Python中的一些常用操作
文章目录
- 一. Python操作之-- 使用Python 提取PDF文件中的表格数据!
- 二:
- 三: Python中的 @staticmethod@classmethod方法
- 四: 反斜杠 \
- 五: 终端的解释器提示符号修改
- 六: python使用json.dumps输出中文
- 七: itertools函数的使用,为高效循环而创建迭代器的函数
- 八: 将列表或者元祖中的数据合并为一个字符串
- 九: 判断某个参数是不是 另一种参数类型,例如 某时间格式数据 str = '2021-02-02' 是不是时间格式
- 十: 时间格式的类型转换,包括时间转换字符、字符转换时间等
- 十一: conda创建环境和删除环境
- 十三: Python 使用flask进行前端展示,以及进行 分页 展示
- 十四: Python使用 Flask中的 render_template() 函数
- 十五:python divmod() 返回的是商和余数的元祖
- 十六: reshape()的使用,
- 十七: expand_dim(数组,axis=[]) 对数组进行维度扩展
- 十八: as_list() 进行列表的转换,例如将一个元组进行列表转换
- 十九: 解决Linux中Python导入包路径错误
- 二十一:Python中的string模块的使用
一. Python操作之-- 使用Python 提取PDF文件中的表格数据!
Python提供了许多可用于pdf表格识别的库,如camelot、tabula、pdfplumber等。
综合来看,pdfplumber库的性能较佳,能提取出完整、且相对规范的表格
该库的安装方式 : pip install pdfplumber
库中提供两种PDF表格提取函数:
-
.extract_tables()
-
.extract_table()
这两种函数 -
.extract_tables()
可输出页面中的所有表格,并且返回一个嵌套列表,其结构层次为table→row→cell
with pdfplumber.open(filepath,‘w’) as pdf: pdf 文件读取方式
page = pdf.pages[45] #这里设置的是想要处理的页面
读取方式是:
page.extract_tables()
- .extract_table()
返回多个独立列表,其结构层次为row→cell。
若页面中存在多个行数相同的表格,则默认输出顶部表格;
否则,仅输出行数最多的一个表格。
注意:此时,表格的每一行都作为一个单独的列表,列表中每个元素即为原表格的各个单元格内容。
在此基础上,从PDF文件中提取表格数据,一种思路就是将提取出来的列表视为一个字符串就,
结合Python的正则表达式re模块进行字符串处理,之后将其保存为以标准英文逗号分割、可被Excel识别的csv格式文件
二:
import pygal 可以
pie_chart = pygal.Pie() #1. 实现扇形图的绘制
#pie_chart = pygal.Line() # 实现多重曲线趋势的绘制
#pie_chart = pygal.Radar() # 可以实现正六边型的趋势绘制
pie_chart.title = ‘’
pie_chart.add(‘name’,比例)
三: Python中的 @staticmethod@classmethod方法
Python 中类中定义的方法可以是:
- @classmethod方法 是装饰的类方法
- @staticmethod@classmethod方法 是装饰的静态方法
- 用的最多的还是不带装饰器的实例方法
装饰之后的函数在进行调用的时候会有着不同的形式
四: 反斜杠 \
- 在行尾的时候用作续航符号
- 在字符串中 、使用转义字符,可一件普通的字符转化为有特殊含义的字符。
如: \n \t
五: 终端的解释器提示符号修改
例如: 将自带的 <<<< 改为 -----
import sys
sys.ps1 = ‘-----’ 进行更改,可以更改为任何东西
六: python使用json.dumps输出中文
在使用json.dumps时注意一个问题
import json
print(json.dumps(‘中国’))
返回的是 “\u4e2d\u56fd”
输出的会是
‘中国’ 中的ascii字符码,而不是真正的中文。
这是因为json.dumps序列化时对中文默认使用的ascii编码
想输出真正的中文需要指定ensure_ascii=False:
中文的时候正确使用方法: 添加上ensure_ascii 参数
import json
print(json.dumps(‘中国’, ensure_ascii=False))
“中国”
七: itertools函数的使用,为高效循环而创建迭代器的函数
下面的网址:包含所有的itertools的模块函数
https://docs.python.org/zh-cn/3.8/library/itertools.html
八: 将列表或者元祖中的数据合并为一个字符串
1. 语法 str.join(squence)
2. 示例>>> str = '-' #指定字符之间的符号>>> seq = ('b','o','o','k')>>> print str.join(seq)>>> b-o-o-k # 输出结果
九: 判断某个参数是不是 另一种参数类型,例如 某时间格式数据 str = ‘2021-02-02’ 是不是时间格式
isinstace(str,datetime.datetime)
十: 时间格式的类型转换,包括时间转换字符、字符转换时间等
import datetime1. 日期时间格式转字符 使用的是 strftime() 函数
date = 2021-12-23
datetime.strptime('2021-12-23','%Y-%m-%d) #这里可以根据需要进行转换 例如:没有中间的'-'符号date.strftime('%Y-%m-%d')
#'2021-12-23'
date.strftime('%Y%m%d')
#'20211223'
date.strftime('%Y-%m')
#'2021-12'2. 字符转换日期时间
法一:
datetime.strptime('2018-09-08','%Y-%m-%d')
#datetime.datetime(2018, 9, 8, 0, 0)法二: 使用的是pandas里面的 to_datetime() 函数
