第60步 深度学习图像识别:误判病例分析(Pytorch)
基于WIN10的64位系统演示
一、写在前面
上期内容基于Tensorflow环境做了误判病例分析(传送门),考虑到不少模型在Tensorflow环境没有迁移学习的预训练模型,因此有必要在Pytorch环境也搞搞误判病例分析。
本期以SqueezeNet模型为例,因为它建模速度快。
同样,基于GPT-4辅助编程,后续会分享改写过程。
二、误判病例分析实战
继续使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)直接分享代码
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
from torch.nn.functional import softmax
import os
from PIL import Image
import pandas as pd
import torch.nn as nn
import timm
from torch.optim import lr_scheduler# 自定义的数据集类
class ImageFolderWithPaths(datasets.ImageFolder):def __getitem__(self, index):original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)path = self.imgs[index][0]tuple_with_path = (original_tuple + (path,))return tuple_with_path# 数据集路径
data_dir = "./MTB"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = ImageFolderWithPaths(data_dir, transform=data_transforms['train'])# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.8 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 应用数据增强到训练集和验证集
train_dataset.dataset.transform = data_transforms['train']
val_dataset.dataset.transform = data_transforms['val']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=0)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes# 获取数据集的类别
class_names = full_dataset.classes# 保存预测结果的列表
results = []###############################定义SqueezeNet模型################################
# 定义SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 这里以SqueezeNet 1.1版本为例
num_ftrs = model.classifier[1].in_channels# 根据分类任务修改最后一层
model.classifier[1] = nn.Conv2d(num_ftrs, len(class_names), kernel_size=(1,1))# 修改模型最后的输出层为我们需要的类别数
model.num_classes = len(class_names)model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 5# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'SqueezeNet_model-1.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################误判病例分析#################################
# 导入 os 库
import os# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels, paths in dataloaders[phase]: # 在这里添加 pathsinputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i, path in enumerate(paths): # 在这里添加 path 和 enumerate 函数# 获取图片的名称、标签、预测值和概率image_name = os.path.basename(path) # 使用 os.path.basename 函数获取图片名称original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到结果列表中results.append({"原始图片的名称": image_name,"属于训练集还是验证集": phase,"预测为Tuberculosis的概率值": probability[1].item(),"判定的组别": group})# 将结果保存为Pandas DataFrame,然后保存到csv文件
result_df = pd.DataFrame(results)
result_df.to_csv("result-2.csv", index=False)跟Tensorflow改写的类似,主要有两处变化:
(1)导入数据集部分:而在误判病例分析中,我们需要知道每一张图片的名称、被预测的结果等详细信息因此需要加载图片路径和图片名称的信息。
(2)误判病例分析部分:也就是需要知道哪些预测正确,哪些预测错误。
(b)调教GPT-4的过程
(b1)咒语:请根据{代码1},改写和续写《代码2》。代码1:{也就是之前用tensorflow写的误判病例分析部分};代码2:《也就是修改之前的SqueezeNet模型建模代码》
还是列出来吧:
代码1:
# 训练模型后,现在使用模型对所有图片进行预测,并保存预测结果到csv文件中
import pandas as pd# 保存预测结果的dataframe
result_df = pd.DataFrame(columns=["原始图片的名称", "属于训练集还是验证集", "预测为Tuberculosis的概率值", "判定的组别"])# 对训练集和验证集中的每一批图片进行预测
for dataset, dataset_name in zip([train_ds_with_filenames, val_ds_with_filenames], ["训练集", "验证集"]):for images, labels, paths in dataset:# 使用模型对这一批图片进行预测probabilities = model.predict(images)predictions = tf.math.argmax(probabilities, axis=-1)# 遍历这一批图片for path, label, prediction, probability in zip(paths, labels, predictions, probabilities):# 获取图片名称和真实标签image_name = path.numpy().decode("utf-8").split('/')[-1]original_label = class_names[label]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到dataframe中result_df = result_df.append({"原始图片的名称": image_name,"属于训练集还是验证集": dataset_name,"预测为Tuberculosis的概率值": probability[1],"判定的组别": group}, ignore_index=True)# 保存结果到csv文件
result_df.to_csv("result.csv", index=False)代码2:
######################################导入包###################################
# 导入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
import torch
from torchvision import datasets, transforms
import os# 数据集路径
