R语言常用数学函数
目录
1.+ - * / ^
2.%/%和%%
3.ceiling,floor,round
4.signif,trunc,zapsamll
5.max,min,mean,pmax,pmin
6.range和sum
7.prod
8.cumsum,cumprod,cummax,cummin
9.sort
10. approx
11.approx fun
12.diff
13.sign
14.var和sd
15.median
16.IQR
17.ave
18.fivenum
19.mad
20.quantile
21.stem
22.一维优化与求根
23.常用数学函数
24.高级数学函数
1.+ - * / ^
1.5 + 2.3 - 0.6 + 2.1*1.2 - 1.5/0.5 + 2^3## [1] 10.72#可以用圆括号改变优先级
1.5 + 2.3 - (0.6 + 2.1)*1.2 - 1.5/0.5 + 2^3## [1] 5.562.%/%和%%
5 %/% 3
## [1] 1
5 %% 3
## [1] 2
5.1 %/% 2.5
## [1] 2
5.1 %% 2.5
## [1] 0.13.ceiling,floor,round
#"ceiling"函数将输入的数字向上取整,返回大于或等于输入值的最小整数。ceiling(3.14) # 输出 4
ceiling(-2.5) # 输出 -2#"floor"函数将输入的数字向下取整,返回小于或等于输入值的最大整数。floor(3.14) # 输出 3
floor(-2.5) # 输出 -3#"round"函数将输入的数字四舍五入为最接近的整数。round(3.14) # 输出 3
round(-2.5) # 输出 -2#round第二个参数,指定要保留的位数
round(3.14159, 2)将返回保留两位小数的结果:3.144.signif,trunc,zapsamll
#signif函数用于保留指定有效数字位数
#它将输入的数字四舍五入到指定位数,并返回结果signif(3.14159, 3) # 输出 3.14
signif(1234.5678, 2) # 输出 1200#trunc函数截断(向零取整)输入的数字,即将小数部分去掉trunc(3.14) # 输出 3
trunc(-2.5) # 输出 -2#zapsmall函数用于移除非常接近零的小数误差
#它将输入的数字中非常小的值替换为零zapsmall(1e-10) # 输出 0
zapsmall(0.000000001) # 输出 0
5.max,min,mean,pmax,pmin
#max函数用于计算一组数中的最大值
#它接受多个参数或一个向量作为输入,并返回其中的最大值。max(2, 5, 1) # 输出 5
max(c(4, 6, 3)) # 输出 6#min函数用于计算一组数中的最小值
#它接受多个参数或一个向量作为输入,并返回其中的最小值。min(2, 5, 1) # 输出 1
min(c(4, 6, 3)) # 输出 3# 计算向量的平均值
x <- c(1, 2, 3, 4, 5)
avg <- mean(x)print(avg)
#输出 [1] 3#pmax函数用于逐个比较两个或多个向量中的相应元素
#并返回对应位置上的最大值向量pmax(c(1, 3, 5), c(2, 4, 6)) # 输出 2 4 6
pmax(c(1, 3, 5), c(2, 4, 6), c(0, 8, 7)) # 输出 2 8 7#pmin函数用于逐个比较两个或多个向量中的相应元素
#并返回对应位置上的最小值向量pmin(c(1, 3, 5), c(2, 4, 6)) # 输出 1 3 5
pmin(c(1, 3, 5), c(2, 4, 6), c(0, 8, 7)) # 输出 0 3 56.range和sum
#返回一个包含最小值和最大值的长度为2的向量range(c(2, 5, 1)) # 输出 1 5
