机器学习理论笔记(二):数据集划分以及模型选择
文章目录
- 1 前言
- 2 经验误差与过拟合
- 3 训练集与测试集的划分方法
- 3.1 留出法(Hold-out)
- 3.2 交叉验证法(Cross Validation)
- 3.3 自助法(Bootstrap)
- 4 调参与最终模型
- 5 结语

1 前言
欢迎来到蓝色是天的机器学习笔记专栏!在上一篇文章《机器学习理论笔记(一):初识机器学习》中,我们初步了解了机器学习,并探讨了其定义、分类以及基本术语。作为继续学习机器学习的进一步之旅,今天我们将进一步讨论机器学习中的一些重要概念和技巧。
在本文中,我们将重点关注以下几个方面:经验误差与过拟合、数据集划分、调参以及最终模型的选择。这些主题对于解决实际问题中的机器学习挑战至关重要。通过深入了解这些概念和方法,我们可以更好地理解机器学习模型的训练过程,提高模型的预测准确性,从而使我们能够做出更好的决策和预测。
无论你是新手还是有经验的机器学习从业者,本文都将为你提供有价值的知识和实用的技巧。让我们一起探索机器学习中这些关键领域,并加深对机器学习的理解。让我们开始吧!
2 经验误差与过拟合
在机器学习中,我们通常希望通过训练学习器来对新样本进行泛化,即在未见过的数据上具有良好的预测准确性。为了衡量学习器的性能,我们引入了错误率、精度、误差等概念。
- 错误率表示分类错误的样本数占样本总数的比例,而精度则是错误率的补数,即1减去错误率。误差是指学习器的实际预测输出样本与样本真实输出之间的差异。
- 训练误差,也称为经验误差,表示学习器在训练集上的误差。训练误差是通过与已知标签进行比较来评估学习器的预测准确性。然而,我们希望学习器在新样本上也能表现出良好的预测能力,即具有较低的泛化误差。
- 泛化误差是指学习器在新样本上的误差,它度量了学习器在未见过的数据上的表现能力。我们希望泛化误差尽可能小,但是我们只能通过训练集的经验误差作为指标进行衡量。
然而,经验误差往往无法完全反映学习器的泛化能力。当学习器过度追求在训练集上的准确性时,很可能会过于贴合训练数据的细节特征,而忽视了样本的一般性质,从而导致泛化性能下降。这种现象被称为过拟合。
过拟合是机器学习中一个常见的问题,即学习器在训练集上表现出较好的性能,但在新样本上的表现却差。它表明学习器过于复杂,将训练样本自身的特点当作了所有潜在样本都会具有的一般性质,从而导致了泛化性能的降低。
相对应的,欠拟合是指学习器对训练样本的一般性质学习得不够好,导致无法很好地进行预测和泛化。