data_dir = "./MTB"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = datasets.ImageFolder(data_dir)# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占80%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 将数据增强应用到训练集
train_dataset.dataset.transform = data_transforms['train']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes###############################定义TNT模型################################
# 导入必要的库
import torch.nn as nn
import timm# 定义Bottleneck Transformer模型
model = timm.create_model('botnet26t_256', pretrained=True) # 你可以选择适合你需求的BotNet版本
num_ftrs = model.feature_info[-1]['num_chs']# 根据分类任务修改最后一层
model.head.fc = nn.Linear(num_ftrs, len(class_names))# 将模型移至指定设备
model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 20# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'tnt_dit_model.pth')GPT-4回复:
代码2的改写版本如下:
首先,我们需要为PyTorch添加类别名称,以便我们在生成结果时可以进行映射,然后创建一个列表来存储预测结果。
################################导入数据集#####################################
...
# 获取数据集的类别
class_names = full_dataset.classes
# 保存预测结果的列表
results = []接着,我们在进行预测时,为了获取每个样本的概率,我们需要使用torch.nn.functional.softmax()函数,同时还需要将预测值与0.5比较,以判定组别。最后,我们使用Pandas将预测结果保存为CSV文件。
import pandas as pd
from torch.nn.functional import softmax# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i in range(inputs.size(0)):# 获取图片的名称、标签、预测值和概率image_name = dataloaders[phase].dataset.dataset.samples[i][0].split('/')[-1]original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到结果列表中results.append({"原始图片的名称": image_name,"属于训练集还是验证集": phase,"预测为Tuberculosis的概率值": probability[1].item(),"判定的组别": group})# 将结果保存为Pandas DataFrame,然后保存到csv文件
result_df = pd.DataFrame(results)
result_df.to_csv("result.csv", index=False)我们看看“result.csv”文件是否符合我们的要求:
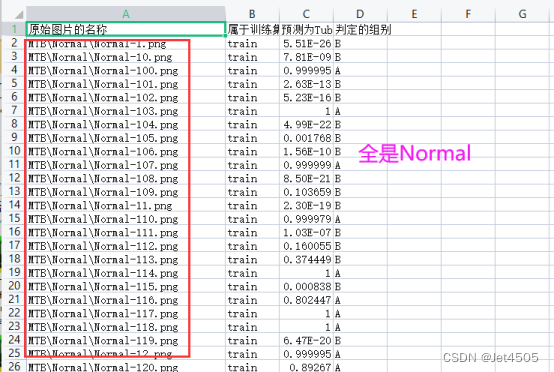
问题很明显,分组全是“Normal”!!!
(b2)咒语:为什么输出的“原始图片的名车”全部是“MTB\Normal\”,完全没有“Tuberculosis”?
GPT-4回复:
在PyTorch中,当我们使用torchvision的datasets.ImageFolder载入数据时,数据被按照文件夹的顺序进行排序,所以获取图片名称时,我们只是在循环中按顺序获取了数据集中的图片路径。这可能会在对验证集进行预测时出现问题,因为我们使用了random_split函数对数据进行了随机划分,而获取图片路径的方式并未考虑到这个随机性。
为了解决这个问题,你可以试试将图片路径也保存在数据加载器中。在这里,我假设你的训练集和验证集是以文件夹的形式存储的,每个文件夹的名字就是类别的名称。以下是一个简单的自定义数据集类,它可以在加载数据的同时获取每个图片的路径:
from torch.utils.data import Dataset
from PIL import Imageclass ImageFolderWithPaths(Dataset):def __init__(self, image_folder, transform=None):self.image_folder = image_folderself.transform = transformself.image_paths = list(map(lambda x: x[0], image_folder.imgs))def __getitem__(self, index):original_tuple = self.image_folder.imgs[index]path = original_tuple[0]image = Image.open(path).convert("RGB")if self.transform is not None:image = self.transform(image)return (image, original_tuple[1], path)def __len__(self):return len(self.image_folder.imgs)你可以这样使用这个数据集类:
# 创建原始的ImageFolder数据集
original_dataset = datasets.ImageFolder(data_dir, transform=data_transforms['train'])# 使用我们的自定义数据集类,获取图片路径
full_dataset = ImageFolderWithPaths(original_dataset, transform=data_transforms['train'])# 现在,你的数据加载器在每次迭代时都会返回图片、标签和图片路径
for images, labels, paths in dataloader:...
看得懂怎么改写代码不?看不懂也不要紧,继续:
(b3)咒语:帮我在这个代码上改写和更新,并展示所有代码:{复制代码}
GPT-4回复:
import torch
from torchvision import datasets, transforms
from torch.nn.functional import softmax
import os
from PIL import Image
import pandas as pd
import torch.nn as nn
import timm
from torch.optim import lr_scheduler# 自定义的数据集类
class ImageFolderWithPaths(datasets.ImageFolder):def __getitem__(self, index):original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)path = self.imgs[index][0]tuple_with_path = (original_tuple + (path,))return tuple_with_path# 数据集路径
data_dir = "./MTB"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = ImageFolderWithPaths(data_dir, transform=data_transforms['train'])# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 应用数据增强到训练集和验证集
train_dataset.dataset.transform = data_transforms['train']
