《Flink学习笔记》——第二章 Flink的安装和启动、以及应用开发和提交
介绍Flink的安装、启动以及如何进行Flink程序的开发,如何运行部署Flink程序等
2.1 Flink的安装和启动
本地安装指的是单机模式
0、前期准备
- java8或者java11(官方推荐11)
- 下载Flink安装包 https://flink.apache.org/zh/downloads/
- hadoop(后面Flink on Yarn部署模式需要)
- 服务器(我是使用虚拟机创建了三个centos的实例hadoop102、hadoop103、Hadoop104)
1、本地安装(单机)
第一步:解压
[root@hadoop102 software]# tar -zxvf flink-1.17.1-bin-scala_2.12.tgz -C /opt/module/
第二步:启动
[root@hadoop102 bin]# cd /opt/module/flink-1.17.1/bin
[root@hadoop102 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
查看进程:
[root@hadoop102 ~]# jps
24817 StandaloneSessionClusterEntrypoint
25330 Jps
25117 TaskManagerRunner
有StandaloneSessionClusterEntrypoint和TaskManagerRunner就说明成功启动。
第三步:提交作业
# 命令
./flink run xxx.jar
Flink提供了一些示例程序,已经打成了jar包可直接运行
# 运行一个统计单词数量的Flink示例程序
[root@hadoop102 bin]# ./flink run ../examples/streaming/WordCount.jar# 查看输出
[root@hadoop102 bin]# tail ../log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
第四步:停止集群
[root@hadoop102 bin]# ./stop-cluster.sh
★★★ 在企业中单机模式无法支撑业务,所以都是以集群的方式安装,故后续内容都是以集群展开。
2、集群安装
(0)集群角色
为了更好理解安装配置过程,这里先提一下Flink集群的几个关键组件
三个关键组件:
-
客户端(JobClient):接收用户的代码,并做一些转换,会生成一个执行计划,这个执行计划我们也叫数据流(data flow),然后发送给JobManager去进行下一步的执行,执行完成后客户端会将结果返回给用户。客户端并不是Flink程序执行的内部组成部分,但它是执行的起点。
-
JobManager:主进程,Flink集群的“管事人”,对作业进行中央调度管理,主要职责包括计划任务、管理检查点、故障恢复等。获取到要执行的作业后,会做进一步的转换,然后分发给众多的TaskManager。
-
TaskManager:真正"干活"的人,数据的处理操作都是他们来做的。
(1)集群规划
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager TaskManager | TaskManager | TaskManager |
(2)集群安装及启动
第一步:下载解压(见本地安装)
下载jar上传到hadoop102上,然后解压。如果本地安装已经操作则无需操作。
第二步:修改集群配置
进入conf目录:
/opt/module/flink-1.17.1/conf
a.进入conf目录,修改flink-conf.yaml文件
[root@hadoop102 conf]# vim flink-conf.yaml
以下几个地方需要修改:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
b.workers指定hadoop102、hadoop103和hadoop104为TaskManager
[root@hadoop102 conf]# vim workers
修改为:
hadoop102
hadoop103
hadoop104
c.修改masters文件,指定hadoop102为JobManager
[root@hadoop102 conf]# vim masters
hadoop102:8081
在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,可先自行了解下
主要配置项如下:
- jobmanager.memory.process.size
- taskmanager.memory.process.size
- taskmanager.numberOfTaskSlots
- parallelism.default
第三步:发送到其它所有服务器(hadoop103、Hadoop04)
[root@hadoop102 module]# scp -r flink-1.17.1 root@hadoop103:/opt/module/
[root@hadoop102 module]# scp -r flink-1.17.1 root@hadoop104:/opt/module/
hadoop103、hadoop104配置修改 taskmanager.host
[root@hadoop103 conf]# vim flink-conf.yaml
taskmanager.host: hadoop103[root@hadoop104 conf]# vim flink-conf.yaml
taskmanager.host: hadoop104
第四步:启动集群
hadoop102上执行start-cluster.sh
[root@hadoop102 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop103.
Starting taskexecutor daemon on host hadoop104.
查看进程:
[root@hadoop102 bin]# jps
28656 TaskManagerRunner
28788 Jps
28297 StandaloneSessionClusterEntrypoint[root@hadoop103 conf]# jps
4678 TaskManagerRunner
4750 Jps[root@hadoop104 ~]# jps
6593 TaskManagerRunner
6668 Jps
StandaloneSessionClusterEntrypoint:JobManager进程
TaskManagerRunner:TaskManager进程
访问WEB UI:http://hadoop102:8081/
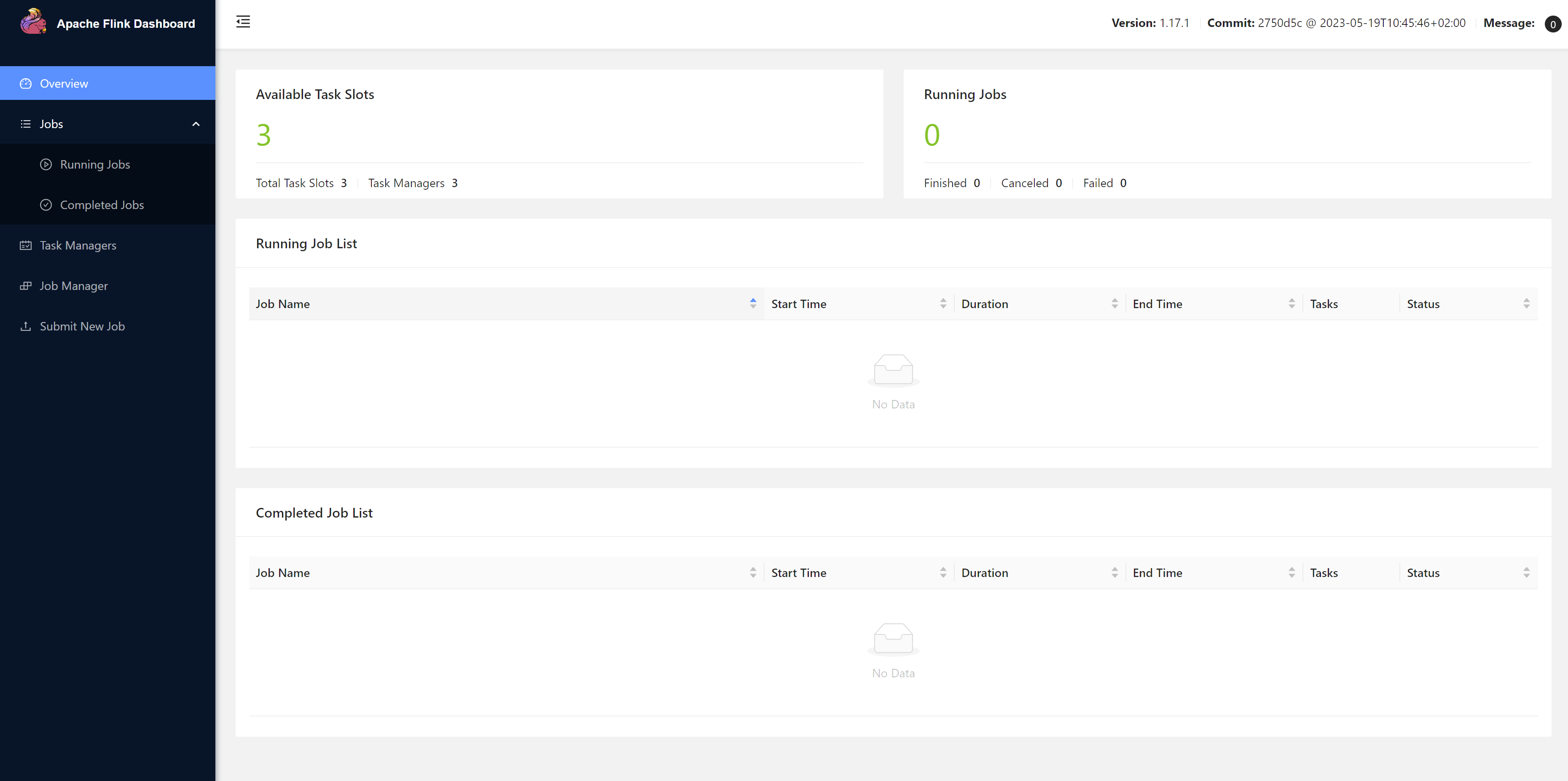
第五步:停止集群
[root@hadoop102 bin]# ./stop-cluster.sh
2.2 Flink应用开发
开发工具:IDEA
0、创建项目
1)创建工程
(1)打开IntelliJ IDEA,创建一个Maven工程。
(2)填写项目信息
(3) 添加项目依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.zlin</groupId><artifactId>flink-study</artifactId><packaging>pom</packaging><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.17.0</flink.version><slf4j.version>2.0.5</slf4j.version></properties><dependencies><!-- Flink相关依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><!-- 日志管理相关依赖 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.19.0</version></dependency></dependencies></project>
