【业务功能篇73】分布式ID解决方案
业界实现方案
1. 基于UUID
2. 基于DB数据库多种模式(自增主键、segment)
3. 基于Redis
4. 基于ZK、ETCD
5. 基于SnowFlake
6. 美团Leaf(DB-Segment、zk+SnowFlake)
7. 百度uid-generator()
1.基于UUID生成唯一ID
UUID:
UUID长度128bit,32个16进制字符,占用存储空间多,且生成的ID是无序的;
对于InnoDB这种聚集主键类型的引擎来说,数据会按照主键进行排序,由于UUID的无序性,InnoDB会产生巨大的IO压力,此时不适合使用UUID做物理主键,可以把它作为逻辑主键,物理主键依然使用自增ID。
组成部分:
为了保证UUID的唯一性,规范定义了包括网卡MAC地址,时间戳,名字空间,随机或伪随机数,时序等元素.
优点:
性能非常高:本地生成,没有网络消耗。
缺点:
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
UUID生成策略
UUID Version 1:基于时间的UUID
基于时间的UUID通过计算当前时间戳、随机数和机器MAC地址得到。由于在算法中使用了MAC地址,这个版本的UUID可以保证在全球范围的唯一性。但与此同时,使用MAC地址会带来安全性问题,这就是这个版本UUID受到批评的地方。如果应用只是在局域网中使用,也可以使用退化的算法,以IP地址来代替MAC地址--Java的UUID往往是这样实现的(当然也考虑了获取MAC的难度)
UUID Version 2:DCE安全的UUID
DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
UUID Version 3:基于名字的UUID(MD5)
基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
UUID Version 4:随机UUID
根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但随机的东西就像是买彩票:你指望它发财是不可能的,但狗屎运通常会在不经意中到来。
UUID Version 5:基于名字的UUID(SHA1)
和版本3的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法
UUID应用
UUID Version 1:基于时间的UUID
从UUID的不同版本可以看出
• Version 1/2适合应用于分布式计算环境下,具有高度的唯一性•• Version 3/5适合于一定范围内名字唯一,且需要或可能会重复生成UUID的环境下•• 至于Version 4,建议是最好不用(虽然它是最简单最方便的)•• 通常我们建议使用UUID来标识对象或持久化数据,但以下情况最好不使用UUID:• 映射类型的对象。比如只有代码及名称的代码表。• 人工维护的非系统生成对象。比如系统中的部分基础数据。• 对于具有名称不可重复的自然特性的对象,最好使用Version 3/5的UUID。比如系统中的用户。如果用户的UUID是Version 1的,如果你不小心删除了再重建用户,你会发现人还是那个人,用户已经不是那个用户了。(虽然标记为删除状态也是一种解决方案,但会带来实现上的复杂性。

