探索数据湖中的巨兽:Apache Hive分布式SQL计算平台浅度剖析!
文章目录
- ◆ Apache Hive 概述
- 1.1 分布式SQL计算
- 1.2 Hive的优势
- ◆ 模拟实现Hive功能
- 2.1 元数据管理
- 2.2 解析器
- 2.3 基础架构
- 2.4 Hive架构
- ◆ Hive基础架构
- 3.1 Hive架构图
- 3.2 Hive组件
- 3.2.1 元数据存储
- 3.2.2 Driver驱动程序
- 3.2.3 用户接口
- ◆ Hive部署
- 4.1 VMware虚拟机部署
- 步骤一:安装MySQL数据库
- 步骤2:配置Hadoop
- 步骤3:下载解压Hive
- 步骤4:提供MySQL Driver包
- 步骤5:配置Hive
- 步骤6:初始化元数据库
- 步骤7:启动Hive(使用Hadoop用户)
- ◆ Hive初体验
- 5.1 hiveShell初体验
- 5.2 补充:JPS命令
- ◆ Hive客户端
- 6.1 HiveServer2服务
- 6.2 HiveServer2服务 启动
- 6.3 Beeline
- 6.4 DataGrip链接Hive
◆ Apache Hive 概述
1.1 分布式SQL计算

- 对数据进行统计分析,SQL是目前最为方便的编程工具
- 大数据体系中充斥着非常多的统计分析场景,所以,使用SQL去处理数据,在大数据中也是有极大的需求的
- MapReduce支持程序开发(Java、Python等),但不支持SQL开发
- Apache Hive是一款分布式SQL计算的工具, 其主要功能是:将SQL语句 翻译成MapReduce程序运行
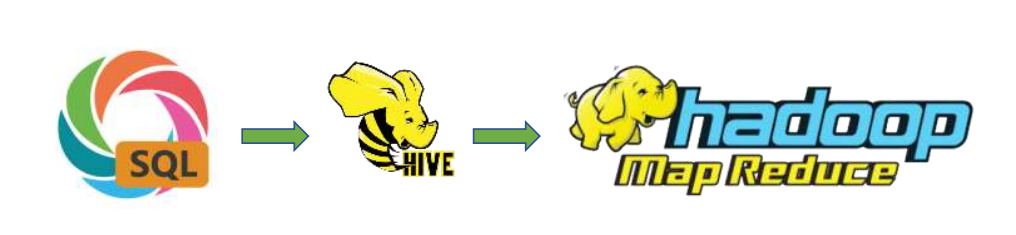
- 基于Hive为用户提供了分布式SQL计算的能力写的是SQL、执行的是MapReduce
1.2 Hive的优势
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 底层执行MapReduce,可以完成分布式海量数据的SQL处理
◆ 模拟实现Hive功能

2.1 元数据管理

- 总结
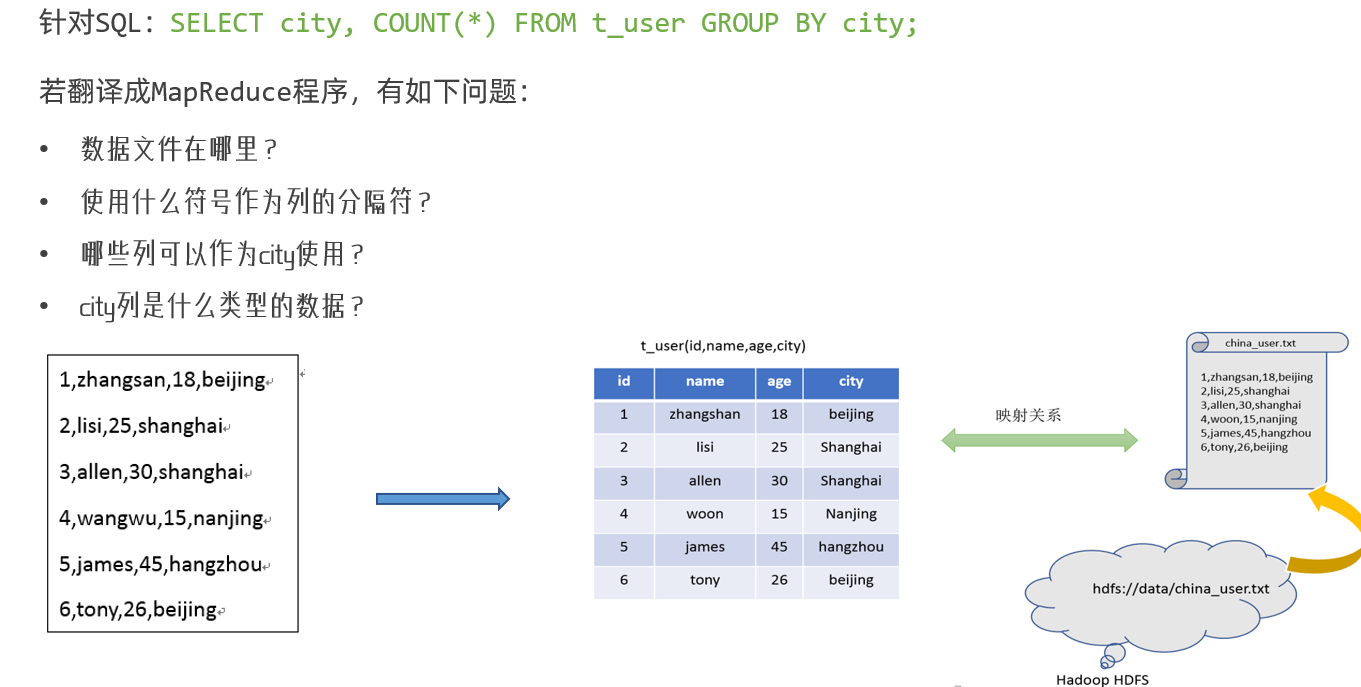
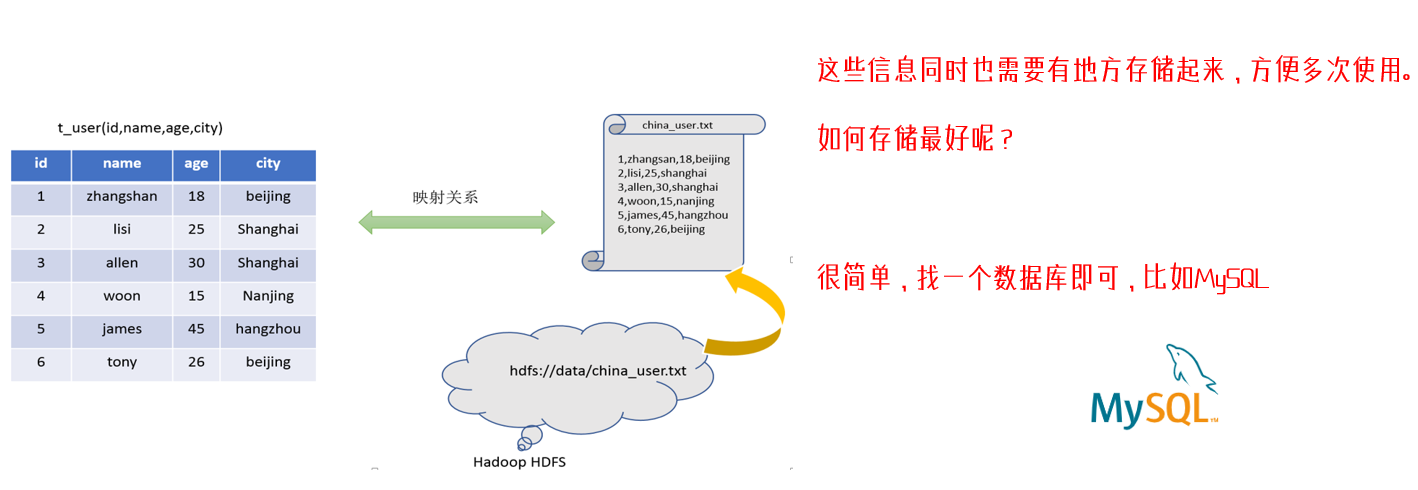
- 构建数据库首先需要拥有元数据管理功能,即:数据位置、数据结构、对数据进行描述 进行记录

