10 卷积神经网络CNN(基础篇)
文章目录
- 全连接
- CNN过程
- 卷积过程
- 下采样过程
- 全连接层
- 卷积原理
- 单通道卷积
- 多通道卷积
- 改进多通道
- 总结以及课程代码
- 卷积改进
- Padding
- Stride
- 下采样过程
- 大池化层(Max Pooling)
- 简单卷积神经网络的实现
- 课程代码
本篇课程来源: 链接
部分文本来源参考: 链接
以及强烈推荐Birandaの
全连接
前篇中的完全由线性层串行而形成的网络层为全连接层,即,对于某一层的每个输出都将作为下一层的输入。即作为下一层而言,每一个输入值和每一个输出值之前都存在权重。
在全连接层中,实际上是把原先空间状态上的信息,转换为了一维的信息,使得原有的空间相对位置所蕴含的信息丢失。
下文仍以MNIST数据集为例。
CNN过程
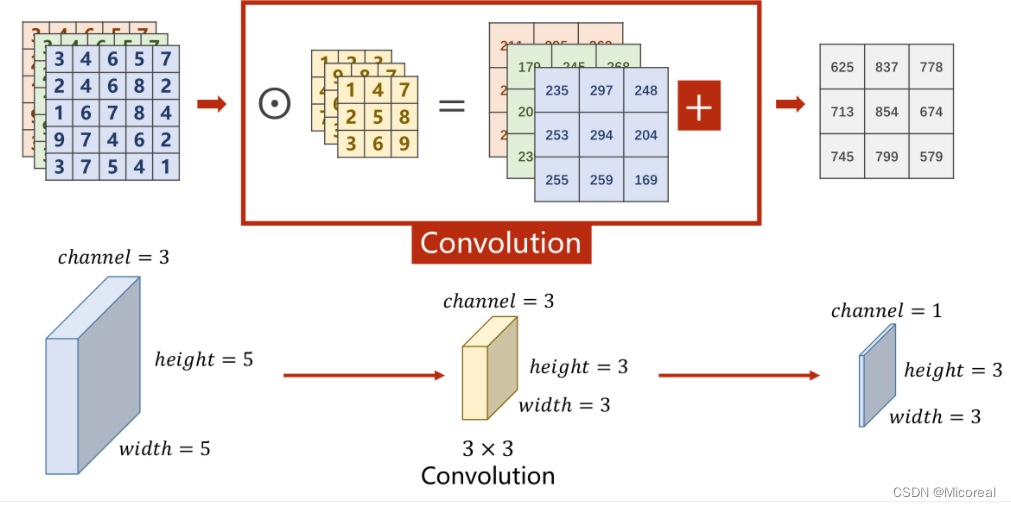
卷积实际上是把原始图像仍然按照空间的结构来进行保存数据。
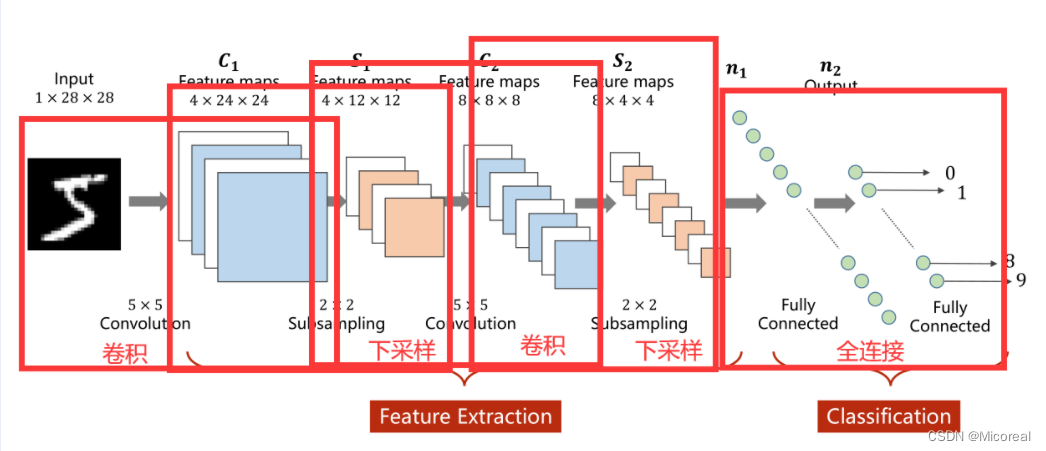
卷积过程
1×28×28指的是C(channle)×W(width)×H(Hight)C(channle) \times W(width) \times H(Hight)C(channle)×W(width)×H(Hight)即通道数 ×\times× 图像宽度 ×\times× 图像高度,通道可以理解为层数,通过同样大小的多层图像堆叠才形成了最原始的图。