2.基于DB数据库多种模式(自增主键、segment)
基于DB的自增主键方案
实现原理:
基于MySQL,最简单的方法是使用auto_increment 来生成全局唯一递增ID,但最致命的问题是在高并发情况下,数据库压力大,DB单点存在宕机风险
优点:
实现简单、基于数据库底层机制
缺点:
高并发情况下,数据库压力大,DB单点存在宕机风险
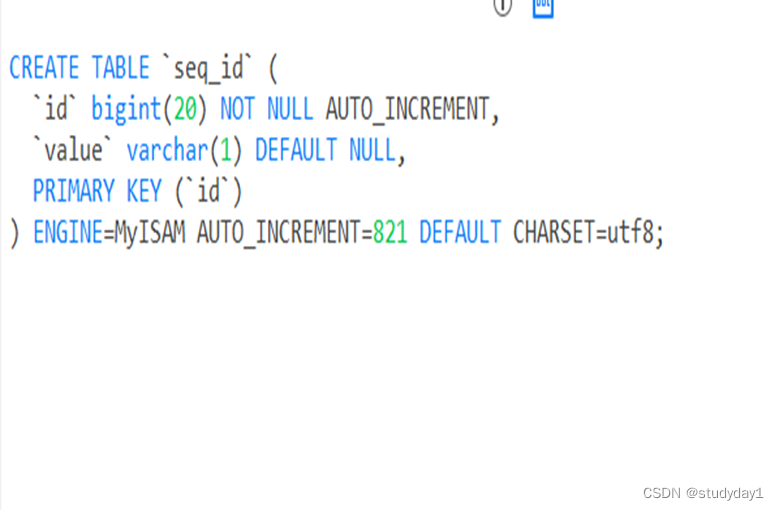
基于DB多主模式方案
在分布式系统中我们可以多部署几台机器,
每台机器设置不同的初始值,且步长和机器数相等。
比如有两台机器。设置步长step为2,
TicketServer1的初始值为1(1,3,5,7,9,11…)、
TicketServer2的初始值为2(2,4,6,8,10…)。
这是Flickr团队在2010年撰文介绍的一种主键生成策略
(Ticket Servers: Distributed Unique Primary Keys on the Cheap )
如下所示,为了实现上述方案分别设置两台机器对应的参数,
TicketServer1从1开始发号,
TicketServer2从2开始发号,
两台机器每次发号之后都递增2
基于DB号段实现方案
实现原理:
每次向db申请一个号段,加载到内存中,然后采用自增的方式来生成id,这个号段用完后,再次向db申请一个新的号段,这样对db的压力就减轻了很多,同时内存中直接生成id。向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
优点:
利用了缓存,减轻DB压力,性能提升
缺点:
依然存在DB模式下的性能瓶颈,ID最大值的限制
3.基于Redis实现分布式ID
- 因为Redis是单线程的,所以天然没有资源争用问题,可以采用 incr 指令,实现ID的原子性自增。
- 但是因为Redis的数据备份-RDB,会存在漏掉数据的可能,所以理论上存在已使用的ID再次被使用,所以备份方式可以加上AOF方式,这样的话性能会有所损耗。
4.基于Zookeeper实现分布式ID
原理:
利用zookeeper中的顺序节点的特性,制作分布式的序列号生成器(ID生成器)
5.基于ETCD实现分布式ID
原理:
每个tx事务有唯一事务ID,在etcd中叫做main ID,全局递增不重复。一个tx可以包含多个修改操作(put和delete),每一个操作叫做一个revision(修订),共享同一个main ID。
一个tx内连续的多个修改操作会被从0递增编号,这个编号叫做sub ID。
每个revision由(main ID,sub ID)唯一标识。
6.美团Leaf-基于ZK的SnowFlake算法
Leaf-snowflake方案完全沿用snowflake方案的bit位设计.
即是“1+41+10+12”的方式组装ID号。
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。
Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性
自动对snowflake节点配置wokerID

7.百度uid-generator分布式ID生成器
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。
UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略,
从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制;
采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,
避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
其实现原理和雪花算法并无二致,自定义号段,并且采用RingBuffer作为缓冲从而提升性能。详见官网地址:
https://github.com/baidu/uidgenerator/blob/master/README.zh_cn.md
相关文章:
【业务功能篇73】分布式ID解决方案
业界实现方案 1. 基于UUID2. 基于DB数据库多种模式(自增主键、segment)3. 基于Redis4. 基于ZK、ETCD5. 基于SnowFlake6. 美团Leaf(DB-Segment、zkSnowFlake)7. 百度uid-generator() 1.基于UUID生成唯一ID UUID:UUID长度128bit,32个16进制字符,占用存储空…...

Qt安卓开发经验技巧总结V202308
01:01-05 pro中引入安卓拓展模块 QT androidextras 。pro中指定安卓打包目录 ANDROID_PACKAGE_SOURCE_DIR $$PWD/android 指定引入安卓特定目录比如程序图标、变量、颜色、java代码文件、jar库文件等。 AndroidManifest.xml 每个程序唯一的一个全局配置文件&…...

【vue2】前端实现下载后端返回的application/octet-stream文件流
1、下载csv/txt时 此时无须修改接口的响应格式 let filenameRegex /filename[^;\n]*((["]).*?\2|[^;\n]*)/; let matches filenameRegex.exec(data.headers[content-disposition]); let blob new Blob([\uFEFF data.data], {//目前只有csv格式type: text/csv;charse…...
)
【Java】SM2Utils(国密 SM2 工具类)
基于 bouncycastle 实现 国密 SM2 <!-- 引入 bouncycastle --> <dependency><groupId>org.bouncycastle</groupId><artifactId>bcprov-jdk15on</artifactId><version>1.70</version> </dependency>import lombok.Sneak…...