val_dataset.dataset.transform = data_transforms['val']# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes# 获取数据集的类别
class_names = full_dataset.classes# 保存预测结果的列表
results = []###############################定义TNT模型################################
# 定义Bottleneck Transformer模型
model = timm.create_model('botnet26t_256', pretrained=True) # 你可以选择适合你需求的BotNet版本
num_ftrs = model.feature_info[-1]['num_chs']# 根据分类任务修改最后一层
model.head.fc = nn.Linear(num_ftrs, len(class_names))# 将模型移至指定设备
model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 4# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'bonet_dit_model-1.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################误判病例分析#################################
# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i in range(inputs.size(0)):# 获取图片的名称、标签、预测值和概率image_name = os.path.basename(paths[i])original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别if original_label == class_names[prediction]:group = 'correct' # 正确预测的图片else:group = 'misclassified' # 错误预测的图片# 将结果保存为字典result = {'image': image_name,'label': original_label,'prediction': class_names[prediction],'probability': probability,'group': group}# 将字典添加到结果列表中results.append(result)# 将结果列表保存为数据框,并输出为csv文件
results_df = pd.DataFrame(results)
results_df.to_csv('classification_results.csv', index=False)运行,报错,哈哈哈:
(b4)咒语:报错:Traceback (most recent call last): File "<string>", line 1, in <module>File "C:\ProgramData\Anaconda3\envs\Pytorch\lib\multiprocessing\spawn.py", line 116, in spawn_main exitcode = _main(fd, parent_sentinel)
File "C:\ProgramData\Anaconda3\envs\Pytorch\lib\multiprocessing\spawn.py", line 126, in _main self = reduction.pickle.load(from_parent)
AttributeError: Can't get attribute 'ImageFolderWithPaths' on <module '__main__' (built-in)>
GPT-4回复:
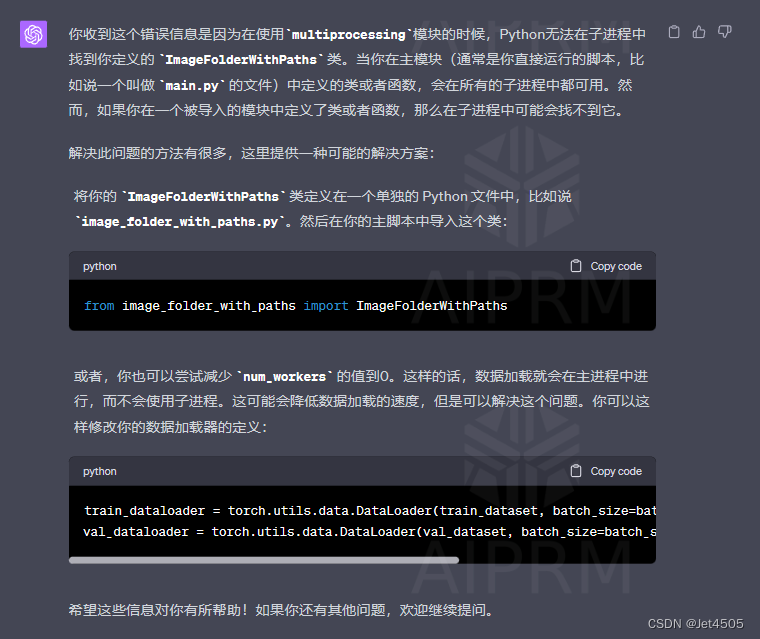
继续报错,继续问:Traceback (most recent call last):
File "C:\Users\Administrator\AppData\Local\Temp\ipykernel_19344\1832509689.py", line 146, in <cell line: 131>
for inputs, labels in dataloaders[phase]:
ValueError: too many values to unpack (expected 2)
GPT-4回答:
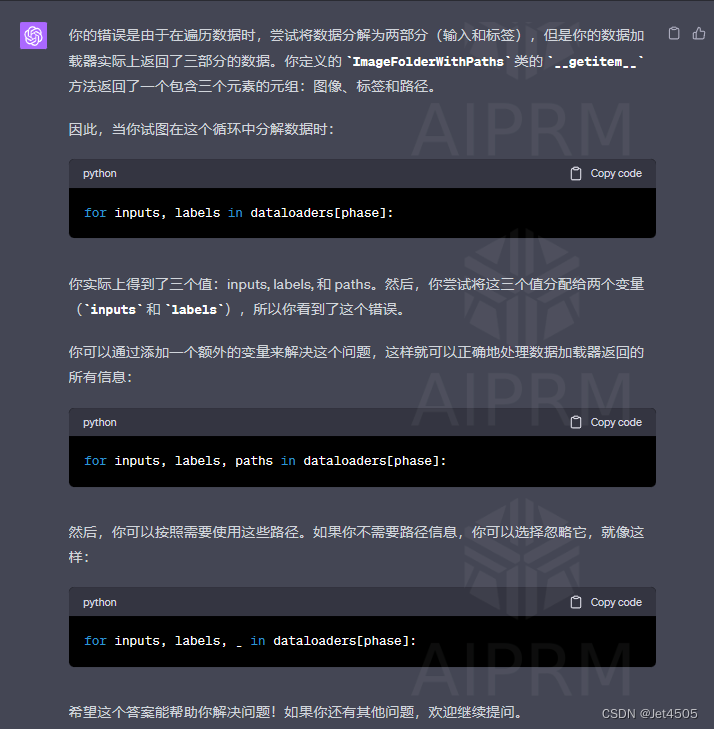
最后能运行了,又回到(b2)的问题:为什么输出的“原始图片的名称”全部是“MTB\Normal\”,完全没有“Tuberculosis”???一脸蒙蔽,无奈我又问了TA一次。
(b4)咒语:为什么输出的“原始图片的名车”还全部是“MTB\Normal\”,完全没有“Tuberculosis”????请显示完整的代码以解决这个问题。
GPT-4这回给出正确答案:
# 导入 os 库
import os# 使用模型对训练集和验证集中的所有图片进行预测,并保存预测结果
for phase in ['train', 'val']:for inputs, labels, paths in dataloaders[phase]: # 在这里添加 pathsinputs = inputs.to(device)labels = labels.to(device)# 使用模型对这一批图片进行预测outputs = model(inputs)probabilities = softmax(outputs, dim=1)_, predictions = torch.max(outputs, 1)# 遍历这一批图片for i, path in enumerate(paths): # 在这里添加 path 和 enumerate 函数# 获取图片的名称、标签、预测值和概率image_name = os.path.basename(path) # 使用 os.path.basename 函数获取图片名称original_label = class_names[labels[i]]prediction = predictions[i]probability = probabilities[i]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到结果列表中results.append({"原始图片的名称": image_name,"属于训练集还是验证集": phase,"预测为Tuberculosis的概率值": probability[1].item(),"判定的组别": group})# 将结果保存为Pandas DataFrame,然后保存到csv文件
result_df = pd.DataFrame(results)
result_df.to_csv("result-2.csv", index=False)总结:现在来看,改写过程中出问题大概率是图片的路径提取中出了问题。核心咒语还是一样的:{以0.5为阈值,因此可以样本分为三份:(a)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测正确,判定为A组;(b)本来就是Normal的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为B组;(c)本来就是Normal的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测错误,判定为C组;(d)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为D组;},剩余的就跟GPT-4对线,出了问题及时且准确的进行反馈,这很重要!!!
三、输出结果
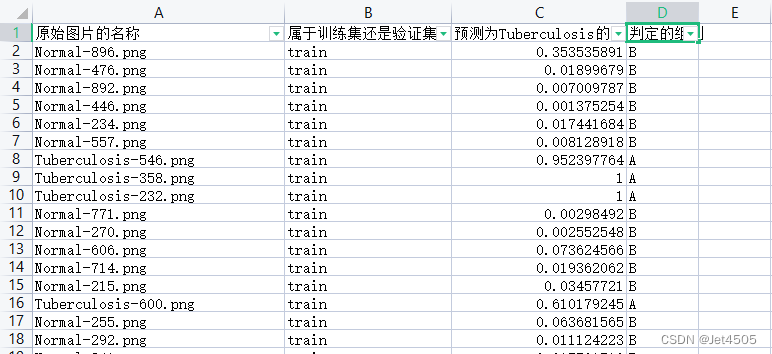
有了这个表,又可以水不少图了。
四、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf
相关文章:
第60步 深度学习图像识别:误判病例分析(Pytorch)
基于WIN10的64位系统演示 一、写在前面 上期内容基于Tensorflow环境做了误判病例分析(传送门),考虑到不少模型在Tensorflow环境没有迁移学习的预训练模型,因此有必要在Pytorch环境也搞搞误判病例分析。 本期以SqueezeNet模型为…...
基于Java+SpringBoot+vue前后端分离夕阳红公寓管理系统设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

