如何用Python实现从pdf文件精准抓取数据生成数据库!
要从PDF文件中提取数据并生成数据库,你可以使用Python中的一些库和工具来实现。
1、安装必要的库:确保已安装所需的库。除了之前提到的PyPDF2、pdfminer.six和pdftotext之外,你可能还需要其他的库来处理提取的数据和数据库操作。例如,你可以使用re库进行正则表达式匹配,使用sqlite3库进行SQLite数据库操作,或使用pymysql库与MySQL数据库进行交互。
2、导入库:在Python脚本中导入所需的库。根据你选择的库和功能,你可能需要导入多个库。
3、打开PDF文件:使用适当的库打开PDF文件。如果使用PyPDF2库,可以使用以下代码:
pdf_file = open('file.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)4、读取PDF内容:根据你选择的库,使用适当的方法来读取PDF的文本内容。如果使用PyPDF2库,可以使用以下代码:
num_pages = pdf_reader.numPages
all_text = ''
for page_num in range(num_pages):page = pdf_reader.getPage(page_num)text = page.extract_text()all_text += text如果使用pdftotext库,可以使用以下代码:
pdf_text = pdftotext.PDF(pdf_file)
all_text = '\n\n'.join(pdf_text)5、提取所需的数据:根据PDF的结构和内容,使用适当的技术来提取所需的数据。这可能涉及到字符串处理、正则表达式、文本解析等。例如,如果你要从PDF中提取姓名和电子邮件地址,你可以使用正则表达式来匹配并提取它们。以下是一个简单的示例:
import re# 使用正则表达式提取姓名和电子邮件地址
name_pattern = r"Name: ([A-Za-z ]+)"
email_pattern = r"Email: ([\w.-]+@[\w.-]+)"
names = re.findall(name_pattern, all_text)
emails = re.findall(email_pattern, all_text)根据PDF的结构和内容,你可能需要自定义和调整这些模式。
6、创建数据库连接:使用Python中的数据库库来创建与数据库的连接。这取决于你使用的数据库类型。例如,如果你使用SQLite数据库,可以使用sqlite3库进行连接:
import sqlite3conn = sqlite3.connect('database.db')如果你使用的是MySQL数据库,可以使用pymysql库:
import pymysqlconn = pymysql.connect(host='localhost', user='username', password='password', database='database')请根据实际情况进行适当的调整。
7、创建表格:使用数据库连接,创建适当的表格来存储提取的数据。你可以使用SQL语句在数据库中执行创建表格的操作。以下是一个简单的SQLite示例:
# 创建表格
cursor = conn.cursor()
create_table_query = """
CREATE TABLE IF NOT EXISTS data (id INTEGER PRIMARY KEY AUTOINCREMENT,name TEXT,email TEXT
);
"""
cursor.execute(create_table_query)对于MySQL数据库,创建表格的SQL语句可能会有所不同。
8、插入数据:使用适当的SQL语句将提取的数据插入到数据库表中。以下是一个示例,将姓名和电子邮件地址插入SQLite数据库:
# 插入数据
insert_query = "INSERT INTO data (name, email) VALUES (?, ?)"
data = [(name, email) for name, email in zip(names, emails)]
cursor.executemany(insert_query, data)
conn.commit()对于MySQL数据库,插入数据的SQL语句可能会有所不同。
9、关闭连接:完成数据库操作后,记得关闭数据库连接:
conn.close()这是一个基本的框架,用于从PDF文件中提取数据并生成数据库。请根据你的具体需求和PDF文件的特点进行适当的调整和定制。例如,你可能需要处理数据清洗、处理缺失值、处理特殊字符等。此外,PDF文件的结构和内容也可能影响提取数据的复杂性。因此,根据具体的情况,你可能需要使用更高级的技术和库来处理PDF文件。
黑马程序员python教程,8天python从入门到精通,学python看这套就够了
相关文章:

如何用Python实现从pdf文件精准抓取数据生成数据库!
要从PDF文件中提取数据并生成数据库,你可以使用Python中的一些库和工具来实现。 1、安装必要的库:确保已安装所需的库。除了之前提到的PyPDF2、pdfminer.six和pdftotext之外,你可能还需要其他的库来处理提取的数据和数据库操作。例如&#x…...