『C语言入门』初识C语言
文章目录 前言C语言简介一、Hello World!1.1 编写代码1.2 代码解释1.3 编译和运行1.4 结果 二、数据类型2.1 基本数据类型2.2 复合数据类型2.3 指针类型2.4 枚举类型 三、C语言基础3.1 变量和常量3.2 运算符3.3 控制流语句3.4 注释单行注释多行注释注释的作用 四、 …...

jira创建条目rest实用脚本
最近在搞crash崩溃分析,直接把解析到的信息录入jira系统进行跟踪; 经历了多次碰壁后终于调通,现记录一下 实用json请求脚本如下: {"fields":{"project":{"id":"10945"},"issuety…...

红外/可见光图像配准融合
红外/可见光图像配准融合 根据文献【1】,对于平行光轴的红外可见光双目配置进行图像配准,主要的限制是图像配准只是对特定的目标距离(Dtarget)有效。并排配置的配准误差 δx(以像素表示)的数学表达式为&…...

更高效稳定 | 基于ACM32 MCU的编程直流电源应用方案
随着电子设备的多样化发展,面对不同的应用场景,需要采用特定的供电电源。因此,在电子产品的开发测试过程中,必不可少使用编程直流电源来提供测试电压,协助完成初步的开发测试过程。 编程直流电源概述 编程直流电源结构…...

postgresql创建一个只读账户指定数据库
要在 PostgreSQL 中创建一个只读账户,您可以按照以下步骤进行操作: 1. **登录到 PostgreSQL:** 使用具有足够权限的管理员账户(通常是 "postgres" 用户)连接到 PostgreSQL 数据库。 2. **创建只读账户&…...
CSDN编程题-每日一练(2023-08-25)
CSDN编程题-每日一练(2023-08-25) 一、题目名称:影分身二、题目名称:小鱼的航程(改进版)三、题目名称:排查网络故障 一、题目名称:影分身 时间限制:1000ms内存限制:256M 题目描述&am…...

前端面试:【前端工程化】构建工具Webpack、Parcel和Rollup
嗨,亲爱的前端开发者!在现代Web开发中,前端工程化变得愈发重要。构建工具如Webpack、Parcel和Rollup帮助我们自动化任务、管理依赖、优化性能等。本文将深入探讨这三个前端构建工具,帮助你了解它们的优点和用途。 1. Webpack&…...

大型企业是否有必要进行数字化转型?
在数字化、信息化、智能化蓬勃发展的今天,初创公司可以很轻易的布局规划数字化发展的路径。而对于大型企业而言,其已经形成了较为成熟稳固的业务及组织架构,是否还有必要根据自身行业发展特点寻求数字化转型?(比如制造…...