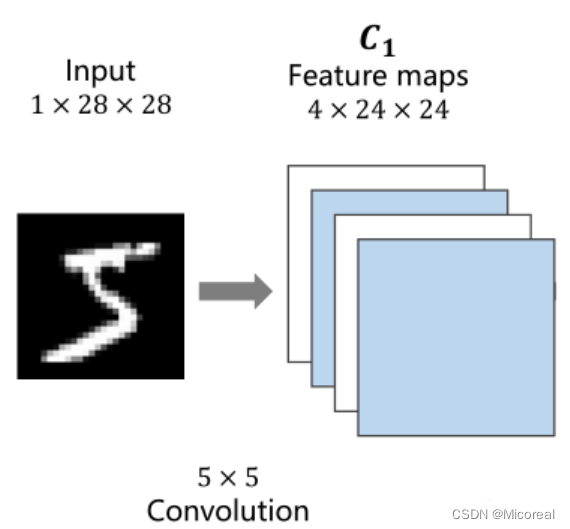
可以抽象的理解成原先的图是一个立方体性质的,卷积是将立方体的长宽高按照新的比例进行重新分割而成的。
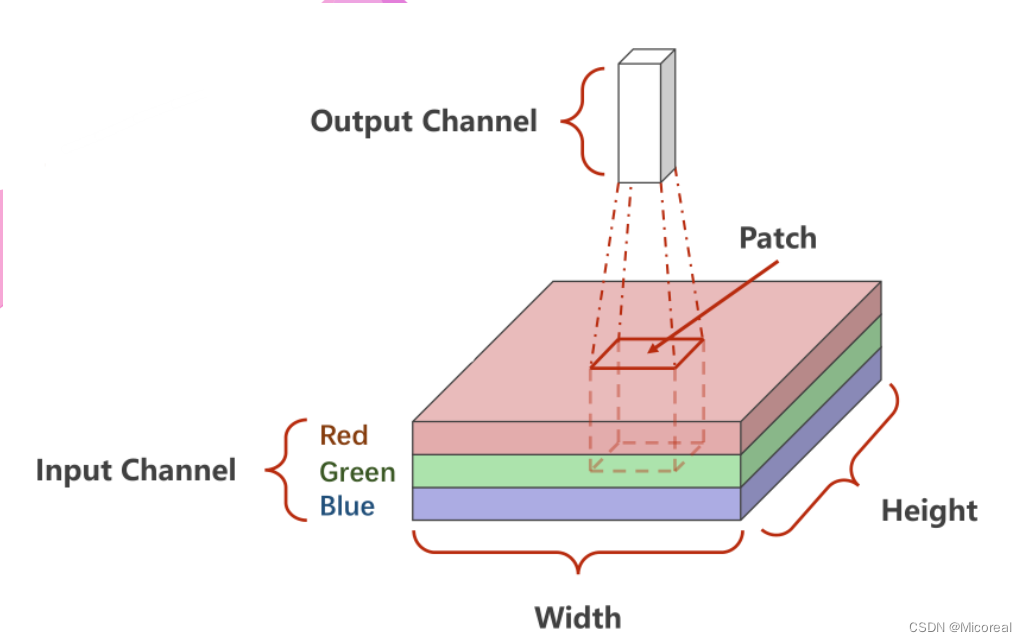
如下图所示,底层是一个3×W×H3 \times W \times H3×W×H的原始图像,卷积的处理是每次对其中一个Patch进行处理,也就是从原数图像的左上角开始依次抽取一个3×W′×H′3 \times W' \times H'3×W′×H′的图像对其进行卷积,输出一个C′×W′′×H′′C' \times W'' \times H''C′×W′′×H′′的子图。
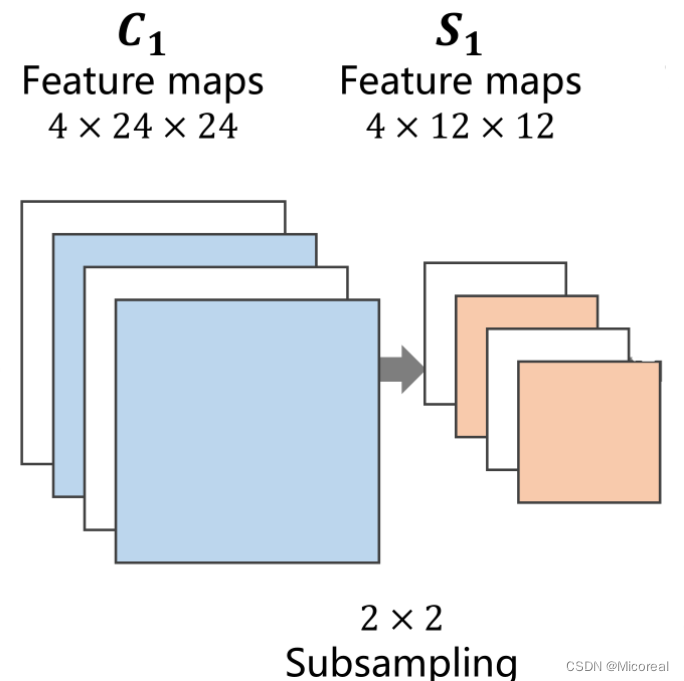
下采样过程
下采样的目的是减少特征图像的数据量,降低运算需求。在下采样过程中,通道保持不变,图像的宽度和高度发生改变
全连接层
先将原先多维的卷积结果通过全连接层转为一维的向量,再通过多层全连接层将原向量转变为可供输出的向量。
在前文的卷积过程与下采样过程,实际上是一种特征提取的手段或者过程,真正用于分类的过程是后续的全连接层。
卷积原理
单通道卷积
设定对于规格为1×W×H1 \times W \times H1×W×H的原图,利用一个规格为1×W′×H′1 \times W' \times H'1×W′×H′的卷积核进行卷积处理的数乘操作。
则需要从原始数据的左上角开始依次选取与核的规格相同(1×W′×H′1 \times W' \times H'1×W′×H′)的输入数据进行数乘操作,并将求得的数值作为一个Output值进行填充。
