【云原生】Docker的数据管理(数据卷、容器互联)
目录
一、数据卷(容器与宿主机之间数据共享)
二、数据卷容器(容器与容器之间数据共享)
三、 容器互联(使用centos镜像)
总结
用户在使用Docker的过程中,往往需要能查看容器内应用产生的数据,或者需要把容器内的数据进行备份,甚至多个容器之间进行数据的共享,这必然涉及容器的数据管理操作。
容器中管理数据主要有两种方式:
- 数据卷(Data Volumes)
- 数据卷容器(Data Volume Dontainers)
一、数据卷(容器与宿主机之间数据共享)
数据卷是一个供容器使用的特殊目录,位于容器中。可将宿主机的目录挂载到数据卷上,对数据卷的修改操作立刻可见,并且更新数据不会影响镜像,从而实现数据在宿主机与容器之间的迁移。数据卷的使用类似于Linux下对目录进行的mount操作。
想要将容器中的数据持久化,可以将宿主机目录挂载到容器中。
一般只建议在创建容器时进行挂载,不建议启动容器后再挂载。因为启动容器后再挂载的话,需要修改配置文件,且不一定能挂载成功。
docker run -v 数据卷 #在容器内创建数据卷docker run -v 宿主机目录:数据卷 #将宿主机目录挂载到容器中#注意:宿主机本地目录的路径必须是使用绝对路径。如果路径不存在,Docker会自动创建相应的路径。#挂载后的目录默认可读可写#如果希望挂载后的目录为只读目录,可以在挂载时加:ro参数docker run -v 宿主机目录:数据卷:ro #将宿主机目录挂载到容器中,只可读
示例:
[root@yuji ~]# ls /var/share #创建数据卷前,该目录不存在ls: 无法访问/var/share: 没有那个文件或目录#将宿主机目录/var/share挂载到容器中的/data1。#注意:宿主机本地目录的路径必须是使用绝对路径。如果路径不存在,Docker会自动创建相应的路径。#-v选项可以在容器内创建数据卷[root@yuji ~]# docker run -v /var/share:/data1 --name web1 -itd centos:7 /bin/bash670bf71814364638c4b21a1fb13bcf95c6a2125cd379a5717061d41f9673b0fe[root@yuji ~]# ls /var/share -d #自动创建了该目录/var/share#进入容器[root@yuji ~]# docker exec -it web1 bash [root@670bf7181436 /]# ls #容器中自动创建了/data1目录anaconda-post.log data1 etc lib media opt root sbin sys usrbin dev home lib64 mnt proc run srv tmp var[root@670bf7181436 /]# echo "this is web1"> /data1/abc.txt #向数据卷中写入数据[root@670bf7181436 /]# exit #退出容器exit#返回宿主机进行查看[root@yuji ~]# cd /var/share[root@yuji share]# lsabc.txt[root@yuji share]# cat abc.txt #可以看到容器中写入的数据,数据同步成功this is web1#在宿主机目录中写入数据,之后进容器中查看[root@yuji share]# cp /etc/passwd ./[root@yuji share]# lsabc.txt passwd[root@yuji share]# docker exec -it web1 bash #进入容器[root@670bf7181436 /]# ls /data1 abc.txt passwd #完成了数据同步


二、数据卷容器(容器与容器之间数据共享)
如果需要在容器之间共享一些数据,最简单的方法就是使用数据卷容器。数据卷容器是一个普通的容器,专门提供数据卷给其他容器挂载使用。
#创建数据卷容器web2。创建/data1和/data2两个数据卷。docker run --name web2 -v /data1 -v /data2 -itd centos:7docker exec -it web2 bash #进入web2容器echo "this is web2" > /data1/aaa.txt #向数据卷/data1中写入数据echo "this is yuji" > /data2/bbb.txt #向数据卷/data2中写入数据#使用--volumes-from 来挂载web2容器中的数据卷到新的容器web3docker run -itd --volumes-from web2 --name web3 centos:7docker exec -it web3 bash #进入web3容器cat /data1/aaa.txt #查看/data1中的数据是否和web2一致cat /data2/bbb.txt #查看/data2中的数据是否和web2一致


