Ceph源码解析:PG peering
集群中的设备异常(异常OSD的添加删除操作),会导致PG的各个副本间出现数据的不一致现象,这时就需要进行数据的恢复,让所有的副本都达到一致的状态。
一、OSD的故障和处理办法:
1. OSD的故障种类:
故障A:一个正常的OSD 因为所在的设备发生异常,导致OSD不能正常工作,这样OSD超过设定的时间 就会被 out出集群。
故障B: 一个正常的OSD因为所在的设备发生异常,导致OSD不能正常工作,但是在设定的时间内,它又可以正常的工作,这时会添加会集群中。
2. OSD的故障处理:
故障A:OSD上所有的PG,这些PG就会重新分配副本到其他OSD上。一个PG中包含的object数量是不限制的,这时会将PG中所有的object进行复制,可能会产生很大的数据复制。
故障B:OSD又重新回到PG当中去,这时需要判断一下,如果OSD能够进行增量恢复则进行增量恢复,否则进行全量恢复。(增量恢复:是指恢复OSD出现异常的期间,PG内发生变化的object。全量恢复:是指将PG内的全部object进行恢复,方法同故障A的处理)。
需要全量恢复的操作叫做backfill操作。需要增量恢复的操作叫做recovery操作。
二、概念解析:
1.osdmap:集群所有osd的集合,包括每个osd的ip & state(up or down)
2.acting set & up set:每个pg都有这两个集合,acting set中保存是该pg所有的副本所在OSD的集合,比如acting[0,1,2],就表示这个pg的副本保存在OSD.0 、OSD.1、OSD.2中,而且排在第一位的是OSD.0 ,表示这个OSD.0是PG的primary副本。在通常情况下 up set 与 acting set是相同的。区别不同之处需要先了解pg_temp。
3.Epoch:osdmap的版本号,单调递增,osdmap每变化一次加1
4.current_interval & past interval:一个epoch序列,在这个序列内,这个PG的acting set没有变化过,current是当前的序列,past是指过去的interval。
last_epoch_started:上次经过peering后的osdmap版本号epoch。
last_epoch_clean:上次经过recovery或者backfill后的osdmap版本号epoch。
(注:peering结束后,数据的恢复操作才刚开始,所以last_epoch_started与last_epoch_clean可能存在不同)。
例如:
ceph 系统当前的epoch值为20, pg1.0 的 acting set 和 up set 都为[0,1,2]
-
osd.3失效导致了osd map变化,epoch变为 21
-
osd.5失效导致了osd map变化,epoch变为 22
-
osd.6失效导致了osd map变化,epoch变为 23
上述三次epoch的变化都不会改变pg1.0的acting set和up set
-
osd.2失效导致了osd map变化,epoch变为 24
此时导致pg1.0的acting set 和 up set变为 [0,1,8],若此时 peering过程成功完成,则last_epoch_started 为24
-
osd.12失效导致了osd map变化,epoch变为 25
此时如果pg1.0完成了recovery,处于clean状态,last_epoch_clean就为25
-
osd13失效导致了osd map变化,epoch变为 26
epoch 序列 21,22,23,23 就为pg1.0的past interval
epoch 序列 24,25,26就为 pg1.0的current interval
5.authoritative history:完整的pg log操作序列
6.last epoch start:上次peering完成的epoch
7.up_thru:一个past interval内,第一次完成peering的epoch
8.pg_temp : 假设当一个PG的副本数量不够时,这时的副本情况为acting/up = [1,2]/[1,2]。这时添加一个OSD.3作为PG的副本。经过crush的计算发现,这个OSD.3应该为当前PG的primary,但是呢,这OSD.3上面还没有PG的数据,所以无法承担primary,所以需要申请一个pg_temp,这个pg_temp就还采用OSD.1作为primary,此时pg的集合为acting,pg_temp的集合为up。当然pg与pg_temp是不一样的,所以这时pg的集合变成了[3,1,2]/[1,2,3]。当OSD.3上的数据全部都恢复完成后,就变成了[3,1,2]/[3,1,2]。
