flink sql checkpoint 调优配置
- `execution.checkpointing.interval`: 检查点之间的时间间隔(以毫秒为单位)。在此间隔内,系统将生成新的检查点
SET execution.checkpointing.interval = 6000;
- `execution.checkpointing.tolerable-failed-checkpoints`: 允许的连续失败检查点的最大数量。如果连续失败的检查点数量超过此值,作业将失败。
SET execution.checkpointing.tolerable-failed-checkpoints = 10;
- `execution.checkpointing.timeout`: 检查点的超时时间(以毫秒为单位)。如果在此时间内未完成检查点操作,作业将失败。
SET execution.checkpointing.timeout =600000;
- `execution.checkpointing.externalized-checkpoint-retention`: 外部化检查点的保留策略。`RETAIN_ON_CANCELLATION`表示在作业取消时保留外部化检查点。
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
- `execution.checkpointing.mode`: 检查点模式。`EXACTLY_ONCE`表示每个检查点只会在作业处理完全一次时生成。
SET execution.checkpointing.mode = EXACTLY_ONCE;
- `execution.checkpointing.unaligned`: 检查点是否对齐。如果设置为`true`,则检查点将在作业的所有任务完成之前生成。
SET execution.checkpointing.unaligned = true;
- `execution.checkpointing.max-concurrent-checkpoints`: 并发生成检查点的最大数量。在此数量的检查点生成之前,不会生成新的检查点。
SET execution.checkpointing.max-concurrent-checkpoints = 1;
- `state.checkpoints.num-retained`: 保留的检查点数量。超过此数量的检查点将被删除
SET state.checkpoints.num-retained = 3;
暂未使用
SET execution.checkpointing.interval = 6000;
SET execution.checkpointing.tolerable-failed-checkpoints = 10;
SET execution.checkpointing.timeout =600000;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
SET execution.checkpointing.mode = EXACTLY_ONCE;
SET execution.checkpointing.unaligned = true;
SET execution.checkpointing.max-concurrent-checkpoints = 1;
SET state.checkpoints.num-retained = 3;
yaml 文件中 起作用的配置信息如下:
flinkConfiguration:
taskmanager.numberOfTaskSlots: "36"
state.backend: rocksdb
state.checkpoint-storage: filesystem
state.checkpoints.num-retained: "3"
state.backend.incremental: "true"
state.savepoints.dir: file:///flink-data/savepoints
state.checkpoints.dir: file:///flink-data/checkpoints
high-availability.type: kubernetes
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory # JobManager HA
high-availability.storageDir: file:///opt/flink/flink_recovery # JobManager HA数据保存路径
serviceAccount: flink
登录到
kubectl -n flink exec -it session-deployment-only-taskmanager-2-1 bash
查看 cat flink-conf.yaml
blob.server.port: 6124
kubernetes.jobmanager.annotations: flinkdeployment.flink.apache.org/generation:2
state.checkpoints.num-retained: 3
kubernetes.jobmanager.replicas: 2
high-availability.type: kubernetes
high-availability.cluster-id: session-deployment-only
state.savepoints.dir: file:///flink-data/savepoints
kubernetes.taskmanager.cpu: 4.0
kubernetes.service-account: flink
kubernetes.cluster-id: session-deployment-only
state.checkpoint-storage: filesystem
high-availability.storageDir: file:///opt/flink/flink_recovery
kubernetes.internal.taskmanager.replicas: 1
kubernetes.container.image: localhost:5000/flink-sql:1.14.21
parallelism.default: 1
kubernetes.namespace: flink
taskmanager.numberOfTaskSlots: 36
kubernetes.rest-service.exposed.type: ClusterIP
high-availability.jobmanager.port: 6123
kubernetes.jobmanager.owner.reference: blockOwnerDeletion:false,apiVersion:flink.apache.org/v1beta1,kind:FlinkDeployment,uid:fadef756-d327-4f19-b1b4-181d92c659eb,name:session-deployment-only,controller:false