科技资讯|苹果Apple Watch新专利,可根据服装、表带更换表盘颜色
根据美国商标和专利局(USPTO)公示的清单,苹果公司近日获得了一项 Apple Watch 相关的技术专利,最大的亮点在于配备颜色采样传感器,可以根据表带、服装自动变幻变盘颜色和主题。 Apple Watch 正面配备颜色采样传感器&am…...

猜数游戏-Rust版
cargo new guessing_game 创建项目 输入任意内容,并打印出来 main.rs: use std::io; // 像String这些类型都在预先导入的prelude里,如果要使用的不在prelude里,则需要显式导入fn main() { println!("猜数"); println!("…...

从零起步:学习数据结构的完整路径
文章目录 1. 基础概念和前置知识2. 线性数据结构3. 栈和队列4. 树结构5. 图结构6. 散列表和哈希表7. 高级数据结构8. 复杂性分析和算法设计9. 实践和项目10. 继续学习和深入11. 学习资源12. 练习和实践 🎉欢迎来到数据结构学习专栏~从零起步:学习数据结构…...

如何在浏览器中启用 WebGL 以使用 HTML5 3D 查看器
描述 WebCenter 中的 HTML5 3D Collada Viewer(自 14.1 以来新增)要求在浏览器中启用 WebGL。较旧的浏览器可能不支持此功能,或者要求用户首先显式启用此功能。本页介绍如何为所有主要浏览器启用此功能。WebGL 3D 查看器 本文是以下超级用户…...
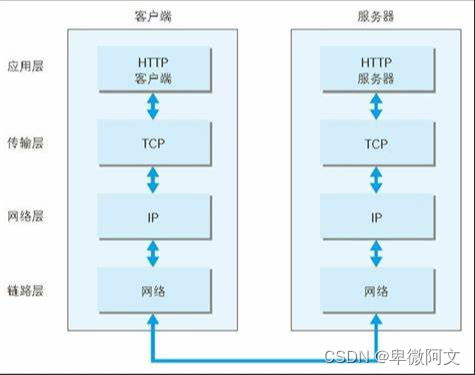
【计算机协议】第一章——HTTP协议详解
前言 HTTP(Hypertext Transfer Protocol)即超文本传输协议,是一种用于传输超媒体文档(例如HTML)的应用层协议。HTTP协议采用C/S(客户端/服务器)模式,客户端发起请求,服务…...
【FAQ】安防监控视频汇聚平台EasyCVR接入GB国标设备,无法显示通道信息的排查方法
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...

Matlab 生成一定信噪比的信号
文章目录 【 1. 信噪比 】【 2. 功率归一化 】2.1 实信号实噪声2.2 实信号复噪声 【 3. 能量归一化 】3.1 实信号实噪声3.2 实信号复噪声 【 4. 小结 】 【 1. 信噪比 】 信噪比公式 1 : S N R 10 ∗ l o g 10 P s P n 信噪比公式1:SNR10*log_{10}\frac…...

[国产MCU]-W801开发实例-定时器
定时器 文章目录 定时器1、定时器介绍2、定时器驱动API3、定时器使用示例本文将详细介绍如何使用W801的定时器模块。 1、定时器介绍 W801的定时器包含一个32-bit自动加载的计数器,该计数器由系统时钟经过分频后驱动。 W801有 6路完全独立定时器。实现了精确的定时时间以及中断…...