#在容器web3的挂载目录中写入数据,观察web2中能否同步成功[root@e99ee4f80519 /]# echo "this is web3" > /data1/web3.txt[root@e99ee4f80519 /]# exitexit[root@yuji ~]# docker exec -it web2 bash #进入容器web2[root@146f1012bc08 /]# cat /data1/web3.txt #数据共享成功this is web3

三、 容器互联(使用centos镜像)
容器互联是通过容器的名称在容器间建立一条专门的网络通信隧道。简单点说,就是会在源容器和接收容器之问建立一条隧道,接收容器可以看到源容器指定的信息。
示例1:做容器互联
#创建并运行源容器取名c1docker run -itd -P --name c1 centos:7 /bin/bash#创建并运行接收容器取名c2,使用--1ink选项指定连接容器c1以实现容器互联。docker run -itd -P --name c2 --link c1:C1 centos:7 /bin/bash##--link 容器名:连接的别名#进c2容器,ping c1,通过容器名称或者别名都可以通信docker exec -it c2 bashping c1 #ping c1容器名称ping C1 #ping c1容器的别名PING C1 (172.17.0.5) 56(84) bytes of data.64 bytes from C1 (172.17.0.5): icmp_seq=1 ttl=64 time=0.105 ms64 bytes from C1 (172.17.0.5): icmp_seq=2 ttl=64 time=0.066 ms#可以看到c1容器的IP地址为172.17.0.5#进入c1容器,查看c1的IP地址docker exec -it c1 bashyum install -y net-tools #下载网络工具ifconfig #查看IP为172.17.0.5,和c2中显示的一致eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 172.17.0.5 netmask 255.255.0.0 broadcast 172.17.255.255



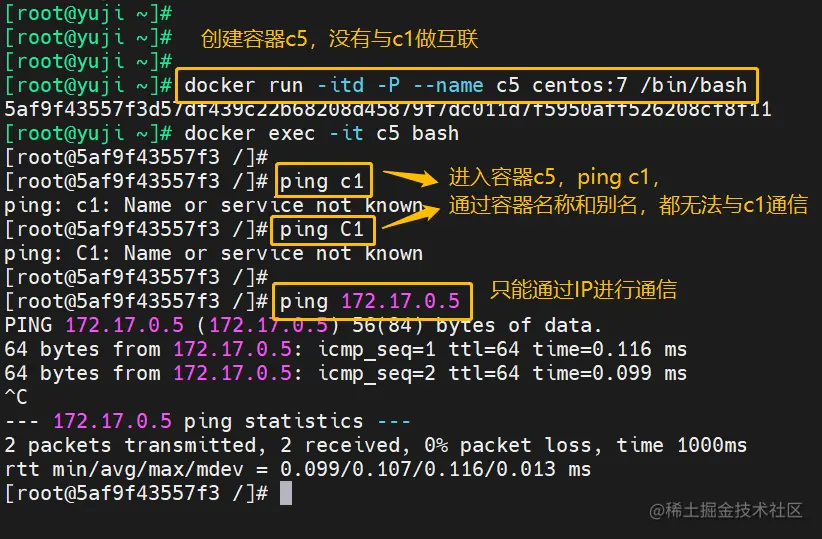
示例2:如果不做互联的话只能通过IP进行通信
#创建容器c5,没有与c1做互联docker run -itd -P --name c5 centos:7 /bin/bashdocker exec -it c5 bash #进入容器c5#通过c1的容器名称和别名,都无法和c1通信ping c1 #提示:ping: c1: Name or service not knownping C1 #提示:ping: C1: Name or service not known#只能通过IP进行通信ping 172.17.0.5
总结
本文介绍了通过数据卷和数据卷容器对容器内数据进行共享、备份和恢复等操作,通过这些机制,即使容器在运行中出现故障,用户也不必担心数据发生丢失,只需要快速地重新创建容器即可。
| 命令 | 说明 |
|---|---|
| docker run -v 宿主机目录:数据卷 | 将宿主机目录挂载到容器中 |
| docker run -v 数据卷 | 创建数据卷容器 |
| docker run --volumes-from 数据卷容器 | 挂载数据卷容器(挂载点路径不变) |
| docker run --link 源容器名称:别名 | 容器互联 |
注意:一般只建议在创建容器时进行挂载,不建议启动容器后再挂载。
因为启动容器后再挂载的话,需要修改配置文件,且不一定能挂载成功。
相关文章:
【云原生】Docker的数据管理(数据卷、容器互联)
目录 一、数据卷(容器与宿主机之间数据共享) 二、数据卷容器(容器与容器之间数据共享) 三、 容器互联(使用centos镜像) 总结 用户在使用Docker的过程中,往往需要能查看容器内应用产生的数据…...
使用vlc在线播放rtsp视频url
1. 2. 3. 工具链接: https://download.csdn.net/download/qq_43560721/88249440...
copy is all you need前向绘图 和疑惑标记
疑惑的起因 简化前向图 GPT4解释 这段代码实现了一个神经网络模型,包含了BERT、GPT-2和MLP等模块。主要功能是给定一个文本序列和一个查询序列,预测查询序列中的起始和结束位置,使其对应文本序列中的一个短语。具体实现细节如下:…...

