cuml机器学习GPU库 sklearn升级版AutoDL使用
CUML库
最近在做机器学习任务的时候发现我自己的数据集太大,直接用sklearn 跑起来时间很长,然后问GPT得知了有CUML库,后来去研究了一下,发现这个库只支持linux系统,从官网直接获取下载命令基本上也实现不了最后,选择使用AutoDL租了一个GPU来安装这个库。具体步骤如下。
如果是正常讨论的话本身电脑就是liunx系统,按照道理说,直接去下面的官网链接去过去下载指令就可以了。进去之后的界面如下,反正我是没有成功,单我看似乎别人都是这吗做的,所以姑且把链接贴上。
链接: https://docs.rapids.ai/install#prerequisites
安装
接下啦是我的方法,首先进入AutoDL官网
链接: https://www.autodl.com/home
点击右上角的控制台
点击左侧的实例容器
点击租用新的实例
选择一个带GPU的设备
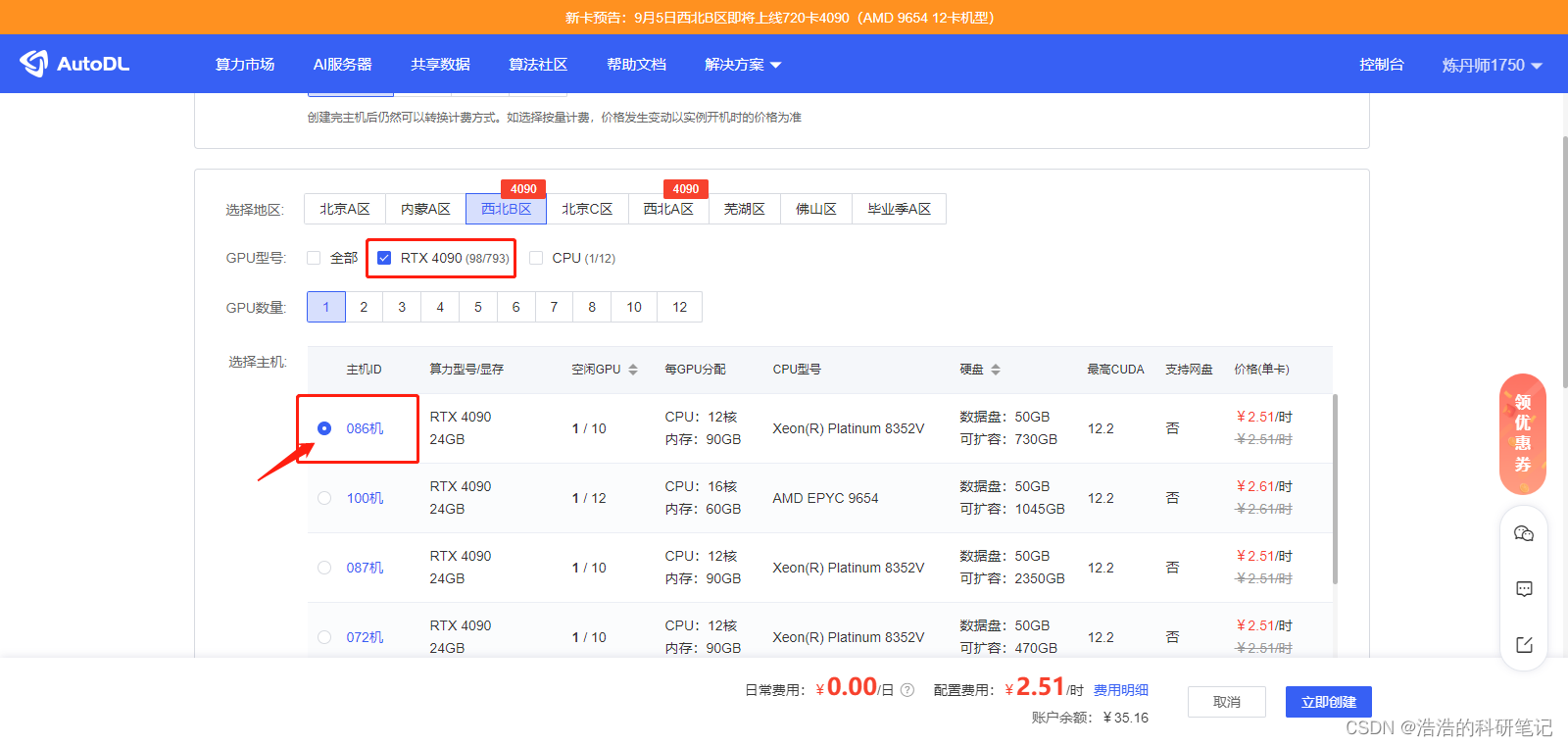
滑到最底部然后选择框架,以及cuda版本