基于 CentOS 7 构建 LVS-DR 群集,配置nginx负载均衡。
基于 CentOS 7 构建 LVS-DR 群集。 关闭防火墙 [rootlocalhost ~]# systemctl stop firewalld 安装ifconfig yum install net-tools.x86_64 -y 准备四台虚拟机 IP 用途 19.168.244.144 客户端 192.168.244.145 lvs 192.168.244.148 RS 192.168.244.149 RS 在DS上 …...
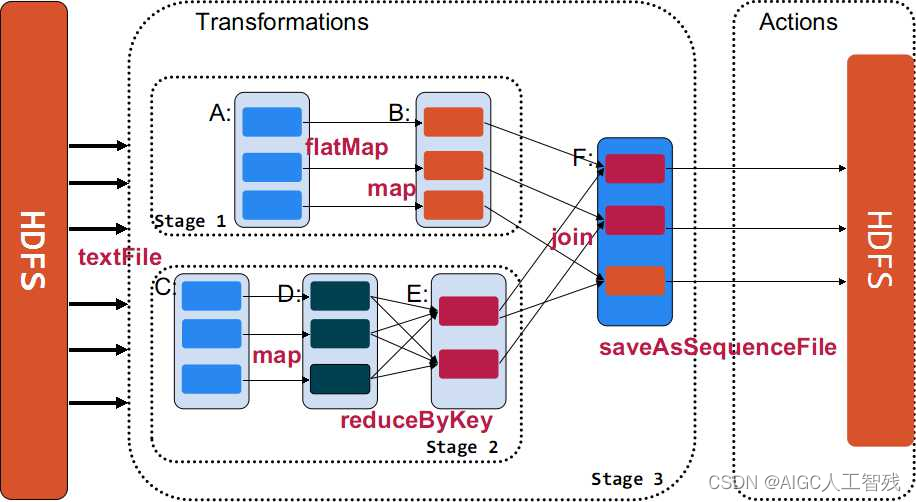
大数据——spark一文全知道
1、spark概述 spark是专为大规模数据处理而设计的快速通用计算引擎,与Hadoop的MapReduce功能类似,但它是基于内存的分布式计算框架,存储还是采用HDFS。 MapReduce和Spark的区别 MapReduce的MapReduce之间需要通过磁盘进行数据传递…...

Linux命令200例:telnet用于远程登录的网络协议(常用)
🏆作者简介,黑夜开发者,全栈领域新星创作者✌。CSDN专家博主,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。 &…...

使用 eBPF 在云中实现网络可观测性
可观测性是一种了解和解释应用当前状态的能力,也是一种知道何时出现问题的方法。随着在 Kubernetes 和 OpenShift 上以微服务形式进行云部署的应用程序越来越多,可观察性受到了广泛关注。许多应用程序都有严格的承诺,比如在停机时间、延迟和吞…...
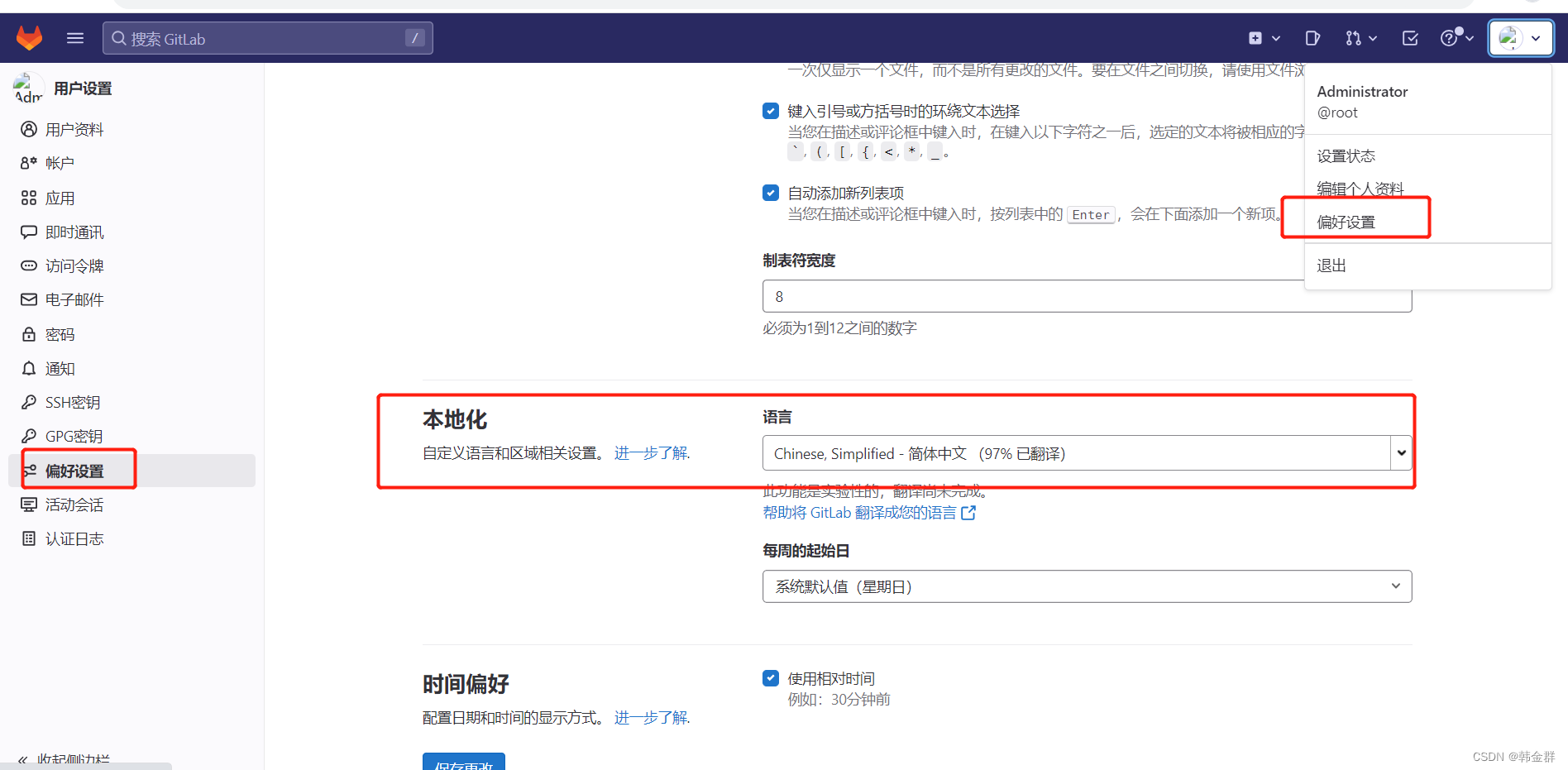
linux安装部署gitlab全教程,包含配置中文
linux安装部署gitlab全教程,包含配置中文 大家好,我是酷酷的韩~ 1.前期准备 安装包下载地址 https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/ 我这里选择的这个gitlab-ce-15.7.3-ce.0.el7.x86_64.rpm 还有一些相关依赖包(地址等审核过我放到…...