虽然完全避免过拟合是不可能的,但我们可以采取一些措施来“缓解”过拟合并减小其风险。例如,我们可以增加更多的训练数据,以减少对特定样本的过度依赖。另外,我们还可以采用正则化方法来约束学习器的复杂度,以防止其过度拟合训练数据。
同时,对于欠拟合问题,我们可以尝试增加模型的复杂度或采用更复杂的算法来提高学习器的性能。此外,合理选择特征、调整模型参数以及使用集成学习等方法也可以帮助克服欠拟合问题。
在实际应用中,我们需要根据问题的特点和数据的情况来选择合适的机器学习算法,并采取恰当的方法来克服过拟合或欠拟合的问题,以达到更好的泛化性能。
3 训练集与测试集的划分方法
在机器学习中,训练集和测试集的划分是评估模型性能的重要步骤。合理划分训练集和测试集能够准确评估模型的泛化能力和性能。本文将介绍三种常用的训练集与测试集划分方法:留出法、交叉验证法和自助法,并讨论它们的优缺点和适用场景。
3.1 留出法(Hold-out)
留出法是最简单直接的划分方法之一。它将原始数据集划分为两个互斥的集合:一个用作训练集,另一个用作测试集。训练集用于训练模型的参数和规则,而测试集则用于评估模型的性能。划分时应保持训练集和测试集的数据分布相同,并确保测试集与训练集互斥,即测试样本不在训练集中出现。为了减小随机划分的影响,通常建议进行多次随机划分,并取平均值作为留出法的评估结果。
直接将数据集刀划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D = S∪T, S∩T = ∅。 上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计
优点:
简单易行,实现方便。
计算效率高,适用于大数据集。
缺点:
可能由于随机划分的不一致导致评估结果偏差较大。
对于小规模数据集,划分比例的选择有一定的挑战。
适用场景:
数据集规模较大。
对划分效果要求不苛刻的场景。
3.2 交叉验证法(Cross Validation)
交叉验证法是一种更稳健的划分方法,它将原始数据集划分为k个大小相似的互斥子集。然后,使用k-1个子集作为训练集,剩下的一个子集作为测试集,进行模型的训练和测试。重复这个过程k次,每次选择不同的测试集,最终将k次测试结果的均值作为最终评估结果。交叉验证法能够更充分地利用数据集的信息,减小因单次划分导致的偏差。常见的k值有10、5、20等,其中10折交叉验证是最常用的。
D=D1∪D2∪……Dk,Di∩Dj=∅(i≠j)
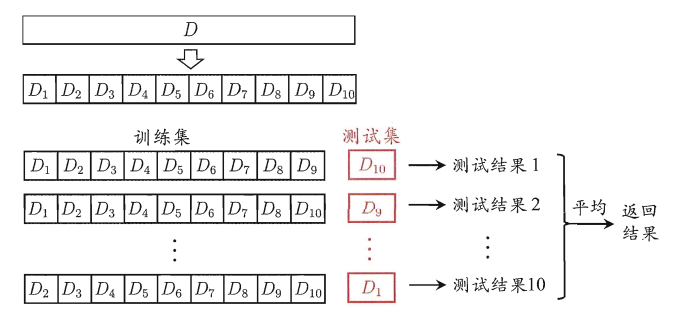
优点:
可以更准确地评估模型的性能,有效利用数据集。
具有较低的评估结果方差。
对于数据集较小且难以进行有效划分的情况下特别有用。
缺点:
计算复杂度高,需要进行多次模型训练和测试。
对于大规模数据集,计算资源消耗较大。
适用场景:
数据集规模较小。
对模型性能评估要求较高的场景。
3.3 自助法(Bootstrap)
自助法是一种特殊的划分方法,适用于数据集较小或难以有效划分训练集和测试集的情况。自助法通过自助采样的方式,从原始数据集中进行有放回地采样,生成一个与原始数据集大小相同的自助样本集。由于自助样本集的生成过程中部分样本可能多次出现,而另一部分样本可能未出现,因此可以使用自助样本集作为训练集,剩余未出现的样本作为测试集,得到一个称为包外估计(out-of-bag estimate)的评估结果。自助法能够更充分地利用数据集的信息,减小因划分导致的偏差,并且适用于数据集较小或难以有效划分的情况。
给定包含m个样本的数据集Q ,我们对它进行釆样产生数据集每次随机从Q中挑选一个样本,将其拷贝放入Df,然后再将该样本放回初始数据集D中,使得该样本在下次釆样时仍有可能被釆到;这个过程重复执行m次后,我们就得到了包含m个样本的数据集Df,这就是自助釆样的结果。显然,D中有一部分样本会在Df中多次出现,而另一部分样本不出现。可以做一个简单的估计,样本在m次釆样中始终不被釆到的概率是:
( 1 − 1 m ) m \left(1-{\frac{1}{m}}\right)^{m} (1−m1)m
取极限得到
* l i m m → ∞ ( 1 − 1 m ) m ↦ 1 e ≈ 0.368 \operatorname*{lim}_{m\rightarrow\infty}\left(1-\frac{1}{m}\right)^{m}\mapsto\frac{1}{e}\approx0.368 *limm→∞(1−m1)m↦e1≈0.368
优点:
可以有效利用小规模数据集,减小由于数据量不足导致的问题。
无需对数据集进行显式的划分,简化了训练集和测试集的划分过程。
缺点:
自助样本集中约有37%的样本未被采样到,可能导致评估结果偏乐观。
对于大规模数据集,自助法可能会导致计算资源浪费。
适用场景:
数据集规模较小或难以有效划分训练集和测试集的情况。
对数据集的利用率要求较高的场景。
4 调参与最终模型
在机器学习中,调参和算法选择是非常重要的步骤,它们直接影响到最终模型的性能和泛化能力。本章将介绍调参的概念以及一些常见的调参方法,同时还会涉及到最终模型的训练和评估。
调参的过程实际上和算法选择并没有本质的区别。对于许多学习算法来说,有很多参数需要设置,而这些参数的不同取值通常会导致学得模型的性能有显著差异。因此,我们需要对参数进行调节以找到最优的参数配置。然而,由于学习算法的参数通常是连续的实数值,无法对每种参数取值都进行模型训练。为了解决这个问题,我们常常会选择一个参数的范围和变化步长,然后在这个范围内进行参数的取值评估。例如,在范围 [0, 0.2] 内以 0.05 为步长进行取值评估,这样就得到了5个候选参数值。尽管这种方法不能保证找到最佳的参数值,但是通过权衡计算开销和性能估计,它仍然是一个可行的解决方案。
我们通常会将学得模型在实际使用中遇到的数据称为测试数据,为了区分,模型评估和选择中用于评估测试的数据集被称为验证集(validation set)。在调参过程中,我们会使用验证集来评估不同参数配置下模型的性能,并选择表现最好的参数配置作为最终模型的参数。
需要注意的是,在模型训练和调参完成后,我们还需要使用初始的数据集重新训练模型。这样做的目的是让初始的测试集也被模型学习,从而进一步提升模型的学习效果。类比于考试的情形,就像我们每次考试完后,需要复习和消化考试题目的内容,从而能够更好地应对下一次考试。因此,重新训练模型可以增强模型的泛化能力和性能。
综上所述,调参和最终模型的训练是实现好的机器学习模型的重要步骤。通过选择合适的参数值以及重新训练模型,我们可以进一步提升模型的性能和泛化能力,从而更好地适应实际应用场景。调参需要耐心和实践经验,同时也需要通过验证集的评估来指导参数选择的过程。最终,我们希望通过调参和最终模型的训练得到一个具有良好性能的模型,以解决实际问题并取得好的效果。
5 结语
在本篇文章中,我们介绍了机器学习中的调参与最终模型的相关内容。调参是为了找到最优的参数配置,能够提高模型的性能和泛化能力。同时,为了评估模型的性能,在训练和调参过程中,我们将数据集划分为训练集和测试集。
对于数据集的划分,我们介绍了三种常用的方法:留出法、交叉验证法和自助法。每种方法都有各自的使用场景和特点,可以根据实际情况选择合适的方法。
调参过程需要一定的经验和技巧,在限定的参数范围内尝试不同的取值,并通过验证集来评估模型的性能。通过不断地调节参数,我们可以找到最佳的参数配置,以获得最佳的模型性能。
最终模型的训练也是十分重要的,通过重新使用全部的数据集来训练模型,可以进一步提高模型的泛化能力和性能。
调参与最终模型的训练是机器学习中不可忽视的环节,需要经过实践与验证逐步优化模型。通过本文的内容,我们希望读者能够理解调参的重要性,并掌握划分数据集和调参的基本方法。只有通过合理的调参和最终模型的训练,我们才能得到好的结果,并应用机器学习技术来解决现实问题。