点击立即创建
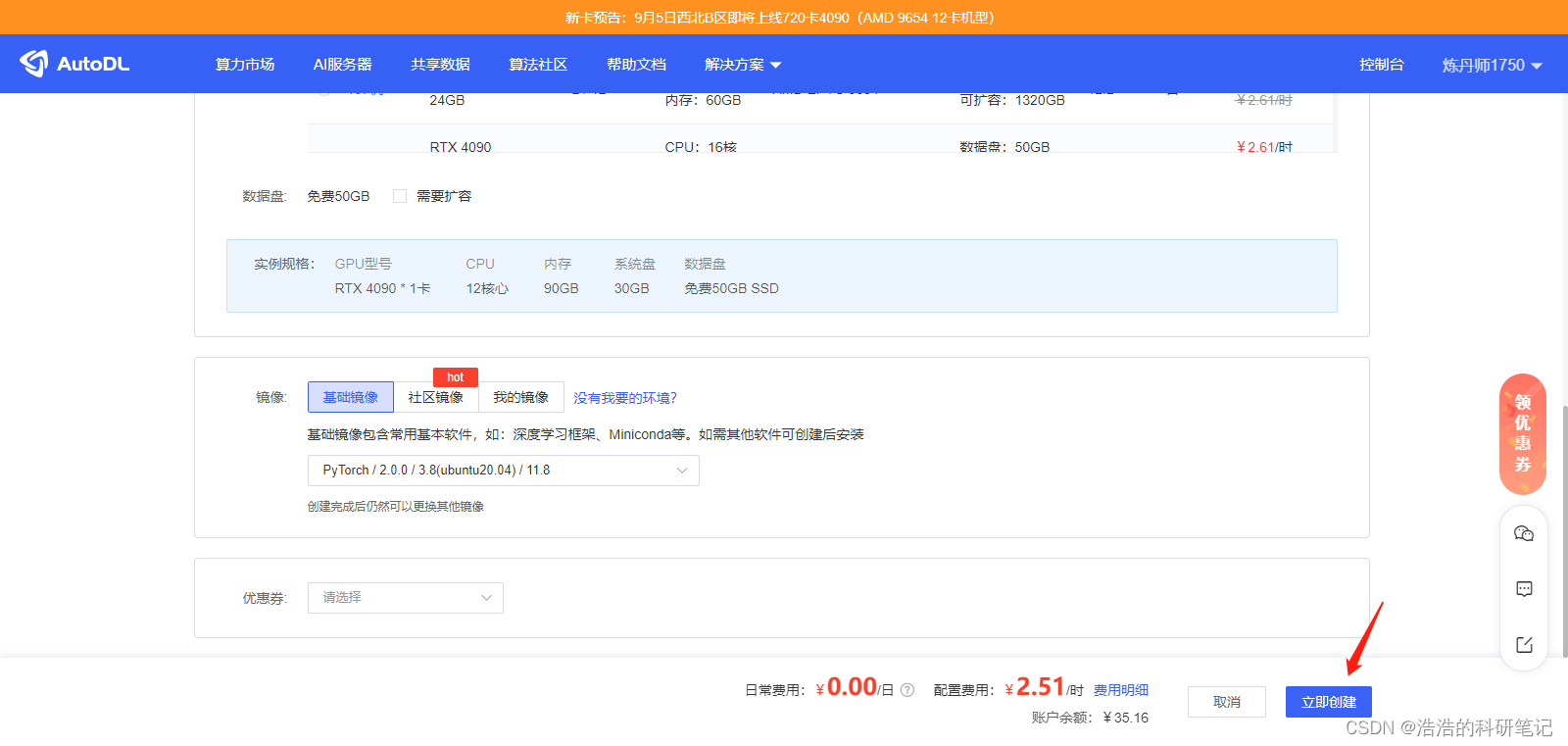
创建成功之后点击右侧的jupterlab
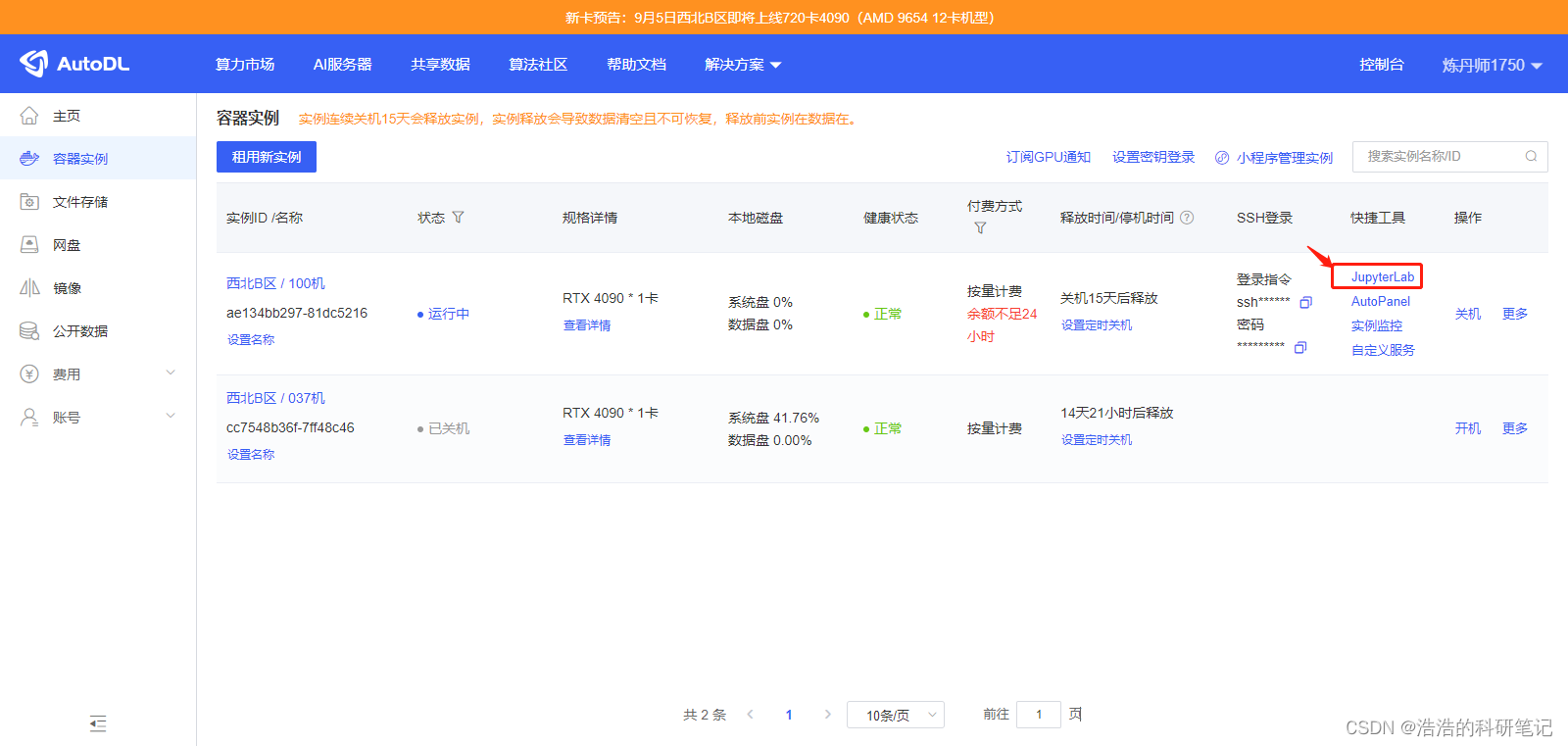
点击下面的终端创建一个终端窗口
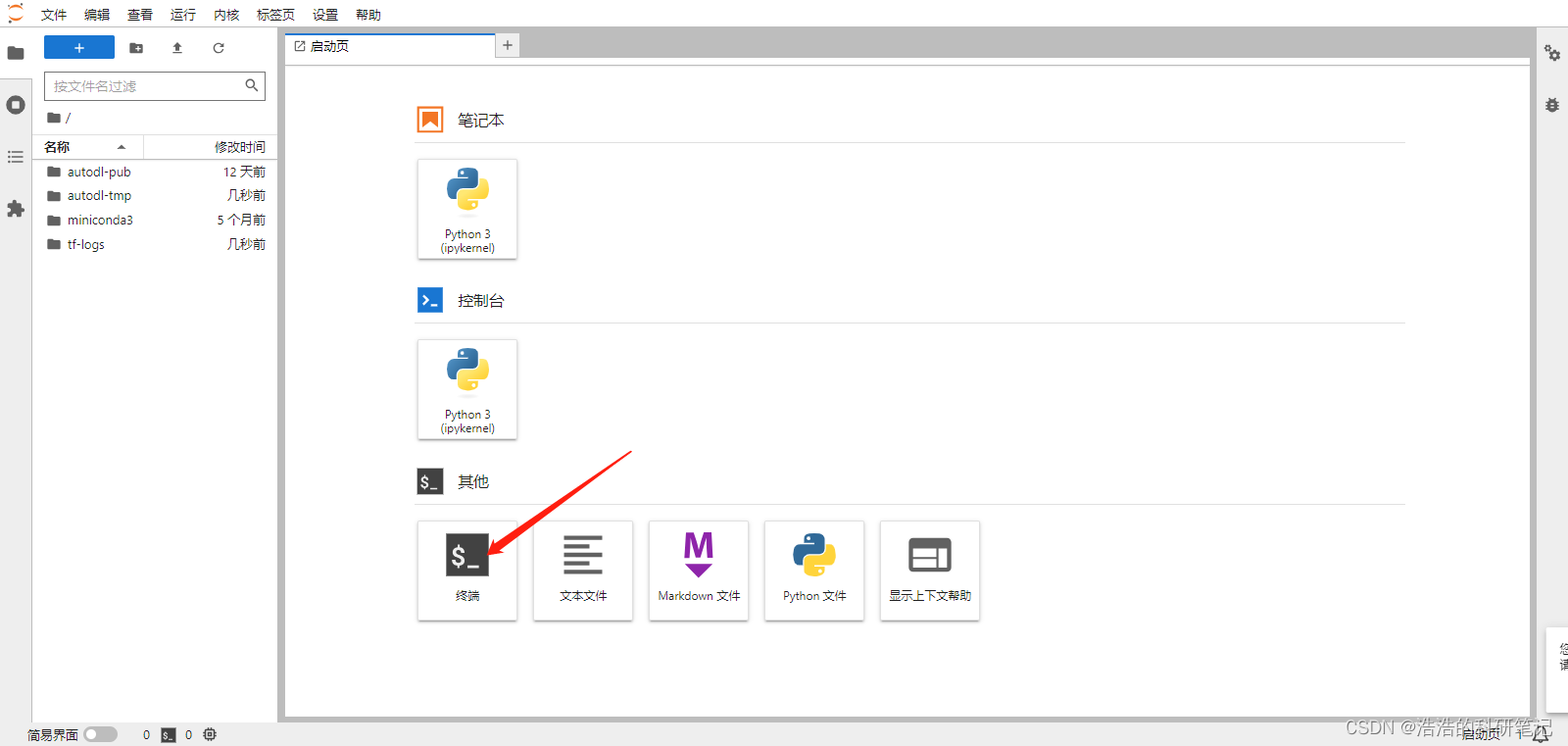
然后再里面我们需要建立一个新的解释器环境,来保证与cuml库适配,不会因为python版本问题导致安装失败。
我们先输入如下指令
conda create -n rapids python=3.9
然后输入y敲回车进入安装
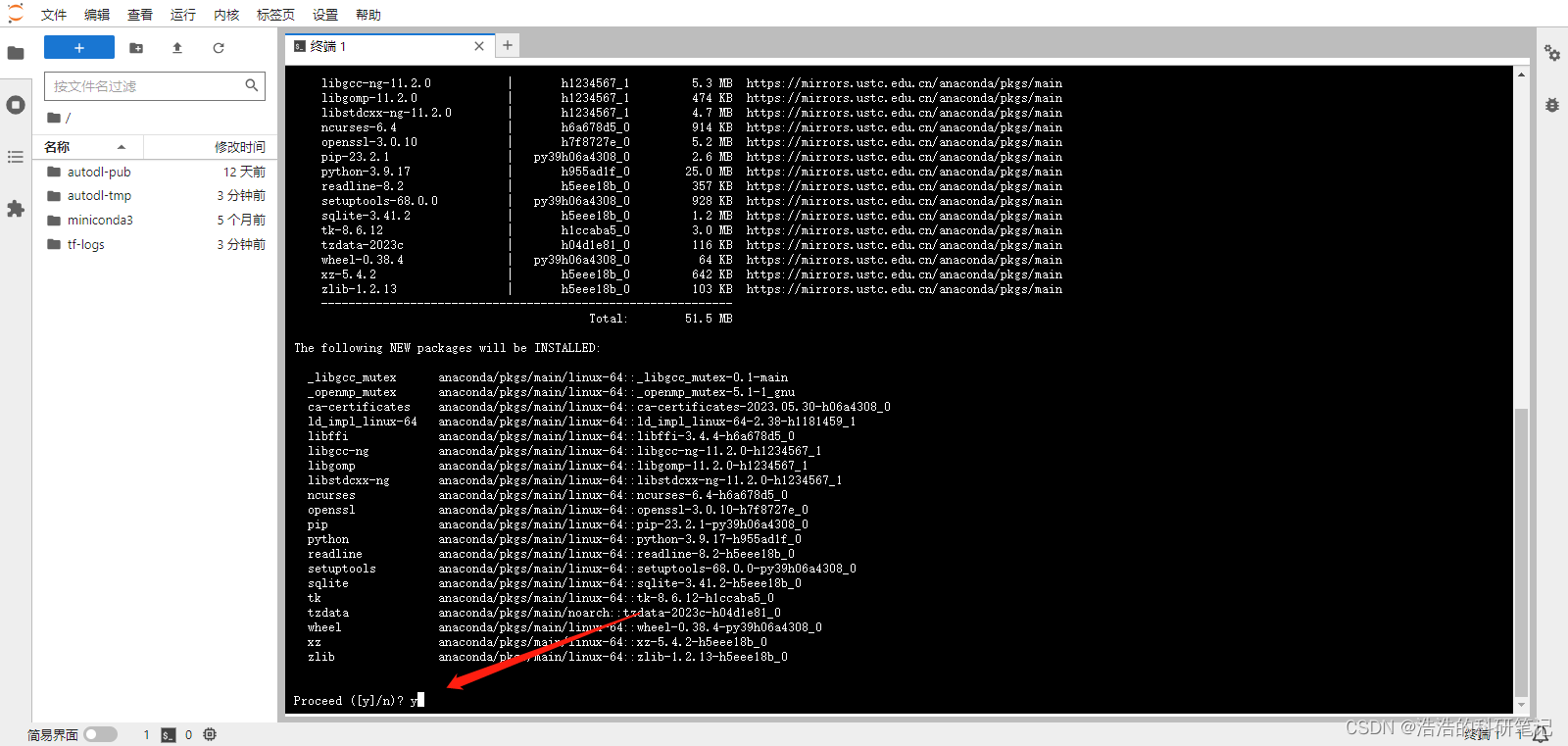
然后输入如下指令
source activate rapids
进入我们刚刚安装好的环境
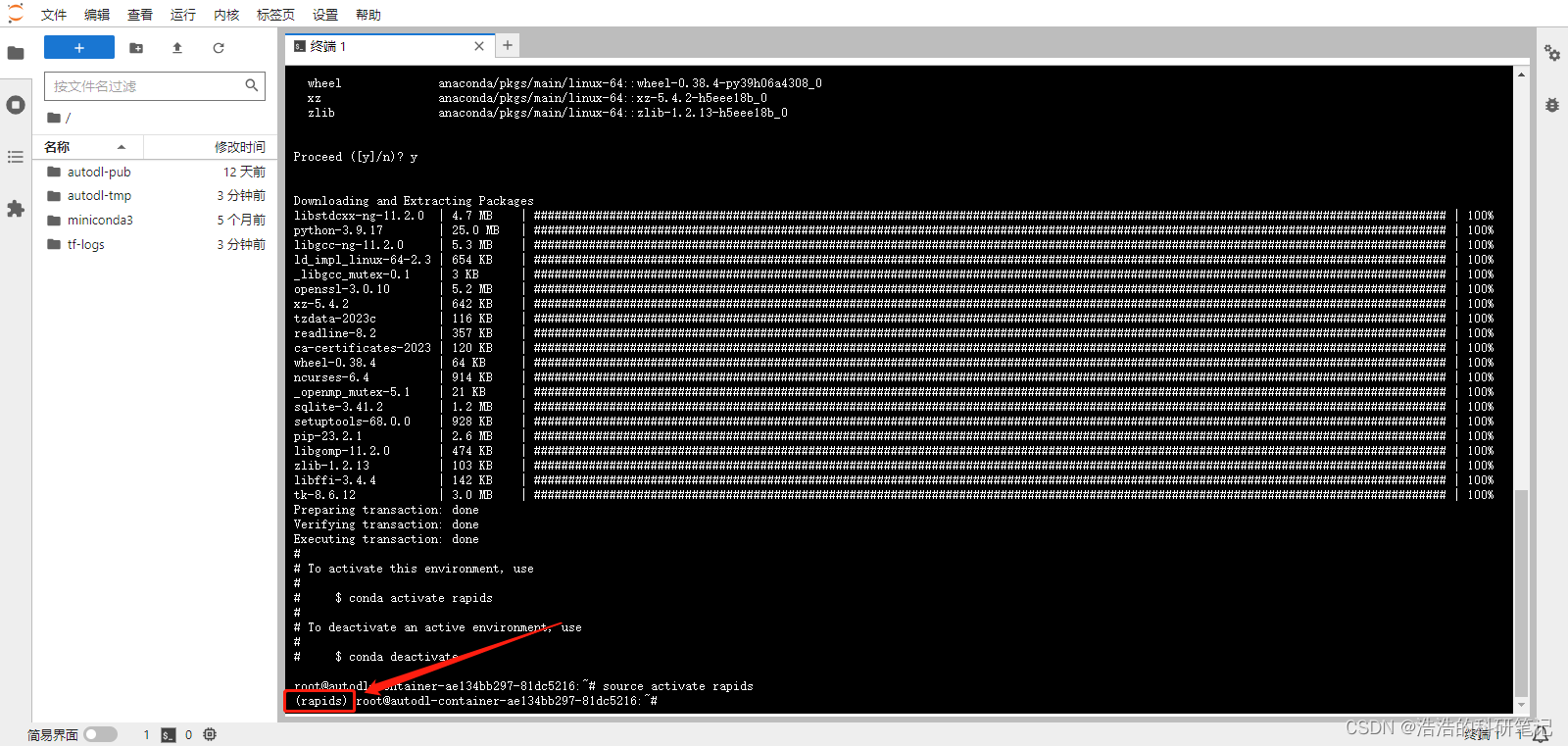
最关键的部分来了请运行如下命令,从这个源安装cuml库