软考高级系统架构设计师系列论文八十:论企业信息化战略规划技术
软考高级系统架构设计师系列论文八十:论企业信息化战略规划技术 一、企业信息化相关知识点二、摘要三、正文四、总结一、企业信息化相关知识点 软考高级系统架构设计师:企业信息化战略与实施...

使用ChatGPT构建一个AIML聊天机器人是什么体验
使用ChatGPT构建一个AIML聊天机器人是什么体验,使用ChatGPT将C#代码转换为Swift代码以实现Swift版的Aiml聊天机器人,AIML(全名为Artificial Intelligence Markup Language)是一种基于XML模式匹配的人工智能标记语言,…...
[JavaWeb]【九】web后端开发-SpringBootWeb案例(菜单)
目录 一、准备工作 1.1 需求 1.2 环境搭建 1.2.1 准备数据库&表 1.2.2 创建springboot工程 1.2.3 配置application.properties & 准备对应实体类 1.2.3.1 application.properties 1.2.3.2 实体类 1.2.3.2.1 Emp类 1.2.3.2.2 Dept类 1.2.4 准备对应的Mapper、…...

vue 主组件把日期选择器给子组件props传obj值, 与子组件监听 watch对象或对象属性
1 主组件 1.1 :passObj 这种 非v-model ; change"DateChange"触发事件 <template> <div class"date-picker-panel"><el-date-picker v-model"value2" type"datetimerange" :picker-options"pickerOptions"…...