相关文章:
机器学习理论笔记(二):数据集划分以及模型选择
文章目录 1 前言2 经验误差与过拟合3 训练集与测试集的划分方法3.1 留出法(Hold-out)3.2 交叉验证法(Cross Validation)3.3 自助法(Bootstrap) 4 调参与最终模型5 结语 1 前言 欢迎来到蓝色是天的机器学习…...
10*1000【2】
知识: -----------金融科技背后的技术---------------- -------------三个数字化趋势 1.数据爆炸:internet of everything(iot);实时贡献数据;公有云服务->提供了灵活的计算和存储。 2.由计算能力驱动的&#x…...

“探秘JS加密算法:MD5、Base64、DES/AES、RSA你都知道吗?”
目录 1、什么是JS、JS反爬是什么?JS逆向是什么? 2、JS逆向的大致流程 3、逆向的环境搭建 3.1、安装node.js 3.2、安装js代码调试工具(vscode) 3.3、安装PyExecJs模块 4、JS常见加密算法 4.1、Base64算法 4.2、MD5算法 4.3、DES/AES算法 4.2.2 AES与DES的…...
Spark项目Java和Scala混合打包编译
文章目录 项目结构Pom完整文件编译查看 实际开发用有时候引用自己写的一些java工具类,但是整个项目是scala开发的spark程序,在项目打包时需要考虑到java和scala混合在一起编译。 今天看到之前很久之前写的一些打包编译文章,发现很多地方不太对…...
深度学习处理文本(NLP)
文章目录 引言1. 反向传播1.1 实例流程实现1.2 前向传播1.3 计算损失1.4 反向传播误差1.5 更新权重1.6 迭代1.7 BackPropagation & Adam 代码实例 2. 优化器 -- Adam2.1 Adam解析2.2 代码实例 3. NLP任务4. 神经网络处理文本4.1 step1 字符数值化4.2 step 2 矩阵转化为向量…...
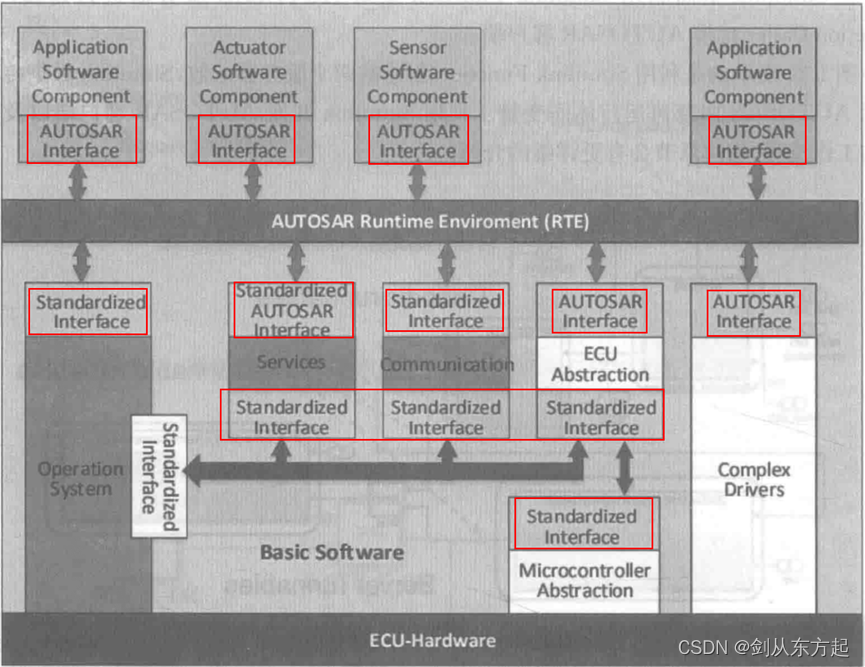
汽车电子笔记之:AUTOSAR方法论及基础概念
目录 1、AUTOSAR方法论 2、AUTOSAR的BSW 2.1、MCAL 2.2、ECU抽象层 2.3、服务层 2.4、复杂驱动 3、AUTOSAR的RTE 4、AUTOSAR的应用层 4.1、SWC 4.2、AUTOSAR的通信 4.3、AUTOSAR软件接口 1、AUTOSAR方法论 AUTOSAR为汽车电子软件系统开发过程定义了一套通用的技术方法…...

鼠标拖拽盒子移动
目录 需求思路代码页面展示【补充】纯js实现 需求 浮动的盒子添加鼠标拖拽功能 思路 给需要拖动的盒子添加鼠标按下事件鼠标按下后获取鼠标点击位置与盒子边缘的距离给 document 添加鼠标移动事件鼠标移动过程中,将盒子的位置进行重新定位侦听 document 鼠标弹起&a…...