远控木马病毒分析
一、病毒简介 SHA256:880a402919ba4e896f6b4b2595ecb7c06c987b025af73494342584aaa84544a1 MD5:0902b9ff0eae8584921f70d12ae7b391 SHA1:f71b9183e035e7f0039961b0ac750010808ebb01 二、行为分析 同样在我们win7虚拟机中,使用火绒剑进行监控,分析行为…...
线性代数的学习和整理7:各种特殊效果矩阵汇总
目录 1 矩阵 1.1 1维的矩阵 1.2 2维的矩阵 1.3 没有3维的矩阵---3维的是3阶张量 1.4 下面本文总结的都是各种特殊效果矩阵特例 2 方阵: 正方形矩阵 3 单位矩阵 3.1 单位矩阵的定义 3.2 单位矩阵的特性 3.3 为什么单位矩阵I是 [1,0;0,1] 而不是[0,1;1,0] 或[1,1;1,1]…...

[git]github上传大文件
github客户端最高支持100Mb文件上传,如果要>100M只能用git-lfs,但是测试发现即使用git lfs,我上传2.5GB也不行,测试737M文件可以,GitHub 目前 Git LFS的总存储量为1G左右,超过需要付费。(上传失败时&…...

element ui - el-select获取点击项的整个对象item
1.背景 在使用 el-select 的时候,经常会通过 change 事件来获取当前绑定的 value ,即对象中默认的某个 value 值。但在某些特殊情况下,如果想要获取的是点击项的整个对象 item,该怎么做呢? 2.实例 elementUI 中是可…...