2.2 解析器
- 解决了元数据管理后,我们还有一个至关重要的步骤, 即完成SQL到MapReduce转换的功能。

- SQL解析器需要完成的功能:
- SQL分析
- SQL到MapReduce程序的转换
- 提交MapReduce程序运行并收集执行结果
2.3 基础架构

- 至此,一款基于MapReduce的,分布式SQL执行引擎的基础构建完成。
- 核心组件需要有:
- 元数据管理,帮助记录各类元数据
- SQL解析器,完成SQL到MapReduce程序的转换
2.4 Hive架构
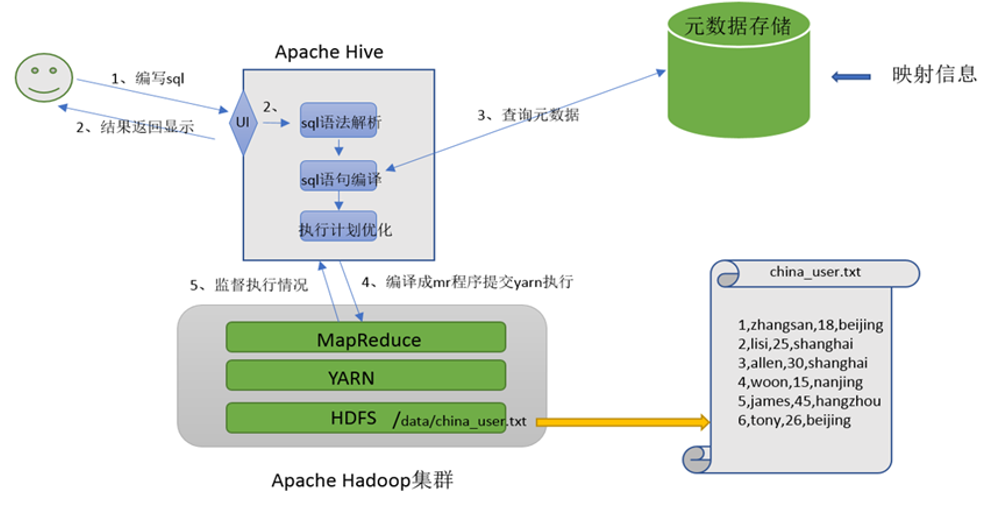
- Apache Hive其2大主要组件就是:SQL解析器以及元数据存储。
◆ Hive基础架构
3.1 Hive架构图
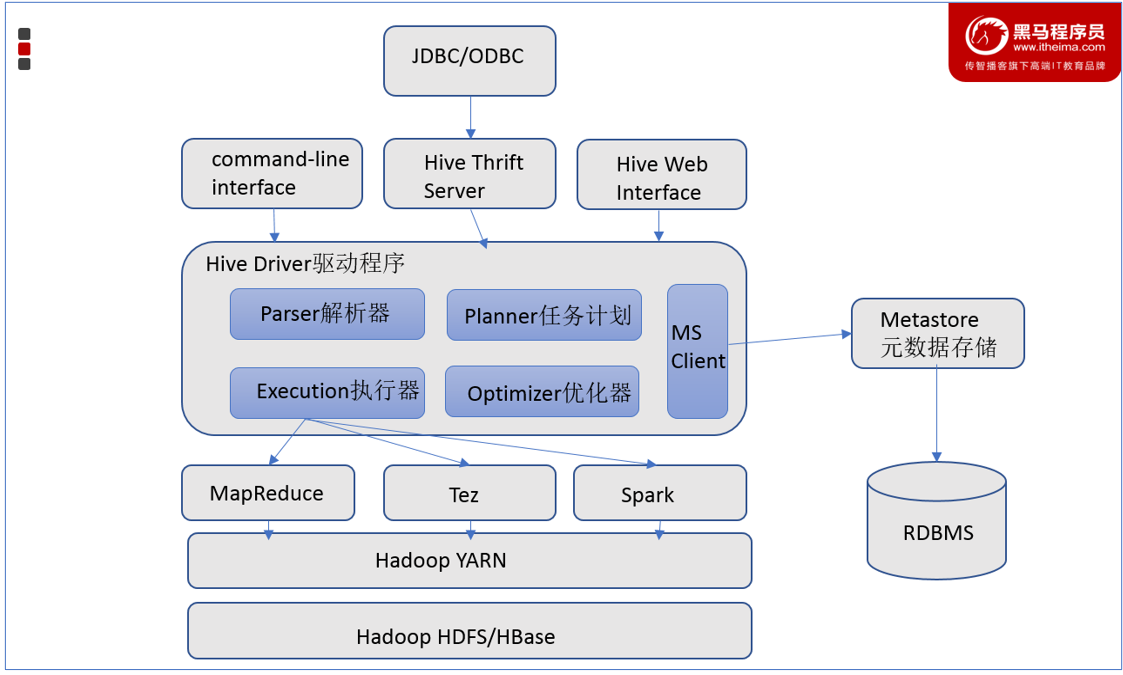
3.2 Hive组件
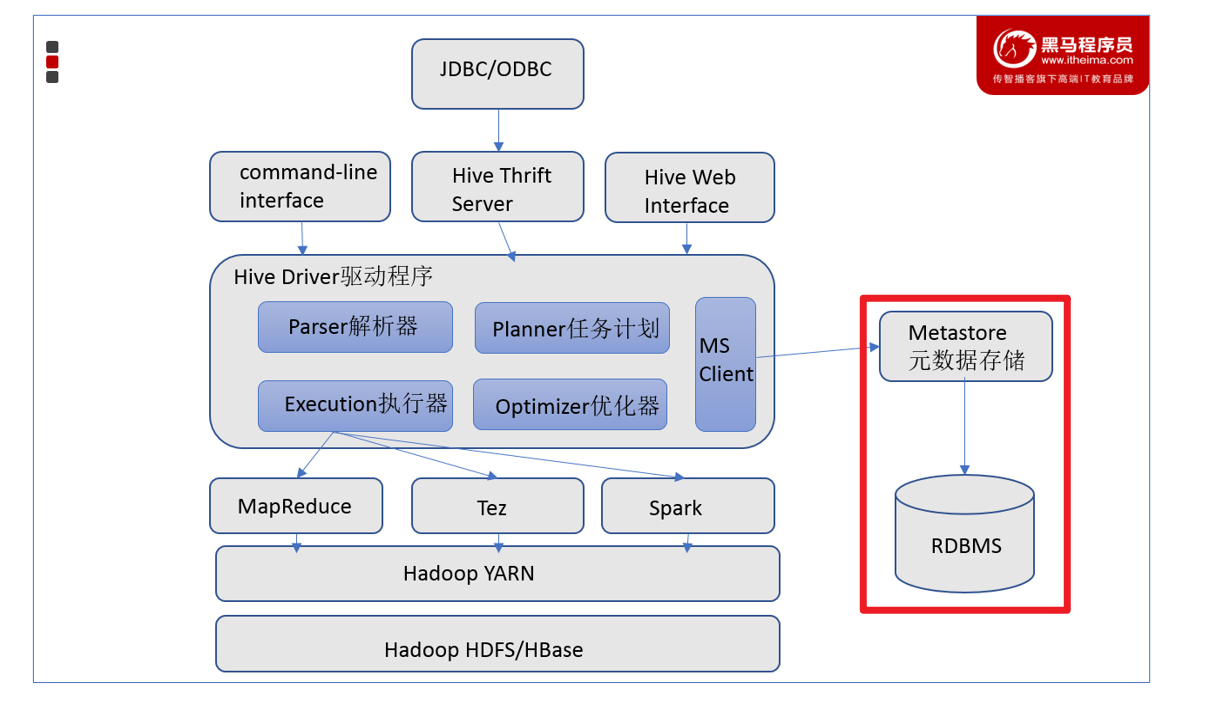
3.2.1 元数据存储
- 元数据通常存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是
否为外部表等),表的数据所在目录等。 - Hive提供了 Metastore 服务进程提供元数据管理功能
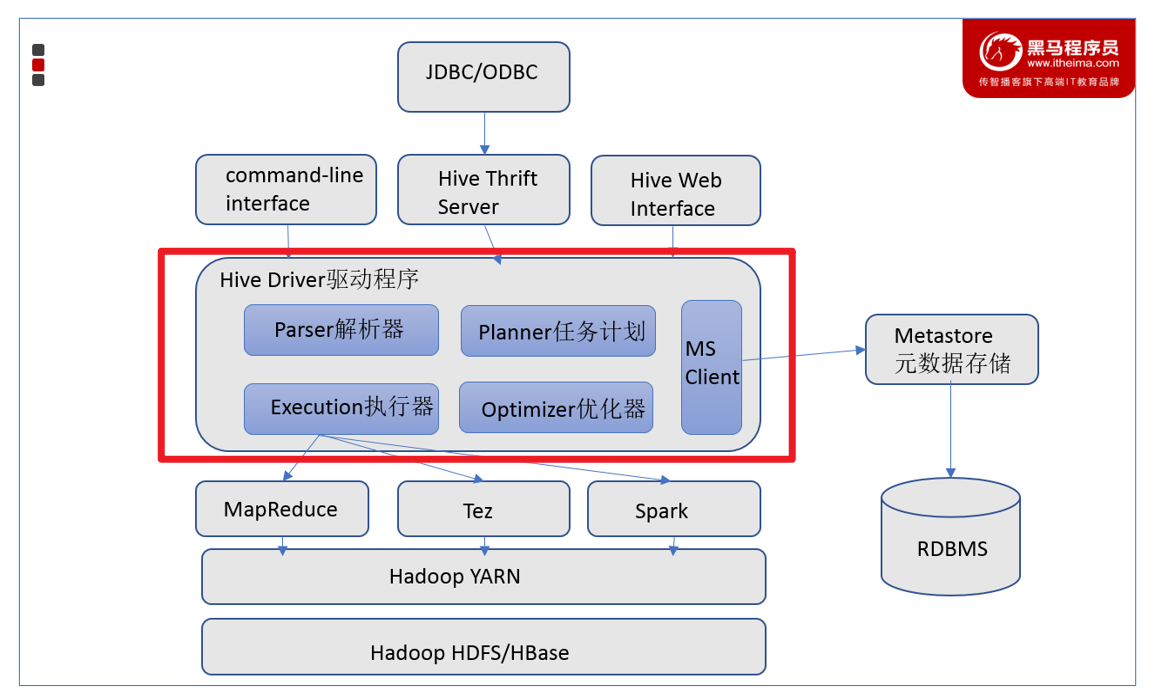
3.2.2 Driver驱动程序
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
- 功能:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
- 这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即Java代码中。
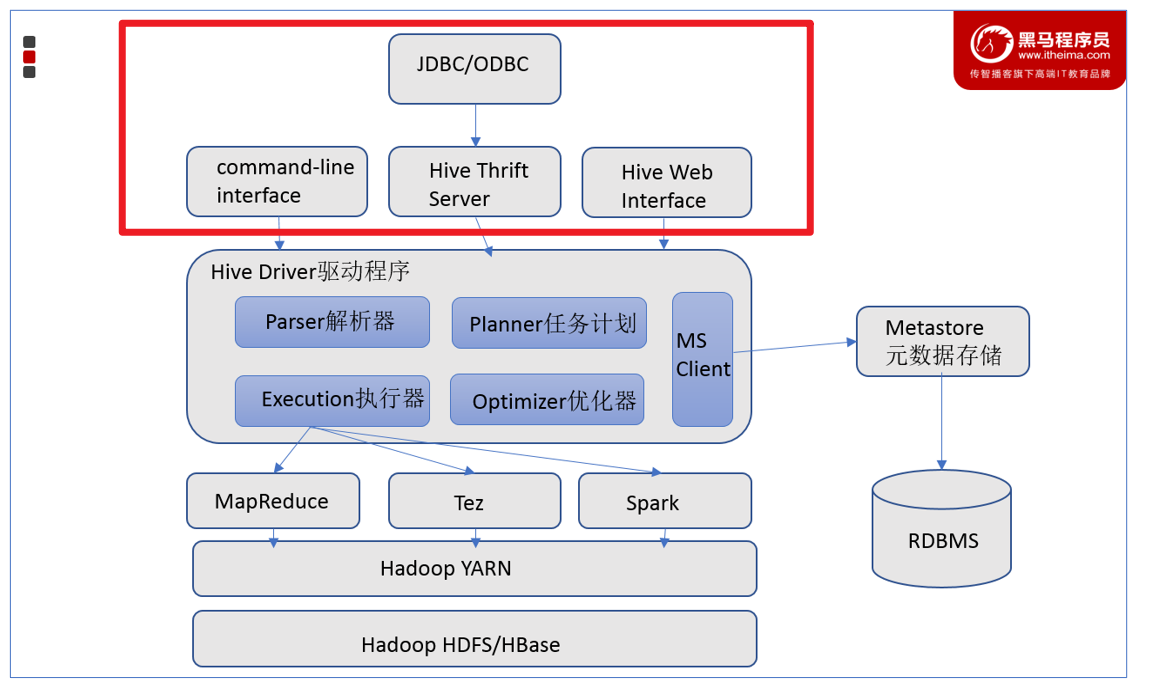
3.2.3 用户接口
- 用户接口包括 CLI、JDBC/ODBC、WebGUI。
- CLI(command line interface)为shell命令行
- Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。
- WebGUI是通过浏览器访问Hive
- Hive提供了 Hive Shell、 ThriftServer等服务进程向用户提供操作接口
◆ Hive部署
- Hive是分布式运行的框架还是单机运行的?
- Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行
4.1 VMware虚拟机部署
- Hive是单机工具,需要准备一台服务器供Hive使用即可。同时Hive需要使用元数据服务,即需要提供一个关系型数据库,我们也选择一台服务器安装关系型数据库即可。