05有监督学习——神经网络
线性模型 给定n维输入: x [ x 1 , x 1 , … , x n ] T x {[{x_1},{x_1}, \ldots ,{x_n}]^T} x[x1,x1,…,xn]T 线性模型有一个n维权重和一个标量偏差: w [ w 1 , w 1 , … , w n ] T , b w {[{w_1},{w_1}, \ldots ,{w_n}]^T},b w[w1,w1,…,wn]T,b 输…...
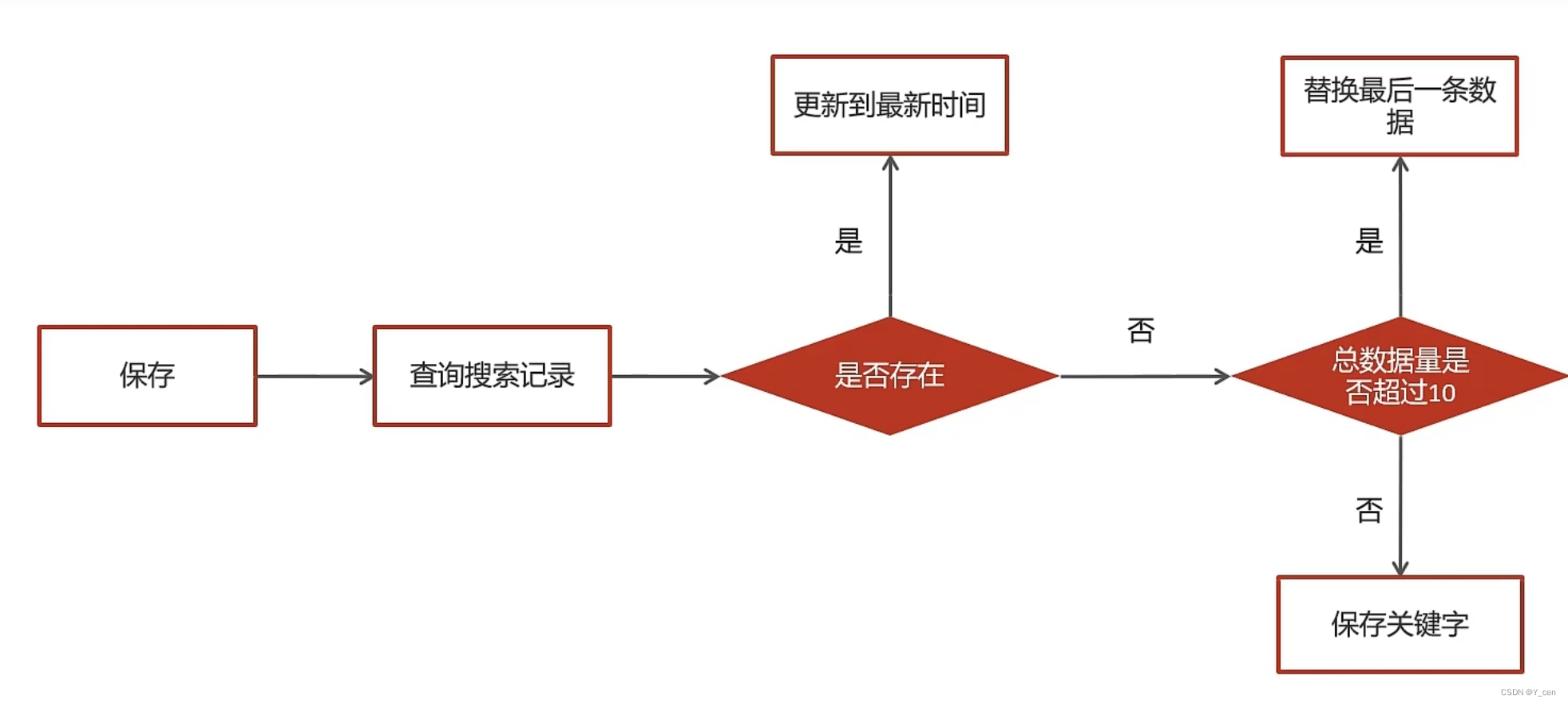
JavaWeb_LeadNews_Day7-ElasticSearch, Mongodb
JavaWeb_LeadNews_Day7-ElasticSearch, Mongodb elasticsearch安装配置 app文章搜索创建索引库app文章搜索思路分析具体实现 新增文章创建索引思路分析具体实现 MongoDB安装配置SpringBoot集成MongoDB app文章搜索记录保存搜索记录思路分析具体实现 查询搜索历史删除搜索历史 搜…...

redux中间件理解,常见的中间件,实现原理。
文章目录 一、Redux中间件介绍1、什么是Redux中间件2、使用redux中间件 一、Redux中间件介绍 1、什么是Redux中间件 redux 提供了类似后端 Express 的中间件概念,本质的目的是提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 actio…...
麒麟系统上安装 MySQL 8.0.24
我介绍一下在麒麟系统上安装 MySQL 8.0.24 的详细步骤,前提是您已经下载了 mysql-8.0.24-linux-glibc2.12-x86_64.tar.xz 安装包。其实安装很简单,但是有坑,而且问题非常严重!由于麒麟系统相关文章博客较少,导致遇到了…...
vue 展开和收起
效果图 代码块 <div><span v-for"(item,index) in showHandleList" :key"item.index"><span>{{item.emailFrom}}</span></span><span v-if"this.list.length > 4" click"showAll !showAll">{…...
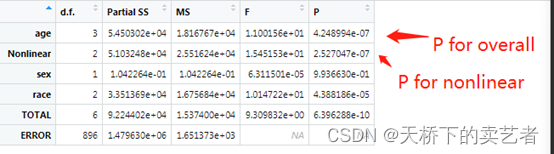
限制立方样条(RCS)中的P for overall和P for nonlinear的计算
最近不少人私信我,说有些SCI文章报了两个P值一个是P for overall,一个是P for nonlinear,就像下图这样,问我P for overall怎么计算。 P for overall我也不清楚是什么,有些博主说这个是总效应的P值,但是我没有找到相关出处。但是怎…...

vue3+ts引入echarts并实现自动缩放
第一种写法(不支持随页面大小变化而缩放) 统一的HTML页面 <div class"content_box" ref"barChart" id"content_box"></div>TS语法 <script setup lang"ts">import * as echarts from echar…...
Compressor For Mac强大视频编辑工具 v4.6.5中文版
Compressor for Mac是苹果公司推出的一款视频压缩工具,可以将高清视频、4K视频、甚至是8K视频压缩成适合网络传输或存储的小文件。Compressor支持多种视频格式,包括H.264、HEVC、ProRes和AVC-Intra等,用户可以根据需要选择不同的压缩格式。 …...