import pandas as pdpd.to_datetime('2018-09-08')
#Timestamp('2018-09-08 00:00:00')
pd.to_datetime('201909',format='%Y%m')
#Timestamp('2019-09-01 00:00:00')3. 数值转换日期
dt = 20180908
datetime.strptime(str(dt),'%Y%m%d')
#datetime.datetime(2018, 9, 8, 0, 0)4. pandas中的时间处理
import random
df = pd.DataFrame({'some_data' : [random.randint(100,999) for i in range(1,10)],'a_col' : '2019-07-12','b_col' : datetime.datetime.now().date(),'c_col' : time.time()},index=range(1,10))
十一: conda创建环境和删除环境
删除虚拟环境:
(推荐教程:Python入门教程)
conda remove -n your_env_name(虚拟环境名称) --all删除虚拟环境中的包:
conda remove --name $your_env_name $package_name(包名)退出虚拟环境:Linux:source deactivate your_env_name(虚拟环境名称)Windows:deactivate 也可以使用`activate root`切回root环境。
十三: Python 使用flask进行前端展示,以及进行 分页 展示
1. 使用flask进行前端展示2. 使用flask进行 分页 展示from flask_paginate import Pagination,get_page_parameter
# from flask import Flask, render_template,request
from flask_sqlalchemy import SQLAlchemy
上面的两个是我找到得两个进行分页的参数,目前不知道区别以及期使用用途使用flask_paginate分页技术进行分页
使用参数:
from flask_paginate import Pagination, get_page_parameter
from Config import DBsession, EventRecordDB, draughtFan, wind, and_, StatiscDataPagination: 类函数
get_page_parameter: 获取当前翻页的参数
上面的两个参数是flask-paginate的主要点1. 在视图函数定义方法
pagination = Pagination('参数')
page = request.args.get(get_page_parameter(), type=int, default=1)Pagination.__init__(**kwargs) 注意:标注 --- 的是重点关注参数
found=0: 当使用搜索是使用
page: 当前页, 使用实例对象中的page -----------------------
per_page: 每页显示多少项, 可以使用数据表的切片slice操作来定义, per_page ----------------
page_parameter: 页面参数, 默认为page, http://localhost:5000/?page=2
prev_label: 上一页, 默认为<<, 可以定义prev_label='上一页'
next_label: 下一页, 默认为>>, 可以定义next_label='下一页'
total: 总共有多少页 -----------------------
bs_version=2: Bootstrap版本, 默认为版本2 -------------------------
注意: 如果使用的是Boostrap3的CDN, 那么就要设置bs_version=3, 否则会无法正常显示
{{ pagination.links }} 这段 代码放在HTML页面中,作用就是,将我们的分页放在先要展示的位置 links 表示的是链接网址以上为主要参数的使用具体使用方法:# 获取当前为第几页
page = request.args.get(get_page_parameter(), type=int, default=1)
# 定义每页显示多少项
start = (page-1)*config.PER_PAGE
end = start + config.PER_PAGE
# 使用切片来显示每页显示多少项
posts = PostModel.query.slice(start, end)
pagination = Pagination(bs_version=3, page=page, total=PostModel.query.count())context = {"posts": posts,"pagination": pagination,# ... others
}
return render_template('index.html', **context)2. 在模板中使用方法
直接在想要放置分页条的地方使用 ↓↓↓↓
{{ pagination.links }}
十四: Python使用 Flask中的 render_template() 函数
render_template() 作用:在Python代码中 直接生成 HTML 缺点很多,比如笨拙,效率低,可读性差。
因此, Flask 提供了 Jinja2 模板引擎来帮助开发者高效灵活生成HTMLhtml模板文件的位置
模板即自己写好的模板html文件,需要放在templates文件夹内。目录结构如下:
1.
/application.py
/templates/hello.html
2.
/application/__init__.py/templates/hello.html
以上两种存放情况。具体的实施方法: `render_template()`函数是`flask`函数的,他从模板文件夹`templates`中呈现给定的模板上下文。语法以及参数:
import flask
