《机器学习核心技术》分类算法 - 决策树
「作者主页」:士别三日wyx
「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者
「推荐专栏」:小白零基础《Python入门到精通》
决策树
- 1、决策树API
- 2、决策时实际应用
- 2.1、获取数据集
- 2.2、划分数据集
- 2.3、决策树处理
- 2.4、模型评估
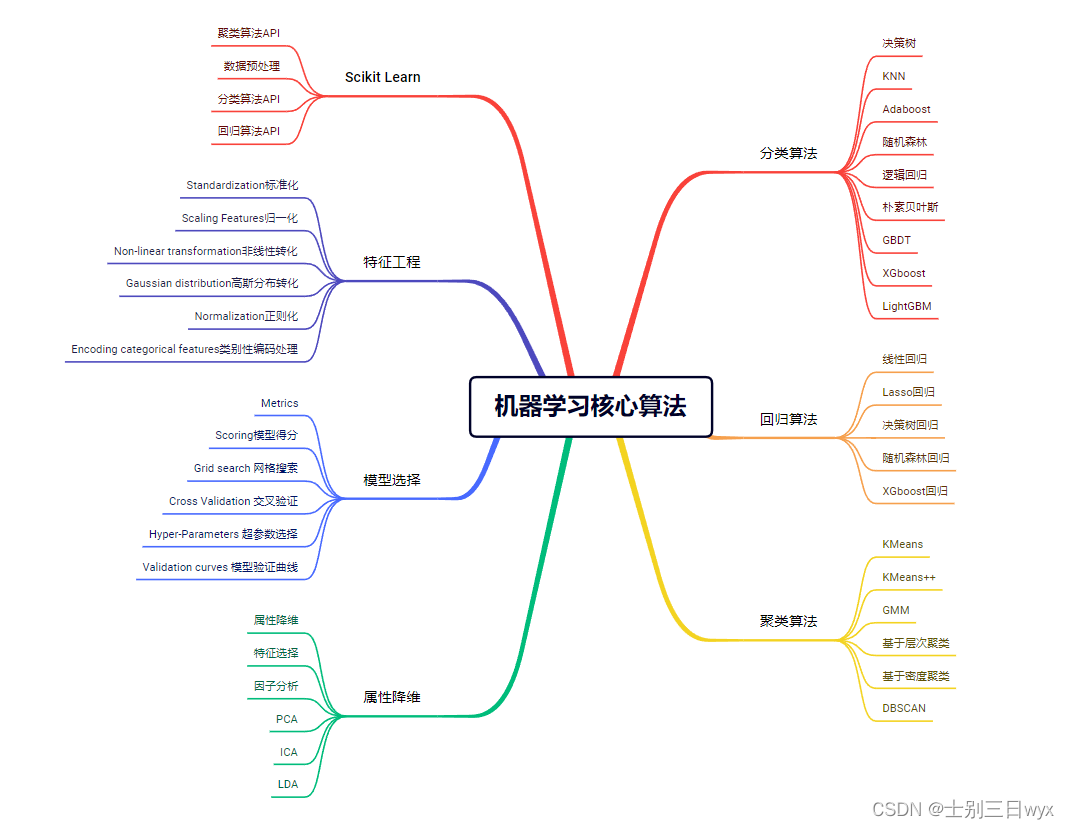
决策树是一种 「二叉树形式」的预测模型,每个 「节点」对应一个 「判断条件」, 「满足」上一个条件才能 「进入下一个」判断条件。
就比如找对象,第一个条件肯定是长得帅,长得帅的才考虑下一个条件;长得不帅就直接pass,不往下考虑了。
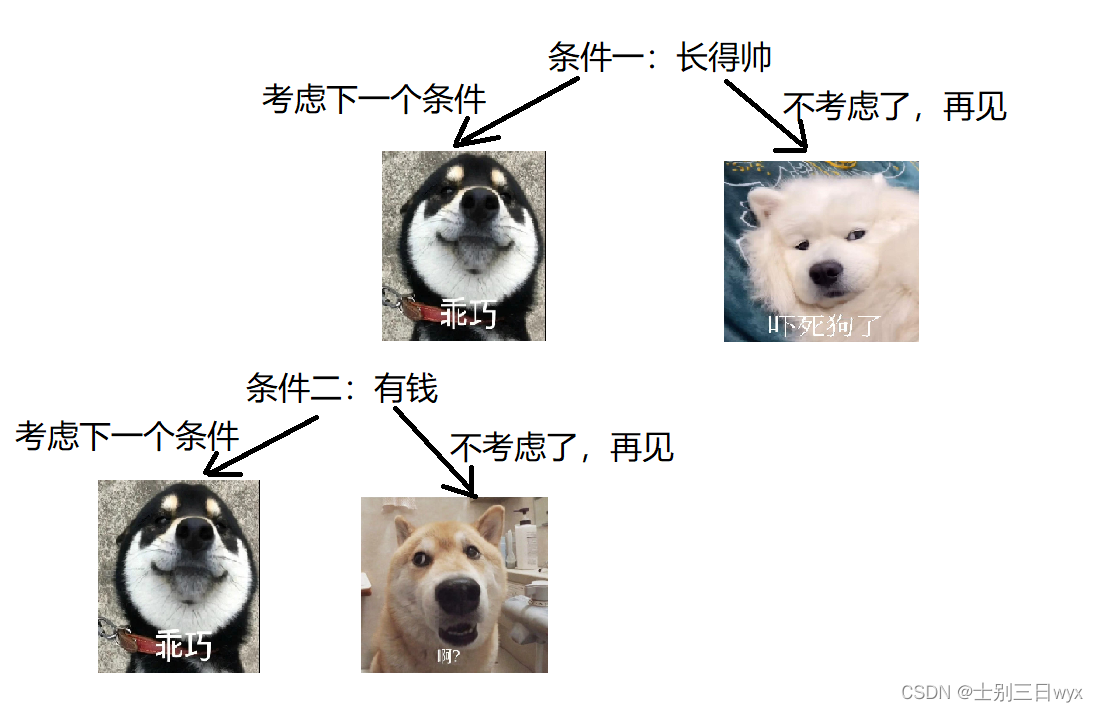
决策树的「核心」在于:如何找到「最高效」的「决策顺序」。
1、决策树API
sklearn.tree.DecisionTreeClassifier() 是决策树分类算法的API
参数
- criterion:(可选)衡量分裂的质量,可选值有
gini、entropy、log_loss,默认值gini - splitter:(可选)给每个节点选择分割的策略,可选值有
best、random,默认值best - max_depth:(可选)树的最大深度,默认值
None - min_samples_split:(可选)分割节点所需要的的最小样本数,默认值 2
- min_samples_leaf:(可选)叶节点上所需要的的最小样本数,默认值 1
- min_weight_fraction_leaf:(可选)叶节点的权重总和的最小加权分数,默认值 0.0
- max_features:(可选)寻找最佳分割时要考虑的特征数量,默认值
None - random_state:(可选)控制分裂特征的随机数,默认值