1、代码编写(WordCount)
在开发中,如果我们有很多子项目,则可以创建一个个Module。相当于一个个子项目,这样结构清晰而且所有子项目都拥有父项目pom文件中的依赖。
需求:统计一段文字中,每个单词出现的频次。
环境准备:在src/main/java目录下,新建一个包,命名为com.atguigu.wc
这里也给出了批处理的代码,可以和流处理做下对比。
1.批处理
1)数据准备
工程目录下创建一个目录 input, 目录下创建一个文件,文件名随意,写一些单词
1.txt
hello udian hello flink
test test
2)代码编写
创建package com.zlin.wc 创建类BatchWordCount
package com.zlin.wc;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** 单词统计(批处理)* @author ZLin* @since 2022/12/17*/
public class BatchWordCount {public static void main(String[] args) throws Exception {// 1. 创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件读取数据,按行读取DataSource<String> lineDs = env.readTextFile("input/");// 3. 转换数据格式FlatMapOperator<String, Tuple2<String, Long>> wordAndOnes = lineDs.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 按照word(下标为0)进行分组UnsortedGrouping<Tuple2<String, Long>> wordAndOneUg = wordAndOnes.groupBy(0);// 5. 分组内聚合统计AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUg.sum(1);// 6. 打印结果sum.print();}
}
3)输出
(java,1)
(flink,1)
(test,2)
(hello,2)
2.流处理
a.从文件读取
package com.zlin.wc;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** 有界流* @author ZLin* @since 2022/12/19*/
public class BoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 配置数据源FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/")).build();// 3. 从数据源中读取数据DataStreamSource<String> lineDss = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"file-source");// 4.转换格式 (word, 1L)SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDss.flatMap((String line, Collector<String> words) -> Arrays.stream(line.split(" ")).forEach(words::collect)).returns(Types.STRING).map(word -> Tuple2.of(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));// 5. 按单词分组KeyedStream<Tuple2<String, Long>, String> wordAndOneKs = wordAndOne.keyBy(t -> t.f0);// 6. 求和SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKs.sum(1);// 7. 打印result.print();// 8. 执行env.execute("单词统计(有界流");}
}
输出:
(java,1)
(flink,1)
(test,2)
(hello,2)
b.从socket读取
package com.zlin.wc;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** 单词统计(无界流)* @author ZLin* @since 2022/12/20*/
public class StreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2. 从socket读取文本流DataStreamSource<String> lineDss = env.socketTextStream("hadoop102", 7777);//3. 转换数据格式SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDss.flatMap((String line, Collector<String> words) -> Arrays.stream(line.split(" ")).forEach(words::collect)).returns(Types.STRING).map(word -> Tuple2.of(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));//4. 分组KeyedStream<Tuple2<String, Long>, String> wordAndOneKs = wordAndOne.keyBy(t -> t.f0);//5. 求和SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKs.sum(1);//6. 打印result.print();//7. 执行env.execute("单词统计(无界流)");}
}
测试->在hadoop102中用 netcat 命令进行发送测试
nc -lk 7777注意:这里要先在hadoop102上先执行nc -lk 7777把端口打开,再在IDEA中运行程序,否则连不上端口会报错。
输出:
4> (hello,1)
2> (java,1)
4> (hello,2)
10> (flink,1)
7> (test,1)
7> (test,2)
2.3 Flink应用提交到集群
在IDEA中,我们开发完了项目后我们需要把我们的项目部署到集群中。
首先将程序打包:
(1)pom.xml文件添加打包插件的配置
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
点击Maven->你的moudle->package 进行打包,显示如下即打包成功。
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 15.263 s
[INFO] Finished at: 2022-12-22T00:53:50+08:00
[INFO] ------------------------------------------------------------------------Process finished with exit code 0可在target目录下看到打包成功的jar包

