16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors 示例:Elasticsearch
- 1、maven依赖(java编码依赖)
- 2、创建 Elasticsearch 表并写入数据
- 3、连接器参数
- 4、特性
- 1)、Key 处理
- 2)、动态索引
- 5、数据类型映射
- 二、Flink SQL示例:将kafka数据写入es
- 1、依赖环境
- 2、创建表并提交任务
- 3、验证
- 1)、创建es表
- 2)、创建kafka表
- 3)、提交任务
- 4)、创建kafkatopic
- 5)、往kafka topic中写入数据
- 6)、查看es中的数据
本文介绍了Elasticsearch连接器的使用,并以2个示例完成了外部系统是Elasticsearch的介绍,即使用datagen作为数据源写入Elasticsearch和kafka作为数据源写入Elasticsearch中。
本文依赖环境是Flink、kafka、Elasticsearch、hadoop环境好用,如果是ha环境则需要zookeeper的环境。
本文分为2个部分,即Elasticsearch的基本介绍及示例和Elasticsearch与kafka的使用示例。
一、Table & SQL Connectors 示例:Elasticsearch
Elasticsearch 连接器允许将数据写入到 Elasticsearch 引擎的索引中(不支持读取,截至1.17版本)。本文档描述运行 SQL 查询时如何设置 Elasticsearch 连接器。
连接器可以工作在 upsert 模式,使用 DDL 中定义的主键与外部系统交换 UPDATE/DELETE 消息。
如果 DDL 中没有定义主键,那么连接器只能工作在 append 模式,只能与外部系统交换 INSERT 消息。
1、maven依赖(java编码依赖)
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7</artifactId><version>3.0.1-1.17</version>
</dependency>
2、创建 Elasticsearch 表并写入数据
本示例的Elasticsearch是7.6,故需要Elasticsearch7的jar文件
flink-sql-connector-elasticsearch7_2.11-1.13.6.jar
CREATE TABLE source_table (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,WATERMARK FOR t_insert_time AS t_insert_time
) WITH ('connector' = 'datagen','rows-per-second'='5','fields.userId.kind'='sequence','fields.userId.start'='1','fields.userId.end'='5000','fields.balance.kind'='random','fields.balance.min'='1','fields.balance.max'='100','fields.age.min'='1','fields.age.max'='1000','fields.userName.length'='10'
);CREATE TABLE alan_flink_es_user_idx (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,PRIMARY KEY (userId) NOT ENFORCED
) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://192.168.10.41:9200,http://192.168.10.42:9200,http://192.168.10.43:9200','index' = 'alan_flink_es_user_idx'
