-Shot任务”
Prompt任务(Prompt Tasks) 通过设计提示(prompt)模板,实现使用更少量的数据在预训练模型(Pretrained Model)上得到更好的效果,多用于:Few-Shot,Zero-Shot 等…...

玩转Mysql系列 - 第6篇:select查询基础篇
这是Mysql系列第6篇。 环境:mysql5.7.25,cmd命令中进行演示。 DQL(Data QueryLanguage):数据查询语言,通俗点讲就是从数据库获取数据的,按照DQL的语法给数据库发送一条指令,数据库将按需求返回数据。 DQ…...
【SpringCloud技术专题】「Gateway网关系列」(1)微服务网关服务的Gateway组件的原理介绍分析
为什么要有服务网关? 我们都知道在微服务架构中,系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢?难道要一个个的去调用吗?很显然这是不太实际的,我们需要有一个统一的接口与这些微服务打交道…...

【面试刷题】————STL中的vector是如何实现的?
STL(Standard Template Library)是C标准库中的一部分,它提供了许多常用的数据结构和算法,其中包括了动态数组 vector。 vector std::vector 是一个动态数组,它能够自动调整自己的大小,以适应存储元素的需…...
)
使用钉钉的扫码会出现多个回调(DTFrameLogin)
官方:地址 标题 出现的问题解决后效果正常使用(按照官网的流程进行使用)自己的理解(路人可忽略该内容!) 出现的问题 1692861955468 解决后效果 1692861665687 正常使用(按照官网的流程进行使用) fn.js 该文件就是钉钉官网的js文件,我下载到了…...

Android | 关于 OOM 的那些事儿
作者:345丶 前言 Android 系统对每个app都会有一个最大的内存限制,如果超出这个限制,就会抛出 OOM,也就是Out Of Memory 。本质上是抛出的一个异常,一般是在内存超出限制之后抛出的。最为常见的 OOM 就是内存泄露(大量…...

珠玑妙算游戏
珠玑妙算游戏,OJ练习 一、描述二、方法一三、方法二 一、描述 珠玑妙算游戏(the game of master mind)的玩法如下: 计算机有4个槽,每个槽放一个球,颜色可能是红色(R)、黄色…...

【rust语言】rust多态实现方式
文章目录 前言一、多态二、rust实现多态trait的静态方式还有一种方式可以通过动态分发,还以上面那段代码,比如dyn关键字 泛型方式枚举方式优点:缺点: 总结 前言 学习rust当中遇到了这个问题,记录一下,不对…...

两年半机场,告诉我如何飞翔
为说明如何坐飞机离港,故此记录一篇。何为离港,顾名思义,离开港湾,那何为港湾,便是机场。 机场,一个你可能经常去,亦或不曾去之地。我想,管你去没去过,先说下怎么去&…...
【动手学深度学习】--21.锚框
锚框 学习视频:锚框【动手学深度学习v2】 官方笔记:锚框 1.锚框 目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(gro…...
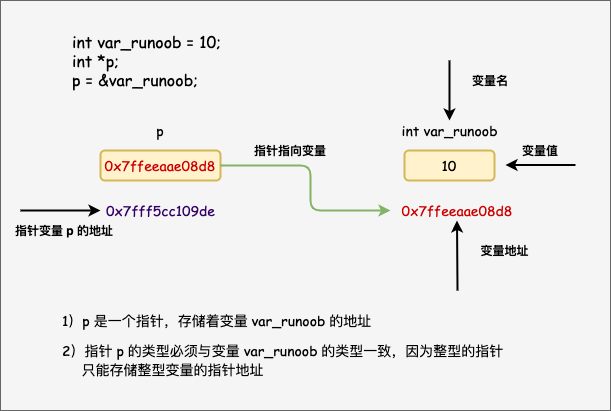
C语言学习笔记(完整版)
文章目录 算法算法的基本概念算法的特征算法的优劣 描述算法三种基本结构流程图N-S流程图伪代码 常量和变量了解数据类型常量整形常量实型常量字符型常量转义字符符号常量 变量整形变量实型变量字符型变量 表达式与运算符赋值运算符和赋值表达式变量赋初值强制类型转换 算术运算…...

【Unity3D赛车游戏】【四】在Unity中添加阿克曼转向,下压力,质心会让汽车更稳定
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

Python爬虫requests判断请求超时并重新post/get发送请求
在使用Python爬虫中,你可以使用requestsimport requests #Python爬虫requests判断请求超时并重新post发送请求,proxies为代理 def send_request_post(url, data, headers , proxies , max_retries3, timeout5):retries 0while retries < max_retries…...

CSS中如何实现多列布局?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 多列布局(Multi-column Layout)⭐ column-count⭐ column-width⭐ column-gap⭐ column-rule⭐ column-span⭐ 示例⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧…...

【C++】string简单实用详解
本片要分享的内容是有关于string的知识,在这之前得介绍一下什么是STL; 目录 1.STL简单介绍 2. string简单介绍 3.string简单使用 3.1.string的定义 3.2.字符串的拼接 3.3.string的遍历 3.3.1.循环遍历 3.3.2.迭代器遍历 4.string的函数构造 1.…...