pip install --default-time=300 --extra-index-url=https://pypi.nvidia.com cuml-cu11
等待安装成功之后,在命令行输入python,然后再输入import cuml
OK 没问题
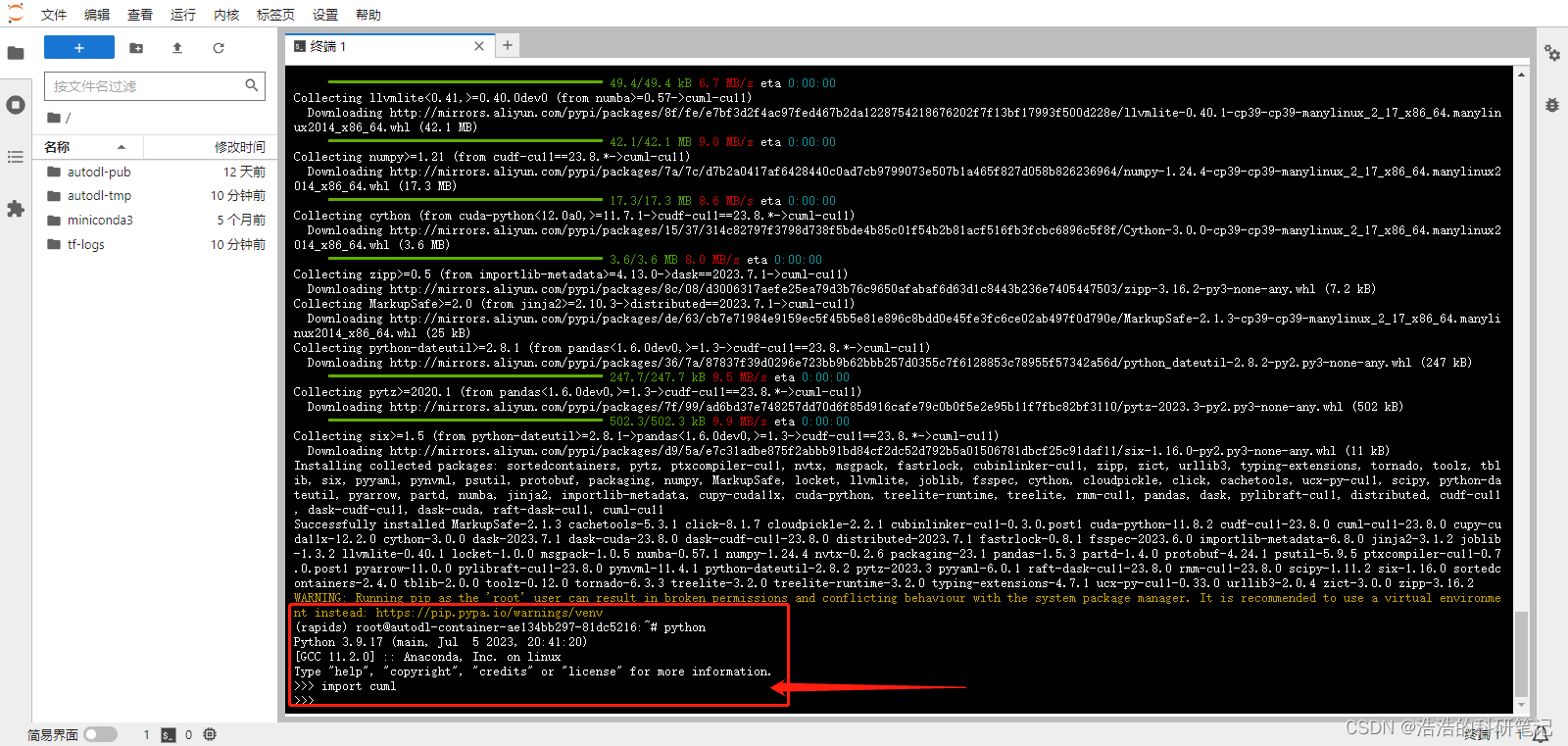
然后我们要在jupter上使用所以需要配置一下新的内核,我们先输入exit()退出python,然后再命令行输入如下命令
python -m ipykernel install --name rapids
如果遇到如下情况我们先安装ipykernel
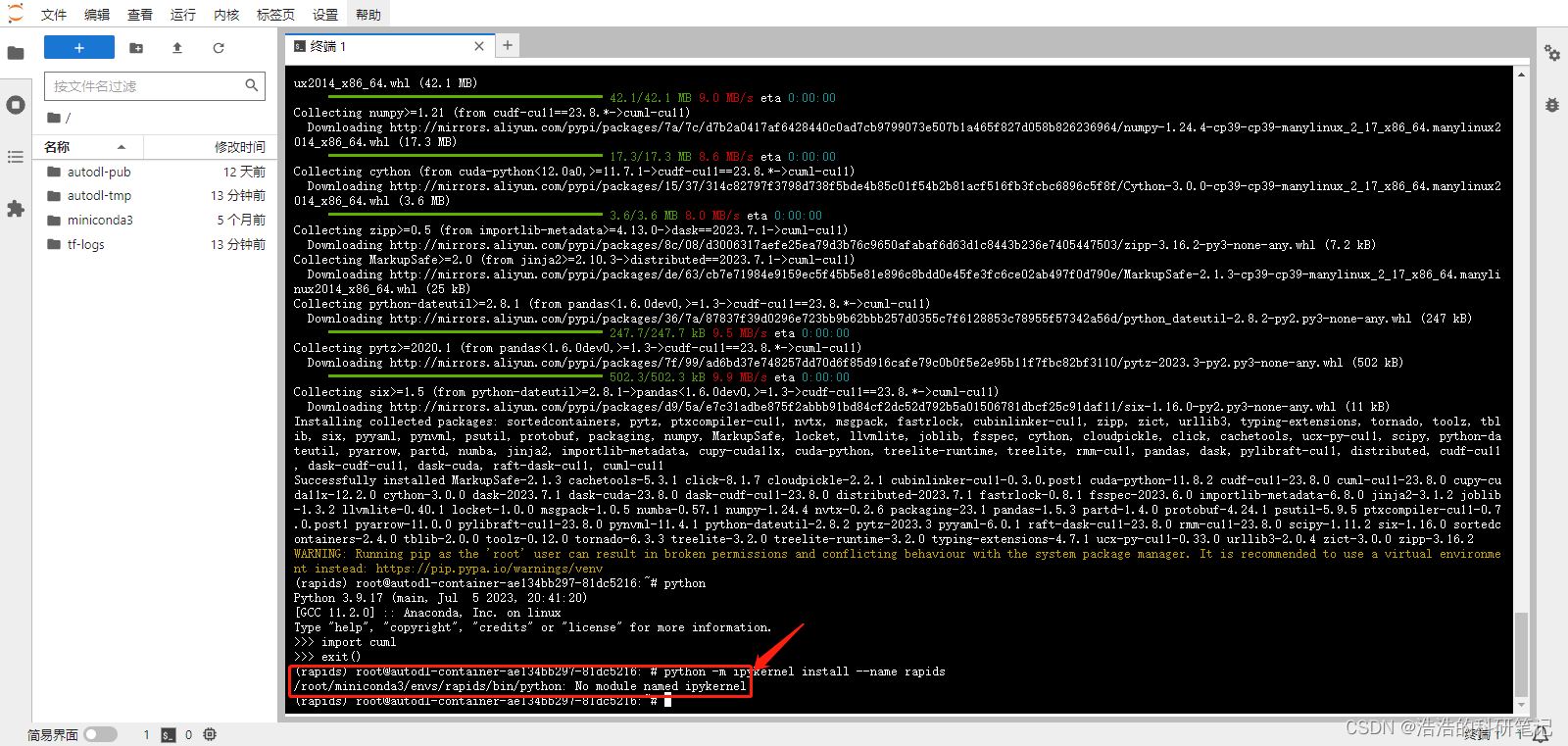
输入如下指令安装
pip install ipykernel
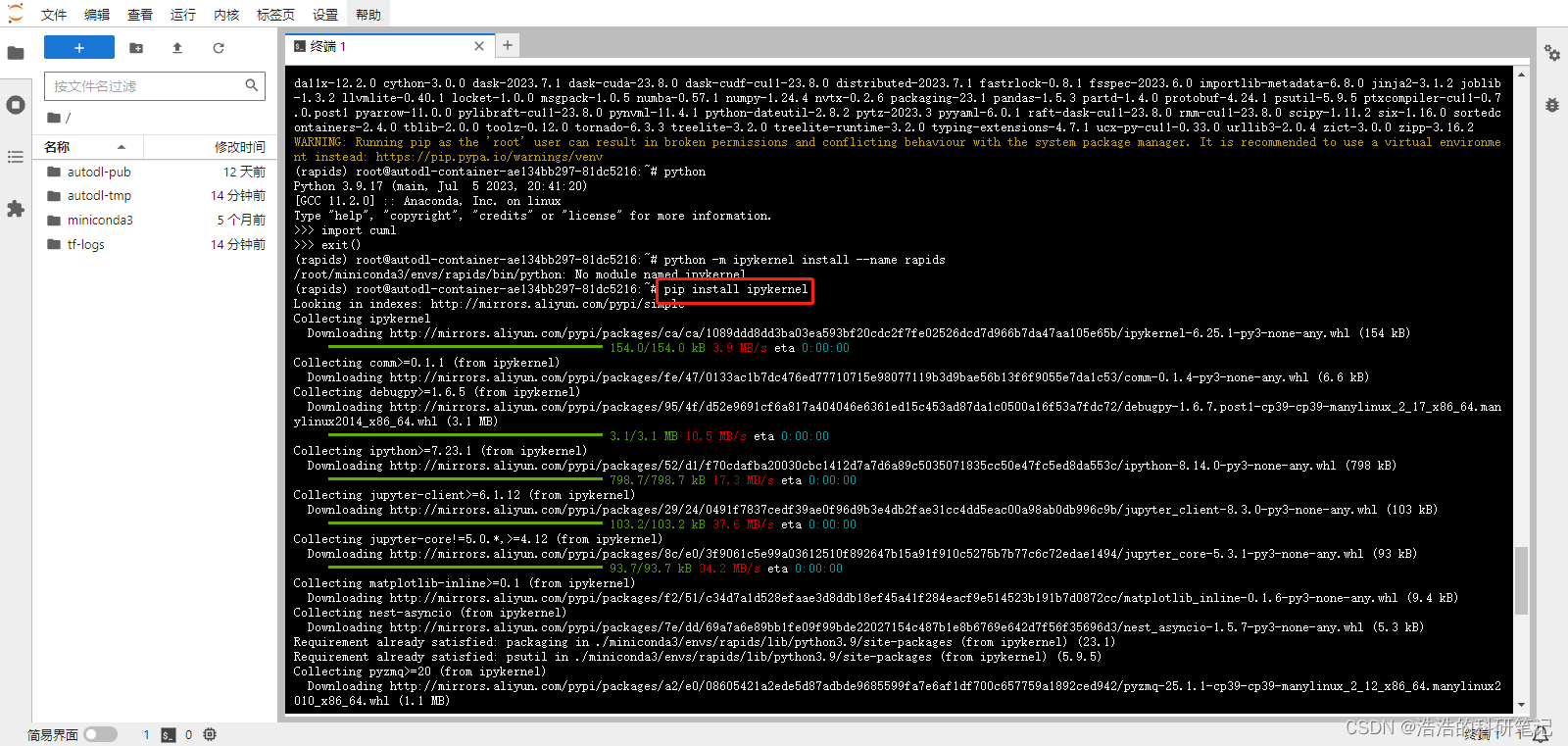
之后输入
python -m ipykernel install --name rapids
注意一定要在新建的环境下输入该命令
如果安装错了运行如下命令删除内核
