9. 优化器
9.1 优化器
① 损失函数调用backward方法,就可以调用损失函数的反向传播方法,就可以求出我们需要调节的梯度,我们就可以利用我们的优化器就可以根据梯度对参数进行调整,达到整体误差降低的目的。
② 梯度要清零,如果梯度不清零会导致梯度累加。
9.2 神经网络优化一轮
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = Sequential(Conv2d(3,32,5,padding=2),MaxPool2d(2),Conv2d(32,32,5,padding=2),MaxPool2d(2),Conv2d(32,64,5,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # 随机梯度下降优化器
for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距optim.zero_grad() # 梯度清零result_loss.backward() # 反向传播,计算损失函数的梯度optim.step() # 根据梯度,对网络的参数进行调优print(result_loss) # 对数据只看了一遍,只看了一轮,所以loss下降不大结果:
Files already downloaded and verified tensor(2.2978, grad_fn=<NllLossBackward0>) tensor(2.2988, grad_fn=<NllLossBackward0>) tensor(2.3163, grad_fn=<NllLossBackward0>) tensor(2.3253, grad_fn=<NllLossBackward0>) tensor(2.2952, grad_fn=<NllLossBackward0>) tensor(2.3066, grad_fn=<NllLossBackward0>) tensor(2.3085, grad_fn=<NllLossBackward0>) tensor(2.3106, grad_fn=<NllLossBackward0>) tensor(2.2960, grad_fn=<NllLossBackward0>) tensor(2.3053, grad_fn=<NllLossBackward0>) tensor(2.2892, grad_fn=<NllLossBackward0>) tensor(2.3090, grad_fn=<NllLossBackward0>) tensor(2.2956, grad_fn=<NllLossBackward0>) tensor(2.3041, grad_fn=<NllLossBackward0>) tensor(2.3012, grad_fn=<NllLossBackward0>) tensor(2.3043, grad_fn=<NllLossBackward0>) tensor(2.2760, grad_fn=<NllLossBackward0>) tensor(2.3051, grad_fn=<NllLossBackward0>) tensor(2.2951, grad_fn=<NllLossBackward0>) tensor(2.3168, grad_fn=<NllLossBackward0>) tensor(2.3140, grad_fn=<NllLossBackward0>) tensor(2.3096, grad_fn=<NllLossBackward0>) tensor(2.2945, grad_fn=<NllLossBackward0>) tensor(2.3115, grad_fn=<NllLossBackward0>) tensor(2.2987, grad_fn=<NllLossBackward0>) tensor(2.3029, grad_fn=<NllLossBackward0>) tensor(2.3096, grad_fn=<NllLossBackward0>) tensor(2.3064, grad_fn=<NllLossBackward0>) tensor(2.3161, grad_fn=<NllLossBackward0>) tensor(2.3129, grad_fn=<NllLossBackward0>) tensor(2.2903, grad_fn=<NllLossBackward0>) tensor(2.3043, grad_fn=<NllLossBackward0>) tensor(2.3034, grad_fn=<NllLossBackward0>) tensor(2.3169, grad_fn=<NllLossBackward0>) tensor(2.3090, grad_fn=<NllLossBackward0>) tensor(2.3039, grad_fn=<NllLossBackward0>) tensor(2.3019, grad_fn=<NllLossBackward0>) tensor(2.3071, grad_fn=<NllLossBackward0>) tensor(2.3018, grad_fn=<NllLossBackward0>) tensor(2.3083, grad_fn=<NllLossBackward0>) tensor(2.2994, grad_fn=<NllLossBackward0>) tensor(2.2909, grad_fn=<NllLossBackward0>) tensor(2.3130, grad_fn=<NllLossBackward0>) tensor(2.2993, grad_fn=<NllLossBackward0>) tensor(2.2906, grad_fn=<NllLossBackward0>) tensor(2.3084, grad_fn=<NllLossBackward0>) tensor(2.3123, grad_fn=<NllLossBackward0>) tensor(2.2931, grad_fn=<NllLossBackward0>) tensor(2.3059, grad_fn=<NllLossBackward0>) tensor(2.3117, grad_fn=<NllLossBackward0>) tensor(2.2975, grad_fn=<NllLossBackward0>) tensor(2.3109, grad_fn=<NllLossBackward0>) tensor(2.3029, grad_fn=<NllLossBackward0>) tensor(2.3020, grad_fn=<NllLossBackward0>) tensor(2.3022, grad_fn=<NllLossBackward0>) tensor(2.3005, grad_fn=<NllLossBackward0>) tensor(2.2920, grad_fn=<NllLossBackward0>) tensor(2.3016, grad_fn=<NllLossBackward0>) tensor(2.3053, grad_fn=<NllLossBackward0>) tensor(2.