实现SSM简易商城项目的购物车实现
实现SSM简易商城项目的购物车实现 在这篇博客中,我们将使用SSM框架来实现一个简易的购物车功能。我们将使用Spring框架来管理Bean,使用SpringMVC框架来处理HTTP请求,使用MyBatis框架来操作数据库。 实现SSM简易商城项目的购物车功能的思路如…...
【学习FreeRTOS】第17章——FreeRTOS任务通知
1.任务通知的简介 任务通知:用来通知任务的,任务控制块中的结构体成员变量 ulNotifiedValue就是这个通知值。 使用队列、信号量、事件标志组时都需另外创建一个结构体,通过中间的结构体进行间接通信! 使用任务通知时,…...
GO-vscode远程开发和调试
本文内容主要包括: 概述: 主要就是把代码放到服务器上然后远程去开发和调试 工具: vscode 远程端: linux 一.安装远程插件 vscode安装Remote - SSH,Remote Explorer,Remote Development,…...

【笔记】判断两个Double类型的值是否相同
在Java中,将两个double值转换为String类型,然后使用equals方法进行比较是一个常见的做法,但是这种方法并不是完全可靠,特别是在涉及浮点数的精度时仍然可能会遇到问题。 浮点数在内部以二进制表示,有时会存在舍入误差…...
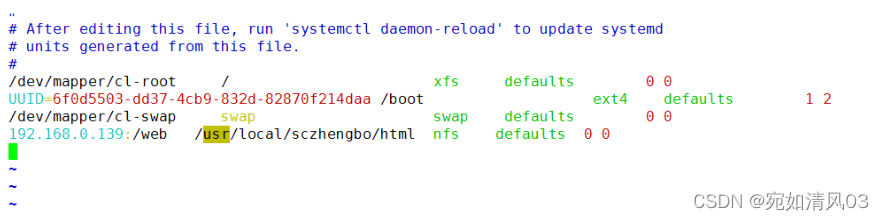
Linux —— nfs文件系统
简介 NFS 是Network File System的缩写,即网络文件系统。一种使用于分散式文件系统的协定,由Sun公司开发,于1984年向外公布。功能是通过网络让不同的机器、不同的操作系统能够彼此分享个别的数据,让应用程序在客户端通过网络访问位…...