【附安装包】Vred2023安装教程
软件下载 软件:Vred版本:2023语言:简体中文大小:2.39G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.0GHz 内存4G(或更高)下载通道①百度网盘丨64位下载链接:https://pan.baidu.com…...

ASP.NET Core 中的 Dependency injection
依赖注入(Dependency Injection,简称DI)是为了实现各个类之间的依赖的控制反转(Inversion of Control,简称IoC )。 ASP.NET Core 中的Controller 和 Service 或者其他类都支持依赖注入。 依赖注入术语中&a…...

优化物料编码规则,提升物料管理效率
导 读 ( 文/ 2358 ) 物料是生产过程的必需品。对物料进行身份的唯一标识,可以更好的管理物料库存、库位,更方便的对物料进行追溯。通过编码规则的设计,可以对物料按照不同的属性、类别或特征进行分类,从而更好地进行库存分析、计划…...
Jetbrains IDE新UI设置前进/后退导航键
背景 2023年6月,Jetbrains在新发布的IDE(Idea、PyCharm等)中开放了新UI选项,我们勾选后重启IDE,便可以使用这一魔性的UI界面了。 但是前进/后退这对常用的导航键却找不到了,以前的设置方式(Vi…...
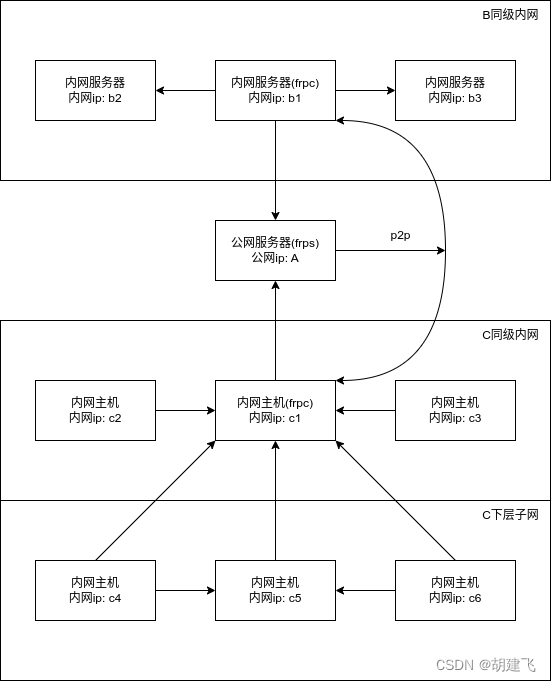
借助frp的xtcp+danted代理打通两边局域网p2p方式访问
最终效果 实现C内网所有设备借助c1内网代理访问B内网所有服务器 配置公网服务端A frps 配置frps.ini [common] # 绑定frp穿透使用的端口 bind_port 7000 # 使用token认证 authentication_method token token xxxx./frps -c frps.ini启动 配置service自启(可选) /etc/…...