步骤一:安装MySQL数据库
- 这里展示课件中的MYSQL5.7安装方式和使用MySQL8.+版本的操作,请按照喜欢选择
- 在node1节点使用yum在线安装MySQL5.7版本
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm# yum安装Mysql
yum -y install mysql-community-server# 启动Mysql设置开机启动
systemctl start mysqld
systemctl enable mysqld# 检查Mysql服务状态
systemctl status mysqld# 第一次启动mysql,会在日志文件中生成root用户的一个随机密码,使用下面命令查看该密码
grep 'temporary password' /var/log/mysqld.log
# 修改root用户密码
mysql -u root -p -h localhost
Enter password:mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root!@#$';# 如果你想设置简单密码,需要降低Mysql的密码安全级别
set global validate_password_policy=LOW; # 密码安全级别低
set global validate_password_length=4; # 密码长度最低4位即可# 然后就可以用简单密码了(课程中使用简单密码,为了方便,生产中不要这样)
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';/usr/bin/mysqladmin -u root password 'root'grant all privileges on *.* to root@"%" identified by 'root' with grant option;
flush privileges;
- 在node1节点使用yum在线安装MySQL8.+版本
-
更新软件
sudo yum update -
安装 MySQL 官方的 Yum Repository:
sudo rpm -ivh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm -
安装 MySQL 服务器:
sudo yum install mysql-server --nogpgcheck -
启动 MySQL 服务:
sudo systemctl start mysqld- 设置MySQL 服务在系统启动时自动启动
sudo systemctl enable mysqld -
获取初始密码并进行安全设置:
- 当次安装 MySQL 8 之后,它会为 root 用户生成一个随机的临时密码。通过查看日志来获得这个密码:
sudo grep 'temporary password' /var/log/mysqld.log -
登录到 MySQL,输入之前设置的 root 用户的密码:
mysql -u root -p -
然后,设置root用户密码:
# 设置用户密码xxxxx ALTER USER 'root'@'localhost' IDENTIFIED BY 'xxxxx';
- 以下操作时给与root用户的远程登录权限
- 创建或修改用户
- 如果root@"%"用户不存在:
CREATE USER 'root'@'%' IDENTIFIED BY 'xxx';- 如果root@"%"用户已存在,并且您只是想更新密码:
ALTER USER 'root'@'%' IDENTIFIED BY 'xxx'; - 赋予权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION; - 刷新权限
FLUSH PRIVILEGES; - 退出
exit
步骤2:配置Hadoop
- Hive的运行依赖于Hadoop(HDFS、MapReduce、YARN都依赖),同时涉及到HDFS文件系统的访问,所以需要配置Hadoop的代理用户,即设置hadoop用户允许代理(模拟)其它用户。
- 配置如下内容在Hadoop的core-site.xml中,并分发到其它节点,且重启HDFS集群
<property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value>
</property>
步骤3:下载解压Hive
- 切换到hadoop用户
su - hadoop - 下载Hive安装包,打开apache归档网址,点击公共软件版本档案,Ctrl+F查找
hive打开目录,找到3.1.3版本进行下载


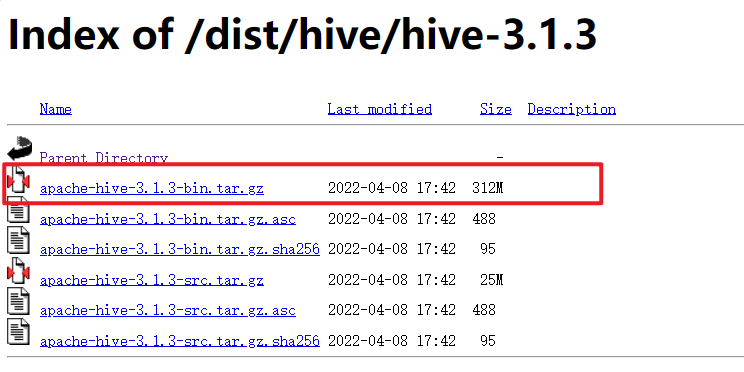
- 解压到node1服务器的:/export/server/内
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/ - 设置软连接
ln -s /export/server/apache-hive-3.1.3-bin/ /export/server/hive
步骤4:提供MySQL Driver包
- 下载MySQL驱动包
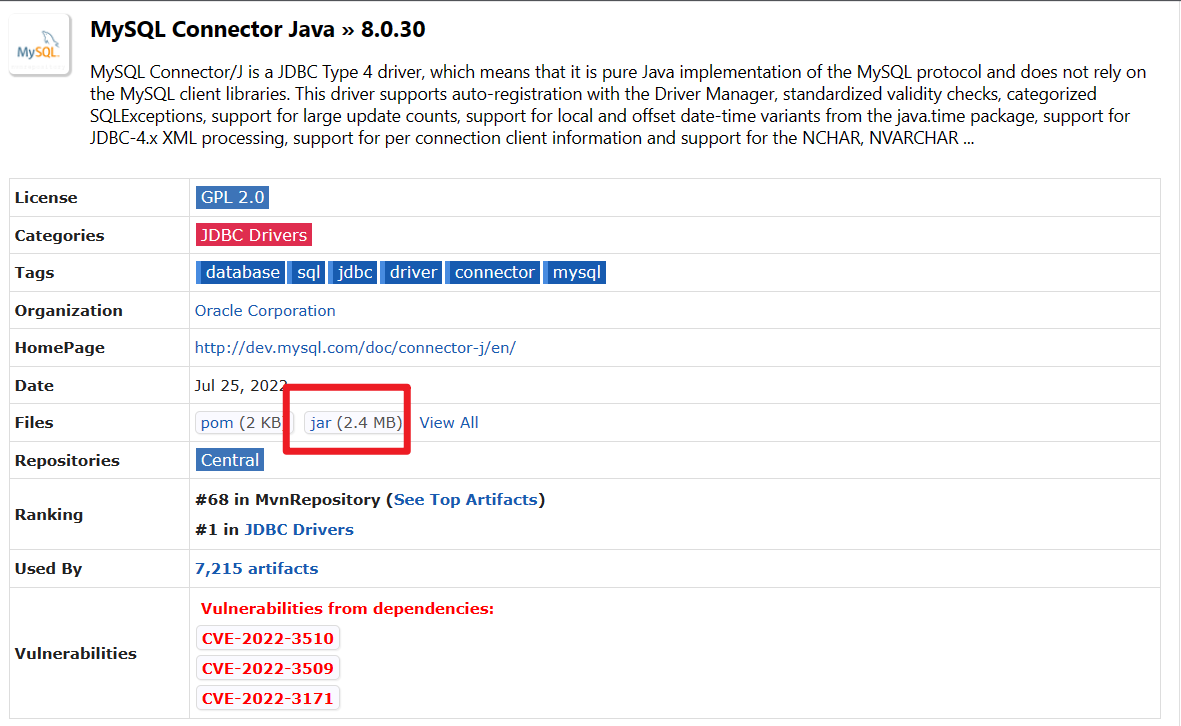
- ·将下载好的驱动jar包,放入: Hive安装文件夹的lib目录内
mv mysql-connector-java-8.0.30.jar /export/server/hive/lib/
步骤5:配置Hive
- 在Hive的conf目录内,新建hive-env.sh文件,填入以下环境变量内容:
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
- 在Hive的conf目录内,新建
hive-site.xml文件,填入以下内容【注意修改Mysql连接密码为自己的密码】
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>xxxx</value></property><property><name>hive.server2.thrift.bind.host</name><value>node1</value></property><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
步骤6:初始化元数据库
- Hive的配置已经完成,现在在启动Hive前,需要先初始化Hive所需的元数据库
- 在MySQL中新建数据库:
hive
CREATE DATABASE hive CHARSET UTF8;
- 执行元数据库初始化命令:
#进入hive的bin目录
cd /export/server/hive/bin/
#执行初始化命令
./schematool -initSchema -dbType mysql -verbos
- 初始化成功后,会在MySQL的hile库中新建74张元数据管理的表
步骤7:启动Hive(使用Hadoop用户)
- 确保Hive文件夹所属为hadoop用户,创建一个hive的日志文件夹:
mkdir /export/server/hive/logs - 启动元数据管理服务(必须启动,否则无法工作)
- 前台启动:
bin/hive --service metastore - 后台启动【推荐】:
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &

nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &含义:将元数据相关的日志存储到logs/文件夹下
- 前台启动:
- 启动客户端,二选一(当前先选择Hive Shell方式)
- Hive Shell方式(可以直接写SQL):
/bin/hive - Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用):
bin/hive --service hiveserver2
- Hive Shell方式(可以直接写SQL):
◆ Hive初体验
5.1 hiveShell初体验
- 首先,确保启动Metastore服务。
jps ps -ef|grep 端口号
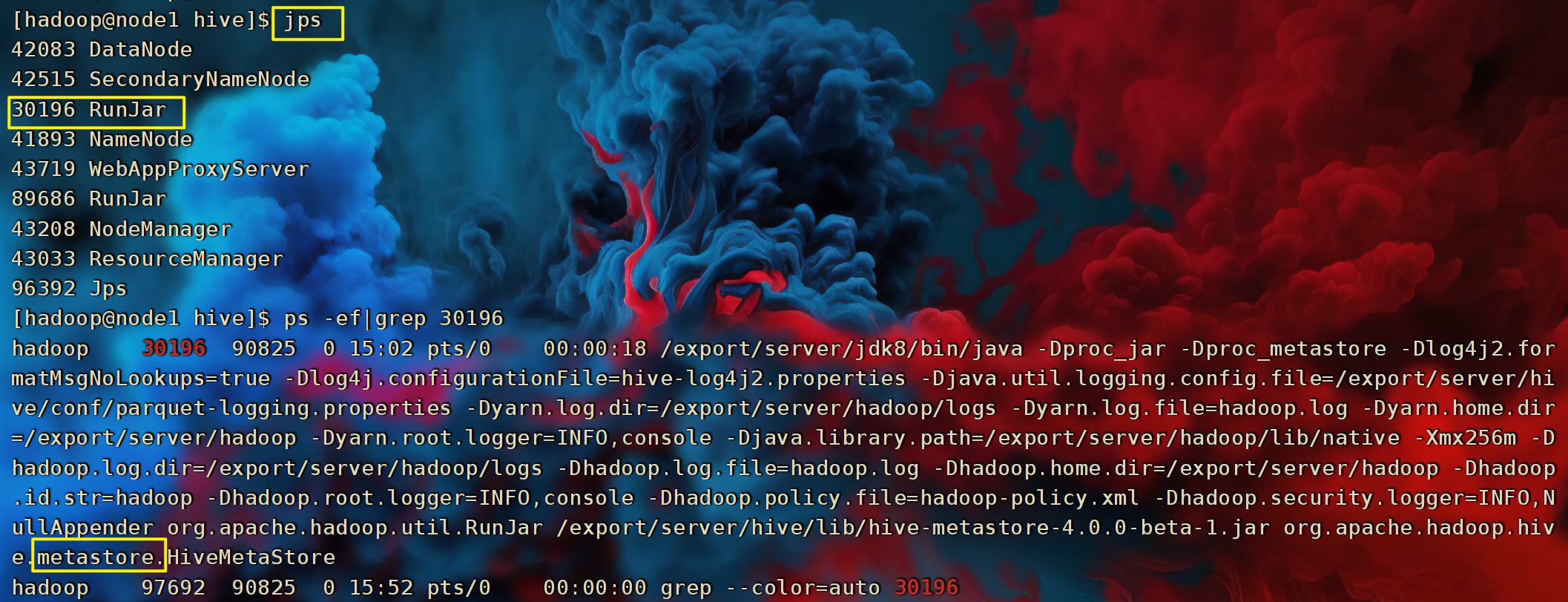
-
在hive目录下执行:
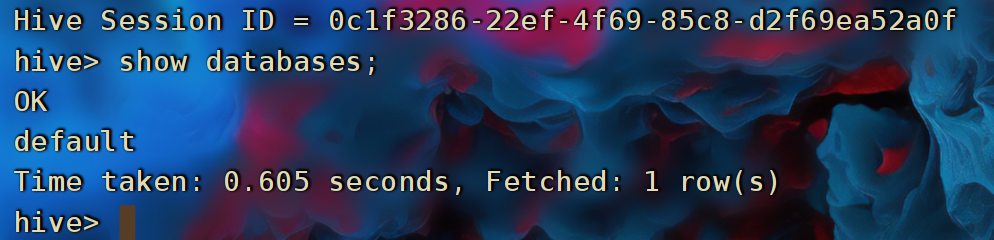
bin/hive,进入到Hive Shell环境中,可以直接执行SQL语句 -
创建表
CREATE TABLE test(id INT, name STRING, gender STRING); -
插入数据
INSERT INTO test VALUES(1,'王力红','男'),(2,'周杰轮','男'),(3, '林志灵','女');
-
查询数据
SELECT gender, COUNT(*) AS cnt FROM test GROUP BY gender; -
验证Hive的数据存储
- Hive的数据存储在HDFS的:
/user/hive/warehouse中
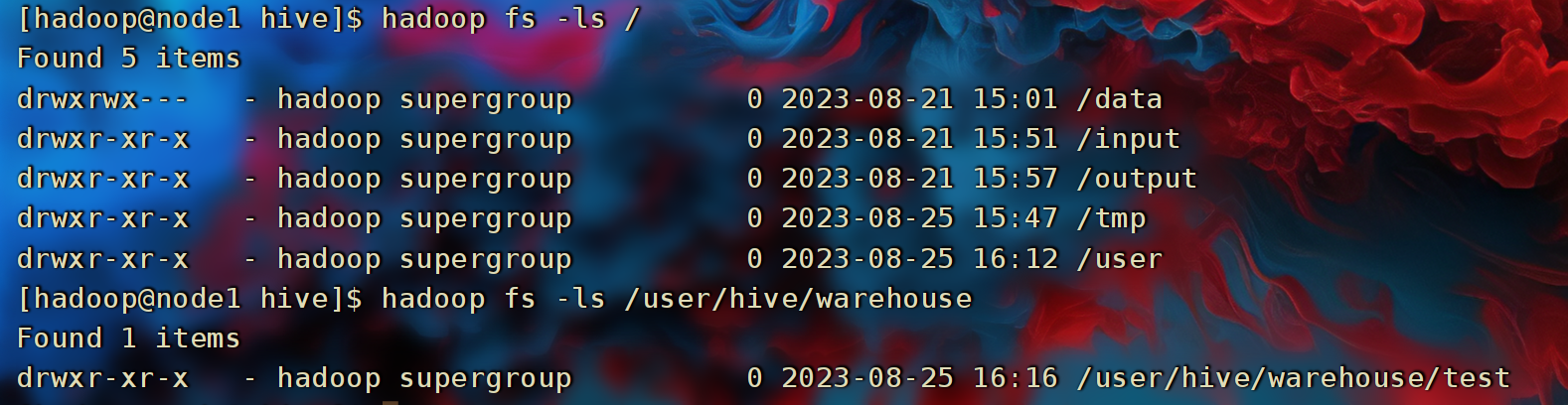