opencv 进阶16-基于FAST特征和BRIEF描述符的ORB(图像匹配)
在计算机视觉领域,从图像中提取和匹配特征的能力对于对象识别、图像拼接和相机定位等任务至关重要。实现这一目标的一种流行方法是 ORB(Oriented FAST and Rotated Brief)特征检测器和描述符。ORB 由 Ethan Rublee 等人开发,结合了…...
Unity 类Scene窗口相机控制
类Scene窗口相机控制 🍔效果 🍔效果 传送门👈...
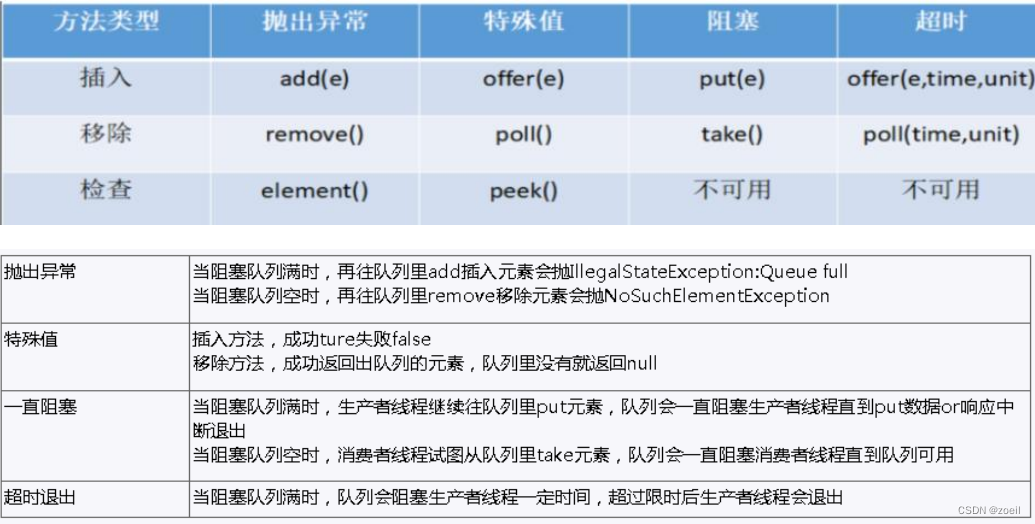
juc基础(三)
目录 一、读写锁 1、读写锁介绍 2、ReentrantReadWriteLock 3、例子 4、小结 二、阻塞队列 1、BlockingQueue 简介 2、BlockingQueue 核心方法 3、案例 4、常见的 BlockingQueue (1)ArrayBlockingQueue(常用) (2)Li…...
c语言函数指针和指针函数的区别,以及回调函数的使用。
函数指针是什么,函数指针本质也是指针,不过是指向函数的指针,存储的是函数的地址。 指针函数是什么,指针函数其实就是返回值是指针的函数,本质是函数。 函数指针是如何定义的呢,如下 void (*pfun)(int a,int b) 这…...

什么是服务端渲染?前后端分离的优点和缺点?
一.概念 服务端渲染简单点就是服务端直接返回给客户端一个完整的页面,也就是一个完整的html页面,这个页面上已经有数据了。说到这里你可能会觉得后端怎么写页面啊,而且服务端返回页面不是加载更慢吗?错了,因为我们现在…...

WechatRealFriends:微信好友关系检测终极方案深度解析
WechatRealFriends:微信好友关系检测终极方案深度解析 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...

观察Taotoken用量看板如何帮助团队精打细算每一分token
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken用量看板如何帮助团队精打细算每一分token 对于依赖大模型进行开发的团队而言,成本控制与预算规划是日常运…...

计算机视觉:YOLOv12安装环境
YOLOv12安装环境 一、工具软件准备 1、yolov12 1)下载yolov12主体部分 推荐官方地址:https://github.com/sunsmarterjie/yolov12 2)下载训练模型 地址: https://github.com/sunsmarterjie/yolov12 3)安装命令和p…...

Windows 11终极优化指南:使用Win11Debloat实现专业级系统调校
Windows 11终极优化指南:使用Win11Debloat实现专业级系统调校 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter…...

告别‘Requirement already satisfied’:精准定位Python环境,让pip install不再迷茫
1. 为什么pip总是说"已经安装好了"? 每次看到"Requirement already satisfied"这个提示,我都想对着屏幕大喊:"不!它根本没装在我想要的地方!"这种抓狂的感觉,相信很多Python…...

告别重影和误检:手把手教你为Apollo 7.0激光雷达数据做运动补偿
激光雷达运动补偿实战:解决Apollo 7.0中的点云畸变问题 当自动驾驶车辆以72km/h的速度行驶时,激光雷达每采集一帧点云的100毫秒内,车辆已经移动了2米。这个看似微小的位移,却会导致点云中出现车辆"分身"、建筑物扭曲等诡…...

新手避坑指南:STM32用Makefile编译时,遇到‘junk at end of line’错误怎么办?
STM32 Makefile编译实战:彻底解决junk at end of line汇编错误 第一次用Makefile编译STM32项目时,看到满屏的junk at end of line错误提示,确实容易让人头皮发麻。这就像你兴冲冲地下载了一个开源项目准备大展身手,结果刚执行make…...

Keil C51评估版SRC指令限制解析与解决方案
1. 问题现象与背景解析最近在调试一个基于8051架构的嵌入式项目时,遇到了一个令人困惑的编译错误。当我在Keil C51开发环境中使用SRC指令时,编译器突然报出致命错误(Fatal Error),但检查代码语法看起来完全正确。这个SRC指令是用来控制编译器…...

Qalculate! 终极数学计算库:从新手到专家的完整指南
Qalculate! 终极数学计算库:从新手到专家的完整指南 【免费下载链接】libqalculate Qalculate! library and CLI 项目地址: https://gitcode.com/gh_mirrors/li/libqalculate Qalculate! 是一个功能强大的开源数学计算库,它提供了从简单算术到复杂…...

堆叠集成方法
原文:towardsdatascience.com/the-stacking-ensemble-method-984f5134463a 发现堆叠在机器学习中的力量——一种将多个模型组合成一个单一强大预测器的技术。本文从基础知识到高级技术探讨了堆叠,揭示了它是如何结合不同模型的优势以提高准确性的。无论你…...