《Flink学习笔记》——第七章 处理函数
为了让代码有更强大的表现力和易用性,Flink 本身提供了多层 API
在更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process)操作——它是所有转换算子的一个概括性的表达,可以自定义处理逻辑,所以这一层接口就被叫作“处理函数”(process function)。是整个DataStream API的基础
7.1 基本处理函数
处理函数主要是定义数据流的转换操作,Flink提供的处理函数类接口ProcessFunction
7.1.1 处理函数的功能和使用
我们之前讲过的MapFunction(一一处理,仅仅拿到数据)、AggregateFunction(窗口聚合,除了数据还可以拿到当前的状态)
另外,RichMapFunction提供了获取上下文的方法——getRuntimeContext(),可以拿到状态,并行度、任务名等运行时信息
但上面这些无法拿到事件的时间戳或者当前水位线。
而在很多应用需求中,要求我们对时间有更精细的控制,需要能够获取水位线,甚至要“把控时间”、定义什么时候做什么事,这就不是基本的时间窗口能够实现的了,所以这个时候就要用到底层的API——处理函数ProcessFunction了
- 提供“定时服务”,可以通过它访问事件流中的事件、时间戳、水位线,甚至可以注册“定时事件”
- 继承了AbstractRichFunction,拥有富函数所有特性
- 可以直接将数据输出到侧输出流
使用:
直接基于 DataStream 调用.process()方法就可以了。方法需要传入一个 ProcessFunction 作为参数,用来定义处理逻辑。
stream.process(new MyProcessFunction())
7.1.2 ProcessFunction解析
public abstract class ProcessFunction<I, O> extends AbstractRichFunction{public abstract void processElement(I var1, ProcessFunction<I, O>.Context var2, Collector<O> var3);public void onTimer(long timestamp, ProcessFunction<I, O>.OnTimerContext ctx, Collector<O> out);
}
1.抽象方法.processElement()
- var1:正在处理的数据
- var2:上下文
- var3:“收集器”,用于返回数据
2.非抽象方法.onTimer()
- 用于定义定时触发的操作
7.1.3 处理函数的分类
Flink 中的处理函数其实是一个大家族,ProcessFunction 只是其中一员
Flink 提供了 8 个不同的处理函数:
(1) ProcessFunction
最基本的处理函数,基于 DataStream 直接调用.process()时作为参数传入
(2) KeyedProcessFunction
对流按键分区后的处理函数,基于 KeyedStream 调用.process()时作为参数传入。要想使用定时器,比如基于 KeyedStream
(3) ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于 WindowedStream 调用.process()时作为参数传入
(4)ProcessAllWindowFunction
同样是开窗之后的处理函数,基于 AllWindowedStream 调用.process()时作为参数传入
(5) CoProcessFunction
合并(connect)两条流之后的处理函数,基于 ConnectedStreams 调用.process()时作为参数传入
(6) ProcessJoinFunction
间隔连接(interval join)两条流之后的处理函数,基于 IntervalJoined 调用.process()时作为参数传入
(7)BroadcastProcessFunction
广播连接流处理函数,基于 BroadcastConnectedStream 调用.process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未 keyBy 的普通 DataStream 与一个广播流(BroadcastStream)做连接(conncet)之后的产物
(8) KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于 BroadcastConnectedStream 调用.process()时作为参数传入。与 BroadcastProcessFunction 不同的是,这时的广播连接流,是一个 KeyedStream 与广播流(BroadcastStream)做连接之后的产物
7.2 按键分区处理函数
public abstract class KeyedProcessFunction<K, I, O> extends AbstractRichFunction
只有在 KeyedStream 中才支持使用 TimerService 设置定时器的操作,所以一般情况下,我们都是先做了 keyBy 分区之后,再去定义处理操作;代码中更加常见的处理函数是 KeyedProcessFunction,最基本的 ProcessFunction 反而出镜率没那么高。KeyedProcessFunction 可以说是处理函数中的“嫡系部队”,可以认为是 ProcessFunction 的一个扩展。
7.2.1 定时器(Timer)和定时服务(TimerService)
首先通过定时服务注册一个定时器,ProcessFunction 的上下文(Context)中提供了.timerService()方法,可以直接返回一个 TimerService 对象。
TimerService 是 Flink 关于时间和定时器的基础服务接口,包含以下六个方法:
// 获取当前的处理时间
long currentProcessingTime();// 获取当前的水位线(事件时间)
long currentWatermark();// 注册处理时间定时器,当处理时间超过 time 时触发
void registerProcessingTimeTimer(long time);// 注册事件时间定时器,当水位线超过 time 时触发
void registerEventTimeTimer(long time);// 删除触发时间为 time 的处理时间定时器
void deleteProcessingTimeTimer(long time);// 删除触发时间为 time 的处理时间定时器
void deleteEventTimeTimer(long time);
7.2.2 KeyedProcessFunction的使用
与 ProcessFunction 的定义几乎完全一样,区别只是在于类型参数多了一个 K, 这是当前按键分区的 key 的类型。在KeyedProcessFunction中可以注册定时器,定义定时器触发逻辑。
KeyedProcessFunction是个抽象类,继承了AbstractRichFunction。
public abstract class KeyedProcessFunction<K, I, O> extends AbstractRichFunction
主要有两个核心的方法:
// 定义处理每个元素的逻辑
public abstract void processElement(I value, Context ctx, Collector<O> out)// 定时器触发时处理逻辑
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out)
从上面可以看到,参数里面都有Context(这里OnTimerContext继承了Context),所以都可以通过
ctx.timerService().registerEventTimeTimer(long time);
去注册定时器。
示例:
自定义数据源