);INSERT INTO alan_flink_es_user_idx
SELECT userId, age, balance , userName FROM source_table;---------------------具体操作如下-----------------------------------
Flink SQL> CREATE TABLE source_table (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING,
> t_insert_time AS localtimestamp,
> WATERMARK FOR t_insert_time AS t_insert_time
> ) WITH (
> 'connector' = 'datagen',
> 'rows-per-second'='5',
> 'fields.userId.kind'='sequence',
> 'fields.userId.start'='1',
> 'fields.userId.end'='5000',
>
> 'fields.balance.kind'='random',
> 'fields.balance.min'='1',
> 'fields.balance.max'='100',
>
> 'fields.age.min'='1',
> 'fields.age.max'='1000',
>
> 'fields.userName.length'='10'
> );
[INFO] Execute statement succeed.Flink SQL>
>
> CREATE TABLE alan_flink_es_user_idx (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING,
> t_insert_time AS localtimestamp,
> PRIMARY KEY (userId) NOT ENFORCED
> ) WITH (
> 'connector' = 'elasticsearch-7',
> 'hosts' = 'http://192.168.10.41:9200,http://192.168.10.42:9200,http://192.168.10.43:9200',
> 'index' = 'alan_flink_es_user_idx'
> );
[INFO] Execute statement succeed.Flink SQL>
>
> INSERT INTO alan_flink_es_user_idx
> SELECT userId, age, balance , userName FROM source_table;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 1163eb7a404c2678322adaa89409bcda
-----由于es的表不支持source,故不能查询,查询会报如下错误----
Flink SQL> select * from alan_flink_es_user_idx;
[ERROR] Could not execute SQL statement. Reason:
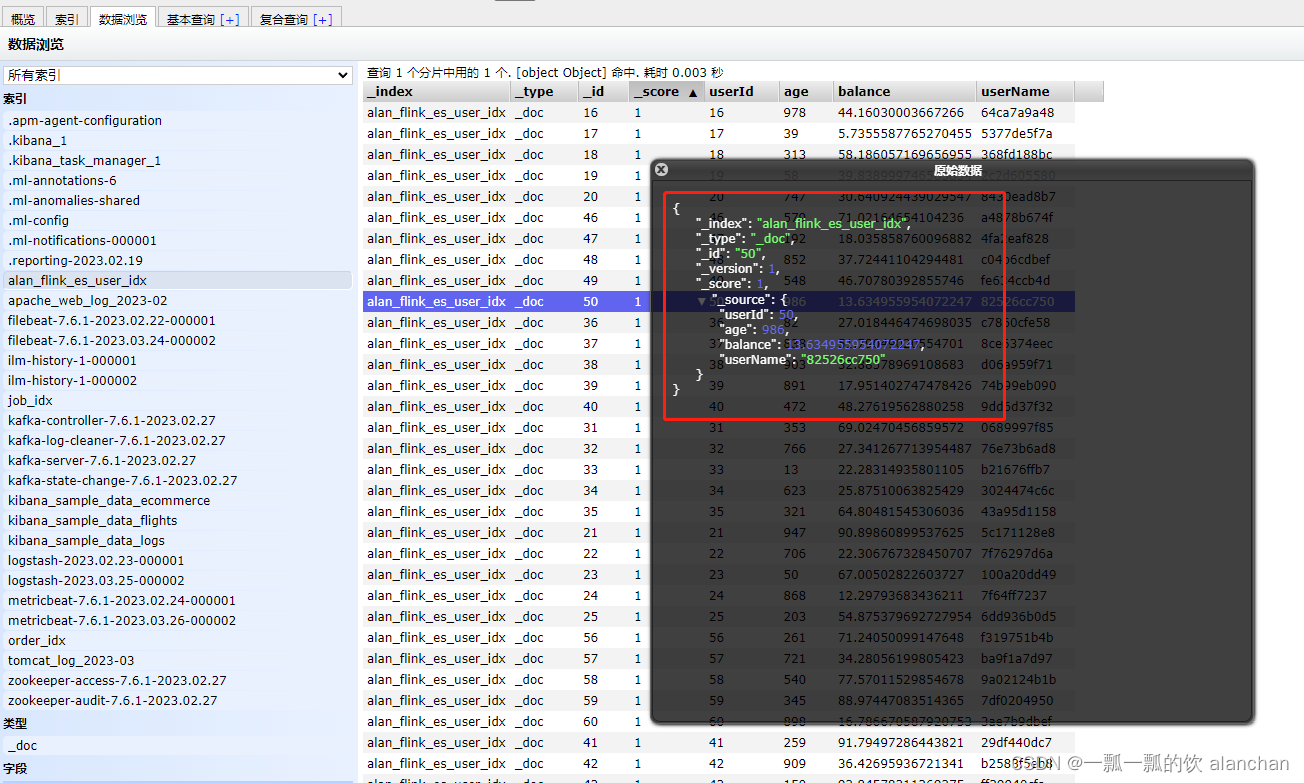
org.apache.flink.table.api.ValidationException: Connector 'elasticsearch-7' can only be used as a sink. It cannot be used as a source.Elasticsearch结果如下图
3、连接器参数