range(1:10) # 输出 1 10#sum函数用于计算给定向量或数值序列的总和
#它接受一个向量作为输入,并返回所有元素的累加和sum(c(2, 5, 1)) # 输出 8
sum(1:10) # 输出 55
7.prod
#prod是用于计算一组数的乘积的函数prod(c(2, 3, 4)) # 输出 24,即 2 * 3 * 4#如果向量中存在0,则结果将始终为0prod(c(2, 0, 4)) # 输出 0,因为存在0#同样,如果向量中有任何非数值(例如字符或缺失值)
则结果将为NA(不可用)prod(c(2, "a", 4)) # 输出 NA,因为存在非数值元素
8.cumsum,cumprod,cummax,cummin
#cumsum函数用于计算给定向量或数值序列中元素的累积和cumsum(c(2, 3, 4))
# 输出 2 5 9,即 2, 2+3, 2+3+4#cumprod函数用于计算给定向量或数值序列中元素的累积乘积cumprod(c(2, 3, 4))
# 输出 2 6 24,即 2, 2*3, 2*3*4#cummax函数用于计算给定向量或数值序列中元素的累积最大值cummax(c(2, 3, 4, 1, 5))
# 输出 2 3 4 4 5,即 2, max(2,3), max(2,3,4), max(2,3,4,1), max(2,3,4,5)#cummin函数用于计算给定向量或数值序列中元素的累积最小值cummin(c(2, 3, 4, 1, 5))
# 输出 2 2 2 1 1,即 2, min(2,3), min(2,3,4), min(2,3,4,1),min(2,3,4,1,5)9.sort
(1)对向量排序
sort(c(3, 1, 4, 2)) # 输出 1 2 3 4
(2) 降序排序
sort(c(3, 1, 4, 2), decreasing = TRUE) # 输出 4 3 2 1
(3) 对数据框按照某列进行排序
df <- data.frame(x = c(3, 1, 4, 2), y = c("A", "B", "C", "D"))
sorted_df$x # 获取排序后的 x 列
sorted_df$y # 获取排序后的 y 列
sorted_df[1, ] # 获取排序后的第一行数据
(4) 降序排序
sorted_df <- df[order(df$x, decreasing = TRUE), ] # 按 x 列降序排序
10. approx
#approx函数用于执行线性插值或平滑插值
approx(x, y = NULL, xout, method = "linear", rule = 2, f = 0, ties = mean)常用参数
x:输入变量的向量。y:输出变量的向量。当进行插值时,需要提供此参数。xout:用于进行估计或插值的输出变量的取值点。这是一个可选的参数。method:指定插值方法,默认为"linear"(线性插值)。还可以选择"constant"(常数插值)或"spline"(样条插值)等。rule:在估计或插值点不在输入变量范围内时的处理规则。它控制如何对缺失值或超出范围的值进行处理。默认为2,表示生成具有最小相对误差的结果。f:自定义函数,用于在估计或插值点上执行特定的计算。ties:用于处理在估计或插值点存在多个匹配的情况下如何处理。
"ordered":根据输入变量x的顺序,按照与估计或插值点最接近的方式处理匹配值。默认情况下,ties参数设置为"mean"。"mean":将匹配值的平均值作为结果。如果有多个匹配值,将它们的平均值用于计算结果。"min":选择匹配值中的最小值作为结果。"max":选择匹配值中的最大值作为结果。
# 创建输入数据
x <- c(1, 2, 4, 5) # 输入变量 x
y <- c(3, 6, 2, 8) # 输出变量 y# 进行线性插值
interp <- approx(x, y, xout = seq(min(x), max(x), by = 0.1))# 输出结果
print(interp)