public class CustomSource implements SourceFunction<Event> {@Overridepublic void run(SourceContext<Event> ctx) throws Exception {// 直接发出一条数据ctx.collect(new Event("Mark", "./hhhh.com", 1000L));// 中间停顿5秒Thread.sleep(5000L);// 发出10秒后的数据ctx.collect(new Event("Mark", "/home", 11000L));Thread.sleep(5000L);// 发出 10 秒+1ms 后的数据ctx.collect(new Event("Alice", "./cart", 11001L));Thread.sleep(5000L);}@Overridepublic void cancel() {}
}
创建一个KeyedProcessFunction实现类
public class MyKeyedProcessFunction extends KeyedProcessFunction<Boolean, Event, String> {@Overridepublic void processElement(Event value, KeyedProcessFunction<Boolean, Event, String>.Context ctx, Collector<String> out) throws Exception {out.collect("数据到达,时间戳为:" + ctx.timestamp());out.collect("数据到达,水位线为:" + ctx.timerService().currentWatermark());// 注册一个 1 秒后的定时器ctx.timerService().registerEventTimeTimer(ctx.timestamp() + 1000L);out.collect(String.format("注册定时器:%d%n-------分割线-------", ctx.timestamp() + 1000L));}@Overridepublic void onTimer(long timestamp, KeyedProcessFunction<Boolean, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {out.collect("定时器触发,触发时间:" + timestamp);}
}
主函数
public class EventTimeTimerTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Event> stream = env.addSource(new CustomSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event element, long recordTimestamp) {return element.getTimestamp();}}));stream.keyBy(data->true).process(new MyKeyedProcessFunction()).print();env.execute();}
}
输出结果:
数据到达,时间戳为:1000
数据到达,水位线为:-9223372036854775808
注册定时器:2000
-------分割线-------
数据到达,时间戳为:11000
数据到达,水位线为:999
注册定时器:12000
-------分割线-------
定时器触发,触发时间:2000
数据到达,时间戳为:11001
数据到达,水位线为:10999
注册定时器:12001
-------分割线-------
定时器触发,触发时间:12000
定时器触发,触发时间:12001
输出结果解释:
当第一条数据 Event(“Mark”, “./hhhh.com”, 1000L) 过来,由于水位线生成的周期是默认(200ms)一次,所以第一次数据过来时,水位线没有更新,为默认值Long.MIN_VALUE,此时注册一个以事件时间为准加1000ms的定时器。所以输出就是:
数据到达,时间戳为:1000
数据到达,水位线为:-9223372036854775808
注册定时器:2000
-------分割线-------过了200ms后,到了水位线生成时间,此时最大时间戳为1000,由于没有设置水位线延迟,所以默认减1ms。此时水位线为:1000-1=999.并未达到定时器触发时间(2000)
过了5秒钟第二条数据 Event(“Mark”, “/home”, 11000L) 过来,输出并注册了一个12000的定时器:
数据到达,时间戳为:11000
数据到达,水位线为:999
注册定时器:12000
-------分割线-------达到水位线生成时间后,更新为11000-1=10999,此时达到(注册定时器:2000)触发时间,所以输出:
定时器触发,触发时间:2000
过了5秒,数据 Event(“Alice”, “./cart”, 11001L) 过来,输出并注册了一个12001的定时器
数据到达,时间戳为:11001
数据到达,水位线为:10999
注册定时器:12001
-------分割线-------达到水位线生成时间后,更新为11001-1=11000
过了5秒,数据发送执行完毕,第三条数据发出后再过 5 秒,没有更多的数据生成了,整个程序运行结束将要退出,此时 Flink 会自动将水位线推进到长整型的最大值(Long.MAX_VALUE)。于是所有尚未触发的定时器这时就统一触发了,输出
定时器触发,触发时间:12000
定时器触发,触发时间:12001
7.3 窗口处理函数
除了按键分区的处理,还有就是窗口数据的处理,常用的有:
- ProcessWindowFunction
- ProcessAllWindowFunction
7.3.1 窗口处理函数的使用
进行窗口计算,我们可以直接调用现成的简单聚合方法(sum/max/min),也可以通过调用.reduce()或.aggregate()来自定义一般的增量聚合函数(ReduceFunction/AggregateFucntion);而对于更加复杂、需要窗口信息和额外状态的一些场景,我们还可以直接使用全窗口函数、把数据全部收集保存在窗口内,等到触发窗口计算时再统一处理。窗口处理函数就是一种典型的全窗口函数。
窗口处理函数 ProcessWindowFunction 的使用与其他窗口函数类似,也是基于WindowedStream 直接调用方法就可以,只不过这时调用的是.process()
stream.keyBy( t -> t.f0 ).window( TumblingEventTimeWindows.of(Time.seconds(10)) ).process(new MyProcessWindowFunction())
7.3.2 ProcessWindowFunction 解析
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window>extends AbstractRichFunction/*
IN: 输入数据类型
OUT:输出数据类型
KEY:数据中key的类型
W:窗口类型
*/
方法:
// 窗口数据的处理
public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out);
/*
key: 键
context: 上下文
elements: 窗口收集到用来计算的所有数据,这是一个可迭代的集合类型
out: 发送输出结果的收集器
*/// 这主要是方便我们进行窗口的清理工作。如果我们自定义了窗口状态,那么必须在.clear()方法中进行显式地清除,避免内存溢出
public void clear(Context context);
还定义了一个抽象类
public abstract class Context implements java.io.Serializable
// 我们之前可以看到,processFunction用的都是Context,但是这里ProcessWindowFunction 自己定义了一个Context,他是没有定时器的。为什么呢?因为本身窗口操作已经起到了一个触发计算的时间点,一般情况下是没有必要去做定时操作的。如果非要这么做,可以使用窗口触发器Trigger,里面有一个TriggerContext
ProcessAllWindowFunction的用法相似
stream.windowAll( TumblingEventTimeWindows.of(Time.seconds(10)) ).process(new MyProcessAllWindowFunction())
7.4 应用案例——TopN
窗口的计算处理,在实际应用中非常常见。对于一些比较复杂的需求,如果增量聚合函数无法满足,我们就需要考虑使用窗口处理函数这样的“大招”了。
网站中一个非常经典的例子,就是实时统计一段时间内的热门 url。例如,需要统计最近