flask.render_template(template_name, **context)render_template()函数需要调用flask包template_name 参数是: 模板的文件名字 类型是字符串类型,不可省略context 参数是: 模板的参数 由模板参数和对应的值组成的字典,可以省略的参数返回值: str render_template() 函数返回替换模板参数后的模板文本。有两种使用情况:1. 模板中没有参数,就是说不需要给模板中给定参数。例如:<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Hello world</title></head><body><h1> Hello World! </h1></body></html>import flaskapp = flask.Flask(__name__)@app.route("/hello")def hello():return flask.render_template("hello_world.html")if __name__ == '__main__':app.run()运行后在浏览器中输入http://地址/hello,结果如下:2. 给模板中传递参数。例如: 模板../templates/for.html如下:<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>Jinja2 Circulation Control</title></head><body><h1> {{product}} list: </h1><ul>{% for product in products %}<li>{{product}}</li>{% endfor %}</ul></body></html>import flaskapp = flask.Flask(__name__)@app.route("/")def index():products = ["iphoneX", "MacBook Pro", "Huawei"]kwargs = {"products": products}return flask.render_template("for.html", **kwargs)if __name__ == '__main__':app.run()
十五:python divmod() 返回的是商和余数的元祖
使用功能方法:divmod(x, y)函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。# 我们这里要计算的是总页数 如果有余数的话还要+1才是总页数。
十六: reshape()的使用,
例如: reshape(2,6) 就是将一个数转换成 2行 6列reshape(8,-1) 就是将一个数组转换成 8行 的数据,至于是几列会自动进行计算。同理的(-1,5) 就是固定列的数量,行数进行自动计算。
十七: expand_dim(数组,axis=[]) 对数组进行维度扩展
一般的 axis=[-1] 的意思就是在最后面进行维度扩展 [1,2,3] -->> [1,2,3,1]
axis = 多少 就是说在那个位置进行扩展 0,1,2,3 再多的话,就会提示错误,不管多少的
维度,他们的数据总量是不变的。
关键理解:就是说 expand_dim(input,axis=[]) input的shape是固定的,扩展的结果就是在相应的维度上进行扩展,
只要保证数据的参数量不变,不过一般好像都是 1。
详细介绍的网址:
https://blog.csdn.net/hong615771420/article/details/83448878#:~:text=np.%20expand_dims%20%E7%9A%84%E4%BD%9C%E7%94%A8%E6%98%AF%E9%80%9A%E8%BF%87%E5%9C%A8%E6%8C%87%E5%AE%9A%E4%BD%8D%E7%BD%AE%E6%8F%92%E5%85%A5%E6%96%B0%E7%9A%84%E8%BD%B4%E6%9D%A5%E6%89%A9%E5%B1%95%E6%95%B0%E7%BB%84%E5%BD%A2%E7%8A%B6%EF%BC%8C%20%E5%87%BD%E6%95%B0%E6%A0%BC%E5%BC%8F%E5%A6%82%E4%B8%8B%EF%BC%9A%20np.%20expand_dims%20%28array%2C%20axis%29,np.%20expand_dims%2C%20np%20.newaxis%29%E5%92%8C%E5%88%A0%E9%99%A4%E7%BB%B4%E5%BA%A6%20%28%20np%20.squeeze%29%E7%9A%84%E6%96%B9%E6%B3%95.%20cxx654%E7%9A%84%E5%8D%9A%E5%AE%A2.
十八: as_list() 进行列表的转换,例如将一个元组进行列表转换
a = (1,3)
a.as_list()
一般用于在TensorFlow中的获取某个 tensor(张量) 的形状后 get_shape().as_list()
这样使用,如此可获取 某一维度的形状。
十九: 解决Linux中Python导入包路径错误
原因:IDE环境下,例如:pycharm 下,会自动搜索代码所在的目录,寻找相关的包,而Linux环境下,
直接运行 .py 文件,只会搜索默认的路径,此时需要把代码所在的目录添加到 sys.path 当中。
解决步骤:1. 终端进入Python,键入: import sys 并且查看 print(sys.path)2. cd 进入上述打印出的路径的 site-packages 目录下3. 增加 .pth 文件 vim code_path.pth (若是没有这个文件,此命令会自动生成该文件)4. 在该文件下添加你的代码目录(代码目录就是我们的项目文件所在目录),按 Esc 键入: :wq 进行保存。
二十一:Python中的string模块的使用
String模块中的常量:
string.digits:数字0~9
string.ascii_letters:所有字母(大小写)
string.lowercase:所有小写字母
string.printable:可打印字符的字符串
string.punctuation:所有标点
string.uppercase:所有大写字母
相关文章:

Python中的一些常用操作
文章目录 一. Python操作之-- 使用Python 提取PDF文件中的表格数据!二:三: Python中的 staticmethodclassmethod方法四: 反斜杠 \五: 终端的解释器提示符号修改六: python使用json.dumps输出中文七…...

go语言调用python脚本
文章目录 代码gopython 在 go语言中调用 python 程序,你可能会用到 代码 亲测 go 测试 go 文件 func TestR(t *testing.T) {// 设置要执行的Python脚本和参数scriptPath : "../nansen.py"arg1 : "nansen"// 执行Python脚本cmd : exec.Comm…...

2.3 【MySQL】命令行和配置文件中启动选项的区别
在命令行上指定的绝大部分启动选项都可以放到配置文件中,但是有一些选项是专门为命令行设计的,比方说defaults-extra-file 、 defaults-file 这样的选项本身就是为了指定配置文件路径的,再放在配置文件中使用就没啥意义了。 如果同一个启动选…...

外部库/lib/maven依赖项 三者关系
外部库(存放项目初始配置的jar包)(它的文件夹里并没有包含lib文件夹的引的外部的依赖的jar包) lib(存放外部导入到项目的依赖的jar包) maven依赖项(管理项目所有的jar包依赖) 三者存放jar包的关系 项目所依赖的全部的jar包 maven依赖项的jar包 外部库中的jar包 lib中的…...
在线制作作息时间表
时光荏苒,岁月如梭,人们描述时光易逝的句子,多如星河。 一寸光阴一寸金,寸金难买寸光阴。 人生就是一段时间而已,所以我明白了一个道理 人生之中最大的浪费就是时间的浪费 因此我想我们教给我们孩子重要的一课应该也是…...