taskmanager.memory.process.size: 6048m
kubernetes.internal.jobmanager.entrypoint.class: org.apache.flink.kubernetes.entrypoint.KubernetesSessionClusterEntrypoint
kubernetes.pod-template-file: /tmp/flink_op_generated_podTemplate_4716243666145995447.yaml
state.backend.incremental: true
web.cancel.enable: false
execution.target: kubernetes-session
jobmanager.memory.process.size: 1024m
taskmanager.rpc.port: 6122
kubernetes.container.image.pull-policy: IfNotPresent
internal.cluster.execution-mode: NORMAL
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
kubernetes.jobmanager.cpu: 1.0
state.backend: rocksdb
$internal.flink.version: v1_14
state.checkpoints.dir: file:///flink-data/checkpoints
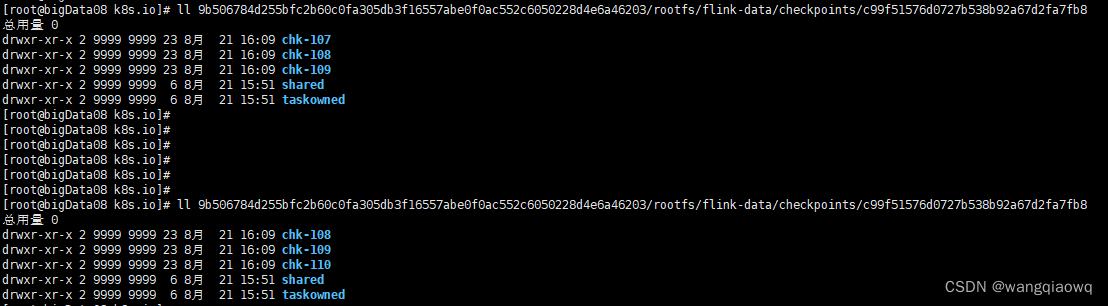
只产生3个chk文件了
一个chk-X代表了一次Checkpoint信息,里面存储Checkpoint的元数据和数据。
taskowned: TaskManagers拥有的状态
shared: 共享的状态
默认情况下,如果设置了Checkpoint选项,Flink只保留最近成功生成的1个Checkpoint。当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活。Flink支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置指定最多需要保存Checkpoint的个数,例如指定保留最近的10个Checkpoint(就是保留上面的10个chk-X):
state.checkpoints.num-retained: 10
ps1:Checkpoint目录如果删除,任务就无法指定从Checkpoint恢复了
ps2:如果job是失败了而不是手动cancel,那么无论选择上面哪种策略,state记录都会保留下来
ps3:使用RocksDB来作为增量checkpoint的存储,可以进行定期Lazy合并清除历史状态。
最后的yaml配置如下:
#Flink Session集群 源码请到
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: session-deployment-only
spec:
image: 192.168.1.249:16443/bigdata/flink-sql:1.14.21
#image: localhost:5000/flink-sql:1.14.21
flinkVersion: v1_14
#imagePullPolicy: Never # 镜像拉取策略,本地没有则从仓库拉取
imagePullPolicy: IfNotPresent
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "48"
state.backend: rocksdb
state.checkpoint-storage: filesystem
state.checkpoints.num-retained: "20"
state.backend.incremental: "true"
state.savepoints.dir: file:///opt/flink/volume/flink-sp
state.checkpoints.dir: file:///opt/flink/volume/flink-cp
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory # JobManager HA
high-availability.storageDir: file:///opt/flink/volume/flink-ha # JobManager HA数据保存路径
serviceAccount: flink
jobManager:
replicas: 2
resource:
memory: "1024m"
cpu: 1
taskManager:
replicas: 1
resource:
memory: "6048m"
cpu: 4
podTemplate:
spec:
hostAliases:
- ip: "192.168.1.236"
hostnames:
- "sql.server"
- ip: "192.168.1.246"
hostnames:
- "doris.server"
containers:
- name: flink-main-container
env:
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: flink-volume #挂载checkpoint pvc
mountPath: /opt/flink/volume
volumes:
- name: flink-volume
persistentVolumeClaim:
claimName: flink-checkpoint-pvc
pvc:
#Flinnk checkpoint 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-checkpoint-pvc # checkpoint pvc名称
namespace: flink # 指定归属的名命空间
spec:
storageClassName: nfs-client #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 20Gi #存储容量,根据实际需要更改
相关文章:
flink sql checkpoint 调优配置
- execution.checkpointing.interval: 检查点之间的时间间隔(以毫秒为单位)。在此间隔内,系统将生成新的检查点 SET execution.checkpointing.interval 6000; - execution.checkpointing.tolerable-failed-checkpoints: 允许的连续失败检查…...