告别光流计算!用PyTorch复现MotionNet,5分钟搞定视频动作识别
5分钟实现视频动作识别:PyTorch版MotionNet实战指南 在咖啡还没凉透的间隙里,让AI看懂视频动作——这曾是计算机视觉领域最耗时的任务之一。传统双流网络需要预计算光流,像手工制作意大利面般繁琐;而2017年问世的MotionNet就像发…...

Vue3后台管理系统终极指南:5个关键问题与V3 Admin Vite解决方案
Vue3后台管理系统终极指南:5个关键问题与V3 Admin Vite解决方案 【免费下载链接】v3-admin-vite ☀️ A crafted Vue3 admin template | Vue Admin | Vue Template | Vue3 Admin | Vue3 Template | Vue 后台 | Vue 模板 | Vue3 后台 | Vue3 模板 项目地址: https:…...

从信号放大器到协议感知:深入解析Retimer与Redriver在高速链路中的角色演进
1. 高速链路中的信号完整性挑战 当你把手机靠近路由器时,网速会突然变快;用Type-C线连接移动硬盘传输大文件时,偶尔会出现卡顿——这些现象背后都隐藏着信号完整性这个关键问题。在AI服务器、数据中心互连、高端显卡这些需要高速数据传输的场…...

Go语言事件驱动:CloudEvents
Go语言事件驱动:CloudEvents 1. CloudEvents实现 type Event struct {SpecVersion stringType stringSource stringID stringData []byte }2. 总结 CloudEvents是云原生事件的标准格式,促进跨服务的事件交互。...

GIS技巧100例23-ArcGIS像元统计实战:从月度栅格到年度气候指标
1. 像元统计基础与气候数据特点 刚接触GIS处理气候数据时,我经常被各种栅格格式和统计方法搞得晕头转向。直到有次用ArcGIS的像元统计工具批量处理了5年的月降水数据,才发现这个功能简直是隐藏的效率神器。像元统计(Cell Statisticsÿ…...
)
告别JNI内存泄漏:实战中那些容易踩坑的字符串与数组操作(附完整代码示例)
告别JNI内存泄漏:实战中那些容易踩坑的字符串与数组操作(附完整代码示例) 在Android NDK开发和高性能Java服务中,JNI(Java Native Interface)作为连接Java与C的桥梁,其重要性不言而喻。然而&…...

不只是F5隐写:一次CTF解题,带你深入理解ZIP伪加密的底层原理与手动修复
深入解析ZIP伪加密:从CTF实战到二进制手动修复 在CTF竞赛中,ZIP伪加密一直是Misc类题目的经典考点。不同于常规的加密破解,伪加密巧妙地利用了ZIP文件格式的设计特性,在不实际加密数据的情况下制造出需要密码的假象。本文将带您深…...

基于CircuitPython与RP2040打造可编程USB脚踏开关:从硬件到软件的完整指南
1. 项目概述:为什么你需要一个可编程的脚踏开关? 在剪辑视频、处理音频、写代码或者玩游戏的时候,你的双手是不是永远不够用?频繁地在键盘、鼠标、调音台或者剪辑软件的面板之间切换,不仅效率低下,还容易打…...
)
从3D打印机到机械臂:聊聊步进电机选型时,那些容易被忽略的‘动态指标’(附避坑清单)
从3D打印机到机械臂:步进电机选型中那些被低估的动态性能指标 在自动化设备和精密运动控制领域,步进电机因其开环控制特性、高性价比和易于集成的特点,成为3D打印机、CNC机床、机械臂等设备的首选驱动元件。然而,许多工程师在选型…...

构建多模型备援策略以提升企业级 AI 应用可靠性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建多模型备援策略以提升企业级 AI 应用可靠性 在构建企业级 AI 应用时,服务的稳定性与可靠性是核心考量之一。单一模…...