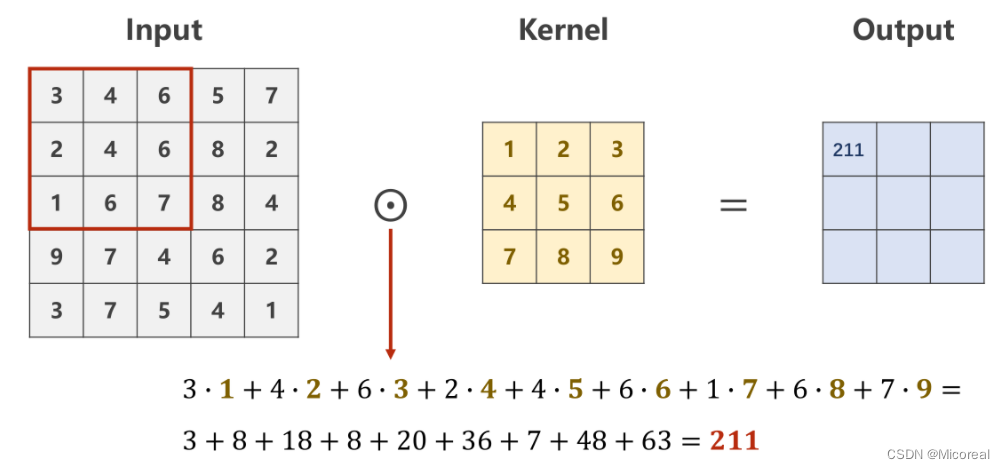
Patch在原图上进行滑动时,每次只滑动一个像素,即包含重复计算的部分
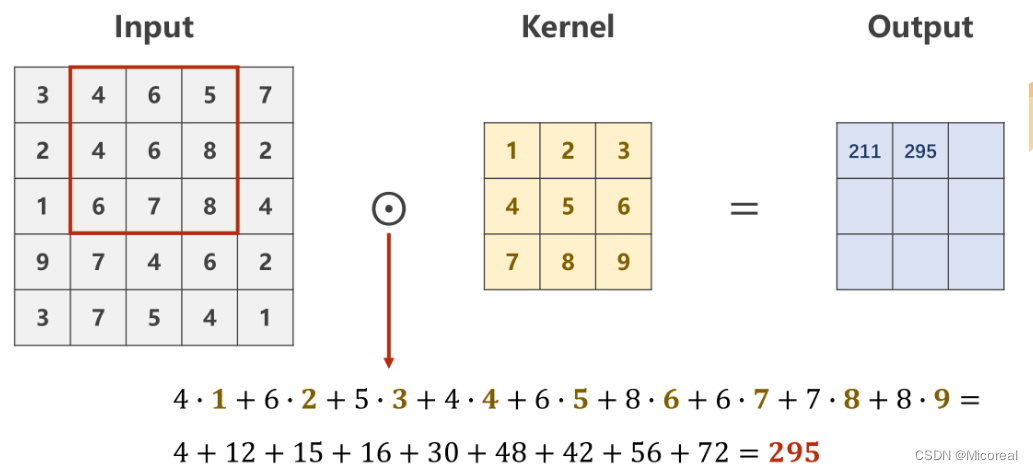
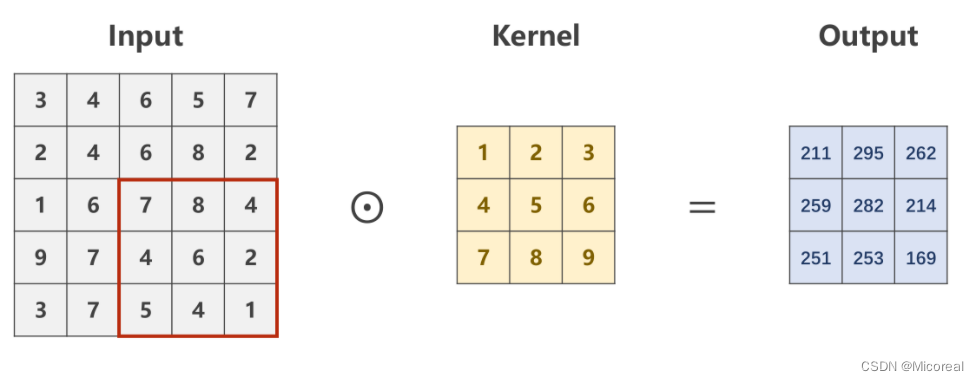
最后求得的Output的像素矩阵,即是对原图像,在设定的卷积核下的卷积结果,是一个规格为1×W′×H′1 \times W' \times H'1×W′×H′的图像。
多通道卷积
对于多通道图像(N×W×HN \times W \times HN×W×H),每一个通道是一个单通道的图像(1×W×H1 \times W \times H1×W×H)都要有一个自己的卷积核(1×W′×H′1 \times W' \times H'1×W′×H′)来进行卷积。
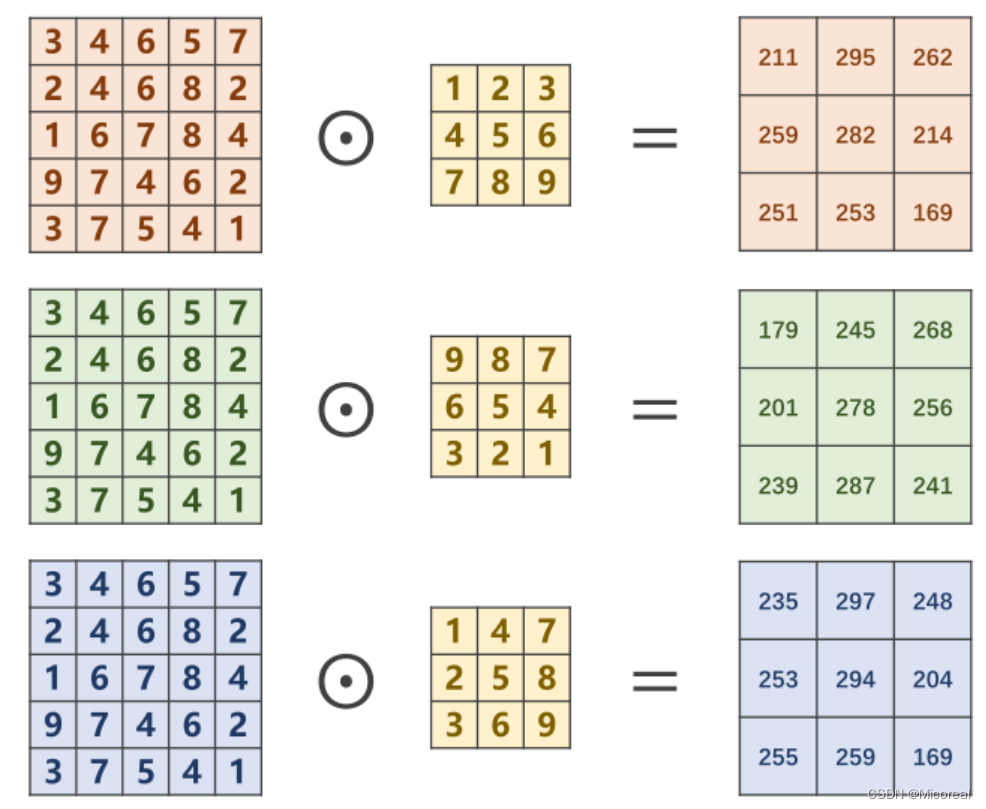
对于分别求出来的矩阵,需要再次进行求和才能得到最后的输出矩阵,最终的输出矩阵仍然是一个1×W′×H′1 \times W' \times H'1×W′×H′的 图像。
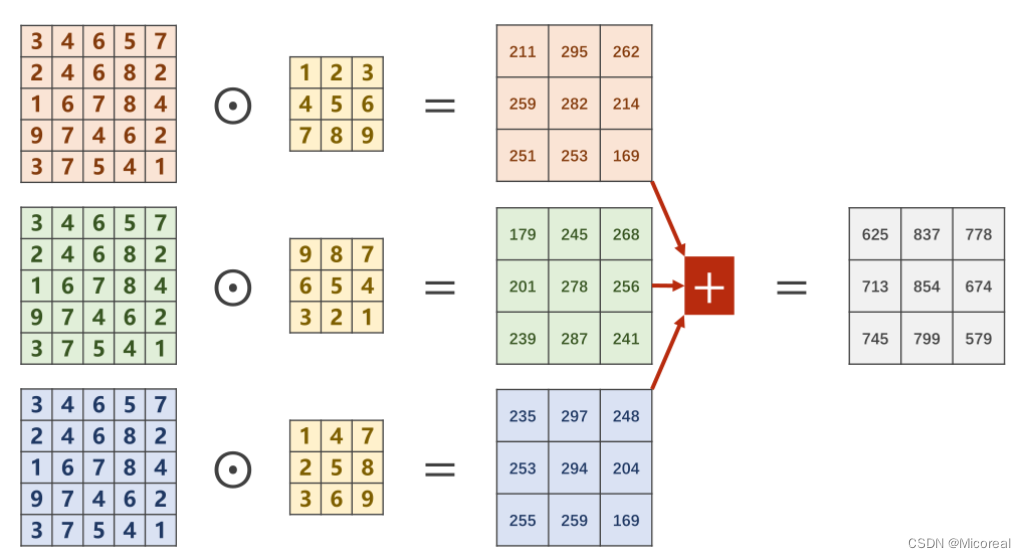
将平面的图像转为立体的角度即如下图
改进多通道
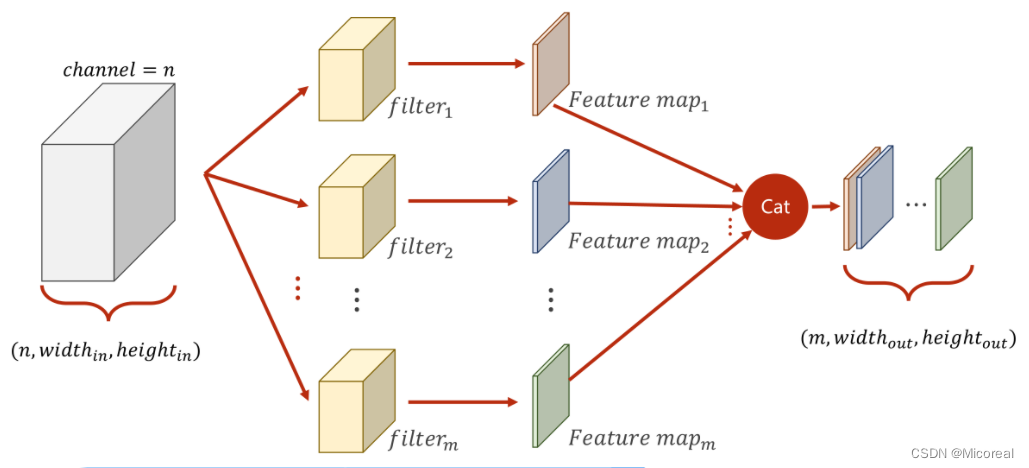
多通道卷积中,每次只能把NNN个通道转变为1个通道,而无法在通道这个维度进行增加或降低。
因此,为了对通道进行更加灵活的操作,可以将原先N×W×HN \times W \times HN×W×H的图像,利用不同的卷积核对其多次求卷积,由于每次求卷积之后的输出图像为1×W′×H′1 \times W' \times H'1×W′×H′,若一共求解了MMM次,即可以将此MMM次的求解结果按顺序在通道(Channel)这一维度上进行拼接,以此来形成一个规格为M×W′×H′M \times W' \times H'M×W′×H′的图像。
总结以及课程代码
- 每个卷积核的通道数与原通道数一致
- 卷积核的数量与输出通道数一致
- 卷积核的大小与图像大小无关
上述中所提到的卷积核,是指的多通道的卷积核,而非前文中提到的二维的。
综上所述为了使下图所表征的过程成立,即若需要使得原本为n×widthin×heightinn \times width_{in} \times height_{in}n×widthin×heightin的图像转变为一个m×widthout×heightoutm \times width_{out} \times height_{out}m×widthout×heightout的图像,可以利用mmm个大小为n×kernel_sizewidth×kernel_sizeheightn \times kernel\_size_{width} \times kernel\_size_{height}n×kernel_sizewidth×kernel_sizeheight的卷积核。