Linux 网络文件共享介绍
Linux 网络文件共享介绍 一.常见的存储类型 目前常见的存储类型有 DAS,NAS,SAN 等,最主要的区别是硬盘存储媒介是如何 于处理器连接的,以及处理器使用何种方式来访问磁盘,以及访问磁盘使用 的协议(网络协议、I/O 协议)。 三种存储类型如下 直…...

Qt中如何在qml文件中使用其他的qml文件并创建对象
如果想使用其他的qml文件直接创建对象,必须先这样导入其qml文件并as成别名,才可以创建对象并使用它。 一、导入qml文件,例如: import "CameraConfig.qml" as CameraConfig import "CameraDevelopView.qml" a…...

学习心得04:CUDA
2018年的时候,看过同事使用CUDA。因为工作忙,所以也没请教。 近来买了本入门的CUDA书,学习了一番。有两个心得: 工作拆分。 CUDA是并行计算,也就是大量重复的可拆分的计算。数组最符合这个要求。简单点就是把数组外面…...
)
OpenCV实现摄像头图像分类(Python版)
先安装MMEdu库! MMEdu安装:https://blog.csdn.net/zyl_coder/article/details/132483865 下面的代码请在Jupyter上运行,并自己准备数据集。若模型还未训练,请先在本地训练完模型后再进行模型推理。 import cv2 capture cv2.Vi…...
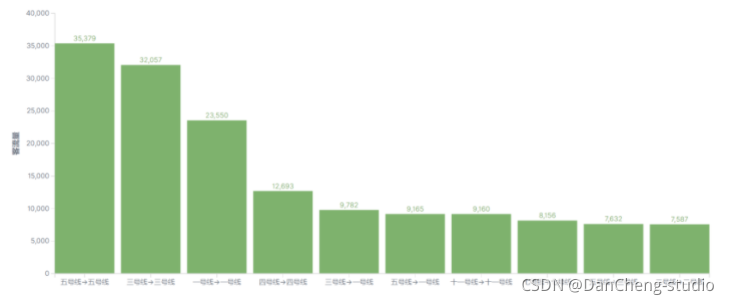
计算机竞赛 地铁大数据客流分析系统 设计与实现
文章目录 1 前言1.1 实现目的 2 数据集2.2 数据集概况2.3 数据字段 3 实现效果3.1 地铁数据整体概况3.2 平均指标3.3 地铁2018年9月开通运营的线路3.4 客流量相关统计3.4.1 线路客流量排行3.4.2 站点客流量排行3.4.3 入站客流排行3.4.4 整体客流随时间变化趋势3.4.5 不同线路客…...

sonarqube报错http status 500-internal server error,什么原因,怎么解决
sonarqube报错http status 500-internal server error,什么原因,怎么解决 答案: SonarQube报错HTTP状态500-内部服务器错误通常是由于服务器端出现了一些问题导致的。这可能是由于配置错误、资源不足、数据库连接问题或其他一些未知的问题引起的。 以下…...

工业设计的四个主要阶段,你都知道吗?优漫动游
一般来说,工业设计有几个基本程序:概念过程——设计创造的意识,即为什么创造。如何使你的想法成为现实,最终形成一个实体;实现过程——在工作消费中创造;行为过程实现其所有价值。在整个设计过程中,设计师需要始终站在…...
【DevOps视频笔记】4.Build 阶段 - Maven安装配置
一、Build 阶段工具 二、Operate阶段工具 三、服务器中安装 四、修改网卡信息 五、安装 jdk 和 maven Stage1 : 安装 JDK Stage 2 : 安装 Maven 2-1 : 更换文件夹名称 2-2 : 替换配置文件 settings.xml- 2-3 : 修改settings.xml详情 A. 修改maven仓库地址 - 阿里云 B…...