3082, grad_fn=<NllLossBackward0>) tensor(2.3011, grad_fn=<NllLossBackward0>) tensor(2.3040, grad_fn=<NllLossBackward0>) tensor(2.3130, grad_fn=<NllLossBackward0>) tensor(2.2981, grad_fn=<NllLossBackward0>) tensor(2.2977, grad_fn=<NllLossBackward0>) tensor(2.2994, grad_fn=<NllLossBackward0>) tensor(2.3075, grad_fn=<NllLossBackward0>) tensor(2.3016, grad_fn=<NllLossBackward0>) tensor(2.2966, grad_fn=<NllLossBackward0>) tensor(2.3015, grad_fn=<NllLossBackward0>) tensor(2.3000, grad_fn=<NllLossBackward0>) tensor(2.2953, grad_fn=<NllLossBackward0>) tensor(2.2958, grad_fn=<NllLossBackward0>) tensor(2.2977, grad_fn=<NllLossBackward0>) tensor(2.2928, grad_fn=<NllLossBackward0>) tensor(2.2989, grad_fn=<NllLossBackward0>) tensor(2.2968, grad_fn=<NllLossBackward0>) tensor(2.2982, grad_fn=<NllLossBackward0>) tensor(2.2912, grad_fn=<NllLossBackward0>) tensor(2.3005, grad_fn=<NllLossBackward0>) tensor(2.2909, grad_fn=<NllLossBackward0>) tensor(2.2940, grad_fn=<NllLossBackward0>) tensor(2.2959, grad_fn=<NllLossBackward0>) tensor(2.2993, grad_fn=<NllLossBackward0>) tensor(2.2933, grad_fn=<NllLossBackward0>) tensor(2.2951, grad_fn=<NllLossBackward0>) tensor(2.2824, grad_fn=<NllLossBackward0>) tensor(2.2987, grad_fn=<NllLossBackward0>) tensor(2.2961, grad_fn=<NllLossBackward0>) tensor(2.2914, grad_fn=<NllLossBackward0>) tensor(2.3025, grad_fn=<NllLossBackward0>) tensor(2.2895, grad_fn=<NllLossBackward0>) tensor(2.2943, grad_fn=<NllLossBackward0>) tensor(2.2974, grad_fn=<NllLossBackward0>) tensor(2.2977, grad_fn=<NllLossBackward0>) tensor(2.3069, grad_fn=<NllLossBackward0>) tensor(2.2972, grad_fn=<NllLossBackward0>) tensor(2.2979, grad_fn=<NllLossBackward0>) tensor(2.2932, grad_fn=<NllLossBackward0>) tensor(2.2940, grad_fn=<NllLossBackward0>) tensor(2.3014, grad_fn=<NllLossBackward0>) tensor(2.2958, grad_fn=<NllLossBackward0>) tensor(2.3013, grad_fn=<NllLossBackward0>) tensor(2.2953, grad_fn=<NllLossBackward0>) tensor(2.2951, grad_fn=<NllLossBackward0>) tensor(2.3116, grad_fn=<NllLossBackward0>) tensor(2.2916, grad_fn=<NllLossBackward0>) tensor(2.2871, grad_fn=<NllLossBackward0>) tensor(2.2975, grad_fn=<NllLossBackward0>) tensor(2.2950, grad_fn=<NllLossBackward0>) tensor(2.3039, grad_fn=<NllLossBackward0>) tensor(2.2901, grad_fn=<NllLossBackward0>) tensor(2.2950, grad_fn=<NllLossBackward0>) tensor(2.2958, grad_fn=<NllLossBackward0>) tensor(2.2893, grad_fn=<NllLossBackward0>) tensor(2.2917, grad_fn=<NllLossBackward0>) tensor(2.3001, grad_fn=<NllLossBackward0>) tensor(2.2988, grad_fn=<NllLossBackward0>) tensor(2.3069, grad_fn=<NllLossBackward0>) tensor(2.3083, grad_fn=<NllLossBackward0>) tensor(2.2841, grad_fn=<NllLossBackward0>) tensor(2.2932, grad_fn=<NllLossBackward0>) tensor(2.2857, grad_fn=<NllLossBackward0>) tensor(2.2971, grad_fn=<NllLossBackward0>) tensor(2.2999, grad_fn=<NllLossBackward0>) tensor(2.2911, grad_fn=<NllLossBackward0>) tensor(2.2977, grad_fn=<NllLossBackward0>) tensor(2.3027, grad_fn=<NllLossBackward0>) tensor(2.2940, grad_fn=<NllLossBackward0>) tensor(2.2939, grad_fn=<NllLossBackward0>) tensor(2.2950, grad_fn=<NllLossBackward0>) tensor(2.2951, grad_fn=<NllLossBackward0>) tensor(2.3000, grad_fn=<NllLossBackward0>) tensor(2.2935, grad_fn=<NllLossBackward0>) tensor(2.2817, grad_fn=<NllLossBackward0>) tensor(2.2977, grad_fn=<NllLossBackward0>) tensor(2.3067, grad_fn=<NllLossBackward0>) tensor(2.2742, grad_fn=<NllLossBackward0>) tensor(2.2964, grad_fn=<NllLossBackward0>) tensor(2.2927, grad_fn=<NllLossBackward0>) tensor(2.2941, grad_fn=<NllLossBackward0>) tensor(2.3003, grad_fn=<NllLossBackward0>) tensor(2.2965, grad_fn=<NllLossBackward0>) tensor(2.2908, grad_fn=<NllLossBackward0>) tensor(2.2885, grad_fn=<NllLossBackward0>) tensor(2.2984, grad_fn=<NllLossBackward0>) tensor(2.3009, grad_fn=<NllLossBackward0>) tensor(2.2931, grad_fn=<NllLossBackward0>) tensor(2.2856, grad_fn=<NllLossBackward0>) tensor(2.2907, grad_fn=<NllLossBackward0>) tensor(2.2938, grad_fn=<NllLossBackward0>) tensor(2.2880, grad_fn=<NllLossBackward0>) tensor(2.2975, grad_fn=<NllLossBackward0>) tensor(2.2922, grad_fn=<NllLossBackward0>) tensor(2.2966, grad_fn=<NllLossBackward0>) tensor(2.2804, grad_fn=<NllLossBackward0>)
9.3 神经网络优化多轮
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = Sequential(Conv2d(3,32,5,padding=2),MaxPool2d(2),Conv2d(32,32,5,padding=2),MaxPool2d(2),Conv2d(32,64,5,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # 随机梯度下降优化器
for epoch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距optim.zero_grad() # 梯度清零result_loss.backward() # 反向传播,计算损失函数的梯度optim.step() # 根据梯度,对网络的参数进行调优running_loss = running_loss + result_lossprint(running_loss) # 对这一轮所有误差的总和结果:
Files already downloaded and verified tensor(358.1069, grad_fn=<AddBackward0>) tensor(353.8411, grad_fn=<AddBackward0>) tensor(337.3790, grad_fn=<AddBackward0>) tensor(317.3237, grad_fn=<AddBackward0>) tensor(307.6762, grad_fn=<AddBackward0>) tensor(298.2425, grad_fn=<AddBackward0>) tensor(289.7010, grad_fn=<AddBackward0>) tensor(282.7116, grad_fn=<AddBackward0>) tensor(275.8972, grad_fn=<AddBackward0>) tensor(269.5961, grad_fn=<AddBackward0>) tensor(263.8480, grad_fn=<AddBackward0>) tensor(258.5006, grad_fn=<AddBackward0>) tensor(253.4671, grad_fn=<AddBackward0>) tensor(248.7994, grad_fn=<AddBackward0>) tensor(244.4917, grad_fn=<AddBackward0>) tensor(240.5728, grad_fn=<AddBackward0>) tensor(236.9719, grad_fn=<AddBackward0>) tensor(233.6264, grad_fn=<AddBackward0>) tensor(230.4298, grad_fn=<AddBackward0>) tensor(227.3427, grad_fn=<AddBackward0>)
9.4 神经网络学习率优化
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__() self.model1 = Sequential(Conv2d(3,32,5,padding=2),MaxPool2d(2),Conv2d(32,32,5,padding=2),MaxPool2d(2),Conv2d(32,64,5,padding=2),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # 随机梯度下降优化器
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=5, gamma=0.1) # 每过 step_size 更新一次优化器,更新是学习率为原来的学习率的的 0.1 倍
for epoch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距optim.zero_grad() # 梯度清零result_loss.backward() # 反向传播,计算损失函数的梯度optim.step() # 根据梯度,对网络的参数进行调优scheduler.step() # 学习率太小了,所以20个轮次后,相当于没走多少running_loss = running_loss + result_lossprint(running_loss) # 对这一轮所有误差的总和结果:
Files already downloaded and verified tensor(359.4722, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>) tensor(359.4630, grad_fn=<AddBackward0>)
相关文章:

9. 优化器
9.1 优化器 ① 损失函数调用backward方法,就可以调用损失函数的反向传播方法,就可以求出我们需要调节的梯度,我们就可以利用我们的优化器就可以根据梯度对参数进行调整,达到整体误差降低的目的。 ② 梯度要清零,如果梯…...

go学习之流程控制语句
文章目录 流程控制语句1.顺序控制2.分支控制2.1单分支2.2双分支单分支和双分支的四个题目switch分支结构 3.循环控制for循环控制while 和do...while的实现 4.跳转控制语句breakcontinuegotoreturngotoreturn 流程控制语句 介绍:在程序中,程序运行的流程…...

docker基于已有容器和通过Dockerfile进行制作镜像配置介绍
目录 一.制作镜像的两种方式 1.在已有容器中更新并提交这个镜像 2.使用Dockerfile来制作 二.基于容器制作镜像 1.格式 (1)主要格式 (2)可选参数 2.案例 基于容器创建镜像设置标签并进行验证是否可用 (1&…...

2022年09月 C/C++(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
第1题:最长上升子序列 一个数的序列bi,当b1 < b2 < … < bS的时候,我们称这个序列是上升的。对于给定的一个序列(a1, a2, …, aN),我们可以得到一些上升的子序列(ai1, ai2, …, aiK),这里1 < i1 < i2 &…...
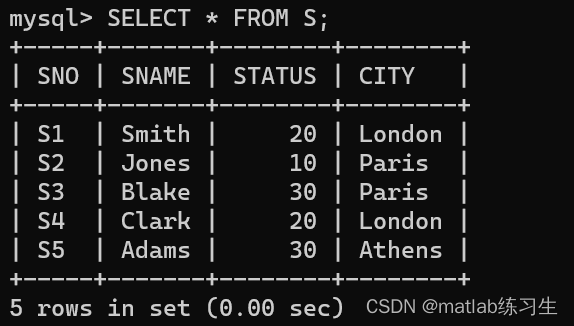
二级MySQL(九)——表格数据处理练习
在Mysql中,可以用INSERT或【REPLACE】语句,向数据库中已一个已有的表中插入一行或多行记录。 在Mysql中,可以用【DELETE】或【TRUNCATE】语句删除表中的所有记录。 在Mysql中,可以用【UPDATE】语句来修改数据表中的记录。 为了完…...

QT ListQvector at赋值出错以及解决办法 QT基础入门【QT存储结构】
1、问题 error: passing const QString as this argument discards qualifiers error: assignment of read-only location vec.QVector<int>::at(0) 在Qt中QList,Qvector一般获取元素都是通过at(index)来获取,但是at()的返回是一个const & 常引用,也就是元素不支…...

STM32 CubeMX (H750)RGB屏幕 LTDC
STM32 CubeMX STM32 RGB888 LTDC STM32 CubeMX一、STM32 CubeMX 设置时钟树LTDC使能设置屏幕参数修改RGB888的GPIO 二、代码部分效果 RGB屏幕线束定义: 一、STM32 CubeMX 设置 时钟树 这里设置的时钟,关于刷新速度 举例子:LCD_CLK24MHz 时…...

Redis问题集合(三)在Redis容器里设置键值对
前言 前提是已经拉取了Redis镜像并创建了对应的容器做个记录,方便后续查看 步骤 查看Redis容器的ID:docker ps -a 进入容器:docker exec -it 容器ID /bin/bash进入redis命令行:redis-cli输入密码:auth 配置密码 查看…...
spark中排查Premature EOF: no length prefix available
报错信息 /07/22 10:20:28 WARN DFSClient: Error Recovery for block BP-888461729-172.16.34.148-1397820377004:blk_15089246483_16183344527 in pipeline 172.16.34.64:50010, 172.16.34.223:50010: bad datanode 172.16.34.64:50010 [DataStreamer for file /bdp/data/u9…...

numpy高级函数之where和extract函数
1 numpy.where() 函数返回输入数组中满足给定条件的元素的索引 ---------------------------------------------------- 代码: n1np.random.randint(10,20,10) n2np.where(n1>15) 结果: [17 15 19 15 12 10 16 11 15 13] #原始数组 (array([…...