AUTOSAR从入门到精通-【应用篇】面向车联网的车辆攻击方法及入侵检测
目录 前言 国内外研究现状 (1)车辆攻击方法的研究 (2)车辆安全防护技术的研究...
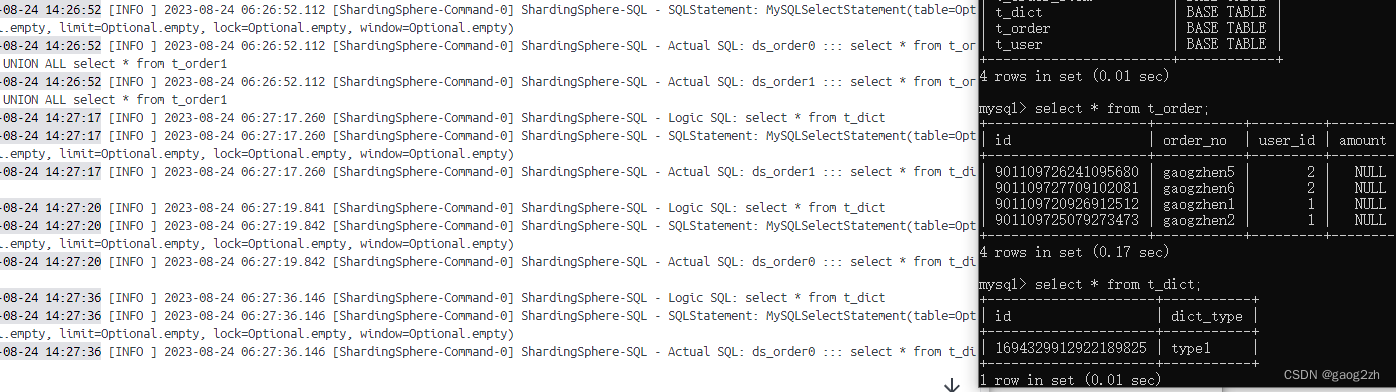
0101prox-shardingsphere-中间件
1 启动ShardingSphere-Proxy 1.1 获取 目前 ShardingSphere-Proxy 提供了 3 种获取方式: 二进制发布包DockerHelm 这里我们使用Docker安装。 1.2 使用Docker安装 step1:启动Docker容器 docker run -d \ -v /Users/gaogzhen/data/docker/shardings…...

FactoryBean和BeanFactory:Spring IOC容器的两个重要角色简介
目录 一、简介 二、BeanFactory 三、FactoryBean 四、区别 五、使用场景 总结 一、简介 在Spring框架中,IOC(Inversion of Control)容器是一个核心组件,它负责管理和配置Java对象及其依赖关系,实现了控制反转&a…...
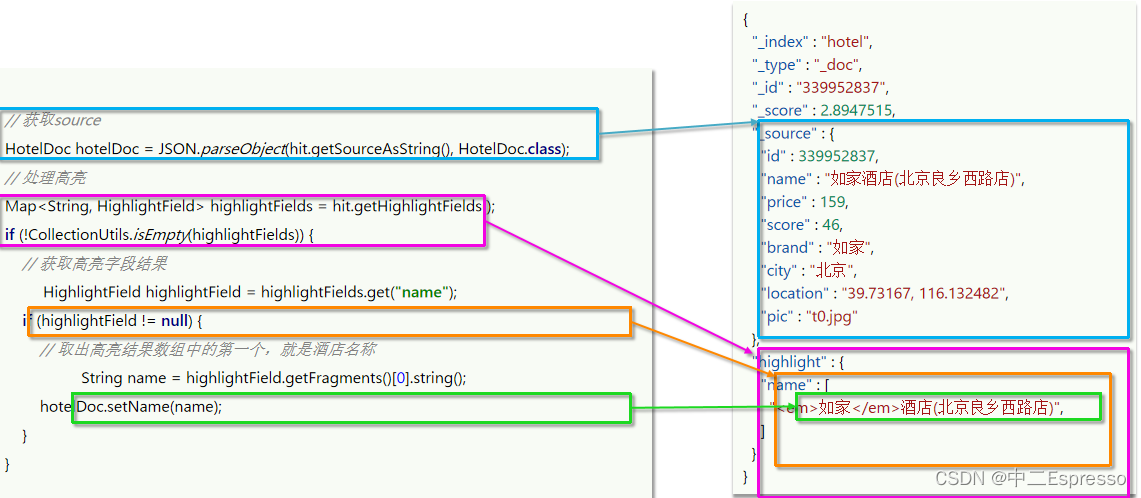
微服务中间件--分布式搜索ES
分布式搜索ES 11.分布式搜索 ESa.介绍ESb.IK分词器c.索引库操作 (类似于MYSQL的Table)d.查看、删除、修改 索引库e.文档操作 (类似MYSQL的数据)1) 添加文档2) 查看文档3) 删除文档4) 修改文档 f.RestClient操作索引库1) 创建索引库2) 删除索引库/判断索引库 g.RestClient操作文…...
触摸屏与PLC之间 EtherNet/IP无线以太网通信
在实际系统中,同一个车间里分布多台PLC,用触摸屏集中控制。通常所有设备距离在几十米到上百米不等。在有通讯需求的时候,如果布线的话,工程量较大耽误工期,这种情况下比较适合采用无线通信方式。 本方案以MCGS触摸屏和…...