linux非GUI模式执行带有jpgc线程组jmeter脚本报错
linux非GUI模式执行jmeter脚本报错 Error in NonGUIDriver java.lang.IllegalArgumentException: Problem loading XML from:/root/fer/xxx.jmx. Cause: CannotResolveClassException: kg.apc.jmeter.vizualizers.CorrectedResultCollectorDetail:com.thoughtworks.xstream.c…...
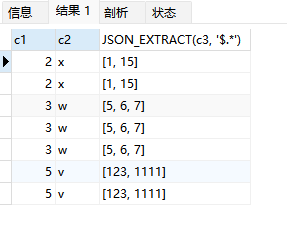
mysql处理json格式的字段,一文搞懂mysql解析json数据
文章目录 一、概述1、什么是JSON2、MySQL的JSON3、varchar、text、json类型字段的区别 二、JSON类型的创建1、建表指定2、修改字段 三、JSON类型的插入1、字符串直接插入2、JSON_ARRAY()函数插入数组3、JSON_OBJECT()函数插入对象4、JSON_ARRAYAGG()和JSON_OBJECTAGG()将查询结…...

测试数据生成
要生成300亿的文本数据,刚开始用python,实在是太慢了,改成c后速度提升了10几倍,看来干大事还是不能用python。代码留一下,以后可能还可以用上。 #include <stdio.h> #include <stdlib.h> #include <ti…...

网安周报|国防承包商Belcan泄露了带有漏洞列表的管理员密码
1.国防承包商Belcan泄露了带有漏洞列表的管理员密码 网络新闻研究团队发现了一个开放的 Kibana 实例,其中包含有关 Belcan、其员工和内部基础设施的敏感信息。Belcan 是一家政府、国防和航空航天承包商,提供全球设计、软件、制造、供应链、信息技术和数字…...
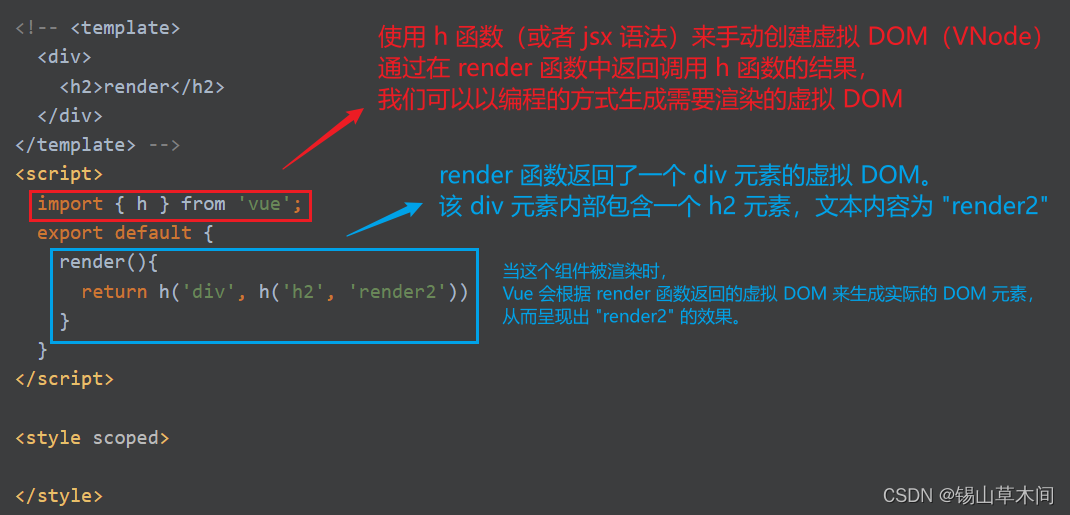
Vue3语法系统进阶 - 全面掌握Vue3特性
目录 01-ref属性在元素和组件上的分别使用02-利用nextTick监听DOM更新后的情况03-自定义指令与自定义全局属性及应用场景04-复用组件功能之Mixin混入05-插件的概念及插件的实现06-transition动画与过渡的实现07-动态组件与keep-alive组件缓存08-异步组件与Suspense一起使用09-跨…...