- Hive的数据存储在HDFS的:
-
验证SQL语句启动的MapReduce程序
- 打开YARN的WEB UI页面查看任务情况:
http://node1:8088
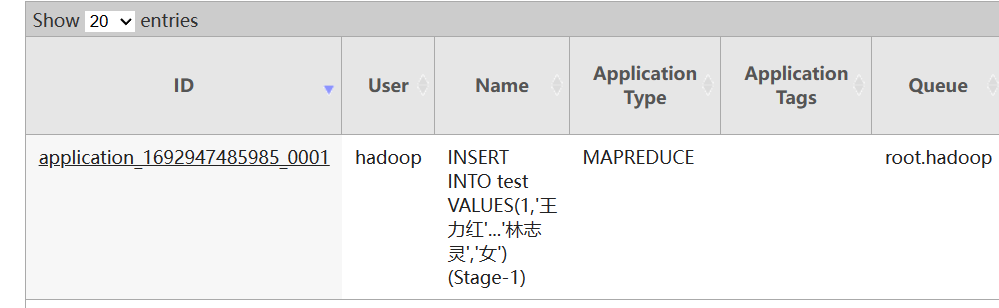
- 打开YARN的WEB UI页面查看任务情况:
5.2 补充:JPS命令
- 在Linux系统中,jps 命令并不是自带的命令,而是Java开发工具包(JDK)提供的工具。
- 在Linux系统中安装了JDK,可以在JDK的安装路径下的bin目录中找到 jps 命令。通常,安装JDK后,你可以通过在终端中输入 jps 来执行该命令。但在某些Linux发行版中,jps 命令可能需要通过设置环境变量或使用完整的路径来执行。
- jps 是 Java Virtual Machine Process Status Tool(Java虚拟机进程状态工具)的缩写。它是Java开发工具包中的一个命令行工具,用于列出当前系统中所有正在运行的Java进程的相关信息。jps 命令通常用于诊断和监控Java应用程序的运行状态。
- 使用 jps 命令可以列出正在运行的Java进程的进程ID(PID)以及这些进程的主类名。它可以帮助开发人员确定系统中正在运行的Java进程及其状态,特别是在进行多进程调试或监控的情况下。
- ps 命令常用的选项和用法:
- jps:列出并显示所有正在运行的Java进程的进程ID和主类名。
- jps -l 或 jps --list:显示进程ID、主类名以及传递给主类的参数。
- jps -v 或 jps --verbose:显示进程ID、主类名、传递给主类的参数以及JVM的启动参数。
- jps -m 或 jps --m:显示进程ID、主类名、传递给主类的参数以及传递给JVM的参数。
- jps -q 或 jps --quiet:只显示进程ID,不显示主类名。
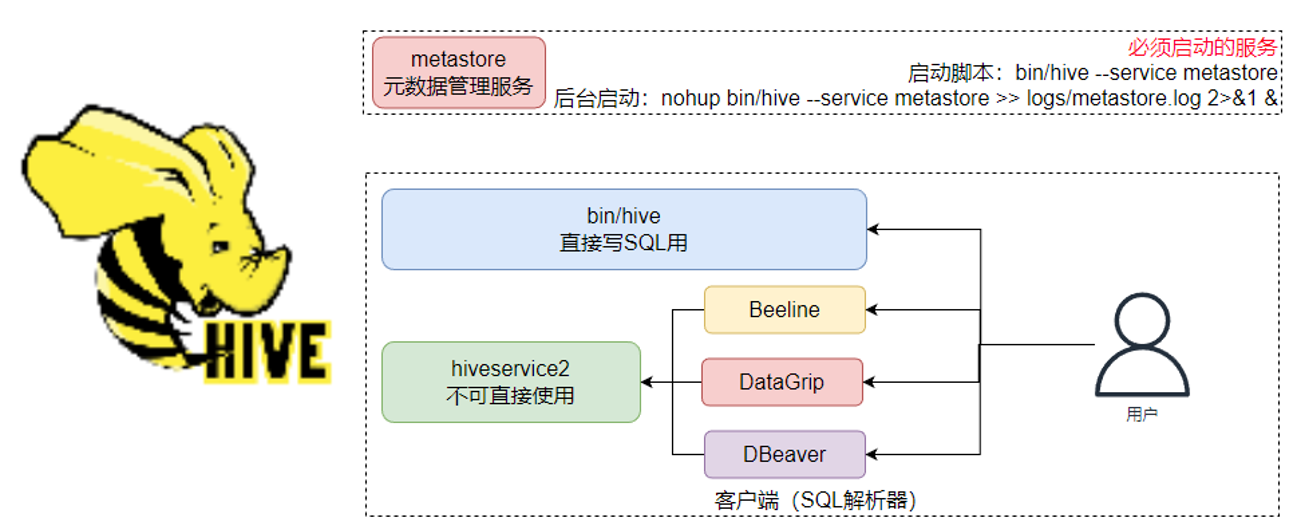
◆ Hive客户端
6.1 HiveServer2服务
在启动Hive的时候,除了必备的Metastore服务外,还有2种方式使用Hive:
- 方式1:
bin/hive即Hive的Shell客户端,可以直接写SQL - 方式2:
bin/hive --service hiveserver2- 后台执行脚本:
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
bin/hive --service metastore,启动的是元数据管理服务
bin/hive --service hiveserver2,启动的是HiveServer2服务
- 后台执行脚本:
- HiveServer2是Hive内置的一个ThriftServer服务,提供Thrift端口供其它客户端链接.可以连接ThriftServer的客户端有:
- Hive内置的 beeline客户端工具(命令行工具)
- 第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等
- Hive的客户端体系
6.2 HiveServer2服务 启动
- 在hive安装的服务器上,首先启动metastore服务,然后启动hiveserver2服务
#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &

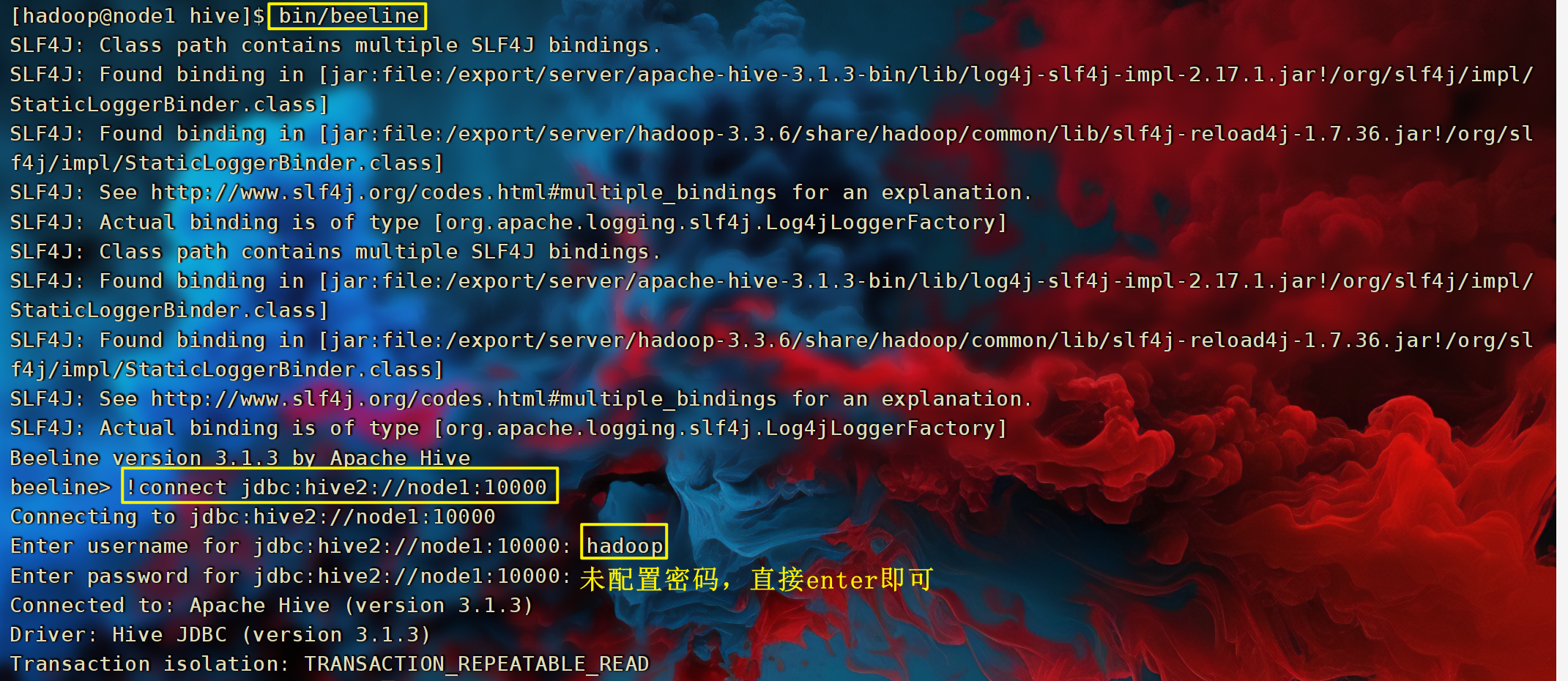
6.3 Beeline
- 在node1上使用beeline客户端进行连接访问。需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务。
# 在hive目录下执行 bin/beeline - Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:
jdbc:hive2://node1:10000
6.4 DataGrip链接Hive
- DataGrip、Dbeaver、SQuirrel SQL Client等可以在Windows、MAC平台中通过JDBC连接HiveServer2的图形界面工具;
- 这类工具往往专门针对SQL类软件进行开发优化、页面美观大方,操作简洁,更重要的是SQL编辑环境优雅;
- SQL语法智能提示补全、关键字高亮、查询结果智能显示、按钮操作大于命令操作;
- DataGrip是由JetBrains公司推出的数据库管理软件,DataGrip支持几乎所有主流的关系数据库产品,如DB2、Derby、
MySQL、Oracle、SQL Server等,也支持几乎所有主流的大数据生态圈SQL软件,并且提供了简单易用的界面。
-
windows创建工程文件夹
-
DataGrip中创建新Project
-
DataGrip连接Hive
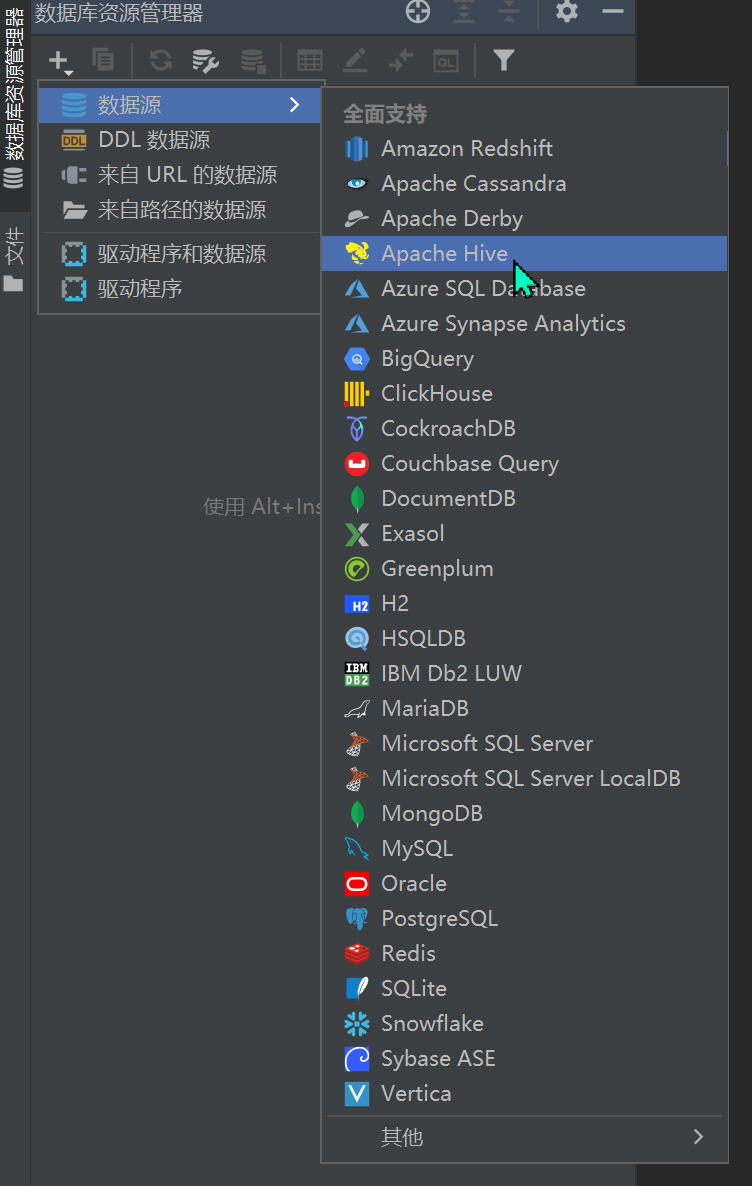
-
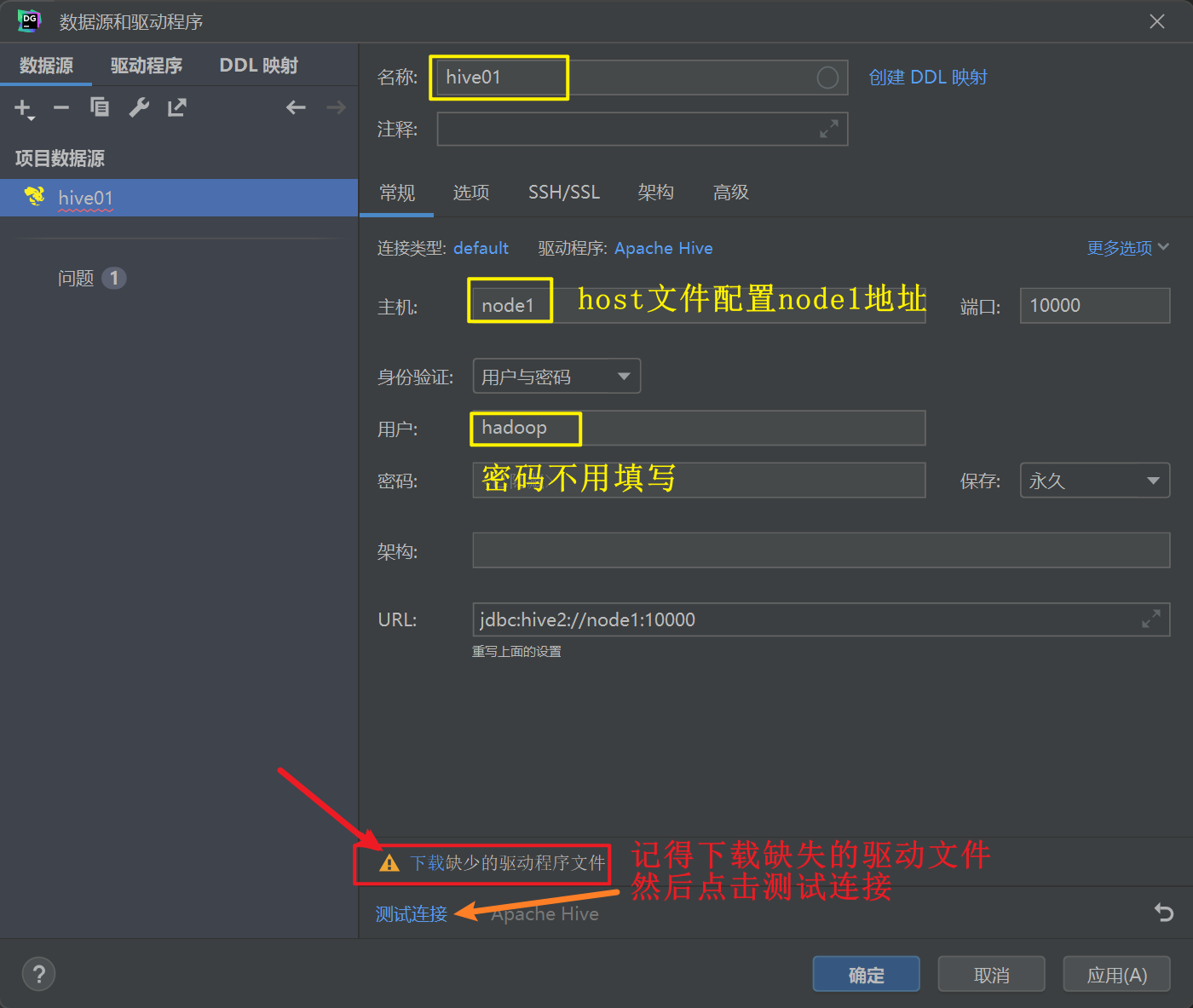
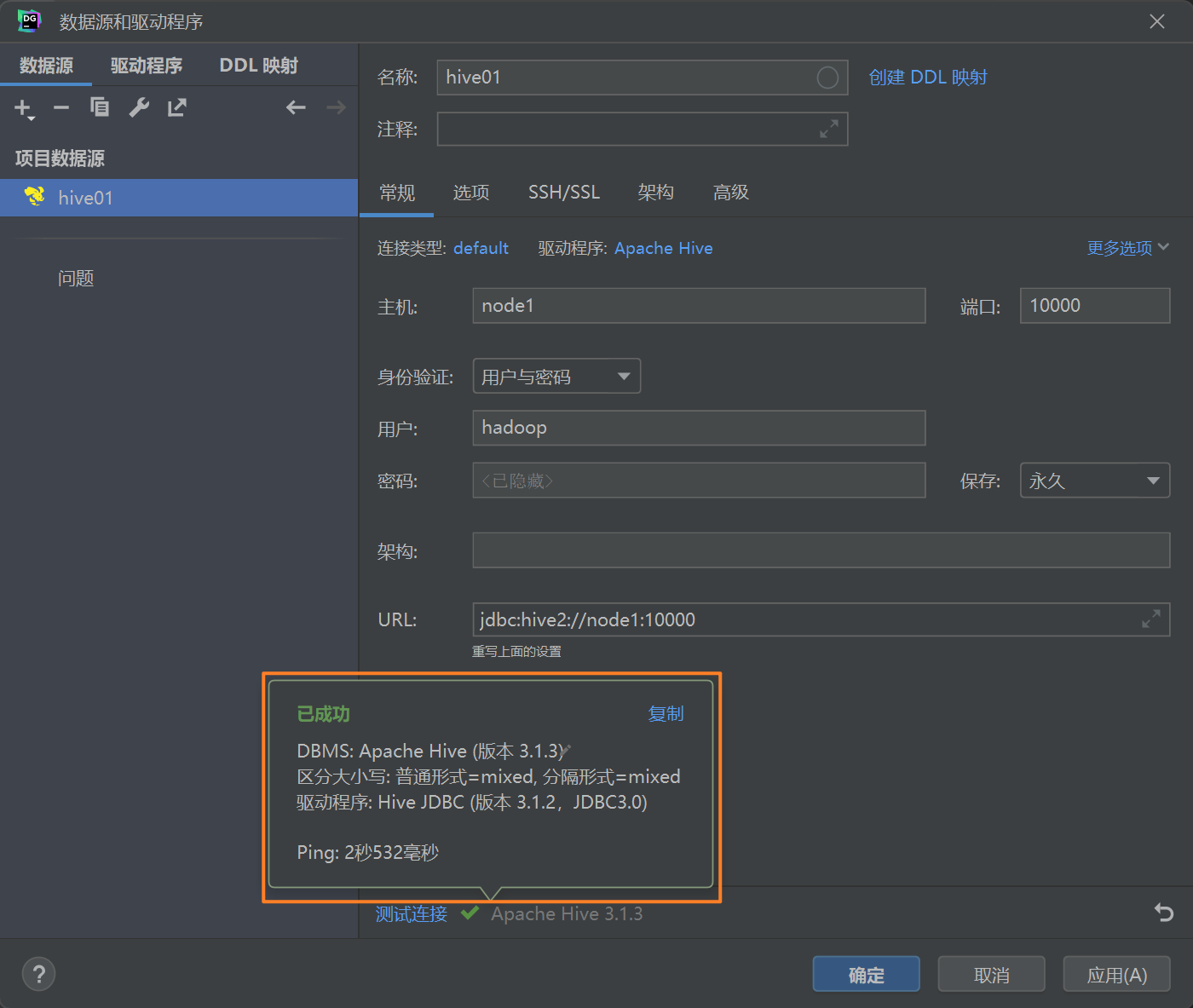
配置配置Hiveserver2服务连接信息和Hive JDBC连接驱动
相关文章:
探索数据湖中的巨兽:Apache Hive分布式SQL计算平台浅度剖析!
文章目录 ◆ Apache Hive 概述1.1 分布式SQL计算1.2 Hive的优势 ◆ 模拟实现Hive功能2.1 元数据管理2.2 解析器2.3 基础架构2.4 Hive架构 ◆ Hive基础架构3.1 Hive架构图3.2 Hive组件3.2.1 元数据存储3.2.2 Driver驱动程序3.2.3 用户接口 ◆ Hive部署4.1 VMware虚拟机部署步骤一…...
Node.js 的 Buffer 是什么?一站式了解指南
在 Node.js 中,Buffer 是一种用于处理二进制数据的机制。它允许你在不经过 JavaScript 垃圾回收机制的情况下直接操作原始内存,从而更高效地处理数据,特别是在处理网络流、文件系统操作和其他与 I/O 相关的任务时。Buffer 是一个全局对象&…...