9.pg_log:pg_log是用于恢复数据重要的结构,每个pg都有自己的log。对于pg的每一个object操作都记录在pg当中。
-
__s32 op; 操作的类型
-
hobject_t soid; 操作的对象
-
eversion_t version, prior_version, reverting_to; 操作的版本
三、peering具体流程
算法流程图:
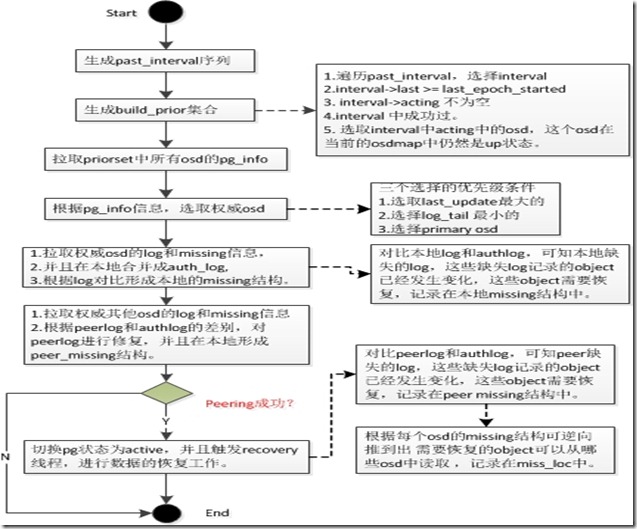
Peering:互为副本的三个(此处为设置的副本个数,通常设置为3)pg的元数据达到一致的过程。官方解释如下:
the process of bringing all of the OSDs that store a Placement Group (PG) into agreement about the state of all of the objects (and their metadata) in that PG. Note that agreeing on the state does not mean that they all have the latest contents.
primary PG和raplica PG: 互为副本的三个pg中,有一个主,另外两个为辅;其中为主的称为primary PG,其他两个都称为replica PG。
1、peering过程的影响
故障osd重新上线后,primary PG和replica PG会进入不同的处理流程。primary PG会先进入peering状态,在这个状态的pg暂停处理IO请求,在生产环境中表现为集群部分IO不响应,甚至某些云主机因为等待IO造成应用无法正常处理。下面就peering过程的主要操作结合源码进行分析。
2、peering过程分析
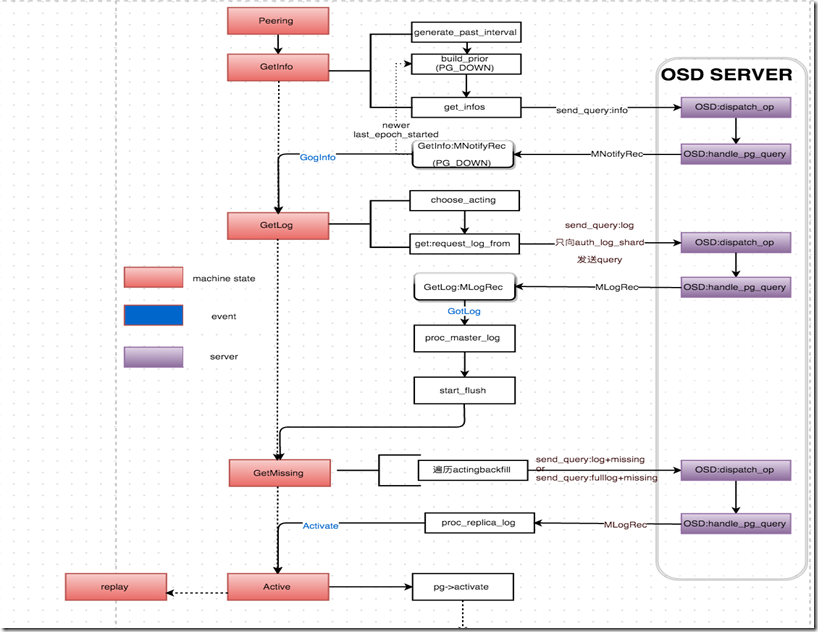
pg是由boost::statechart实现的状态机,peering经历以下主要过程:
1、GetInfo:
1.1、选取一个epoch区间,对区间内的每个epoch计算其对应的acting set、acting primary、up set、up primary,将相同的结果作为一个interval;
pg->generate_past_intervals();
调用generate_past_intervals()函数,生成past_interval序列。首先确定查找interval的start_epoch(history.last_epoch_clean 上次恢复数据完成的epoch)和end_epoch(history.same_interval_since 最近一次interval的起始epoch)。确定了start_epoch和end_epoch之后,循环这个两个版本间的所有osdmap,确定pg成员变化的区间interval。
1.2、判断每个interval,将up状态的osd加入到prior set;同时将当前的acting set和up set加入到prior set;
pg->build_prior(prior_set);
据past_interval生成prior set集合。确定prior set集合,如果处于当前的acting和up集合中的成员,循环遍历past_interval中的每一个interval,interval.last >= info.history.last_epoch_started、! interval.acting.empty()、interval.maybe_went_rw,在该interval中的acting集合中,并且在集群中仍然是up状态的。
1.3、向prior_set中的每个up状态的osd发送Query INFO请求,并等待接收应答,将接收到的请求保存到peer_info中;
context< RecoveryMachine >().send_query(
peer, pg_query_t(pg_query_t::INFO,
it->shard, pg->pg_whoami.shard,
pg->info.history,
pg->get_osdmap()->get_epoch()));根据priorset 集合,开始获取集合中的所有osd的info。这里会向所有的osd发送请求info的req(PG::RecoveryState::GetInfo::get_infos())。发送请求后等待回复。