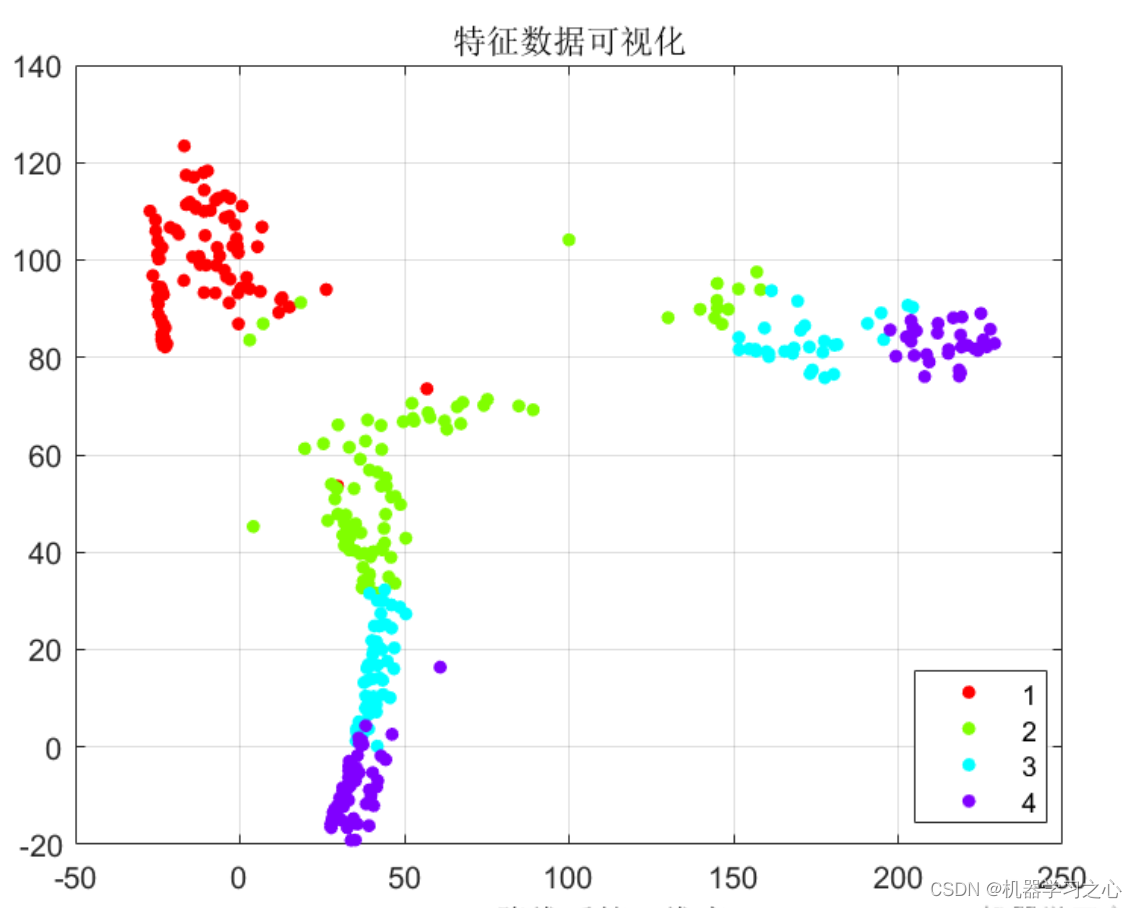
数据降维 | MATLAB实现T-SNE降维特征可视化
数据降维 | MATLAB实现T-SNE降维特征可视化 目录 数据降维 | MATLAB实现T-SNE降维特征可视化降维效果基本描述程序设计参考资料 降维效果 基本描述 T-SNE降维特征可视化,MATLAB程序。 T-分布随机邻域嵌入,主要用途是对高维数据进行降维并进行可视化&…...
)
蓝桥杯上岸每日N题 (交换瓶子)
大家好 我是寸铁 希望这篇题解对你有用,麻烦动动手指点个赞或关注,感谢您的关注 题目描述 有 N 个瓶子,编号 1∼N,放在架子上。 比如有 5 个瓶子: 2 1 3 5 4 要求每次拿起 2 个瓶子,交换它们的位置。 …...
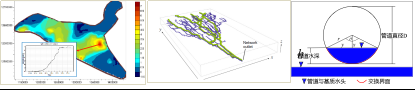
GMS基本模块TIN、Solids、Modflow2000/2005、MT3DMS、MODPATH。及其在地下水流动、溶质运移、粒子追踪方面的应用
解决地下水数值模拟技术实施过程中遇到的困难,从而提出切实可行的环境保护措施,达到有效保护环境、防治地下水污染,推动经济社会可持续发展的目的。 (1)水文地质学,地下水数值模拟基础理论;&am…...
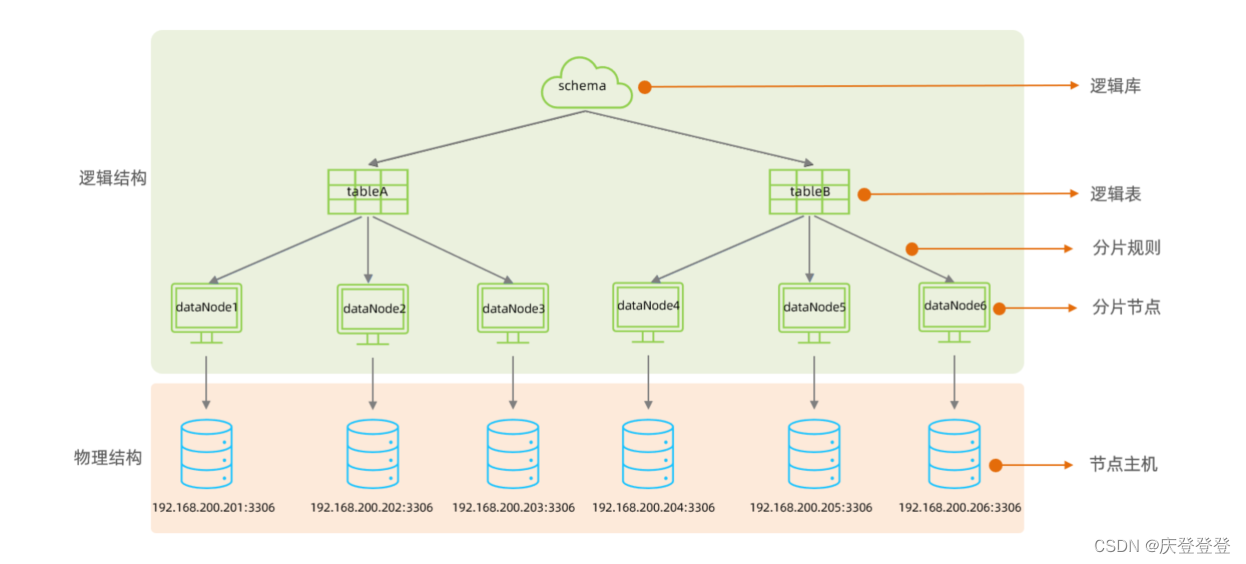
MySQL数据库中间件Mycat介绍及下载安装(教程)