他们朝我扔泥巴(scratch)
前言 纯~~~属~~~虚~~~构~~~(同学看完短视频要我做,蟹蟹你) 用scratch做的,幼稚得嘞( ̄_ ̄|||)呵呵(强颜欢笑) 完成视频 视频试了好久,就是传不上来,私信我加我…...

docker部署前端项目保姆级教程
本地启动docker(有不会启动的吗?下载docker(小海豚)双击起来就行) 准备阿里云账号(免费) 没有就去注册一个,记住密码后面要用到 官网地址:阿里云登录 - 欢迎登录阿里云…...

《C和指针》笔记13: static关键字总结
这里对static关键字做一下总结,可以回顾一下前面两篇博客的文章。 《C和指针》笔记11: external和internal链接属性 《C和指针》笔记12: 存储类型(自动变量、静态变量和寄存器变量) 当它用于函数定义时,或用于代码块之外的变量声…...

Docker harbor私有仓库部署与管理
一、搭建本地私有仓库二、Harbor私有仓库部署与管理1、Harbor概述2、Harbor的特性3、Harbor的核心组件3.1 Proxy3.2 Registry3.3 Core services3.3.1 UI(harbor-ui)3.3.2 WebHook3.3.3 Token 服务 3.4 Database(harbor-db)3.5 Log…...

解锁Selenium的力量:不仅仅是Web测试
Selenium简介 Selenium,作为Web应用测试的领军者,已经成为了无数开发者和测试人员的首选工具。它不仅仅是一个自动化测试工具,更是一个强大的Web应用交互框架。 Selenium的起源与发展 Selenium的历史可以追溯到2004年,由Jason Hu…...
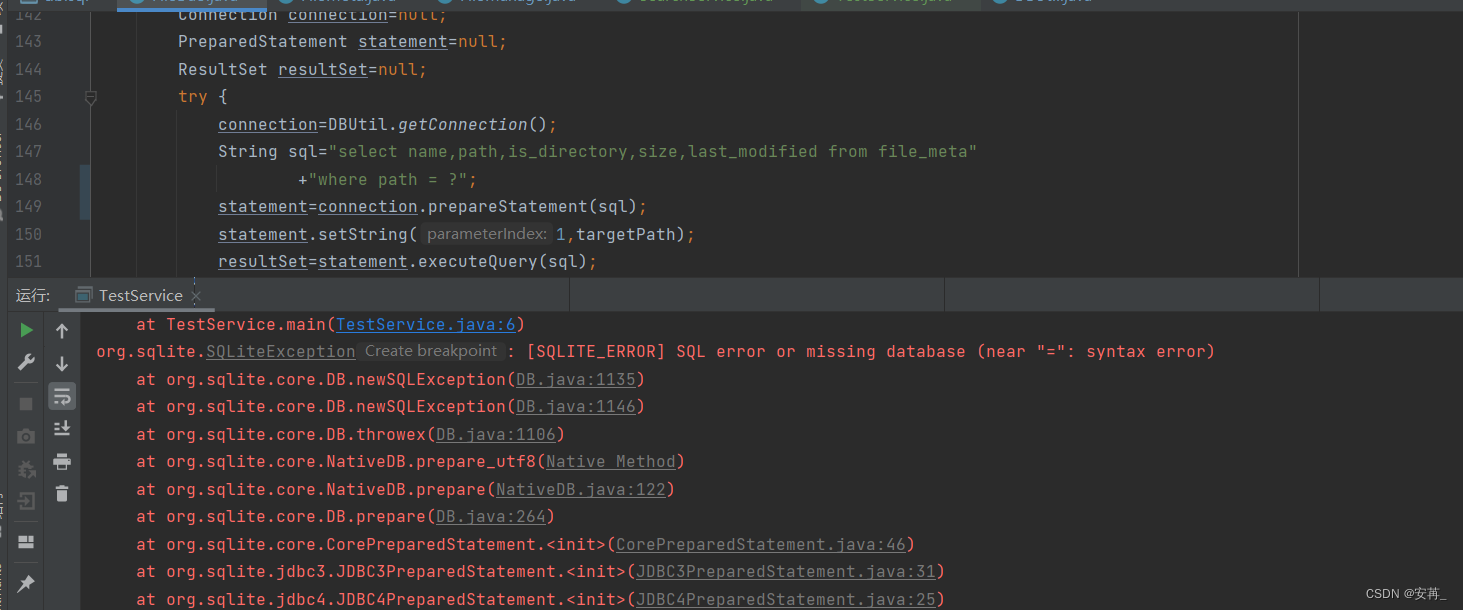
[SQLITE_ERROR] SQL error or missing database (near “=“: syntax error)【已解决】
这个报的错误是语法错误,但是我并没有看出来这行代码有什么错。 通过排除掉下边两个问题解决的 从增加记录方法复制的下来的代码,只删除了关闭自动提交事务,但是connection.commit忘记删除executeQuery和executeUpdate方法的用法忘记了&…...