则在实际操作中,即可抽象为利用一个四维张量作为卷积核,此四维张量的大小为m×n×kernel_sizewidth×kernel_sizeheightm \times n \times kernel\_size_{width} \times kernel\_size_{height}m×n×kernel_sizewidth×kernel_sizeheight
import torch
in_channels, out_channels = 5, 10
width, height = 100, 100kernel_size = 3 #默认转为3*3,最好用奇数正方形#在pytorch中的数据处理都是通过batch来实现的
#因此对于C*W*H的三个维度图像,在代码中实际上是一个B(batch)*C*W*H的四个维度的图像
batch_size = 1#生成一个四维的随机数
input = torch.randn(batch_size, in_channels, width, height)#Conv2d需要设定,输入输出的通道数以及卷积核尺寸
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size)output = conv_layer(input)print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
输出结果:

卷积改进
Padding
若对于一个大小为N×NN \times NN×N的原图,经过大小为M×MM \times MM×M的卷积核卷积后,仍然想要得到一个大小为N×NN \times NN×N的图像,则需要对原图进行Padding,即外围填充。
例如,对于一个5×55 \times 55×5的原图,若想使用一个3×33 \times 33×3的卷积核进行卷积,并获得一个同样5×55 \times 55×5的图像,则需要进行Padding,通常外围填充0
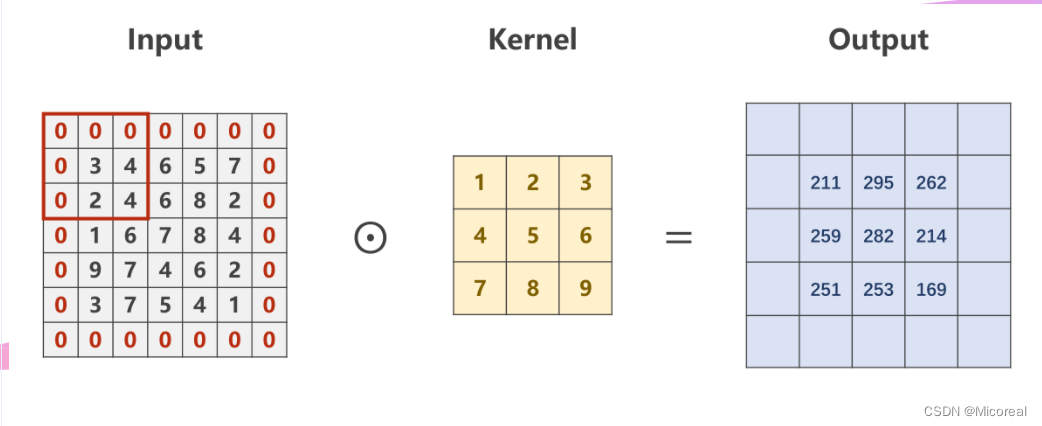
input = [3,4,6,5,7,2,4,6,8,2,1,6,7,8,4,9,7,4,6,2,3,7,5,4,1]#将输入变为B*C*W*H
input = torch.Tensor(input).view(1, 1, 5, 5)#偏置量bias置为false
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)#将卷积核变为CI*CO*W*H
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)#将做出来的卷积核张量,赋值给卷积运算中的权重(参与卷积计算)
conv_layer.weight.data = kernel.dataoutput = conv_layer(input)print(output)
Stride
本质上即是Batch的步长,在Batch进行移动时,每次移动Stride的距离,以此来有效降低图像的宽度与高度。
例如,对于一个5×55 \times 55×5的原图,若想使用一个3×33 \times 33×3的卷积核进行卷积,并获得一个2×22 \times 22×2的图像,则需要进行Stride,且Stride=2
import torch
input = [3,4,6,5,7,2,4,6,8,2,1,6,7,8,4,9,7,4,6,2,3,7,5,4,1]#将输入变为B*C*W*H