11.approx fun
# 自定义函数
my_fun <- function(x, y) {return(x^2 + y)
}# 创建输入数据
x <- c(1, 2, 4, 5)
y <- c(3, 6, 2, 8)# 使用自定义函数进行插值
interp <- approx(x, y, xout = seq(min(x), max(x), by = 0.1), f = my_fun)# 输出结果
print(interp)

12.diff
#diff函数用于计算向量或时间序列的差分
#对于长度为 n 的向量,diff函数将返回一个长度为 n-1 的向量
#其中第 i 个元素是原始向量中第 (i+1) 个元素减去第 i 个元素的结果。
vec <- c(2, 6, 5, 8, 3)diff_vec <- diff(vec)print(diff_vec)#输出 [1] 4 -1 3 -5
13.sign
sign函数用于返回给定数值的符号
- 如果输入值大于0,则返回1。
- 如果输入值等于0,则返回0。
- 如果输入值小于0,则返回-1。
num <- -5sign_num <- sign(num)print(sign_num)#输出 [1] -1
#因为-5是一个负数
14.var和sd
# 计算向量的方差和标准差
x <- c(1, 2, 3, 4, 5)variance <- var(x)
standard_deviation <- sd(x)print(variance)
print(standard_deviation)

15.median
# 计算向量的中位数
x <- c(1, 2, 3, 4, 5)median_value <- median(x)print(median_value)#输出 [1] 3
16.IQR
# 计算向量的四分位距
x <- c(1, 2, 3, 4, 5)iqr_value <- IQR(x)print(iqr_value)#输出 [1] 217.ave
用于根据某个变量对向量或数据框进行分组,并对每个组应用函数
# 创建一个数据框
df <- data.frame(name = c("Alice", "Bob", "Alice", "Charlie", "Charlie", "Bob"),score = c(85, 90, 92, 78, 80, 88)
)# 对数据框中的 score 列按 name 分组,计算每个组的平均值
average_scores <- ave(df$score, df$name, FUN = mean)print(average_scores)

18.fivenum
# 计算向量的五数概括统计量
#包括最小值、下四分位数、中位数、上四分位数和最大值
x <- c(1, 2, 3, 4, 5)fivenum_values <- fivenum(x)print(fivenum_values)

19.mad
# 计算向量的绝对中位差
x <- c(1, 2, 3, 4, 5)mad_value <- mad(x)print(mad_value)

20.quantile
# 计算向量的分位数
x <- c(1, 2, 3, 4, 5)# 计算四分位数
quartiles <- quantile(x, probs = c(0.25, 0.5, 0.75))print(quartiles)

21.stem
# 创建茎叶图
x <- c(12, 23, 34, 45, 56, 67, 78, 89, 90)stem(x)
22.一维优化与求根
(1)optimize
optimize()函数用于在给定区间内寻找一个函数的最小值或最大值。
#optimize(f, interval, maximum = FALSE, tol = .Machine$double.eps^0.25)#f 是要最小化或最大化的函数;
#interval 是定义函数的有效区间。
#maximum:一个逻辑值,用于指定是寻找最小值还是最大值。默认为 FALSE,表示寻找最小值。
#tol:一个数值,表示收敛容差(convergence tolerance)。默认值为 .Machine$double.eps^0.25,使用机器精度的推荐容差。f <- function(x) x^2 - 4 * x + 3result <- optimize(f, c(0, 5))
print(result$minimum) # 输出函数的最小值
#输出 [1] 2
(2)uniroot
uniroot()函数用于在给定区间内寻找一个函数的根
#uniroot(f, interval)
#f 是要寻找根的函数;interval 是定义函数的有效区间
f <- function(x) x^3 - 2 * x - 5result <- uniroot(f, c(1, 3))
print(result$root) # 输出函数的根#输出 [1] 2.094526(3)polyroot
polyroot()函数用于找到多项式函数的所有根
# polyroot(coeffs)
#coeffs 是一个包含多项式系数的向量coeffs <- c(1, -5, 4)roots <- polyroot(coeffs)
print(roots) # 输出多项式函数的所有根#输出 [1] 4+0i 1+0i
23.常用数学函数
#abs:获取数值的绝对值
abs(-5) # 输出 5
abs(3.14) # 输出 3.14#sqrt:计算数值的平方根
sqrt(9) # 输出 3
sqrt(2) # 输出 1.414213 #sin:正弦
sin(x)#cos:余弦
cos(x)#tan:正切
tan(x)#asin:反正弦
asin(x)#acos:反余弦
acos(x)#atan:反正切
atan(x)#atan2:给定y和x坐标的反正切
atan2(y,x)#sinh:双曲正弦值
sinh(x)#cosh:双曲余弦值
cosh(x)#tanh:双曲正弦值
tanh(x)#ashih:反双曲正弦值
ashih(x)#acosh:反双曲余弦值
acosh(x)#atanh:反双曲正切值
atanh(x)
24.高级数学函数
#beta函数:计算两个参数的Beta函数值beta(x,y)#lbeta函数:计算两个参数的Beta函数的自然对数lbeta(x,y)#gamma函数:计算给定参数的伽玛函数值gamma(x)#lgamma函数:计算给定参数的伽玛函数的自然对数lgamma(x)#digamma函数:计算给定参数的Ψ函数值(第一类对数勒让德函数)digamma(x)#digamma函数:计算给定参数的Ψ函数值(第一类对数勒让德函数)trigamma(x)#tetragamma函数:计算给定参数的Ψ函数的二阶导数值(第三类对数勒让德函数)tetragamma(x)#pentagamma函数:计算给定参数的Ψ函数的三阶导数值(第四类对数勒让德函数)pentagamma(x)#choose函数:计算组合数choose(n,k)#lchoose函数:计算组合数的自然对数lchoose(n,k)#fft函数:执行快速傅里叶变换(FFT),将信号从时域转换为频域。fft(x)#mvfft函数:执行多维傅里叶变换。mvfft(x)#convolve函数:计算两个向量的卷积(线性卷积)。convolve(x, y)#polyroot函数:找到多项式的根。polyroot(p)#polyroot函数:找到多项式的根。poly(x,degree)#spline函数:执行样条插值,生成平滑插值曲线。spline(x, y, xout)#splinefun函数:生成根据样条插值生成的函数。splinefun(x,y)参数 x:输入值。参数 nu:阶数。
#besselI函数:计算修正的贝塞尔函数I。besselI(x, nu)#besselK函数:计算修正的贝塞尔函数K。besselK(x,nu)#besselJ函数:计算贝塞尔函数J。besselJ(x, nu)#besselY函数:计算贝塞尔函数Y。besselY(x, nu)#gammaCody函数:计算递归修正伽玛函数。gammaCody(x)#deriv函数:对简单表达式进行符号微分或算法微分。deriv(expr, name)
如有新学习的知识会补充,如有错误或遗漏请大佬们不吝赐教!!💖💖💖
相关文章:

R语言常用数学函数
目录 1. - * / ^ 2.%/%和%% 3.ceiling,floor,round 4.signif,trunc,zapsamll 5.max,min,mean,pmax,pmin 6.range和sum 7.prod 8.cumsum,cumprod,cummax,cummin 9.sort 10. approx 11.approx fun 12.diff 13.sign 14.var和sd 15.median 16.IQR 17.ave 18.five…...
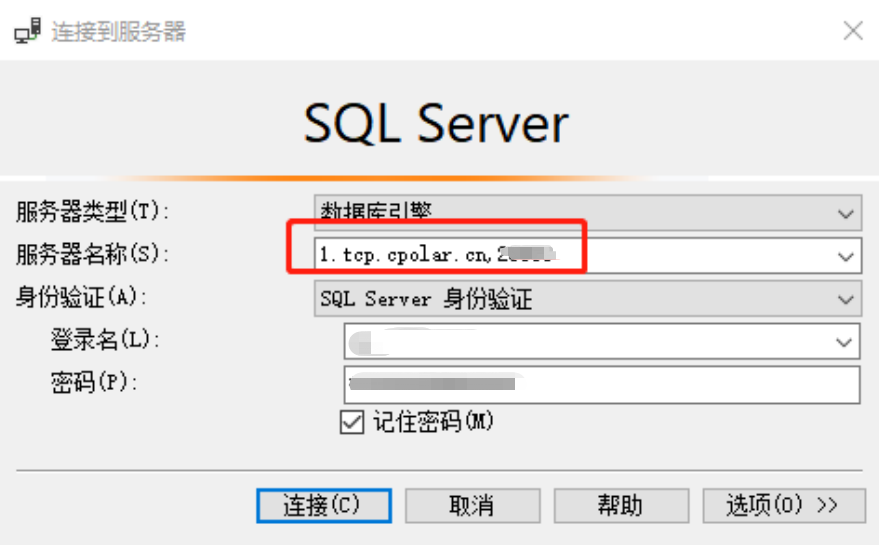
公网远程访问局域网SQL Server数据库
文章目录 1.前言2.本地安装和设置SQL Server2.1 SQL Server下载2.2 SQL Server本地连接测试2.3 Cpolar内网穿透的下载和安装2.3 Cpolar内网穿透的注册 3.本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4.公网访问测试5.结语 1.前言 数据库的重要性相信大家都有所了解&…...