1.4、收到最后一个应答后,状态机post event到GotInfo状态;如果在此期间有一个接收请求的osd down掉,这个PG的状态将持续等待,直到对应的osd恢复;
boost::statechart::result PG::RecoveryState::GetInfo::react(const MNotifyRec &infoevt)
回复处理函数。主要调用了pg->proc_replica_info进行处理:1.将info放入peerinfo数组中。2.合并history记录。 在这里会等待所有的副本都回复info信息。进入下一个状态GetLog。
2、GetLog:
2.1、遍历peer_info,查找best info,将其作为authoritative log;将acting set/peer_info中将处于complete状态的pg以及up set的所有pg存入acting_backfill;
pg->choose_acting(auth_log_shard,
&context< Peering >().history_les_bound)通过pg->choose_acting(auth_log_shard)选择acting集合和auth_osd.
choose_acting中主要进行了两项重要的措施:
find_best_info,查找一个最优的osd。在 find_best_info中查找最优的osd时,判断的条件的优先级有三个:最大的last_update、最小的log_tail、当前的primary。
map<pg_shard_t, pg_info_t>::const_iterator auth_log_shard =
find_best_info(all_info, history_les_bound);calc_replicated_acting ,选择参与peering、recovering的osd集合。
up集合中的成员。所有的成员都是加入到acting_backfilling中,如果是incomplete状态的成员或者 日志衔接不上的成员(cur.last_update<auth.log_tail)则添加到backfill中,否则添加到want成员中。
acting集合中的成员,该组内的成员不会添加到backfill中,所以只需要判断 如果状态是complete并且 日志能够衔接的上,则添加到want和acting_backfilling中。
其他prior中的osd成员 处理同acting一致。
经过这一步可知,acting_backfilling的成员(可用日志恢复数据,或者帮助恢复数据的成员),backfill的成员(只能通过其他的osd上pg的数据进行全量拷贝恢复),want的成员(同样在acting_backfill中,但是不同于backfill的成员)。
calc_ec_acting。ceph有两种pool,一种是副本类型pool,一种是纠删码类型pool(类似RAID)。具体实现后续补充,今天太晚了,有空看代码补补。
2.2、如果计算出的authoritative log对应的pg是自身,直接post event到GotLog;否则,向其所在的osd发送Query Log请求;
context<RecoveryMachine>().send_query(
auth_log_shard,
pg_query_t(
pg_query_t::LOG,
auth_log_shard.shard, pg->pg_whoami.shard,
request_log_from, pg->info.history,
pg->get_osdmap()->get_epoch()));
2.3、接收请求的osd应答,并将获取的log merge到本地,状态机post event到GetMissing;如果收不到应答,状态将持续等待;
boost::statechart::result PG::RecoveryState::GetLog::react(const GotLog &)
{
dout(10) << "leaving GetLog" << dendl;
PG *pg = context< RecoveryMachine >().pg;
if (msg)
{
dout(10) << "processing master log" << dendl;
pg->proc_master_log(*context<RecoveryMachine>().get_cur_transaction(),