4、特性
1)、Key 处理
Elasticsearch sink 可以根据是否定义了一个主键来确定是在 upsert 模式还是 append 模式下工作。 如果定义了主键,Elasticsearch sink 将以 upsert 模式工作,该模式可以消费包含 UPDATE/DELETE 消息的查询。 如果未定义主键,Elasticsearch sink 将以 append 模式工作,该模式只能消费包含 INSERT 消息的查询。
在 Elasticsearch 连接器中,主键用于计算 Elasticsearch 的文档 id,文档 id 为最多 512 字节且不包含空格的字符串。 Elasticsearch 连接器通过使用 document-id.key-delimiter 指定的键分隔符按照 DDL 中定义的顺序连接所有主键字段,为每一行记录生成一个文档 ID 字符串。 某些类型不允许作为主键字段,因为它们没有对应的字符串表示形式,例如,BYTES,ROW,ARRAY,MAP 等。 如果未指定主键,Elasticsearch 将自动生成文档 id。
有关 PRIMARY KEY 语法的更多详细信息,请参见 22、Flink 的table api与sql之创建表的DDL。
2)、动态索引
Elasticsearch sink 同时支持静态索引和动态索引。
如果你想使用静态索引,则 index 选项值应为纯字符串,例如 ‘myusers’,所有记录都将被写入到 “myusers” 索引中。
如果你想使用动态索引,你可以使用 {field_name} 来引用记录中的字段值来动态生成目标索引。 你也可以使用 ‘{field_name|date_format_string}’ 将 TIMESTAMP/DATE/TIME 类型的字段值转换为 date_format_string 指定的格式。 date_format_string 与 Java 的 DateTimeFormatter 兼容。 例如,如果选项值设置为 ‘myusers-{log_ts|yyyy-MM-dd}’,则 log_ts 字段值为 2020-03-27 12:25:55 的记录将被写入到 “myusers-2020-03-27” 索引中。
你也可以使用 ‘{now()|date_format_string}’ 将当前的系统时间转换为 date_format_string 指定的格式。now() 对应的时间类型是 TIMESTAMP_WITH_LTZ 。 在将系统时间格式化为字符串时会使用 session 中通过 table.local-time-zone 中配置的时区。 使用 NOW(), now(), CURRENT_TIMESTAMP, current_timestamp 均可以。
使用当前系统时间生成的动态索引时, 对于 changelog 的流,无法保证同一主键对应的记录能产生相同的索引名, 因此使用基于系统时间的动态索引,只能支持 append only 的流。
5、数据类型映射
Elasticsearch 将文档存储在 JSON 字符串中。因此数据类型映射介于 Flink 数据类型和 JSON 数据类型之间。 Flink 为 Elasticsearch 连接器使用内置的 ‘json’ 格式。更多类型映射的详细信息,请参阅 35、Flink 的JSON Format。
二、Flink SQL示例:将kafka数据写入es
本示例是将kafka的数据通过Flink 的任务写入es中。
1、依赖环境
需要增加kafka和es相关的jar包,本示例用到如下:
flink-sql-connector-elasticsearch7_2.11-1.13.6.jar
flink-sql-connector-kafka_2.11-1.13.5.jar
2、创建表并提交任务
在flink sql中运行
CREATE TABLE alan_flink_es_kafka_user_idx (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,PRIMARY KEY (userId) NOT ENFORCED
) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://192.168.10.41:9200','index' = 'alan_flink_es_kafka_user_idx_test'
);CREATE TABLE alanchan_kafka_table (`id` INT,name STRING,age INT,balance DOUBLE,ts BIGINT, -- 以毫秒为单位的时间t_insert_time AS TO_TIMESTAMP_LTZ(ts,3),WATERMARK FOR t_insert_time AS t_insert_time - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列上定义 watermark