一,介绍 MyCat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用MySQL一样来使用MyCat,对于开发人员来说根本感觉不到MyCat的存在。 开发人员只需要连接MyCat即可,而具体底层用到几台数据库,每一台数据库服务器…...
【VMware】CentOS 设置静态IP(Windows 宿主机)
文章目录 1. 更改网络适配器设置2. 配置虚拟网络编辑器3. 修改 CentOS 网络配置文件4. ping 测试结果 宿主机:Win11 22H2 虚拟机:CentOS-Stream-9-20230612.0 (Minimal) 1. 更改网络适配器设置 Win R:control 打开控制面板 依次点击&#x…...
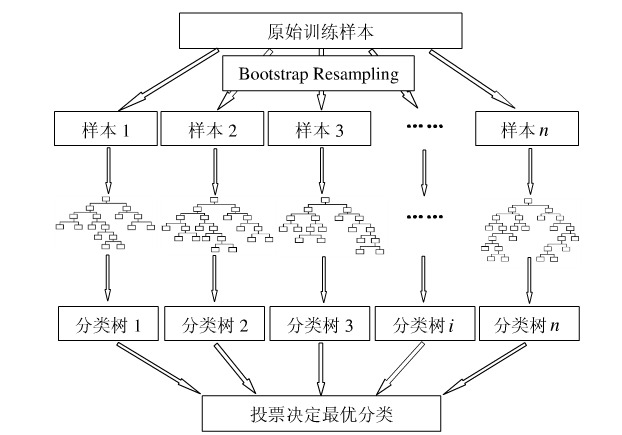
机器学习十大算法之七——随机森林
0 引言 集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个横型,集成所有模型的建模结果,基本上所有的机器学习领域都可以看到集成学习…...
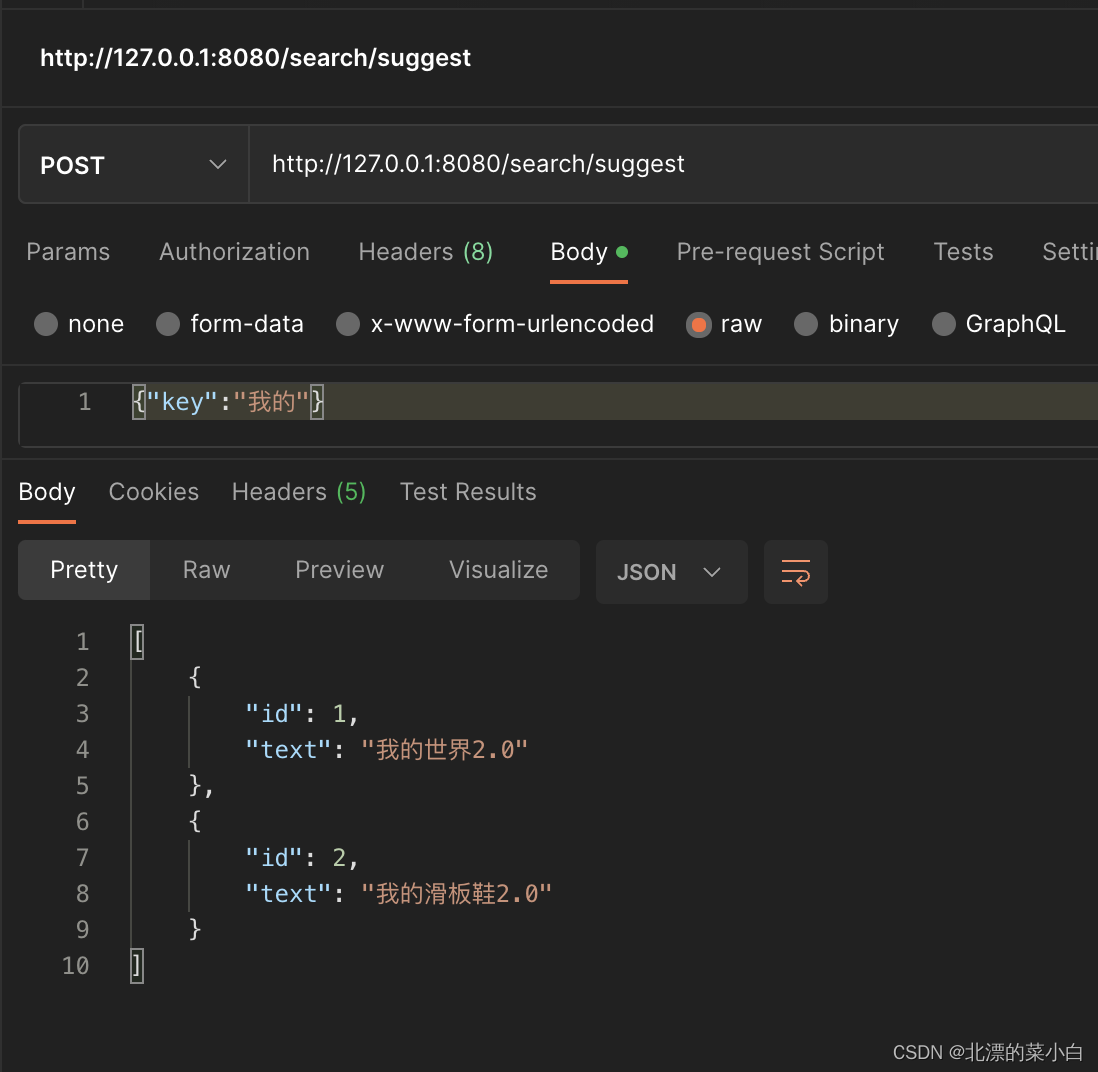
spring boot 3使用 elasticsearch 提供搜索建议
业务场景 用户输入内容,快速返回建议,示例效果如下 技术选型 spring boot 3elasticsearch server 7.17.4spring data elasticsearch 5.0.1elasticsearch-java-api 8.5.3 pom.xml <dependency><groupId>org.springframework.boot</gr…...