msg->info, msg->log, msg->missing,
auth_log_shard);//log处理函数
}
pg->start_flush(
context< RecoveryMachine >().get_cur_transaction(),
context< RecoveryMachine >().get_on_applied_context_list(),
context< RecoveryMachine >().get_on_safe_context_list());
return transit< GetMissing >();//跳转到GetMissing
}void PG::proc_master_log(
ObjectStore::Transaction &t, pg_info_t &oinfo,
pg_log_t &olog, pg_missing_t &omissing, pg_shard_t from)
{
dout(10) << "proc_master_log for osd." << from << ": "
<< olog << " " << omissing << dendl;
assert(!is_peered() && is_primary());// merge log into our own log to build master log. no need to
// make any adjustments to their missing map; we are taking their
// log to be authoritative (i.e., their entries are by definitely
// non-divergent).
merge_log(t, oinfo, olog, from);//该函数对log进行合并,形成一个权威顺序完整的一个log。包括日志前后的修补,而且最重要的是修补的过程中,统计了本地副本中需要恢复object的情况missing.add_next_event(ne)。这里已经开始统计missing结构了。
peer_info[from] = oinfo;//保存来自best_log的oinfo到本地的peer-info数组中。
dout(10) << " peer osd." << from << " now " << oinfo << " " << omissing << dendl;
might_have_unfound.insert(from);// See doc/dev/osd_internals/last_epoch_started
if (oinfo.last_epoch_started > info.last_epoch_started)
{
info.last_epoch_started = oinfo.last_epoch_started;
dirty_info = true;
}
if (info.history.merge(oinfo.history)) //对history信息进行合并。
dirty_info = true;
assert(cct->_conf->osd_find_best_info_ignore_history_les ||
info.last_epoch_started >= info.history.last_epoch_started);peer_missing[from].swap(omissing);//将missing结构统计到本地的peer_missing结构中。
}
auth_log:一个是auth_log的合并,最大最权威的log,恢复数据要根据这里进行。
missing:另外就是合并log过程中发现本地副本需要恢复的object集合。
omissing:auth_osd需要进行恢复的object集合。
3、GetMissing:
3.1、遍历acting_backfill,向与primary pg log有交集的pg所在的osd发送Query Log请求;将剩余没有交集的pg放入peer_missing,生成missing set用于后续recovery;
context< RecoveryMachine >().send_query(
*i,
pg_query_t(
pg_query_t::LOG,
i->shard, pg->pg_whoami.shard,
since, pg->info.history,
pg->get_osdmap()->get_epoch()));