input = torch.Tensor(input).view(1, 1, 5, 5)#偏置量bias置为false
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)#将卷积核变为CI*CO*W*H
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)#将做出来的卷积核张量,赋值给卷积运算中的权重(参与卷积计算)
conv_layer.weight.data = kernel.dataoutput = conv_layer(input)print(output)
下采样过程
大池化层(Max Pooling)
对于一个M×MM \times MM×M图像而言,通过最大池化层可以有效降低其宽度和高度上的数据量,例如通过一个N×NN \times NN×N的最大池化层,即将原图分为若干个N×NN \times NN×N大小的子图,并在其中选取最大值填充到输出图中,此时输出图的大小为MN×MN\frac{M}{N} \times \frac{M}{N}NM×NM 。
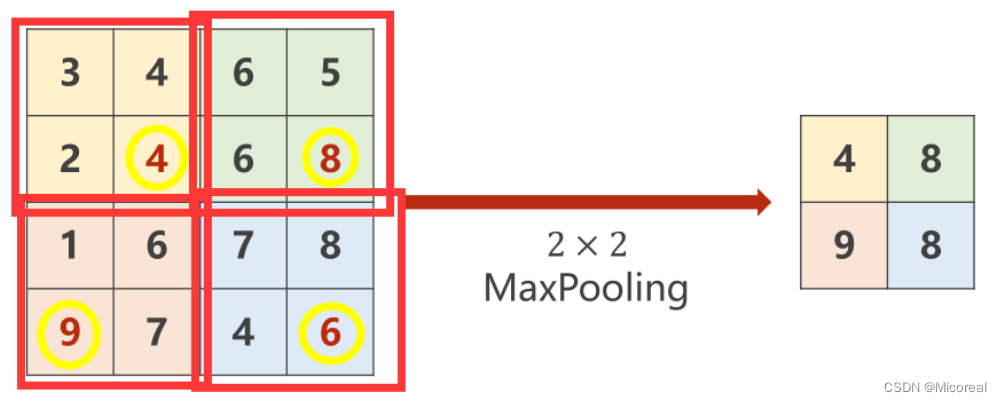
import torch
input = [3,4,6,5,2,4,6,8,1,6,7,8,9,7,4,6]input = torch.Tensor(input).view(1, 1, 4, 4)#kernel_size=2 则MaxPooling中的Stride也为2
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)output = maxpooling_layer(input)print(output)
简单卷积神经网络的实现
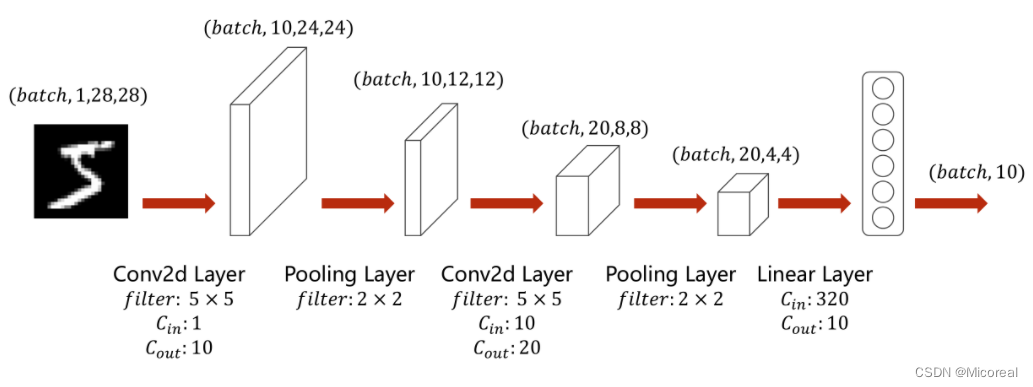
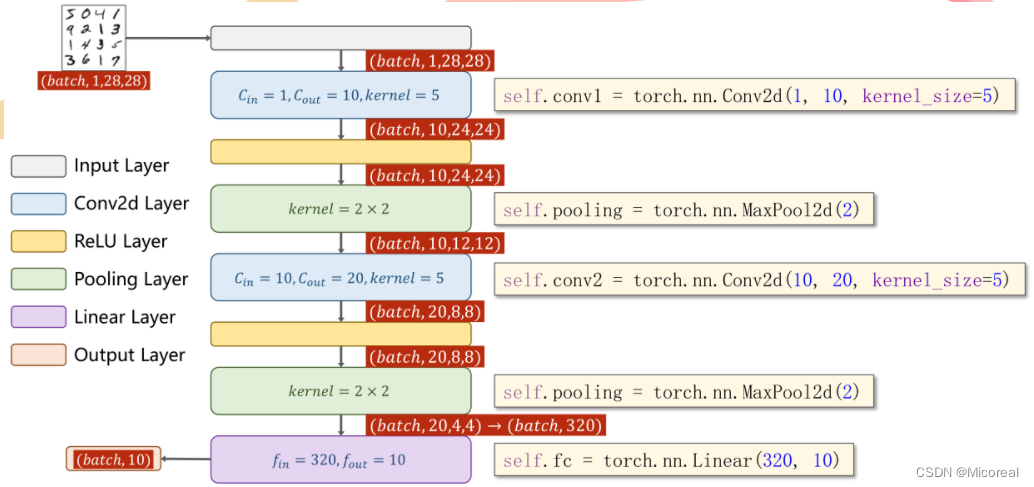
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):batch_size = x.size(0)x = self.pooling(F.relu(self.conv1(x)))x = self.pooling(F.relu(self.conv2(x)))x = x.view(batch_size, -1)x = self.fc(x)return x
课程代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此处自动算出的是320x = self.fc(x)return xmodel = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100*correct/total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()
相关文章:
10 卷积神经网络CNN(基础篇)
文章目录全连接CNN过程卷积过程下采样过程全连接层卷积原理单通道卷积多通道卷积改进多通道总结以及课程代码卷积改进PaddingStride下采样过程大池化层(Max Pooling)简单卷积神经网络的实现课程代码本篇课程来源: 链接部分文本来源参考&#…...