-with-dependencies是带依赖的,另一个是不带依赖的。
如果运行的环境中已经有程序所要运行的依赖则直接使用不带依赖的。
1. Web UI
点击+Add New上传我们的jar包,然后填写配置,最后点击提交
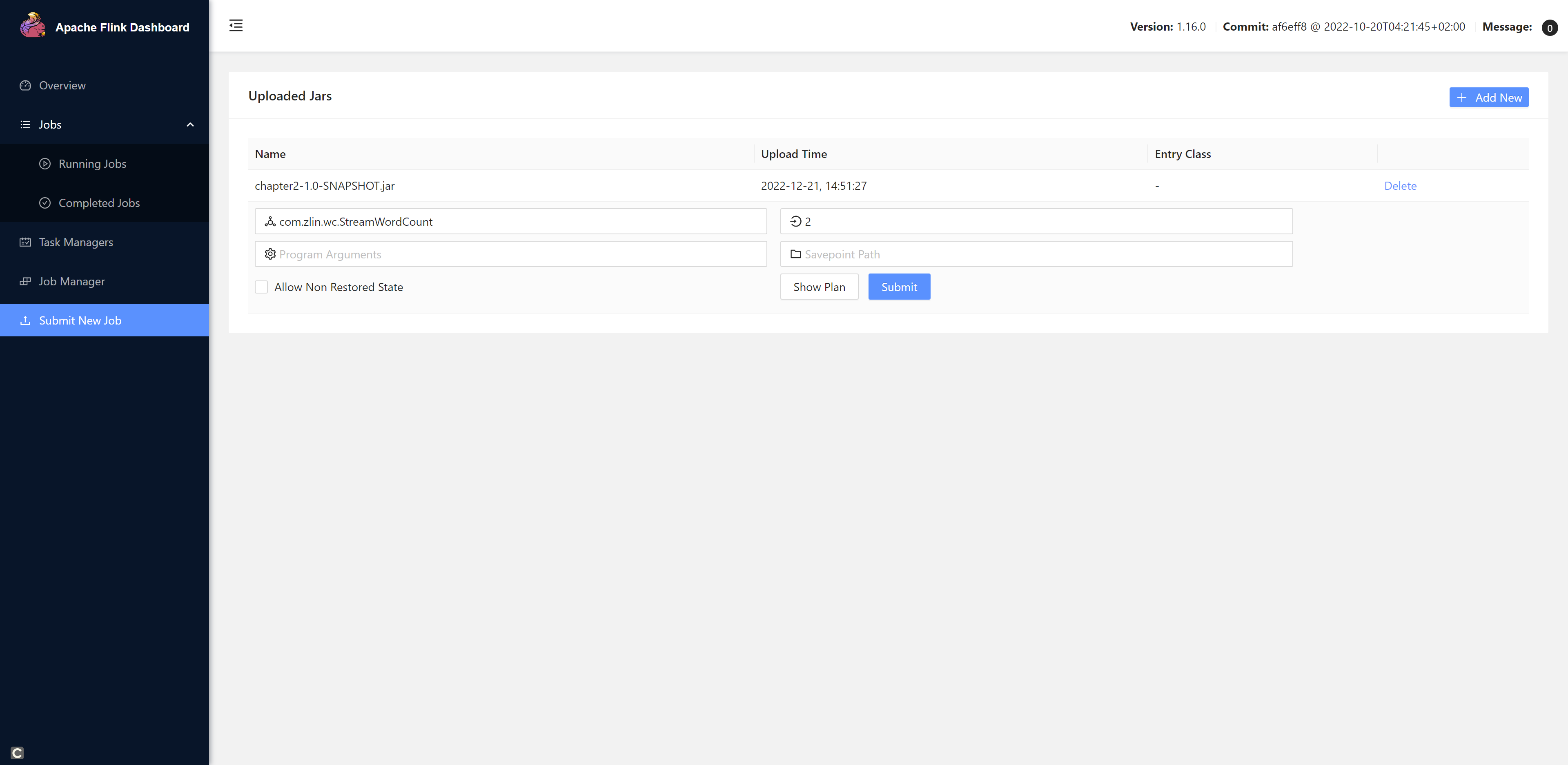
注意: 由于我们的程序是统计Hadoop102:7777这个端口发送过来的数据,所以我们需要先开启这个端口。不然程序提交会报错。
[root@hadoop102 bin]# nc -lk 7777之后我们再submit我们的任务。
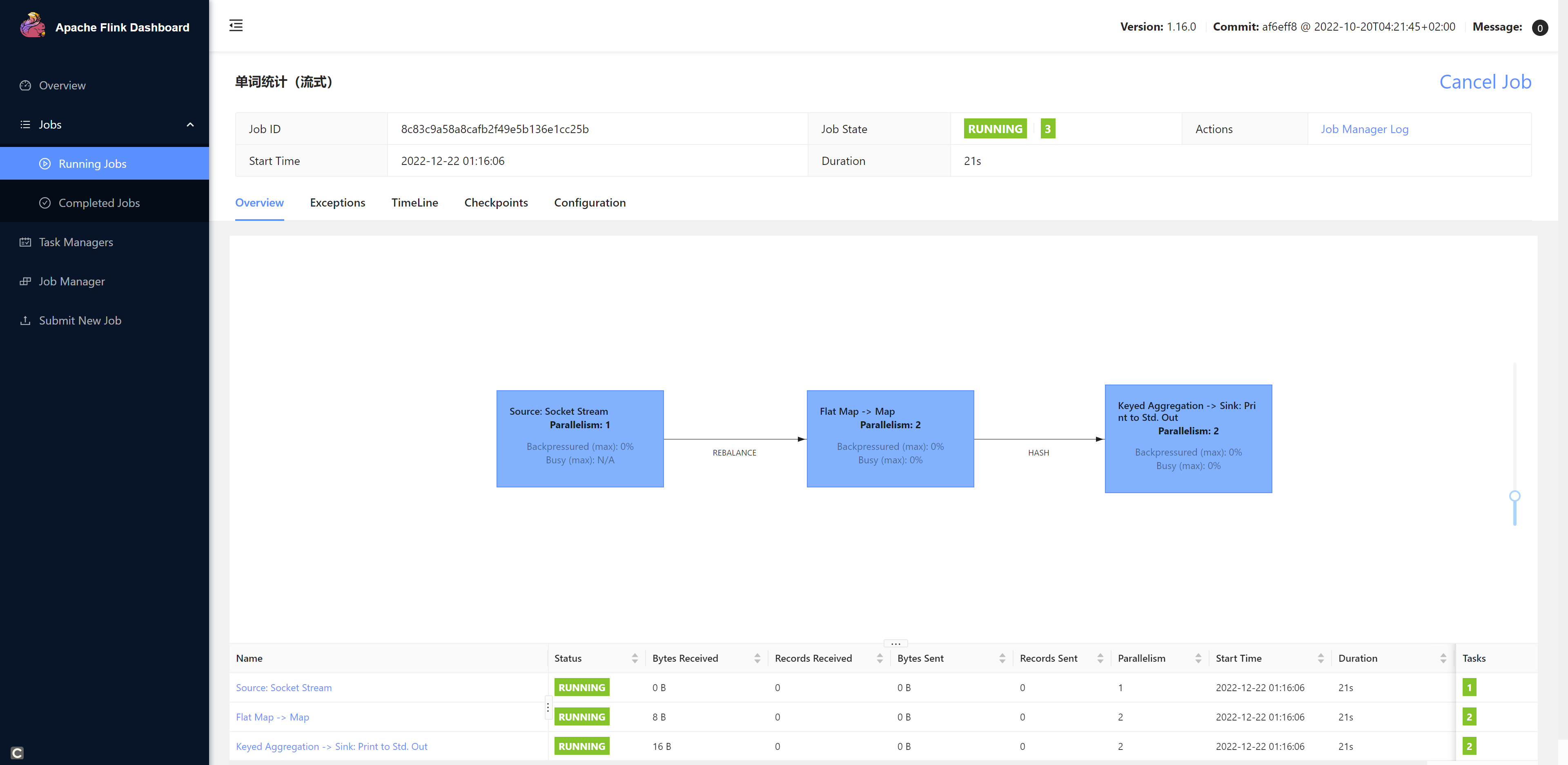
我们发送一些数据测试一下:
[root@hadoop102 bin]# nc -lk 7777
heelo 222
ppp
fff
hello world