延时盲注技术:SQL 注入漏洞检测入门指南
部分数据来源:ChatGPT 引言 在网络安全领域中,SQL 注入漏洞一直是常见的安全隐患之一。它可以利用应用程序对用户输入的不恰当处理,导致攻击者能够执行恶意的 SQL 查询语句,进而获取、修改或删除数据库中的数据。为了帮助初学者更好地理解和检测 SQL 注入漏洞,本文将介绍…...

【Midjourney电商与平面设计实战】创作效率提升300%
不得不说,最近智能AI的话题火爆圈内外啦。这不,战火已经从IT行业燃烧到设计行业里了。 刚研究完ChatGPT,现在又出来一个AI作图Midjourney。 其视觉效果令不少网友感叹:“AI已经不逊于人类画师了!” 现如今,在AIGC 热…...

URI、URL、URIBuilder、UriBuilder、UriComponentsBuilder说明及基本使用
之前想过直接获取url通过拼接字符串的方式实现,但是这种只是暂时的,后续地址如果有变化或参数很多,去岂不是要拼接很长,由于这些等等原因,所以找了一些方法实现 java.net.URI URI全称是Uniform Resource Identifier,也就是统一资源标识符,它是一种采用特定的语法标识一…...

抓包 - 简要总结 - Windows和Android抓包
抓包 - 简要总结 - Windows和Android抓包 前言 小巧且强大的抓包工具“Fiddler”安装可参考我的另一篇博客:抓包 - 经典抓包工具Fiddler的安装与初使用 本文主要介绍如何使用Fiddler抓包Windows和安卓。 Windows 抓包Windows很简单,安装证书&#x…...
iOS脱壳技术(二):深入探讨dumpdecrypted工具的高级使用方法
前言 应用程序脱壳是指从iOS应用程序中提取其未加密的二进制可执行文件,通常是Mach-O格式。这可以帮助我们深入研究应用程序的底层代码、算法、逻辑以及数据结构。这在逆向工程、性能优化、安全性分析等方面都有着重要的应用。 在上一篇内容中我们已经介绍了Clutc…...

4.RabbitMQ高级特性 幂等 可靠消息 等等
一、如何保证生产者生产消息100%的投递成功 保障消息的成功发出保障MQ节点的成功接收发送端收到MQ节点(Broker)确认应答完善的消息进行补偿机制 1. 理解Confirm确认消息机制 消息的确认,是指生产者投递消息后,如果Broker收到消…...

ES常见错误总结
目录 报错信息 复盘 org.elasticsearch.index.query.QueryShardException:No mapping found for [xx] in order to sort on 报错信息 测试环境 org.elasticsearch.index.query.QueryShardException: No mapping found for [xx] in order to sort on 数据不存在的时候或者…...
35、下载、安装 jdk11 记录,Idea中把项目从 jdk8 换 jdk 11
之前一直用jdk8,现在改成 11的试试看 登录官网下载这个11 https://www.oracle.com/cn/java/technologies/downloads/#java11-windows 下载jdk的oracle官网 需要自己注册oracle账户 修改环境变量的 JAVA_HOME Path 路径这里原本添加8的时候有了,不…...
TinyVue - 华为云 OpenTiny 出品的企业级前端 UI 组件库,免费开源,同时支持 Vue2 / Vue3,自带 TinyPro 中后台管理系统
华为最新发布的前端 UI 组件库,支持 PC 和移动端,自带了 admin 后台系统,完成度很高,web 项目开发又多一个选择。 关于 OpenTiny 和 TinyVue 在上个月结束的华为开发者大会2023上,官方正式进行发布了 OpenTiny&#…...
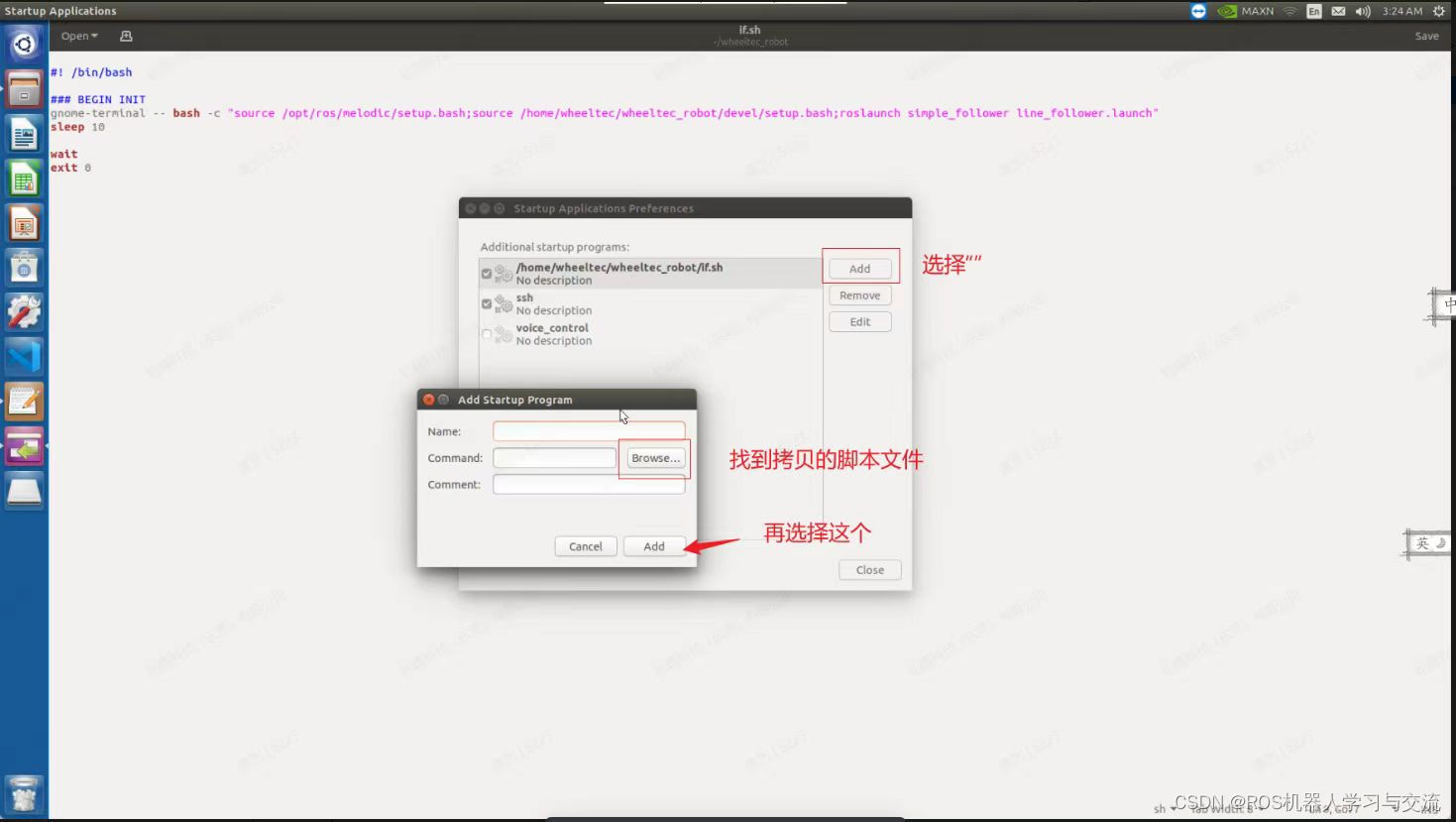
ubuntu下自启动设置,为了开机自启动launch文件
1、书写sh脚本文件 每隔5秒钟启动一个launch文件,也可以直接在一个launch文件中启动多个,这里为了确保启动顺利,添加了一些延时 #! /bin/bash ### BEGIN INIT sleep 5 gnome-terminal -- bash -c "source /opt/ros/melodic/setup.bash…...
)
脚本:PDF文件批量转换成图片(python3)
文章目录 语言用法源码1源码2 语言 语言:python 3 用法 用法:选择PDF文件所在的目录,点击 确定 后,自动将该目录下的所有PDF转换成单个图片,图片名称为: pdf文件名.page_序号.jpg 如运行中报错,需要自行…...