Windows下LuaBridge2.8的环境配置及简单应用
Windows下LuaBridge2.8的环境配置及简单应用 LuaBridge2.8下载链接: https://github.com/vinniefalco/LuaBridge/tags 关于Lua的环境配置可参考以下链接(这里不做简述): https://ufgnix0802.blog.csdn.net/article/details/125341…...

每天10个前端小知识 【Day 10】
前端面试基础知识题 1. es5 中的类和es6中的class有什么区别? 在es5中主要是通过构造函数方式和原型方式来定义一个类,在es6中我们可以通过class来定义类。 class类必须new调用,不能直接执行。 class类执行的话会报错,而es5中…...

【LeetCode】1223. 掷骰子模拟
1223. 掷骰子模拟 题目描述 有一个骰子模拟器会每次投掷的时候生成一个 1 到 6 的随机数。 不过我们在使用它时有个约束,就是使得投掷骰子时,连续 掷出数字 i 的次数不能超过 rollMax[i](i 从 1 开始编号)。 现在,…...

SPSS数据分析软件的安装与介绍(附网盘链接)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
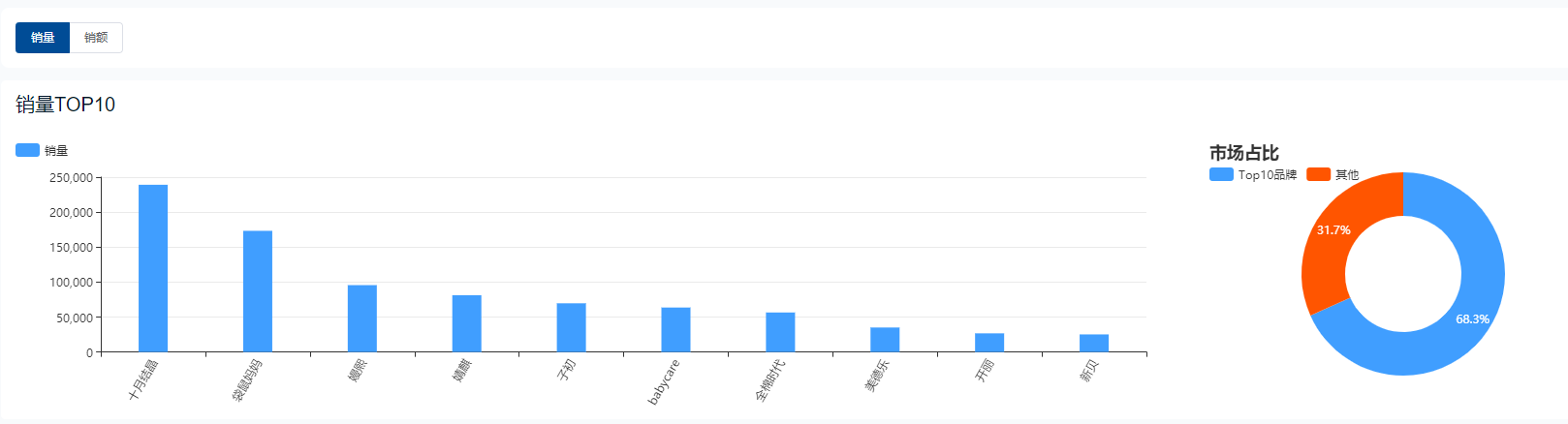
2022年38女神节大促美妆、珠宝、母婴、保健电商数据回顾
近期,我们陆续接收到了品牌商家朋友们对于2022年女神节大促期间部分品类的数据需求,希望能对今年的大促活动有一个更宏观的认知、更精准的预测,从而拿到更好的数据效果。 为此,在距离大促开启一个月的备货阶段,鲸参谋决…...

Java笔记-线程同步
目录线程的同步---以三个窗口售票100张为例方式一:同步代码块方式二:同步方法使用同步机制的作用:线程的同步—以三个窗口售票100张为例 (1)问题:卖票的过程出现重票和错票 (2)原因…...
通过python 调用OpenAI api_key提交问题解答
通过python 调用OpenAI api_key提交问题解答✨可以通过网页版的jupyter notebook调用,也可以通过spyder窗口等IDE窗口. 🌼通过python 调用OpenAI api_key接口,可以避免国内网页不能访问的问题。前提是需要自己已经注册了OpenAI帐号ÿ…...
图表控件LightningChart .NET再破世界纪录,支持实时可视化 1 万亿个数据点
LightningChart.NET SDK 是一款高性能数据可视化插件工具,由数据可视化软件组件和工具类组成,可支持基于 Windows 的用户界面框架(Windows Presentation Foundation)、Windows 通用应用平台(Universal Windows Platfor…...
什么是响应性?
响应性: 这个术语在今天的各种编程讨论中经常出现,但人们说它的时候究竟是想表达什么意思呢?本质上,响应性是一种可以使我们声明式地处理变化的编程范式。一个经常被拿来当作典型例子的用例即是 Excel 表格: 这里单元…...
黑马】后台管理176-183
一、新建订单管理的分支二、创建一个订单管理的vue文件进行组件页面的路由配置import Order from ../components/order/Order.vue{path:/orders,component:Order},注意上面的components不要忘记少加一个s!三,获取后台数据面包屑导航粘贴过来文本输入框&a…...
通俗易懂详细教程)
Typescript - 类型守卫(typeof / in / instanceof / 自定义类型保护的类型谓词)通俗易懂详细教程
前言 类型守卫用于获取变量类型信息,通常使用在条件块语句中。类型守卫是返回布尔值的常规函数,接受一个类型并告诉 TypeScript 是否可以缩小到更具体的类型。类型守卫具有唯一的属性,可以确保测试的值返回的是布尔值类型。 TypeScript 使用了…...