第9天----【位运算进阶之----按位取反(~)】(附补码,原码讲解)
今天我们来谈谈按位取反这件事。 简单来说,按位取反就是先将一个数写成其二进制表达形式,然后1变0,0变1。下面就让我们展开深入地讨论吧! 文章目录 一、预备知识:1. 原码:定义:优缺点ÿ…...

如何获取当前 JAR 包的存放位置?
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言代码中如何获取打包后的jar包存放的位置? 前言 代码中如何获取打包后的jar包存放的位置? 要获取当前运行的 JAR 包所存放的位置&#…...

微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。 一些知识点 llama2相比于前一代,令牌数量增加了40%࿰…...

Java【手撕双指针】LeetCode 57. “两数之和“, 图文详解思路分析 + 代码
文章目录 前言一、两数之和1, 题目2, 思路分析3, 代码展示 前言 各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你: 📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等 📗 Java数据结构: 顺序表, 链表…...

大数据(一)定义、特性
大数据(一)定义、特性 本文目录: 一、写在前面的话 二、大数据定义 三、大数据特性 3.1、大数据的大量 (Volume) 特性 3.2、大数据的高速(Velocity)特性 3.3、大数据的多样化 (Variety) 特性 3.4、大数据的价值 (value) 特性 3.5、大…...
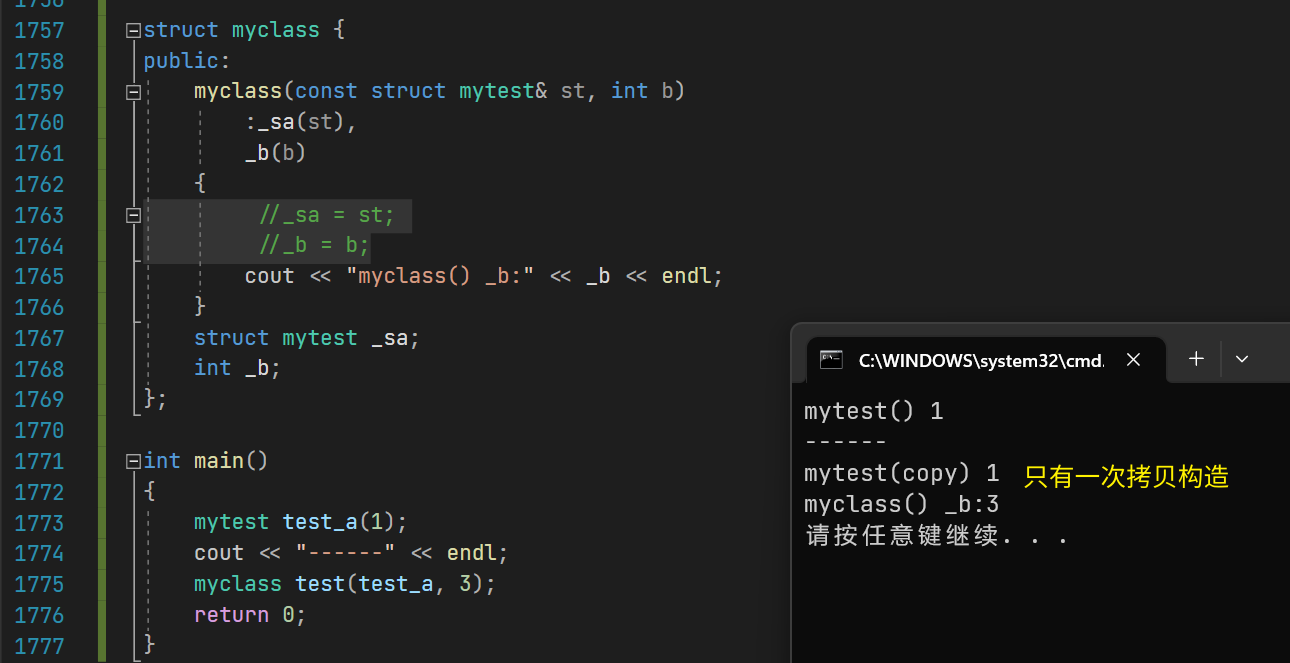
【C++】构造函数和初始化列表的性能差距
构造函数和初始化列表的性能差距对比测试 1.说明 在C类和对象中,你可能听到过更加推荐用初始化列表来初始化类内成员。如果类内成员是自定义类型,则只能在初始化列表中调用自定义类型的构造函数。 但初始化列表和在构造函数体内直接赋值有无性能差距呢…...