None - max_leaf_nodes:(可选)最大叶子节点数,默认值
None - min_impurity_decrease:(可选)如果分裂指标的减少量大于该值,就进行分裂,默认值 0.0
- class_weight:(可选)每个类的权重,默认值
None - ccp_alpha:(可选)将选择成本复杂度最大且小于ccp_alpha的子树。默认情况下,不执行修剪。
函数
- fit( x_train, y_train ):接收训练集特征 和 训练集目标
- predict( x_test ):接收测试集特征,返回数据的类标签。
- score( x_test, y_test ):接收测试集特征 和 测试集目标,返回准确率。
- predict_log_proba():预测样本的类对数概率
属性
- classes_:类标签
- feature_importances_:特征的重要性
- max_features_:最大特征推断值
- n_classes_:类的数量
- n_features_in_:特征数
- feature_names_in_:特征名称
- n_outputs_:输出的数量
- tree_:底层的tree对象
2、决策时实际应用
2.1、获取数据集
这里使用sklearn自带的鸢尾花数据集进行演示。
from sklearn import datasets# 1、获取数据集
iris = datasets.load_iris()
2.2、划分数据集
传入数据集的特征值和目标值,按照默认的比例划分数据集。
from sklearn import datasets
from sklearn import model_selection# 1、获取数据集
iris = datasets.load_iris()