) WITH ('connector' = 'kafka','topic' = 't_kafkasource2','scan.startup.mode' = 'earliest-offset','properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format' = 'csv'
);INSERT INTO alan_flink_es_kafka_user_idx
SELECT id, age, balance , name FROM alanchan_kafka_table;
3、验证
本示例没有特别说明,则是在flink sql cli中操作,kafka则是kafka的运行环境命令。
1)、创建es表
Flink SQL> CREATE TABLE alan_flink_es_kafka_user_idx (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING,
> t_insert_time AS localtimestamp,
> PRIMARY KEY (userId) NOT ENFORCED
> ) WITH (
> 'connector' = 'elasticsearch-7',
> 'hosts' = 'http://192.168.10.41:9200',
> 'index' = 'alan_flink_es_kafka_user_idx_test'
> );
[INFO] Execute statement succeed.2)、创建kafka表
Flink SQL> CREATE TABLE alanchan_kafka_table (
> `id` INT,
> name STRING,
> age INT,
> balance DOUBLE,
> ts BIGINT, -- 以毫秒为单位的时间
> t_insert_time AS TO_TIMESTAMP_LTZ(ts,3),
> WATERMARK FOR t_insert_time AS t_insert_time - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列上定义 watermark
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 't_kafkasource2',
> 'scan.startup.mode' = 'earliest-offset',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.3)、提交任务
Flink SQL> INSERT INTO alan_flink_es_kafka_user_idx
> SELECT id, age, balance , name FROM alanchan_kafka_table;
........
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: dc19c9b904f69985d40eca372af9553a4)、创建kafkatopic
[alanchan@server3 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic t_kafkasource2 --partitions 1 --replication-factor 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic t_kafkasource2.>5)、往kafka topic中写入数据
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource2
>1,alan,15,100,1692593500222
>2,alanchan,20,200,1692593501230
>3,alanchanchn,25,300,1692593502242
>4,alan_chan,30,400,1692593503256
>5,alan_chan_chn,500,45,1692593504270
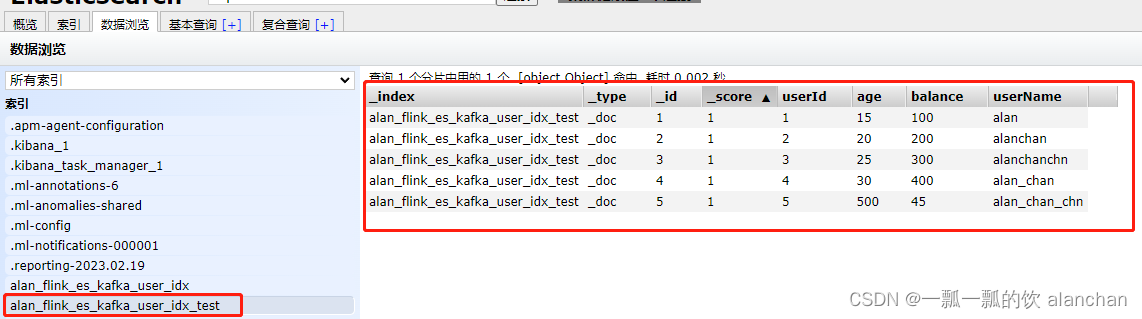
>6)、查看es中的数据
以上,完成了外部系统是Elasticsearch的介绍,使用了2个示例,即使用datagen作为数据源写入Elasticsearch和kafka作为数据源写入Elasticsearch中。
相关文章:
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