【视觉系统】笔芯内径机器视觉测量软硬件方案-康耐德智能
检测内容 笔芯内径机器视觉测量系统 检测要求 精度0.03mm,速度120~180个/分钟 视觉可行性分析 对样品进行了光学实验,并进行图像处理,原则上可以使用机器视觉系统进行测试测量。 结果: 对所有样品进行分析,可以在不…...

将文件夹的名称写到Excel中
查看文件夹名称 os.listdir()函数会返回指定路径下的所有文件和文件夹的名称列表,包括隐藏文件和文件夹 import osfolder_path . # 文件夹路径 # . is当前路径 files os.listdir(folder_path) # 获取文件夹内所有文件的名称列表for filename in files:print(fi…...

关于Vue CLI项目 运行发生了 less-lorder错误的解决方案
Module node found :Error: Can’t resolve ‘less-loader’ 报错 文章目录 Module node found :Error: Cant resolve less-loader 报错解决方案:安装 webpack 和 less安装 less-loader 问题: 在运行vue项目的时候发生: Module not found: Er…...

【Qt学习】02:信号和槽机制
信号和槽机制 OVERVIEW 信号和槽机制一、系统自带信号与槽二、自定义信号与槽1.基本使用student.cppteacher.cppwidget.cppmain.cpp 2.信号与槽重载student.cppteacher.cppwidget.cppmain.cpp 3.信号连接信号4.Lambda表达式5.信号与槽总结 信号槽机制是 Qt 框架引以为豪的机制之…...

软件工程(十三) 设计模式之结构型设计模式(一)
前面我们记录了创建型设计模式,知道了通过各种模式去创建和管理我们的对象。但是除了对象的创建,我们还有一些结构型的模式。 1、适配器模式(Adapter) 简要说明 将一个类的接口转换为用户希望得到的另一个接口。它使原本不相同的接口得以协同工作。 速记关键字 转换接…...
Node与Express后端架构:高性能的Web应用服务
在现代Web应用开发中,后端架构的性能和可扩展性至关重要。Node.js作为一个基于事件驱动、非阻塞I/O的平台,以及Express作为一个流行的Node.js框架,共同构建了高性能的Web应用服务。 在本文中,我们将深入探讨Node与Express后端架构…...

C++炸弹小游戏
游戏效果 小人可以随便在一些元素(如石头,岩浆,水,宝石等)上跳跃,“地面”一直在上升,小人上升到顶部或者没有血的时候游戏结束(初始20点血),小人可以随意放炸…...

发送通知消息
目录 1 himall3.0商城源码 1.1 SendMessageOnOrderShipping 1.1.1 //发送通知消息 1.2 /// 所有订单是否都支付 1.2.1 //有待付款的订单,则未支付完成 himall3.0商城源码 public static List<InvoiceTitleInfo> GetInvoiceTitles(long userid) { re…...