3.2、将收到的每一个应答merge到本地,如果在此期间有osd down掉,这个PG的状态将持续等待;收到所有的应答后,当前pg的状态机进入Activate状态,peering过程结束;
boost::statechart::result PG::RecoveryState::GetMissing::react(const MLogRec &logevt)
{
PG *pg = context< RecoveryMachine >().pg;peer_missing_requested.erase(logevt.from);
pg->proc_replica_log(*context<RecoveryMachine>().get_cur_transaction(),
logevt.msg->info, logevt.msg->log, logevt.msg->missing, logevt.from);//接收到其他osd发回的log信息并且进行处理。在proc_replica_log中对peer_log进行修剪,丢弃那些不完整不可用的log。整理接收到的oinfo到peerinfo中,omissing到peer_missing中。直接来到active状态。if (peer_missing_requested.empty())
{
if (pg->need_up_thru)
{
dout(10) << " still need up_thru update before going active" << dendl;
post_event(NeedUpThru());
}
else
{
dout(10) << "Got last missing, don't need missing "
<< "posting Activate" << dendl;
post_event(Activate(pg->get_osdmap()->get_epoch()));
}
}
return discard_event();
}
3、总结
从以上分析来看,整个peering过程主要分为三个阶段,GetInfo -> GetLog -> GetMissing,首先向prior set、acting set、up set中的每个osd请求pg infos, 选出authoritative log对应的pg;其次向authoritative log所在的osd请求authoritative log;最后获取recovery过程需要的missing set;
peering时间的长短并不可控,主要是在于请求的osd是否能够及时响应;如果这个阶段某个osd down掉,很可能导致部分pg一直处在peering状态,即所有分布到这个pg上的IO都会阻塞。
此文仅讲述了peering过程,peering之后还会进行recovery操作,recovery操作由处理线程直接调用函数void OSD::do_recovery(PG *pg, ThreadPool::TPHandle &handle)进行,后续再总结总结recovery过程和PG的状态机。
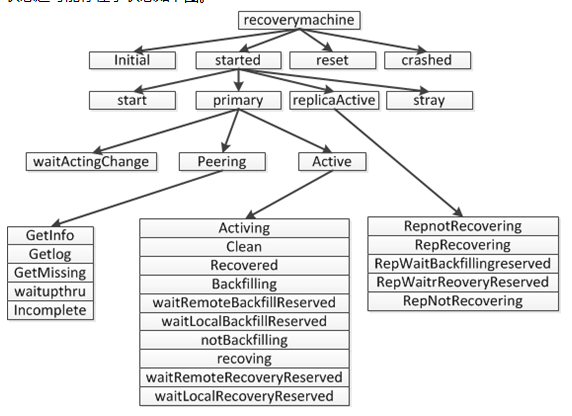
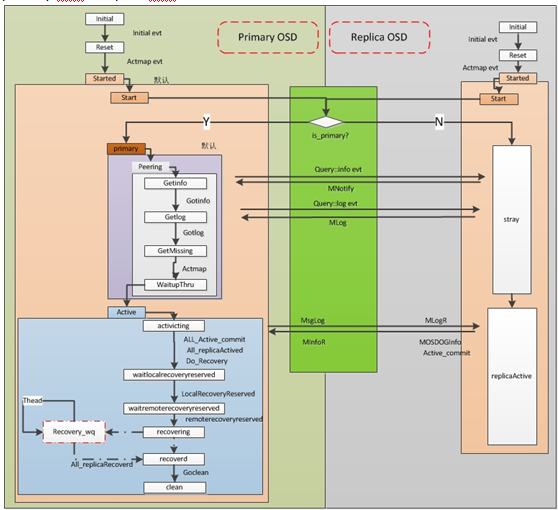
先附两张PG状态机的类型以及流程图:
参考资料:
作者:一只小江 http://my.oschina.net/u/2460844/blog/596895
作者:王松波 https://www.ustack.com/blog/ceph%EF%BC%8Dpg-peering/
作者:刘世民(Sammy Liu) 理解 OpenStack + Ceph (2):Ceph 的物理和逻辑结构 [Ceph Architecture] - SammyLiu - 博客园
作者:常涛 ceph 源代码分析 — peering 过程_ceph peering_Jack-changtao的博客-CSDN博客
感谢以上作者无私的分享。
相关文章:
Ceph源码解析:PG peering
集群中的设备异常(异常OSD的添加删除操作),会导致PG的各个副本间出现数据的不一致现象,这时就需要进行数据的恢复,让所有的副本都达到一致的状态。 一、OSD的故障和处理办法: 1. OSD的故障种类: 故障A:一…...
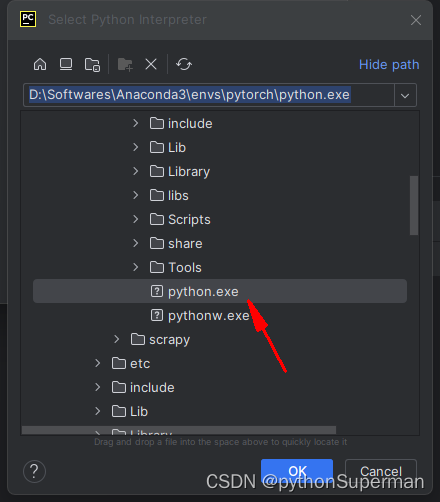
解决jupyter notebook可以使用pytorch而Pycharm不能使用pytorch的问题
之前我是用的这个目录下的Python 开始更新目录 1、 2、 3、...