Java代码优化案例2:使用HashMap代替List进行数据查找
在开发过程中,我们经常需要在一个集合中查找某个元素。一种常见的做法是使用List来存储数据,然后通过循环遍历List来查找目标元素。然而,当数据量较大时,这种做法效率较低。我们可以通过使用HashMap来优这个过程。 1. 原始代码实…...
每天一道leetcode:542. 01 矩阵(图论中等广度优先遍历)
今日份题目: 给定一个由 0 和 1 组成的矩阵 mat ,请输出一个大小相同的矩阵,其中每一个格子是 mat 中对应位置元素到最近的 0 的距离。 两个相邻元素间的距离为 1 。 示例1 输入:mat [[0,0,0],[0,1,0],[0,0,0]] 输出ÿ…...

SQL SERVER 日期函数相关内容
最近跟日期相关的内容杠上了,为方便自己后期查阅,特地做笔记。 DECLARE chanenddate datetime----截止日期转成当天的年月日尾巴 DECLARE chanbengindate datetime----开始日期转成当天的年月日0000000 截取日期的 年月日,字符串类型 co…...

多维时序 | MATLAB实现SCNGO-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现SCNGO-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现SCNGO-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现SCNGO-BiGRU-Attention多变量时间序列预测。 模型描述…...
)
从零开始学习 Java:简单易懂的入门指南之JDK8时间相关类(十八)
JDK8时间相关类 JDK8时间相关类1.1 ZoneId 时区1.2 Instant 时间戳1.3 ZoneDateTime 带时区的时间1.4DateTimeFormatter 用于时间的格式化和解析1.5LocalDate 年、月、日1.6 LocalTime 时、分、秒1.7 LocalDateTime 年、月、日、时、分、秒1.8 Duration 时间间隔(秒…...
)
Spring Boot实践八--用户管理系统(下)
step3:多线程task 首先,实现两个UserService和AsyncUserService两个服务接口: 接口: package com.example.demospringboot.service;public interface UserService {void checkUserStatus(); }package com.example.demospringbo…...
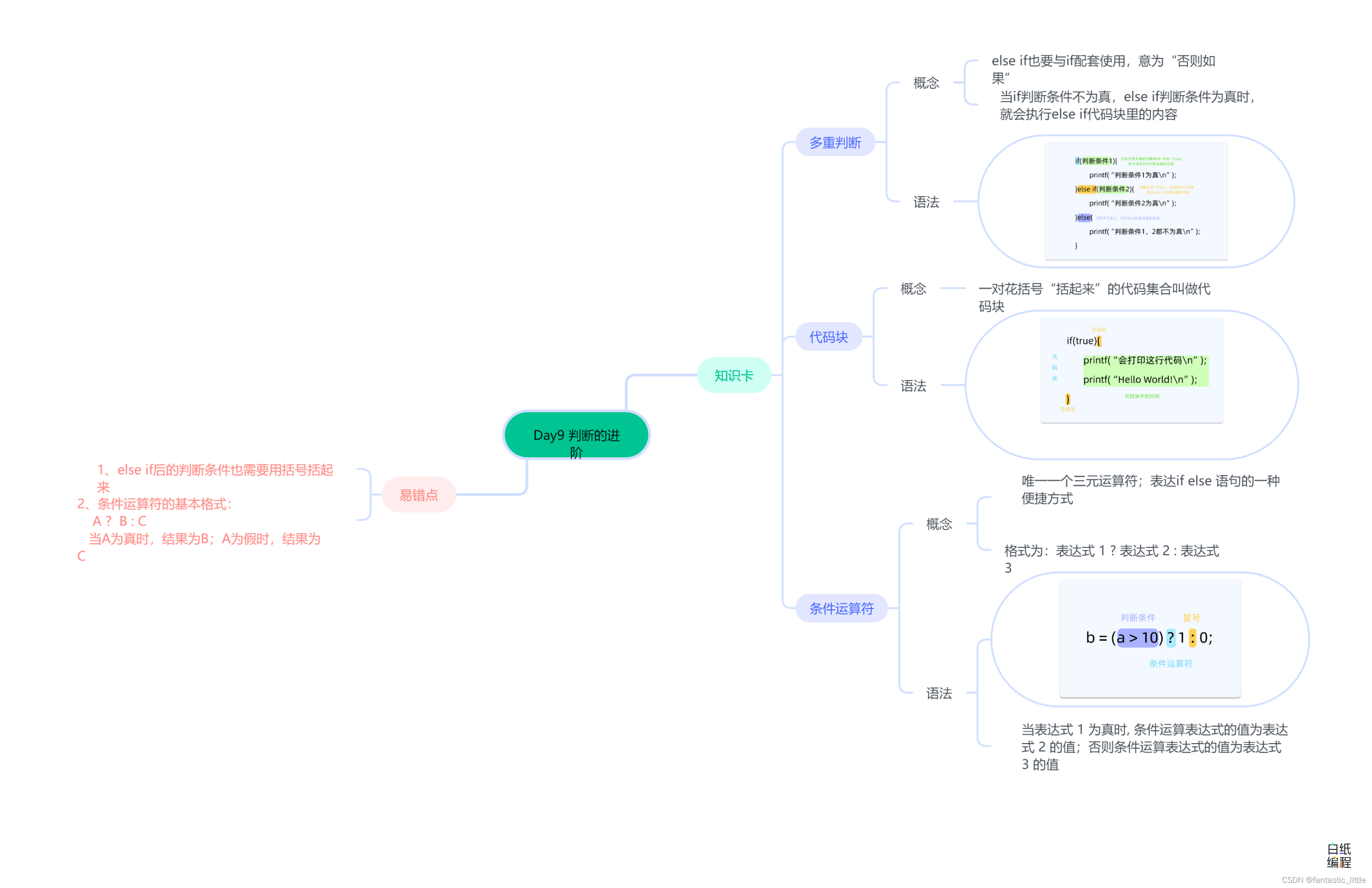
C语言入门 Day_10 判断的进阶
目录 前言 1.多重判断 2.代码块 3.条件运算符 3.易错点 4.思维导图 前言 if和else能够处理两种不同的情况,如果(if)满足条件,我们就执行这几行代码;否则(else)的话,我们就执行…...
)
机器学习基础13-基于集成算法优化模型(基于印第安糖尿病 Pima Indians数据集)
有时提升一个模型的准确度很困难。如果你曾纠结于类似的问题,那 我相信你会同意我的看法。你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善。这时你会觉得无助和困顿,这也是 90%的数据科学家开始放弃的时候。不过,这才是…...