Crontab定时任务运行Docker容器(Ubuntu 20)
对于一些离线预测任务,或者D1天的预测任务,可以简单地采用Crontab做定时调用项目代码运行项目 Crontab简介: Linux crontab命令常见于Unix和类Unix的操作系统之中,用于设置周期性被执行的指令。该命令从标准输入设备读取指令&…...
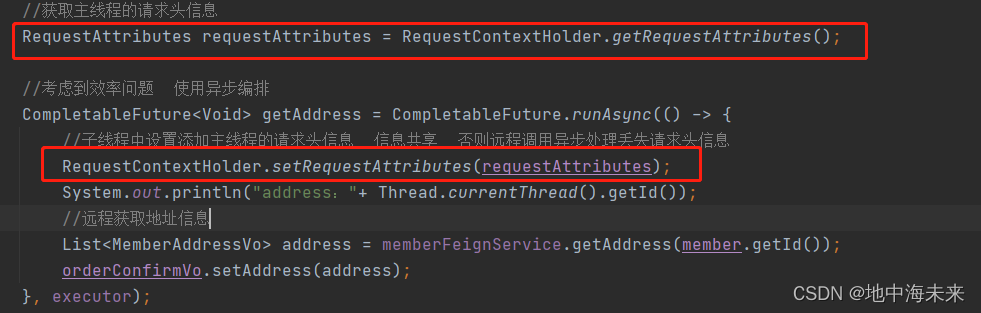
Fegin异步情况丢失上下文问题
在微服务的开发中,我们经常需要服务之间的调用,并且为了提高效率使用异步的方式进行服务之间的调用,在这种异步的调用情况下会有一个严重的问题,丢失上文下 通过以上图片可以看出异步丢失上下文的原因是不在同一个线程,…...

《Linux从练气到飞升》No.17 进程创建
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...