对建造者模式理解
当对象成员变量太多时,使用建造方法给变量赋值往往变得很臃肿,所以可以这样做 public class Something {private String a;private String b;private String c;private String d;private String e;public Something(Builder builder) {this.a builder.…...

回归预测 | MATLAB实现CSO-ELM布谷鸟算法优化极限学习机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现CSO-ELM布谷鸟算法优化极限学习机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现CSO-ELM布谷鸟算法优化极限学习机多输入单输出回归预测(多指标,多图)效果一览基本介…...

静态链接库和动态链接库的区别
C静态链接库(Static Linking)和动态链接库(Dynamic Linking)的主要区别在于代码的组织和加载方式。 静态链接库 在编译时将库的代码和应用程序的代码合并在一起,生成一个单独的可执行文件。执行文件独立包含所需的库…...

使用 python 源码搭建 conda 环境
今天需要使用 python 2.6.8 的环境,发现 conda 设置成清华源后,没有旧版本了。所以打算从官网上下载一份 python 进行安装, 结果发现,conda 不能直接安装离线包(也可能我没找到方法),经过一番尝…...

dart 学习之 异步操作
import package:dio/dio.dart;// 定义一个异步函数,用于获取 URL 的内容 Future<String> getUrl(String url) async {Dio dio Dio();Response response await dio.get(url);return response.data; }void main() async {// 在主函数中执行异步操作var conten…...
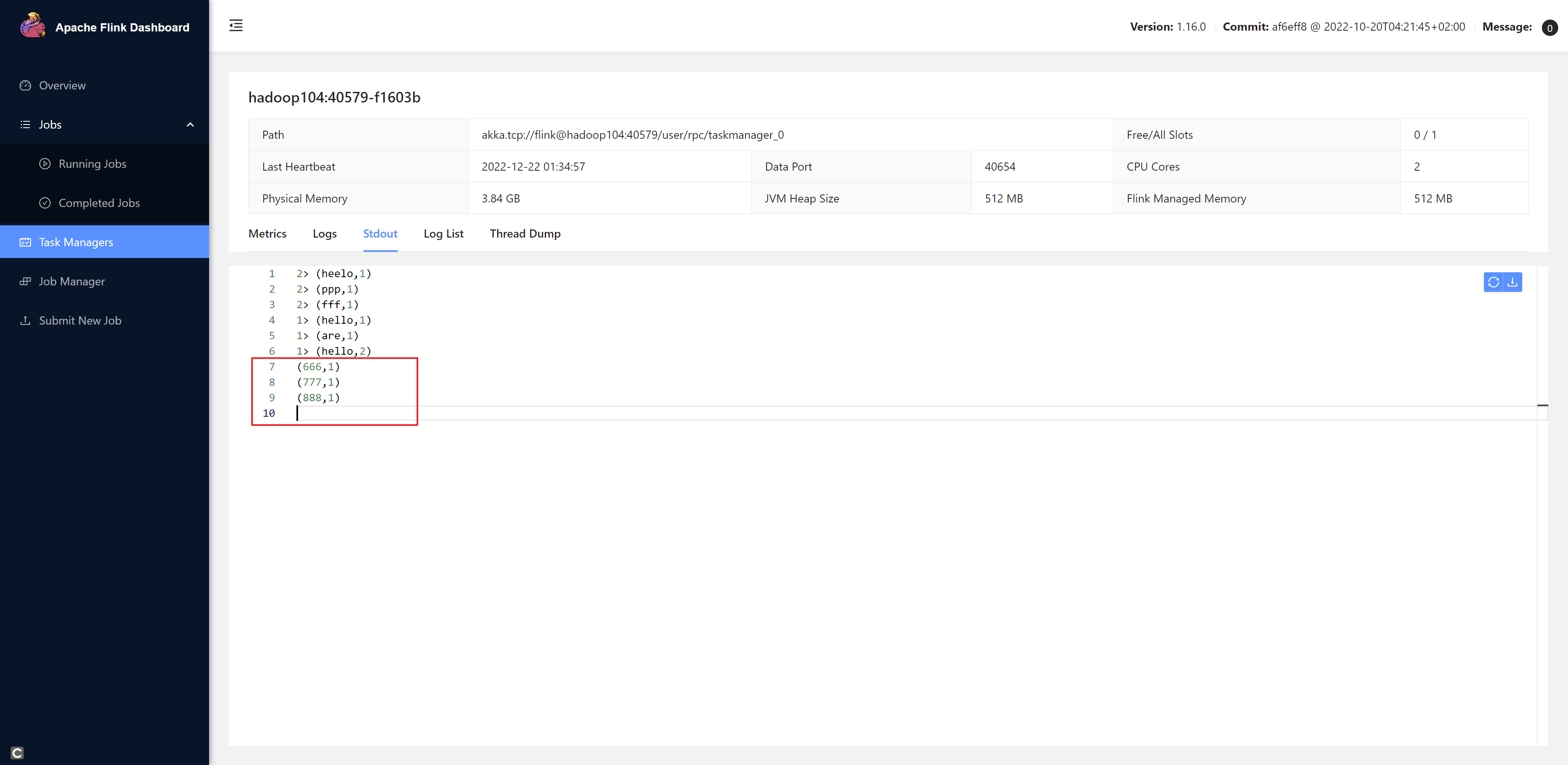
《Flink学习笔记》——第二章 Flink的安装和启动、以及应用开发和提交
介绍Flink的安装、启动以及如何进行Flink程序的开发,如何运行部署Flink程序等 2.1 Flink的安装和启动 本地安装指的是单机模式 0、前期准备 java8或者java11(官方推荐11)下载Flink安装包 https://flink.apache.org/zh/downloads/hadoop&a…...
网易新财报:游戏稳、有道进、云音乐正爬坡
今年以来,AI大模型的火热程度屡屡攀升,越来越多的企业都加入到了AI大模型的赛场中,纷纷下场布局。而在众多参与者中,互联网企业的身影更是频频浮现,比如,百度、阿里巴巴、腾讯等等。值得一提的是࿰…...
Docsify的评论系统gitalk配置过程
💖 作者简介:大家好,我是Zeeland,开源建设者与全栈领域优质创作者。📝 CSDN主页:Zeeland🔥📣 我的博客:Zeeland📚 Github主页: Undertone0809 (Zeeland)&…...
卡片开发应用上下文Context使用场景二)
HarmonyOS/OpenHarmony(Stage模型)卡片开发应用上下文Context使用场景二
3.创建其他应用或其他Module的Context 基类Context提供创建其他应用或其他Module的Context的方法为createModuleContext(moduleName:string),创建其他应用或者其他Module的Context,从而通过该Context获取相应的资源信息(例如获取其他Module的…...