Apache Celeborn 让 Spark 和 Flink 更快更稳更弹性
摘要:本文整理自阿里云/数据湖 Spark 引擎负责人周克勇(一锤)在 Streaming Lakehouse Meetup 的分享。内容主要分为五个部分: Apache Celeborn 的背景Apache Celeborn——快Apache Celeborn——稳Apache Celeborn——弹Evaluation…...
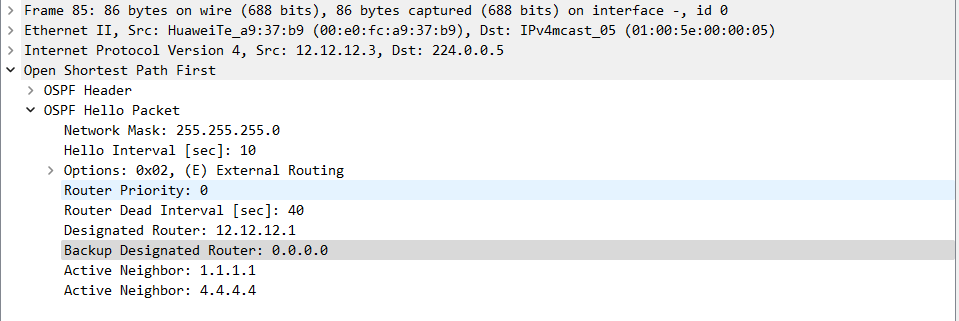
华为数通方向HCIP-DataCom H12-821题库(单选题:141-160)
第141题 Router-LSA 能够描述不同的链路类型,不属于Router LSA 链路类型的是以下哪一项? A、Link Type 可以用来描述到末梢网络的连接,即 SubNet B、Link Type 可以用来描述到中转网络的连接,即 TranNet C、Link Type 可以用来描述到另一…...

Windows-docker集成SRS服务器的部署和使用
Windows-docker集成SRS服务器的部署和使用 一、Windows Docker安装 Docker Desktop 官方下载地址: https://docs.docker.com/desktop/install/windows-install/ 下载windows版本的就可以了。 注意:此方法仅适用于 Windows 10 操作系统专业版、企业版、…...

element-ui table表格滚动条拉到最右侧 表头与内容不能对齐
1.问题概述 当表格数据太多,会出现纵向滚动条和横向滚动条,把横向滚动条拉到最右侧时,会出现表头与内容不能对齐的现象。 2.解决方法 1.当页面数据加载完毕后,在后面加上 this.$nextTick(() > {this.$refs.table.doLayout()…...

React中的性能测试工具组件Profiler的基本使用
React中的性能测试工具组件Profiler是一个非常有用的工具,它可以帮助我们分析React应用程序的性能瓶颈。在本文中,我们将学习如何使用Profiler组件来测试React应用程序的性能。 首先,让我们来了解一下Profiler组件的基本用法。在React中&…...

提升生产效率,降低运维成本:纺织业物联网网关应用
在众多物联网技术应用中纺织业正逐渐崭露头角。物联网技术通过无线连接纺织设备、PLC、传感器,实现了纺织厂的生产数据信息的远程监控和数据采集、远程管理,为企业提供了更高效、智能的生产方式。智联物联小编在本文中将重点介绍纺织业物联网的应用与通讯…...
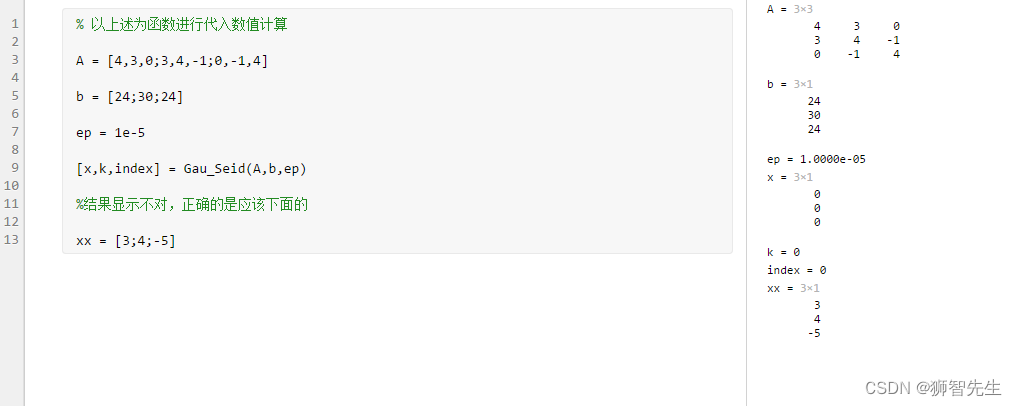
【学习笔记】求解线性方程组的G-S迭代法
求解线性方程组的G-S迭代法 // 运行不成功啊function [x,k,index] Gau_Seid(A,b,ep,it_max) % 求解线性方程组的G-S迭代法,其中 % A为方程组的系数矩阵 % b为方程组的右端项 % ep为精度要求,省缺为1e-5 % it_max为最大迭代次数,省缺为100 % …...
Kotlin协程flow缓冲buffer
Kotlin协程flow缓冲buffer 先看一个普通的flow: import kotlinx.coroutines.delay import kotlinx.coroutines.flow.* import kotlinx.coroutines.runBlocking import kotlin.system.measureTimeMillisfun main(args: Array<String>) {val delayTime 100Lru…...
完全免费的GPT,最新整理,2023年8月24日,已人工验证,不用注册,不用登录,更不用魔法,点开就能用
完全免费的ChatGPT,最新整理,2023年8月24日,已人工验证, 不用注册,不用登录,更不用魔法,点开就能用! 第一个:网址地址统一放在文末啦!文末直达 看上图你就能…...
LeetCode538. 把二叉搜索树转换为累加树
538. 把二叉搜索树转换为累加树 文章目录 [538. 把二叉搜索树转换为累加树](https://leetcode.cn/problems/convert-bst-to-greater-tree/)一、题目二、题解方法一:递归(中序遍历与节点更新)方法二:反向中序遍历与累加更新&#x…...