用Python写一个武侠游戏
前言 在本教程中,我们将使用Python写一个武侠类的游戏,大的框架全部搭好了,很多元素都可以自己添加,让游戏更丰富 📝个人主页→数据挖掘博主ZTLJQ的主页 个人推荐python学习系列: ☄️爬虫JS逆向系列专栏 -…...

Java --- 异常处理
目录 一、什么是异常 二、异常抛出机制 三、如何对待异常 四、 Java异常体系 4.1、Throwable 4.2、Error 4.2、Exception 4.2.1、编译时异常 4.2.2、运行时期异常 五、异常处理 5.1、捕获异常(try-catch) 5.1.2、catch中异常处理方式 …...
CDN/DCDN(全站加速)排查过程中如何获取Eagle ID/UUID
目录 前言1.通过浏览器直接访问文件时获取Request ID 前言 阿里云CDN/DCDN(全站加速)为接收到的每个请求分配唯一的服务器请求ID,作为关联各类日志信息的标识符。当您在使用CDN/DCDN(全站加速)过程中遇到错误且希望阿里云技术支持提供协助时,需要提交失…...

网络安全应急响应预案培训与演练目的
1、增强网络安全意识 网络安全事故隐患往往“生成”于无形。例如,漏洞或黑客攻 击发生之时,受害方企事业单位可能处于非常危险的境地而无所察 觉,一些内部部门人员的网络安全意识也容易懈怠。但不论是内部 员工的疏忽还是管理上的大意&am…...

2023年高教社杯 国赛数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

7.Oracle视图创建与使用
1、视图的创建与使用 在所有进行的SQL语句之中,查询是最复杂的操作,而且查询还和具体的开发要求有关,那么在开发过程之中,程序员完成的并不是是和数据库的所有内容,而更多的是应该考虑到程序的设计结构。可以没有一个项…...

rust学习-不安全操作
在 Rust 中,不安全代码块用于避开编译器的保护策略 四种不安全操作 解引用裸指针通过 FFI (Foreign Function Interface,外部语言函数接口)调用函数调用不安全的函数内联汇编(inline assembly)解引用裸指针 原始指针(raw pointer,裸指针)* 和引用 &T 有类似的功…...
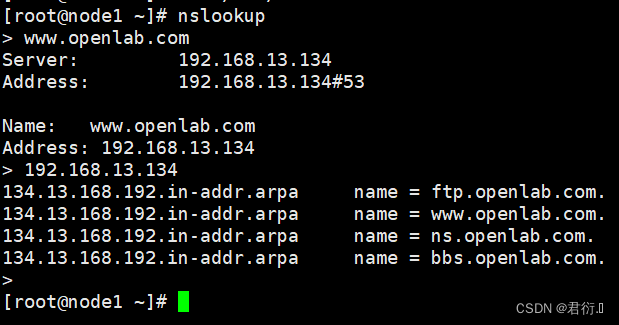
RHCE——八、DNS域名解析服务器
RHCE 一、概述1、产生原因2、作用3、连接方式4、因特网的域名结构4.1 拓扑4.2 分类4.3 域名服务器类型划分 二、DNS域名解析过程1、分类2、解析图:2.1 图:2.2 过程分析 三、搭建DNS域名解析服务器1、概述2、安装软件3、/bind服务中三个关键文件4、配置文…...

flink cdc初始全量速度很慢原因和优化点
link cdc初始全量速度很慢的原因之一是,它需要先读取所有的数据,然后再写入到目标端,这样可以保证数据的一致性和顺序。但是这样也会导致数据的延迟和资源的浪费。flink cdc初始全量速度很慢的原因之二是,它使用了Debezium作为捕获…...
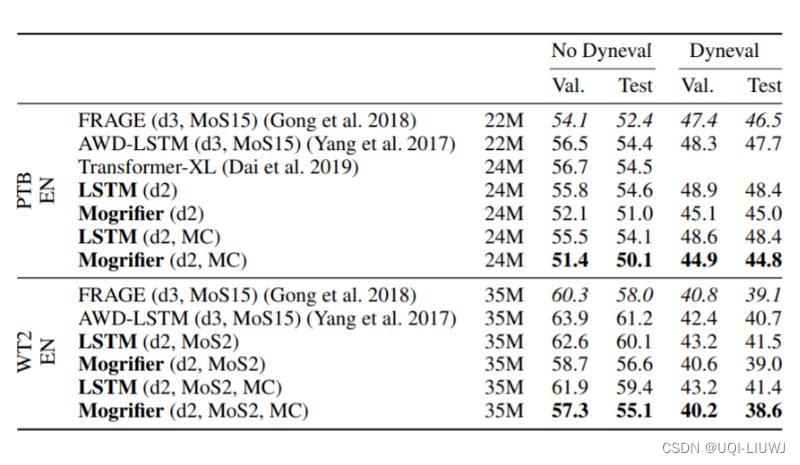
论文笔记: MOGRIFIER LSTM
2020 ICLR 修改传统LSTM 当前输入和隐藏状态充分交互,从而获得更佳的上下文相关表达 1 Mogrifier LSTM LSTM的输入X和隐藏状态H是完全独立的 机器学习笔记:GRU_gruc_UQI-LIUWJ的博客-CSDN博客这篇论文想探索,如果在输入LSTM之前…...