Rancher部署k8s集群
Rancher部署 Rancher是一个开源的企业级容器管理平台。通过Rancher,企业再也不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用的管理Docker和Kubernetes的全栈化容器部署与管理平台。 首先所有节点部署docker 安装docker 安…...

前端油猴脚本开发小技巧笔记
调试模式下,单击选中某dom代码,控制台里可以用$0访问到该dom对象。 $0.__vue___ 可以访问到该dom对应的vue对象。 jquery 对象 a,a[0]是对应的原生dom对象,$(原生对象) 得到对应的 jquery 对象。 jquery 选择器,加空格是匹配下…...

软考高级系统架构设计师系列之:搭建论文写作的万能模版
软考高级系统架构设计师系列之:搭建论文写作的万能模版 一、选择合适的模版二、论文摘要模版1.论文摘要模版一2.论文摘要模版二3.论文摘要模版三4.论文摘要模版四三、项目背景四、正文写作五、论文结尾六、论文万能模版一、选择合适的模版 选择中、大型商业项目,一般金额在2…...

多线程常见面试题
常见的锁策略 这里讨论的锁策略,不仅仅局限于 Java 乐观锁 vs 悲观锁 锁冲突: 两个线程尝试获取一把锁,一个线程能获取成功,另一个线程阻塞等待。 乐观锁: 预该场景中,不太会出现锁冲突的情况。后续做的工作会更少。 悲观锁: 预测该场景,非常容易出现锁冲突。后…...

Java接收json参数
JSON 并不是唯一能够实现在互联网中传输数据的方式,除此之外还有一种 XML 格式。JSON 和 XML 能够执行许多相同的任务,那么我们为什么要使用 JSON,而不是 XML 呢? 之所以使用 JSON,最主要的原因是 JavaScript。众所周知…...