jupyter kernelspec remove rapids
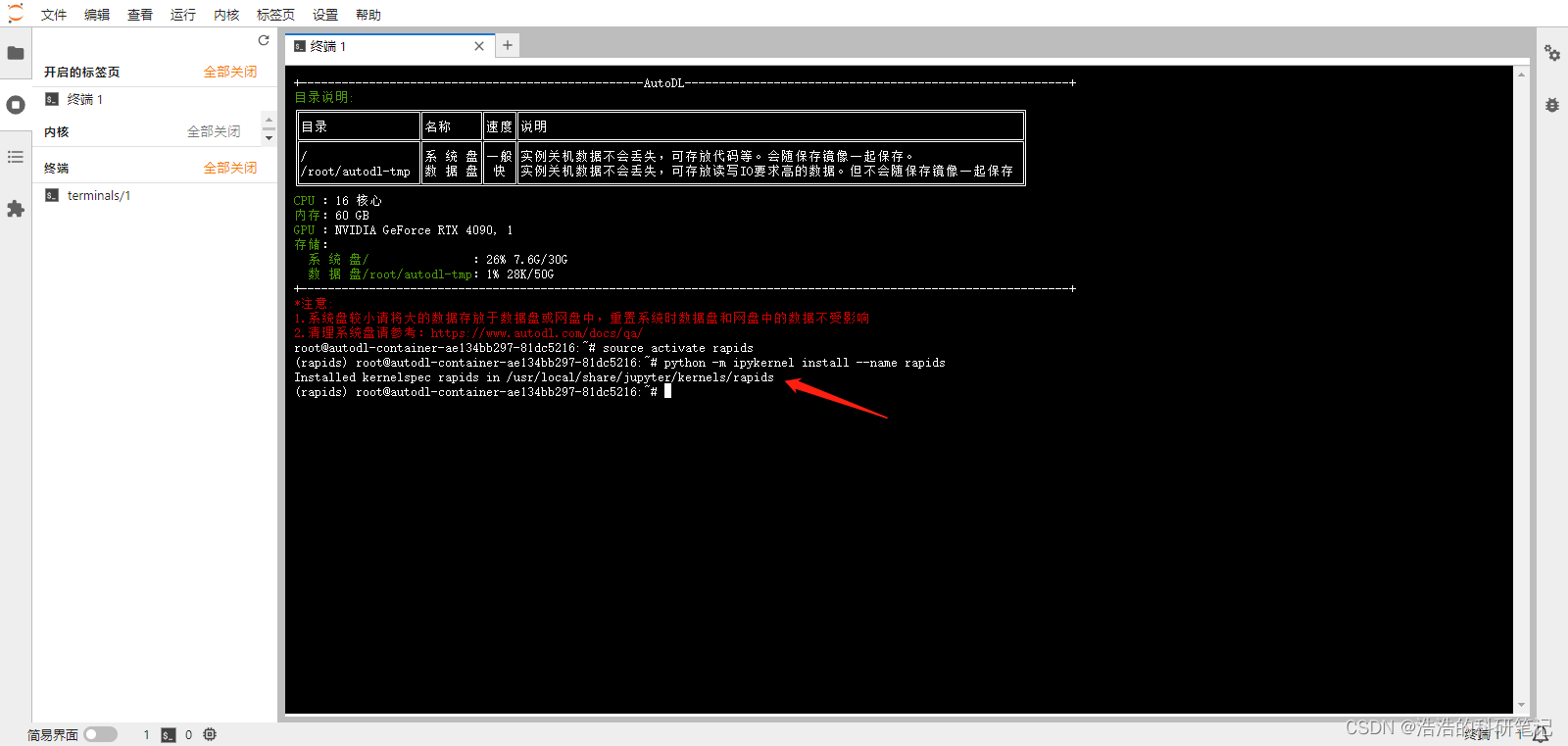
之后点击一下浏览器的页面刷新
再点击右侧加号
即可以看到新的内核的jupter笔记本,点开笔记本。
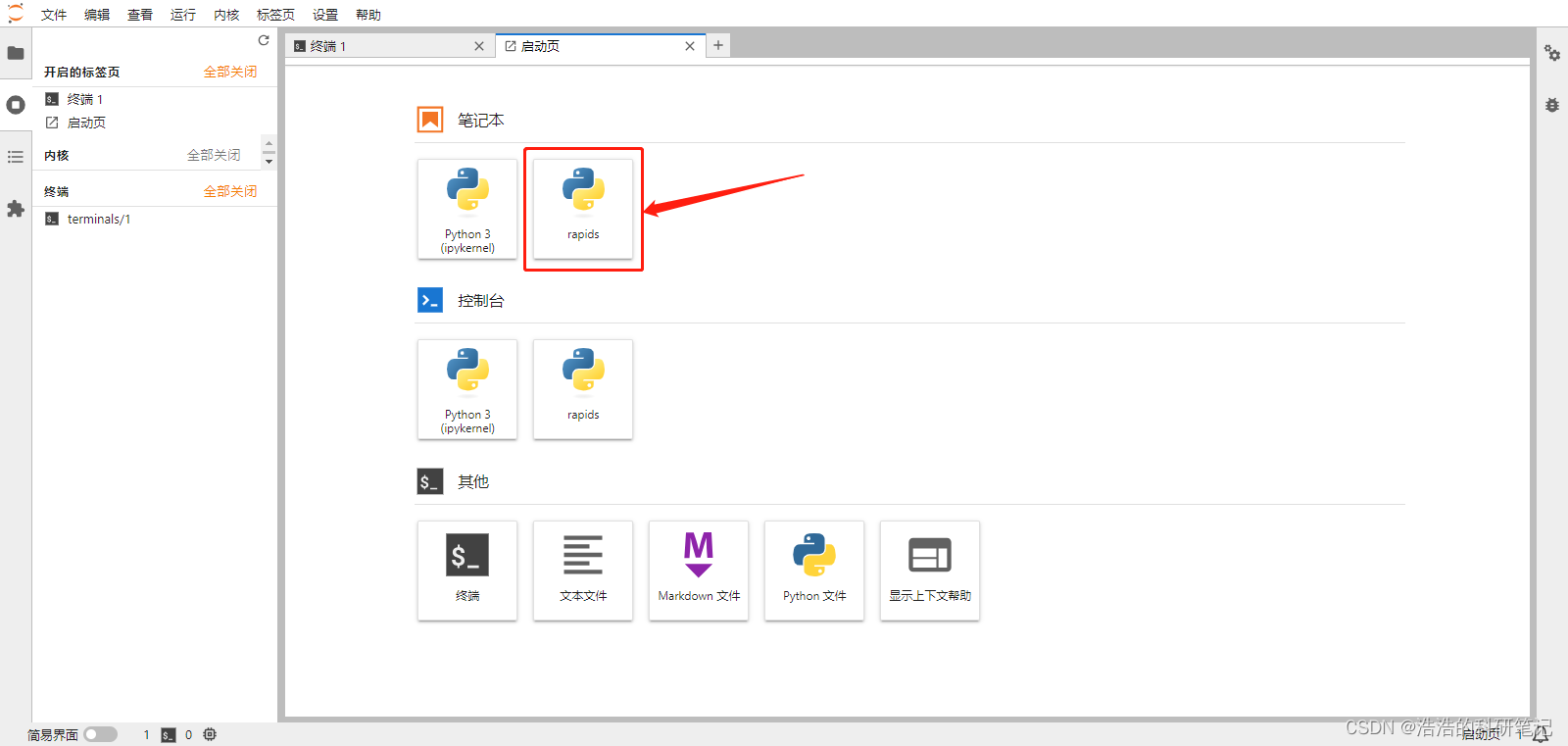
输入
import cuml
然后点击上方小三角,没有报错运行成功
对比实验
为了对比我们也要安装sklearn库做一下时间的对比
回到启动页点击终端
进入终端依次输入以下两个指令
source activate rapids
清华园 sklearn安装命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
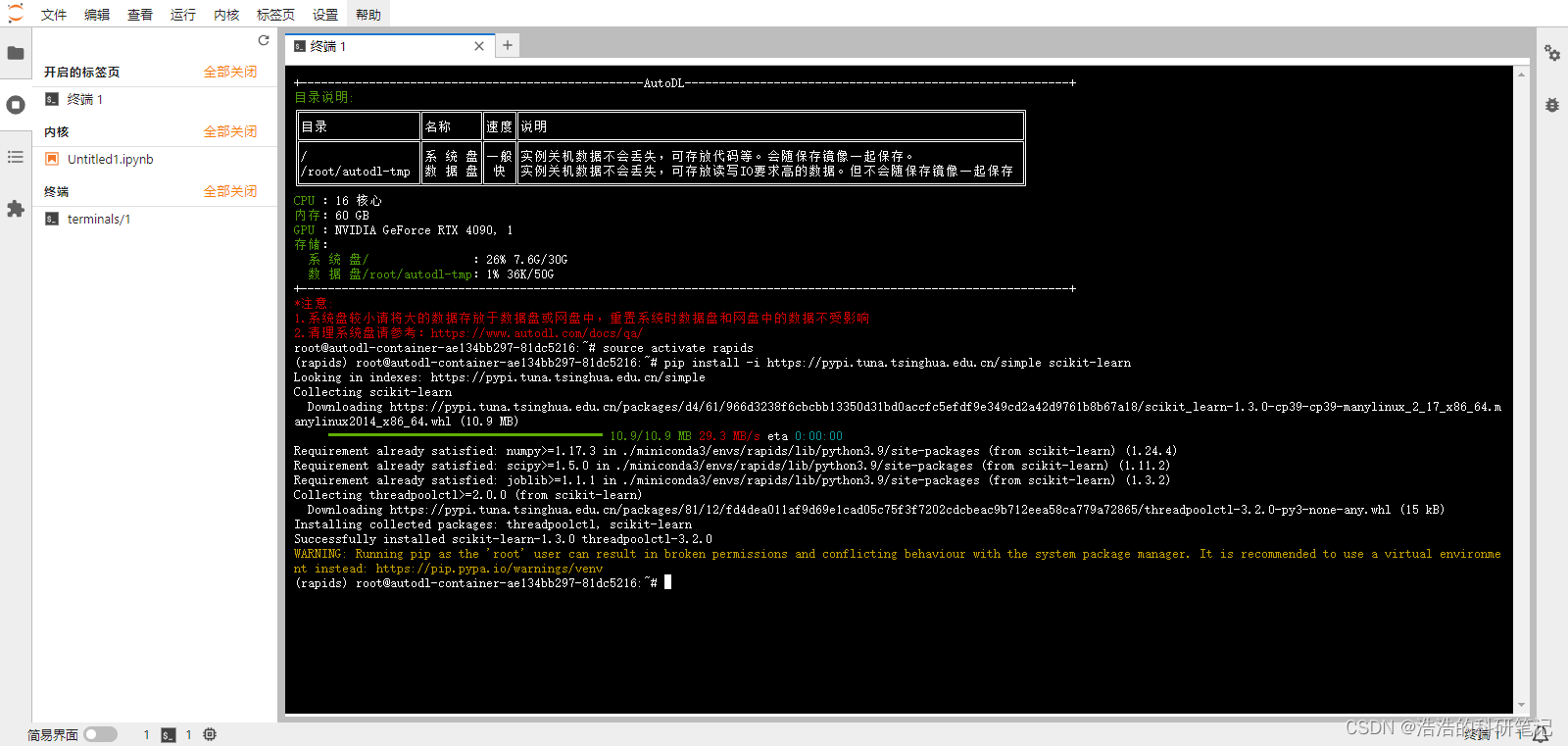
看到安装成功
回到刚才建好的ipynb文件,输入
import sklearn
运行没报错
接下来我们用KNN算法进行以下对比
首先运行sklearn的KNN算法如下,运行时间1分11秒