2026年度能耗监测系统的深度分析与展望
在当前全球可持续发展的大背景下,能耗监测系统的重要性愈发凸显。随着技术的进步和社会对节能减排的需求,2026年度的能耗监测系统将迎来一场技术革命和应用升级。本文将从市场需求、技术现状、未来发展方向及实施策略等多个方面,对2026能耗监…...

HiveWE:基于C++20模块化架构的下一代魔兽争霸III地图创作引擎
HiveWE:基于C20模块化架构的下一代魔兽争霸III地图创作引擎 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE HiveWE作为开源社区驱动的魔兽争霸III地图编辑器,通过现代C20模块化架构重…...

三引脚压电陶瓷片:从自激振荡原理到高效驱动电路设计
1. 三引脚压电陶瓷片为何成为硬件工程师的新宠 第一次接触三引脚压电陶瓷片时,我和大多数工程师一样充满疑惑:为什么要在传统两引脚结构上增加第三个引脚?直到在某个低功耗项目中,传统它激式蜂鸣器耗电量超出预期,我才…...

imFile下载管理器:从入门到精通的免费全能下载解决方案
imFile下载管理器:从入门到精通的免费全能下载解决方案 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop imFile是一款功能全面的免费下载管理器,支持HTTP、FTP、…...

GeoServer部署实战与前端地图调用跨域配置详解
1. GeoServer快速部署指南 第一次接触GeoServer的朋友可能会觉得这个开源地图服务器有点神秘,其实它的安装比想象中简单得多。我在多个项目中部署过不同版本的GeoServer,总结出了一套最稳妥的安装流程。GeoServer本质上是一个基于Java的Web应用ÿ…...

veil:专为AI智能体设计的无头浏览器自动化工具
1. 项目概述:为AI智能体打造的“隐形之手”如果你正在构建或使用AI智能体,并且希望它能像真人一样操作浏览器——登录社交平台、发布内容、浏览网页、点击按钮——那么你很可能已经感受到了传统自动化工具的掣肘。Selenium、Puppeteer这些工具很棒&#…...
)
告别手动重命名!Win10下用CMD脚本批量给照片加001-999编号(保姆级教程)
告别手动重命名!Win10下用CMD脚本批量给照片加001-999编号(保姆级教程) 每次整理上百张照片时,最痛苦的就是一张张手动重命名。作为一名经常需要处理大量素材的自媒体创作者,我试过各种方法——从资源管理器的F2快捷键…...

RK3368安卓9.0升级后卡Recovery?手把手教你分析串口日志定位NAND/EMMC分区问题
RK3368安卓9.0升级卡Recovery?串口日志深度分析与NAND/EMMC分区修复实战 当RK3368平台设备在升级Android 9.0固件后卡在Recovery界面时,这往往意味着底层存储设备的分区加载机制出现了问题。作为一名嵌入式开发者,能够从串口日志中抽丝剥茧定…...

从零构建开源语音AI交互中枢:EchoKit Server部署与调优指南
1. 项目概述:构建你自己的语音AI交互中枢 如果你对智能音箱、语音助手这类设备感兴趣,但又觉得市面上的产品要么功能封闭,要么隐私堪忧,那么今天聊的这个项目——EchoKit Server,可能会让你眼前一亮。简单来说&#x…...

深入u-boot目录结构:以全志V3s的LicheePi Zero为例,理解每个文件夹的作用
深入解析u-boot目录结构:全志V3s平台下的LicheePi Zero实践指南 当你第一次打开u-boot源码仓库时,面对密密麻麻的目录结构可能会感到无从下手。作为嵌入式系统开发中至关重要的启动加载程序,u-boot的架构设计既体现了通用性又兼顾了平台特异…...