how are you
hello flink
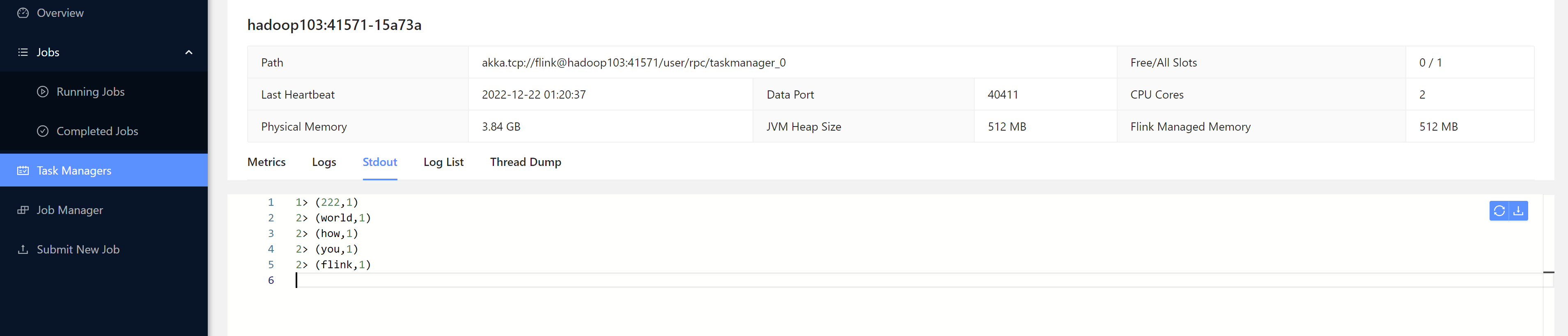
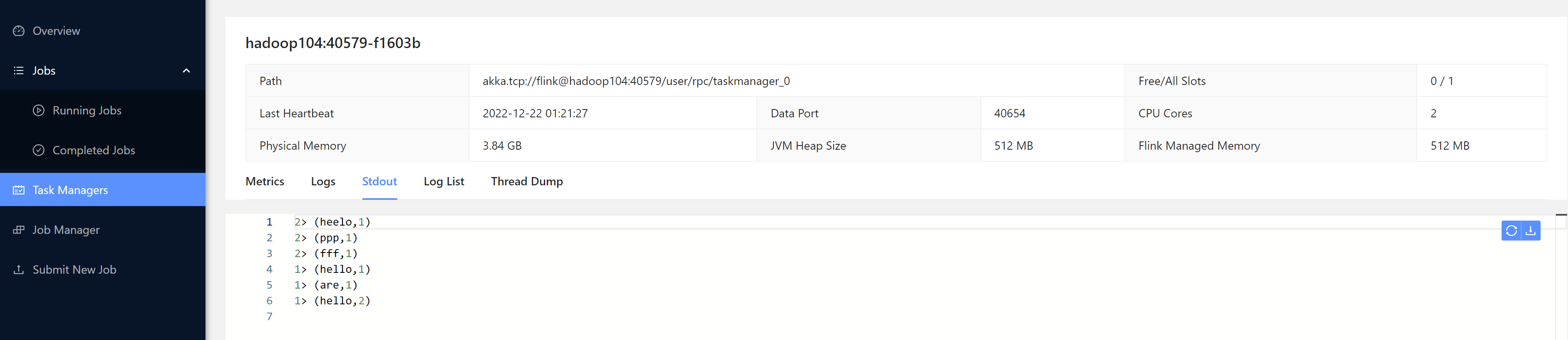
2. 命令行方式
确认flink集群已经启动
第一步:将jar包上传到服务器上
第二步:开启hadoop102:7777端口
[root@hadoop102 bin]# nc -lk 7777
第三步:提交作业
[root@hadoop102 jars]# flink run -m hadoop102:8081 -c com.zlin.wc.StreamWordCount ./chapter2-1.0-SNAPSHOT.jar
Job has been submitted with JobID f00421ad4c893deb17068047263a4e9e