10 秒钟内最热门的两个 url 链接,并且每 5 秒钟更新一次。我们知道,这可以用一个滑动窗口来实现,而“热门度”一般可以直接用访问量来表示。于是就需要开滑动窗口收集 url 的访问数据,按照不同的 url 进行统计,而后汇总排序并最终输出前两名。这其实就是著名的“Top N” 问题。
很显然,简单的增量聚合可以得到 url 链接的访问量,但是后续的排序输出 Top N 就很难实现了。所以接下来我们用窗口处理函数进行实现。
7.4.1 使用 ProcessAllWindowFunction
一种最简单的想法是,我们干脆不区分 url 链接,而是将所有访问数据都收集起来,统一进行统计计算。所以可以不做 keyBy,直接基于 DataStream 开窗,然后使用全窗口函数ProcessAllWindowFunction 来进行处理。
在窗口中可以用一个 HashMap 来保存每个 url 的访问次数,只要遍历窗口中的所有数据, 自然就能得到所有 url 的热门度。最后把 HashMap 转成一个列表 ArrayList,然后进行排序、取出前两名输出就可以了
public class ProcessAllWindowTopN {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event event, long l) {return event.getTimestamp();}}));SingleOutputStreamOperator<String> urlStream = stream.map(new MapFunction<Event, String>() {@Overridepublic String map(Event event) throws Exception {return event.getUrl();}});SingleOutputStreamOperator<String> result = urlStream.windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))).process(new ProcessAllWindowFunction<String, String, TimeWindow>() {@Overridepublic void process(ProcessAllWindowFunction<String, String, TimeWindow>.Context context,Iterable<String> elements, Collector<String> out) throws Exception {HashMap<String, Long> urlCountMap = new HashMap<>(10);for (String url : elements) {if (urlCountMap.containsKey(url)) {long count = urlCountMap.get(url);urlCountMap.put(url, count + 1);} else {urlCountMap.put(url, 1L);}}// 转存为ArrayListArrayList<Tuple2<String, Long>> mapList = new ArrayList<Tuple2<String, Long>>();for (String key : urlCountMap.keySet()) {mapList.add(Tuple2.of(key, urlCountMap.get(key)));}mapList.sort(new Comparator<Tuple2<String, Long>>() {@Overridepublic int compare(Tuple2<String, Long> o1, Tuple2<String, Long> o2) {return o2.f1.intValue() - o1.f1.intValue();}});// 取排序后的前两名,构建输出结果StringBuilder result = new StringBuilder();result.append("========================================\n");for (int i = 0; i < 2; i++) {Tuple2<String, Long> temp = mapList.get(i);String info = "浏览量 No." + (i + 1) +" url:" + temp.f0 +" 浏览量:" + temp.f1 +" 窗口结束时间:" + new Timestamp(context.window().getEnd()) + "\n";result.append(info);}result.append("========================================\n");out.collect(result.toString());}});result.print();env.execute();}
}7.4.2 使用KeyedProcessFunction
直接将所有数据放在一个分区上进行开窗操作。这相当于将并行度强行设置为 1,在实际应用中是要尽量避免的。
思路:
(1)读取数据源
(2)提取时间戳并生成水位线
(3)按照url进行keyBy分区
(4)开长度为10s步长为5的滑动窗口
(5)使用增量聚合函数 AggregateFunction,并结合全窗口函数 WindowFunction 进行窗口聚合,得到每个 url、在每个统计窗口内的浏览量,包装成 UrlViewCount
(6)按照窗口进行 keyBy 分区操作
(7)对同一窗口的统计结果数据,使用 KeyedProcessFunction 进行收集并排序输出
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7iv6fbOt-1693232836517)(第七章处理函数.assets/image-20230406003916609.png)]
// 自定义增量聚合
public class UrlViewCountAgg implements AggregateFunction<Event, Long, Long> {@Overridepublic Long createAccumulator() {return 0L;}@Overridepublic Long add(Event event, Long accumulator) {return accumulator + 1;}@Overridepublic Long getResult(Long accumulator) {return accumulator;}@Overridepublic Long merge(Long aLong, Long acc1) {return null;}
}
便于按窗口统计
public class UrlViewCount {public String url;public Long count;public Long windowStart;public Long windowEnd;public UrlViewCount() {}public UrlViewCount(String url, Long count, Long windowStart, Long windowEnd) {this.url = url;this.count = count;this.windowStart = windowStart;this.windowEnd = windowEnd;}@Overridepublic String toString() {return "UrlViewCount{" +"url='" + url + '\'' +", count=" + count +", windowStart=" + windowStart +", windowEnd=" + windowEnd +'}';}
}
窗口聚合函数
public class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {@Overridepublic void process(String url, ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow>.Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {long start = context.window().getStart();long end = context.window().getEnd();System.out.println(url);System.out.println(elements);out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));}