python + pyside2,pyside6,运行错误
在visual studio code运行pyside的时候报错 qt.qpa.plugin: Could not find the Qt platform plugin “windows“ in 后来发现在cmd命令行可以正常运行,应该是VScode和虚拟机类似的问题。 额外设置一下环境变量就可以了。 执行print(os.path.dirname(PySide6.__f…...
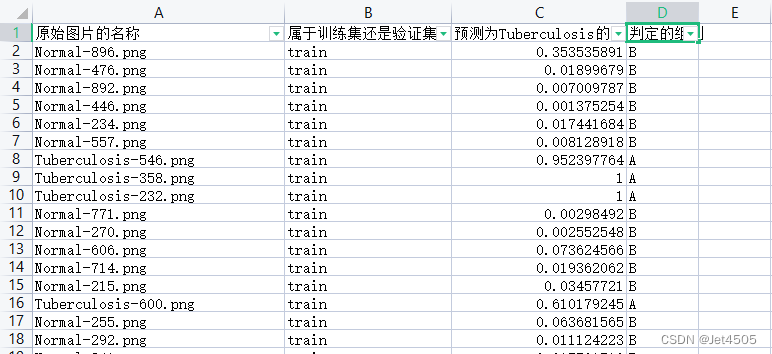
第60步 深度学习图像识别:误判病例分析(Pytorch)
基于WIN10的64位系统演示 一、写在前面 上期内容基于Tensorflow环境做了误判病例分析(传送门),考虑到不少模型在Tensorflow环境没有迁移学习的预训练模型,因此有必要在Pytorch环境也搞搞误判病例分析。 本期以SqueezeNet模型为…...
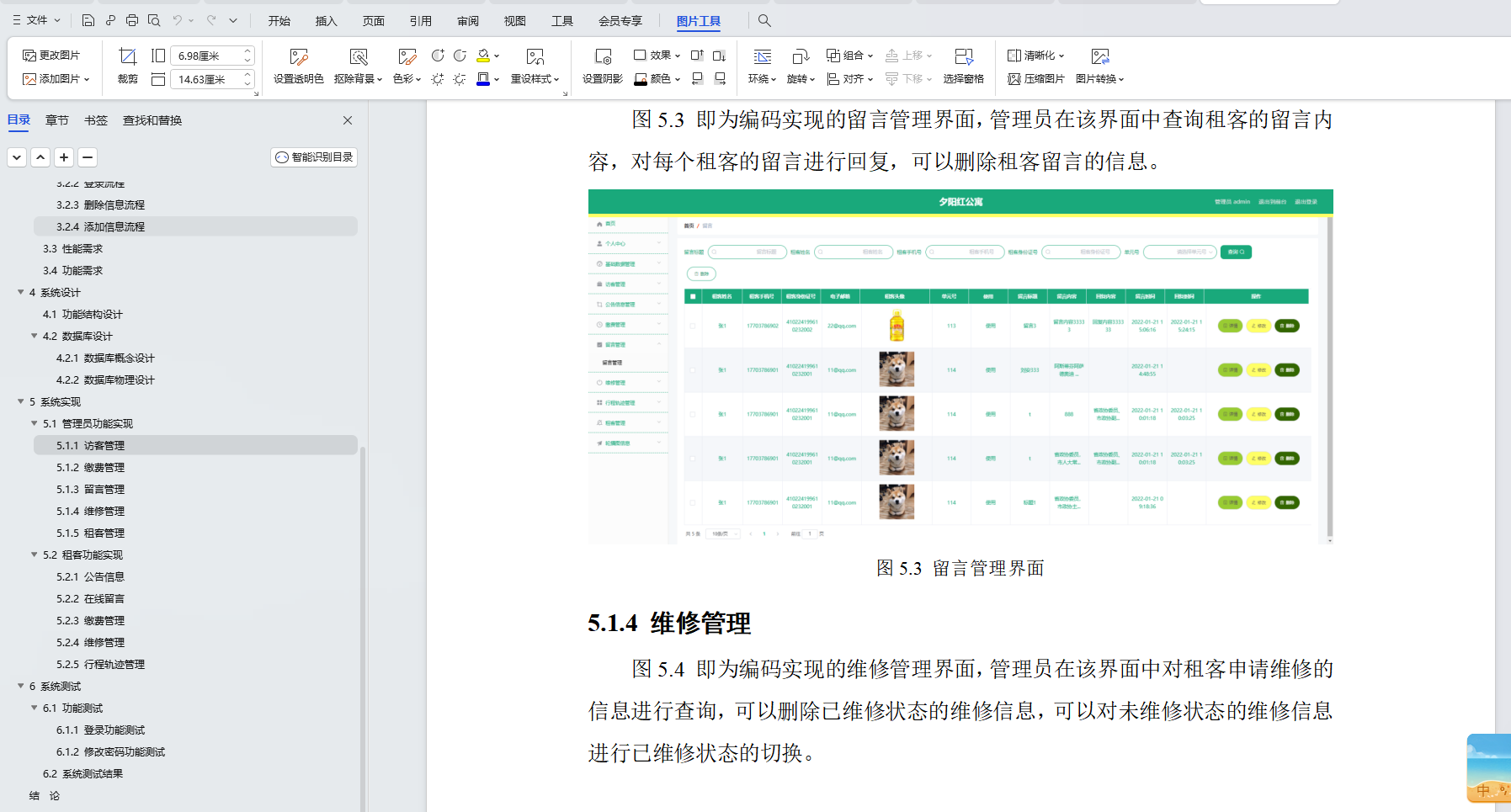
基于Java+SpringBoot+vue前后端分离夕阳红公寓管理系统设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

远控木马病毒分析
一、病毒简介 SHA256:880a402919ba4e896f6b4b2595ecb7c06c987b025af73494342584aaa84544a1 MD5:0902b9ff0eae8584921f70d12ae7b391 SHA1:f71b9183e035e7f0039961b0ac750010808ebb01 二、行为分析 同样在我们win7虚拟机中,使用火绒剑进行监控,分析行为…...
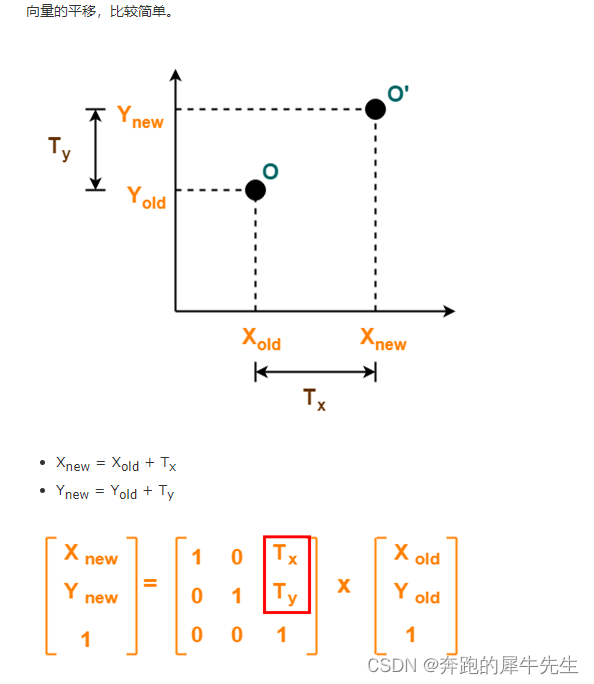
线性代数的学习和整理7:各种特殊效果矩阵汇总
目录 1 矩阵 1.1 1维的矩阵 1.2 2维的矩阵 1.3 没有3维的矩阵---3维的是3阶张量 1.4 下面本文总结的都是各种特殊效果矩阵特例 2 方阵: 正方形矩阵 3 单位矩阵 3.1 单位矩阵的定义 3.2 单位矩阵的特性 3.3 为什么单位矩阵I是 [1,0;0,1] 而不是[0,1;1,0] 或[1,1;1,1]…...