TP6 使用闭合语句查询多个or的模型语句
例子:查询出在单位表中所有的小学,初中和高中;其中school_period保存的就是学段数据$where []; $where[] function ($query) {$query->where(school_period, like, %小学%)->whereOr(school_period, like, %初中%)->whereOr(schoo…...

浅析Linux SCSI子系统:设备管理
文章目录 概述设备管理数据结构scsi_host_template:SCSI主机适配器模板scsi_host:SCSI主机适配器主机适配器支持DIF scsi_target:SCSI目标节点scsi_device:SCSI设备 添加主机适配器构建sysfs目录 添加SCSI设备挂载LunIO请求队列初…...
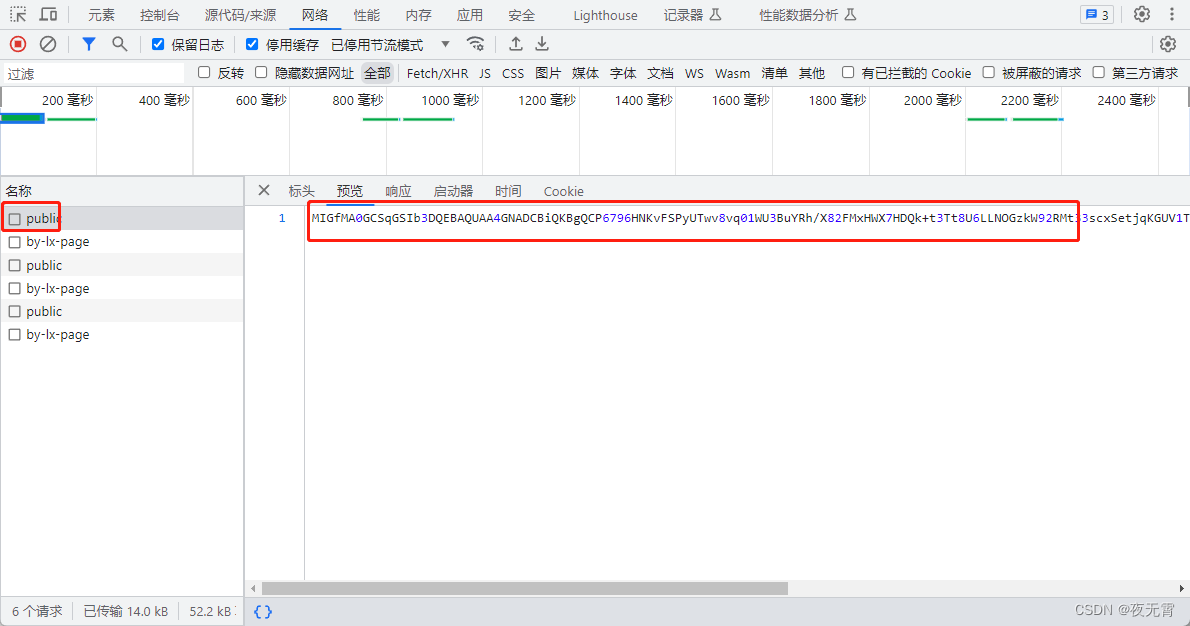
爬虫逆向实战(二十五)--某矿采购公告
一、数据接口分析 主页地址:某矿 1、抓包 通过抓包可以发现数据接口是cgxj/by-lx-page 2、判断是否有加密参数 请求参数是否加密? 通过查看“载荷”模块可以发现有一个param的加密参数 请求头是否加密? 无响应是否加密? 无c…...