}
排序取TopN
public class TopN extends KeyedProcessFunction<Long, UrlViewCount, String> {private Integer n;// 定义一个列表状态private ListState<UrlViewCount> urlViewCountListState;public TopN(Integer n) {this.n = n;}@Overridepublic void open(Configuration parameters) throws Exception {// 从环境中获取列表状态句柄urlViewCountListState = getRuntimeContext().getListState(new ListStateDescriptor<UrlViewCount>("url-view-count-list", Types.POJO(UrlViewCount.class)));}@Overridepublic void processElement(UrlViewCount value, KeyedProcessFunction<Long, UrlViewCount, String>.Context ctx, Collector<String> out) throws Exception {// 将 count 数据添加到列表状态中,保存起来urlViewCountListState.add(value);// 注册 window end + 1ms 后的定时器,等待所有数据到齐开始排序ctx.timerService().registerEventTimeTimer(ctx.getCurrentKey() + 1);}@Overridepublic void onTimer(long timestamp, KeyedProcessFunction<Long, UrlViewCount, String>.OnTimerContext ctx, Collector<String> out) throws Exception {// 将数据从列表状态变量中取出,放入 ArrayList,方便排序ArrayList<UrlViewCount> urlViewCountArrayList = new ArrayList<>();for (UrlViewCount urlViewCount : urlViewCountListState.get()) {urlViewCountArrayList.add(urlViewCount);}// 清空状态,释放资源urlViewCountListState.clear();// 排 序urlViewCountArrayList.sort(new Comparator<UrlViewCount>(){@Overridepublic int compare(UrlViewCount o1, UrlViewCount o2) {return o2.count.intValue() - o1.count.intValue();}});// 取前两名,构建输出结果StringBuilder result = new StringBuilder(); result.append("========================================\n");result.append("窗口结束时间:" + new Timestamp(timestamp - 1) + "\n");for (int i = 0; i < this.n; i++) {UrlViewCount UrlViewCount = urlViewCountArrayList.get(i); String info = "No." + (i + 1) + " "+ "url:" + UrlViewCount.url + " "+ "浏览量:" + UrlViewCount.count + "\n"; result.append(info);} result.append("========================================\n");out.collect(result.toString());}
}
主方法:
public class KeyedProcessTopN {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// 从自定义数据源读取数据SingleOutputStreamOperator<Event> eventStream = env.addSource(new ClickSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Event>() {@Overridepublic long extractTimestamp(Event element, long recordTimestamp) {return element.getTimestamp();}}));SingleOutputStreamOperator<UrlViewCount> urlCountStream = eventStream.keyBy(Event::getUrl).window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))).aggregate(new UrlViewCountAgg(), new UrlViewCountResult());SingleOutputStreamOperator<String> result = urlCountStream.keyBy(data -> data.windowEnd).process(new TopN(2));result.print();env.execute();}
}
其实这里面是可以优化的。每次其实是把所有url——count都会发过来,保存到一个列表状态中。虽然只是一个窗口的,但是如果数据量大的话还是可以优化的。
7.5 侧输出流
处理函数还有另外一个特有功能,就是将自定义的数据放入“侧输出流”(side output)输出。这个概念我们并不陌生,之前在讲到窗口处理迟到数据时,最后一招就是输出到侧输出流。而这种处理方式的本质,其实就是处理函数的侧输出流功能。
我们之前讲到的绝大多数转换算子,输出的都是单一流,流里的数据类型只能有一种。而侧输出流可以认为是“主流”上分叉出的“支流”,所以可以由一条流产生出多条流,而且这些流中的数据类型还可以不一样。利用这个功能可以很容易地实现“分流”操作。
具体应用时,只要在处理函数的.processElement()或者.onTimer()方法中,调用上下文的.output()方法就可以了
DataStream<Integer> stream = env.addSource(...);
SingleOutputStreamOperator<Long> process = eventStream.process(new ProcessFunction<Integer, Long>() {@Overridepublic void processElement(Integer value, ProcessFunction<Integer, Long>.Context ctx, Collector<Long> out) throws Exception {out.collect(Long.valueOf(value));ctx.output(outputTag, "side-output: " + value);}
});
这里 output()方法需要传入两个参数,第一个是一个“输出标签”OutputTag,用来标识侧输出流,一般会在外部统一声明;第二个就是要输出的数据。
我们可以在外部先将 OutputTag 声明出来
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
如果想要获取这个侧输出流,可以基于处理之后的 DataStream 直接调用.getSideOutput() 方法,传入对应的 OutputTag,这个方式与窗口 API 中获取侧输出流是完全一样的。
DataStream<String> stringStream = longStream.getSideOutput(outputTag);
相关文章:

《Flink学习笔记》——第七章 处理函数
为了让代码有更强大的表现力和易用性,Flink 本身提供了多层 API 在更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process&a…...
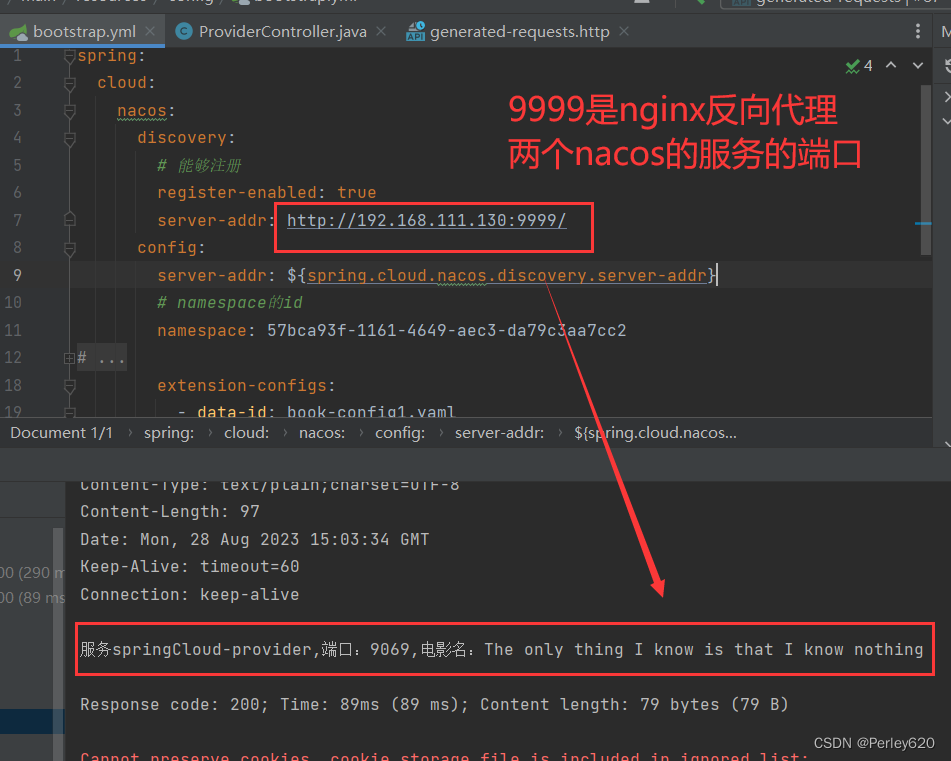
Nacos基础(3)——nacos+nginx 集群的配置和启动 端口开放 nginx反向代理nacos集群
目录 引出nacos集群nginx反向代理nacos集群停止单例nacos准备8848和8858修改cluster.conf配置【配置】修改启动配置文件【配置】开放8858的端口分别以集群方式启动【启动】前端访问查看生产者测试8858nacos nginx反向代理配置代理tcp代理http启动nginx反向代理容器生产者访问测…...