发送一些数据
[root@hadoop102 bin]# nc -lk 7777
666
777
888
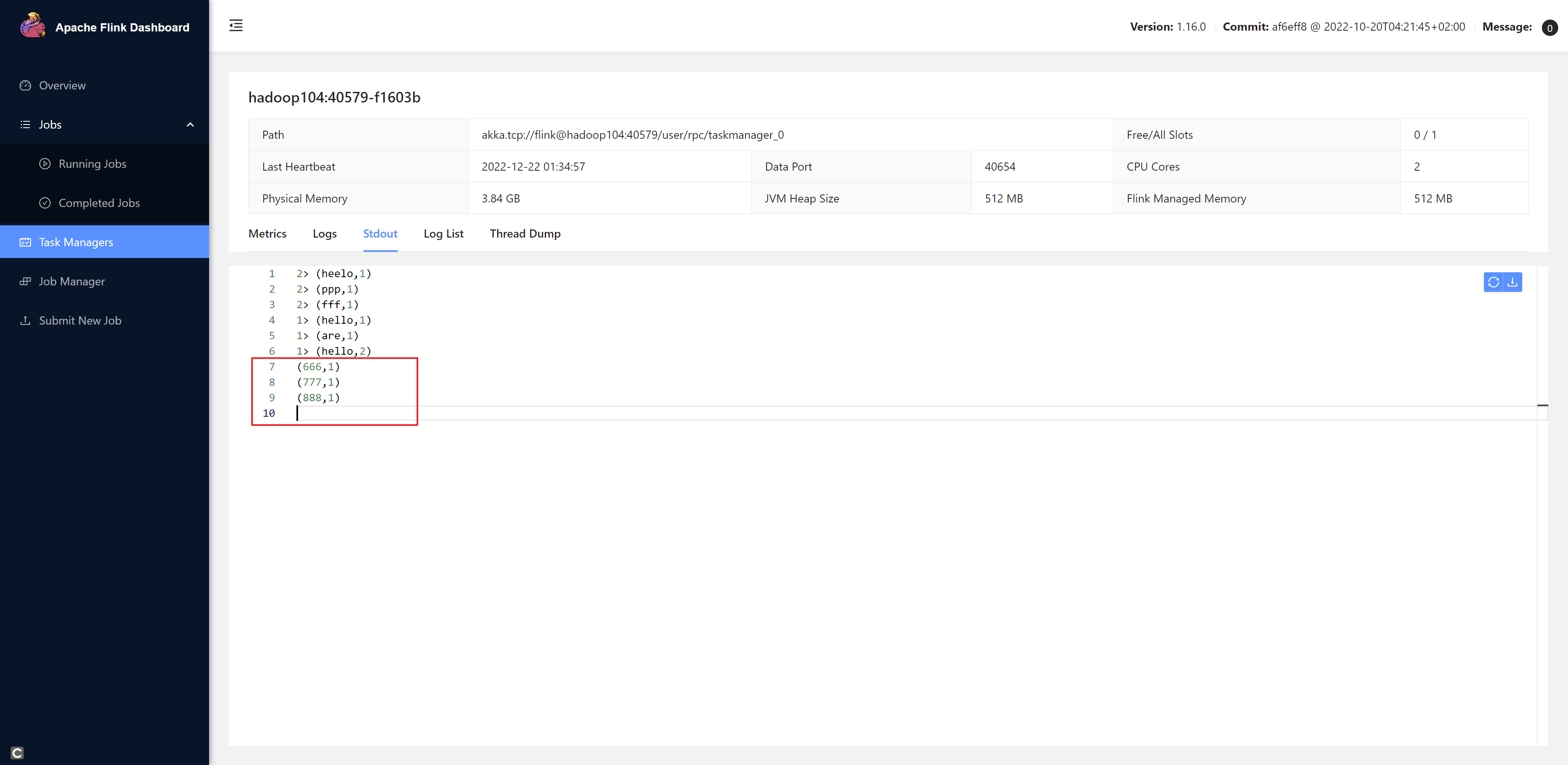
相关文章:
《Flink学习笔记》——第二章 Flink的安装和启动、以及应用开发和提交
介绍Flink的安装、启动以及如何进行Flink程序的开发,如何运行部署Flink程序等 2.1 Flink的安装和启动 本地安装指的是单机模式 0、前期准备 java8或者java11(官方推荐11)下载Flink安装包 https://flink.apache.org/zh/downloads/hadoop&a…...
网易新财报:游戏稳、有道进、云音乐正爬坡
今年以来,AI大模型的火热程度屡屡攀升,越来越多的企业都加入到了AI大模型的赛场中,纷纷下场布局。而在众多参与者中,互联网企业的身影更是频频浮现,比如,百度、阿里巴巴、腾讯等等。值得一提的是࿰…...
Docsify的评论系统gitalk配置过程
💖 作者简介:大家好,我是Zeeland,开源建设者与全栈领域优质创作者。📝 CSDN主页:Zeeland🔥📣 我的博客:Zeeland📚 Github主页: Undertone0809 (Zeeland)&…...
卡片开发应用上下文Context使用场景二)
HarmonyOS/OpenHarmony(Stage模型)卡片开发应用上下文Context使用场景二
3.创建其他应用或其他Module的Context 基类Context提供创建其他应用或其他Module的Context的方法为createModuleContext(moduleName:string),创建其他应用或者其他Module的Context,从而通过该Context获取相应的资源信息(例如获取其他Module的…...