数字货币量化交易平台
数字货币量化交易平台是近年来金融科技领域迅速崛起的一种创新型交易方式。它通过应用数学模型和算法策略,实现对数字货币市场的自动交易和风险控制。然而,要在这个竞争激烈的领域中脱颖而出,一个数字货币量化交易平台需要具备足够的专业性&a…...
)
2022 ICPC 济南 E Identical Parity (扩欧)
2022 ICPC 济南 E. Identical Parity (扩欧) Problem - E - Codeforces 大意:给出一个 n 和一个 k , 问是否能构造一个长 n 的排列使得所有长 k 的连续子序列和的奇偶性相同。 思路:通过分析可知 , 任两个间隔 k - 1 的元素奇偶…...

【BUG事务内消息发送】事务内消息发送,事务还未结束,消息发送已被消费,查无数据怎么解决?
问题描述 在一个事务内完成插入操作,通过MQ异步通知其他微服务进行事件处理。 由于是在事务内发送,其他服务消费消息,查询数据时还不存在如何解决呢? 解决方案 通过spring-tx包的TransactionSynchronizationManager事务管理器解…...
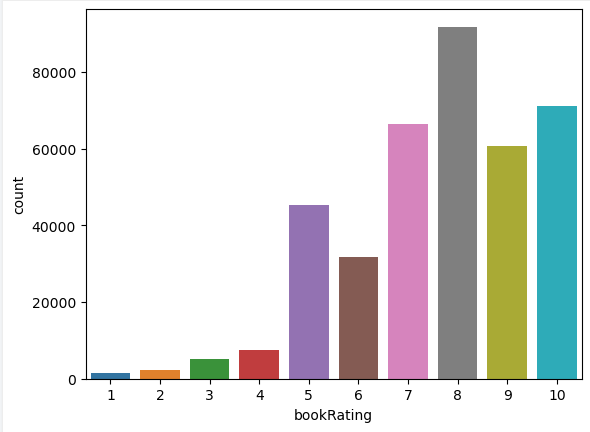
数据分析作业四-基于用户及物品数据进行内容推荐
## 导入支持库 import pandas as pd import matplotlib.pyplot as plt import sklearn.metrics as metrics import numpy as np from sklearn.neighbors import NearestNeighbors from scipy.spatial.distance import correlation from sklearn.metrics.pairwise import pairwi…...

在腾讯云服务器OpenCLoudOS系统中安装svn(有图详解)
1. 安装svn yum -y install subversion 安装成功: 2. 创建数据根目录及仓库 mkdir -p /usr/local/svn/svnrepository 创建test仓库: svnadmin create /usr/local/svn/test test仓库创建成功: 3. 修改配置test仓库 cd /usr/local/svn/te…...

C语言日常刷题5
文章目录 题目答案与解析1234567、 题目 1、以下叙述中正确的是( ) A: 只能在循环体内和switch语句体内使用break语句 B: 当break出现在循环体中的switch语句体内时,其作用是跳出该switch语句体,并中止循环体的执行 C: continue语…...
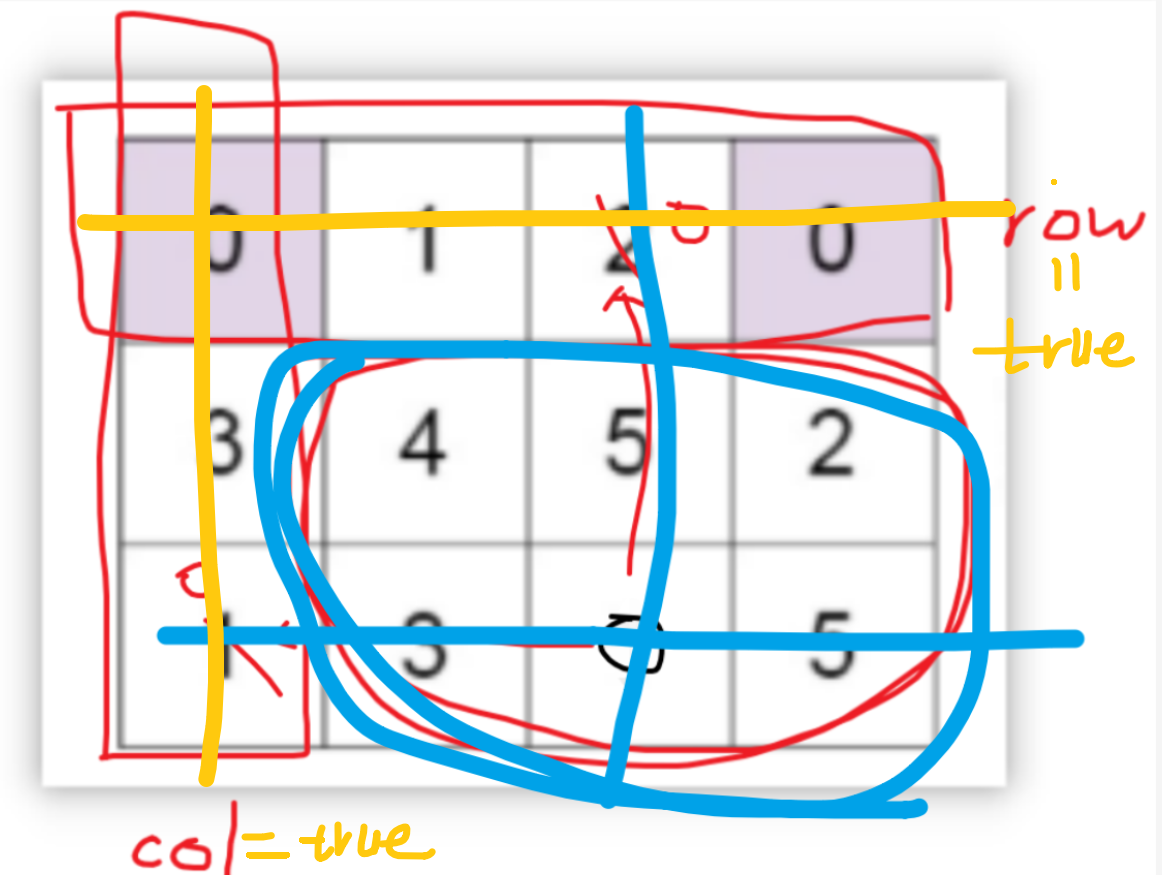
【LeetCode-中等题】73. 矩阵置零
题目 题解一:使用标记数组 public void setZeroes(int[][] matrix) {int m matrix.length;int n matrix[0].length;boolean[] row new boolean[m];boolean[] col new boolean[n];for(int i0; i< m;i){for(int j 0;j<n;j){if (matrix[i][j] 0) row[i]col…...