传承精神 缅怀伟人——湖南多链优品科技有限公司赴韶山开展红色主题活动
8月27日上午, 湖南多链优品科技有限公司全体员工怀着崇敬之情,以红色文化为引领,参加了毛泽东同志诞辰130周年的纪念活动。以董事长程小明为核心的公司班子成员以及全国优秀代表近70人一行专赴韶山,缅怀伟人毛泽东同志的丰功伟绩。…...

安全知识普及-如何创建一个安全的密码
文章目录 安全密码的特点创建安全密码的方法为何要创建一个安全的密码推荐阅读 安全密码是一种强化的密码,旨在提供更高级别的安全性,以防止未经授权的访问、数据泄露和其他安全威胁。 安全密码的特点 安全密码,有七大特点,特点如…...

Lua基础知识
文章目录 1. Lua简介1.1 设计目的:1.2 特性1.3 应用场景 2. Lua脚本学习2.1 安装2.2 lua操作2.3 lua案例 学习lua主要是为了后续做高性能缓存架构所准备的基础技术。可以先了解下基础,在实际使用时,再查缺补漏。 1. Lua简介 Lua 是一种轻量小…...

Java Math方法记录
Java 提供 java.lang.Math 类,很方便的进行数学运算。 Math 类是基于浮点数的运算,可能导致精度损失,不适用于高精度计算。 记录如下 常量 提供了两个常量, Math.PI :圆周率πMath.E :自然对数的底数 …...
)
Java XPath 使用(2023/08/29)
Java XPath 使用(2023/08/29) 文章目录 Java XPath 使用(2023/08/29)1. 前言2. 技术选型3. 技术实现 1. 前言 众所周知,Java 语言适合应用于 Web 开发领域,不擅长用来编写爬虫。但在 Web 开发过程中有时又…...
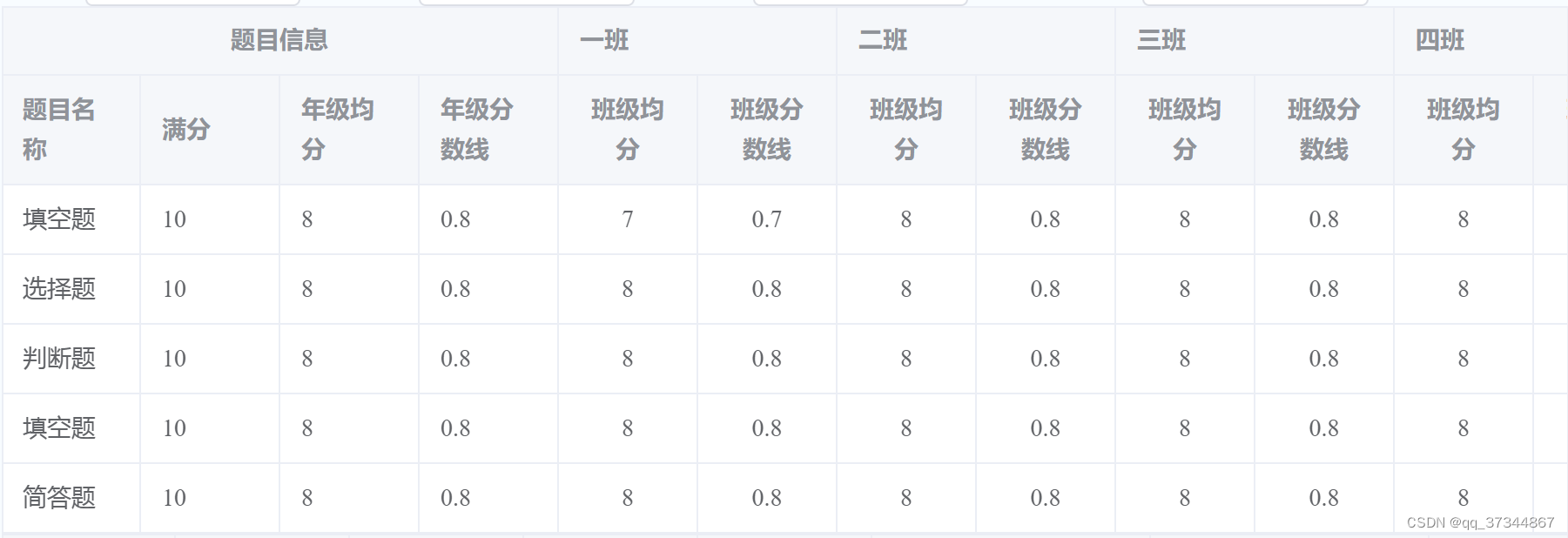
el-table动态生成多级表头的表格(js + ts)
展示形式: 详细代码: (js) <template><div><el-table :data"tableData" style"width: 100%"><el-table-column label"题目信息" align"center"><el-table-…...
四、Kafka Broker
4.1.1 Zookeeper 存储的 Kafka 信息 4.1.2 Kafka Broker 总体工作流程 4.2 生产经验 - 节点的服役和退役 自己的理解:其实就是将kafka的分区,负载到集群中的各个节点上。 1、服役新节点 2、退役旧节点 4.3 kafka副本 1、副本的作用 2、Leader的选…...
ssm+vue医院医患管理系统源码和论文
ssmvue医院医患管理系统源码和论文077 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm vue.js 摘 要 21世纪的今天,随着社会的不断发展与进步,人们对于信息科学化的认识,已…...
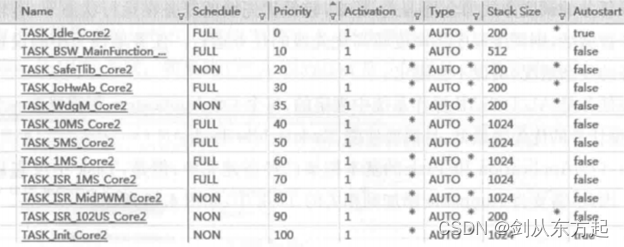
汽车电子笔记之:基于AUTOSAR的电机控制器架构设计
目录 1、概述 2、AUTOSAR设计 2.1、SWC设计 2.2、PORT设计 2.3、Runnable设计 2.4、电机控制器OS实现 1、概述 电机控制器应用层的软件架构较为复杂,主要包括PMSM(Permanent-MagnetSynchronous Motor)的矢量控制算法。根据PMSM的控制算法,对算法中的软件功能进行分析&…...