如何通过内存注入技术在英雄联盟国服实现安全换肤?
如何通过内存注入技术在英雄联盟国服实现安全换肤? 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想象一下,你正在峡谷中奋战&…...

智能视频转PPT:3分钟实现视频内容自动提取的完整方案
智能视频转PPT:3分钟实现视频内容自动提取的完整方案 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 你是否曾为整理会议录像中的PPT内容而烦恼?手动暂停、截…...

10分钟带你完成:Claude Code CC Switch 接入DeepSeek-V4
文章目录概要环境要求整体流程概要 本项目在 Windows 环境下,如何让强大的 AI 编程助手 Claude Code 成功“变身”,接入国产顶尖大模型 DeepSeek-V4。通过利用 DeepSeek 的 API 兼容性,不仅保留了 Claude Code 极致的终端交互体验…...

敏感词过滤的‘内存刺客’?深入剖析DFA/Trie树的优化实战与替代方案
敏感词过滤系统的内存优化实战:从DFA到双数组Trie的进阶之路 当你的应用日活突破百万级别,每天产生数千万条UGC内容时,敏感词过滤系统突然开始频繁触发Full GC——这可能是每个后端工程师的噩梦。传统的DFA实现就像潜伏在JVM中的"内存刺…...

HNU 计算机系统 bomblab:从GDB断点到链表重构的逆向实战
1. 逆向工程实战:从零开始拆解二进制炸弹 第一次接触bomblab时,我盯着终端里那个名为"bomb"的可执行文件发呆了十分钟。这个看似普通的Linux程序就像个黑盒子,里面藏着六个需要密码才能解除的"炸弹"。作为计算机系统课程…...

Linux CoreDump实战指南:从原理到容器化环境配置与自动化分析
1. 项目概述:为什么我们需要一份CoreDump实战指南?在服务器运维和后台开发领域,最让人头疼的瞬间之一,莫过于半夜被电话叫醒,被告知线上服务“挂了”。登录服务器一看,进程消失得无影无踪,只留下…...

VCSA底层网络配置实战:从IP修改到SSH登录的运维指南
1. 环境准备与基础概念 刚接触VMware vCenter Server Appliance(VCSA)的朋友可能会觉得底层配置有点神秘。其实就像给新买的智能手机设置Wi-Fi一样,我们需要根据实际网络环境调整它的"网络身份"。VCSA本质上是个预配置的Linux虚拟机…...

2026届学术党必备的十大AI学术方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI工具运用越来越广泛,然而随之出现的信息过多无法承受以及决策变得复杂的状况&…...

工业质检落地新思路:拆解SimpleNet如何用‘特征空间加噪’搞定缺陷检测
工业质检革命:SimpleNet如何用特征空间扰动突破小样本缺陷检测瓶颈 在PCB板生产线上,一个肉眼几乎不可见的焊点虚接可能导致整批产品报废;在汽车零部件装配车间,细微的划痕可能引发后续使用中的安全隐患。传统工业质检依赖人工目检…...
)
告别手动评分!用ImageJ的IHC Profiler插件,5分钟搞定免疫组化定量分析(附避坑指南)
告别手动评分!用ImageJ的IHC Profiler插件,5分钟搞定免疫组化定量分析(附避坑指南) 免疫组化(IHC)作为病理诊断和生物医学研究中的金标准技术,其结果的量化分析一直是困扰研究人员的难题。传统人…...