2023年高教社杯数学建模思路 - 案例:FPTree-频繁模式树算法
文章目录 算法介绍FP树表示法构建FP树实现代码 建模资料 ## 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模式树算法,…...

批量根据excel数据绘制饼状图
要使用Python批量根据Excel数据绘制饼状图,可以使用pandas和matplotlib库来实现。以下是一个基本的代码示例: import pandas as pd import matplotlib.pyplot as plt # 读取Excel文件 data pd.read_excel(data.xlsx) # 提取需要用于绘制饼状图的数据列…...

C++头文件和std命名空间
C 是在C语言的基础上开发的,早期的 C 还不完善,不支持命名空间,没有自己的编译器,而是将 C 代码翻译成C代码,再通过C编译器完成编译。 这个时候的 C 仍然在使用C语言的库,stdio.h、stdlib.h、string.h 等头…...

浏览器有哪几种缓存?各种缓存之间的优先级
在浏览器中,有以下几种常见的缓存: 1、强制缓存:通过设置 Cache-Control 和 Expires 等响应头实现,可以让浏览器直接从本地缓存中读取资源而不发起请求。2、协商缓存:通过设置 Last-Modified 和 ETag 等响应头实现&am…...
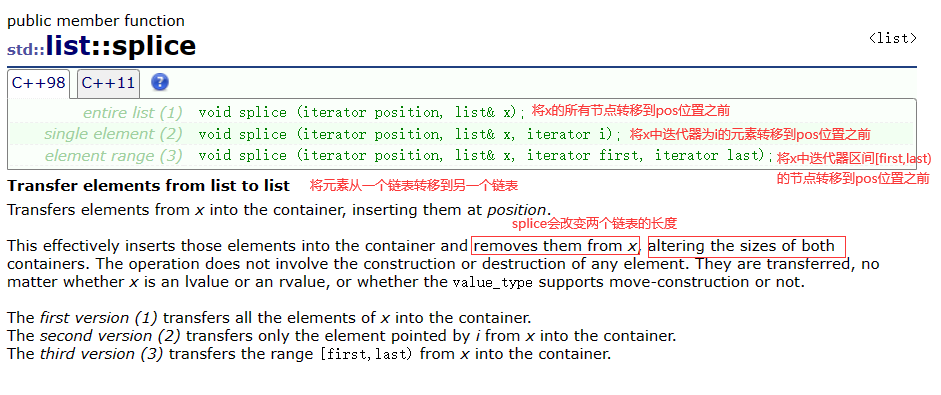
【C++】list
list 1. 简单了解list2. list的常见接口3. 简单实现list4. vector和list比较 1. 简单了解list list的底层是带头双向循环列表。因此list支持任意位置的插入和删除,且效率较高。但其缺陷也很明显,由于各节点在物理空间是不连续的,所以不支持对…...

剪枝基础与实战(2): L1和L2正则化及BatchNormalization讲解
1. CIFAR10 数据集 CIFAR10 是深度学习入门最先接触到的数据集之一,主要用于图像分类任务中,该数据集总共有10个类别。 图片数量:6w 张图片宽高:32x32图片类别:10Trainset: 5w 张,5 个训练块Testset: 1w 张,1 个测试块Pytorch 集成了很多常见数据集的API, 可以通过py…...

C语言学习笔记---指针进阶01
C语言程序设计笔记---016 C语言指针进阶前篇1、字符指针2、指针数组2.1、指针数组例程1 -- 模拟一个二维数组2.2、指针数组例程2 3、数组指针3.1、回顾数组名?3.2、数组指针定义与初始化(格式)3.3、数组指针的作用 --- 常用于二维数组3.4、数…...

【Go 基础篇】Go 语言字符串函数详解:处理字符串进阶
大家好!继续我们关于Go语言中字符串函数的探索。字符串是编程中常用的数据类型,而Go语言为我们提供了一系列实用的字符串函数,方便我们进行各种操作,如查找、截取、替换等。在上一篇博客的基础上,我们将继续介绍更多字…...