from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import numpy as np
import timeX = np.random.random((1000000,70))
y = np.random.randint(0,2,1000000)# 分割数据为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化KNN分类器。这里选择邻居数为3。
knn = KNeighborsClassifier(n_neighbors=20)# 使用训练数据拟合模型
start_time = time.time() # 记录开始时间
knn.fit(X_train, y_train)# 进行预测
y_pred = knn.predict(X_test)
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算程序运行时间,单位为秒
# 将秒数转换为小时、分钟和秒数
hours = int(elapsed_time // 3600)
minutes = int((elapsed_time % 3600) // 60)
seconds = int(elapsed_time % 60)
print(f"程序运行时间:{hours}小时 {minutes}分钟 {seconds}秒\n")# 评估预测的准确性
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
接下来我们查找cuml库中KNN算法的API
cuml库API用法查询
链接: https://docs.rapids.ai/api/cuml/stable/
点击右上角小放大镜
然后输入sklearn中KNN算法的API名称
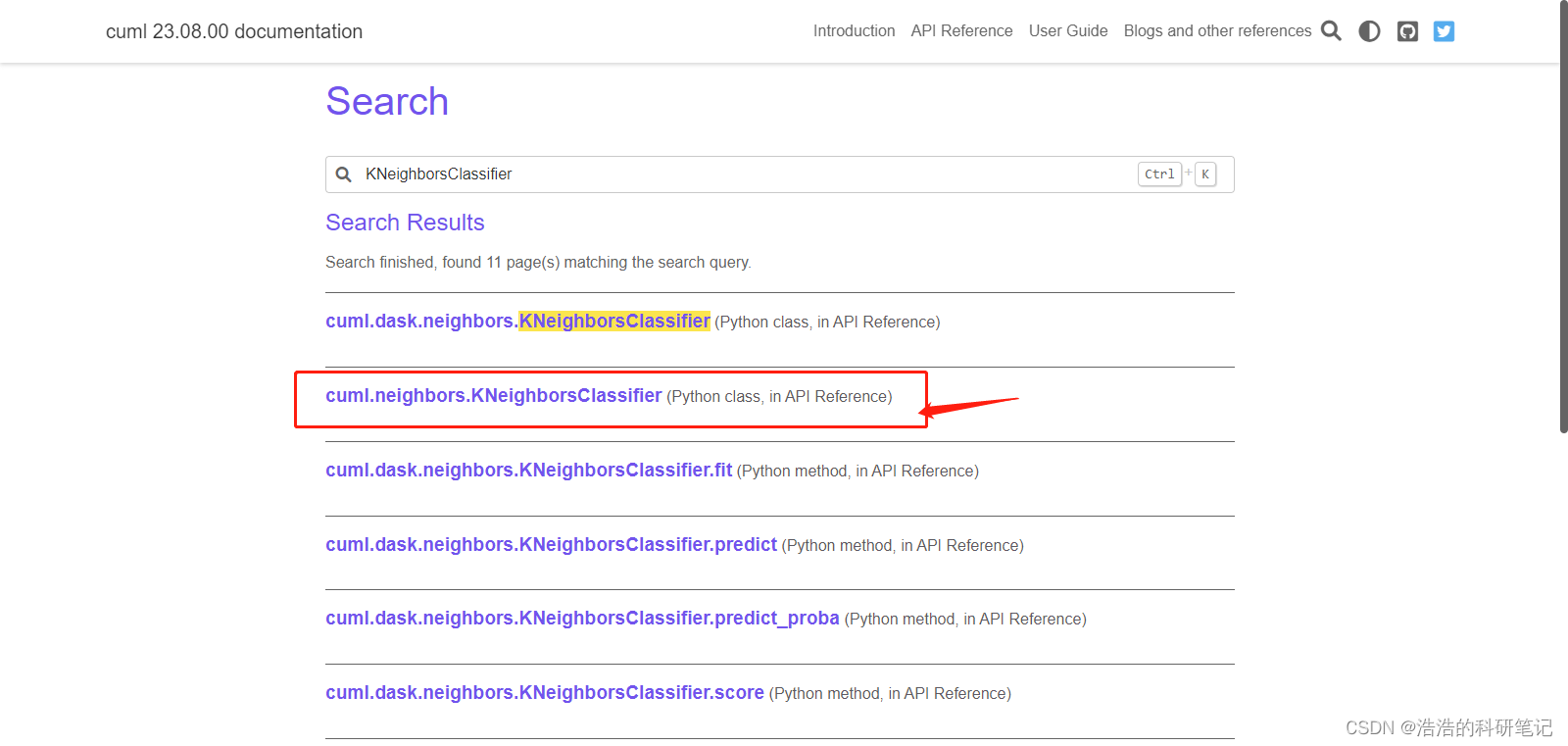
我研究了一下用的是这个
然后我们用
from cuml.neighbors import KNeighborsClassifier
替换
from sklearn.neighbors import KNeighborsClassifier
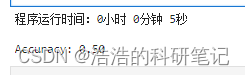
运行,使用时间从1分11秒缩短为5秒
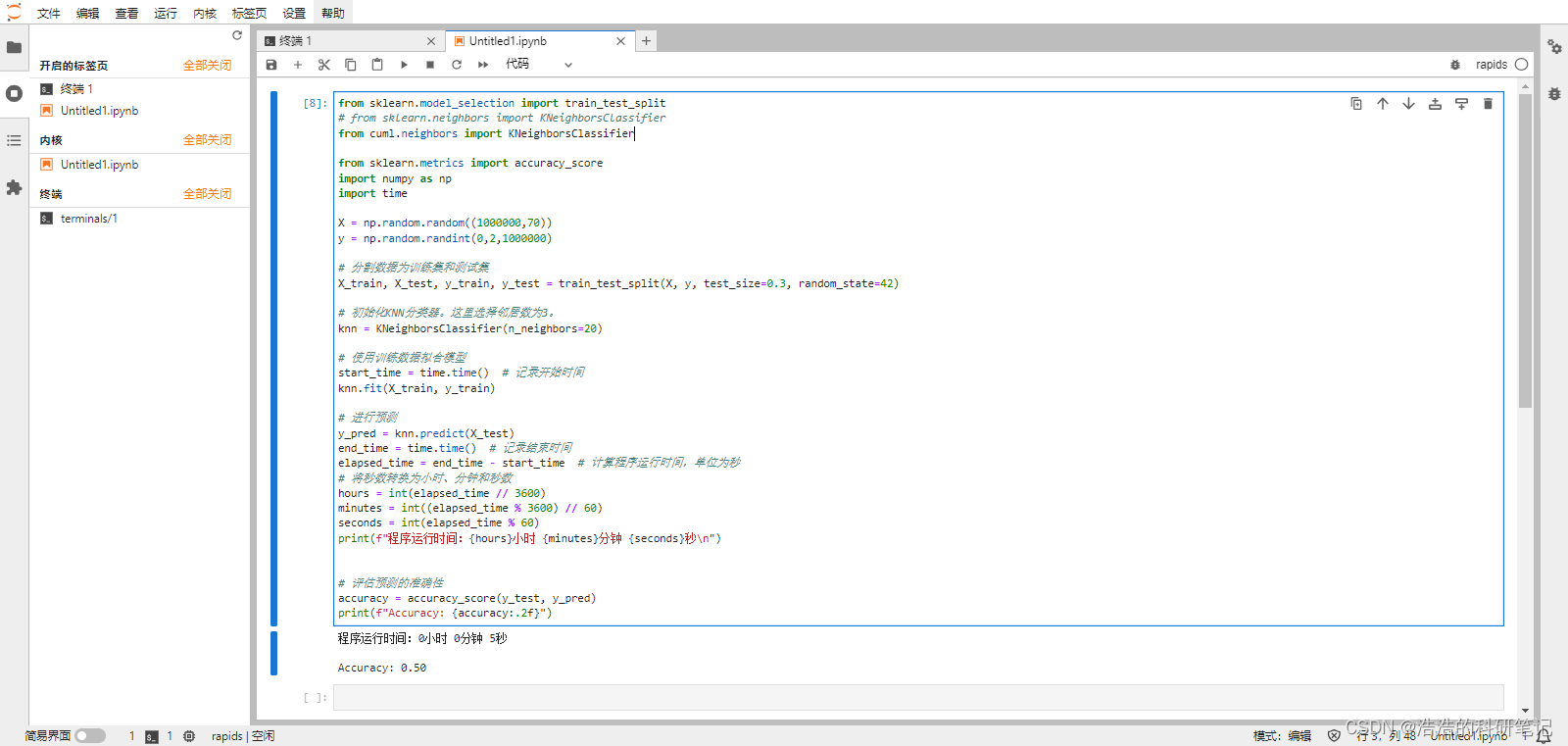
from sklearn.model_selection import train_test_split
# from sklearn.neighbors import KNeighborsClassifier
from cuml.neighbors import KNeighborsClassifierfrom sklearn.metrics import accuracy_score
import numpy as np
import timeX = np.random.random((1000000,70))
y = np.random.randint(0,2,1000000)# 分割数据为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化KNN分类器。这里选择邻居数为3。
knn = KNeighborsClassifier(n_neighbors=20)# 使用训练数据拟合模型
start_time = time.time() # 记录开始时间
knn.fit(X_train, y_train)# 进行预测
y_pred = knn.predict(X_test)
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算程序运行时间,单位为秒
# 将秒数转换为小时、分钟和秒数
hours = int(elapsed_time // 3600)
minutes = int((elapsed_time % 3600) // 60)
seconds = int(elapsed_time % 60)
print(f"程序运行时间:{hours}小时 {minutes}分钟 {seconds}秒\n")# 评估预测的准确性
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
完结撒花
相关文章:
cuml机器学习GPU库 sklearn升级版AutoDL使用
CUML库 最近在做机器学习任务的时候发现我自己的数据集太大,直接用sklearn 跑起来时间很长,然后问GPT得知了有CUML库,后来去研究了一下,发现这个库只支持linux系统,从官网直接获取下载命令基本上也实现不了最后&#…...