住宅IP:解锁更快速、稳定的互联网,你准备好了吗?
随着互联网的广泛普及,我们对网络的需求也越来越高。无论是工作、学习还是娱乐,我们都希望能够享受到更快速、稳定的互联网连接。而在实现这一目标的过程中,住宅IP正逐渐崭露头角,成为了一种备受关注的解决方案。那么,…...

支持dolby vision的盒子接支持dolby vision的电视,在adaptive hdr时,播放非dv的hdr视频,输出sdr
支持dolby vision的盒子接支持dolby vision的电视,setting选择adaptive hdr,按照这个配置在播放非dv的hdr视频时,会输出sdr。 看起来是很不合理的,高级的产品播放高级的片源,却输出低级的画质。 想要搞清楚这个问题&am…...
)
告别Resources和AssetBundle!用Unity Addressable重构你的资源管理(附迁移实战)
Unity Addressable系统深度重构:从传统资源管理到现代化架构的平滑迁移 在Unity项目开发中,资源管理一直是困扰开发者的核心难题之一。随着项目规模扩大,传统的Resources加载和AssetBundle管理方案逐渐暴露出性能瓶颈、热更新困难、依赖管理复…...

设计饮用水水质饮用习惯监测程序,统计每日饮水量,提醒科学补水养成健康习惯。
饮用水水质与饮水习惯监测程序——基于日志与规则的健康行为实验系统一、实际应用场景描述在现代城市生活中,很多人存在以下问题:- 不清楚自己每天喝了多少水- 饮水时间集中在晚上或运动后- 长期饮水不足或过量- 对水质来源缺乏基本记录意识本项目的目标…...

HPM6750 LVGL性能优化:片内SRAM帧缓冲实战解析
1. 项目概述:当LVGL遇上HPM6750的片内“新大陆”最近在嵌入式图形界面开发的圈子里,一个关于HPM6750的话题热度不低。起因是有开发者发现,在基于HPM6750这款高性能RISC-V MCU进行LVGL(Light and Versatile Graphics Library&#…...

告别命令行!用这个免费软件5分钟搞定Abaqus三维Voronoi泡沫模型
五分钟可视化构建Abaqus三维Voronoi泡沫模型:零代码解决方案全指南 在材料科学与工程仿真领域,三维Voronoi泡沫结构的建模一直是学术研究和工业应用的热点。这种仿生多孔结构因其优异的力学性能和轻量化特性,被广泛应用于缓冲材料、骨科植入物…...

高数函数定义域避坑指南:从‘x不能为零’到抽象函数,手把手教你识别题目陷阱
高数函数定义域避坑指南:从‘x不能为零’到抽象函数,手把手教你识别题目陷阱 考前冲刺阶段,函数定义域问题往往是高数考试中的"隐形杀手"。许多学生明明掌握了复杂计算技巧,却在基础定义域判断上频频失分。本文将直击五…...

拯救者工具箱终极指南:3大场景化解决方案提升笔记本使用体验
拯救者工具箱终极指南:3大场景化解决方案提升笔记本使用体验 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 联想…...

一线观察:赣州新房装修公司的可靠细节
上个月,有个老朋友找我帮他参谋新房装修的事。赣州章江新区某刚交付的高端盘,精装改毛坯,180平的大户型。他跟我说,前后跑了五六家装修公司,聊完最大的感觉是——云里雾里。报价单看不懂方案,总觉得藏着坑&…...

AI 写作一键生成超简单,焦圈儿免费积分福利等你来领
「现在写一篇公众号推文,没三四个小时都下不来。」一位做个人 IP 的朋友跟我抱怨。问题不在于工具太少,而在于门槛太高, 要么你得自己熬夜改稿,要么你得学一堆复杂 Prompt,才能把 AI 伺候好。内容行业正在进入一个悖论…...

【VASP实战】Ubuntu 22.04 LTS 部署 vasp.6.x 指南:从Intel oneAPI编译到GPU加速测试
1. VASP 6.x与Ubuntu 22.04 LTS环境概述 VASP(Vienna Ab initio Simulation Package)是材料科学领域广泛使用的第一性原理计算软件,能够模拟原子尺度的电子结构、分子动力学等过程。最新版VASP 6.x在并行计算效率和GPU加速支持上有显著提升&a…...

从STM32F103到GD32F303:如何用CubeMX和Keil5低成本‘平替’升级你的项目?
从STM32F103到GD32F303:低成本高性能迁移实战指南 在嵌入式开发领域,芯片选型往往需要在性能与成本之间寻找平衡点。对于已经熟悉STM32F103系列开发但面临成本压力或性能瓶颈的工程师来说,GD32F303系列提供了一个极具吸引力的替代方案。这款国…...