# # 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target)
2.3、决策树处理
实例化对象,传入训练集特征值和目标值,开始训练。
from sklearn import datasets
from sklearn import model_selection
from sklearn import tree# 1、获取数据集
iris = datasets.load_iris()
# # 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target)
# # 3、决策树处理
estimator = tree.DecisionTreeClassifier()
estimator.fit(x_train, y_train)
2.4、模型评估
对比测试集,验证准确率。
from sklearn import datasets
from sklearn import model_selection
from sklearn import tree# 1、获取数据集
iris = datasets.load_iris()
# # 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target)
# # 3、决策树处理
estimator = tree.DecisionTreeClassifier()
estimator.fit(x_train, y_train)
# # 4、模型评估
y_predict = estimator.predict(x_test)
print('对比真实值和预测值', y_test == y_predict)
score = estimator.score(x_test, y_test)
print('准确率:', score)
输出:
对比真实值和预测值 [ True True True True True False True True True True True TrueFalse True True True True True True True True True True TrueTrue True True True True True True True True True True TrueTrue True]
准确率: 0.9473684210526315
从结果可以看到,准确率达到了94%
相关文章:
《机器学习核心技术》分类算法 - 决策树
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:小白零基础《Python入门到精通》 决策树 1、决策树API2、决策时实际应用2.1、获取数据集2.2、划分数据集2.3、决策…...
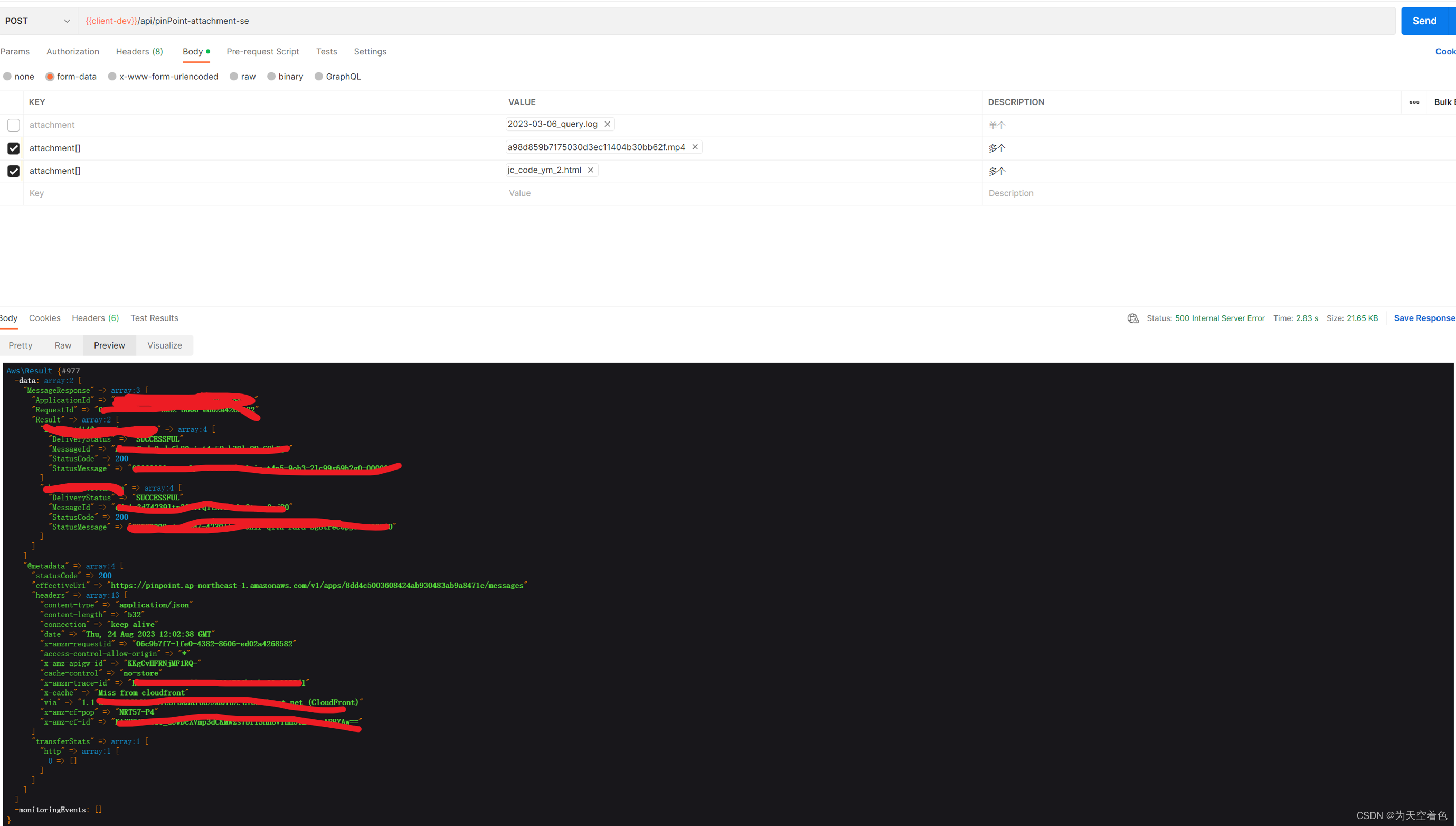
aws PinPoint发附件demo
php 版aws PinPoint发附件demo Laravel8框架,安装了"aws/aws-sdk-php": "^3.257" 主要代码: public function sendRawMail(Request $request) {$file $request->file(attachment);/*echo count($file);dd($file);*/$filenam…...
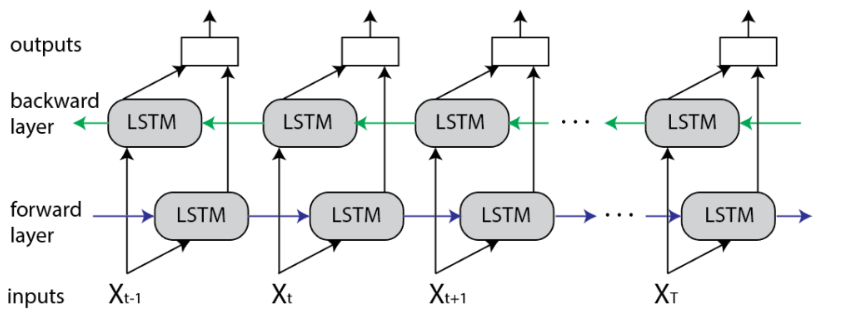
边写代码边学习之Bidirectional LSTM
1. 什么是Bidirectional LSTM 双向 LSTM (BiLSTM) 是一种主要用于自然语言处理的循环神经网络。 与标准 LSTM 不同,输入是双向流动的,并且它能够利用双方的信息。 它也是一个强大的工具,可以在序列的两个方向上对单词和短语之间的顺序依赖…...