数字货币量化交易平台
数字货币量化交易平台是近年来金融科技领域迅速崛起的一种创新型交易方式。它通过应用数学模型和算法策略,实现对数字货币市场的自动交易和风险控制。然而,要在这个竞争激烈的领域中脱颖而出,一个数字货币量化交易平台需要具备足够的专业性&a…...
)
2022 ICPC 济南 E Identical Parity (扩欧)
2022 ICPC 济南 E. Identical Parity (扩欧) Problem - E - Codeforces 大意:给出一个 n 和一个 k , 问是否能构造一个长 n 的排列使得所有长 k 的连续子序列和的奇偶性相同。 思路:通过分析可知 , 任两个间隔 k - 1 的元素奇偶…...

【BUG事务内消息发送】事务内消息发送,事务还未结束,消息发送已被消费,查无数据怎么解决?
问题描述 在一个事务内完成插入操作,通过MQ异步通知其他微服务进行事件处理。 由于是在事务内发送,其他服务消费消息,查询数据时还不存在如何解决呢? 解决方案 通过spring-tx包的TransactionSynchronizationManager事务管理器解…...
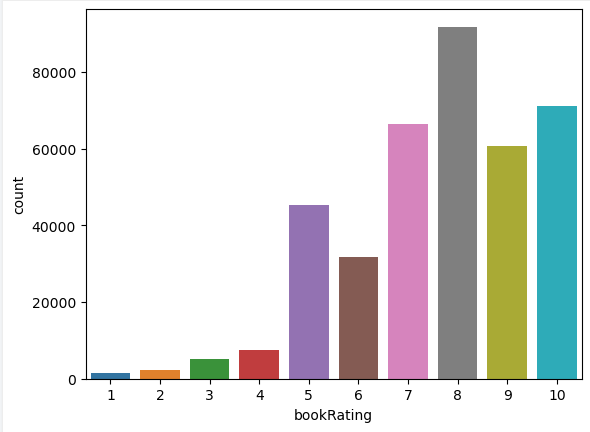
数据分析作业四-基于用户及物品数据进行内容推荐
## 导入支持库 import pandas as pd import matplotlib.pyplot as plt import sklearn.metrics as metrics import numpy as np from sklearn.neighbors import NearestNeighbors from scipy.spatial.distance import correlation from sklearn.metrics.pairwise import pairwi…...