GAN原理 代码解读
模型架构 代码 数据准备 import os import time import matplotlib.pyplot as plt import numpy as np import torchvision.transforms as transforms from torch.utils.data import DataLoader from torchvision import datasets import torch.nn as nn import torch# 创建文…...
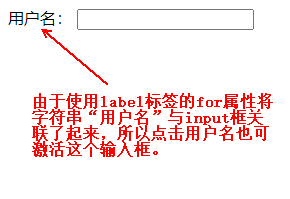
HTML的label标签有什么用?
当你想要将表单元素(如输入框、复选框、单选按钮等)与其描述文本关联起来,以便提供更好的用户界面和可访问性时,就可以使用HTML中的<label>标签。<label>标签用于为表单元素提供标签或标识,使用户能够更清…...
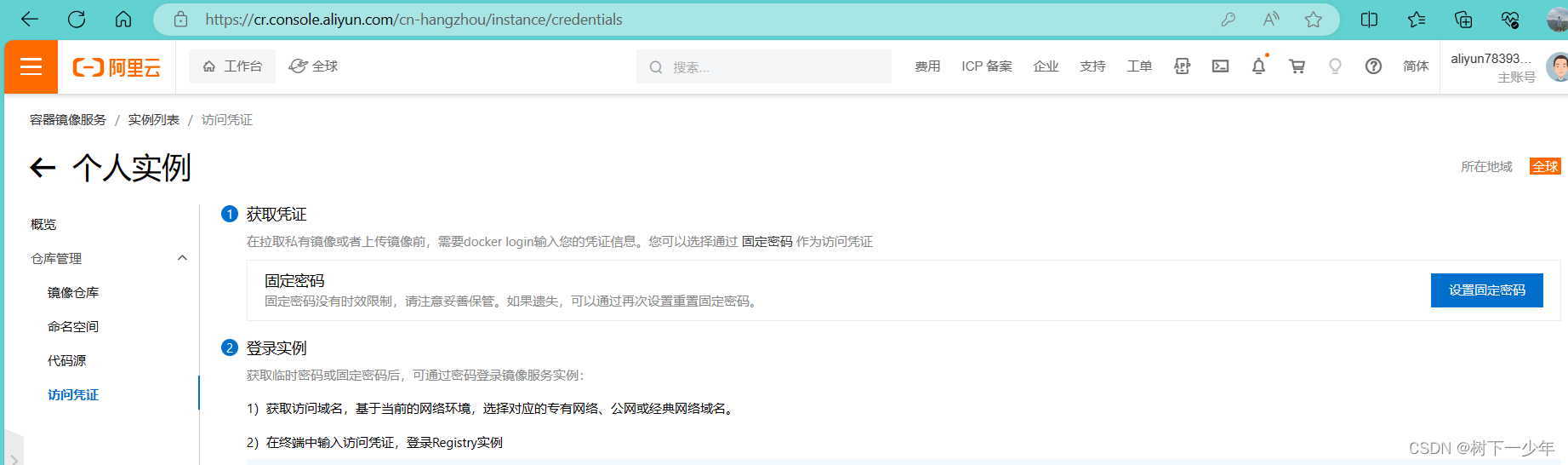
docker在阿里云上的镜像仓库管理
目录 一.登录进入阿里云网站,点击个人实例进行创建 二.创建仓库,填写相关信息 三.在访问凭证中设置固定密码用于登录,登录时用户名是使用你注册阿里云的账号名称,密码使用设置的固定密码 四.为镜像打标签并推送到仓库 五.拉取…...

html-dom核心内容--四要素
1、结构 HTML DOM (文档对象模型) 当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。 2、核心关注的内容:“元素”,“属性”,“修改样式”,“事件反应”。>四要素…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

服务器日志分析实战:用Python追踪HTTP 404错误并可视化异常频率
作为一名爬虫开发者或网站运维人员,服务器日志就像飞机的“黑匣子”——它记录了每个请求的来龙去脉。而404错误(页面未找到)尤其值得关注:它可能是用户输错了网址,可能是你爬虫的URL构造逻辑有漏洞,也可能是网站改版后旧的链接失效了。更严重的是,大量突然涌出的404请求…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...

英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南
英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟旧…...