Django学习笔记-实现联机对战
笔记内容转载自 AcWing 的 Django 框架课讲义,课程链接:AcWing Django 框架课。 CONTENTS 1. 统一长度单位2. 增加联机对战模式3. 配置Django Channels 1. 统一长度单位 多人模式中每个玩家所看到的地图相对来说应该是一样的,因此需要固定地…...
nacos总结1
5.Nacos注册中心 国内公司一般都推崇阿里巴巴的技术,比如注册中心,SpringCloudAlibaba也推出了一个名为Nacos的注册中心。 5.1.认识和安装Nacos Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比Eureka功能更加丰富,…...
Web安全测试(三):SQL注入漏洞
一、前言 结合内部资料,与安全渗透部门同事合力整理的安全测试相关资料教程,全方位涵盖电商、支付、金融、网络、数据库等领域的安全测试,覆盖Web、APP、中间件、内外网、Linux、Windows多个平台。学完后一定能成为安全大佬! 全部…...
Webstorm 入门级玩转uni-app 项目-微信小程序+移动端项目方案
1. Webstorm uni-app语法插件 : Uniapp Support Uniapp Support - IntelliJ IDEs Plugin | Marketplace 第一个是不收费,第二个收费 我选择了第二个Uniapp Support ,有试用30天,安装重启webstorm之后,可以提高生产率…...
| 集群分发脚本xsync)
从零开始的Hadoop学习(三)| 集群分发脚本xsync
1. Hadoop目录结构 bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件lib目录:存放Hadoop的本地库(对…...
golang http transport源码分析
golang http transport源码分析 前言 Golang http库在日常开发中使用会很多。这里通过一个demo例子出发,从源码角度梳理golang http库底层的数据结构以及大致的调用流程 例子 package mainimport ("fmt""net/http""net/url""…...
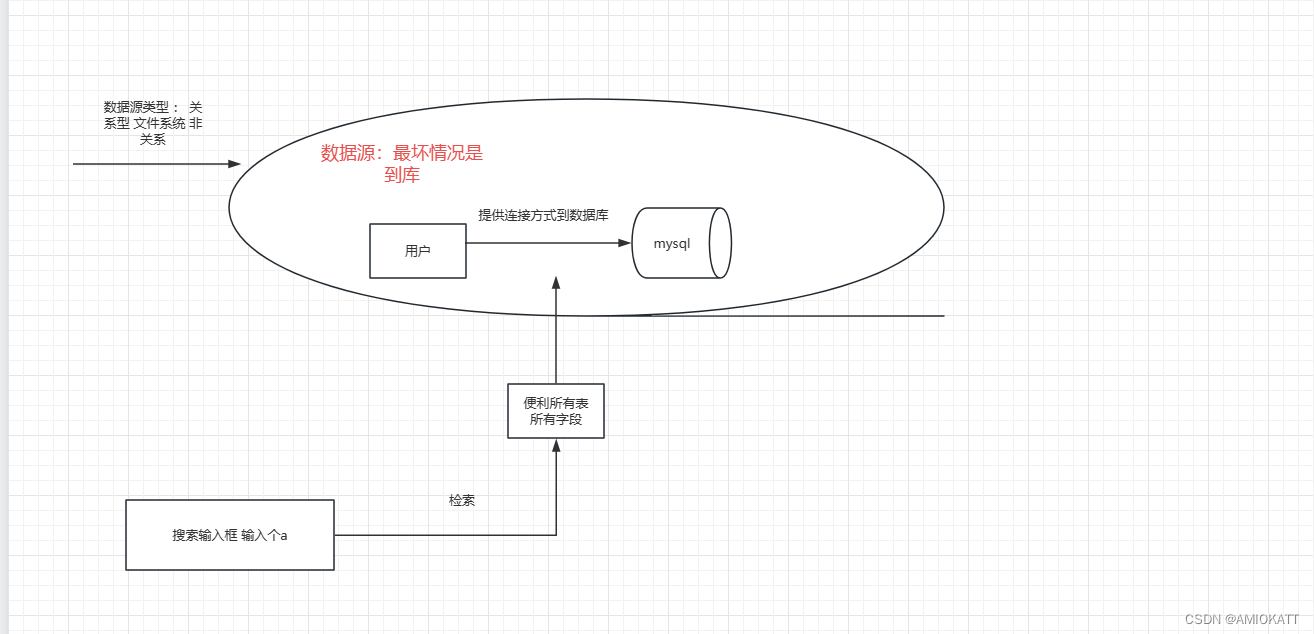
spring boot 项目整合 websocket
1.业务背景 负责的项目有一个搜索功能,搜索的范围几乎是全表扫,且数据源类型贼多。目前对搜索的数据量量级未知,但肯定不会太少,不仅需要搜索还得点击下载文件。 关于搜索这块类型 众多,未了避免有个别极大数据源影响整…...