飞凌嵌入式i.MX 95xx核心板:高性能边缘计算与安全开发的硬件平台解析
1. 项目概述:一颗新旗舰的落地与嵌入式开发者的新选择最近,NXP(恩智浦)新一代的i.MX 95系列应用处理器正式进入量产阶段,而作为其重要的生态合作伙伴,飞凌嵌入式也同步发布了基于该系列芯片的全新核心板。这…...

深度解读|当增强现实遇上美妆教学:帕克西的AR美妆实训解决方案
在职业院校的形象设计、美容化妆等专业中,实训教学长期面临耗材成本高、练习机会有限、考核标准难量化等难题。学生每练习一次就消耗一次化妆品;教师逐个检查妆容步骤,费时费力。 增强现实(AR)技术的介入,正…...

智慧树视频自动播放插件:3分钟搞定所有课程学习的终极指南
智慧树视频自动播放插件:3分钟搞定所有课程学习的终极指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的手动操作而烦恼吗&#x…...

Yuzu模拟器进阶设置指南:图形选项怎么调?多核CPU如何利用?让你的《王国之泪》帧数翻倍
Yuzu模拟器进阶设置指南:图形选项与多核CPU优化实战 当《塞尔达传说:王国之泪》在Yuzu模拟器上运行时,你是否遇到过这些情况:画面闪烁不定、帧数剧烈波动、复杂场景突然卡顿?这些问题往往源于模拟器设置与硬件特性的不…...

3分钟掌握Typora LaTeX主题:用Markdown写出专业学术论文的终极指南
3分钟掌握Typora LaTeX主题:用Markdown写出专业学术论文的终极指南 【免费下载链接】typora-latex-theme 将Typora伪装成LaTeX的中文样式主题,本科生轻量级课程论文撰写的好帮手。This is a theme disguising Typora into Chinese LaTeX style. 项目地…...

MATLAB实战:从SSE到R方,手把手教你用误差指标评估预测模型
1. 为什么需要误差指标? 在数据分析和预测建模中,我们经常需要评估模型的预测效果。想象一下,你开发了一个房价预测模型,输入房屋面积、地段等信息后,模型会输出预测价格。但你怎么知道这个预测准不准呢?这…...

利用模型广场为不同文本处理任务选择合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用模型广场为不同文本处理任务选择合适的大模型 面对创意写作、代码生成、文档总结等多样化的AI任务,开发者或产品经…...

终极指南:5分钟在ComfyUI中实现智能图像分割
终极指南:5分钟在ComfyUI中实现智能图像分割 【免费下载链接】comfyui_segment_anything Based on GroundingDino and SAM, use semantic strings to segment any element in an image. The comfyui version of sd-webui-segment-anything. 项目地址: https://git…...

LLaMA论文里没细说的三个“小”改进:RMSNorm、SwiGLU和RoPE到底强在哪?
LLaMA模型三大底层优化技术解析:RMSNorm、SwiGLU与RoPE的设计哲学 当大多数人关注大语言模型的参数量级时,LLaMA团队却在微观架构层面做了一系列精妙改进。这些看似微小的技术选择,实则是支撑模型高效运行的关键支柱。本文将带您深入LLaMA的&…...

QT 5.14.2 编译调试踩坑实录:从‘file not found’到‘Illegal byte sequence’的保姆级排错指南
QT 5.14.2 编译调试实战:从文件缺失到编码陷阱的深度排错手册 接手一个遗留的QT串口通信项目时,本以为只是简单的代码移植,却在QT 5.14.2环境下遭遇了三个典型的"拦路虎":神秘的库文件失踪、程序突然崩溃的灵异事件&…...