Docker 可以共享主机的参数
命令 docker run -it --ipchost nginx:latest /bin/bashdocker run -it --nethost nginx:latest /bin/bashdocker run -it --pidhost nginx:latest /bin/bashdocker run -it --utshost nginx:latest /bin/bash 参考 Docker run reference | Docker Docs...
)
STL之list模拟实现(反向迭代器讲解以及迭代器失效)
这次是关于list的模拟实现的代码,先看看下面的代码: #pragma once #include <iostream> #include "reve_iterator.hpp" using namespace std; namespace cc {//链表节点template<class T>struct ListNode{T _val;ListNode *_next…...

Firewalld防火墙新增端口、开启、查看等
Linux操作系统中,Firewalld防火墙相关操作如下: 安装 yum install firewalld firewalld-configFirewall开启常见端口命令 新增防火墙端口命令: firewall-cmd --zonepublic --add-port80/tcp --permanentfirewall-cmd --zonepublic --add-…...
【腾讯云 TDSQL-C Serverless 产品测评】- 云原生时代的TDSQL-C MySQL数据库技术实践
一、活动介绍: “腾讯云 TDSQL-C 产品测评活动”是由腾讯云联合 CSDN 推出的针对数据库产品测评及产品体验活动,本次活动主要面向 TDSQL-C Serverless版本,初步的产品体验或针对TDSQL-C产品的自动弹性能力、自动启停能力、兼容性、安全、并发…...

计算机硬件基础
计算机硬件基础 教程:计算机硬件基础_哔哩哔哩_bilibili 一.计算机的分类 台式机、笔记本电脑、上网本、超薄笔记本、平板电脑、游戏本、智能手机、超级移动电脑、便携式电脑、车用电脑、工作站、服务器、工业电脑IPC、ECDIS 二.机箱 放硬件的地方、一般由钢和铝等…...

云计算和Docker分别适用场景
在大规模网络爬虫系统中,通过使用云计算和Docker技术,可以实现大规模网络爬虫系统的高效架构设计和部署。这种架构能够提供可扩展性、高可用性和灵活性,为爬虫系统的运行和管理带来便利。 云计算和Docker在大规模网络爬虫系统中有不同的业务…...
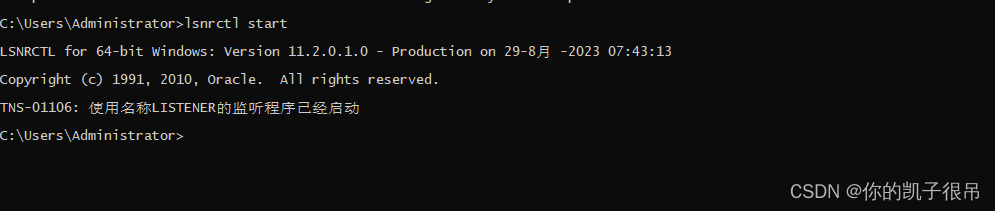
oracle 基础运用2
首先在电脑上安装PLSQL developer,这个是oracle图形化连接工具,然后安装win64_11gR2_client,这个是orace客户端,安装完成后可以在cmd命令行输入sqlplus命令进行验证,如图表示安装成功。 作为sys的连接应该是SySDBA或Sy…...