DPLL 算法之分裂策略
前言 DPLL算法确实是基于树(或二叉树)的回溯搜索算法,它用于解决布尔可满足性问题(SAT问题)。下面我会分析您提到的DPLL算法中的分裂策略,以及它是如何在搜索过程中起作用的。 DPLL算法中的分裂策略是用于在…...
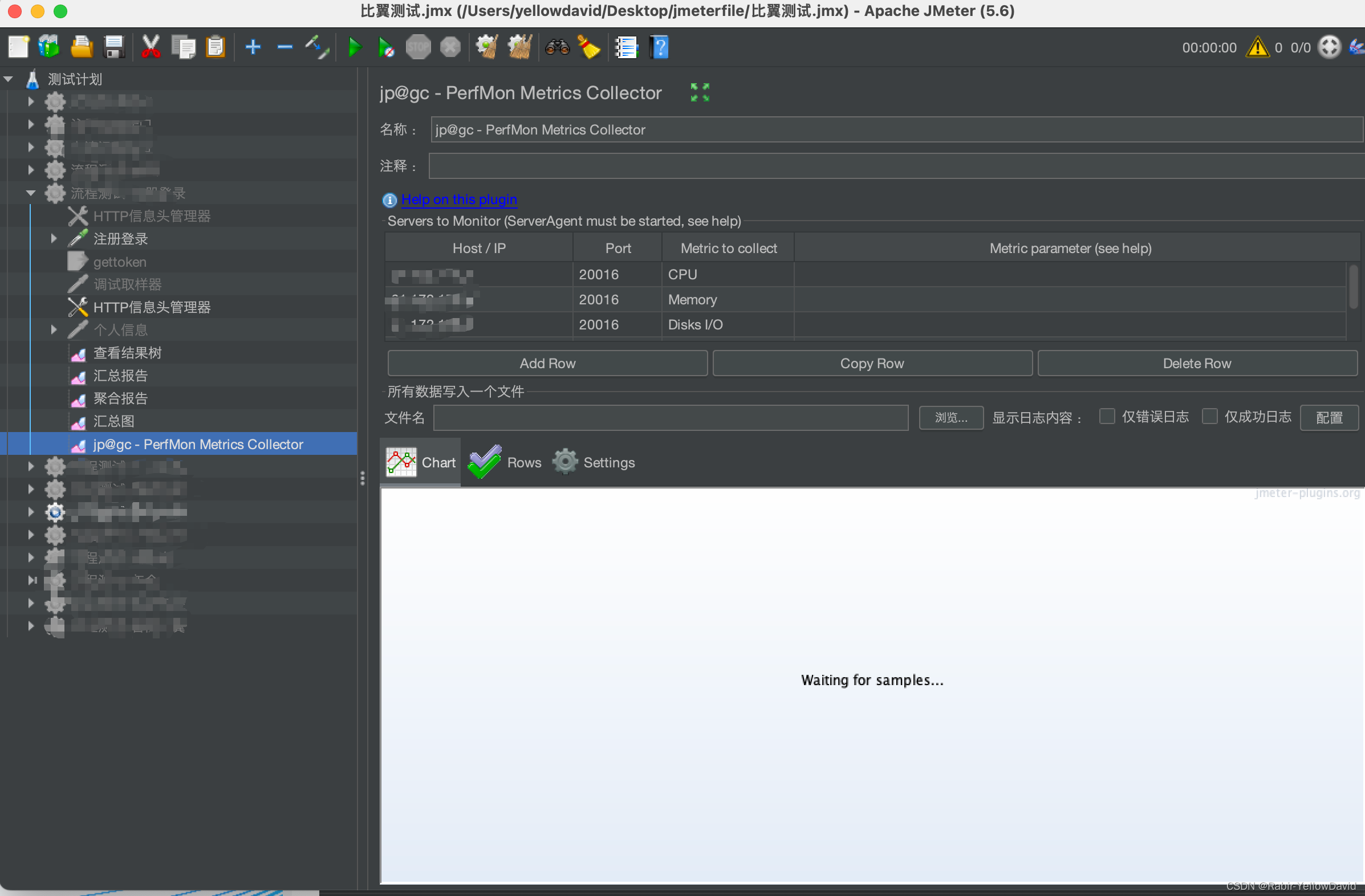
Jmeter+ServerAgent
一、Jmeter 下载 https://jmeter.apache.org/download_jmeter.cgi选择Binaries二进制下载 apache-jmeter-5.6.2.tgz 修改配置文件 jmeter下的bin目录,打开jmeter.properties 文件 languagezh_CN启动命令 cd apache-jmeter-5.6/bin sh jmeter二、ServerAgent 监…...