WebDAV之π-Disk派盘 + 一刻日记
一刻日记是一款日记、笔记和备忘录应用程序,旨在提供一个简单而专注的日记写作工具。它提供了一个干净、直观的界面,允许用户记录和管理他们的日常事务、个人情感、成就和目标等内容。 一刻日记的主要功能包括: – 创建和编辑日记、用户可以撰写和编辑自己的日记,记录重要…...

springboot aop实现接口防重复操作
一、前言 有时在项目开发中某些接口逻辑比较复杂,响应时间长,那么可能导致重复提交问题。 二、如何解决 1.先定义一个防重复提交的注解。 import java.lang.annotation.*;Inherited Target(ElementType.METHOD) Retention(RetentionPolicy.RUNTIME) Do…...

macOS Unlocker V3.0:在Windows/Linux电脑上运行macOS虚拟机的终极指南
macOS Unlocker V3.0:在Windows/Linux电脑上运行macOS虚拟机的终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unlo/unlocker macOS Unlocker V3.0是一款革命性的开源工具,专为VMware W…...

观察taotoken在ubuntu高峰期调用时的稳定性与自动路由效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在 Ubuntu 高峰期调用时的稳定性与自动路由效果 1. 背景与测试环境 在日常的开发与调试工作中,我们经常…...

告别SVN提交冲突!手把手教你配置TortoiseSVN 1.10.5的忽略列表与清理功能
告别SVN提交冲突!手把手教你配置TortoiseSVN 1.10.5的忽略列表与清理功能 团队协作开发中,版本控制系统是必不可少的工具。Subversion(SVN)作为一款经典的集中式版本控制系统,至今仍在许多项目中发挥着重要作用。然而&…...

拾亩绿光纯亚麻籽微粉效果怎么样
很多人想通过亚麻籽补充营养,却常遇到传统亚麻籽难吸收、营养易流失的问题:直接嚼咽口感粗糙,普通研磨粉冲调结块,榨油后Omega-3等核心营养大量损耗。拾亩绿光纯亚麻籽微粉依托南京国英健康科技有限公司的专利技术,可解…...

计算机视觉导航评估框架:从算法指标到用户体验的完整闭环
1. 项目概述:为什么我们需要一个“导航评估框架”?在计算机视觉辅助视障人士导航这个领域,我见过太多“实验室里的英雄”和“现实中的矮子”。一个算法在精心布置的走廊里识别障碍物准确率高达99.9%,但一到人潮涌动的火车站广场&a…...

英特尔转型芯片代工:从IDM巨头到服务商的六大挑战与机遇
1. 英特尔代工之路:从IDM巨头到服务提供商的六大挑战在半导体行业,英特尔这个名字几乎就是高性能微处理器的代名词。这家公司凭借其垂直整合制造模式,在过去几十年里构筑了难以撼动的技术护城河。然而,当行业的目光从单纯的制程竞…...

告别训练中断:在PyCharm中利用Tmux实现远程GPU服务器的持久化会话
1. 为什么需要持久化训练会话? 作为一名长期在深度学习领域摸爬滚打的工程师,我最头疼的就是训练过程中突然断网或者需要关闭电脑的情况。想象一下,你正在用PyCharm远程连接公司的GPU服务器训练一个需要48小时的模型,突然家里停电…...

嵌入式Linux SPI屏驱动踩坑实录:fbtft模块加载失败与dmesg排错指南
嵌入式Linux SPI屏驱动深度排错指南:从dmesg到硬件配置的全链路解析 当你在树莓派或全志H3开发板上折腾那块SPI接口的TFT屏幕时,是否经历过这样的绝望时刻?设备树配置看起来完美无缺,insmod命令执行后却只收获一片漆黑的屏幕和满屏…...
)
STM32CubeMX实战:用高级定时器TIM1实现带刹车功能的互补PWM输出(F4系列)
STM32CubeMX实战:用高级定时器TIM1实现带刹车功能的互补PWM输出(F4系列) 在电机控制、电源管理等工业应用中,硬件级的保护机制往往比软件响应更加可靠。STM32F4系列的高级定时器TIM1提供的互补PWM输出与刹车功能,正是为…...
pc手机通用)
明末:渊虚之羽加修改器2026.5.12最新破解版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)pc手机通用
游戏本体下载链接 修改器链接 由成都灵泽科技(Leenzee Games)开发,505 Games发行的动作角色扮演游戏《明末:渊虚之羽》(WUCHANG: Fallen Feathers)在近年来备受动作游戏玩家的关注。作为一款扎根于中国历…...