在腾讯云服务器OpenCLoudOS系统中安装svn(有图详解)
1. 安装svn yum -y install subversion 安装成功: 2. 创建数据根目录及仓库 mkdir -p /usr/local/svn/svnrepository 创建test仓库: svnadmin create /usr/local/svn/test test仓库创建成功: 3. 修改配置test仓库 cd /usr/local/svn/te…...

C语言日常刷题5
文章目录 题目答案与解析1234567、 题目 1、以下叙述中正确的是( ) A: 只能在循环体内和switch语句体内使用break语句 B: 当break出现在循环体中的switch语句体内时,其作用是跳出该switch语句体,并中止循环体的执行 C: continue语…...
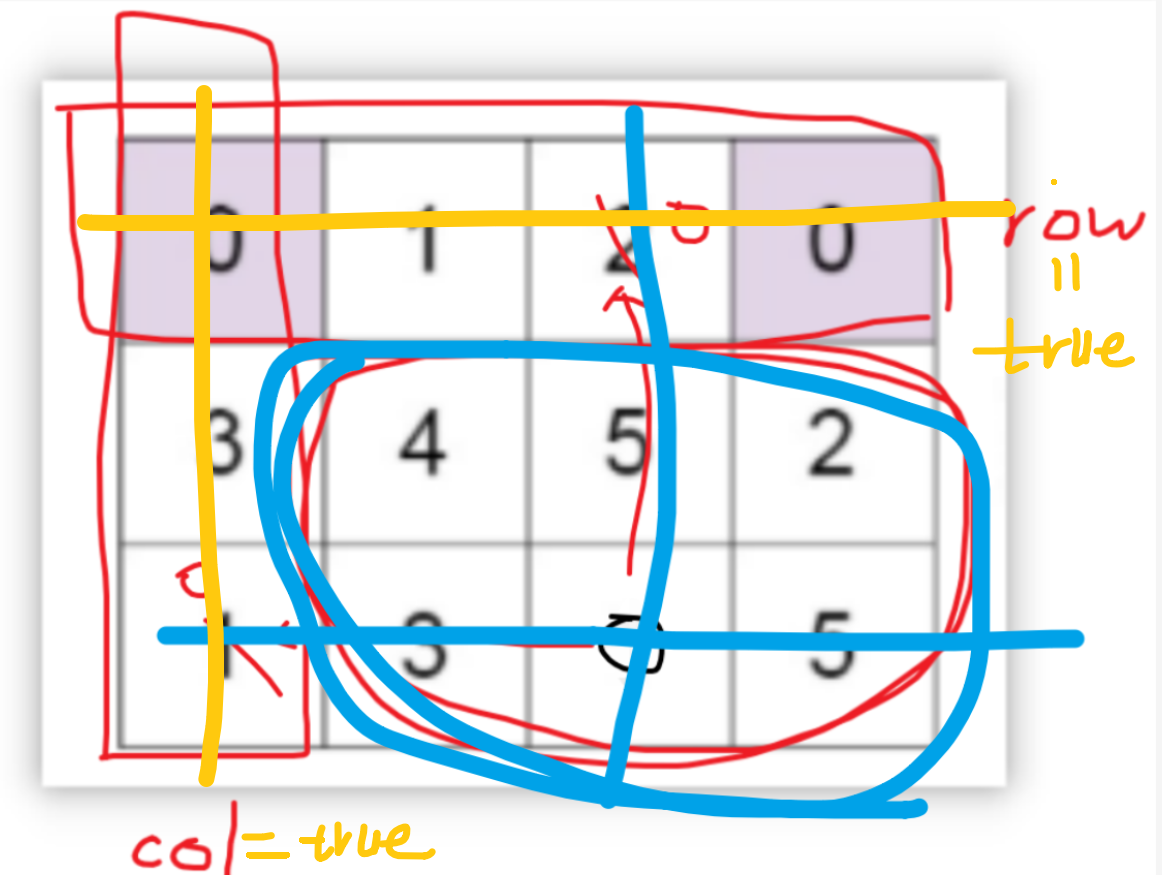
【LeetCode-中等题】73. 矩阵置零
题目 题解一:使用标记数组 public void setZeroes(int[][] matrix) {int m matrix.length;int n matrix[0].length;boolean[] row new boolean[m];boolean[] col new boolean[n];for(int i0; i< m;i){for(int j 0;j<n;j){if (matrix[i][j] 0) row[i]col…...

本地部署 FastGPT
本地部署 FastGPT 1. FastGPT 是什么2. 部署 FastGPT 1. FastGPT 是什么 FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景! …...