C语言练习题Day1
从今天开始分享C语言的练习题,每天都分享,差不多持续16天,看完对C语言的理解可能更进一步,让我们开始今天的分享吧! 题目一 执行下面的代码,输出结果是() int x5,y7; void swap()…...

使用kubeadm安装和设置Kubernetes(k8s)
用kubeadm方式搭建K8S集群 kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。 这个工具能通过两条指令完成一个kubernetes集群的部署: # 创建一个 Master 节点 kubeadm init# 将一个 Node 节点加入到当前集群中 kubeadm join <Master节点的IP和端口…...

Docker安装延迟队列插件
下载插件地址:https://www.rabbitmq.com/community-plugins.html 插件上传服务器 选择跟我们rabbitmq版本一致或者小于的插件即可。版本可在web管理首页查看。 将下载的插件上传到Linux系统上,使用 docker 命令将插件复制到容器内部 plugins目录下 do…...
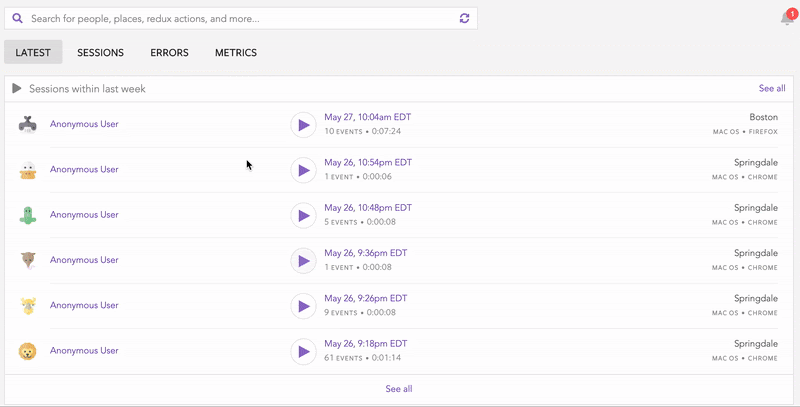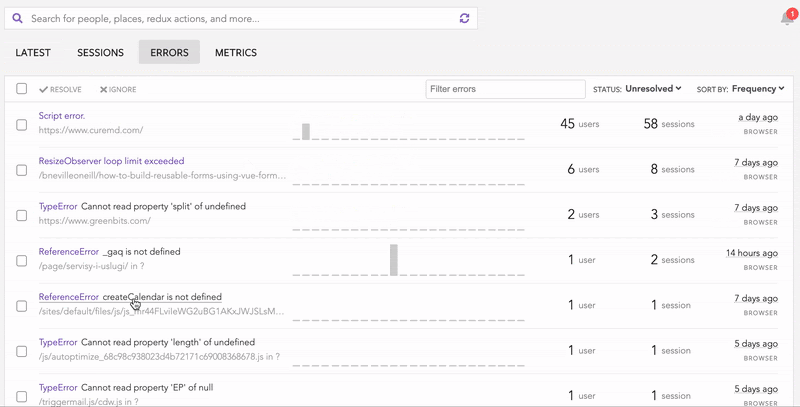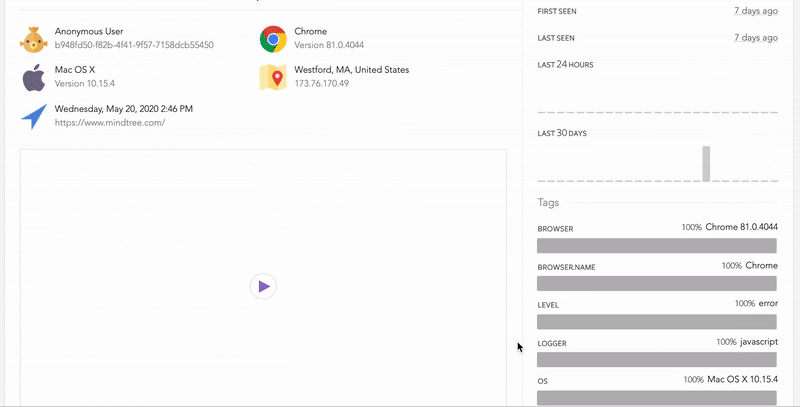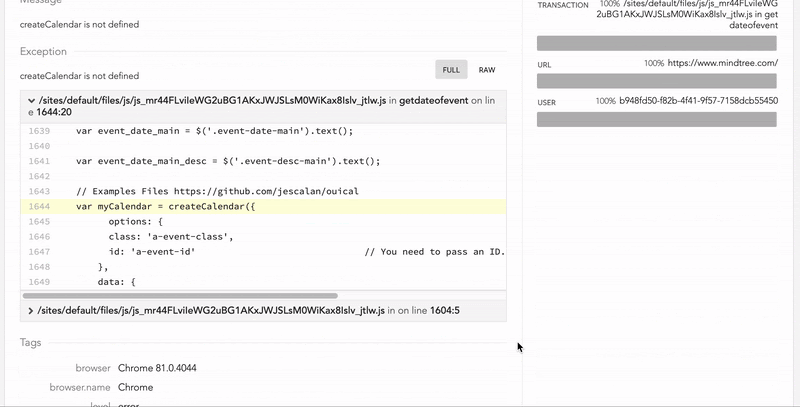
推荐前 6 名 JavaScript 和 HTML5 游戏引擎
推荐:使用 NSDT场景编辑器 助你快速搭建3D应用场景 事实是,自从引入JavaScript WebGL API以来,现代浏览器具有直观的功能,使它们能够渲染更复杂和复杂的2D和3D图形,而无需依赖第三方插件。 你可以用纯粹的JavaScript开…...