本地部署 FastGPT
本地部署 FastGPT 1. FastGPT 是什么2. 部署 FastGPT 1. FastGPT 是什么 FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景! …...

软件工程(十八) 行为型设计模式(四)
1、状态模式 简要说明 允许一个对象在其内部改变时改变它的行为 速记关键字 状态变成类 类图如下 状态模式主要用来解决对象在多种状态转换时,需要对外输出不同的行为的问题。比如订单从待付款到待收货的咋黄台发生变化,执行的逻辑是不一样的。 所以我们将状态抽象为一…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书
地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书 副标题:全要素三维动态重建井下场景,融合井下无感坐标解算、跨断面跨镜轨迹串联、身体指纹人员轨迹存档,井下风险前置感知、动态全程透明追溯 前言 矿山井下深部硐室与纵…...

如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程
如何快速掌握阴阳师自动化脚本:OAS解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本(Onmyoji Auto Script,…...

轻量级配置中心zcf:中小团队微服务配置管理实战指南
1. 项目概述:一个轻量级、高可用的配置中心最近在梳理团队内部的技术栈,发现一个挺有意思的现象:很多中小型项目,甚至是一些快速迭代的业务线,在配置管理上依然处于一种“原始”状态。要么是各种application.yml、appl…...

飞书自动化工具feishu-atuo:Python积木式开发与实战指南
1. 项目概述:飞书自动化,从零到一的效率革命 如果你和我一样,每天的工作流里都离不开飞书,那你肯定也经历过这些时刻:手动把日报、周报从文档复制到表格里归档;在多个群里重复发送同样的通知;为…...

韩国市场合规语音交付迫在眉睫!ElevenLabs韩文生成必须配置的4项GDPR+KCC隐私开关
更多请点击: https://intelliparadigm.com 第一章:韩国市场语音AI合规落地的紧迫性与战略意义 韩国《个人信息保护法》(PIPA)于2023年修订后,明确将语音生物特征数据列为“敏感信息”,要求语音AI系统在采集…...

AI智能体分类学:从原理到实践,构建高效Agent系统的设计指南
1. 项目概述与核心价值最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的现象:大家聊起Agent,要么是“它能帮我写代码”,要么是“它能自动处理客服”,但很少有人能系统地说清楚ÿ…...

解密ComfyUI-WanVideoWrapper:在ComfyUI中突破AI视频生成的技术壁垒
解密ComfyUI-WanVideoWrapper:在ComfyUI中突破AI视频生成的技术壁垒 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾想过将脑海中的创意场景转化为生动的视频内容࿰…...

5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程
5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 你是否正在寻找一种简单、快速且免费的方法,…...