ThinkPHP 资源路由的简单使用,restfull风格API
ThinkPHP 资源路由的简单使用,restfull风格API 一、资源控制器二、资源控制器简单使用 一、资源控制器 资源控制器可以轻松的创建RESTFul资源控制器,可以通过命令行生成需要的资源控制器,例如生成index应用的TestR资源控制器使用:…...

利用前缀树获取最小目录
一、任务名: 开发最小目录工具 二、任务描述 开发工具,从桶清单文件中列举出所有最小目录,并列举出每一个最小目录中包含的文件总数与文件总量。 最小目录的解释: 有以下几个目录 a/b/1.txt a/b/2/txt a/3.txt a/b/c/ 则&…...

Jable视频下载工具:高效解决方案与专业使用指南
Jable视频下载工具:高效解决方案与专业使用指南 【免费下载链接】jable-download 方便下载jable的小工具 项目地址: https://gitcode.com/gh_mirrors/ja/jable-download 问题诊断:视频下载的四大核心挑战 技术门槛障碍 传统视频下载工具往往需要…...
)
Ubuntu22.04下RocketMQ-CPP客户端2.2.0编译踩坑实录(附完整依赖包下载)
Ubuntu 22.04下RocketMQ-CPP客户端2.2.0编译全指南:从依赖解析到实战应用 在分布式消息中间件领域,RocketMQ以其高吞吐、低延迟的特性成为企业级应用的首选。而RocketMQ-CPP客户端作为C生态的重要桥梁,其编译过程却常让开发者陷入依赖地狱和…...

从零到集群:基于Rocky Linux ARM64的虚拟化平台构建与自动化部署实战
1. 环境准备与基础配置 第一次接触ARM64架构的虚拟化平台搭建时,我踩过不少坑。不同于常见的x86环境,Rocky Linux ARM64在驱动支持和软件生态上有其特殊性。我们先从最基础的物理服务器配置说起。 假设你面前是一台刚拆封的ARM架构服务器,我…...

PlugY:重塑暗黑破坏神2单机体验的技术突破
PlugY:重塑暗黑破坏神2单机体验的技术突破 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 一、问题篇:暗黑破坏神2单机模式的技术痛点 作为一…...
教程)
课灵h5p-标签页 (Tabs)教程
标签页 (Tabs)教程 标签页 (Tabs) 是一种高效的内容容器,通过水平切换的选项卡界面来组织信息。它允许你在同一页面空间内并行展示多个同层级的主题(如不同类别的资源、不同语言的版本),帮助学习者按需浏览,保持界面整…...
)
别再手动另存为了!用Python脚本5分钟搞定上百个Excel文件的格式转换(附完整代码)
别再手动另存为了!用Python脚本5分钟搞定上百个Excel文件的格式转换(附完整代码) 你是否曾经面对过这样的场景:电脑里堆积着上百个老旧的.xls格式Excel文件,每次需要使用时都得手动一个个"另存为"xlsx格式&a…...

从数据孤岛到智能决策中枢:一体化系统如何重构 HR 数据流
去年某制造企业 HR 总监跟我抱怨:员工入职要在招聘系统录一遍信息,转正时人事系统再录一遍,发工资时薪酬系统又要重新核对。三个系统互不相通,一个员工的完整档案要从三个地方拼凑。这不是个例,而是很多企业正在经历的…...

安防相机WDR功能实测:逆光场景下如何拍清车牌和人脸?
安防相机WDR功能实战解析:逆光场景下的车牌与人脸清晰拍摄指南 停车场出入口的监控画面中,一辆黑色轿车缓缓驶过,阳光从车尾方向直射镜头,车牌区域瞬间变成一片刺眼的白光——这是安防工程中最令人头疼的逆光场景。现代宽动态范围…...

iOS高级开发工程师技术体系与民航行业实践深度解析
第一章 iOS开发技术核心体系 1.1 Swift与Objective-C双语言生态 现代iOS开发需要掌握两种核心语言的技术特点: // Swift类型安全示例 enum FlightStatus {case scheduled, departed, landed, canceled }var currentStatus: FlightStatus = .scheduled// 编译器会阻止非法状…...

JavaScript PPTX操作终极指南:5分钟掌握PPT自动化生成技巧
JavaScript PPTX操作终极指南:5分钟掌握PPT自动化生成技巧 【免费下载链接】js-pptx Pure Javascript reader/writer for PowerPoint 项目地址: https://gitcode.com/gh_mirrors/js/js-pptx 在当今数字化时代,自动化办公已经成为提升工作效率的关…...