【Django】 Task5 DefaultRouter路由组件和自定义函数
文章目录 【Django】 Task5 DefaultRouter路由组件和自定义函数1.路由组件1.1路由组件介绍1.2SimpleRouter1.3DefaultRouter1.4DefaultRouter示例1.5查看访问服务接口url 2.自定义函数 【Django】 Task5 DefaultRouter路由组件和自定义函数 Task5 主要了解了DefaultRouter路由…...
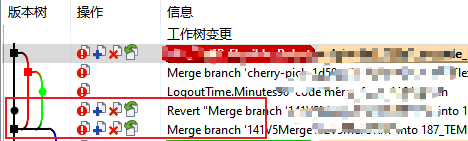
Git拉取分支、基于主分支创建新的开发分支、合并开发分支到主分支、回退上一次的merge操作
系列文章目录 第1章 Git拉取分支、基于主分支创建新的开发分支、合并开发分支到主分支、回退上一次的merge操作 文章目录 系列文章目录一、拉取分支二、如何从master分支创建一个dev分支三、如何将dev分支合并到master分支四、如何回退上一次的merge 一、拉取分支 项目文件夹…...

SpringBoot实现定时任务操作及cron在线生成器
spring根据定时任务的特征,将定时任务的开发简化到了极致。怎么说呢?要做定时任务总要告诉容器有这功能吧,然后定时执行什么任务直接告诉对应的bean什么时间执行就行了,就这么简单,一起来看怎么做 步骤①:…...

数据结构(Java实现)-栈和队列
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。 先进后出 栈的使用 栈的模拟实现 上述的主要代码 public class MyStack {private int[] elem;private int usedSize;public MyStack() {this.elem new int[5];}Overridepublic …...