统计学补充概念-17-线性决策边界
概念 线性决策边界是一个用于分类问题的线性超平面,可以将不同类别的样本分开。在二维空间中,线性决策边界是一条直线,将两个不同类别的样本分隔开来。对于更高维的数据,决策边界可能是一个超平面。 线性决策边界的一般形式可以表…...

指针变量、指针常量与常量指针的区别
指针变量、指针常量与常量指针 一、指针变量 定义:指针变量是指存放地址的变量,其值是地址。 一般格式:基类型 指针变量名;(int p) 关键点: 1、int * 表示一种指针类型(此处指int 类型),p(变量…...
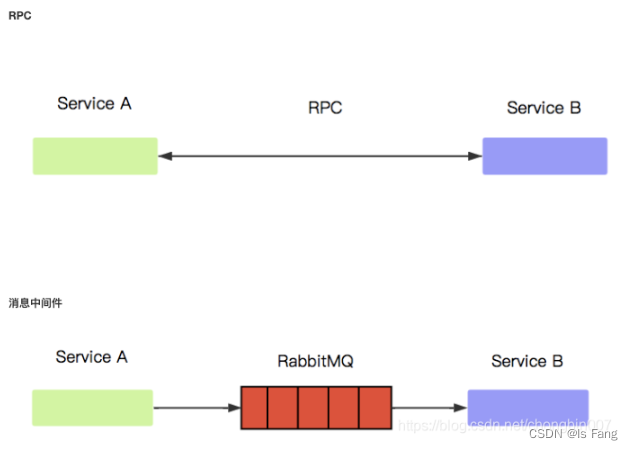
mq与mqtt的关系
文章目录 mqtt 与 mq的区别mqtt 与 mq的详细区别传统消息队列RocketMQ和微消息队列MQTT对比:MQ与RPC的区别 mqtt 与 mq的区别 mqtt:一种通信协议,规范 MQ:一种通信通道(方式),也叫消息队列 MQ…...
)
代码大全阅读随笔 (二)
软件设计 设计就是把需求分析和编码调试连在一起的活动。 设计不是在谁的头脑中直接跳出来了,他是不断的设计评估,非正式讨论,写实验代码以及修改实验代码中演化和完善。 作为软件开发人员,我们不应该试着在同一时间把整个程序都塞…...