软件工程(十八) 行为型设计模式(四)
1、状态模式 简要说明 允许一个对象在其内部改变时改变它的行为 速记关键字 状态变成类 类图如下 状态模式主要用来解决对象在多种状态转换时,需要对外输出不同的行为的问题。比如订单从待付款到待收货的咋黄台发生变化,执行的逻辑是不一样的。 所以我们将状态抽象为一…...
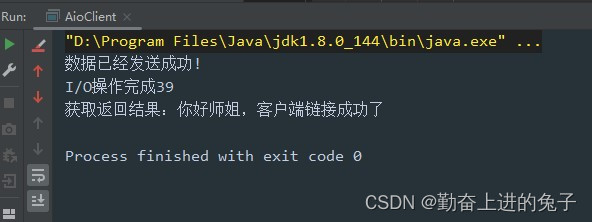
Socket通信与WebSocket协议
文章目录 目录 文章目录 前言 一、Socket通信 1.1 BIO 1.2 NIO 1.3 AIO 二、WebSocket协议 总结 前言 一、Socket通信 Socket是一种用于网络通信的编程接口(API),它提供了一种机制,使不同主机之间可以通过网络进行数据传输和通信…...

新KG视点 | Jeff Pan、陈矫彦等——大语言模型与知识图谱的机遇与挑战
OpenKG 大模型专辑 导读 知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织…...

详解过滤器Filter和拦截器Interceptor的区别和联系
目录 前言 区别 联系 前言 过滤器(Filter)和拦截器(Interceptor)都是用于在Web应用程序中处理请求和响应的组件,但它们在实现方式和功能上有一些区别。 区别 1. 实现方式: - 过滤器是基于Servlet规范的组件,通过实现javax.servlet.Filt…...

List常用的操作
1、看List里是否存在某个元素 contains //省略建立listboolean contains stringList.contains("上海");System.out.println(contains); 如果存在是true,不存在是false 2、看某个元素在List中的索引号 .indexOf List<String>stringList new Ar…...

Android studio APK切换多个摄像头(Camera2)
1.先设置camera的权限 <uses-permission android:name"android.permission.CAMERA" /> 2.布局 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"and…...

ChatGPT 对教育的影响,AI 如何颠覆传统教育
胜量老师 来源:BV1Nv4y1H7kC 由Chat GPT引发的对教育的思考,人类文明发展至今一直靠教育完成文明的传承,一个年轻人要经历若干年的学习,才能进入社会投入对文明的建设,而学习中有大量内容是需要记忆和反复训练的。 无…...
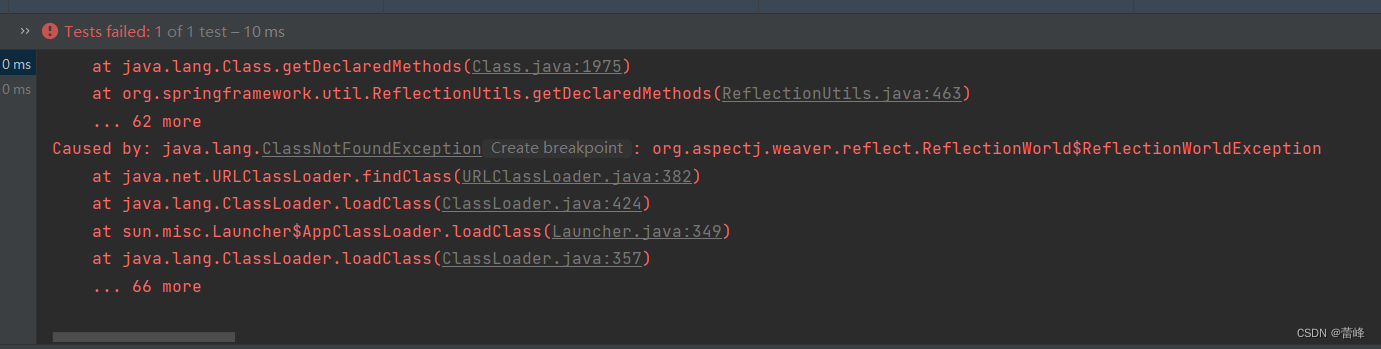
Spring(九)声明式事务
Spring整合Junit4和JdbcTemplater如下所示: 我们所使用的junit的jar包不同,可以整合不同版本的junit。 我们导入的依赖如下所示: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.a…...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...
)
保姆级教程:用Python+NumPy复现经典Laplacian曲面编辑算法(附源码)
从理论到代码:Python实现Laplacian曲面编辑的完整指南 在三维图形处理领域,Laplacian曲面编辑技术因其出色的细节保持能力而备受推崇。这项技术允许开发者对三维模型进行直观的变形操作,同时保持模型表面的几何细节不被破坏。本文将带您从零开…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

OpenAgents开源框架:模块化AI智能体开发实战指南
1. 项目概述:一个面向未来的智能体开发框架最近在AI智能体这个圈子里,OpenAgents这个项目讨论度挺高的。简单来说,它不是一个单一的AI应用,而是一个旨在降低智能体开发门槛、加速智能体应用落地的开源框架。你可以把它想象成一个“…...

Instagram视频下载终极指南:三分钟掌握免费下载技巧
Instagram视频下载终极指南:三分钟掌握免费下载技巧 【免费下载链接】instagram-video-downloader Simple website made with Next.js for downloading instagram videos with an API that can be used to integrate it in other applications. 项目地址: https:…...

学生综合素质评价系统设计实现【附程序】
✨ 长期致力于综合素质评价、AHP层次分析、BP神经网络、遗传算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)三层指标体系构建与AHP动态权重分配&…...