打破数据孤岛!时序数据库 TDengine 与创意物联感知平台完成兼容性互认
新型物联网实现良好建设的第一要务就是打破信息孤岛,将数据汇聚在平台统一处理,实现数据共享,放大物联终端的行业价值,实现系统开放性,以此营造丰富的行业应用环境。在此背景下,物联感知平台应运而生&#…...
ubuntu22安装和部署Kettle8.2
前提 kettle是纯java编写的etl开源工具,目前kettle7和kettle8都需要java8或者以上才能正常运行。所以运行kettle前先检查java环境是否正确配置,java版本是否是8或者以上。 kettle安装 1、创建kettle目录,并将kettle的zip包解压到kettle目…...

修复 Ubuntu Linux 中的“找不到命令‘python’”错误
在ubuntu 22.04版本中使用 callstack backtrace.txt 回溯错误点是碰到了该问题。 参考文章:链接 ubuntu22.04版本中默认只安装了python3版本 查看python各个版本安装情况,在终端输入命令: type python python2 python3如果安装了对应的版本…...
)
ElevenLabs语音合成效果翻倍的秘密(行业未公开的声学参数调优矩阵)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音合成效果翻倍的核心洞察 关键瓶颈在于语音上下文建模粒度 ElevenLabs 的高质量语音合成并非单纯依赖更大模型参数量,而是通过细粒度的语义-韵律联合编码实现自然度跃升。…...

安全聚合技术:原理、实现与多场景应用
1. 安全聚合技术概述安全聚合(Secure Aggregation)是一种多方安全计算技术,它允许多个互不信任的参与方在不泄露各自私有数据的前提下,共同计算出一个聚合结果。这项技术的核心价值在于解决了数据隐私与数据共享之间的矛盾&#x…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...
)
STM8硬件IIC驱动BNO055传感器避坑指南(附完整代码)
STM8硬件IIC驱动BNO055传感器实战解析与优化 BNO055作为一款集成了9轴传感器融合算法的智能芯片,能够直接输出姿态角数据,极大简化了嵌入式系统中姿态解算的复杂度。然而在实际应用中,许多开发者发现使用STM32等常见MCU的模拟IIC接口难以稳定…...

Rulebook-AI:用规则引擎为AI智能体构建可控决策框架
1. 项目概述:一个基于规则的AI智能体框架最近在探索如何让AI智能体(Agent)的行为更可控、更符合业务逻辑时,我遇到了一个挺有意思的开源项目:botingw/rulebook-ai。乍一看这个名字,可能会觉得它又是一个试图…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

用Ruby实现RISC-V模拟器:从指令集架构到交互式教学工具
1. 项目概述:一个为Ruby语言量身打造的RISC-V模拟器如果你是一名Ruby开发者,或者对RISC-V这个新兴的指令集架构充满好奇,那么你很可能已经听说过RuriOSS/rurima这个名字。简单来说,这是一个用Ruby语言实现的RISC-V指令集模拟器。但…...

开源大模型推理引擎Takeoff部署指南:从原理到生产实践
1. 项目概述:一个让大模型推理“起飞”的开源引擎 如果你正在为如何将那些动辄几十GB、几百亿参数的大语言模型(LLM)部署到生产环境而头疼,或者厌倦了为每一次API调用支付高昂的费用,那么今天聊的这个项目,…...