Spring和mybatis整合
一、Spring整合MyBatis 1. 导入pom依赖 1.1 添加spring相关依赖(5.0.2.RELEASE) spring-core spring-beans spring-context spring-orm spring-tx spring-aspects spring-web 1.2 添加mybatis相关依赖 mybatis核心:mybatis(3.4.5) Mybatis分页:pagehel…...
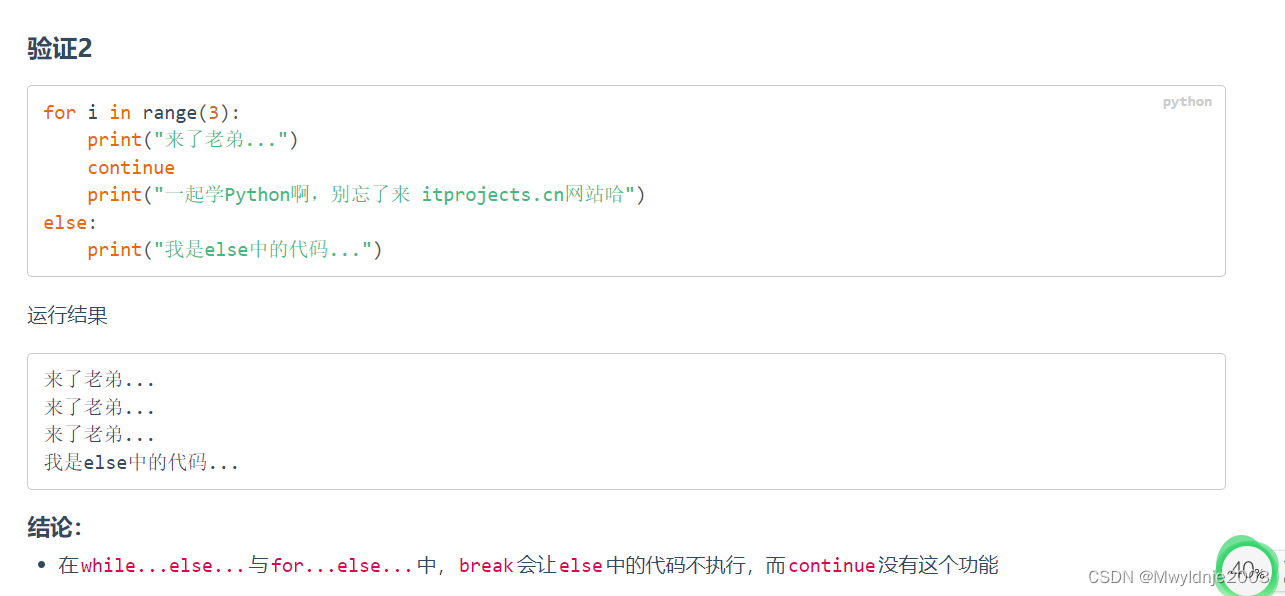
应知道的python基础知识
1、运算符 2、特殊情况下的逻辑运算 3、循环中的else 3.1 while else 3.2 for else 4、列表相关操作 列表的相关操作 4.1增(append, extend, insert) 通过append可以向列表添加元素:列表.append(新元素数据)通过extend可以将另一个列表中的元素逐一添加到列表中:列表.exte…...
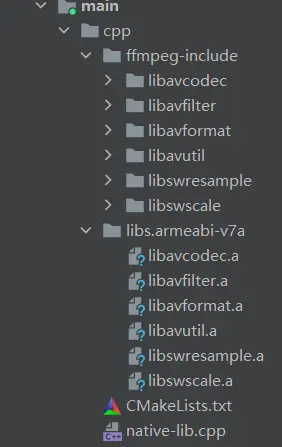
FFmpeg<第一篇>:环境配置
1、官网地址 http://ffmpeg.org/download.html2、linux下载ffmpeg 下载: wget https://ffmpeg.org/releases/ffmpeg-snapshot.tar.bz2解压: tar xvf ffmpeg-snapshot.tar.bz23、FFmpeg ./configure编译参数汇总 解压 ffmpeg-snapshot.tar.bz2 之后&…...

深度学习:Sigmoid函数与Sigmoid层区别
深度学习:Sigmoid函数与Sigmoid层 1. Sigmoid神经网络层 vs. Sigmoid激活函数 在深度学习和神经网络中,“Sigmoid” 是一个常见的术语,通常用来表示两个相关但不同的概念:Sigmoid激活函数和Sigmoid神经网络层。这两者在神经网络…...

❤ Ant Design Vue 2.28的使用
❤ Ant Design Vue 2.28 弹窗 //按钮 <a-button type"primary" click"showModal">Open Modal</a-button>//窗口 <a-modal v-model:visible"visible" title"Basic Modal" ok"handleOk"><p>Some con…...

R语言02-R语言中的向量
概念 在R语言中,向量(Vector)是最基本的数据结构之一,用于存储相同类型的多个元素。向量可以包含数值、字符、逻辑值等,但其中的所有元素必须具有相同的数据类型。向量可以通过c()函数创建,也可以通过其他…...

windows linux 都可执行的脚本 bat, shell 共存
核心, 执行一行解析一行 windows:执行的地方进行解析, 可以任意跳转执行; bash从上往下解析执行; 一行行解析发现语法错误; 差异: windows可以部分不解析; linux需要从上往下解析合法; 总结:linux, windows可以一上一下共存 # linux code# windows code 关键: 脚本解析的差…...
的完整用法)
别让拼写检查器坑了你的代码!Visual Studio中自定义排除字典(exclusion.dic)的完整用法
深度定制Visual Studio拼写检查:打造团队专属的exclusion.dic解决方案 当你在Visual Studio中看到熟悉的红色波浪线时,第一反应可能是代码出现了语法错误。但仔细一看,却发现是拼写检查器在提醒你"Hint"不是一个有效的英文单词。这…...

终极指南:3步掌握Path of Building装备规划与角色构建
终极指南:3步掌握Path of Building装备规划与角色构建 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/gh_mirrors/pat/PathOfBuilding Path of Building是一款强大的离线Build规划工具࿰…...

从用量看板分析月度API调用规律优化Token采购策略
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从用量看板分析月度API调用规律优化Token采购策略 在项目开发中,大模型API的调用成本是技术团队需要持续关注的重要指标…...

探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界
探索NVMe管理工具的未来:v2.12版本如何重新定义存储控制边界 【免费下载链接】nvme-cli NVMe management command line interface. 项目地址: https://gitcode.com/gh_mirrors/nv/nvme-cli NVMe-CLI作为现代NVMe固态存储设备的核心管理工具,在v2.…...

MCUXpresso for VS Code集成J-Link脚本的三种工程化方法详解
1. 项目概述:为什么要在IDE里折腾脚本?如果你是一位使用NXP MCU的嵌入式开发者,大概率对MCUXpresso IDE和SEGGER J-Link调试器这对黄金搭档不陌生。在传统的MCUXpresso IDE(基于Eclipse)里,通过图形界面配置…...

MAA明日方舟自动化工具技术解析:图像识别算法如何解放你的游戏时间
MAA明日方舟自动化工具技术解析:图像识别算法如何解放你的游戏时间 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址:…...

1951-2025年中国1km月平均气温逐年年内季节波动幅度数据集
中国1000米分辨率月平均气温数据集(1951-2025)提供了长时间序列、规则网格的气象背景信息,为开展气候变化分析和区域比较研究提供了基础数据支撑。针对原始月尺度序列直接使用不够便捷的问题,需要进一步形成具有明确主题和统一格式…...
)
Perplexity教育信息检索效率提升70%:从零到精通的4步优化法(附实测数据)
更多请点击: https://kaifayun.com 第一章:Perplexity教育信息检索效率提升70%:从零到精通的4步优化法(附实测数据) Perplexity 作为面向研究与教育场景的AI原生搜索引擎,其语义理解深度与引用溯源能力显著…...

B站视频转文字终极指南:如何快速将B站视频转换为可搜索文本
B站视频转文字终极指南:如何快速将B站视频转换为可搜索文本 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text Bili2Text是一款开源的B站视频转文字工…...

从QRegExp迁移到QRegularExpression避坑全记录:我们项目踩过的雷和最佳实践
从QRegExp迁移到QRegularExpression避坑全记录:我们项目踩过的雷和最佳实践 当团队决定将代码库从Qt4/Qt5升级到Qt6时,正则表达式模块的迁移往往是最容易被低估的挑战之一。我们项目组在重构过程中,曾因QRegExp到QRegularExpression的语法差异…...