赤峰100吨每天医院污水处理设备产品特点
赤峰100吨每天医院污水处理设备产品特点 设备调试要求: 1、要清洗水池内所有的赃物、杂物。 2、对水泵及空压机等需要润滑部位进行加油滑。 3、通电源,启动水泵,检查转向是否与箭头所标方向一致。用水动控制启动空压机,检查空压机…...

nodejs+vue+elementui健身房教练预约管理系统nt5mp
运用新技术,构建了以vue.js为基础的私人健身和教练预约管理信息化管理体系。根据需求分析结果进行了系统的设计,并将其划分为管理员,教练和用户三种角色:主要功能包括首页,个人中心,用户管理,教…...
视频分割合并工具说明
使用说明书:视频分割合并工具 欢迎使用视频生成工具!本工具旨在帮助您将视频文件按照指定的规则分割并合并,以生成您所需的视频。 本程序还自带提高分辨率1920:1080,以及增加10db声音的功能 软件下载地址 https://github.com/c…...

2023java面试深入探析Nginx的处理流程
推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 史上最全文档AI绘画stablediffusion资料分享 「java、python面试题」来自UC网盘app分享,打开手…...
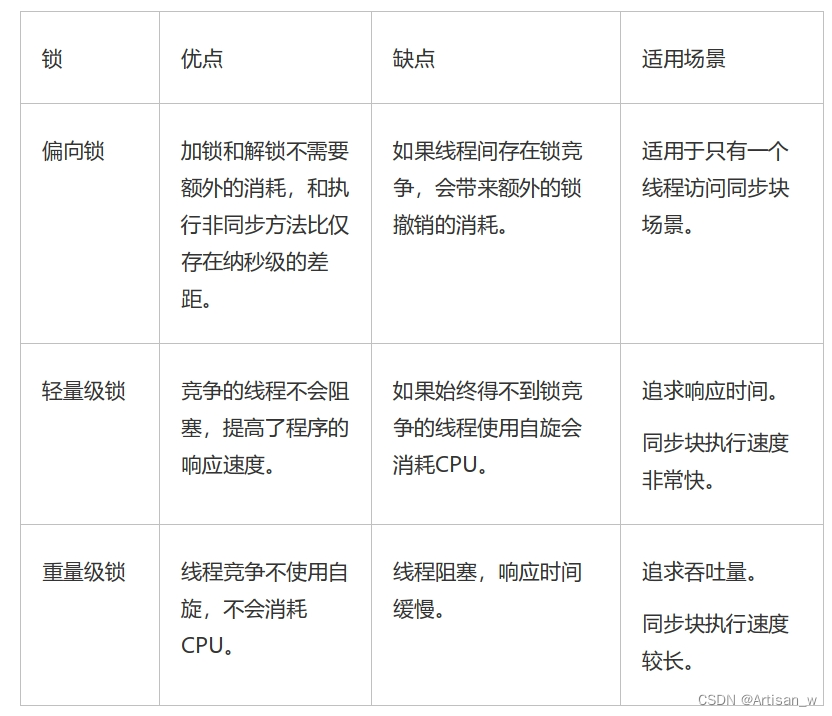
Java的锁大全
Java的锁 各种锁的类型 乐观锁 VS 悲观锁 乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在Java和数据库中都有此概念对应的实际应用。 先说概念。对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数…...

Leetcode80. 删除有序数组中的重复项 II
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。 class Solu…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

第三卷第4章:原型模式设计思想
第三卷第4章:原型模式设计思想 目录介绍 01.案例引入与思考 1.1 痛点场景 1.2 它哪里不舒服 1.3 引出本篇主角 02.原型模式介绍 2.1 原型模式由来 2.2 原型模式定义...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...

基于Jetson Nano与JNEEG Shield的脑电信号采集与边缘AI处理实战
1. 项目概述:低成本脑机接口的硬件基石 如果你对脑机接口、生物信号处理或者边缘AI应用感兴趣,但又苦于专业设备动辄数万甚至数十万的高昂门槛,那么JNEEG Shield的出现,可能会为你打开一扇新的大门。这是一个专为NVIDIA Jetson Na…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...