毕业季如何做好IT技术面试
在IT技术面试过程中,面试者需要展示多个方面的能力和素质,以确保其能够成功地适应公司的文化和环境,并为公司的发展做出贡献。本文将详细介绍IT技术面试的各个方面,并给出建议和指导。 简历和求职信 简历和求职信是面试官了解面…...

springcloud3 GateWay章节-Nacos+gateway(跨域,filter过滤等5
一 常用工具类 1.1 结构 1.2 跨域 Configuration public class CorsConfig {Beanpublic CorsWebFilter corsFilter() {CorsConfiguration config new CorsConfiguration();config.addAllowedMethod("*");config.addAllowedOrigin("*");config.addAllowe…...

Nodejs+Typescript+Eslint+Prettier+Husky项目构建
NodejsTypescriptEslintPrettierHusky项目构建 准备工作初始化项目Eslint安装和配置Prettier安装和配置在Eslint中使用Prettier插件Husky安装和配置修改tsconfig.json启用表示src目录 修改package.json设置vscode调试 仓库地址 准备工作 确保已经安装了git以及Node.js和npm&a…...

轻松正确使用代理IP
Hey,亲爱的程序员小伙伴们!在进行爬虫时,你是否曾使用过别人的代理IP?是否因此慌乱,担心涉及违法问题?不要惊慌!今天我将和你一起揭开法律迷雾,为你的爬虫之路保驾护航。快跟上我的节…...
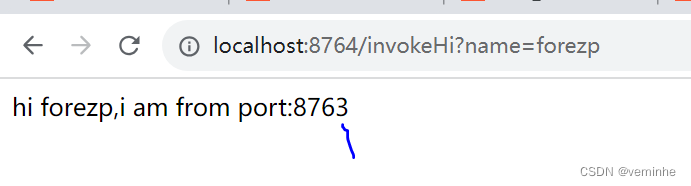
SpringCloud教程 | 第二篇: 服务消费者(rest+ribbon)
在上一篇文章,讲了服务的注册和发现。在微服务架构中,业务都会被拆分成一个独立的服务,服务与服务的通讯是基于http restful的。Spring cloud有两种服务调用方式,一种是ribbonrestTemplate,另一种是feign。在这一篇文章…...

lintcode 961 · 设计日志存储系统预【系统设计题 中等】
题目链接,描述 https://www.lintcode.com/problem/961 您将获得多个日志,每个日志都包含唯一的 ID 和时间戳。 时间戳是一个具有以下格式的字符串:Year:Month:Day:Hour:Minute:Second,例如2017:01:01:23:59:59。 所有域都是零填…...

windows下Qt、MinGW、libmodbus源码方式的移植与使用
windows下Qt、MinGW、libmodbus源码方式的移植与使用 1、前言 libmodbus官网:https://libmodbus.org/ github下载:https://github.com/stephane/libmodbus 截止2023年8月26日时,libmodbus最新版本为3.1.10,本篇博客基于此版本进…...

leetcode做题笔记104. 二叉树的最大深度
给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 思路一:递归 int dfs(struct TreeNode* node){int rdepth 1;int ldepth 1;if(node->left!NULL) ldepth rdepth dfs(node->lef…...
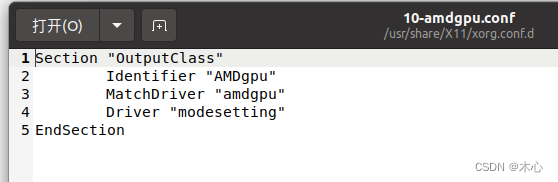
【Luniux】解决Ubuntu外接显示器不显示的问题
Luniux】解决Ubuntu外接显示器不显示的问题 文章目录 Luniux】解决Ubuntu外接显示器不显示的问题1. 检查nvidia显卡驱动是否正常2. 更新驱动3. 检查显示器是否能检测到Reference 1. 检查nvidia显卡驱动是否正常 使用命令行 nvidia-smi来检查显卡驱动是否正常,如果…...
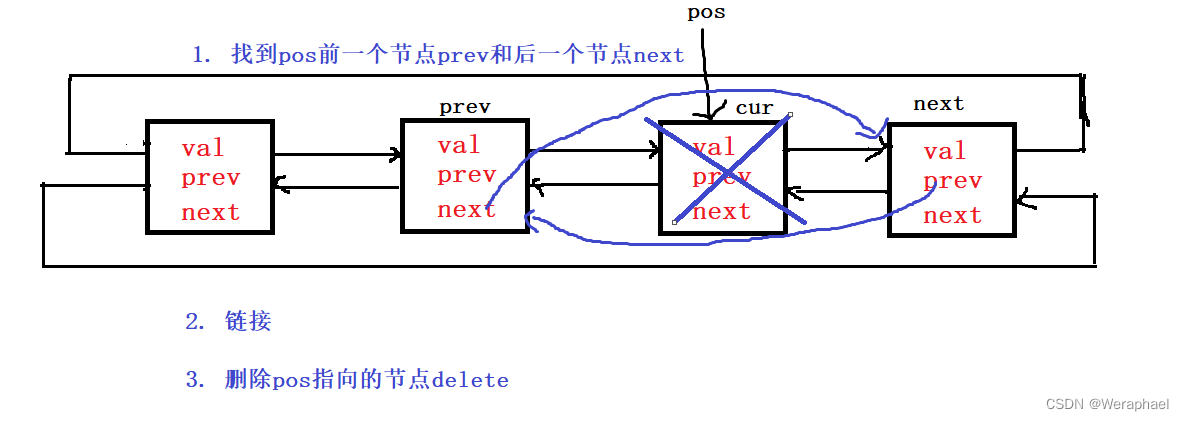
【C++初阶】模拟实现list
👦个人主页:Weraphael ✍🏻作者简介:目前学习C和算法 ✈️专栏:C航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞…...
三维模拟推演电子沙盘虚拟数字沙盘开发教程第13课
三维模拟推演电子沙盘虚拟数字沙盘开发教程第13课 该数据库中只提供 成都市火车南站附近的数据请注意,104.0648,30.61658 在SDK中为了方便三方数据的接入,引入了一个用户层接口。主要是完成三方数据的接入,含动态数据(如GPS&…...

如何用Python快速接入Taotoken调用多模型API完成开发任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken调用多模型API完成开发任务 对于开发者而言,快速验证想法、构建原型是开发流程中的关键环…...

免费商用音乐下载网站TOP5 | 基于版权合规与素材复用效率的横评
引言 2026年,国内内容营销市场持续扩张,企业短视频、直播切片、线下活动音视频等场景对背景音乐的需求量同比增长37%(根据《2026中国数字内容版权白皮书》)。然而,创作者在实际选曲过程中普遍存在三类矛盾:…...

C++图文并茂轻松进阶面向对象
一、进阶面向对象(上)面向对象的意义在于将日常生活中习惯的思维方式引入程序设计中将需求中的概念直观的映射到解决方案中以模块为中心构建可复用的软件系统提高软件产品的可维护性和可扩展性类和对象是面向对象中的两个基本概念类∶指的是一类事物&…...

[模型解析] GPT: 模型演进分析从GPT-3到GPT-5.5
GPT 模型演进分析:从 GPT-3 到 GPT-5.5 OpenAI 的 GPT 系列模型在过去几年经历了快速演进,从 2020 年的 GPT-3 到 2026 年的 GPT-5.5,每一次迭代都带来了显著的能力提升和架构创新。本文将系统分析 GPT 模型的演进路径与技术特点。 一、GPT 模…...

TaskbarX完整指南:Windows任务栏图标居中与动画特效实战教程
TaskbarX完整指南:Windows任务栏图标居中与动画特效实战教程 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX TaskbarX是一款专为Windows 10/11设…...

SwinFusion论文精读与代码复现:拆解‘跨域远程学习’如何让图像融合效果开挂
SwinFusion技术解析:跨域远程学习如何重塑图像融合范式 图像融合技术正经历一场由Transformer架构引领的范式变革。传统方法在全局依赖建模和跨域交互方面的局限性,催生了基于Swin Transformer的创新解决方案。本文将深入剖析SwinFusion这一通用图像融合…...

戴森球计划工厂蓝图库:3000+专业设计解决太空建造难题
戴森球计划工厂蓝图库:3000专业设计解决太空建造难题 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints FactoryBluePrints是戴森球计划游戏中规模最大的工厂蓝图开…...

OAuthlib错误诊断实战:从invalid_grant到temporarily_unavailable根因定位
1. 为什么OAuthlib的错误信息总让你一头雾水?你刚在Flask或Django项目里集成OAuth2登录,用户点“用GitHub登录”后页面直接报500,控制台只甩出一行红字:oauthlib.oauth2.rfc6749.errors.InvalidGrantError: (invalid_grant) Bad r…...

AzurLaneAutoScript:碧蓝航线自动化管理的完整解决方案
AzurLaneAutoScript:碧蓝航线自动化管理的完整解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧…...

CLIP实战指南:零样本图文检索与跨模态应用落地
1. 这不是又一个“多模态模型”名词解释,而是你真正能用起来的CLIP实战指南如果你最近在做图像搜索、零样本分类、图文匹配、跨模态检索,或者哪怕只是想给自家图库自动打标签、给设计稿配文案、给电商商品图生成合规描述——那CLIP绝不是论文里那个高冷的…...