6.8 左特征向量
特征值很复杂,除了普通的特征向量外,还有左特征向量和广义特征向量。先说说比较容易的左特征向量吧。它是这样定义的,AAA是一个矩阵,λ\lambdaλ是它的一个特征值,下面的向量yyy就是矩阵关于特征值的左特征向量left ei…...
10个自动化测试框架,测试工程师用起来
软件行业正迈向自主、快速、高效的未来。为了跟上这个高速前进的生态系统的步伐,必须加快应用程序的交付时间,但不能以牺牲质量为代价。快速实现质量是必要的,因此质量保证得到了很多关注。为了满足卓越的质量和更快的上市时间的需求…...

城市C友会【官方牵头更多的线下交流的机会,你有怎样的期待?】
文章目录🌟 课前小差🌟 长沙线下🌟 C友会你也可以是组织者🌟 线下交流提升价值🌟 官方与抖音合作?🌟 23年动起来🌟 写在最后🌟 课前小差 哈喽,大家好&#x…...

CSDN 编程竞赛二十七期题解
竞赛总览 CSDN 编程竞赛二十七期:比赛详情 (csdn.net) 四道题都不难,本来十分钟内就可以解决,但是这次竞赛bug比较多,体验不是很好。 竞赛题解 题目1、幸运数字 小艺定义一个幸运数字的标准包含三条:1、仅包含4或…...

RMI攻击中的ServerClient相互攻击反制
前言 前文中,我们分析了攻击Registry的两种方式,这里我们接着前面的内容,分析Server和Client的相互攻击方式。 Attacked Server Attacked By Client 首先我们搭建个示例,这里直接注册端和服务端放置在一起。 package pers.rm…...

值类型和引用类型
一、值类型和引用类型示例: 值类型:基本数据类型系列,如:int,float,bool,string,数组和结构体等。 引用类型:如:指针,slice切片,map&a…...
后端开发必懂nginx面试40问
什么是Nginx? Nginx是一个 轻量级/高性能的反向代理Web服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发,现在中国使用ngin…...

Redis为什么这么快?
1.基于内存存储实现 在MySQL数据库中,所有的读写操作都要通过IO的方式从硬盘中获取。在Redis中,所有的操作都是基于内存实现的,从而减少IO操作提高数据库性能。 2.高效的数据结构 SAS简单动态字符串 字符串长度:SAS查询的时间复杂度O(1),c语言中时间复杂度O(n)空间分配来…...

B站成分检测器:3秒洞察评论区用户真实身份的智能工具
B站成分检测器:3秒洞察评论区用户真实身份的智能工具 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-checker 在B站…...

RISC-V PLIC中断控制器详解:从原理到SiFive U54实战配置
1. 平台级中断控制器(PLIC)是什么?为什么需要它?如果你正在接触基于RISC-V架构的嵌入式系统开发,尤其是像SiFive U54这样的多核处理器,那么“PLIC”这个缩写会频繁地出现在你的视野里。它全称是Platform-Le…...

终极指南:如何用GetQzonehistory完整备份你的QQ空间历史记录
终极指南:如何用GetQzonehistory完整备份你的QQ空间历史记录 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心QQ空间里的青春记忆会随着时间流逝而消失ÿ…...

AI智能体安全框架实战:从提示词注入防御到工具调用沙箱化
1. 项目概述:当AI智能体需要“安全管家”最近在折腾AI智能体(Agent)的开发,尤其是在尝试让它们接入外部工具和API时,一个绕不开的“老大难”问题就是安全性。你辛辛苦苦训练或调教好的智能体,一旦让它能执行…...

魔百和CM311-1A刷机后体验:S905L3A芯片+安卓9,到底能装哪些好玩的应用?
魔百和CM311-1A刷机后应用生态全攻略:释放S905L3A芯片的隐藏潜力 当你的魔百和CM311-1A成功刷入纯净安卓9系统后,这台搭载S905L3A芯片的设备便从一台普通电视盒子蜕变为开放式的娱乐中心。ADB功能默认开启的状态下,它的可能性只受限于你的想…...

【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告
更多请点击: https://intelliparadigm.com 第一章:【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告 现象复现与基准测试协议 我们在标准LIGO-PRL语料集(v2.3)上对NotebookLM…...

JetBrains IDE试用期重置技术全解析:从原理到实战的开发者指南
JetBrains IDE试用期重置技术全解析:从原理到实战的开发者指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在JetBrains IDE生态系统中,试用期管理是每个开发者都会面临的实际问题。ide…...

如何3分钟为Windows 11 LTSC系统恢复微软商店:一键安装完整指南
如何3分钟为Windows 11 LTSC系统恢复微软商店:一键安装完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否正在使用Windows 11…...

Go语言集成OpenAI智能体:从原理到工程实践
1. 项目概述:当Go语言遇上OpenAI智能体最近在GitHub上看到一个挺有意思的项目,叫openai-agents-go。光看名字,大概就能猜到它的定位:一个用Go语言实现的、基于OpenAI API的智能体(Agent)框架。对于咱们这些…...

Perseus:碧蓝航线皮肤解锁补丁的完整使用指南
Perseus:碧蓝航线皮肤解锁补丁的完整使用指南 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 你是否曾经在《碧蓝航线》中看到心仪的舰船皮肤,却因为需要付费而望而却步࿱…...