vue 项目的屏幕自适应方案
方案一:使用 scale-box 组件 属性: width 宽度 默认 1920height 高度 默认 1080bgc 背景颜色 默认 "transparent"delay自适应缩放防抖延迟时间(ms) 默认 100 vue2版本:vue2大屏适配缩放组件(vu…...

23软件测试高频率面试题汇总
一、 你们的测试流程是怎么样的? 答:1.项目开始阶段,BA(需求分析师)从用户方收集需求并将需求转化为规格说明书,接 下来在项目组领导会组织需求评审。 2.需求评审通过后,BA 会组织项目经理…...

PHP8的匿名函数-PHP8知识详解
php 8引入了匿名函数(Anonymous Functions),它是一种创建短生命周期的函数,不需要命名,并且可以在其作用域内直接使用。以下是在PHP 8中使用匿名函数的知识要点: 1、创建匿名函数,语法格式如下&…...

Redis—Redis介绍(是什么/为什么快/为什么做MySQL缓存等)
一、Redis是什么 Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。 Redis 提供了多种数据类型来支持不同的业务场景,比如 String(字符串)、…...
C语言链表梳理-2
链表头使用结构体:struct Class 链表中的每一项使用结构体:struct Student#include <stdio.h>struct Student {char * StudentName;int StudentAge;int StudentSex;struct Student * NextStudent; };struct Class {char *ClassName;struct Stude…...
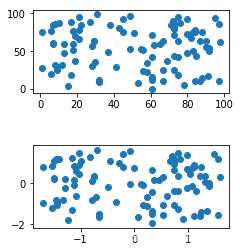
【深度学习】实验03 特征处理
文章目录 特征处理标准化归一化正则化 特征处理 标准化 # 导入标准化库 from sklearn.preprocessing import StandardScalerfrom matplotlib import gridspec import numpy as np import matplotlib.pyplot as plt import warnings warnings.filterwarnings("ignore&quo…...

MarkdownReader:重构浏览器文档阅读体验的渐进式渲染引擎
MarkdownReader:重构浏览器文档阅读体验的渐进式渲染引擎 【免费下载链接】markdownReader markdownReader is a extention for chrome, used for reading markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownReader 在当今技术文档创作与…...

5G NR里那个神秘的Timing Advance,到底是怎么让手机和基站‘对表’的?
5G NR中的Timing Advance:手机与基站如何实现精准"对表" 想象一下音乐会现场,指挥家轻轻抬起指挥棒,所有乐手在同一瞬间开始演奏——这种完美同步在5G网络中同样至关重要。当你的手机与基站通信时,电磁波以光速穿梭&…...

Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南
Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 深…...

英雄联盟智能助手League Akari:重新定义你的游戏体验边界
英雄联盟智能助手League Akari:重新定义你的游戏体验边界 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在英雄联盟的竞技世界中&…...

YOLOv5 COCO数据集 实战训练全流程解析 | 【从零到一】
1. 环境准备:从零搭建YOLOv5训练环境 第一次接触YOLOv5时,我最头疼的就是环境配置。记得当时为了一个CUDA版本问题折腾了整整两天,现在回想起来其实只要按步骤来就能避免90%的坑。下面是我总结的最稳环境搭建方案: 首先确保你的机…...

Speechless:你的微博时光机,一键备份珍贵回忆
Speechless:你的微博时光机,一键备份珍贵回忆 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社…...

AI账号自动化管理工具集:从注册到运维的全流程实战指南
1. 项目概述:一个AI账号自动化管理的“军火库”如果你正在批量使用ChatGPT、Claude、Gemini这些AI服务,或者在做一些相关的开发和研究,那你肯定遇到过这些让人头疼的问题:注册账号需要接码、管理几十上百个API密钥手忙脚乱、临时邮…...

tf_unet 实战应用:从玩具问题到射电天文干扰检测的完整案例
tf_unet 实战应用:从玩具问题到射电天文干扰检测的完整案例 【免费下载链接】tf_unet Generic U-Net Tensorflow implementation for image segmentation 项目地址: https://gitcode.com/gh_mirrors/tf/tf_unet Tensorflow U-Net 是一个通用的图像分割深度学…...

HBase集群部署避坑指南:从NoNode for /hbase/master错误到稳定启动
1. 遇到NoNode错误时别慌,先看懂它在说什么 第一次看到"HBase报错ERROR: KeeperErrorCode NoNode for /hbase/master"这个错误时,我正端着咖啡准备庆祝集群启动成功。结果这行红字直接给我泼了盆冷水——相信很多新手朋友都有类似的经历。这个…...

MotuBrain:一种用于机器人控制的高级世界动作模型
26年4月来自生数公司MotuBrain团队的论文“MotuBrain: An Advanced World Action Model for Robot Control”。 Motus [5] 建立一种统一的“世界-动作”建模范式,将视频与动作纳入同一个生成式框架中进行建模;借此,策略建模、世界建模、视频生…...