Python报错:PermissionError: [Errno 13] Permission denied解决方案
Python报错:PermissionError: [Errno 13] Permission denied 翻译为:权限错误:[errno 13]权限被拒绝 错误产生的原因是文件无法打开,可能产生的原因是文件找不到,或者被占用,或者无权限访问,或者…...

【深度学习】Ubuntu服务器从零部署:Anaconda环境搭建、PyCharm配置与YOLOv8项目实战全解析
1. 安装Anaconda:打造专属Python工作区 第一次在Ubuntu服务器上配置深度学习环境时,我强烈推荐从Anaconda开始。这个工具就像个万能工具箱,能帮你轻松管理各种Python版本和依赖包。记得去年给实验室新服务器配环境时,用Anaconda省…...

Heightmapper完全指南:5步将全球地形数据变成3D模型
Heightmapper完全指南:5步将全球地形数据变成3D模型 【免费下载链接】heightmapper interactive heightmaps from terrain data 项目地址: https://gitcode.com/gh_mirrors/he/heightmapper 还在为3D地形建模发愁吗?Heightmapper让你的地形创作效…...

泛微E-Office V10 OfficeServer 文件上传漏洞深度剖析与实战复现
1. 漏洞背景与影响范围 泛微E-Office作为国内广泛使用的协同办公系统,其V10版本中的OfficeServer.php组件存在高危文件上传漏洞。这个漏洞的本质在于服务端未对上传文件的类型、内容及路径进行严格校验,导致攻击者可以绕过常规防护机制,直接上…...

GoPaw框架解析:基于Go的高性能网络任务调度与并发处理实践
1. 项目概述与核心价值最近在折腾一个需要处理大量网络请求和并发任务的小工具,偶然间在GitHub上看到了一个叫GoPaw的项目,作者是Aragorn271828。这个项目名挺有意思,Paw是爪子的意思,GoPaw直译过来就是“Go爪子”,听起…...

Node.js服务端应用无缝集成Taotoken提供多模型AI能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js服务端应用无缝集成Taotoken提供多模型AI能力 将大模型能力集成到Node.js后端服务中,可以快速为应用增加智能对…...

Arm Neoverse CMN-650信号接口架构与设计解析
1. Arm Neoverse CMN-650信号接口架构解析在现代SoC设计中,一致性互连网络如同城市交通系统,负责协调各个功能区块的数据流动。Arm Neoverse CMN-650作为第五代一致性网状网络IP,其信号接口设计体现了高性能计算对带宽、延迟和可靠性的极致追…...

基于MCP协议连接AI与Postal邮件服务器的自动化实践
1. 项目概述:一个连接Postal与MCP的桥梁最近在折腾一些自动化工作流,发现很多内部系统的数据都通过Postal(一个开源的邮件服务器管理平台)来流转,而我又想用上新兴的模型上下文协议(MCP)来让AI助…...

GitHub平台功能全解析:AI代码创作、安全保障及多场景解决方案助力开发
导航菜单可进行切换导航操作。[ ](/)[ 登录 ](/login?return_tohttps%3A%2F%2Fgithub.com%2Fanthropics%2Fclaude-for-legal)可进行外观设置。平台AI代码创作- [GitHub Copilot:借助AI编写更优质代码](https://github.com/features/copilot)- [GitHub Spark&#x…...
:波数域解析、阵列流形可视化与频率响应设计)
阵列信号处理笔记(2):波数域解析、阵列流形可视化与频率响应设计
1. 波数域解析:空域频率的物理意义 波数域是理解阵列信号处理的关键视角。简单来说,波数(k)相当于空域中的"频率",就像时域中的角频率(ω)描述信号随时间变化的快慢一样,波…...

大语言模型智能体长期记忆解决方案:LightMem架构解析与LangChain实战
1. 项目概述:轻量化记忆增强的智能体新范式最近在探索大语言模型智能体应用时,一个核心痛点始终绕不开:如何让智能体在长对话或多轮任务中,记住关键信息,并做出连贯、精准的决策?传统的做法要么是将整个对话…...